MySQL优化(面试)
文章目录
- 通信优化
- 查询缓存
- 语法解析及查询优化器
- 查询优化器的策略
- 性能优化建议
- 数据类型优化
- 索引优化
- 优化关联查询
- 优化limit分页
- 对于varchar
- end
mysql查询过程:

- 客户端向MySQL服务器发送一条查询请求
- 服务器首先检查查询缓存,如果命中缓存,则立刻返回存储在缓存中的结果。否则进入下一阶段
- 服务器进行SQL解析、预处理、再由优化器生成对应的执行计划
- MySQL根据执行计划,调用存储引擎的API来执行查询
- 将结果返回给客户端,同时缓存查询结果
通信优化
因为mysql是半双工的,如果查询的数据太大就会类似阻塞住通信,以此减小数据通信间数据包大小:
所以说需要避免使用select*并且加上LIMIT限制
查询缓存
1.类似于一层hashMap的缓存层
如果查询中包含自定义函数,存储函数,用户变量临时表小图标
则查询结果都不会缓存
2.不要轻易打开缓存,如果修改数据次数比较多,系统将需要费更多的精力用来删和读缓存,还会有碎片产生
1.多个小表替代大表
2.批量少次插入
3.合理控制缓存空间
4.可以通过SQL_CACHE和SQL_NO_CACHE来控制某个查询语句是否需要进行缓存(将query_cache_type设置为DEMAND,这时只有加入SQL_CACHE的查询才会走缓存)
语法解析及查询优化器
语法树—>查询计划
语法树是指语法分析阶段的将源代码转换为可执行代码
查询计划是指查询在数据库中实际执行时所采取的具体操作方式,但是查询计划一般有多个,性能对应也不同,就需要找到最优执行计划,
基于成本的优化器使得mysql会尝试每个查询计划并计算成本,(性能因素:数据量,硬件资源,执行算法之类的)
last_query_cost值就是查询的成本,单位: 次数据页的随机查找
(让我想起了英伟达还是哪家的一个算法,
计算性能过剩,但是处理过程长
就猜测处理的结果,然后在上一个函数结果导出前,把几个猜测的结果放到下一个函数运行,
如果上一个函数结果猜对的有就使用对应的下一个函数的预测结果)
查询优化器的策略
定义表的关联顺序
优化MIN()和MAX()函数
提前终止查询
优化排序
性能优化建议
只是建议,在实际生产或者测试的情况下需要仔细斟酌优化的可能性
数据类型优化
遵循小而简单,就会节省磁盘,内存,CPU(是表,字段,都相对的变小)
整形比字符串代价低(但是uuid针对分布式大数据还是挺好用的)
- 选择最合适的数据类型: 使用最合适的数据类型来存储数据可以节省存储空间并提高查询性能。例如,使用TINYINT代替INT或VARCHAR代替TEXT,并且指定其宽度
- 避免过大的数据类型: 不要使用过大的数据类型,这会占用更多的存储空间,并且在查询和索引操作时增加额外的开销。尽量选择更小的数据类型,以节约存储和提高查询性能
- 整数类型优先于浮点类型: 整数类型的比较和计算通常比浮点类型更快,因此如果可以使用整数类型来存储数据,尽量避免使用浮点类型。(比如说价格9.99,就可以转成整数的999来存储,避免浮点的浪费。DECIMAL可以将浮点放大转成BIGINT的大数)
- 避免使用ENUM类型: ENUM类型虽然可以节省存储空间,但在某些情况下会影响查询性能,因为MySQL在处理ENUM类型时需要额外的计算
- 使用CHAR而非VARCHAR来存储固定长度的字符串: 如果某个列存储的字符串长度基本固定,使用CHAR类型会比VARCHAR类型更高效,因为CHAR类型在存储时会占用固定的存储空间,而VARCHAR类型则根据实际长度占用变长空间
- 避免使用TEXT和BLOB类型: TEXT和BLOB类型通常用于存储大量的文本或二进制数据,但它们在查询和索引操作时会增加额外的开销。如果可能,尽量将这些数据拆分为多个字段或使用合适的字符类型来存储。更大点的最好还是存在hadoop或者文件夹里
- 使用合适的字符集和排序规则: 选择合适的字符集和排序规则可以确保数据存储和查询的正确性和性能。UTF-8字符集是通用的选择,但在特定场景下,可能需要其他字符集
- 避免使用NULL值: NULL值会增加存储空间和查询复杂性,尽量避免在不必要的情况下使用NULL,可以使用默认值或空字符串代替
- 分割大型表: 对于包含大量数据的表,可以考虑对其进行分割,将频繁访问的热数据与不经常访问的冷数据分开存储,以提高查询性能
- 定期检查和清理数据: 定期检查表中的无用或过期数据,并进行清理操作,以避免数据冗余和浪费。
- UNSIGNED无符号数:没有负数,但是正数翻一倍.
- TIMESTAMP表示的时间太短了,4字节的TIMESTAMP只能表示1970 - 2038年,比8字节的DATETIME表示的范围小得多,而且TIMESTAMP的值因时区不同而不同。
索引优化
mysql或者其他关系型数据库 一般是B-Tree索引(InnoDB是B+Tree,B+Tree是B-Tree的改进型,)
B意思是balance平衡,Tree就是二叉树
B+Tree是多路搜索树(二叉变成n叉)索引关键字都存放在叶子节点叶子节点用有序链表连接
