Python实战项目——旅游数据分析(四)
由于有之前的项目,所以今天我们直接开始,不做需求分析,还不会需求分析的可以看我之前的文章。Python实战项目——用户消费行为数据分析(三)
导入库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
plt.rcParams['font.sans-serif']=['SimHei']# 用来正常显示中文标签
from datetime import datetime
1.初识数据
df = pd.read_csv('kelu.csv')
df.info()
df.head()

- 基本信息:门票价格101,数据来自16年~19年,8K+多数据量
df.describe()

- 根据平均分92,和1/2分位得知,大多数用户评分在100,效果非常不错。
- 16年~19年门票价格都是110
2.分析数据
a1.每天销量分析
df['time'] = pd.to_datetime(df['time'],format='%Y/%m/%d')
df.groupby('time')['rating'].count().plot(figsize=(12,4))

- 整体来看每日销量呈现上升趋势,但是在18年5月份前后(2,3,4)出现一次较大的波动,销量急剧下滑,猜测:台风,疫情,运营推广不利
- 16年9月~17年1月,销量非常低,每天平均2-3张门票,猜测:101观景台门票刚刚上线发售,观景台刚刚对游客进行开放
a2.每月销量分析
df['month'] = df['time'].values.astype('datetime64[M]') #保留月份精度的日期
df.head()
df.groupby('month')['rating'].count().plot(figsize=(12,4)) #按照月份进度进行计数
plt.xlabel('月份')
plt.ylabel('销售数量')
plt.title('16~19年每月销量分析')

月份整体销量依然呈现上升趋势,但是在18年2,3,4月份月销量下滑明显。跟每天销量下降有关。猜测:台风,疫情,运营推广不利
a3.每个用户的购买量和消费金额分析
merge用法,相当于sql当中join:
df1 = pd.DataFrame({'name':['zhangsan','lisi'],'group':['A','B']
})
df2 = pd.DataFrame({'name':['wangwu','lisi'],'score':[88,90],'group':['C','D']
})
pd.merge(left=df1,right=df2,on='name',how='inner',suffixes=['_1','_2'])left:左表 right:右表 on:关联字段 how:inner(默认值,交集)|outer(并集)|left(只保留左侧)|right(只保留右侧)
#suffixes:如果两个表中有多个相同列,用suffixes给的值进行区分(默认值xy)

#按照游客分组,统计每个游客的购买次数
grouped_count_author = df.groupby('author')['frequency'].count().reset_index()
#按照游客分组,统计每个游客的消费金额
grouped_sum_amount = df.groupby('author')['amount'].sum().reset_index()
user_purchase_retention = pd.merge(left=grouped_count_author,right=grouped_sum_amount,on='author',how='inner')
user_purchase_retention.tail(60)
user_purchase_retention.plot.scatter(x='frequency',y='amount',figsize=(12,4))
plt.title('用户的购买次数和消费金额关系图')
plt.xlabel('购物次数')
plt.ylabel('消费金额')

结论:斜率就是门票价格110,用户的消费金额和消费次数呈现线性关系
b1.用户购买门票数量分析
df.groupby('author')['frequency'].count().plot.hist(bins=50) #影响柱子的宽度,宽度= (最大值-最小值)/bins
plt.xlim(1,17)
plt.xlabel('购买数量')
plt.ylabel('人数')
plt.title('用户购买门票数量直方图')

- 绝大多数用户购买过1张门票,用户在7000人次左右
- 少数人购买过2~4张门票,猜测:可能是台北周边用户
b2.用户购买门票2次及以上情况分析
df_frequency_2 = df.groupby('author').count().reset_index()
df_frequency_2.head()
df_frequency_2[df_frequency_2['frequency']>=2].groupby('author')['frequency'].sum().plot.hist(bins=50)
plt.xlabel('购买数量')
plt.ylabel('人数')
plt.title('购买门票在2次及以上的用户数量')

消费两次的用户在整体上占比较大,大于2次的用户占小部分,用户购买次数最多为8次
b3.查看购买2次及以上的具体人数
df_frequency_2[df_frequency_2['frequency']>=2].groupby('frequency')['author'].count()

