【打卡】Datawhale暑期实训ML赛事
文章目录
- 赛题描述
- 任务要求
- 数据集介绍
- 评估指标
- 赛题分析
- 基于LightGBM模型
- Baseline详解
- 改进baseline
- 早停法
- 添加特征
赛题描述
赛事地址:科大讯飞锂离子电池生产参数调控及生产温度预测挑战赛
任务要求
初赛任务:初赛提供了电炉17个温区的实际生产数据,分别是电炉上部17组加热棒设定温度T1-1 ~ T1-17,电炉下部17组加热棒设定温度T2-1~T2-17,底部17组进气口的设定进气流量V1-V17,选手需要根据提供的数据样本构建模型,预测电炉上下部空间17个测温点的测量温度值。
数据集介绍
初赛任务:初赛提供了电炉17个温区的实际生产数据,分别是电炉上部17组加热棒设定温度T1-1 ~ T1-17,电炉下部17组加热棒设定温度T2-1~T2-17,底部17组进气口的设定进气流量V1-V17,选手需要根据提供的数据样本构建模型,预测电炉上下部空间17个测温点的测量温度值。
评估指标
初赛考核办法采用测试集各行数据的加热棒上部温度设定值、加热棒下部温度设定值、进气流量3类数据作为输入,选手分别预测上部空间测量温度、下部空间测量温度。将选手预测的上部空间测量温度、下部空间测量温度与测试集数据的测量值进行比较。采用MAE平均绝对误差作为评价指标。
赛题分析
本次比赛为数据挖掘类型的比赛,聚焦于工业场景。本赛题实质上为回归任务,其中会涉及到时序预测相关的知识。
通过电炉空间温度推测产品内部温度,设计烧结过程的温度场和浓度场的最优控制律:
任务输入:电炉对应17个温区的实际生产数据,分别是电炉上部17组加热棒设定温度T1-1 ~ T1-17,电炉下部17组加热棒设定温度T2-1~T2-17,底部17组进气口的设定进气流量V1-V17;
任务输出:电炉对应17个温区上部空间和下部空间17个测温点的测量温度值。
值得注意的是预测目标为34个,所以需要我们进行34次模型训练和预测。
同时数据规模比较小,可以快速处理数据和搭建模型,对于机器要求8g内存即可。
本次为结构化赛题,包含电炉烧结每个时间段的流量、上下部设定温度,以及预测目标上下部测量温度值。
基于LightGBM模型
在处理这个问题时,我们主要考虑的是回归预测。一种常规的解决思路是运用机器学习技术,例如 LightGBM 或 XGBoost,或者借助深度学习方法进行实践。当我们选择自行搭建模型的路径时,我们将面临更为复杂的挑战,包括构建模型结构以及对数值数据进行标准化处理。
然而,一个简易的解决方案可能就在我们眼前,那就是直接使用现成的机器学习模型。这种方法具有明显的优势,其模型使用简单,数据预处理的需求也大大减少。
总的来说,我们需要经过以下步骤来解决本问题:
数据预处理
切分训练集与验证集
训练模型
生成最后的预测结果。
在实施这些步骤的过程中,我们需要根据模型的性质和数据的特点灵活调整,确保每一步的实施都能最大化模型的预测准确性,从而有效解决这个回归预测问题。
Baseline详解
导入需要的库:
import pandas as pd # 用于处理数据的工具
import lightgbm as lgb # 机器学习模型 LightGBM
from sklearn.metrics import mean_absolute_error # 评分 MAE 的计算函数
from sklearn.model_selection import train_test_split # 拆分训练集与验证集工具
from tqdm import tqdm # 显示循环的进度条工具
读取数据:
# 数据准备
train_dataset = pd.read_csv("./data/train.csv") # 原始训练数据。
test_dataset = pd.read_csv("./data/test.csv") # 原始测试数据(用于提交)。submit = pd.DataFrame() # 定义提交的最终数据。
submit["序号"] = test_dataset["序号"] # 对齐测试数据的序号。MAE_scores = dict() # 定义评分项。
查看数据:
train_dataset.head()
test_dataset.head()
设置lgb参数:
# 参数设置
pred_labels = list(train_dataset.columns[-34:]) # 需要预测的标签。
train_set, valid_set = train_test_split(train_dataset, test_size=0.2) # 拆分数据集。# 设定 LightGBM 训练参,查阅参数意义:https://lightgbm.readthedocs.io/en/latest/Parameters.html
lgb_params = {'boosting_type': 'gbdt', #使用的提升方法,使用梯度提升决策树gbdt'objective': 'regression', #使用的最小化指标'metric': 'mae', #使用的评价指标'min_child_weight': 5, #子节点中样本权重最小和,用于控制过拟合'num_leaves': 2 ** 5, #每棵树上的叶子节点数,影响模型的复杂度'lambda_l2': 10, #L2正则项的权重,用于控制模型的复杂度'feature_fraction': 0.8, #随机选择特征的比例,用于防止过拟合'bagging_fraction': 0.8, #随机采样的比例,用于防止过拟合'bagging_freq': 4, #随机采样的频率,用于防止过拟合'learning_rate': 0.05, #学习率'seed': 2023, #随机数种子,保持结果的可重复性'nthread' : 16, #线程数'verbose' : -1, #可视化开关,-1为不打印,0为打}no_info = lgb.callback.log_evaluation(period=-1) # 禁用训练日志输出。
