RCU 使用及机制源码的一些分析
===============================》内核新视界文章汇总《===============================
文章目录
- 1 介绍
- 2 使用方法
- 2.1 经典 RCU
- 2.2 不可抢占RCU
- 2.3 加速版不可抢占RCU
- 2.4 链表操作的RCU版本
- 2.5 slab 缓存支持RCU
- 3 源码与实现机制的简单分析
- 3.1 数据结构
- 3.2 不可抢占RCU
- 3.3 加速版不可抢占RCU
- 3.4 可抢占RCU
- 3.5 报告禁止状态
- 3.6 宽限期的开始和结束
- 3.7 RCU回调函数
- 3.8 加速宽限期
- 3.9 可睡眠RCU
- 3.9.1 使用方法
- 4 总结
1 介绍
RCU(Read-Copy Update)的意思是读-复制更新,它是根据原理命名的。
写者修改对象的过程是:首先复制生成一个副本,然后更新这个副本,最后使用新的对象替换旧的对象。在写者执行复制更新的时候读者可以读数据。
写者删除对象,必须等到所有访问被删除对象的读者访问结束,才能执行销毁操作。
RCU的关键技术是怎么判断所有读者已经完成访问。等待所有读者访问结束的时间称为宽限期(grace period)。
RCU的优点是读者没有任何同步开销:不需要获取任何锁,不需要执行原子指令,(在除了阿尔法以外的处理器上)不需要执行内存屏障。但是写者的同步开销比较大,写者需要延迟对象的释放,复制被修改的对象,写者之间必须使用锁互斥。
RCU的第一个版本称为经典RCU,在内核版本2.5.43中引入,目前内核支持3种RCU:
- 不可抢占RCU(RCU-sched)
不允许进程在读端临界区被其他进程抢占。最初的经典RCU是不可抢占RCU,后来引入了可抢占RCU,所以内核版本2.6.12为不可抢占RCU设计了一套专用编程接口。 - 加速版不可抢占RCU(RCU-bh,bh是“bottom half”的缩写,下半部)
在内核版本2.6.9中引入,是针对不可抢占RCU的改进,在软中断很多的情况下可以缩短宽限期。
内核的网络栈在软中断里面处理报文,如果攻击者疯狂地发送报文攻击设备,导致被攻击设备的处理器大部分时间执行软中断,宽限期会变得很长,大量延后执行的销毁操作没有被执行,可能导致内存耗尽。
为了应对这种分布式拒绝服务攻击,RCU-bh把执行完软中断看作处理器退出读端临界区的标志,缩短宽限期。 - 可抢占RCU(RCU-preempt),也称为实时RCU,在内核版本2.6.26中引入。可抢占RCU允许进程在读端临界区被其他进程抢占。编译内核时需要开启配置宏CONFIG_PREEMPT_RCU。
RCU根据数据结构可以分为以下两种:
(1)树型RCU(tree RCU):也称为基于树的分层RCU(Tree-based hierarchical RCU),为拥有几百个或几千个处理器的大型系统设计。配置宏是CONFIG_TREE_RCU。
(2)微型RCU(tiny RCU):为不需要实时响应的单处理器系统设计。配置宏是CONFIG_TINY_RCU。
2 使用方法
2.1 经典 RCU
如果不关心使用的RCU是不可抢占RCU还是可抢占RCU,应该使用经典RCU的编程接口。
最初的经典RCU是不可抢占RCU,后来实现了可抢占RCU,经典RCU的意思发生了变化:如果内核编译了可抢占RCU,那么经典RCU的编程接口被实现为可抢占RCU,否则被实现为不可抢占RCU。
读者使用函数rcu_read_lock()标记进入读端临界区,使用函数rcu_read_unlock()标记退出读端临界区。读端临界区可以嵌套。
在读端临界区里面应该使用宏rcu_dereference(p)访问指针,这个宏封装了数据依赖屏障,即只有阿尔法处理器需要的读内存屏障。
写者可以使用下面4个函数:
(1)使用函数synchronize_rcu()等待宽限期结束,即所有读者退出读端临界区,然后写者执行下一步操作。这个函数可能睡眠。
(2)使用函数synchronize_rcu_expedited()等待宽限期结束。和函数synchronize_rcu()的区别是:该函数会向其他处理器发送处理器间中断(Inter-Processor Interrupt,IPI)请求,强制宽限期快速结束。我们把强制快速结束的宽限期称为加速宽限期(expedited grace period),把没有强制快速结束的宽限期称为正常宽限期(normal grace period)。
(3)使用函数call_rcu()注册延后执行的回调函数,把回调函数添加到RCU回调函数链表中,立即返回,不会阻塞。函数原型如下:
void call_rcu(struct rcu_head *head, rcu_callback_t func);struct callback_head {struct callback_head *next;void (*func)(struct callback_head *head);
} __attribute__((aligned(sizeof(void *))));
#define rcu_head callback_headtypedef void (*rcu_callback_t)(struct rcu_head *head);
(4)使用函数rcu_barrier()等待使用call_rcu注册的所有回调函数执行完。这个函数可能睡眠。
现在举例说明使用方法,假设链表节点和头节点如下:
typedef struct {struct list_head link;struct rcu_head rcu;int key;int val;
} test_entry;struct list_head test_head;
成员struct rcu_head rcu:调用函数call_rcu把回调函数添加到RCU回调函数链表的时候需要使用。
读者访问链表的方法如下:
int test_read(int key, int *val_ptr)
{test_entry *entry;int found = 0;rcu_read_lock();list_for_each_entry_rcu(entry, &test_head, link) {if (entry->key == key) {*val_ptr = entry->val;found = 1;break;}}rcu_read_unlock();return found;
}
如果只有一个写者,写者不需要使用锁,添加、更新和删除3种操作的实现方法如下:
(1)写者添加一个节点到链表尾部。
void test_add_node(test_entry *entry)
{list_add_tail_rcu(&entry->link, &test_head);
}
(2)写者更新一个节点。
更新的过程是:首先把旧节点复制更新,然后使用新节点替换旧节点,最后使用函数call_rcu注册回调函数,延后释放旧节点:
int test_update_node(int key, int new_val)
{test_entry *entry, *new_entry;int ret;ret = -ENOENT;list_for_each_entry(entry, &test_head, link) {if (entry->key == key) {new_entry = kmalloc(sizeof(test_entry), GFP_ATOMIC);if (new_entry == NULL) {ret = -ENOMEM;break;}*new_entry = *entry;new_entry->val = new_val;list_replace_rcu(&entry->list, &new_entry->list);call_rcu(&entry->rcu, test_free_node);ret = 0;break;} }return ret;