出去购买一次的顾客,可以看出购买2次有402人,购买3次的99人,以此类推得知大多数据倾向于购买2~5
b4.购买次数在1~5次之间的用户占比分析
1.按照用户进行分组 2.取出购买次数 3.过滤出1~5次用户 4.绘制饼图
df_frequency_gte_1 = df.groupby('author')['frequency'].count().reset_index()
#过滤出<=5次的用户
values = list(df_frequency_gte_1[df_frequency_gte_1['frequency']<=5].groupby('frequency')['frequency'].count())
print(values)
plt.pie(values,labels=['购买1次','购买2次','购买3次','购买4次','购买5次'],autopct='%1.1f%%')
plt.title('购买次数在1~5次之间的人数占比')
plt.legend()

可以看出购买一次的占比83%,其次逐渐递减。并且递减比较明显,购买3.4.5的占比相近,人数都很少。
b5.购买次数在2~5次之间的用户占比分析
#过滤出>=2次并且<=5次的用户
df_frequency_gte_2 = df_frequency_2[df_frequency_2['frequency']>=2].reset_index()
values = list(df_frequency_gte_2[df_frequency_gte_2['frequency']<=5].groupby('frequency')['frequency'].count())
print(values)
plt.pie(values,labels=['购买2次','购买3次','购买4次','购买5次'],autopct='%1.1f%%')
plt.title('购买次数在2~5次之间的人数占比')
plt.legend()

在2~5次之间,购买2.3次用户占比最大,综合占据了80%
c1.复购率分析
复购率:在某一时间窗口内(多指一个月)内消费次数在两次及以上的用户在总消费用户的占比
df.head()
pivot_count = df.pivot_table(index='author',columns='month',values='frequency',aggfunc='count').fillna(0)
pivot_count.head()
#三种情况:
#消费次数>1,为复购用户,用1表示
#消费次数=1,为非复购用户,用0表示
#消费次数=0, 未消费用户,用na表示
#applymap:df,处理每一个元素
#apply:df,处理每一行或者每一列数据
#map:Serise,处理每一个元素
pivot_count = pivot_count.applymap(lambda x: 1 if x>1 else np.NAN if x==0 else 0)
# pivot_count[pivot_count['2016-09-01']==1]
(pivot_count.sum()/pivot_count.count()).plot()
plt.xlabel('时间(月)')
plt.ylabel('百分比(%)')
plt.title('16~19年每月用户复购率')
16年9月份复购率最高达到了7.5%,然后开始下降,趋于平稳在1.2%
c2.复购用户人数
pivot_count.sum().plot()
plt.xlabel('时间/月')
plt.ylabel('复购人数')
plt.title('16~19年每月的复购人数折线图'

- 整体来看,复购人数长线上升趋势
- 但是在18年2.3.4.10和19年2月份,复购人数下降较为明显,出现异常信号,需要和业务部门具体分析情况
c3.回购率分析
回购率:在某一个时间窗口内消费过的用户,在下一个时间窗口仍旧消费的占比。
举个例子:当前月消费用户人数1000人,其中200人在下一个月仍旧进行了消费,回购率200/1000=20%
pivot_purchase = df.pivot_table(index='author',columns='month',values='frequency',aggfunc='count').fillna(0)
pivot_purchase.head()
len(pivot_purchase.columns)

def purchase_return(data): #data:代表的是每一名游客的所有月份消费记录status = [] #存储每一个月回购状态for i in range(30):#遍历每一个月(最后一个月除外)####本月消费if data[i] == 1:if data[i+1] ==1:#下个月有消费,是回购用户,1status.append(1)else:#na|未消费status.append(0) #非回购用户,0else: ####本月未消费status.append(np.NaN)status.append(np.NaN)return pd.Series(status,pivot_purchase.columns)
pivot_purchase_return = pivot_purchase.apply(purchase_return,axis=1) #用户回购状态
(pivot_purchase_return.sum()/pivot_purchase_return.count()).plot()
plt.title('16年~19年每月的回购率')
plt.xlabel('月份')
plt.ylabel('回购率%')

