大数据课程D2——hadoop的概述
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 了解hadoop的定义和特点;
⚪ 掌握hadoop的基础结构;
⚪ 掌握hadoop的常见命令;
⚪ 了解hadoop的执行流程;
一、简介
1. 概述
1. HDFS(Hadoop Distributed File System - Hadoop分布式文件系统)是Hadoop提供的一套用于进行分布式存储的机制。
2. HDFS是Doug Cutting根据Google的论文<The Google File System>(GFS)来仿照实现的。
2. 特点
1. 能够存储超大文件。在HDFS集群中,只要节点数量足够多,那么一个文件无论是多大都能够进行存储 - HDFS会对文件进行切块处理。
2. 快速的应对和检测故障。在HDFS集群中,运维人员不需要频繁的监听每一个节点,可以通过监听NameNode来确定其他节点的状态 - DataNode会定时的给NameNode来发送心跳。
3. 具有高容错性。在HDFS中,会自动的对数据来保存多个副本,所以不会因为一个或者几个副本的丢失就导致数据产生丢失。
4. 具有高吞吐量。吞吐量实际上指的是集群在单位时间内读写的数据总量。
5. 可以在相对廉价的机器上来进行横向扩展。
6. 不支持低延迟的访问。在HDFS集群中,响应速度一般是在秒级别,很难做到在毫秒级别的响应。
7. 不适合存储大量的小文件。每一个小文件都会产生一条元数据,大量的小文件就会产生大量的元数据。元数据过多,会占用大量内存,同时会导致查询效率变低。
8. 简化的一致性模型。在HDFS中,允许对文件进行一次写入多次读取,不允许修改,但是允许追加写入。
9. 不支持超强事务甚至不支持事务。在HDFS中,因为数据量较大,此时不会因为一个或者几个数据块出现问题就导致所有的数据重新写入 - 在数据量足够大的前提下,允许出现容错误差。
二、基本概念
1. 基本结构
1. HDFS本身是一个典型的主从(M/S)结构:主节点是NameNode,从节点是DataNode。
2. HDFS会对上传的文件进行切分处理,切出来的每一个数据块称之为Block。
3. HDFS会对上传的文件进行自动的备份。每一个备份称之为是一个副本(replication/replicas)。如果不指定,默认情况下,副本数量为3。
4. HDFS仿照Linux设计了一套文件系统,允许将文件存储到不同的虚拟路径下,同时也设计了一套和Linux一样的权限策略。HDFS的根路径是/。
2. Block
1. Block是HDFS中数据存储的基本形式,即上传到HDFS上的数据最终都会以Block的形式落地到DataNode的磁盘上。
2. 如果不指定,默认情况下,Block的大小是134217728B(即128M)。可以通过dfs.blocksize属性来调节,放在hdfs-site.xml文件中,单位是字节。
3. 如果一个文件不足一个Block的指定大小,那么这个文件是多大,它所对应的Block就是多大。例如一个文件是70M,那么对应的Block就是70M。属性dfs.blocksize指定的值实际上可以立即为一个Block的最大容量。
4. 注意,在设计Block大小的时候,Block是维系在DataNode的磁盘上,要考虑Block在磁盘上的寻址时间以及传输时间(写入时间)的比例值。一般而言,当寻址时间是传输时间的1%的时候,效率最高。而计算机在磁盘上的寻址时间大概在10ms左右,那么写入时间就是10ms/0.01=1000ms=1s。考虑到绝大部分的服务器使用的是机械磁盘,机械磁盘的写入速度一般在120MB/s左右,此时一个Block大小是1s*120MB/s=120M左右。
5. HDFS会为每一个Block来分配一个唯一的编号BlockID。
6. 切块的意义:
a. 能够存储超大文件。
b. 能够进行快速备份。
3. NameNode
1. NameNode是HDFS中的主(核心)节点。在Hadoop1.X中,NameNode只能有1个,容易存在单点故障;在Hadoop2.X中,NameNode最多允许存在2个;在Hadoop3.X中,不再限制NameNode的数量,也因此在Hadoop3.X的集群中,NameNode不存在单点故障。
2. NameNode的作用:对外接收请求,记录元数据,管理DataNode。
3. 元数据(metadata)是用于描述数据的数据(大概可以将元数据理解为账本)。在HDFS中,元数据实际上是用于描述文件的一些性质。在HDFS中,将元数据拆分成了很多项,主要包含了以下几项:
a. 上传的文件名以及存储的虚拟路径,例如/log/a.log。
b. 文件对应的上传用户以及用户组。
c. 文件的权限,例如-rwxr-xr--。
d. 文件大小。
e. Block大小。
f. 文件和BlockID的映射关系。
g. BlockID和DataNode的映射关系。
h. 副本数量等。
4. 一条元数据大小大概在150B左右。
5. 元数据是维系在内存以及磁盘中。
a. 维系在内存中的目的是查询快
b. 维系在磁盘中的目的是持久化
6. 元数据在磁盘上的存储位置由属性hadoop.tmp.dir来决定,是放在core-site.xml文件中。如果不指定,默认情况下是放在/tmp下。
7. 和元数据相关的文件:
a. edits:写操作文件。用于记录HDFS的写操作。
b. fsimage:元映像文件。存储了NameNode对元数据的序列化形态(大概可以理解为元数据在磁盘上的持久化存储形式)。
8. 当NameNode接收到写操作(命令)的时候,会先将这个写操作(命令)记录到edits_inprogress文件中。记录成功之后,NameNode会解析这个命令,然后修改内存中的元数据。修改成功之后,会给客户端来返回一个ACK信号表示成功。在这个过程中,会发现,fsimage文件中的元数据并没有发生变化。
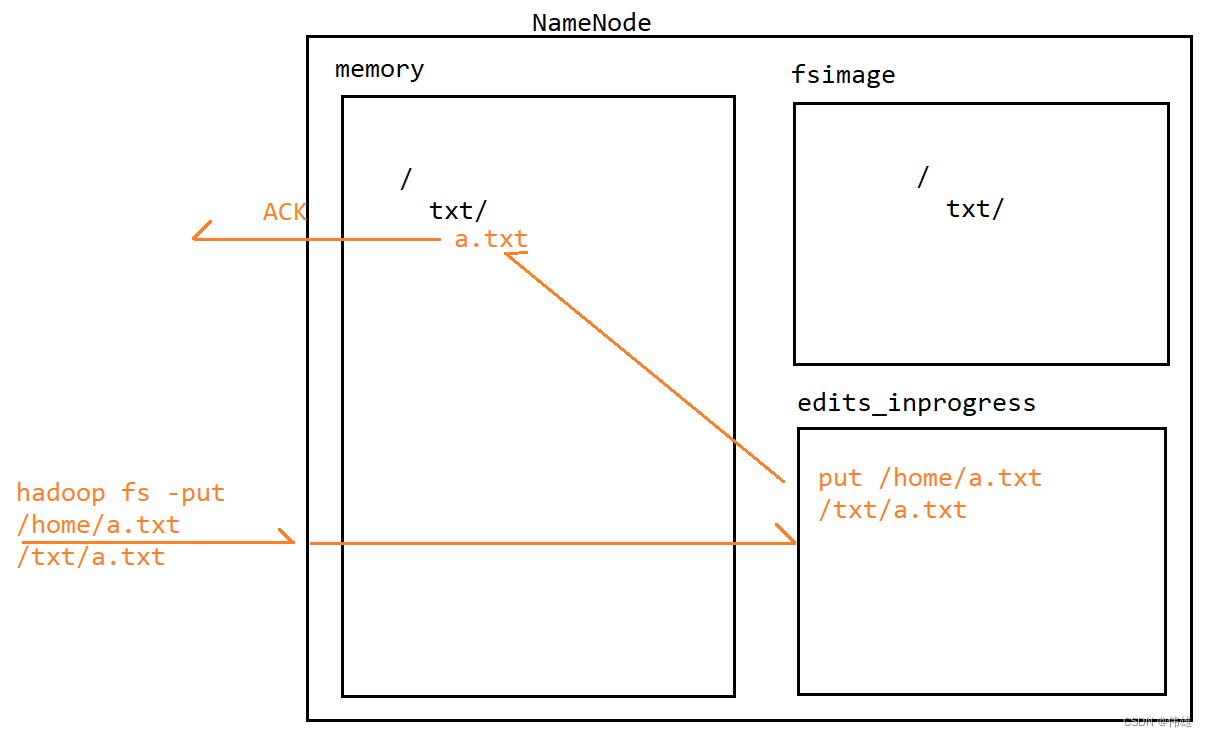
