MySQL主从复制、读写分离
- 一、前言
- 二、主从复制原理
- 2.1 MySQL复制类型
- 2.2 MySQL主从复制工作过程
- 2.3 MySQL的四种同步方式
- 2.3.1 异步复制(MySQL默认)
- 2.3.2 同步复制
- 2.3.3 半同步复制(企业常用)
- 2.3.4 增强半同步复制
- 2.4 MySQL主从复制延迟原因和优化方法
- 2.5 Mysql应用场景
- 三、主从复制实验
- 3.1 实验环境
- 3.2 主从服务器时间同步
- 3.2.1 master服务器配置
- 3.2.2 两台SLAVE服务器配置
- 3.3 配置主从同步
- 3.3.1 master服务器修改配置文件(192.168.147.100)
- 3.3.2 slave服务器配置
- 补充:
- 3.4 测试数据同步
- 四、MySQL读写分离
- 4.1、什么是读写分离?
- 4.2、为什么要读写分离呢?
- 4.3、什么时候要读写分离?
- 4.4、主从复制与读写分离
- 4.5、MySQL 读写分离原理
- 4.6、企业 使用MySQL 读写分离场景
- 1)基于程序代码内部实现
- 2)基于中间代理层实现
- 五、读写分离实验
- 5.1 Amoeba服务器配置
- 5.2 测试读写分离 (192.168.147.104)
一、前言
在企业应用中,成熟的业务通常数据量都比较大
单台MySQL在安全性、高可用性和高并发方面都无法满足实际的需求
配置多台主从数据库服务器以实现读写分离
二、主从复制原理
2.1 MySQL复制类型
(1) STATEMENT:基于语句的复制。在服务器上执行sql语句,在从服务器上执行同样的语句,mysql默认采用基于语句的复制(5.7版本之前),执行效率高。高并发的情况可能会出现执行顺序的误差,事务的死锁。
(2)ROW:基于行的复制。把改变的内容复制过去,而不是把命令在从服务器上执行一 遍。精确,但效率低,保存的文件会更大。(5.7版本之后默认采用ROW模式)
(3)MIXED:混合类型的复制。默认采用基于语句的复制,一旦发现基于语句无法精确复制时,就会采用基于行的复制。更智能,所以大部分情况下使用MIXED。
2.2 MySQL主从复制工作过程
Master节点需要开启二进制日志,Slave节点需要开启中继日志。
(1)Master 节点将数据的改变记录成二进制日志(bin log) ,当Master上的数据发生改变时(增删改),则将其改变写入二进制日志中。
(2)Slave节点会在一定时间间隔内对Master的二进制日志进行探测其是否发生改变,如果发生改变,则开始一个I/O线程请求Master的二进制事件。(请求二进制数据)
(3)同时Master 节点为每个I/O线程启动一个dump线程,用于通知和向其发送二进制事件,I/O线程接收到bin-log内容后,将内容保存至slave节点本地的中继日志(Relay log)中,Slave节点将启动SQL线程从中继日志中读取二进制事件,在本地重放,即解析成sql 语句逐一执行,使得其数据和Master节点的保持一致。最后I/O线程和SQL线程将进入睡眠状态,等待下一次被唤醒。