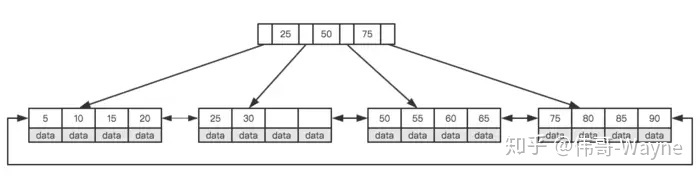
特点是:
- 多叉树结构: B+Tree是一种多叉树结构,每个节点可以包含多个键和对应的子节点。相比B-Tree,B+Tree通常具有更多的分支和更大的叉数。
- 所有数据记录在叶子节点: 与B-Tree不同,B+Tree将所有的数据记录都存储在叶子节点中,而非内部节点。这意味着叶子节点直接包含了真实的数据,而内部节点只包含键用于快速定位。
- 叶子节点通过链表连接: B+Tree的叶子节点通过链表连接在一起,形成一个有序链表。这样做的好处是可以更高效地执行范围查询和排序操作。
- 自平衡性: B+Tree是一种自平衡树,当节点插入或删除数据时,会自动调整树的结构,保持树的平衡性。这保证了B+Tree的查询效率稳定,不会因为数据的插入或删除而导致性能下降。
- 节点大小设置成页的正整数倍:从计算机组成原理讲起,可以减少磁盘IO损耗
排序原则是字段内容(第一字段内容相同就看下一字段)
从索引上优化效率可以从以下几个方面:
- 合适的索引选择: 确保为经常被查询的列创建合适的索引。优先考虑常用于条件查询、连接操作和排序的列。避免过多或不必要的索引,因为索引的增加会增加数据维护的成本。
- 组合索引: 对于经常同时使用多个列进行查询的情况,可以创建组合索引。组合索引可以减少索引数量,提高查询效率。确保组合索引的顺序符合查询的顺序,以最大程度地利用索引的效率。
- 覆盖索引: 尽量创建覆盖索引。覆盖索引是指索引本身包含了查询所需的所有数据,而不需要再回表查询实际数据。覆盖索引可以避免访问数据表,减少IO操作,从而提高查询性能。
- 避免索引过长: 索引的长度也会影响查询性能。尽量使用短索引,避免创建过长的索引。对于字符串类型的列,可以使用前缀索引来减少索引的长度。
- 避免在索引列上进行函数操作: 在索引列上使用函数操作(如函数、表达式等)会导致无法使用索引。尽量避免在索引列上进行函数操作,而是将操作放在查询的条件中。
- 定期优化和重建索引: 随着数据的增删改,索引可能会出现碎片,影响查询性能。定期进行索引优化和重建,可以提高索引的效率。
- 选择合适的存储引擎: 不同的存储引擎对索引的支持和性能有所不同。选择合适的存储引擎可以影响索引的效率。例如,InnoDB存储引擎对B+Tree索引的支持较好,而Memory存储引擎适合于哈希索引。
- 优化查询语句: 最后,优化查询语句本身也是提高查询效率的关键。确保查询语句合理、简洁,并使用正确的索引,以避免全表扫描和不必要的数据操作。
优化关联查询
通过冗余字段关联要比直接使用JOIN有更好的性能,或者通过创建关联相应列创建索引
优化limit分页
SELECT film_id,description FROM film ORDER BY title LIMIT 50,5;
–>搜索页面尽量变少
SELECT film.film_id,film.description
FROM film INNER JOIN (SELECT film_id FROM film ORDER BY title LIMIT 50,5
) AS tmp USING(film_id);
USING(film_id): 这是内连接的条件,使用INNER JOIN将电影表(film)与子查询的结果集(tmp)通过共同的列film_id进行连接。
SELECT id FROM t LIMIT 10000, 10;
改为:
SELECT id FROM t WHERE id > 10000 LIMIT 10;
第二句直接过滤出id>10000的然后才搜索前10条,效率更高
优化UNION
一般是创建临时表,然后查询之后再插入,再做查询
所以最好将LIMIT where等修饰词,放入各个子查询
如果需要服务器去重,则需要用UNION ALL
对于varchar
早期mysql4.1之前(有说版本5)
varchar的宽度是以字节为单位
varchar(255)就是85个汉字 (假如是UTF-8 一个字符三字节)
对于现在mysql4.1之后(有说版本5)
varchar的宽度是以字符为单位
varchar(255)就是255个汉字
新版本中varchar可以不带数字,意思就是可以自动扩展(知道固定字符串大小的话还是写char,比较省空间,text之类的类型没最大长度限制)
varchar最长为65535字节 64KB (和MyISAM数据引擎一行最大值一样,意味着机端情况 下一整行都是varchar字段)(InnoDB行最大限制是16KB)
end
参考
最全 MySQL 优化方法,从此优化不再难:https://zhuanlan.zhihu.com/p/59818056
《高性能mysql》
相关文章:
MySQL优化(面试)
文章目录 通信优化查询缓存语法解析及查询优化器查询优化器的策略 性能优化建议数据类型优化索引优化 优化关联查询优化limit分页对于varchar end mysql查询过程: 客户端向MySQL服务器发送一条查询请求服务器首先检查查询缓存,如果命中缓存,则立刻返回存…...