9. 随着运行时间的推移,edits_inprogress文件中记录的命令会越来越多,同时fsiamge文件中的元数据和内存中的元数据差别也会越来越大。因此,当达到指定条件的时候,edits_inprogress这个文件会产生滚动,滚动生成一个edits文件,同时产生一个新的edits_ingprogress文件。新来的写操作会记录到新的edits_inprogress文件中。滚动生成edits文件之后,NameNode会将edits文件中的命令再一一取出,解析之后修改fsimage文件中的元数据。
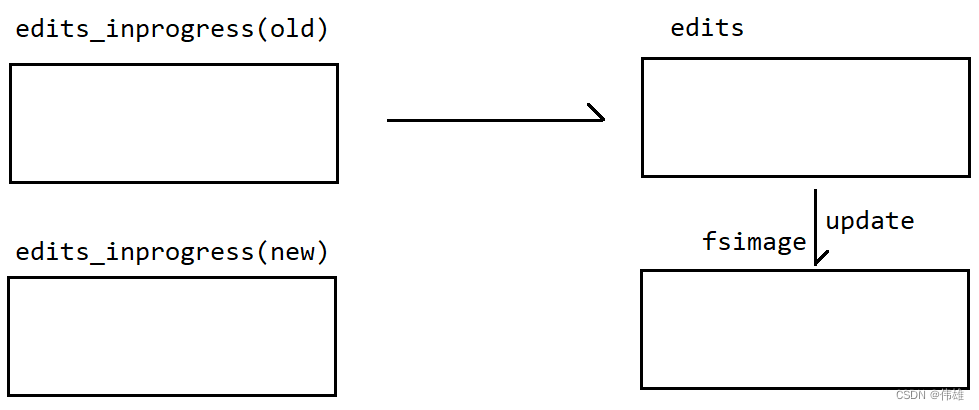
10. edits_inprogress文件的滚动条件:
a. 空间:当edits_inprogress文件达到指定大小(默认是40000,即当edits_inprogress文件中记录的元数据条目数达到40000条,可以通过属性dfs.namenode.checkpoint.txns来修改,放在hdfs-site.xml文件中)的时候,会自动滚动生成一个edits文件。
b. 时间:当距离上一次的滚动时间间隔达到指定大小(默认是3600s,可以通过属性dfs.namenode.checkpoint.period来修改,单位是秒,放在hdfs-site.xml文件汇总)的时候,edits_inprogress文件也会产生滚动。
c. 重启:当NameNode被重启的时候,会自动触发edits_inprogress文件的滚动。
d. 强制:可以通过hdfs dfsadmin -rollEdits命令来强制滚动。
11. 查看edits文件:hdfs oev -i edits_0000000000000000002-0000000000000000009 -o edits.xml
12. 在HDFS中,会将每一个写操作看作是一个事务,会给这个事务分配一个全局递增的编号,称之为事务id,简写为txid
13. 在HDFS中,会将开始记录日志以及结束记录日志都看作是一个写操作,都会分配一个事务id。因此,每一个edits文件,基本上都是以OP_START_LOG_SEGMENT开头,都是以OP_END_LOG_SEGMENT结尾
14. 查看fsimage文件:hdfs oiv -i fsimage_0000000000000000009 -o fsimage.xml -p XML
15. 每一个fsimage文件都会伴随着产生一个.md5文件,这个文件是对fsimage文件进行校验的
16. 需要注意的是,Hadoop在第一次启动之后的1min的时候,会自动触发一次edits_inprogress文件的滚动,之后就是按照指定的时间间隔来进行滚动
17. NameNode通过心跳机制来管理DataNode:DataNode会定时(默认是3s,通过属性dfs.heartbeat.interval来决定,单位是秒,放在hdfs-site.xml文件中)给NameNode发送心跳。如果超过指定的时间,NameNode没有收到DataNode的心跳,那么NameNode就会认为这个DataNode已经lost(丢失),此时NameNode会将这个DataNode上的数据复制一份备份到其他节点上来保证整个集群中的副本数量
18. 心跳的超时时间是由属性dfs.namenode.heartbeat.recheck-interval来决定。如果不指定,默认是300000,单位是毫秒,即300s=5min。但是在计算超时时间的时候,实际超时时间=2*dfs.namenode.heartbeat.recheck-interval + 10*dfs.heartbeat.interval来决定,所以如果不指定,实际超时时间为 2*5min + 10*3s = 10min30s
19. 心跳信号主要包含:
a. clusterid:集群编号。
Ⅰ. 在HDFS中,当NameNode被格式化(hadoop namenode -format)的时候,会自动计算产生一个clusterid。每次NameNode被格式化,都会自动重新计算产生一个新的clusterid。
Ⅱ. 当HDFS集群启动之后,NameNode就会等待DataNode的心跳。当NameNode第一次收到DataNode的心跳之后,会将clusterid在心跳响应中返回给DataNode。
Ⅲ. 当DataNode收到心跳响应之后,会将clusterid获取并且记录到本地的磁盘中,之后DataNode和NameNode之间进行的每一次通信(包括心跳)都会携带这个clusterid。
Ⅳ. NameNode在收到DataNode的请求之后,会先校验clusterid是否一致,如果不一致,则会放弃这个请求;如果一致,才会处理这个请求。
Ⅴ. 如果NameNode被多次格式化,就会导致DataNode和NameNode之间无法进行通信。
b. 当前DataNode的节点状态(预服役、服役、预退役)。
c. 当前DataNode上存储的Block的校验信息。
20. 安全模式:
a. 当NameNode被重启之后,自动进入安全模式。
b. 在安全模式中,NameNode会先自动触发edits_inprogress文件的滚动,滚动完成之后,会触发fsimage文件的更新。fsiamge文件更新完成之后,NameNode会将fsimage文件中的元数据加载到内存中,加载完成之后,会等待DataNode的心跳。
c. 如果没有收到DataNode的心跳,那么说明NameNode被重启过程中,DataNode也出现了骨渣古,此时NameNode就需要将DataNode上的数据备份到其他节点上来保证集群中的副本数量;如果NameNode收到了DataNode的心跳,会校验DataNode上的Block信息。如果校验失败,那么NameNode会试图恢复这个DataNode上的数据,恢复完成之后会再次校验,如果校验失败,则重新恢复重新校验;如果校验成功,则NameNode自动退出安全模式。