记住两个日志和三个线程:
两个日志:二进制日志(bin log) 、中继日志(Relay log)
三个线程:I/O线程、dump线程、SQL线程
2.3 MySQL的四种同步方式
- 异步复制(Async Replication)
- 同步复制(sync Replication)
- 半同步复制(Async Replication)
- 增强半同步复制(lossless Semi-Sync Replication)、无损复制
2.3.1 异步复制(MySQL默认)
主库将更新写入Binlog日志文件后,不需要等待数据更新是否已经复制到从库中,就可以继续处理更多的请求。Master将事件写入binlog,但并不知道Slave是否或何时已经接收且已处理。在异步复制的机制的情况下,如果Master宕机,事务在Master上已提交,但很可能这些事务没有传到任何的Slave上。假设有Master->Salve故障转移的机制,此时Slave也可能会丢失事务。MySQL复制默认是异步复制,异步复制提供了最佳性能。
总结:master完成后直接返回给客户端
2.3.2 同步复制
主库将更新写入Binlog日志文件后,需要等待数据更新已经复制到从库中,并且已经在从库执行成功,然后才能返回继续处理其它的请求。同步复制提供了最佳安全性,保证数据安全,数据不会丢失,但对性能有一定的影响。
总结:当主库执行完成一个事务,然后所有的从库都复制了主库的事务并执行完成才会返回成信息给客户端
2.3.3 半同步复制(企业常用)
主库提交更新写入二进制日志文件后,等待数据更新写入了从服务器中继日志中,然后才能再继续处理其它请求。该功能确保至少有1个从库接收完主库传递过来的binlog内容已经写入到自己的relay log里面了,才会通知主库上面的等待线程,该操作完毕。
半同步复制,是最佳安全性与最佳性能之间的一个折中。
MySQL 5.5版本之后引入了半同步复制功能,主从服务器必须安装半同步复制插件,才能开启该复制功能。如果等待超时,超过rpl_semi_sync_master_timeout参数设置时间(默认值为10000,表示10秒),则关闭半同步复制,并自动转换为异步复制模式。当master dump线程发送完一个事务的所有事件之后,如果在rpl_semi_sync_master_timeout内,收到了从库的响应,则主从又重新恢复为增强半同步复制。
ACK (Acknowledge character)即是确认字符。
总结:半同步就是在异步复制的基础上,确保任何一个主库上的事务在提交之前至少有一个从库已经收到该事物并且存,个于异步和同步之间
2.3.4 增强半同步复制
增强半同步是在MySQL 5.7引入,其实半同步可以看成是一个过渡功能,因为默认的配置就是增强半同步,所以,大家一般说的半同步复制其实就是增强的半同步复制,也就是无损复制。
增强半同步和半同步不同的是,等待ACK时间不同rpl_semi_sync_master_wait_point = AFTER_SYNC(默认)
半同步的问题是因为等待ACK的点是Commit之后,此时Master已经完成数据变更,用户已经可以看到最新数据,当Binlog还未同步到Slave时,发生主从切换,那么此时从库是没有这个最新数据的,用户看到的是老数据。
增强半同步将等待ACK的点放在提交Commit之前,此时数据还未被提交,外界看不到数据变更,此时如果发送主从切换,新库依然还是老数据,不存在数据不一致的问题。
2.4 MySQL主从复制延迟原因和优化方法
主从复制延迟原因:
-
master服务器高并发,形成大量事务。
-
网络延迟。
-
主从硬件设备导致(cpu主频、内存IO、硬盘IO)。
-
是同步复制,而不是异步复制。
优化方法:
- 从库优化Mysql参数。比如增大innodb_buffer_pool_size,让更多操作在Mysql内存中完成,减少磁盘操作。
- 从库使用高性能主机。包括cpu强悍、内存加大。避免使用虚拟云主机,使用物理主机,这样提升了I/O方面性。
- 从库使用SSD磁盘。
- 网络优化,避免跨机房实现同步。
2.5 Mysql应用场景
mysql 数据库:主要的性能是读和写,一般场景来说读请求更多。
根据主从复制可以演变成读写分离,因为读写分离基于主从复制,使用读写分离从而解决高并发的问题。
mysql架构演变的方向:
- 单台mysql有单点故障
- 集群—》 主从复制
- 主从复制渡河写的压力不均衡
- 读写分离
- 读写分离的基础是主从复制
- mysql的高可用架构MHA(master HA高可用) MGR MMM
三、主从复制实验
3.1 实验环境
- 环境部署 cetos7.6
- 虚拟机服务环境
Master服务器:192.168.147.100 mysql5.7
slave1服务器:192.168.147.101 mysql5.7
slave2服务器:192.168.147.102 mysql5.7
3.2 主从服务器时间同步
3.2.1 master服务器配置
① 安装ntp、修改配置文件
yum -y install ntp
vim /etc/ntp.conf末尾添加
server 127.127.147.0 #设置本机为时间同步源
fudge 127.127.147.0 stratum 10
#设置本机的时间层级为10级,0级表示时间层级为0级,是向其他服务器提供时间同步源的意思,不要设置为0级


② 开启NTP服务
[root@master ~]# systemctl start ntpd
3.2.2 两台SLAVE服务器配置
① 安装ntp、ntpdate服务
yum install ntp ntpdate -y

② 开启ntp服务
systemctl start ntpd
③ 时间同步master服务器
ntpdate 192.168.147.100

④ 两台slave服务器配置相同
#master服务器同步阿里云时钟服务器
ntpdate ntp.aliyun.com
ntpdate 192.168.147.100
crontable -e
*/10 * * * * /usr/sbin/ntpdate 192.168.147.100