进行特征工程,主要是时间文本转换为时间格式,生成年、日、小时、分钟等时间特征:
# 时间特征函数
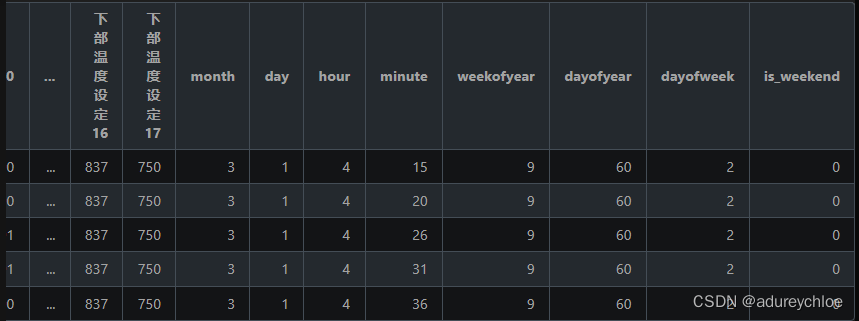
def time_feature(data: pd.DataFrame, pred_labels: list=None) -> pd.DataFrame:"""提取数据中的时间特征。输入: data: Pandas.DataFrame需要提取时间特征的数据。pred_labels: list, 默认值: None需要预测的标签的列表。如果是测试集,不需要填入。输出: data: Pandas.DataFrame提取时间特征后的数据。"""data = data.copy() # 复制数据,避免后续影响原始数据。data = data.drop(columns=["序号"]) # 去掉”序号“特征。data["时间"] = pd.to_datetime(data["时间"]) # 将”时间“特征的文本内容转换为 Pandas 可处理的格式。data["month"] = data["时间"].dt.month # 添加新特征“month”,代表”当前月份“。data["day"] = data["时间"].dt.day # 添加新特征“day”,代表”当前日期“。data["hour"] = data["时间"].dt.hour # 添加新特征“hour”,代表”当前小时“。data["minute"] = data["时间"].dt.minute # 添加新特征“minute”,代表”当前分钟“。data["weekofyear"] = data["时间"].dt.isocalendar().week.astype(int) # 添加新特征“weekofyear”,代表”当年第几周“,并转换成 int,否则 LightGBM 无法处理。data["dayofyear"] = data["时间"].dt.dayofyear # 添加新特征“dayofyear”,代表”当年第几日“。data["dayofweek"] = data["时间"].dt.dayofweek # 添加新特征“dayofweek”,代表”当周第几日“。data["is_weekend"] = data["时间"].dt.dayofweek // 6 # 添加新特征“is_weekend”,代表”是否是周末“,1 代表是周末,0 代表不是周末。data = data.drop(columns=["时间"]) # LightGBM 无法处理这个特征,它已体现在其他特征中,故丢弃。if pred_labels: # 如果提供了 pred_labels 参数,则执行该代码块。data = data.drop(columns=[*pred_labels]) # 去掉所有待预测的标签。return data # 返回最后处理的数据。test_features = time_feature(test_dataset) # 处理测试集的时间特征,无需 pred_labels。
test_features.head(5)
训练模型并进行预测:
# 从所有待预测特征中依次取出标签进行训练与预测。
for pred_label in tqdm(pred_labels):# print("当前的pred_label是:", pred_label)train_features = time_feature(train_set, pred_labels=pred_labels) # 处理训练集的时间特征。# train_features = enhancement(train_features_raw)train_labels = train_set[pred_label] # 训练集的标签数据。# print("当前的train_labels是:", train_labels)train_data = lgb.Dataset(train_features, label=train_labels) # 将训练集转换为 LightGBM 可处理的类型。valid_features = time_feature(valid_set, pred_labels=pred_labels) # 处理验证集的时间特征。# valid_features = enhancement(valid_features_raw)valid_labels = valid_set[pred_label] # 验证集的标签数据。# print("当前的valid_labels是:", valid_labels)valid_data = lgb.Dataset(valid_features, label=valid_labels) # 将验证集转换为 LightGBM 可处理的类型。# 训练模型,参数依次为:导入模型设定参数、导入训练集、设定模型迭代次数(5000)、导入验证集、禁止输出日志model = lgb.train(lgb_params, train_data, 5000, valid_sets=valid_data, callbacks=[no_info])valid_pred = model.predict(valid_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行验证集预测。test_pred = model.predict(test_features, num_iteration=model.best_iteration) # 选择效果最好的模型进行测试集预测。MAE_score = mean_absolute_error(valid_pred, valid_labels) # 计算验证集预测数据与真实数据的 MAE。MAE_scores[pred_label] = MAE_score # 将对应标签的 MAE 值 存入评分项中。submit[pred_label] = test_pred # 将测试集预测数据存入最终提交数据中。submit.to_csv('submit_result.csv', index=False) # 保存最后的预测结果到 submit_result.csv