21. 之所以存在安全模式,实际上是HDFS集群保证数据的完整性。
22. 在安全模式中,HDFS集群只能读(下载)不能写(上传)。
23. 在实际过程中,如果在合理时间内,HDFS集群依然没有退出安全模式,则说明数据已经产生了不可挽回的丢失,此时需要考虑强制退出安全模式。
24. 常见命令:
| 命令 | 解释 |
| hdfs dfsadmin -safemode enter | 进入安全模式 |
| hdfs dfsadmin -safemode get | 查看安全模式状态 |
| hdfs dfsadmin -safemode leave | 退出安全模式 |
4. DataNode
1. DataNode是HDFS的从节点,主要用于存储数据,数据会以Block形式落地到磁盘上。
2. 数据在磁盘上的存储位置同样由hadoop.tmp.dir属性来决定。
3. DataNode会为每一个Block生成一个blk_xxx.meta文件,这个meta文件实际上是blk文件的校验文件。
4. DataNode的状态:预服役、服役、预退役、退役、丢失。
5. DataNode通过心跳机制向NameNode来注册信息。
5. SecondaryNameNode
1. SecondaryNameNode不是NameNode的热备份,但是SecondaryNameNode能够一定程度上对元数据做到备份,但不是全部 - SecondaryNameNode主要是负责edits_inprogress文件的滚动和fsimage文件的更新。
2. 在集群中,如果存在SecondaryNameNode,那么edits_inprogress文件的滚动和fsimage文件的更新是由SecondaryNameNode来完成;如果没有SecondaryNameNode,那么edits_inprogress文件的滚动和fsimage文件的更新就会由NameNode自己来完成。
3. 到目前为止,HDFS集群只支持两种结构:
a. 1个NameNode+1个SecondaryNameNode+n个DataNode。
b. n个NameNode(Hadoop2.X中是2个,Hadoop3.X中是n个,1个Active+多个Standby状态)+n个DataNode。
4. 在HDFS集群中,NameNode如果只有1个,那么NameNode宕机之后,整个集群就无法对外提供服务,所以必须对NameNode来进行备份,避免单点故障,所以在集群中,要考虑使用上述的第二种方案。
6. 机架感知策略
1. 在HDFS中,机架感知策略默认是不开启的。如果需要开启机架感知策略,那么需要在hadoop-site.xml文件中添加如下配置:
<property>
<name>topology.script.file.name</name>
<value>path/rackaware.py</value>
</property
2. 上述配置的value中,需要指定一个脚本文件的存储路径。脚本文件可以使用Python或者Shell等常见脚本语言来实现。
3. 在这个脚本中,需要定义一个Map。Map的键是主机名或者IP,Map的值是用户指定的机架名。只要保证值一致,那么就表示值对应的键放在同一个机架上。
4. 由于这个机架是通过Map映射来完成的,所以本质上是一个逻辑机架,也因此可以将不同物理机架上的节点配置在同一个逻辑机架上。在实际开发过程中,为了方便管理,往往是将同一个物理机架上的节点配置在同一个逻辑机架上。
7. 副本放置策略
1. 在HDFS中,支持多副本策略,这样能够有效的保证数据的可靠性。如果不指定,默认情况下,副本数量为3。通过属性dfs.replication来修改,放在hdfs-site.xml文件中
2. 在HDFS中,如果没有开启机架感知策略,那么默认也不会开启副本放置策略,那么此时多个副本是放在相对空闲的节点上
3. 如果启用了机架感知策略,那么对应的,HDFS也会启用副本放置策略。
a. 第一个副本:如果是集群内上传,则谁上传就放在谁身上;如果是集群外上传,则谁空闲就放在谁身上。
b. 第二个副本:放在和第一个副本相同机架的节点上。实际过程中,会考虑将同一个物理机架上的节点配置在同一个逻辑机架上,此时机架内传输会比跨机架传输要快一些。
c. 第三个副本:放在和第二个副本不同机架的节点上,保证不会因为一个机架整体出现故障导致数据产生丢失。
d. 更多副本:谁空闲放在谁身上。
8. 常见命令
| 命令 | 解释 |
| start-dfs.sh | 启动HDFS |
| stop-dfs.sh | 结束HDFS |
| hdfs --daemon start namenode | 启动NameNode |
| hdfs --daemon start datanode | 启动DataNode |
| hdfs --daemon start secondarynamenode | 启动SecondaryNameNode |
| hadoop fs -put /home/a.txt / 或者 hadoopfs -copyFromLocal /home/a.txt / | 上传文件 |
| hadoop fs -get /a.txt /home 或者 hadoop fs -copyToLocal /a.txt /home | 下载文件 |
| hadoop fs -mkdir /txt | 创建目录 |
| hadoop fs -mkdir -p /video/movie | 创建多级目录 |
| hadoop fs -rm /b.txt | 删除文件 |
| hadoop fs -rmdir /txt | 删除目录 |
| hadoop fs -rm -r /video | 递归删除目录 |
| hadoop fs -cat /c.txt | 查看文件内容 |
| hadoop fs -tail /c.txt | 查看文件最后1000个字节的数据 |
| hadoop fs -mv /c.txt /a.txt | 重命名或者剪切 |