3.3 配置主从同步
3.3.1 master服务器修改配置文件(192.168.147.100)
[root@master ~]# vim /etc/my.cnf
#在mysqld模块下修改一下内容
#开启二进制日志文件(之后生成的日志名为master-bin)
log_bin=master-bin
#开启从服务器日志同步
log_slave-updates=true
#主服务器id为1(不可重复)
server_id = 1
--------》wq重启服务
[root@master ~]# systemct restart mysqld配置规则
mysql -uroot -pabc123GRANT REPLICATION SLAVE ON *.* TO 'myslave'@'192.168.147.%' IDENTIFIED BY 'abc123';#刷新权限表
flush privileges;规则解析:GRANT REPLICATION SLAVE ON *.* TO ‘myslave’@‘192.168.147.%’ IDENTIFIED BY ‘abc123’;
给从服务器提权,允许使用slave的身份复制master的所有数据库的所有表,并指定密码为123456查看master数据库状态
show master status;#以上可见产生了master-bin.000001日志文件,定位为604
#从服务器需要定位到此处进行复制



3.3.2 slave服务器配置
[root@slave1 ~]# vim /etc/my.cnf
#开启二进制日志文件
log-bin=master-bin
#设置server id为2,slave2的server id为3
server_id = 2
#从主服务器上同步日志文件记录到本地
relay-log=relay-log-bin
#定义relay-log的位置和名称(index索引)
relay-log-index=slave-relay-bin.index
--------》wq开启从服务器功能
[root@slave1 ~]# mysql -uroot -pabc123
...............
change master to master_host='192.168.147.100',master_user='myslave',master_password='abc123',master_log_file='master-bin.000001',master_log_pos=604;start slave;查看从服务器状态
show slave status\G;
##确保 IO 和 SQL 线程都是 Yes,代表同步正常。
Slave_IO_Running: Yes #负责与主机的IO通信
Slave_SQL_Running: Yes #负责自己的slave mysql进程Slave2 服务器也是同样配置,注意配置文件中 server-id 要和前面两台不同,我这里设置为 "server-id =3"。


补充:
一般 “Slave_IO_Running: No” 的可能原因:
- 网络不通
- my.cnf配置有问题(server-id重复)
- 密码、file文件名、pos偏移量不对
- 防火墙没有关闭
3.4 测试数据同步
在主服务器上创建一个数据库
create database work;

在两台从服务器上直接查看数据库列表
show databases;


四、MySQL读写分离
4.1、什么是读写分离?
读写分离,基本的原理是让主数据库处理事务性增、改、删操作(INSERT、UPDATE、DELETE),而从数据库处理SELECT查询操作。数据库复制被用来把事务性操作导致的变更同步到集群中的从数据库。
4.2、为什么要读写分离呢?
因为数据库的“写”(写10000条数据可能要3分钟)操作是比较耗时的。
但是数据库的“读”(读10000条数据可能只要5秒钟)。
所以读写分离,解决的是,数据库的写入,影响了查询的效率。
4.3、什么时候要读写分离?
数据库不一定要读写分离,如果程序使用数据库较多时,而更新少,查询多的情况下会考虑使用。利用数据库主从同步,再通过读写分离可以分担数据库压力,提高性能。
4.4、主从复制与读写分离
在实际的生产环境中,对数据库的读和写都在同一个数据库服务器中,是不能满足实际需求的。无论是在安全性、高可用性还是高并发等各个方面都是完全不能满足实际需求的。因此,通过主从复制的方式来同步数据,再通过读写分离来提升数据库的并发负载能力。有点类似于rsync,但是不同的是rsync是对磁盘文件做备份,而mysql主从复制是对数据库中的数据、语句做备份。
4.5、MySQL 读写分离原理
读写分离就是只在主服务器上写,只在从服务器上读。基本的原理是让主数据库处理事务性操作,而从数据库处理 select 查询。数据库复制被用来把主数据库上事务性操作导致的变更同步到集群中的从数据库。
4.6、企业 使用MySQL 读写分离场景
目前较为常见的 MySQL 读写分离分为以下两种:
1)基于程序代码内部实现
在代码中根据 select、insert 进行路由分类,这类方法也是目前生产环境应用最广泛的。
优点是性能较好,因为在程序代码中实现,不需要增加额外的设备为硬件开支;缺点是需要开发人员来实现,运维人员无从下手。
但是并不是所有的应用都适合在程序代码中实现读写分离,像一些大型复杂的Java应用,如果在程序代码中实现读写分离对代码改动就较大。
2)基于中间代理层实现
代理一般位于客户端和服务器之间,代理服务器接到客户端请求后通过判断后转发到后端数据库,有以下代表性程序。
(1)MySQL-Proxy。MySQL-Proxy 为 MySQL 开源项目,通过其自带的 lua 脚本进行SQL 判断。
(2)Atlas。是由奇虎360的Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目。它是在mysql-proxy 0.8.2版本的基础上,对其进行了优化,增加了一些新的功能特性。360内部使用Atlas运行的mysql业务,每天承载的读写请求数达几十亿条。支持事物以及存储过程。
(3)Amoeba。由陈思儒开发,作者曾就职于阿里巴巴。该程序由Java语言进行开发,阿里巴巴将其用于生产环境。但是它不支持事务和存储过程。
由于使用MySQL Proxy 需要写大量的Lua脚本,这些Lua并不是现成的,而是需要自己去写。这对于并不熟悉MySQL Proxy 内置变量和MySQL Protocol 的人来说是非常困难的。
Amoeba是一个非常容易使用、可移植性非常强的软件。因此它在生产环境中被广泛应用于数据库的代理层。
五、读写分离实验
实验环境
- 环境部署 cetos7.6
- 虚拟机服务环境
Master服务器:192.168.147.100
slave1服务器:192.168.147.101
Slave2服务器:192.168.147.102
Amoeba服务器:192.168.147.103 jdk1.6、Amoeba
客户端服务器:192.168.147.104 mysql 测试
5.1 Amoeba服务器配置
##安装 Java 环境##
因为 Amoeba 基于是 jdk1.5 开发的,所以官方推荐使用 jdk1.5 或 1.6 版本,高版本不建议使用。
cd /opt/
cp jdk-6u14-linux-x64.bin /usr/local/
cd /usr/local/
chmod +x jdk-6u14-linux-x64
./jdk-6u14-linux-x64.bin
//按yes,按entermv jdk1.6.0_14/ /usr/local/jdk1.6vim /etc/profile
export JAVA_HOME=/usr/local/jdk1.6
export CLASSPATH=$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
export PATH=$JAVA_HOME/lib:$JAVA_HOME/jre/bin/:$PATH:$HOME/bin
export AMOEBA_HOME=/usr/local/amoeba
export PATH=$PATH:$AMOEBA_HOME/binsource /etc/profile
java -version##安装 Amoeba软件##
mkdir /usr/local/amoeba
tar zxvf amoeba-mysql-binary-2.2.0.tar.gz -C /usr/local/amoeba/
chmod -R 755 /usr/local/amoeba/
/usr/local/amoeba/bin/amoeba
//如显示amoeba start|stop说明安装成功