保存文件:
# 保存文件并查看结果
submit.to_csv('submit_result.csv', index=False) # 保存最后的预测结果到 submit_result.csv。
print(MAE_scores) # 查看各项的 MAE 值。
最后结果是7.94826。
改进baseline
早停法
由于模型有过拟合的风险,所以可以通过早停来让模型在一段时间不能得到提升后提前结束训练。lgb中可以通过添加参数来实现。
lgb_params = {'boosting_type': 'gbdt', #使用的提升方法,使用梯度提升决策树gbdt'objective': 'regression', #使用的最小化指标'metric': 'mae', #使用的评价指标'early_stopping_round':20, #早停,如果20轮没有提升就停止训练'min_child_weight': 5, #子节点中样本权重最小和,用于控制过拟合'num_leaves': 2 ** 5, #每棵树上的叶子节点数,影响模型的复杂度'lambda_l2': 10, #L2正则项的权重,用于控制模型的复杂度'feature_fraction': 0.8, #随机选择特征的比例,用于防止过拟合'bagging_fraction': 0.8, #随机采样的比例,用于防止过拟合'bagging_freq': 4, #随机采样的频率,用于防止过拟合'learning_rate': 0.05, #学习率'seed': 2023, #随机数种子,保持结果的可重复性'nthread' : 16, #线程数'verbose' : -1, #可视化开关,-1为不打印,0为打}
添加特征
尝试提取更多特征,这里尝试添加交叉特征、历史平移特征、差分特征、和窗口统计特征;每种特征都是有理可据的,具体说明如下:
(1)交叉特征:主要提取流量、上部温度设定、下部温度设定之间的关系;
(2)历史平移特征:通过历史平移获取上个阶段的信息;
(3)差分特征:可以帮助获取相邻阶段的增长差异,描述数据的涨减变化情况。在此基础上还可以构建相邻数据比值变化、二阶差分等;
(4)窗口统计特征:窗口统计可以构建不同的窗口大小,然后基于窗口范围进统计均值、最大值、最小值、中位数、方差的信息,可以反映最近阶段数据的变化情况。
在时间特征函数中添加:
# 交叉特征for i in range(1,18):data[f'流量{i}/上部温度设定{i}'] = data[f'流量{i}'] / data[f'上部温度设定{i}']data[f'流量{i}/下部温度设定{i}'] = data[f'流量{i}'] / data[f'下部温度设定{i}']data[f'上部温度设定{i}/下部温度设定{i}'] = data[f'上部温度设定{i}'] / data[f'下部温度设定{i}']# 历史平移for i in range(1,18):data[f'last1_流量{i}'] = data[f'流量{i}'].shift(1)data[f'last1_上部温度设定{i}'] = data[f'上部温度设定{i}'].shift(1)data[f'last1_下部温度设定{i}'] = data[f'下部温度设定{i}'].shift(1)# 差分特征for i in range(1,18):data[f'last1_diff_流量{i}'] = data[f'流量{i}'].diff(1)data[f'last1_diff_上部温度设定{i}'] = data[f'上部温度设定{i}'].diff(1)data[f'last1_diff_下部温度设定{i}'] = data[f'下部温度设定{i}'].diff(1)# 窗口统计for i in range(1,18):data[f'win3_mean_流量{i}'] = (data[f'流量{i}'].shift(1) + data[f'流量{i}'].shift(2) + data[f'流量{i}'].shift(3)) / 3data[f'win3_mean_上部温度设定{i}'] = (data[f'上部温度设定{i}'].shift(1) + data[f'上部温度设定{i}'].shift(2) + data[f'上部温度设定{i}'].shift(3)) / 3data[f'win3_mean_下部温度设定{i}'] = (data[f'下部温度设定{i}'].shift(1) + data[f'下部温度设定{i}'].shift(2) + data[f'下部温度设定{i}'].shift(3)) / 3# 对平移后的空值进行填充 data = data.fillna(method='bfill')
这里要注意在平移之后第一个值会变成nan(因为没有前一个值),包括窗口统计的前3个值,因此需要用后填充的方式将其填充。
经过这两个操作后分数变为7.51948。
由于时间关系,暂时只做这两个改进,后续会进行更多探索。
相关文章:
【打卡】Datawhale暑期实训ML赛事
文章目录 赛题描述任务要求数据集介绍评估指标 赛题分析基于LightGBM模型Baseline详解改进baseline早停法添加特征 赛题描述 赛事地址:科大讯飞锂离子电池生产参数调控及生产温度预测挑战赛 任务要求 初赛任务:初赛提供了电炉17个温区的实际生产数据&…...