| hadoop fs -cp /txt/a.txt /a.txt | 复制文件 |
| hadoop fs -ls / | 查看子文件或者子目录 |
| hadoop fs -ls -R / | 递归查看 |
| hadoop fs -setrep 3 /a.txt | 设置副本数量 |
| hadoop fs -chmod 777 /a.txt | 更改权限 |
| hadoop fs -chown tom /a.txt | 更改用户 |
| hadoop fs -chgrp tedu /a.txt | 更改用户组 |
9. 回收站机制
1. 在HDFS中,回收站机制默认是不开启的,此时删除命令会立即生效,且该操作此时不可逆。
2. 配置回收站策略,配置在cores-site.xml中。
<!--表示指定文件在回收站中的存放时间,单位是min-->
<!--如果超过指定的时间,依然没有将文件从回收站中还原回来-->
<!--回收站就会认为此时文件已经失效,就会清理掉-->
<!--如果不指定,那么此属性的值默认为0-->
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
3. 回收站的默认存放位置为/user/root/.Trash/Current/。
4. 如果需要将文件从回收站中还原回来,那么使用hadoop fs -mv命令即可。
三、流程
1. 写(上传)流程
1. 客户端发起RPC请求到NameNode,请求上传文件。
2. 当NameNode收到请求之后,会先进行校验:
a. 校验是否有指定路径 - FileNotFoundException。
b. 校验是否有写入权限 - AccessControlException。
c. 校验是否有同名文件 - FileAlreadyExistException。
3. 如果校验失败,则直接报错;如果校验成功,则NameNode会给客户端返回信号表示允许上传。
4. 当客户端收到信号之后,会再次给NameNode来发送请求,请求获取第一个Block的存储位置。
5. NameNode收到请求之后,会将这个Block的存储位置(实际上是DataNode的IP或者主机名,默认情况下会返回3个存储位置 - 副本数量为3)返回给客户端。
6. 客户端收到存储位置之后,会从这些地址中选取一个较近(实际上是网络拓扑距离)的地址,发送请求,请求建立pipeline(管道,实际上是基于NIO Channel)用于传输数据;第一个Block所在节点会给下一个Block所在的节点发送请求,请求建立pipeline;依此类推,直到最后一个请求应答成功。
7. 建立好管道应答成功之后,客户端会将当前的Block进行封包,将Packet写入第一个节点;写完之后,第一个Block所在的节点写入第二个节点,依次类推。
8. 当这个Block的所有副本写完之后,客户端会再次给NameNode发送请求,请求获取下一个Block的存储位置,重复5.6.7.8四个步骤,直到所有的Block全部写完。
9. 当客户端写完所有的Block之后,会给NameNode发送一个请求,请求关闭文件(关流)。文件一旦关闭,数据就不能修改。
2. 读(下载)流程
1. 客户端发起RPC请求到NameNode,请求下载文件。
2. NameNode收到请求之后,会先进行校验:
a. 校验是否有读取权限 - AccessControlException。
b. 校验是否有指定文件 - FileNotFoundException。
3. 如果校验失败,会直接报错;如果校验成功,则NameNode就会给客户端返回一个信号表示允许读取。
4. 客户端收到信号之后,会再次发送请求给NameNode,请求获取第一个Block的存储位置。
5. NameNode收到请求之后,会查询元数据,然后将这个Block的存储地址(默认情况下是3个)返回给客户端。
6. 客户端收到地址之后,会从这些地址中选取一个较近的地址来读取这个Block。
7. 读取完这个Block之后,客户端会对这个Block进行checkSum校验。如果校验失败,说明这个Block产生了变动,此时客户端会从剩余的地址中重新选取一个地址重新读取重新校验;如果校验成功,则客户端会再次给NameNode发送请求,请求获取下一个Block的存储位置,重复5.6.7三个步骤,直到读取完所有的Block。
8. 当客户端读取完最后一个Block之后,会给NameNode发送一个结束信号。NameNode收到信号之后会关闭这个文件。
3. 删除流程
1. 客户端发起RPC请求到NameNode,请求删除文件。
2. NameNode收到请求之后,会先进行校验:
a. 校验是否有删除权限 - AccessControlException。
b. 校验是否有指定文件 - FileNotFoundException。
3. 如果校验失败,则直接报错;如果校验成功,则NameNode会将这个写请求记录到edits_inprogress文件中,记录成功之后,会修改内存中的元数据;修改完成之后,NameNode会给客户端返回一个ACK信号表示删除成功。需要注意的是,此时文件并没有真正从HDFS上移除,仅仅是修改了元数据。
4. NameNode给客户端返回信号之后,就会等待DataNode的心跳。NameNode在收到DataNode的心跳之后,会在心跳响应中要求DataNode删除对应的Block。
5. DataNode在收到心跳响应之后,会按照NameNode的要求,去磁盘上删除文件对应的Block。注意,此时文件才真正的从HDFS上移除。
相关文章:
大数据课程D2——hadoop的概述
文章作者邮箱:yugongshiyesina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解hadoop的定义和特点; ⚪ 掌握hadoop的基础结构; ⚪ 掌握hadoop的常见命令; ⚪ 了解hadoop的执行流程; 一、简介 1…...