##配置 Amoeba读写分离,两个 Slave 读负载均衡##
#先在Master、Slave1、Slave2 的mysql上开放权限给 Amoeba 访问
grant all on *.* to test@'192.168.147.%' identified by 'abc123';#再回到amoeba服务器配置amoeba服务:
cd /usr/local/amoeba/conf/cp amoeba.xml amoeba.xml.bak
vim amoeba.xml #修改amoeba配置文件
--30行--
<property name="user">amoeba</property>
--32行--
<property name="password">abc123</property>
--115行--
<property name="defaultPool">master</property>
--117-去掉注释-
<property name="writePool">master</property>
<property name="readPool">slaves</property>




cp dbServers.xml dbServers.xml.bak
vim dbServers.xml #修改数据库配置文件
--23行--注释掉 作用:默认进入test库 以防mysql中没有test库时,会报错
<!-- <property name="schema">test</property> -->
--26--修改
<property name="user">test</property>
--28-30--去掉注释
<property name="password">abc123</property>
--45--修改,设置主服务器的名Master
<dbServer name="master" parent="abstractServer">
--48--修改,设置主服务器的地址
<property name="ipAddress">192.168.147.100</property>
--52--修改,设置从服务器的名slave1
<dbServer name="slave1" parent="abstractServer">
--55--修改,设置从服务器1的地址
<property name="ipAddress">192.168.147.101</property>
--58--复制上面6行粘贴,设置从服务器2的名slave2和地址
<dbServer name="slave2" parent="abstractServer">
<property name="ipAddress">192.168.147.102</property>
--65行--修改
<dbServer name="slaves" virtual="true">
--71行--修改
<property name="poolNames">slave1,slave2</property>




/usr/local/amoeba/bin/amoeba start& #启动Amoeba软件,按ctrl+c 返回
netstat -anpt | grep java #查看8066端口是否开启,默认端口为TCP 8066

5.2 测试读写分离 (192.168.147.104)
#先安装数据库
yum install -y mariadb-server mariadb
systemctl start mariadb.service
在客户端服务器上测试
mysql -u amoeba -pabc123 -h 192.168.147.103 -P8066
//通过amoeba服务器代理访问mysql ,在通过客户端连接mysql后写入的数据只有主服务会记录,然后同步给从--从服务器