- 回购率最高在18年6月份,达到4%
- 整体来看,回购率呈现微弱上升趋势
- 出现了几次较大下滑,分别是17年6月份,18年1月份,18年8月份,19年1月份
c4.回购人数分析
pivot_purchase_return.sum().plot()
plt.title('16年~19年每月的回购人数')
plt.xlabel('月份')
plt.ylabel('回购人数')
print(pivot_purchase_return.sum())

- 整体呈现上升趋势,回购人数最多时在18年11月份,人数未17人
- 其中有几次回购人数下降较为明显,主要在分别是17年6月份,18年1月份,18年8月份,19年1月份
c5.每个月分层用户占比情况
活跃用户|不活跃用户|回流用户|新用户
def active_status(data): #data:每一行数据(共31列)status = [] #存储用户31个月的状态(new|active|unactive|return|unreg)for i in range(31):#判断本月没有消费==0if data[i] ==0:if len(status)==0: #前几个月没有任何记录(也就是97年1月==0)status.append('unreg') else:#之前的月份有记录(判断上一个月状态)if status[i-1] =='unreg':#一直没有消费过status.append('unreg')else:#上个月的状态可能是:new|active|unative|reuturnstatus.append('unactive')else:#本月有消费==1if len(status)==0:status.append('new') #第一次消费else:#之前的月份有记录(判断上一个月状态)if status[i-1]=='unactive':status.append('return') #前几个月不活跃,现在又回来消费了,回流用户elif status[i-1]=='unreg':status.append('new') #第一次消费else:#new|activestatus.append('active') #活跃用户return pd.Series(status,pivot_purchase.columns) #值:status,列名:18个月份
pivot_purchase_status =pivot_purchase.apply(active_status,axis=1)
pivot_status_count =pivot_purchase_status.replace('unreg',np.NaN).apply(pd.value_counts)
pivot_status_count.T.plot.area()

- 可以看出,红色(不活跃用户)占据网站用户的主体
- 橙色(新用户)从17年的1月~19年1月,呈现上升趋势;但是在18年4月份左右,新用户的量突然急剧下降,异常信号;
- 以后,新用户又开始逐渐上涨,回复稳定状态
- 绿色(回流用户),一直维持稳定稳定状态,但是在18年2~4月份,出现异常下降情况,异常信号;
c6.每月不同用户的占比
return_rate = pivot_status_count.apply(lambda x:x/x.sum())
return_rate.T.plot()

- 在17年1月份过后,网站用户主体由不活跃用户组成,新用户占比开始逐渐下降,并且趋于稳定,稳定在10%左右
- 活跃用户和会用户,一直很稳定,并且占比较小
- 16年9月前后,新用户和不活跃用户,发生较大的变化,猜测:活动或者节假日造成…
c7.每月活跃用户的占比
return_rate.T['active'].plot(figsize=(12,6))
plt.xlabel('时间(月)')
plt.ylabel('百分比')
plt.title('每月活跃用户的占比分析')

- 在17年1月份活跃用户占比较高,在0.5%,但是在1-2月份,急剧下降,猜测:春节的影响,或者温度
- 结合历年1~2月份销量来看,都会出现一定比例的下降,再次验证我们的猜测:春节的影响
- 在18年2月和5月出现异常,门票销量下降,猜测:雨水或者台风影响
c8.每月回流用户占比
return_rate.T['return'].plot(figsize=(12,6))
plt.xlabel('时间(月)')
plt.ylabel('百分比')
plt.title('每月回流用户的占比分析')

- 整体来看,回流用户比例上升趋势,但是波动较大
- 在17年1月和6月,18年4月,19年2月,回流用户比例都出现了较大幅度下降,表现为异常信号
- 不论是回流用户还是活跃用户,在以上几个月份中都表现出下降趋势。
np.mean(return_rate.T['return']) #回流用户平均值在0.73%左右
- 在17年9月份以后,仅有两个异常点在平均值以下
- 在17年9月份以前,所有数据都显示出回流用户比例低于平均值,猜测:景点开放不久,很多游客尚未发现本景点;本景点在该平台上线不久
d1.用户的生命周期
#计算方式:每一个用户最后一个购买商品的时间——用户第一次购买商品的时间,转换成天数,即为生命周期
time_min = df.groupby('author')['time'].min()
time_max = df.groupby('author')['time'].max()
life_time = (time_max-time_min).reset_index()
life_time.describe()