}static void test_free_node(struct rcu_head *head)
{test_entry *entry = container_of(head, test_entry, rcu);kfree(entry);
}
(3)写者删除一个节点的第一种实现方法是:首先把节点从链表中删除,然后使用函数call_rcu注册回调函数,延后释放节点:
int test_del_node(int key)
{test_entry *entry;int found = 0;list_for_each_entry(entry, &test_head, link) {if (entry->key == key) {list_del_rcu(&entry->link);call_rcu(&entry->rcu, test_free_node);found = 1;break; } }return found;
}static void test_free_node(struct rcu_head *head)
{test_entry *entry = container_of(head, test_entry, rcu);kfree(entry);
}
(4)写者删除一个节点的第二种实现方法是:首先把节点从链表中删除,然后使用函数synchronize_rcu()等待宽限期结束,最后释放节点:
int test_del_node(int key)
{test_entry *entry;int found = 0;list_for_each_entry(entry, &test_head, link) {if (entry->key == key) {list_del_rcu(&entry->link);synchronize_rcu();kfree(entry);found = 1;break; } }return found;
}
如果有多个写者,那么写者之间必须使用锁互斥,添加、更新和删除3种操作的实现方法如下:
(1)写者添加一个节点到链表尾部。假设使用自旋锁test_lock保护链表:
void test_add_node(test_entry *entry)
{spin_lock(&test_lock);list_add_tail_rcu(&entry->link, &test_head);spin_unlock(&test_lock);
}
(2)写者更新一个节点:
int test_update_node(int key, int new_val)
{test_entry *entry, *new_entry;int ret;ret = -ENOENT;spin_lock(&test_lock);list_for_each_entry(entry, &test_head, link) {if (entry->key == key) {new_entry = kmalloc(sizeof(test_entry), GFP_ATOMIC);if (new_entry == NULL) {ret = -ENOMEM;break;}*new_entry = *entry;new_entry->val = new_val;list_replace_rcu(&entry->list, &new_entry->list);call_rcu(&entry->rcu, test_free_node);ret = 0;break;} }spin_unlock(&test_lock);return ret;
}static void test_free_node(struct rcu_head *head)
{test_entry *entry = container_of(head, test_entry, rcu);kfree(entry);
}
(3)写者删除一个节点:
int test_del_node(int key)
{test_entry *entry;int found = 0;spin_lock(&test_lock);list_for_each_entry(entry, &test_head, link) {if (entry->key == key) {list_del_rcu(&entry->link);call_rcu(&entry->rcu, test_free_node);found = 1;break; } }spin_unlock(&test_lock);return found;
}static void test_free_node(struct rcu_head *head)
{test_entry *entry = container_of(head, test_entry, rcu);kfree(entry);
}
2.2 不可抢占RCU
如果我们的需求是不管内核是否编译了可抢占RCU,都要使用不可抢占RCU,那么应该使用不可抢占RCU的专用编程接口。
读者使用函数rcu_read_lock_sched()标记进入读端临界区,使用函数rcu_read_unlock_sched()标记退出读端临界区。读端临界区可以嵌套。
在读端临界区里面应该使用宏rcu_dereference_sched(p)访问指针,这个宏封装了数据依赖屏障,即只有阿尔法处理器需要的读内存屏障。
写者可以使用下面4个函数:
(1)使用函数synchronize_sched()等待宽限期结束,即所有读者退出读端临界区,然后写者执行下一步操作。这个函数可能睡眠。
(2)使用函数synchronize_sched_expedited()等待宽限期结束。和函数synchronize_sched()的区别是:该函数会向其他处理器发送处理器间中断请求,强制宽限期快速结束。
(3)使用函数call_rcu_sched()注册延后执行的回调函数,把回调函数添加到RCU回调函数链表中,立即返回,不会阻塞。
(4)使用函数rcu_barrier_sched()等待使用call_rcu_sched注册的所有回调函数执行完。这个函数可能睡眠。
2.3 加速版不可抢占RCU
加速版不可抢占RCU在软中断很多的情况下可以缩短宽限期。
读者使用函数rcu_read_lock_bh()标记进入读端临界区,使用函数rcu_read_unlock_bh()标记退出读端临界区。读端临界区可以嵌套。
在读端临界区里面应该使用宏rcu_dereference_bh(p)访问指针,这个宏封装了数据依赖屏障,即只有阿尔法处理器需要的读内存屏障。
写者可以使用下面4个函数:
(1)使用函数synchronize_rcu_bh()等待宽限期结束,即所有读者退出读端临界区,然后写者执行下一步操作。这个函数可能睡眠。
(2)使用函数synchronize_rcu_bh_expedited()等待宽限期结束。和函数synchronize_rcu_bh()的区别是:该函数会向其他处理器发送处理器间中断请求,强制宽限期快速结束。
(3)使用函数call_rcu_bh注册延后执行的回调函数,把回调函数添加到RCU回调函数链表中,立即返回,不会阻塞。
(4)使用函数rcu_barrier_bh()等待使用call_rcu_bh注册的所有回调函数执行完。这个函数可能睡眠。
2.4 链表操作的RCU版本