在主服务器上:
use db_test;
create table test (id int(10),name varchar(10),address varchar(20));在两台从服务器上:
stop slave; #关闭同步
use db_test;
//在slave1上:
insert into test values('1','zhangsan','this_is_slave1');//在slave2上:
insert into test values('2','lisi','this_is_slave2');//在主服务器上:
insert into test values('3','wangwu','this_is_master');//在客户端服务器上:
use db_test;
select * from test; //客户端会分别向slave1和slave2读取数据,显示的只有在两个从服务器上添加的数据,没有在主服务器上添加的数据insert into test values('4','qianqi','this_is_client'); //只有主服务器上有此数据//在两个从服务器上执行 start slave; 即可实现同步在主服务器上添加的数据
start slave;







相关文章:
MySQL主从复制、读写分离
一、前言二、主从复制原理2.1 MySQL复制类型2.2 MySQL主从复制工作过程2.3 MySQL的四种同步方式2.3.1 异步复制(MySQL默认)2.3.2 同步复制2.3.3 半同步复制(企业常用)2.3.4 增强半同步复制 2.4 MySQL主从复制延迟原因和优化方法2.…...
Redis配置与优化
目录 一、关系数据库与非关系型数据库 1、关系型数据库 2、非关系型数据库 3、关系型数据库和非关系型数据库区别 1、数据存储方式不同 2、扩展方式不同 3、对事务性的支持不同 二、Redis 1、简介 2、优点 3、缺点 4、使用场景 5、哪些数据适合放入缓存中 6、为什…...

leetCode刷题记录3-面试经典150题
文章目录 不要摆,没事干就刷题,只有好处,没有坏处,实在不行,看看竞赛题面试经典 150 题80. 删除有序数组中的重复项 II189. 轮转数组122. 买卖股票的最佳时机 II 不要摆,没事干就刷题,只有好处&…...
MySQL优化(面试)
文章目录 通信优化查询缓存语法解析及查询优化器查询优化器的策略 性能优化建议数据类型优化索引优化 优化关联查询优化limit分页对于varchar end mysql查询过程: 客户端向MySQL服务器发送一条查询请求服务器首先检查查询缓存,如果命中缓存,则立刻返回存…...

华为鸿蒙HarmonyOS4发布即巅峰,车机系统、多模态交互等实现突破
7 月 27 日最新消息,华为将于8月4日推出全新鸿蒙HarmonyOS 4.0,届时华为开发者大会也一并举行。 根据证券日报的报道,华为有关负责人在7月27日向媒体确认了以下消息。华为鸿蒙4.0将在汽车娱乐系统、多模态交互等领域实现重大突破,…...
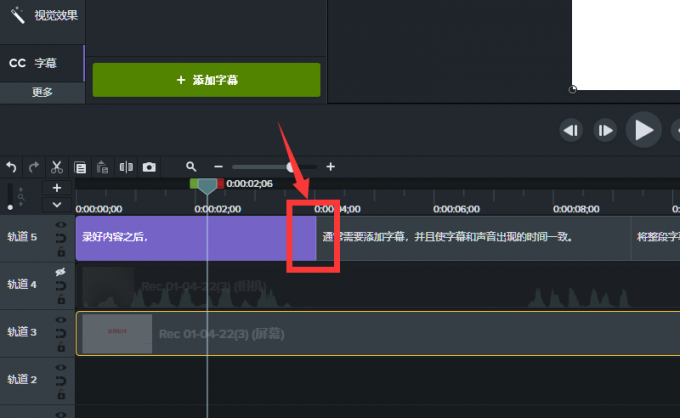
Camtasia2023电脑录屏视频自动生成字幕软件
制作视频通常需要添加字幕,添加字幕比较麻烦的是让字幕和声音同步,使用好的软件可以大大提高剪辑效率,让视频更快制作完成。本文将给大家介绍录制视频自动生成字幕的软件设置字幕语音同步教程。 一、录屏视频自动生成字幕的软件 Camtasia是…...