使用nginx和ffmpeg搭建HTTP FLV流媒体服务器(摄像头RTSP视频流->RTMP->http-flv)
名词解释 RTSP (Real-Time Streaming Protocol) 是一种网络协议,用于控制实时流媒体的传输。它是一种应用层协议,通常用于在客户端和流媒体服务器之间建立和控制媒体流的传输。RTSP允许客户端向服务器发送请求,如…...

揭秘APT团体常用的秘密武器——AsyncRAT
AsyncRAT 是 2019 年 1 月在 [GitHub](https://github.com/NYAN-x-CAT/AsyncRAT-C- Sharp)上开源的远控木马,旨在通过远程加密链接控制失陷主机,提供如下典型功能: 截取屏幕 键盘记录 上传/下载/执行文件 持久化 禁用 Windows Defender 关机/…...
Flutter Widget Life Cycle 组件生命周期
Flutter Widget Life Cycle 组件生命周期 视频 前言 了解 widget 生命周期,对我们开发组件还是很重要的。 今天会把无状态、有状态组件的几个生命周期函数一起过下。 原文 https://ducafecat.com/blog/flutter-widget-life-cycle 参考 https://api.flutter.dev/f…...

LeetCode面向运气之Javascript—第2600题-K件物品的最大和-94.68%
LeetCode第2600题-K件物品的最大和 题目要求 袋子中装有一些物品,每个物品上都标记着数字 1 、0 或 -1 。 四个非负整数 numOnes 、numZeros 、numNegOnes 和 k 。 袋子最初包含: numOnes 件标记为 1 的物品。numZeroes 件标记为 0 的物品。numNegOn…...
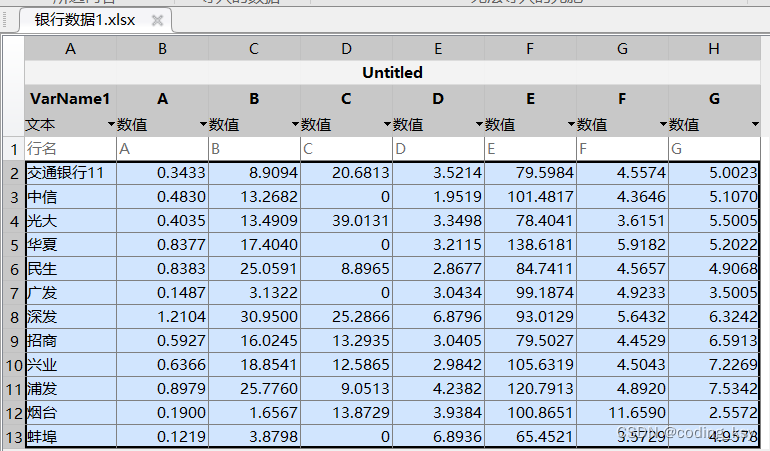
数学建模学习(4):TOPSIS 综合评价模型及编程实战
一、数据总览 需求:我们需要对各个银行进行评价,A-G为银行的各个指标,下面是银行的数据: 二、代码逐行实现 清空代码和变量的指令 clear;clc; 层次分析法 每一行代表一个对象的指标评分 p [8,7,6,8;7,8,8,7];%每一行代表一个…...
PHP之Smarty使用以及框架display和assign原理
一、Smarty的下载 进入Smarty官网下载,复制目录libs目录即可http://www.smarty.net/http://www.smarty.net/ 二、使用Smarty,创建目录demo,把libs放进去改名为Smarty 三、引入Smarty配置,创建目录,index.php文件配置 <?php…...