RCU最常见的使用场合是保护大多数时候读的双向链表。内核实现了链表操作的RCU版本,这些操作封装了内存屏障。
内核实现了4种双向链表:
(1)链表list_head。
(2)链表hlist:和链表list_head相比,优势是头节点只有一个指针,节省内存。
(3)链表hlist_nulls。hlist_nulls是hlist的变体,区别是:链表hlist的结束符号是一个空指针;链表hlist_nulls的结束符号是(1UL | (((long)value) << 1)),最低位为1,value是嵌入的值,比如散列桶的索引。
(4)链表hlist_bl。hlist_bl是hlist的变体,链表头节点的最低位作为基于位的自旋锁保护链表。
链表list_head常用的操作如下:
(1)list_for_each_entry_rcu(pos, head, member)
遍历链表,这个宏封装了只有阿尔法处理器需要的数据依赖屏障。(2)void list_add_rcu(struct list_head *new, struct list_head *head)
把节点添加到链表首部。(3)void list_add_tail_rcu(struct list_head *new, struct list_head *head)
把节点添加到链表尾部。(4)void list_del_rcu(struct list_head *entry)
把节点从链表中删除。(5)void list_replace_rcu(struct list_head *old, struct list_head *new)
用新节点替换旧节点。
链表hlist常用的操作如下:
(1)hlist_for_each_entry_rcu(pos, head, member)
遍历链表。(2)void hlist_add_head_rcu(struct hlist_node *n, struct hlist_head *h)
把节点添加到链表首部。(3)void hlist_add_tail_rcu(struct hlist_node *n, struct hlist_head *h)
把节点添加到链表尾部。(4)void hlist_del_rcu(struct hlist_node *n)
把节点从链表中删除。(5)void hlist_replace_rcu(struct hlist_node *old, struct hlist_node *new)
用新节点替换旧节点。
链表hlist_nulls常用的操作如下:
(1)hlist_nulls_for_each_entry_rcu(tpos, pos, head, member)
遍历链表。(2)void hlist_nulls_add_head_rcu(struct hlist_nulls_node *n, struct hlist_nulls_head *h)
把节点添加到链表首部。(3)void hlist_nulls_add_tail_rcu(struct hlist_nulls_node *n, struct hlist_nulls_head *h)
把节点添加到链表尾部。(4)void hlist_nulls_del_rcu(struct hlist_nulls_node *n)
把节点从链表中删除。
链表hlist_bl常用的操作如下:
(1)hlist_bl_for_each_entry_rcu(tpos, pos, head, member)
遍历链表。(2)void hlist_bl_add_head_rcu(struct hlist_bl_node *n, struct hlist_bl_head *h)
把节点添加到链表首部。(3)void hlist_bl_del_rcu(struct hlist_bl_node *n)
把节点从链表中删除。
2.5 slab 缓存支持RCU
创建 slab 缓存的时候,可以使用标志SLAB_TYPESAFE_BY_RCU(旧的名称是SLAB_DESTROY_BY_RCU),延迟释放 slab 页到RCU宽限期结束,例如:
struct kmem_cache *anon_vma_cachep;anon_vma_cachep = kmem_cache_create("anon_vma", sizeof(struct anon_vma),0, SLAB_TYPESAFE_BY_RCU|SLAB_PANIC|SLAB_ACCOUNT,anon_vma_ctor);
注意:标志SLAB_TYPESAFE_BY_RCU只会延迟释放 slab 页到RCU宽限期结束,但是不会延迟对象的释放。当调用函数kmem_cache_free()释放对象时,对象的内存被释放了,可能立即被分配给另一个对象。
针对使用函数kmalloc()从通用 slab 缓存分配的对象,提供了函数kfree_rcu(ptr, rcu_head)来延迟释放对象到RCU宽限期结束,参数rcu_head是指针ptr指向的结构体里面类型为struct rcu_head的成员的名称。例如:
typedef struct {struct list_head link;struct rcu_head rcu;int key;int val;
} test_entry;test_entry *p;p = kmalloc(sizeof(test_entry), GFP_KERNEL);
...
kfree_rcu(p, rcu);
3 源码与实现机制的简单分析
注意:分析采用 linux-4.18/linux-5.10 内核混合
首先介绍RCU的术语:
(1)读端临界区(Read-Side Critical Section):读者访问RCU保护的对象的代码区域。
(2)静止状态(quiescent state, 简称 qs):处理器的执行状态,处理器没有读RCU保护的对象,也可以理解为读者静止,没有访问临界区。

(3)候选静止状态(Candidate Quiescent State):读端临界区以外的所有点都是候选静止状态。
(4)可被观察的静止状态(Observed Quiescent State):一部分候选静止状态可以很容易观察到,因为它们和内核的某个事件关联,通过内核的事件可以观察到。把这些容易观察到的静止状态称为可被观察的静止状态。内核的RCU使用的静止状态是可被观察的静止状态,不可抢占RCU通过事件进程调度器调度进程观察到静止状态,加速版不可抢占RCU通过事件执行完软中断观察到静止状态。
(5)宽限期(grace period):等待所有处理器上的读者退出临界区的时间称为宽限期。如果所有处理器都至少经历了一个静止状态,那么当前宽限期结束,新的宽限期开始。当前宽限期结束的时候,写者在当前宽限期及以前注册的销毁对象的回调函数就可以安全地执行了。

宽限期分为正常宽限期(normal grace period)和加速宽限期(expedited grace period)。
调用函数synchronize_rcu_expedited()等待宽限期结束的时候,会向其他处理器发送处理器间中断(Inter-Processor Interrupt,IPI)请求,强制产生静止状态,使宽限期快速结束,我们把强制快速结束的宽限期称为加速宽限期。
RCU需要使用位图记录哪些处理器经历了一个静止状态。在宽限期开始的时候,在位图中为所有处理器设置对应的位,如果一个处理器经历了一个静止状态,就把自己的位从位图中清除,处理器修改位图的时候必须使用自旋锁保护。如果处理器很多,对自旋锁的竞争很激烈,会导致系统性能很差。