List有值二次转换给其他对象报null
List<PlatformUsersData> listData platformUsersMapper.selectPlatformUserDataById(data); users.setPlatformUsersData(listData);为什么listData 有值,users.getPlatformUsersData()仍然为空在这段代码中,我们假设listD…...
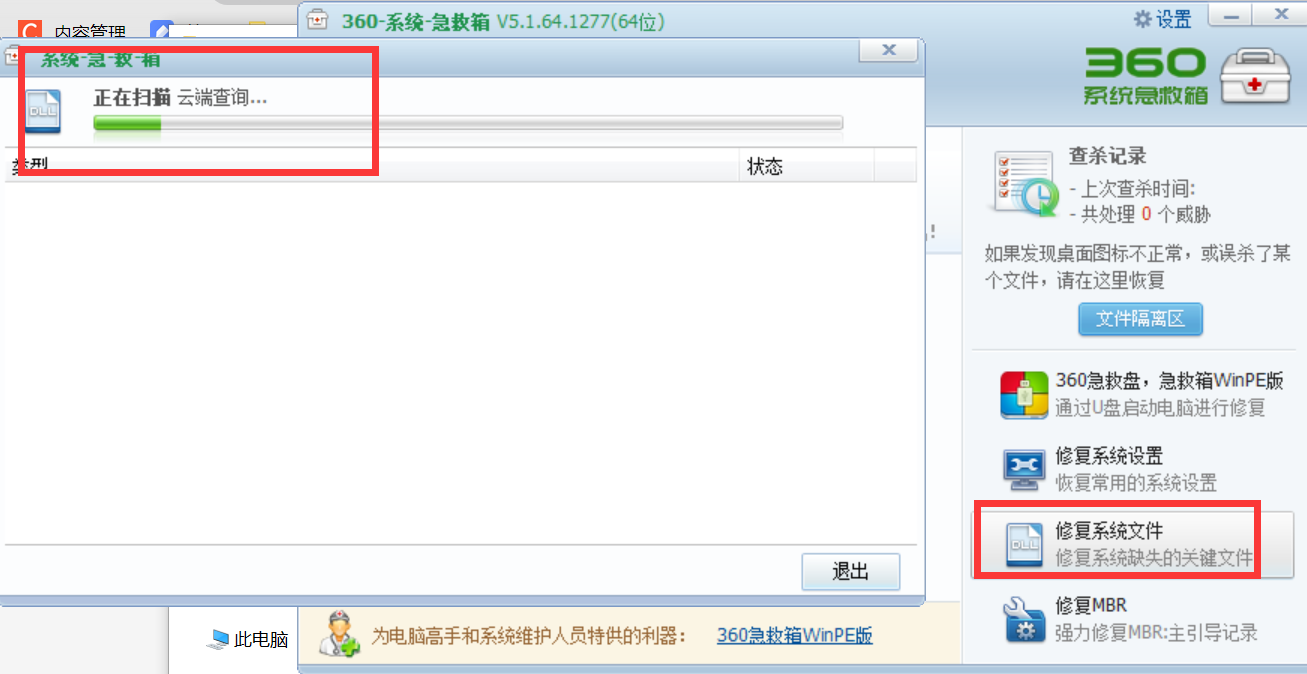
电脑新装系统优化,win10优化,win10美化
公司发了新的笔记本,分为几步做 1.系统优化,碍眼的关掉。防火墙关掉、页面美化 2.安装必备软件及驱动 3.数据迁移 4.开发环境配置 目录 目录复制 这里写目录标题 目录1.系统优化关掉底部菜单栏花里胡哨 2.安装必备软件及驱动新电脑安装360 1.系统优化 关掉底部菜单…...

实现PC端微信扫码native支付功能
目录 实现PC端微信扫码 简介 实现步骤 1. 获取商户号 2. 生成支付二维码 3. 监听支付结果 4. 发起支付请求 5. 处理支付回调 示例代码 结论 Native支付 Native支付的工作原理 Native支付的优势 Native支付的应用和市场地位 开通使用微信 native 支付流程 步骤一…...
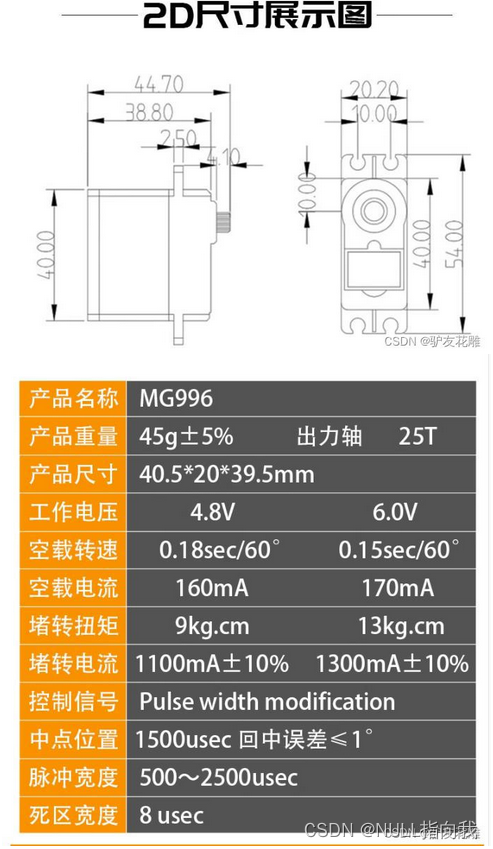
MSP432自主开发笔记4:DS3115舵机的0~180全角度驱动
芯片使用:MSP432P401R. 今日学习一款全角度15KG大扭力舵机的驱动,最近电赛学习任务紧,更新一篇比较水的文章: 文章提供原理解释,全部代码,整体工程: 目录 舵机驱动原理: 这是舵机DS3115MG:…...
)
【Matlab】基于卷积神经网络的时间序列预测(Excel可直接替换数据)
【Matlab】基于卷积神经网络的时间序列预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码6.完整代码7.运行结果1.模型原理 基于卷积神经网络(Convolutional Neural Network,CNN)的时间序列预测是一种用于处理时间序列数据的深度学习方法。…...