【python脚本】python实现:目标检测裁剪图片样本,根据类标签文件进行裁剪保存
python实现:目标检测裁剪图片样本,根据类标签文件进行裁剪保存 我在进行目标检测时候,比如红绿灯检测,目标区域很小,样本杂乱。 想要筛选错误样本的话,很困难。可以把目标区域裁剪出来。人大脑处理对于这…...

Mac 终端美化显示
Linux 也可安装 Zsh 后使用此套配置。 1. 安装 Oh My Zsh sh -c "$(curl -fsSL https://raw.githubusercontent.com/ohmyzsh/ohmyzsh/master/tools/install.sh)"2. 更换主题,修改文件:~/.zshrc,原内容: ZSH_THEME&quo…...
信息安全:密码学基本理论.
信息安全:密码学基本理论. 密码学是研究编制密码和破译密码的技术科学。研究密码变化的客观规律,应用于编制密码以保守通信秘密的,称为编码学;应用于破译密码以获取通信情报的,称为破译学,总称密码学. 目录…...

【linux升级ssh】 利用rpmbuild工具对ssh打包为rpm包进场安装升级
制作rpm包 rpmbuild命令用于创建软件的二进制包和源代码包。 官方文档:rpm.org - RPM Reference Manual rpmbuild 中文手册:rpmbuild 中文手册 [金步国] 使用rpmbuild将tar包打成rpm包 RPM打包使用的是rpmbuild命令,这个命令来自rpm-buil…...
UCloud上线可商用LLaMA2镜像,助力AGI应用发展
随着人工智能技术的快速发展,大模型应用在自然语言处理、图像识别、智能交互等领域展现出了巨大的潜力,为企业带来了更多创新和商机。众多企业纷纷将大模型应用于产品开发和业务优化中,希望通过提升智能化水平和用户体验来赢得竞争优势。近日…...
Linux推出Debian 12.1,并进行多方面系统修复
据了解,Debian是最古老的 GNU / Linux 发行版之一,也是许多其他基于 Linux 的操作系统的基础,包括 Ubuntu、Kali、MX 和树莓派 OS 等。 此外,该操作系统以稳定性为重,不追求花哨的新功能,因此新版本的发布…...

Spring 事务的使用、隔离级别、@Transactional的使用
Spring事务是Spring框架提供的一种机制,用于管理应用程序中的数据库事务。 事务是一组数据库操作的执行单元,要么全部成功提交,要么全部失败回滚,保证数据的一致性和完整性。 Spring事务提供了声明式事务和编程式事务两种方式&am…...
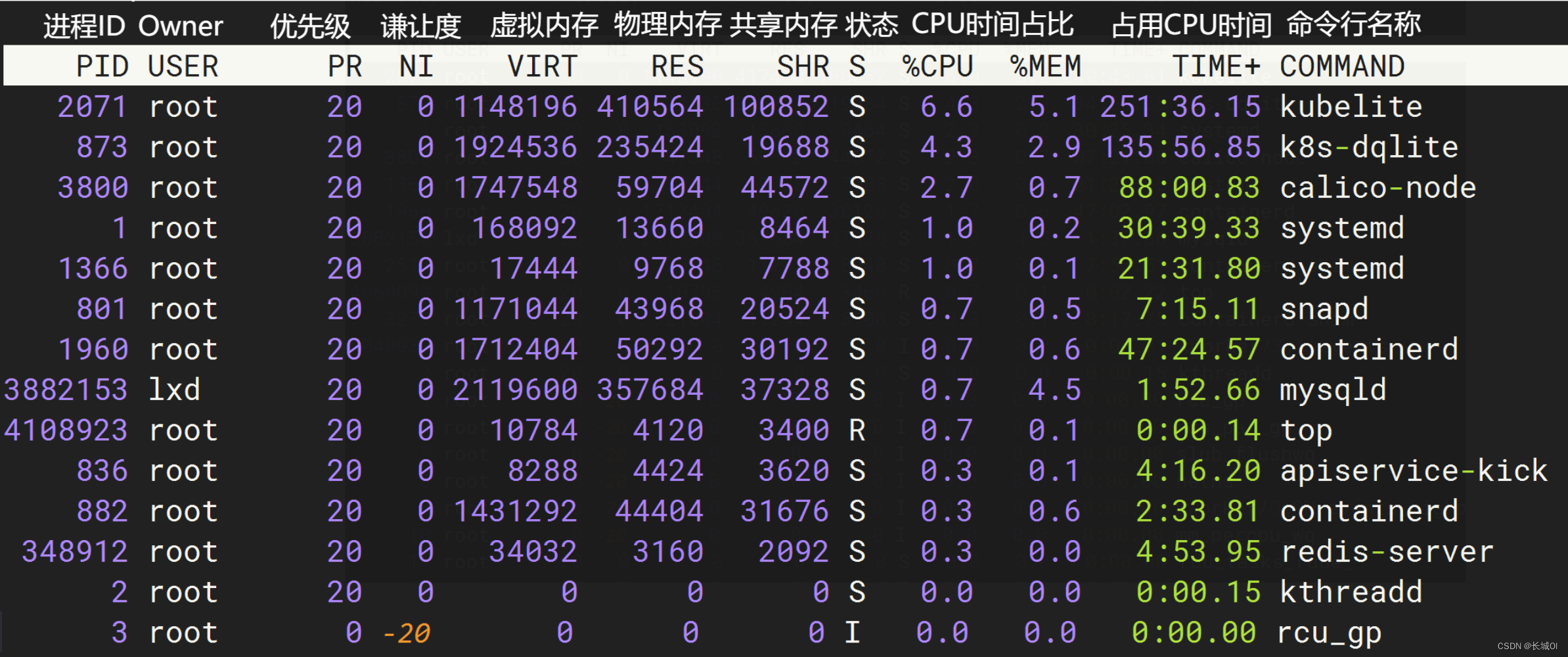
Top命令
Top top - 12:46:01 up 2 days, 11:10, 3 users, load average: 0.56, 0.59, 0.45系统基本信息:显示了系统运行时间、登录用户数和平均负载(load average)情况。平均负载是系统在特定时间范围内的平均活跃进程数,可以用来衡量系…...