为了解决性能问题,基于树的分层RCU采用了类似淘汰赛的原理:把处理器分组,当一个处理器经历了一个静止状态时,把自己的位从分组的位图中清除,只需要竞争分组的自旋锁,当分组中的最后一个处理器经历了一个静止状态时,代表分组从上一层分组的位图中清除位,竞争上一层分组的自旋锁。
这里基于树的分层RCU描述技术原理。微型RCU是一个简化版本,原理相同。
3.1 数据结构
RCU使用数据类型rcu_state描述RCU的全局状态,使用数据类型rcu_node描述一个处理器分组的RCU状态,使用数据类型rcu_data描述一个处理器的RCU状态,每个处理器对应一个rcu_data实例。

配置宏CONFIG_RCU_FANOUT用来配置中间节点的扇出(fanout),即一个中间节点可以拥有的子节点的最大数量,64位内核的默认值是64。
配置宏CONFIG_RCU_FANOUT_LEAF用来配置叶子节点的扇出,即叶子节点可以拥有的rcu_data实例的最大数量,默认值是16。
树的深度取决于处理器的数量、中间节点的扇出和叶子节点的扇出。
数据类型rcu_state描述RCU的全局状态,部分成员如下:
# kernel/rcu/tree.h
struct rcu_state {struct rcu_node node[NUM_RCU_NODES]; /* Hierarchy. */(1)struct rcu_node *level[RCU_NUM_LVLS + 1];(2)/* Hierarchy levels (+1 to *//* shut bogus gcc warning) */int ncpus; /* # CPUs seen so far. */(3)unsigned long gp_seq ____cacheline_internodealigned_in_smp;/* Grace-period sequence #. */(4)struct task_struct *gp_kthread; /* Task for grace periods. */(5)struct swait_queue_head gp_wq; /* Where GP task waits. */(6)short gp_flags; /* Commands for GP task. */(7)short gp_state; /* GP kthread sleep state. */(8)
};
(1)数组node定义了所有树节点。
(2)数组level保存每个层次的第一个rcu_node实例。
(3)成员ncpus是处理器数量。
(4)成员gp_seq是当前宽限期的编号。
(5)成员gp_kthread指向宽限期线程。
(6)成员gp_wq是宽限期线程的等待队列。
(7)成员gp_flags用来向宽限期线程传递命令。
(8)成员gp_state是宽限期线程的睡眠状态。
内核为每种RCU定义了一个rcu_state实例:
(1)不可抢占RCU的rcu_state实例是rcu_sched_state。
(2)加速版不可抢占RCU的rcu_state实例是rcu_bh_state。
(3)可抢占RCU的rcu_state实例是rcu_preempt_state。
(4)经典RCU的rcu_state实例是全局变量rcu_state_p指向的rcu_state实例:如果内核编译了可抢占RCU,rcu_state_p指向可抢占RCU的rcu_state实例,否则指向不可抢占RCU的rcu_state实例。
数据类型rcu_node描述一个处理器分组的RCU状态,主要成员如下:
# kernel/rcu/tree.h
struct rcu_node {raw_spinlock_t __private lock;unsigned long gp_seq; unsigned long qsmask; unsigned long qsmaskinit;unsigned long qsmaskinitnext;unsigned long expmask;unsigned long expmaskinit;unsigned long expmaskinitnext;unsigned long grpmask; int grplo; int grphi; u8 grpnum; u8 level; …struct rcu_node *parent;…
} ____cacheline_internodealigned_in_smp;
(1)成员lock是保护本节点的自旋锁。
(2)成员gp_seq是本节点的当前宽限期编号。
(3)成员qsmask是静止状态位图,用来记录哪些成员经历了正常宽限期的静止状态。如果某个位为1,表示对应的成员没有经历静止状态。
(4)成员qsmaskinit是每个正常宽限期开始的时候静止状态位图的初始值。
(5)成员qsmaskinitnext是下一个正常宽限期开始的时候静止状态位图的初始值,和处理器热插拔有关。
(6)成员expmask是静止状态位图,用来记录哪些成员经历了加速宽限期的静止状态。
(7)成员expmaskinit是每个加速宽限期开始的时候静止状态位图的初始值。
(8)成员expmaskinitnext是下一个加速宽限期开始的时候静止状态位图的初始值。
(9)成员grpmask是该分组在上一层分组的位图中的位掩码。
(10)成员grplo是属于该分组的处理器的最小编号。
(11)成员grphi是属于该分组的处理器的最大编号。
(12)成员grpnum是该分组在上一层分组里面的编号。
(13)成员level是本节点在树中的层次,根的层次是0。
(14)成员parent指向上一层分组。
数据类型rcu_data描述一个处理器的RCU状态,主要成员如下:
# kernel/rcu/tree.h
struct rcu_data {/* 1) 静止状态和宽限期处理: */unsigned long gp_seq; ... union rcu_noqs cpu_no_qs; bool core_needs_qs; ...bool gpwrap; struct rcu_node *mynode; unsigned long grpmask; .../* 2) 批量处理*/struct rcu_segcblist cblist;
};
(1)成员 gp_seq 是本处理器看到的最高宽限期编号。
(2)成员cpu_no_qs记录本处理器是否经历静止状态,数据类型如下:
union rcu_noqs {struct {u8 norm;u8 exp;} b; /* 位 */u16 s; /* 位集合,用来把“norm || exp”聚合为“s”。*/
};
其中norm表示是否经历正常宽限期的静止状态,exp表示是否经历加速宽限期的静止状态。
(3)成员mynode指向本处理器所属的分组。
(4)成员grpmask是本处理器在分组的位图中的位掩码。
(5)成员cblist是回调函数链表,存放函数call_rcu()注册的延后执行的回调函数。
(6)成员cpu是本处理器的编号。
(7)成员rsp指向rcu_state实例。
3.2 不可抢占RCU
不可抢占RCU(RCU-sched)不允许进程在读端临界区被其他进程抢占,使用函数rcu_read_lock_sched()标记读端临界区的开始,使用函数rcu_read_unlock_sched()标记读端临界区的结束。
从代码可以看出,函数rcu_read_lock_sched()禁止内核抢占,函数rcu_read_unlock_sched()开启内核抢占:
# include/linux/rcupdate.h
static inline void rcu_read_lock_sched(void)
{preempt_disable();...