华为鸿蒙HarmonyOS4发布即巅峰,车机系统、多模态交互等实现突破
7 月 27 日最新消息,华为将于8月4日推出全新鸿蒙HarmonyOS 4.0,届时华为开发者大会也一并举行。 根据证券日报的报道,华为有关负责人在7月27日向媒体确认了以下消息。华为鸿蒙4.0将在汽车娱乐系统、多模态交互等领域实现重大突破,…...
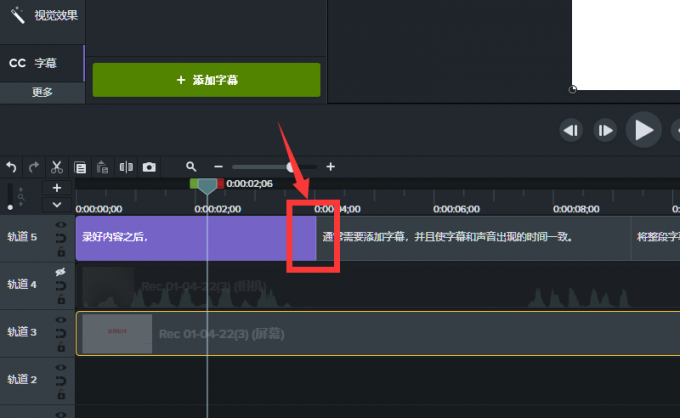
Camtasia2023电脑录屏视频自动生成字幕软件
制作视频通常需要添加字幕,添加字幕比较麻烦的是让字幕和声音同步,使用好的软件可以大大提高剪辑效率,让视频更快制作完成。本文将给大家介绍录制视频自动生成字幕的软件设置字幕语音同步教程。 一、录屏视频自动生成字幕的软件 Camtasia是…...