(三)RabbitMQ七种模式介绍与代码演示
Lison <dreamlison163.com>, v1.0.0, 2023.06.22 七种模式介绍与代码演示 文章目录 七种模式介绍与代码演示四大交换机四种交换机介绍 工作模式简单模式(Hello World)工作队列模式(Work queues)订阅模式(Publis…...
ElasticSearch Java API 操作
1.idea创建Maven项目 2.添加依赖 修改 pom.xml 文件 <dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.8.0</version></dependency><!-- elasticsearch 的客户端 --…...
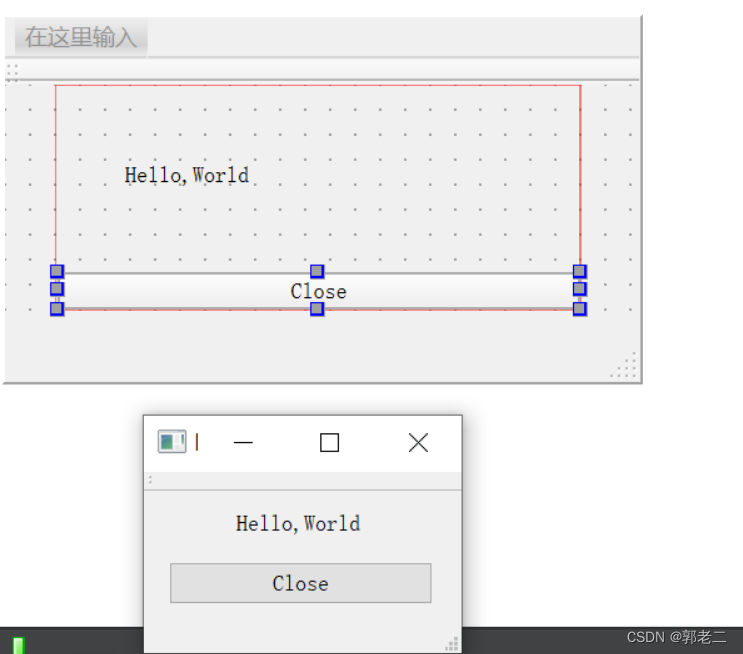
【Qt】QML-01:使用QtCreator10创建QML工程,并讲解第一个程序:Hello World
1、创建QML工程 1)新建工程 打开QtCreator10,依次点击“Create Project” --> “Application(Qt)” --> “Qt Quick Application(compat)” 注意:本人打算使用Qt5.15.2创建工程,而非Qt6,因此选择兼容低于Qt6版本的“Qt Quick Applicat…...
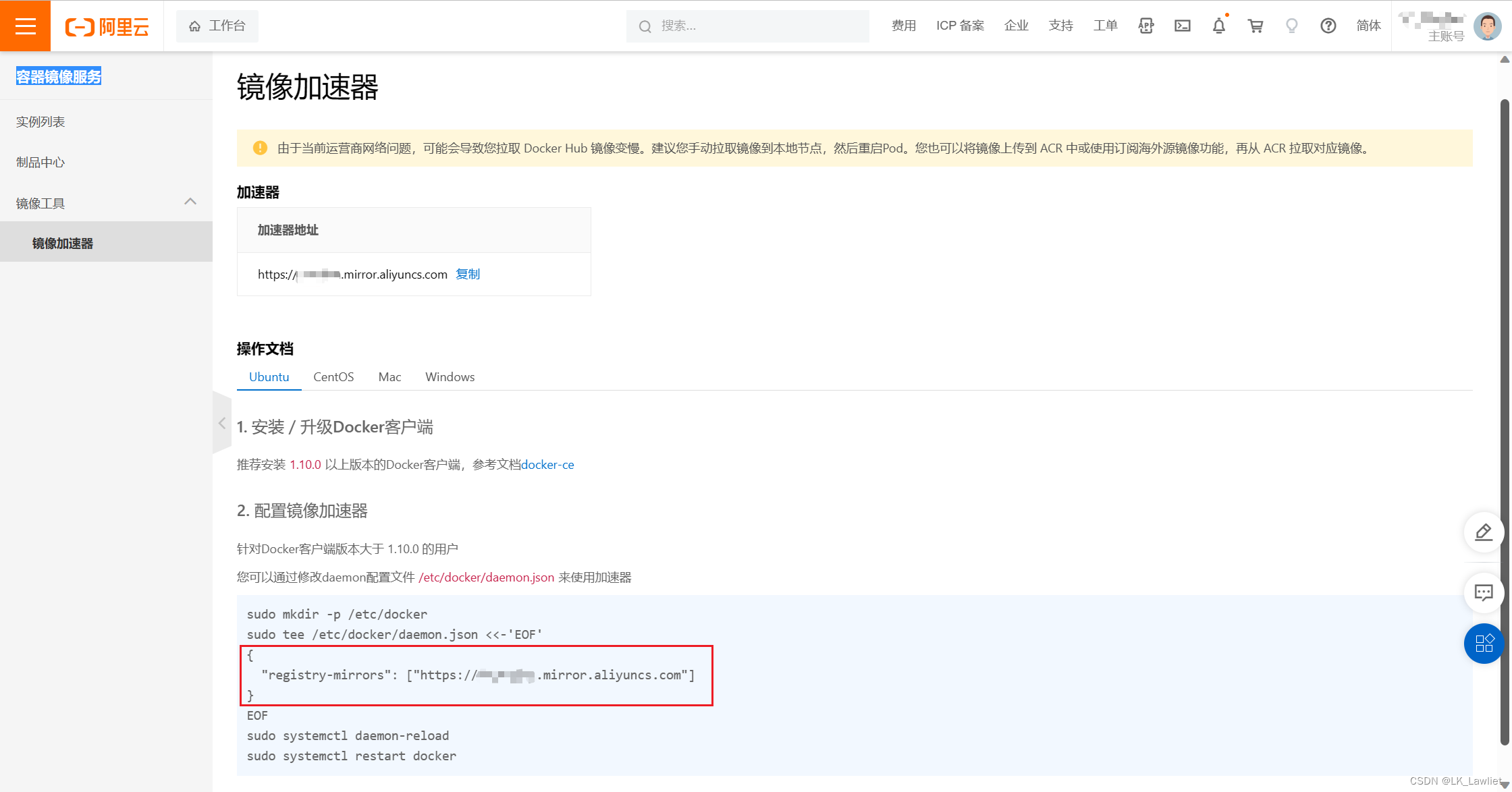
Docker的安装与部署
Docker 基本概念介绍 通俗理解:镜像是类,容器是对象实例 仓库 应用商店、镜像 下载的应用安装程序、容器 应用程序 镜像(Image) 这里面保存了应用和需要的依赖环境 为什么需要多个镜像?当开发、构建和运行容器化应用程序时,我们…...