- 通过原样本8757条和count=7722得知,存在一个用户多次消费的情况
- 平均生命周期天数23天,通过25% 50% 75%分位数得知,绝大多用户生命周期为0天
- 最大生命周期为864天
d2.用户生命周期直方图
#讲日期类型转成数值类型
life_time['life_time'] = life_time['time']/np.timedelta64(1,'D')
life_time['life_time'].plot.hist(bins = 100,figsize=(12,6))
plt.xlabel('天数')
plt.ylabel('人数')
plt.title('所有用户的生命周期直方图')
print(life_time[life_time['life_time']==0])

- 生命周期为0的用户(仅仅在一天内有过消费,之后再没消费过),存在7130个用户
- 由于总用户数为7722,其余592人属于优质的忠诚客户
d3.生命周期大于0天的用户,直方图
life_time[life_time['life_time']>0]['life_time'].plot.hist(bins = 100,figsize=(12,6))
plt.xlabel('天数')
plt.ylabel('人数')
plt.title('生命周期在0天以上的用户分布直方图')
life_time[life_time['life_time']>0]['life_time'].mean()

- 去掉生命周期为0的用户,可知
- 用户平均生命周期为300天,生命周期在100天的用户量达到了最大值17人
- 生命周期在100~350天来看,用户量呈现缓慢下降的趋势
- 350~800天左右来看,用户量下降速度明显,存在一定用户流失,而忠诚用户越来越少
d4.各时间段的用户留存率
#pd.cut()函数
np.random.seed(666) #保证每次运行程序产生的随机数都是相同的。
score_list = np.random.randint(25,100,size=3)
print(score_list)
bins = [0,59,70,80,100] #指定多个区间
score_cut = pd.cut(score_list,bins)
score_cut

- 留存率:1-90天有多少留存用户。求出用户的留存天数,比如留存天数==89,属于190天内的留存用户
- 留存天数计算方式:用户每一次的消费时间分别减去用户第一次消费时间
- left:左表,right:右表,how:连接方式,on:连接字段,suffixes:针对相同列名,指定不同的后缀
user_purchase_retention = pd.merge(left=df,right=time_min.reset_index(),how='inner',on='author',suffixes=('','_min'))#计算留存天数
user_purchase_retention['time_diff'] = user_purchase_retention['time']-user_purchase_retention['time_min']
#将time_diff转成数值
user_purchase_retention['time_diff'] = user_purchase_retention['time_diff'].apply(lambda x:x/np.timedelta64(1,'D'))#生成时间跨度(3个月,即90天),判断属于哪个区间
bin = [i*90 for i in range(11)]
user_purchase_retention['time_diff_bin'] = pd.cut(user_purchase_retention['time_diff'],bin)#统计每个游客,在不同的时间段内的消费频率和值(便于稍后判断该用户在某个区间内是不是留存用户)
pivot_retention = user_purchase_retention.groupby(['author','time_diff_bin'])['frequency'].sum().unstack()#判断是否是留存用户(1:留存,0:未留存)
pivot_retention_trans = pivot_retention.fillna(0).applymap(lambda x:1 if x>0 else 0)
#留存率
print(pivot_retention_trans.sum()/pivot_retention_trans.count())
(pivot_retention_trans.sum()/pivot_retention_trans.count()).plot.bar()
plt.xlabel('时间跨度(天)')
plt.ylabel('留存率')
plt.title('各时间段内的用户留存率')

- 如图,每个周期是3个月,第一个周期的留存率在2.2%,前三个周期的递减速度在0.3%左右。
- 在第四五个周期的时候趋于平稳,稳定在留存率1.5%左右
- 从第五个周期开始,留存率明显下降,下降到几乎0%,在第四五周期(1年)的时候,需要采取方法将用户留住进行再次消费。
- 如果在跨度为1年的时候,不召回用户,则就会面临大量用户流失的风险。
相关文章:
Python实战项目——旅游数据分析(四)
由于有之前的项目,所以今天我们直接开始,不做需求分析,还不会需求分析的可以看我之前的文章。Python实战项目——用户消费行为数据分析(三) 导入库 import numpy as np import pandas as pd import matplotlib.pyplo…...
)
前端CryptoJS-AES加解密 对应php的AES-128-CBC加解密踩坑(java也相同加解密)
前端部分注意看填充是pkcs7 有个前提,要看前端有没有转成hex格式,如果没转,php那边就不需要调用特定函数转hex格式的 const keyStr 5hOwdHxpW0GOciqZ;const iv 0102030405060708;//加密function Encrypt(word) {let key CryptoJS.enc.Ut…...