Ansible安装部署与应用
文章目录 一、ansible简介二、ansible 环境安装部署三、ansible 命令行模块3.1 command 模块3.2 shell 模块3.3 cron 模块3.4 user 模块3.5 group 模块3.6 copy 模块3.7 file 模块3.8 hostname 模块3.9 ping 模块3.10 yum 模块3.11 service/systemd 模块3.12 script 模块3.13 m…...
重生之我要学C++第四天
这篇文章的主要内容是类的默认成员函数。如果对大家有用的话,希望大家三连支持,博主会继续努力! 目录 一.类的默认成员函数 二.构造函数 三.析构函数 四.拷贝构造函数 五.运算符重载 一.类的默认成员函数 如果一个类中什么成员都没有&…...
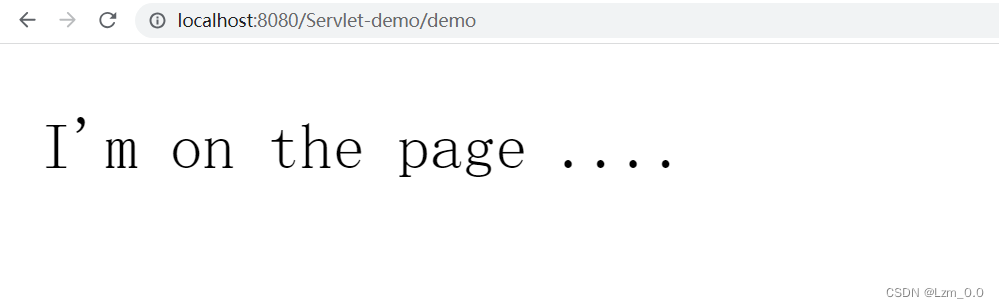
创建一个简单的 Servlet 项目
目录 1.首先创建一个 Maven 项目 2.配置 maven 仓库地址 3.添加引用 4.配置路由文件 web.xml 5.编写简单的代码 6.配置 Tomcat 7.写入名称,点击确定即可 8.访问 1.首先创建一个 Maven 项目 2.配置 maven 仓库地址 3.添加引用 https://mvnrepository.com/ 中央仓库地址…...

godot引擎c++源码深度解析系列一
许久没有使用c开发过项目了,如果按照此时单位的入职要求,必须拥有项目经验的话,那我就得回到十多年前,大学的时代,哪个时候真好,电脑没有这么普及,手机没有这么智能,网络没有这么发达…...
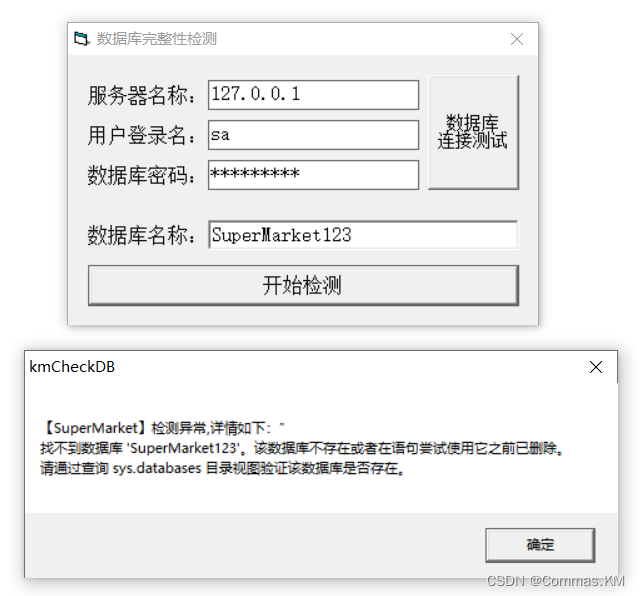
【VB6|第21期】检查SqlServer数据库置疑损坏的小工具(含源码)
日期:2023年7月25日 作者:Commas 签名:(ง •_•)ง 积跬步以致千里,积小流以成江海…… 注释:如果您觉得有所帮助,帮忙点个赞,也可以关注我,我们一起成长;如果有不对的地方…...