List有值二次转换给其他对象报null
List<PlatformUsersData> listData platformUsersMapper.selectPlatformUserDataById(data); users.setPlatformUsersData(listData);为什么listData 有值,users.getPlatformUsersData()仍然为空在这段代码中,我们假设listD…...
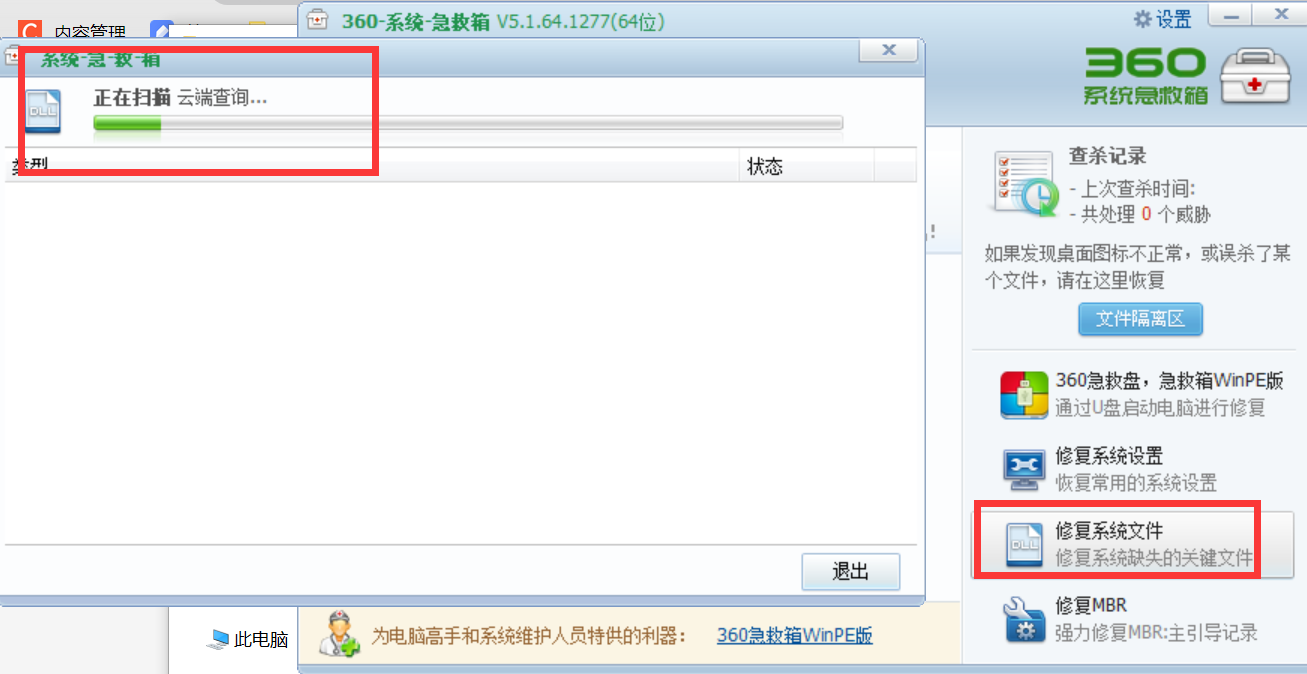
电脑新装系统优化,win10优化,win10美化
公司发了新的笔记本,分为几步做 1.系统优化,碍眼的关掉。防火墙关掉、页面美化 2.安装必备软件及驱动 3.数据迁移 4.开发环境配置 目录 目录复制 这里写目录标题 目录1.系统优化关掉底部菜单栏花里胡哨 2.安装必备软件及驱动新电脑安装360 1.系统优化 关掉底部菜单…...