Python解码张三的法外狂徒之旅,揭秘视频背后的真相!【含jS逆向解密】
前言 嗨喽,大家好呀~这里是爱看美女的茜茜呐 传说中,有人因为只是远远的看了一眼法外狂徒张三就进去了😂 我现在是获取他视频,岂不是直接终生了🤩 网友:赶紧跑路吧 😏 好了话不多说ÿ…...

【解析】对比学习和孪生网络的关系
文章目录 区别联系具体概念孪生网络(Siamese Networks)对比学习(Contrastive Learning) 区别 孪生网络是一种特定的神经网络结构;对比学习是一种学习策略,它试图让模型学习如何区分正样本对(相…...

Java版本企业工程项目管理系统平台源码(三控:进度组织、质量安全、预算资金成本、二平台:招采、设计管理)
工程项目管理软件(工程项目管理系统)对建设工程项目管理组织建设、项目策划决策、规划设计、施工建设到竣工交付、总结评估、运维运营,全过程、全方位的对项目进行综合管理 工程项目各模块及其功能点清单 一、系统管理 1、数据字典&#…...

智能井盖:科技赋能城市脚下安全
在智能化飞速发展的今天,智能井盖作为城市基础设施的一部分,正逐渐走进人们的视野。它利用现代科技手段,实现了对城市井盖的实时监控、及时响应和高效管理,为城市管理、市民出行等方面带来了诸多便利。 城市中井盖数量庞大&#x…...

wangeditor编辑器配置
vue项目中使用编辑器,轻量,操作栏选取自己需要的 官网地址:用于 Vue React | wangEditor 使用在vue项目中引入 npm install wangeditor/editor --savenpm install wangeditor/editor-for-vue --save 封装成组件使用 <template>&…...

Sqlite使用WAL模式指南
本文地址:http://t.csdn.cn/kE8ND 文章目录 一、WAL模式的原理二、开启WAL后必须要设置的参数1.PRAGMA SYNCHRONOUS(1)SYNCHRONOUS的类型(2)WAL下如何选择SYNCHRONOUS类型 2.PRAGMA wal_autocheckpoint3.sqlite3_busy…...