【数据结构】实验四:循环链表
实验四 循环链表 一、实验目的与要求 1)熟悉循环链表的类型定义和基本操作; 2)灵活应用循环链表解决具体应用问题。 二、实验内容 题目一:有n个小孩围成一圈,给他们从1开始依次编号,从编号为1的小孩开…...

【FPGA/D7】
2023年7月26日 串口传图到RAM并TFT显示 视频25note要求:接收两个字节数据合并为一个16位数据并写入ram: FIFO模型与应用场景 视频26 串口传图到RAM并TFT显示 视频25 note 存储器的使用,在开始读写或者结束读写的位置非常容易出现数据错误或…...
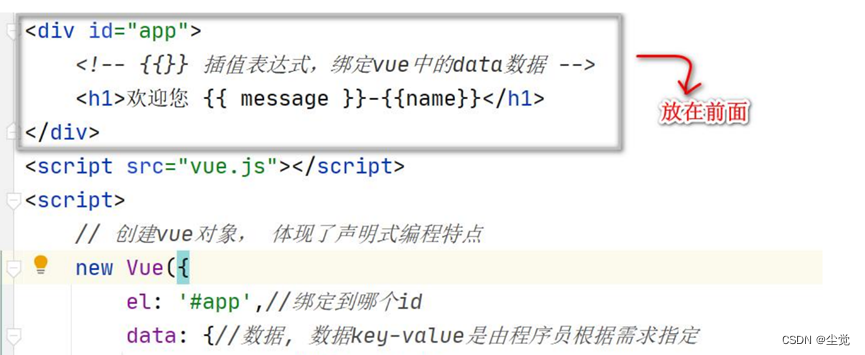
Vue的下载以及MVVM分析
😀前言本片文章是vue系列第一篇整理了vue的基础和发展史 🏠个人主页:尘觉主页 🧑个人简介:大家好,我是尘觉,希望我的文章可以帮助到大家,您的满意是我的动力😉Ƕ…...