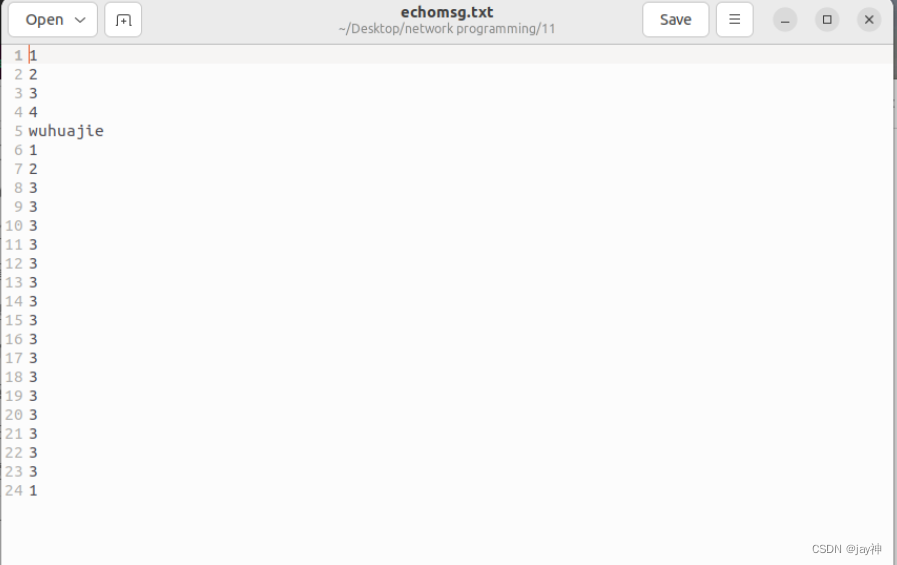
《TCP IP网络编程》第十一章
第 11 章 进程间通信 11.1 进程间通信的基本概念 通过管道实现进程间通信: 进程间通信,意味着两个不同的进程中可以交换数据。下图是基于管道(PIPE)的进程间通信的模型: 可以看出,为了完成进程间通信&…...
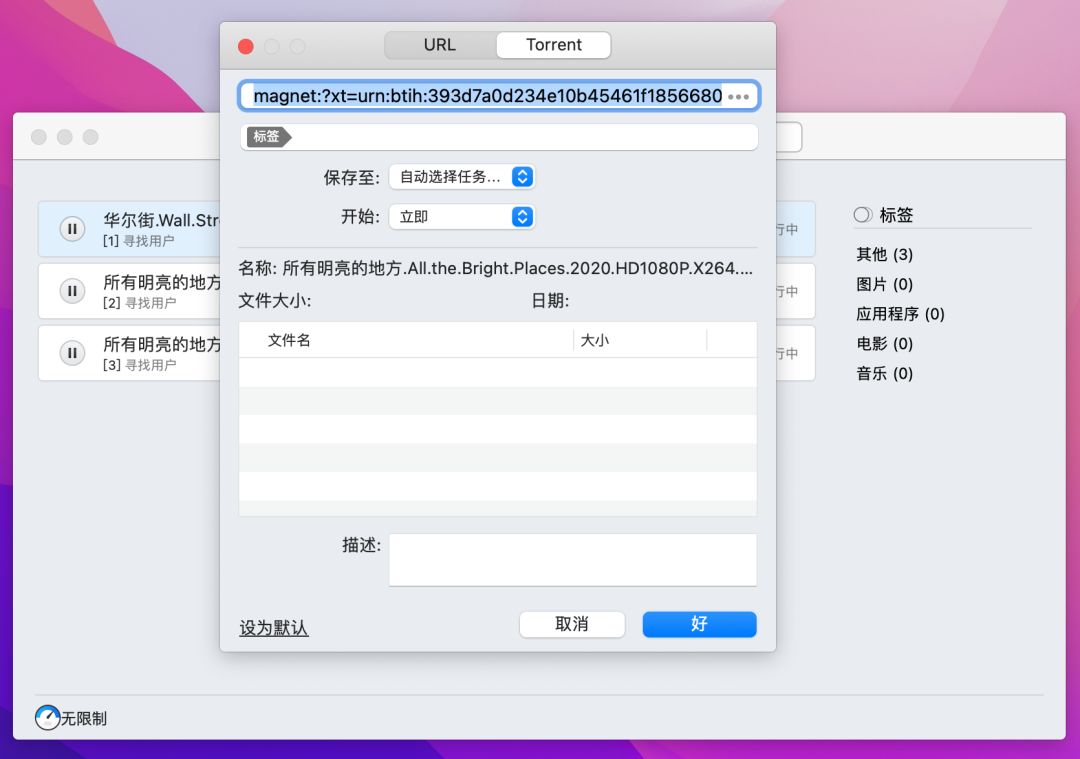
Folx Pro 5 最好用的Mac磁力链接BT种子下载工具
除了迅雷,还有哪个支持磁力链接下载?Mac电脑如何下载磁力链接?经常有小伙伴问老宅。今天,老宅给大家推荐Folx Pro For Mac,Mac系统超好用的磁力下载工具。 Folx是一款功能强大且易于使用的Mac下载管理器,并…...

Redis 数据库的高可用
文章目录 Redis 数据库的高可用一.Redis 数据库的持久化1.Redis 高可用概念2.Redis 实现高可用的技术2.1 持久化2.2 主从复制2.3 哨兵2.4 Cluster集群 3.Redis 持久化3.1 持久化的功能3.2 Redis 提供持久化的方式3.2.1 RDB 持久化3.2.2 AOF 持久化(append only file…...

elementPlus dialog组件设置可拖动,当内容高度大于视口高度拖动显示异常的解决办法
elementPlus UI的dialog弹框组件在设置了draggable属性后就可拖动弹框,但是当弹框的内容高度大于视口高度时去拖动弹框就会出现显示问题。 解决办法(修改源码) 去node_modules下面找到element-plus文件夹,按照以下路径修改onMou…...