实现PC端微信扫码native支付功能
目录 实现PC端微信扫码 简介 实现步骤 1. 获取商户号 2. 生成支付二维码 3. 监听支付结果 4. 发起支付请求 5. 处理支付回调 示例代码 结论 Native支付 Native支付的工作原理 Native支付的优势 Native支付的应用和市场地位 开通使用微信 native 支付流程 步骤一…...
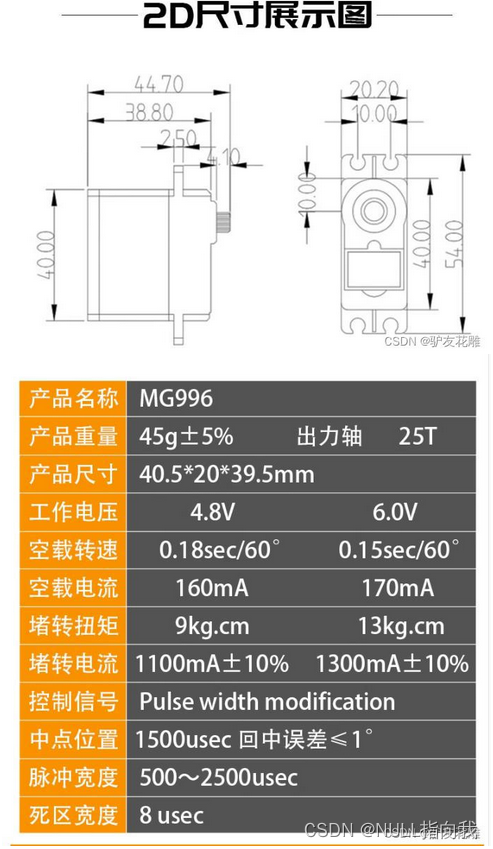
MSP432自主开发笔记4:DS3115舵机的0~180全角度驱动
芯片使用:MSP432P401R. 今日学习一款全角度15KG大扭力舵机的驱动,最近电赛学习任务紧,更新一篇比较水的文章: 文章提供原理解释,全部代码,整体工程: 目录 舵机驱动原理: 这是舵机DS3115MG:…...
)
【Matlab】基于卷积神经网络的时间序列预测(Excel可直接替换数据)
【Matlab】基于卷积神经网络的时间序列预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码6.完整代码7.运行结果1.模型原理 基于卷积神经网络(Convolutional Neural Network,CNN)的时间序列预测是一种用于处理时间序列数据的深度学习方法。…...

Ansible安装部署与应用
文章目录 一、ansible简介二、ansible 环境安装部署三、ansible 命令行模块3.1 command 模块3.2 shell 模块3.3 cron 模块3.4 user 模块3.5 group 模块3.6 copy 模块3.7 file 模块3.8 hostname 模块3.9 ping 模块3.10 yum 模块3.11 service/systemd 模块3.12 script 模块3.13 m…...
重生之我要学C++第四天
这篇文章的主要内容是类的默认成员函数。如果对大家有用的话,希望大家三连支持,博主会继续努力! 目录 一.类的默认成员函数 二.构造函数 三.析构函数 四.拷贝构造函数 五.运算符重载 一.类的默认成员函数 如果一个类中什么成员都没有&…...
创建一个简单的 Servlet 项目
目录 1.首先创建一个 Maven 项目 2.配置 maven 仓库地址 3.添加引用 4.配置路由文件 web.xml 5.编写简单的代码 6.配置 Tomcat 7.写入名称,点击确定即可 8.访问 1.首先创建一个 Maven 项目 2.配置 maven 仓库地址 3.添加引用 https://mvnrepository.com/ 中央仓库地址…...

godot引擎c++源码深度解析系列一
许久没有使用c开发过项目了,如果按照此时单位的入职要求,必须拥有项目经验的话,那我就得回到十多年前,大学的时代,哪个时候真好,电脑没有这么普及,手机没有这么智能,网络没有这么发达…...
【VB6|第21期】检查SqlServer数据库置疑损坏的小工具(含源码)
日期:2023年7月25日 作者:Commas 签名:(ง •_•)ง 积跬步以致千里,积小流以成江海…… 注释:如果您觉得有所帮助,帮忙点个赞,也可以关注我,我们一起成长;如果有不对的地方…...

React的hooks---useCallback useMemo
useCallback 和 useMemo 结合 React.Memo 方法的使用是常见的性能优化方式,可以避免由于父组件状态变更导致不必要的子组件进行重新渲染 useCallback useCallback 用于创建返回一个回调函数,该回调函数只会在某个依赖项发生改变时才会更新,…...
05. 容器资源管理
目录 1、前言 2、CGroup 2.1、是否开启CGroup 2.2、Linux CGroup限制资源能使用 2.2.1、创建一个demo 2.2.2、CGroup限制CPU使用 2.3、Linux CGroup限制内存使用 2.4、Linux CGroup限制IO 3、Docker对资源的管理 3.1、Docker对CPU的限制 3.1.1、构建一个镜像 3.1.2…...
通过ETL自动化同步飞书数据到本地数仓
一、飞书数据同步到数据库需求 使用飞书的企业都有将飞书的数据自动同步到本地数据库、数仓以及其他业务系统表的需求,主要是为了实现飞书的数据与业务系统进行流程拉通或数据分析时使用,以下是一些具体的同步场景示例: 组织架构同步&#…...