一套高质量可靠的 React Hooks 库
个人使用,感受,挺好用 https://ahooks.js.org/zh-CN 我主要用了这个 useCountDown 倒计时,再也不用费心费力去写一个倒计时方法了,而且直接提供end之后要做什么。...
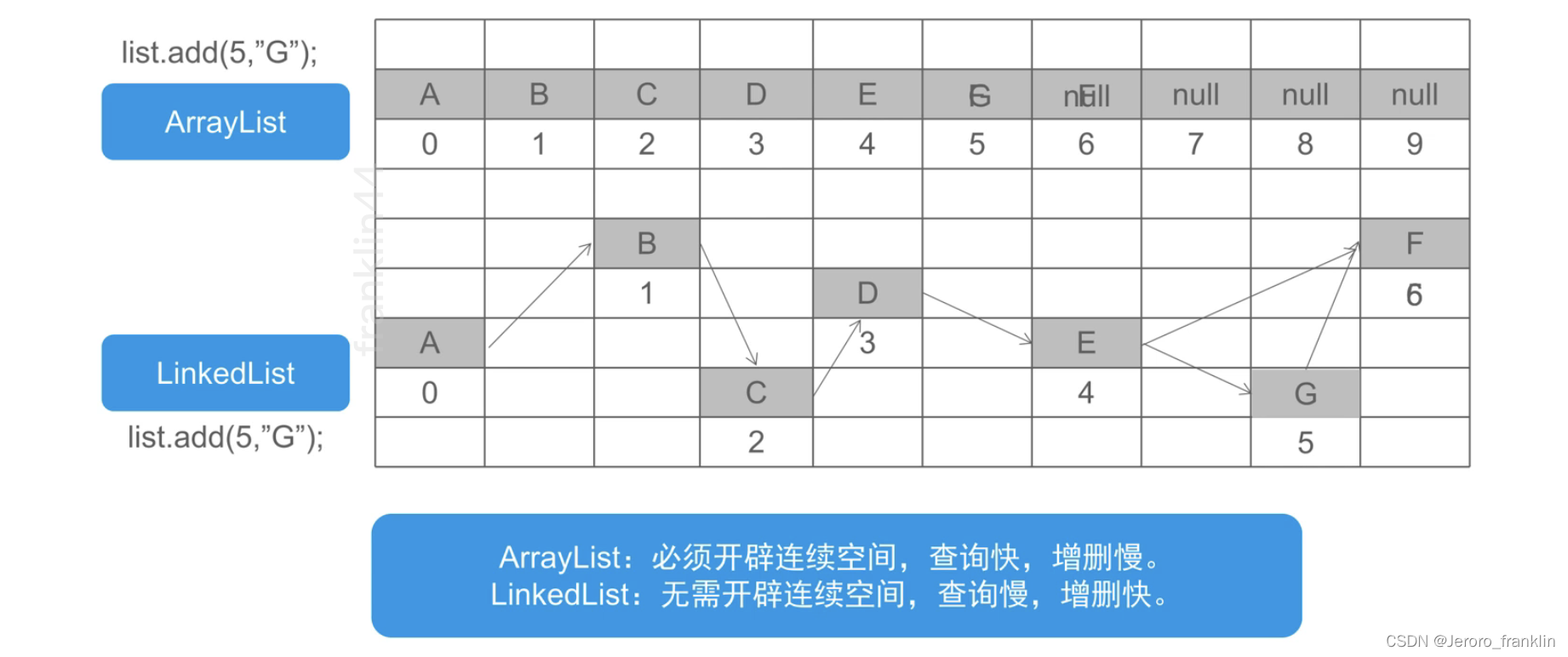
集合---list接口及实现类
一、list概述 1、list接口概述 List接口继承自Collection接口,是单列集合的一一个重要分支,我们习惯性地会将实现了 List接口的对象称为List集合。在List集合中允许出现重复的元素,所有的元素是以一种线性方 式进行有序存储的,在…...
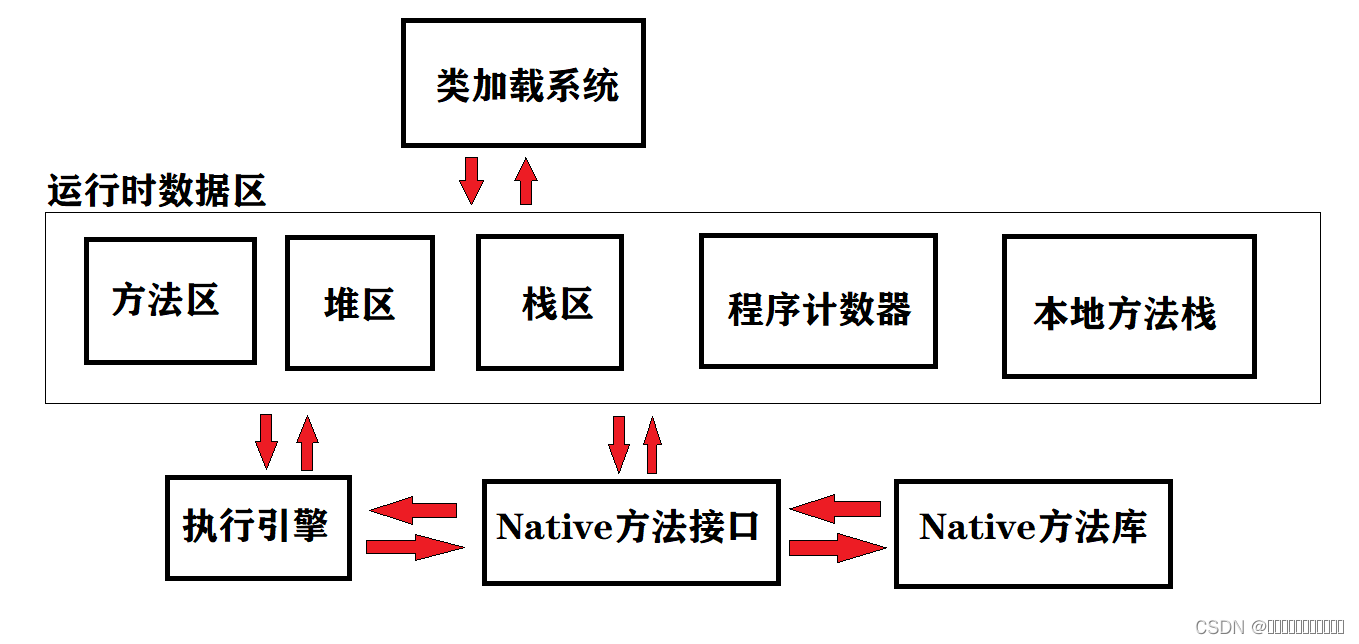
JVM简述
JDK&JRE&JVMJVM运行时内存结构图方法区堆区栈区程序计数器本地方法栈 JVM 的主要组成部分及其作用 JDK&JRE&JVM JVM就是java虚拟机,一台虚拟的机器,用来运行java代码 但并不是只有这台机器就可以的,java程序在运行时需要依赖…...