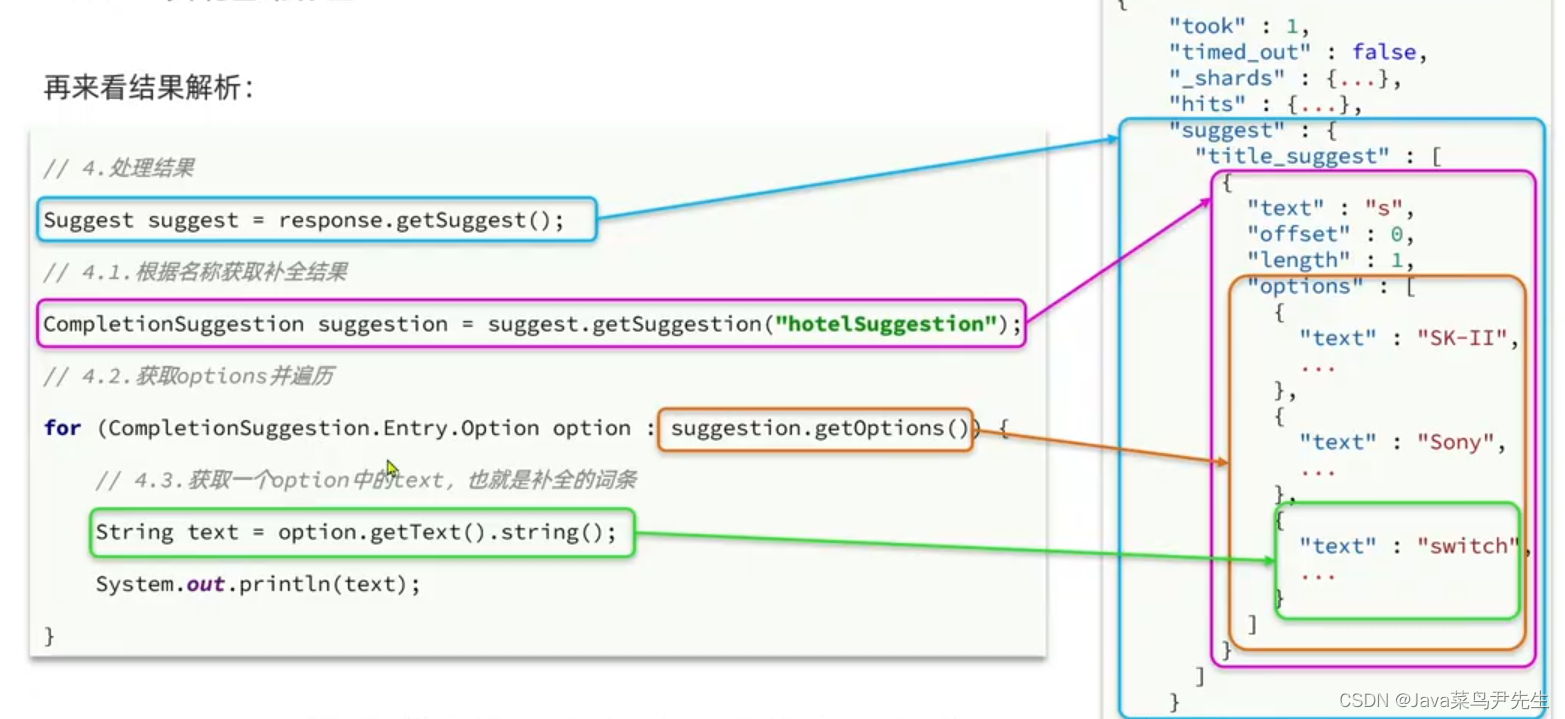
ElasticSearch学习--自动补全
目录 自定义分词器 介绍 配置自定义分词器 拼音分词器的问题编辑 总结 DSL自动补全查询 RestAPI实现自动补全 自定义分词器 介绍 自定义分词器只在当前库中有效 配置自定义分词器 拼音分词器的问题 总结 DSL自动补全查询 RestAPI实现自动补全...
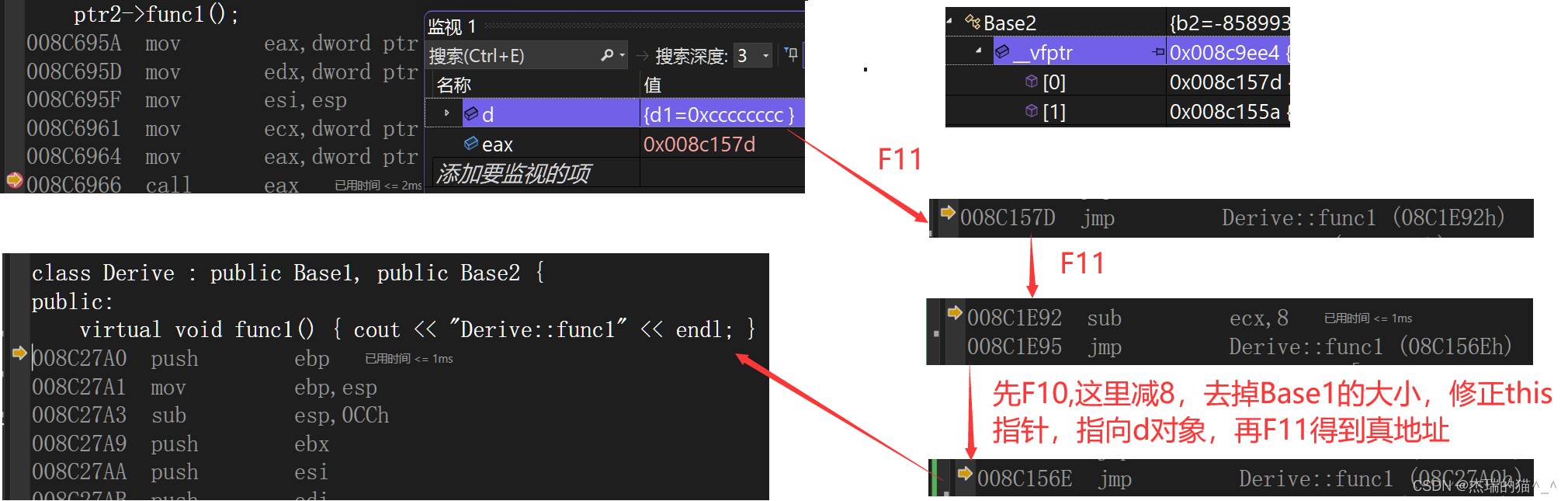
【C++】多态,虚函数表相关问题解决
文章目录 多态概念及其触发条件重写和协变(考点1)(考点2) 虚函数表及其位置(考点3) 多继承中的虚函数表 多态概念及其触发条件 多态的概念:通俗来说,就是多种形态。具体点就是去完成…...