React的hooks---useCallback useMemo
useCallback 和 useMemo 结合 React.Memo 方法的使用是常见的性能优化方式,可以避免由于父组件状态变更导致不必要的子组件进行重新渲染 useCallback useCallback 用于创建返回一个回调函数,该回调函数只会在某个依赖项发生改变时才会更新,…...
05. 容器资源管理
目录 1、前言 2、CGroup 2.1、是否开启CGroup 2.2、Linux CGroup限制资源能使用 2.2.1、创建一个demo 2.2.2、CGroup限制CPU使用 2.3、Linux CGroup限制内存使用 2.4、Linux CGroup限制IO 3、Docker对资源的管理 3.1、Docker对CPU的限制 3.1.1、构建一个镜像 3.1.2…...
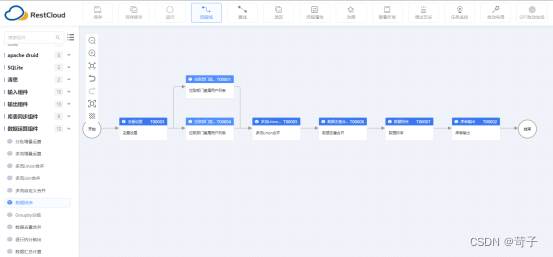
通过ETL自动化同步飞书数据到本地数仓
一、飞书数据同步到数据库需求 使用飞书的企业都有将飞书的数据自动同步到本地数据库、数仓以及其他业务系统表的需求,主要是为了实现飞书的数据与业务系统进行流程拉通或数据分析时使用,以下是一些具体的同步场景示例: 组织架构同步&#…...

MySQL基础扎实——MySQL中各种数据类型之间的区别
在MySQL中,有各种不同的数据类型可供选择来存储不同类型的数据。下面是一些常见的数据类型以及它们之间的区别: 整数类型: TINYINT:1字节,范围为-128到127或0到255(无符号)。SMALLINT࿱…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

Office RibbonX Editor:简单三步打造你的专属Office界面
Office RibbonX Editor:简单三步打造你的专属Office界面 【免费下载链接】office-ribbonx-editor An overhauled fork of the original Custom UI Editor for Microsoft Office, built with WPF 项目地址: https://gitcode.com/gh_mirrors/of/office-ribbonx-edit…...

如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型
如何快速上手DeepPurpose?5分钟完成你的第一个药物-靶点相互作用预测模型 【免费下载链接】DeepPurpose A Deep Learning Toolkit for DTI, Drug Property, PPI, DDI, Protein Function Prediction (Bioinformatics) 项目地址: https://gitcode.com/gh_mirrors/de…...

16个分片+2副本:pg_shard的master_create_worker_shards最佳实践
16个分片2副本:pg_shard的master_create_worker_shards最佳实践 【免费下载链接】pg_shard ATTENTION: pg_shard is superseded by Citus, its more powerful replacement 项目地址: https://gitcode.com/gh_mirrors/pg/pg_shard pg_shard作为PostgreSQL的分…...

别再死记公式了!用Python手写一个卷积层,彻底搞懂CNN里的‘卷’是怎么算的
用Python手写卷积层:从零理解CNN的"卷"运算 当你第一次看到卷积神经网络(CNN)的数学公式时,那些复杂的符号和下标是否让你望而却步?作为计算机视觉领域的基石,CNN的核心在于理解卷积运算的本质。本文将带你用NumPy从零实…...
)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)
Unity3D深度纹理实战:手把手教你实现可交互的激光雷达扫描特效(附完整C#/Shader代码)在科幻题材的游戏开发中,激光雷达扫描特效是营造科技感的经典元素。从《赛博朋克2077》的战术目镜到《看门狗》的环境扫描,这种动态…...

Android Root检测绕过:从逆向分析到Frida分层Hook实战
1. 这不是“绕过root检测”,而是理解检测逻辑后的精准干预在安卓逆向工程的实际工作中,“过root检测”这个说法本身就容易引发误解——它听起来像某种黑箱魔法,仿佛只要套用某个脚本、加载某个插件,就能让App对设备状态“视而不见…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

NHSE终极教程:5分钟掌握动物森友会存档编辑技巧
NHSE终极教程:5分钟掌握动物森友会存档编辑技巧 【免费下载链接】NHSE Animal Crossing: New Horizons save editor 项目地址: https://gitcode.com/gh_mirrors/nh/NHSE 还在为《集合啦!动物森友会》的收集烦恼吗?想快速打造梦想岛屿却…...

泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅
泰拉瑞亚地图编辑器:从像素画布到创意世界的蜕变之旅 【免费下载链接】Terraria-Map-Editor TEdit - Terraria Map Editor - TEdit is a stand alone, open source map editor for Terraria. It lets you edit maps just like (almost) paint! It also lets you cha…...