7.25训练总结
考场错误: A题其实并不简单,但是先想了一个方法后,就交了,wa了后一直卡住,策略不当,到最后后期写C的时候也犯了一些低级的错误,这点需要注意。 之后顺利的把BCDHI写完后,又完成了A的…...
java注解@FeignClient修饰的类路径不在spring boot入口类所在的包下,有哪几种处理方式?
一、注解EnableFeignClients 修饰在spring boot入口类,使得openfeign的FeignClient注解生效。 我们进一步看看注解EnableFeignClients的使用方式。 String[] basePackages() default {};Class<?>[] basePackageClasses() default {};Class<?>[] clie…...

神经网络随记-参数矩阵、剪枝、模型压缩、大小匹配、、
神经网络的参数矩阵 在神经网络中,参数矩阵是模型学习的关键部分,它包含了神经网络的权重和偏置项。下面是神经网络中常见的参数矩阵: 权重矩阵(Weight Matrix):权重矩阵用于线性变换操作,将输…...

4、Kubernetes 集群 YAML 文件详解
目录 一、YAML 概述 二、YAML 基本语法 三、YAML 数据结构 四、k8s资源清单描述方法 五、YAML 快速编写 1、使用 kubectl create 命令 2、使用 kubectl get 命令导出 yaml 文件 一、YAML 概述 k8s 集群中对资源管理和资源对象编排部署都可以通过声明YAML文件来解决&…...
)
leetcode93. 复原 IP 地址(java)
复原 IP 地址 leetcode93. 复原 IP 地址回溯算法代码演示 回溯算法 leetcode93. 复原 IP 地址 有效 IP 地址 正好由四个整数(每个整数位于 0 到 255 之间组成,且不能含有前导 0),整数之间用 ‘.’ 分隔。 例如:“0.1.2…...

极光Java 版本服务器端实现别名消息推送
文章目录 引言I 概述1.1 依赖包1.2 极光证书环境参数1.3 构建推送对象II 推送内容2.1 配置推送内容2.2 获取通知消息内容2.3 配置IOS通知内容2.4 配置Android通知内容2.5 发起推送2.6 分批推送2.7 初始化密钥2.8 配置密钥引言 REST API 文档:https://docs.jiguang.cn/jpush/se…...

【Lua学习笔记】Lua进阶——Table(4)继承,封装,多态
文章目录 封装继承多态 封装 // 定义基类 Object {}//由于表的特性,该句就相当于定义基类变量 Object.id 1//该句相当于定义方法,Object可以视为定义的对象,Test可以视为方法名 //我们知道Object是一个表,但是抽象地看ÿ…...

Linux中常用的指令
ls ls [选项] [目录或文件] 功能:对于目录,列出该目录下所有的子目录和文件;对于文件,列出该文件的文件名和其他属性 常用选项: -a:列出目录下的所有文件,包括以.开头的隐藏文件 -l:列出文件的详细信息。…...