探索大型语言模型的开源人工智能基础设施:北京开源AI Meetup回顾
原文参见Explore open source AI Infra for Large Language Models: Highlights from the Open Source AI Meetup Beijing | Cloud Native Computing Foundation 背景介绍: 最近,在 ChatGPT 的成功推动下,大型语言模型及其应用程序的流行度激…...

Langchain 的 Conversation buffer window memory
Langchain 的 Conversation buffer window memory ConversationBufferWindowMemory 保存一段时间内对话交互的列表。它仅使用最后 K 个交互。这对于保持最近交互的滑动窗口非常有用,因此缓冲区不会变得太大。 我们首先来探讨一下这种存储器的基本功能。 示例代码&…...
)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)
Goframe项目实战:从数据库表到API接口的全链路开发指南(含避坑点)在当今微服务架构盛行的时代,Go语言因其高性能和并发优势成为后端开发的热门选择。而Goframe作为一款企业级的Go应用开发框架,提供了从数据库操作到API…...

AI写的论文双率如何压到20%以下?这几款工具实测有效
毕业季、投稿季用AI写论文已经成为不少人的高效选择,但查重率飘红、AIGC疑似率超标两大问题,让很多人犯了难。2026年学术检测标准持续收紧,知网、维普及主流AIGC检测系统同步上线双检规则,两项指标均控制在20%以下才符合基本提交要…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

关联规则挖掘在Calabi-Yau流形Hodge数分析中的应用与复现
1. 项目概述:当数据挖掘遇见高维几何在理论物理和代数几何的交叉领域,Calabi-Yau流形一直扮演着核心角色。这些具有特殊拓扑结构的空间,不仅是弦理论中额外维度紧化的关键候选者,其本身丰富的数学性质也吸引着无数研究者。然而&am…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...

实战解锁:在Blender中掌握专业级MMD动画制作全流程
实战解锁:在Blender中掌握专业级MMD动画制作全流程 【免费下载链接】blender_mmd_tools MMD Tools is a blender addon for importing/exporting Models and Motions of MikuMikuDance. 项目地址: https://gitcode.com/gh_mirrors/bl/blender_mmd_tools MMD …...
从Stable Diffusion到DiT:为什么说Transformer是扩散模型的下一站?
从Stable Diffusion到DiT:Transformer如何重塑扩散模型的未来 在图像生成领域,扩散模型正经历着从U-Net架构向Transformer架构的范式转移。这一转变不仅仅是技术组件的简单替换,而是代表着生成式AI在可扩展性、训练效率和模型容量方面的重大突…...

对比直接调用厂商API使用Taotoken聚合调用的延迟体感差异
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接调用厂商API使用Taotoken聚合调用的延迟体感差异 在将应用从直接调用单一厂商的模型API迁移到Taotoken平台后,…...

MT-R1-Zero:基于强化学习的机器翻译范式革新与实战指南
1. 项目概述:当强化学习遇上机器翻译 在机器翻译这个老牌的自然语言处理任务里,我们似乎已经习惯了“数据驱动”的剧本:收集海量的双语平行句对,用它们来监督训练模型,让模型学会从源语言到目标语言的映射。这套方法&a…...

摆脱论文困扰!2026年最值得拥有的专业AI智能降重工具
2026年论文降AI率工具已从“基础改写”升级为多维度智能优化系统,核心评价维度涵盖AI生成内容识别精度、语义逻辑一致性、学术格式合规性、查重适配能力及多语言处理水平。本次测评覆盖6款主流工具,测试场景包括中文与英文论文、全流程与专项功能、免费与…...