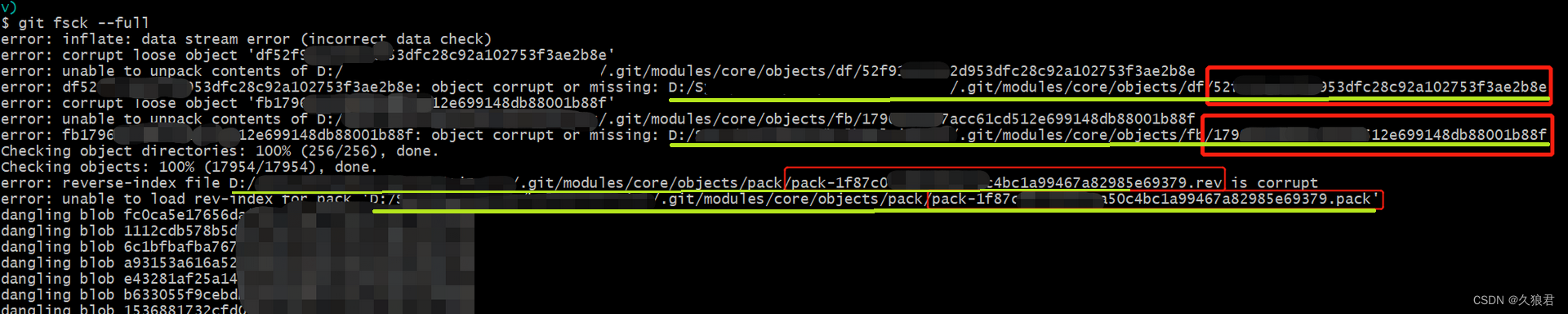
亲测解决Git inflate: data stream error (incorrect data check)
Git inflate: data stream error (incorrect data check) error: unable to unpack… 前提是你的repository在github等服务器或者其他路径有过历史备份/副本,不要求是最新版本的,只要有就可能恢复你做的所有工作。 执行git fsck --full检查损坏的文件 在…...
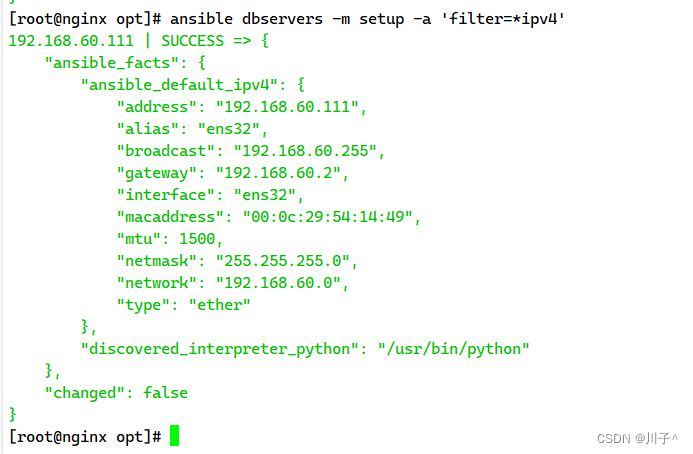
Ansible 自动化运维工具
Ansible 简介 Ansible 自动化运维工具(机器管理工具)可以实现批量管理多台(成百上千)主机,应用级别的跨主机编排工具。现在也在自动化管理领域大放异彩。它融合了众多老牌运维工具的优点,Pubbet和Saltstac…...
node.js 爬虫图片下载
主程序文件 app.js 运行主程序前需要先安装使用到的模块: npm install superagent --save axios要安装指定版,安装最新版会报错:npm install axios0.19.2 --save const {default: axios} require(axios); const fs require(fs); const superagent r…...

VAE-根据李宏毅视频总结的最通俗理解
1.VAE的直观理解 先简单了解一下自编码器,也就是常说的Auto-Encoder。Auto-Encoder包括一个编码器(Encoder)和一个解码器(Decoder)。其结构如下: 自编码器是一种先把输入数据压缩为某种编码, 后仅通过该编…...
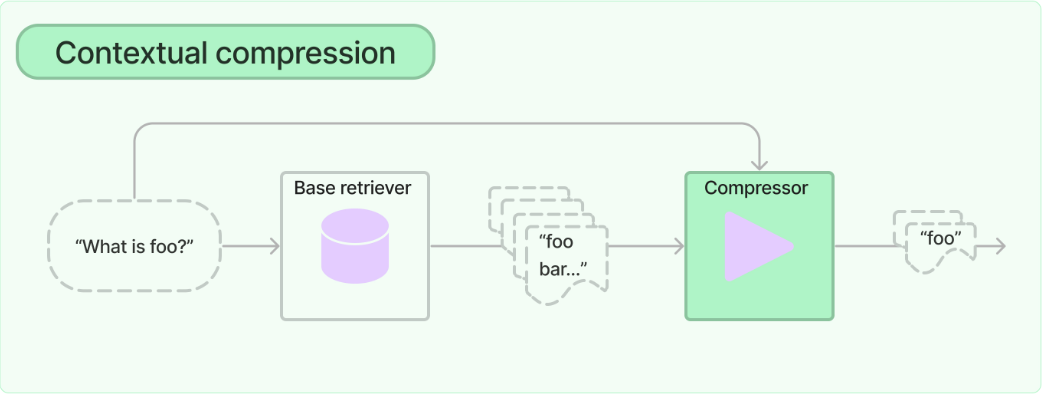
【LangChain】检索器之上下文压缩
LangChain学习文档 【LangChain】检索器(Retrievers)【LangChain】检索器之MultiQueryRetriever【LangChain】检索器之上下文压缩 上下文压缩 LangChain学习文档 概要内容使用普通向量存储检索器使用 LLMChainExtractor 添加上下文压缩(Adding contextual compression with an…...
uniapp 语音文本播报功能
最近uniapp项目上遇到一个需求 就是在接口调用成功的时候加上语音播报 , ‘创建成功’ ‘开始成功’ ‘结束成功’ 之类的。 因为是固定的文本 ,所以我先利用工具生成了 文本语音mp3文件,放入项目中,直接用就好了。 这里用到的工…...

腾讯云高IO型云服务器CPU型号处理器主频性能
腾讯云服务器高IO型CVM实例CPU处理器主频性能说明,高IO型云服务器具有高随机IOPS、高吞吐量、低访问延时等特点,适合对硬盘读写和时延要求高的高性能数据库等I/O密集型应用,腾讯云服务器网分享高IO型云服务器IT5和IT3的CPU处理器说明…...