}static inline void rcu_read_unlock_sched(void)
{...preempt_enable();
}
不可抢占RCU通过以下事件观察到静止状态:
(1)进程调度器调度进程。因为不可抢占RCU的读端临界区禁止内核抢占,所以进程调度器不会在读端临界区里面调度进程。如果进程调度器调度进程,处理器一定不在读端临界区里面。
(2)当前进程正在用户模式下运行。
(3)处理器空闲,正在执行空闲线程。
记录点:
1)如下所示,当进程调度器调度进程的时候,观察到静止状态,调用函数rcu_qs记录静止状态:
__schedule-> rcu_note_context_switch-> rcu_qs
2)如下所示,时钟中断处理程序调用函数rcu_check_callbacks检查静止状态。函数rcu_check_callbacks的代码如下:
tick_sched_timer-> tick_sched_handle-> update_process_times-> rcu_check_callbacks-> (user || rcu_is_cpu_rrupt_from_idle())?-> rcu_qs
user为1表示当前进程正在用户模式下运行。
rcu_is_cpu_rrupt_from_idle()表示处理器正在执行空闲线程,并且时钟中断是第一层中断。
为什么要求时钟中断是第一层中断?
如果是第二层中断,说明第一层中断正在执行下半部,下半部可能正在执行读端临界区,第二层中断抢占第一层中断的下半部。
通过这两个事件观察到静止状态,调用函数rcu_qs记录静止状态。
函数rcu_qs记录静止状态,其代码如下:
# kernel/rcu/tree.c
static void rcu_qs(void)
{RCU_LOCKDEP_WARN(preemptible(), "rcu_qs() invoked with preemption enabled!!!");if (!__this_cpu_read(rcu_data.cpu_no_qs.s))return;trace_rcu_grace_period(TPS("rcu_sched"),__this_cpu_read(rcu_data.gp_seq), TPS("cpuqs"));__this_cpu_write(rcu_data.cpu_no_qs.b.norm, false);if (!__this_cpu_read(rcu_data.cpu_no_qs.b.exp))return;__this_cpu_write(rcu_data.cpu_no_qs.b.exp, false);rcu_report_exp_rdp(this_cpu_ptr(&rcu_data));
}
如果没有记录过静止状态,那么记录本处理器经历了静止状态,把rcu_data实例的成员cpu_no_qs.b.norm设置为假。RCU不关心处理器经历了多少个静止状态,只关心是否经历过静止状态。
3.3 加速版不可抢占RCU
加速版不可抢占RCU(RCU-bh)使用函数rcu_read_lock_bh()标记读端临界区的开始,使用函数rcu_read_unlock_bh()标记读端临界区的结束。
从代码可以看出,函数rcu_read_lock_bh()禁止软中断,函数rcu_read_unlock_bh()开启软中断:
include/linux/rcupdate.h
static inline void rcu_read_lock_bh(void)
{local_bh_disable();...
}static inline void rcu_read_unlock_bh(void)
{...local_bh_enable();
}
加速版不可抢占RCU通过以下事件观察到静止状态:
(1)执行完软中断。因为RCU-bh的读端临界区禁止软中断,所以进程在读端临界区里面不会被软中断抢占。考虑到软中断也可能执行读端临界区,所以执行完软中断的时候,处理器一定不在读端临界区里面。
(2)当前进程正在用户模式下运行。
(3)处理器空闲,正在执行空闲线程。
(4)处理器没有执行软中断或禁止软中断的代码区域。
记录点:
1)如下所示,执行完一轮软中断之后,禁止硬中断之前,调用函数rcu_bh_qs记录静止状态:
irq_exit-> invoke_softirq-> __do_softirq-> local_irq_enable-> 执行软中断-> rcu_softirq_qs-> rcu_qs-> local_irq_disable
2)如下所示(4.18),同样是在时钟中断中,时钟中断处理程序调用函数rcu_check_callbacks检查静止状态。函数rcu_check_callbacks的代码如下:
tick_sched_timer-> tick_sched_handle-> update_process_times-> rcu_check_callbacks-> !in_softirqs() ?-> rcu_bh_qs
!in_softirq()表示时钟中断打断的时候,处理器没有执行软中断或禁止软中断的代码区域。
通过这3个事件观察到静止状态,调用函数rcu_bh_qs记录静止状态。
函数rcu_bh_qs记录静止状态,其代码如下:
kernel/rcu/tree.c
void rcu_bh_qs(void)
{if (__this_cpu_read(rcu_bh_data.cpu_no_qs.s)) {…__this_cpu_write(rcu_bh_data.cpu_no_qs.b.norm, false);}
}
如果没有记录过静止状态,那么记录本处理器经历了静止状态,把rcu_bh_data实例的成员cpu_no_qs.b.norm设置为假。
3.4 可抢占RCU
可抢占RCU(RCU-preempt)允许进程在读端临界区里面被其他进程抢占,使用函数rcu_read_lock()标记读端临界区的开始,使用函数rcu_read_unlock()标记读端临界区的结束。
可抢占RCU观察静止状态,需要考虑以下因素:
(1)进程在读端临界区里面被其他进程抢占以后,可能被迁移到其他处理器:可能是同一个分组的其他处理器,也可能是其他分组的处理器。造成的后果是:进程可能在一个处理器上进入读端临界区,在同一个分组的另一个处理器上退出读端临界区;进程可能在一个分组中进入读端临界区,在另一个分组中退出读端临界区。
(2)读端临界区可能嵌套。
可抢占RCU观察静止状态的实现方案如下:
(1)不是以处理器为单位观察静止状态,而是以最底层分组为单位观察静止状态。不可抢占RCU和加速版不可抢占RCU都是以处理器为单位观察静止状态。
(2)进程需要记录读端临界区的嵌套层数,进入读端临界区的时候把嵌套层数加1,退出读端临界区的时候把嵌套层数减1。当嵌套层数变成0的时候,说明进程已退出最外层的读端临界区。
(3)当进程在读端临界区里面被其他进程抢占的时候,把进程添加到分组的阻塞进程链表中,并且记录分组。
(4)当进程退出最外层的读端临界区的时候,把进程从分组的阻塞进程链表中删除。如果分组的阻塞进程链表变为空,那么观察到一个静止状态。注意这里的分组是第3步记录的分组,不是进程当前所在的处理器的分组。换句话说,在分组n中进入读端临界区的进程,不管是不是在分组n中退出读端临界区,都看作在分组n中退出读端临界区。当在分组n中进入读端临界区的所有进程退出读端临界区的时候,分组n观察到一个静止状态。
举例说明:假设处理器0属于分组0,处理器16属于分组1。进程在处理器0上运行,在读端临界区里面被其他进程抢占的时候,把进程添加到分组0的阻塞进程链表中。然后进程被迁移到处理器16,退出最外层的读端临界区,把进程从分组0的阻塞进程链表中删除,分组0的阻塞进程链表变为空,观察到分组0的一个静止状态。
可抢占RCU在进程描述符里面增加了成员:
include/linux/sched.h
struct task_struct {...