超越单一工具:在快马平台探索多模型ai辅助开发的全新工作流
在开发过程中,AI辅助工具已经逐渐成为提升效率的利器。最近我在尝试使用InsCode(快马)平台时,发现它提供的多模型AI辅助开发能力,远比单一工具更加强大和灵活。下面分享一个我实践的综合示例项目,展示如何利用平台的多模型能力优化…...
)
R语言新手必看:clusterProfiler功能富集分析从安装到实战(附常见报错解决方案)
R语言实战:clusterProfiler功能富集分析全流程指南 第一次接触功能富集分析时,我被那些密密麻麻的基因列表和复杂的生物学术语搞得晕头转向。直到发现了clusterProfiler这个神器,它就像生物信息学分析中的瑞士军刀,把复杂的富集过…...
分步求解)
LFM2.5-1.2B-Thinking-GGUF惊艳效果:复杂逻辑推理题(如数理推导)分步求解
LFM2.5-1.2B-Thinking-GGUF惊艳效果:复杂逻辑推理题(如数理推导)分步求解 1. 模型能力概览 LFM2.5-1.2B-Thinking-GGUF是Liquid AI推出的轻量级文本生成模型,专为低资源环境优化设计。这个1.2B参数的模型采用GGUF格式࿰…...

GitHub加速工具:解决开发者访问难题的终极方案
GitHub加速工具:解决开发者访问难题的终极方案 【免费下载链接】fetch-github-hosts 🌏 同步github的hosts工具,支持多平台的图形化和命令行,内置客户端和服务端两种模式~ | Synchronize GitHub hosts tool, support multi-platfo…...

ChineseChess-AlphaZero技术架构与实践指南:从环境搭建到模型训练
ChineseChess-AlphaZero技术架构与实践指南:从环境搭建到模型训练 【免费下载链接】ChineseChess-AlphaZero Implement AlphaZero/AlphaGo Zero methods on Chinese chess. 项目地址: https://gitcode.com/gh_mirrors/ch/ChineseChess-AlphaZero 副标题&…...

Mermaid在线编辑器:开源可视化工具的图表创作革命
Mermaid在线编辑器:开源可视化工具的图表创作革命 【免费下载链接】mermaid-live-editor Edit, preview and share mermaid charts/diagrams. New implementation of the live editor. 项目地址: https://gitcode.com/GitHub_Trending/me/mermaid-live-editor …...

STM32CubeMX+Keil MDK联合开发:手把手教你配置蓝桥杯G431工程模板
STM32CubeMXKeil MDK联合开发:手把手教你配置蓝桥杯G431工程模板 对于参加蓝桥杯嵌入式赛道的选手来说,掌握STM32G431RBT6开发板的快速工程搭建是必备技能。本文将带你从零开始,通过STM32CubeMX和Keil MDK的协同工作,完成一个标准…...

解锁自定义键盘体验:用Vial-QMK打造个性化配置指南
解锁自定义键盘体验:用Vial-QMK打造个性化配置指南 【免费下载链接】vial-qmk QMK fork with Vial-specific features. 项目地址: https://gitcode.com/gh_mirrors/vi/vial-qmk 核心价值:为什么选择Vial-QMK定制键盘? 在机械键盘的世…...
)
别再ping IP了!手把手教你给ZeroTier虚拟网络里的设备起个‘好记’的名字(DNS/mDNS实战)
告别IP记忆困扰:ZeroTier网络中的智能命名方案实战指南 每次在ZeroTier虚拟网络中访问设备时,你是否也厌倦了反复查看和输入那串冗长的IP地址?想象一下,当你想连接家庭NAS时,只需输入nas.home就能立即访问,…...
如何为Unity游戏实现实时翻译:XUnity Auto Translator完整指南
如何为Unity游戏实现实时翻译:XUnity Auto Translator完整指南 【免费下载链接】XUnity.AutoTranslator 项目地址: https://gitcode.com/gh_mirrors/xu/XUnity.AutoTranslator 你是否遇到过想玩一款优秀的Unity游戏,却发现它只支持日语或英语&am…...