MySQL基础扎实——MySQL中各种数据类型之间的区别
在MySQL中,有各种不同的数据类型可供选择来存储不同类型的数据。下面是一些常见的数据类型以及它们之间的区别: 整数类型: TINYINT:1字节,范围为-128到127或0到255(无符号)。SMALLINT࿱…...
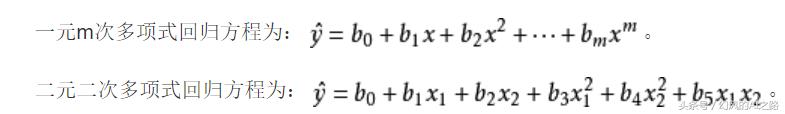
每天五分钟机器学习:多项式非线性回归模型
本文重点 在前面的课程中,我们学习了线性回归模型和非线性回归模型的区别和联系。多项式非线性回归模型是一种用于拟合非线性数据的回归模型。与线性回归模型不同,多项式非线性回归模型可以通过增加多项式的次数来适应更复杂的数据模式。在本文中,我们将介绍多项式非线性回…...

ETH网络学习
概要 ETH网络是一个P2P网络,整个网络又区分为“执行层”与“共识层”。“执行层”节点负责交易交换,“共识层”节点负责区块打包、区块验证、区块同步和链同步。 执行层 执行层分为“服务发现”与“DevP2P”,两者共同并行执行。 服务发现…...

01-将函数参数化进行传递
项目源码:https://github.com/java8/ 1 应对不断变化的需求 在我们进行开发中,经常需要面临需求的不断变更,我们可以将行为参数化以适应不断变更的需求。 行为参数化就是可以帮助我们处理频繁变更的需求的一种软件开发模式 我们可以将代码…...

Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南
Qwen3-Coder-30B-A3B-Instruct-FP8:终极代码模型对比分析指南 【免费下载链接】Qwen3-Coder-30B-A3B-Instruct-FP8 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 在当今AI代码生成领域,Qwen3-Coder-30B-…...

基于Arduino的智能蓝调节拍器:DIY音乐练习伴侣
1. 项目概述:一个能“演奏”蓝调的低成本节拍器玩乐器的人,对节拍器这东西又爱又恨。它像一位严厉的监工,用单调的“嘀嗒”声强迫你跟上节奏。但你想过没有,这个监工其实可以很有趣?几年前,我在练习蓝调吉他…...

WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南
WarcraftHelper:魔兽争霸III现代兼容性问题的终极解决方案指南 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 魔兽争霸III作为经典即时战…...

Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线
Style-Bert-VITS2未来发展方向:从语音克隆到实时语音转换的技术演进路线 【免费下载链接】Style-Bert-VITS2 Style-Bert-VITS2: Bert-VITS2 with more controllable voice styles. 项目地址: https://gitcode.com/gh_mirrors/st/Style-Bert-VITS2 Style-Bert…...

遭遇薪酬倒挂后的反向谈判与资产重估策略「蒸汽求职分享」
在 2026 年全球科技大厂与跨国泛金融巨头追求极致人效、频繁进行组织架构重组(Reorg)的买方市场中,一个让无数海外名校留学生在入职两年后心态瞬间崩塌的现象,正在高频发生——“薪酬倒挂(Salary Inversion)…...

别再把大模型当搜索框了:一文讲透 LLM 的基本原理、能力边界与局限性
写在前面很多人把大语言模型当成“会聊天的搜索引擎”,结果一上线就遇到幻觉、口径不稳、上下文丢失、成本失控。真正理解 LLM,要先抓住一句话:它是基于 Transformer 的概率生成模型,核心能力来自海量预训练、上下文学习与后训练对…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...

3步开启Windows 11安卓应用新体验:WSA完整使用指南
3步开启Windows 11安卓应用新体验:WSA完整使用指南 【免费下载链接】WSA Developer-related issues and feature requests for Windows Subsystem for Android 项目地址: https://gitcode.com/gh_mirrors/ws/WSA Windows Subsystem for Android(简…...

Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案
Awoo Installer:让Switch游戏安装变得简单高效的终极解决方案 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer 厌倦了繁琐的Switch游戏安…...

3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能
3步免费解锁Cursor Pro:告别设备限制,永久享受AI编程助手高级功能 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: …...