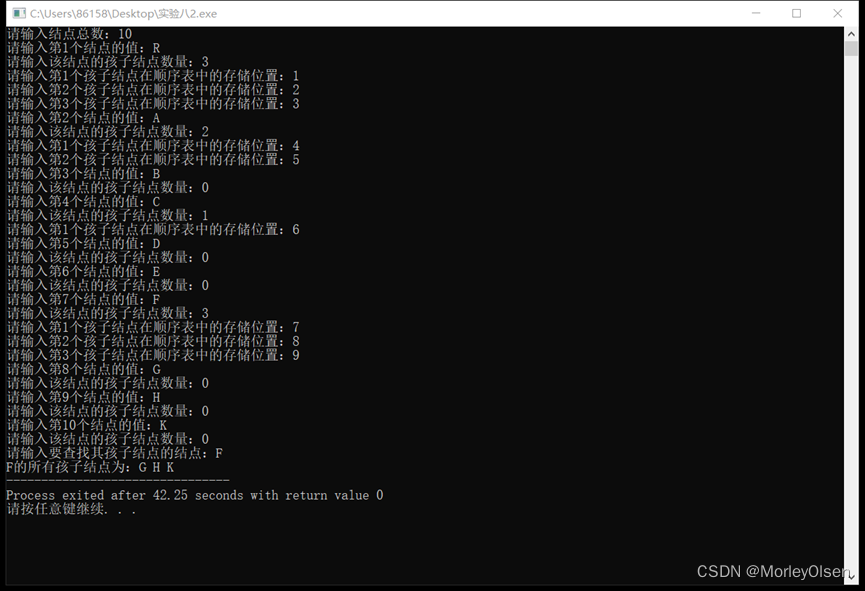
【数据结构】实验八:树
实验八 树 一、实验目的与要求 1)理解树的定义; 2)掌握树的存储方式及基于存储结构的基本操作实现; 二、 实验内容 题目一:采用树的双亲表示法根据输入实现以下树的存储,并实现输入给定结点的双亲结点…...
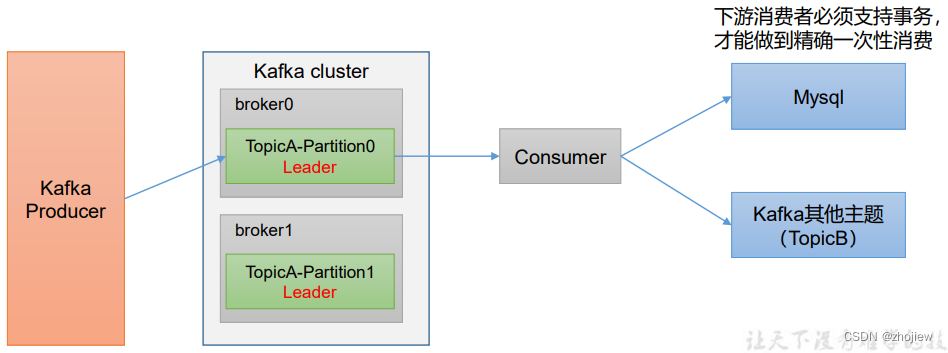
kafka消费者api和分区分配和offset消费
kafka消费者 消费者的消费方式为主动从broker拉取消息,由于消费者的消费速度不同,由broker决定消息发送速度难以适应所有消费者的能力 拉取数据的问题在于,消费者可能会获得空数据 消费者组工作流程 Consumer Group(CG&#x…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

百考通智能任务书:贴合你的选题,拒绝空话假大空
毕业设计任务书是高校教学管理中的关键环节,它不仅标志着研究工作的正式启动,更是后续开题、实施、论文撰写和答辩全过程的行动依据。然而,许多学生在撰写时常常因不熟悉本专业写作规范、技术表达能力有限,或缺乏权威模板参考而陷…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...

2026 西安 AI 问答曝光搭建技术解析:GEO 知识图谱 + 深度测评
随着大语言模型技术的快速普及,AI 搜索已经成为用户获取企业信息、商家服务的核心入口。根据中国互联网信息中心 2026 年发布的《中国人工智能搜索发展报告》显示,2025 年国内 AI 搜索用户规模突破 8.2 亿,日均搜索请求超过 20 亿次ÿ…...

2026 新视角:化妆品开发的底层逻辑,做好一款产品,从选对原料开始
在化妆品研发链条中,配方架构、生产工艺、包装设计固然重要,但决定一款产品上限的,永远是原料。一款稳定、安全、表现优异的护肤成品,离不开纯净、达标、批次一致的优质原料。对于品牌方、配方师、代工企业而言,原料不…...

2605.VGGT-Omega 论文解读: 3D重建的Scaling Law, Register Attention效率革命 | Oxford+Meta CVPR26 Oral
VGGT-Omega: Scaling Feed-Forward 3D Reconstruction Jianyuan Wang, Minghao Chen, Shangzhan Zhang, Nikita Karaev, Johannes Schonberger, et al. Visual Geometry Group, Oxford Meta AI | CVPR 2026 Oral | arXiv 2605.15195 Paper | Project Page 一句话总结 VGGT-Om…...

量子软件测试的挑战与优化策略
1. 量子软件测试的挑战与机遇量子计算正在从实验室走向实际应用,随之而来的是对可靠量子软件的需求激增。与传统软件不同,量子程序面临三大独特挑战:首先,量子态的叠加性和纠缠性使得测试变得异常复杂。一个n量子比特系统可以同时…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...

华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate
华硕笔记本终极性能控制指南:用G-Helper完全替代Armoury Crate 【免费下载链接】g-helper Lightweight Armoury Crate alternative for Asus laptops with nearly the same functionality. Works with ROG Zephyrus, Flow, TUF, Strix, Scar, ProArt, Vivobook, Zen…...

MongoDB Limit 与 Skip 方法详解
MongoDB Limit 与 Skip 方法详解 引言 MongoDB 是一个高性能、可伸缩的文档存储系统,它提供了强大的数据存储和查询功能。在处理大量数据时,Limit 与 Skip 方法是 MongoDB 中常用的查询优化工具。本文将详细介绍 MongoDB 中的 Limit 与 Skip 方法,包括其基本用法、性能影响…...