#ifdef CONFIG_PREEMPT_RCUint rcu_read_lock_nesting;union rcu_special rcu_read_unlock_special;struct list_head rcu_node_entry;struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_PREEMPT_RCU */…
};
(1)成员rcu_read_lock_nesting记录读端临界区的嵌套次数。
(2)成员rcu_read_unlock_special的数据类型如下:
union rcu_special {struct {u8 blocked;u8 need_qs;u8 exp_need_qs;u8 pad;} b; /* 位 */u32 s; /* 位集合 */
};
- 成员blocked:如果为真,表示进程在读端临界区里面被其他进程抢占,阻塞了当前宽限期。
- 成员need_qs:如果为真,表示需要进程报告正常宽限期的静止状态。
- 成员exp_need_qs:如果为真,表示需要进程报告加速宽限期的静止状态。
(3)当进程在读端临界区里面被其他进程抢占的时候,使用成员rcu_node_entry把进程加入分组的阻塞进程链表,使用成员rcu_blocked_node记录当前处理器所属的分组。
可抢占RCU在数据类型rcu_node中增加了以下成员:
# kernel/rcu/tree.h
struct rcu_node {…struct list_head blkd_tasks;struct list_head *gp_tasks;struct list_head *exp_tasks;…
} ____cacheline_internodealigned_in_smp;
(1)成员blkd_tasks是阻塞进程链表,保存在读端临界区里面被其他进程抢占的进程。
(2)成员gp_tasks指向阻塞当前正常宽限期的第一个进程,从这个节点开始到链表尾部的所有进程都阻塞当前正常宽限期。
(3)成员exp_tasks指向阻塞当前加速宽限期的第一个进程,从这个节点开始到链表尾部的所有进程都阻塞当前加速宽限期。
- 从首部到gp_tasks的前一个链表节点是没有阻塞当前宽限期的进程。
- 从gp_tasks到尾部是阻塞当前正常宽限期的进程。
- 从exp_tasks到尾部是阻塞当前加速宽限期的进程
(1)进入读端临界区。
函数rcu_read_lock()把当前进程的读端临界区的嵌套次数加1,其代码如下:
rcu_read_lock() -> __rcu_read_lock()kernel/rcu/update.c
#ifdef CONFIG_PREEMPT_RCU
void __rcu_read_lock(void)
{current->rcu_read_lock_nesting++;barrier();
}
#endif
(2)在读端临界区里面被抢占。
当进程在读端临界区里面被其他进程抢占的时候,执行流程如下所示,函数rcu_preempt_note_context_switch的代码如下:
__schedule-> rcu_note_context_switch-> rcu_preempt_note_context_switch-> 进程在读端临界区里面?-> 进程描述符 rcu_read_unlock_special.b.blocked = true-> 进程描述符 rcu_blocked_node 记录当前处理器分组-> rcu_preempt_ctxt_queue 把进程加入分组的阻塞进程链表-> 进程正在退出读端临界区的最外层?-> rcu_read_unlock_special 继续执行从读端临界区退出的剩余部分-> rcu_preempt_qs# kernel/rcu/tree_plugin.hstatic void rcu_preempt_note_context_switch(void){struct task_struct *t = current;struct rcu_data *rdp;struct rcu_node *rnp;if (t->rcu_read_lock_nesting > 0 &&!t->rcu_read_unlock_special.b.blocked) {rdp = this_cpu_ptr(rcu_state_p->rda);rnp = rdp->mynode;raw_spin_lock_rcu_node(rnp);t->rcu_read_unlock_special.b.blocked = true;t->rcu_blocked_node = rnp;…rcu_preempt_ctxt_queue(rnp, rdp); } else if (t->rcu_read_lock_nesting < 0 &&t->rcu_read_unlock_special.s) {rcu_read_unlock_special(t);}rcu_preempt_qs();}
- 如果进程在读端临界区里面,处理如下:
- 记录进程被抢占,把进程描述符的成员
rcu_read_unlock_special.b.blocked设置为真。 - 使用进程描述符的成员
rcu_blocked_node记录当前处理器的分组。 - 调用函数
rcu_preempt_ctxt_queue(),把进程加入分组的阻塞进程链表。
- 记录进程被抢占,把进程描述符的成员
- 如果进程描述符的成员
rcu_read_lock_nesting是负数,说明进程正在退出读端临界区的最外层,那么继续执行从读端临界区退出的剩余部分。
3.5 报告禁止状态
如果一个处理器经历了静止状态,那么需要向分组报告静止状态。如果是分组中最后一个经历静止状态的处理器,那么还需要代表分组向上一层分组报告静止状态。当根节点的所有成员都报告了静止状态后,当前宽限期可以结束。
如下所示,时钟中断处理程序调用函数rcu_check_callbacks,函数rcu_check_callbacks调用函数rcu_pending以检查本处理器是否有RCU相关的工作需要处理,如果有,那么触发RCU软中断:
tick_sched_timer-> tick_sched_handle-> update_process_times-> rcu_check_callbacks-> rcu_pending?-> invoke_rcu_core-> raise_softirq(RCU_SOFTIRQ)
函数rcu_pending把主要工作委托给函数__rcu_pending,函数__rcu_pending检查是否需要报告静止状态的代码如下:
# kernel/rcu/tree.c
static int __rcu_pending(struct rcu_state *rsp, struct rcu_data *rdp)
{struct rcu_node *rnp = rdp->mynode;…if (…) {…} else if (rdp->core_needs_qs && !rdp->cpu_no_qs.b.norm) {rdp->n_rp_report_qs++;return 1;}…
}
rdp->core_needs_qs 为真表示RCU需要本处理器报告静止状态,!rdp->cpu_no_qs.b.norm 为真表示本处理器经历了正常宽限期的静止状态。
如下所示,RCU软中断的处理函数rcu_process_callbacks调用函数rcu_check_quiescent_state来检查是否需要报告静止状态。如果RCU需要本处理器报告静止状态,并且本处理器经历了正常宽限期的静止状态,那么调用函数rcu_report_qs_rdp报告静止状态:
软中断 RCU_SOFTIRQ 的处理函数
rcu_process_callbacks-> __rcu_process_callbacks-> rcu_check_quiescent_state-> 如果RCU需要本处理器报告禁止状态, 并且本处理器经历了正常宽限期的静止状态-> rcu_report_qs_rdp
3.6 宽限期的开始和结束
每种RCU创建了一个宽限期线程,专门负责启动新的宽限期和结束当前宽限期。数据类型rcu_state中和宽限期线程相关的成员如下:
# kernel/rcu/tree.h
struct rcu_state {…struct task_struct *gp_kthread; struct swait_queue_head gp_wq; short gp_flags; short gp_state; …
};
(1)成员gp_kthread指向宽限期线程。
(2)成员gp_wq是宽限期线程的等待队列。
(3)成员gp_flags用来向宽限期线程传递命令,目前有如下两个标志位。
- 标志位
RCU_GP_FLAG_INIT表示需要启动新的宽限期。 - 标志位
RCU_GP_FLAG_FQS表示需要强制静止状态。
(4)成员gp_state是宽限期线程的睡眠状态,取值如下:
#define RCU_GP_IDLE 0 /* 没有宽限期. */
#define RCU_GP_WAIT_GPS 1 /* 等待宽限期开始 */
#define RCU_GP_DONE_GPS 2 /* 停止等待宽限期开始 */
#define RCU_GP_WAIT_FQS 3 /* 等待强制静止状态时刻 */
#define RCU_GP_DOING_FQS 4 /* 停止等待强制静止状态时刻 */
#define RCU_GP_CLEANUP 5 /* 宽限期清理开始 */
#define RCU_GP_CLEANED 6 /* 宽限期清理结束 */
3.7 RCU回调函数
(1)回调函数链表。
每个处理器的rcu_data实例的成员cblist是回调函数链表,里面存放使用函数call_rcu()注册的回调函数,其定义如下:
# include/linux/rcu_segcblist.h
#define RCU_DONE_TAIL 0 /* 也是 RCU_WAIT 的首部. */
#define RCU_WAIT_TAIL 1 /* 也是 RCU_NEXT_READY 的首部. */
#define RCU_NEXT_READY_TAIL 2 /* 也是 RCU_NEXT 的首部 */
#define RCU_NEXT_TAIL 3
#define RCU_CBLIST_NSEGS 4struct rcu_segcblist {struct rcu_head *head;struct rcu_head **tails[RCU_CBLIST_NSEGS];unsigned long gp_seq[RCU_CBLIST_NSEGS];long len;long len_lazy;
};
成员head指向第一个回调函数。
数组tails指向每一段的结束位置。tails[n]是第n段的最后一个rcu_head实例的成员next的地址,因为next是rcu_head的第一个成员,所以*tails[n]等价于((struct rcu_head *)tails[n])->next,指向下一段的开始位置。
数组gp_seq保存每一段的宽限期编号。
成员len是回调函数链表的长度。
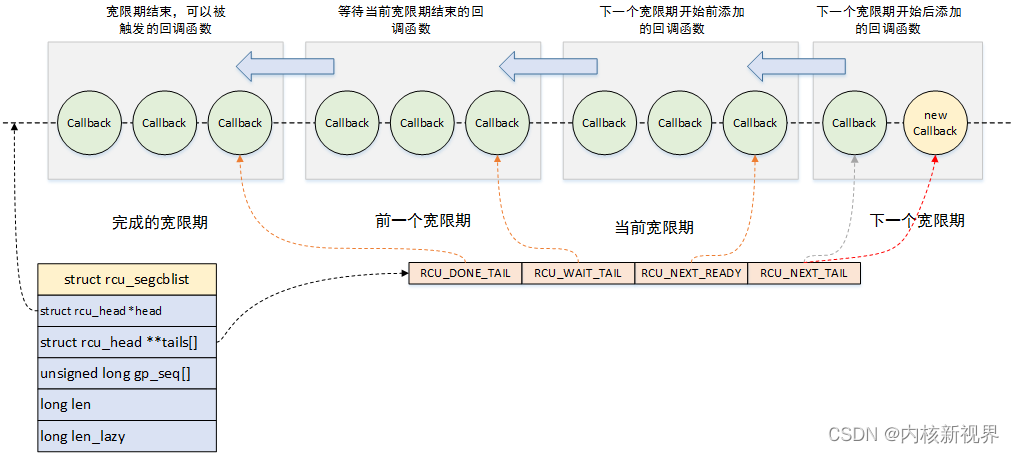
1)[head, *tails[RCU_DONE_TAIL]):子链表RCU_DONE_TAIL,宽限期已经结束的回调函数,可以被执行。
2)[*tails[RCU_DONE_TAIL], *tails[RCU_WAIT_TAIL]):子链表RCU_WAIT_TAIL,等待当前宽限期的回调函数。
3)[*tails[RCU_WAIT_TAIL], *tails[RCU_NEXT_READY_TAIL]):子链表RCU_NEXT_READY_TAIL,在下一个宽限期开始之前添加的回调函数,在下一个宽限期可以执行这些回调函数。
4)[*tails[RCU_NEXT_READY_TAIL], *tails[RCU_NEXT_TAIL]):子链表RCU_NEXT_TAIL,在下一个宽限期开始之后添加的回调函数。
这里说的当前宽限期是处理器看到的当前宽限期,宽限期线程启动新的宽限期时,处理器的rcu_data实例记录的当前宽限期可能还是旧的,落后于全局的当前宽限期。
(2)注册回调函数。
使用call_rcu注册回调函数的执行流程如下所示,把主要工作委托给函数__call_rcu,执行过程如下:
call_rcu/call_rcu_sched/call_rcu_bh-> __call_rcu-> rcu_segcblist_enqueue-> __call_rcu_core-> 如果回调函数太多-> note_gp_changes-> __note_gp_changes-> 如果没有启动宽限期-> rcu_start_gp 启动宽限期-> 如果启动了宽限期-> force_quiescent_state 强制静止状态
1)调用函数rcu_segcblist_enqueue,把回调函数添加到最后一个子链表RCU_NEXT_TAIL的尾部。
2)调用函数__call_rcu_core,如果回调函数太多,处理如下:
- 调用函数
note_gp_change,把叶子节点的已结束宽限期和最新宽限期同步到本处理器的rcu_data实例。 - 如果没有启动宽限期,那么通知宽限期线程启动宽限期。
- 如果启动了宽限期,那么通知宽限期线程强制静止状态。
(3)执行回调函数。
RCU软中断执行回调函数的流程如下所示:
软中断 RCU_SOFTIRQ 的处理函数 rcu_process_callbacks-> __rcu_process_callbacks-> rcu_check_quiescent_state-> note_gp_changes-> __note_gp_changes-> rcu_segcblist_ready_cbs(&rdp->cblist)?-> invoke_rcu_callbacks-> rcu_do_batch
1)调用函数__note_gp_changes,推进回调函数链表。
2)如果子链表RCU_DONE_TAIL不是空的,那么调用函数rcu_do_batch执行回调函数。
如下所示,函数__note_gp_changes比较本处理器的rcu_data实例的已结束宽限期编号和叶子节点的已结束宽限期编号,分情况处理:
__note_gp_changes-> 如果没有宽限期结束-> rcu_accelerate_cbs-> 如果有宽限期结束-> rcu_advance_cbs-> rcu_segcblist_advance-> rcu_accelerate_cbs-> 把已结束宽限期编号更新为叶子节点的已结束宽限期编号
1)如果相等,说明没有宽限期结束,那么调用函数rcu_accelerate_cbs加速回调函数,把最后一个子链表RCU_NEXT_TAIL的回调函数移到前面的子链表中。
2)如果不等,说明有宽限期结束,处理如下:
- 调用函数
rcu_advance_cbs推进回调函数链表:首先调用函数rcu_segcblist_advance,把已结束宽限期的回调函数移到子链表RCU_DONE_TAIL中,然后调用函数rcu_accelerate_cbs加速回调函数,把最后一个子链表RCU_NEXT_TAIL的回调函数移到前面的子链表中。 - 把
rcu_data实例的已结束宽限期编号更新为叶子节点的已结束宽限期编号。
1)函数rcu_segcblist_advance。
函数rcu_segcblist_advance负责处理子链表RCU_WAIT_TAIL和RCU_NEXT_READY_TAIL。如果子链表的宽限期是已结束宽限期,那么把回调函数移到子链表RCU_DONE_TAIL中。
2)函数rcu_accelerate_cbs。
函数rcu_accelerate_cbs负责加速回调函数,把最后一个子链表RCU_NEXT_TAIL的回调函数移到前面的子链表中。
3.8 加速宽限期
加速宽限期的原理是在所有处理器上强制产生静止状态,使宽限期快速结束。加速宽限期减少了函数synchronize_rcu_expedited及其变体的等待时间,但是提高了处理器利用率,增加了实时延迟和耗电。
以不可抢占RCU的函数synchronize_sched_expedited()为例说明,调用函数smp_call_function_single,在每个处理器上执行强制产生静止状态的函数sync_sched_exp_handler,函数smp_call_function_single根据情况进行处理。
(1)如果目标处理器是本处理器,那么直接执行强制产生静止状态的函数sync_sched_exp_handler。
(2)如果目标处理器是其他处理器,那么发送处理器间中断请求到目标处理器,目标处理器在中断处理程序里面执行强制产生静止状态的函数sync_sched_exp_handler。
3.9 可睡眠RCU
可睡眠RCU(Sleepable RCU,SRCU)允许在读端临界区里面睡眠。
在读端临界区里面睡眠,可能导致宽限期很长。为了避免影响整个系统,使用SRCU的子系统需要定义一个SRCU域,每个SRCU域有自己的读端临界区和宽限期。
目前内核有3种可睡眠RCU:
(1)经典SRCU:传统的SRCU,配置宏是CONFIG_CLASSIC_SRCU。
(2)微型SRCU:为单处理器系统设计,配置宏是CONFIG_TINY_SRCU。
(3)树型SRCU:为拥有几百个或几千个处理器的大型系统设计,配置宏是CONFIG_TREE_SRCU。
内核4.12版本引入微型SRCU和树型SRCU,保留经典SRCU,作为微型SRCU和树型SRCU出现问题时的备选项。由于微型SRCU和树型SRCU在测试中表现非常好,所以内核4.13版本废除了经典SRCU。
3.9.1 使用方法
首先需要定义一个SRCU域:
struct srcu_struct ss;
然后初始化SRCU域:
int init_srcu_struct(struct srcu_struct *sp);
成功则返回0,分配内存失败则返回-ENOMEM。
读者访问临界区的方法如下:
int idx;idx = srcu_read_lock(&ss);
/* 读端临界区 */
srcu_read_unlock(&ss, idx);
函数srcu_read_lock()返回一个索引,需要把这个索引传给函数srcu_read_unlock()。
在读端临界区里面应该使用宏srcu_dereference(p, sp)访问指针,这个宏封装了数据依赖屏障,即只有阿尔法处理器需要的读内存屏障。
写者可以使用下面4个函数:
(1)使用函数synchronize_srcu()等待宽限期结束,即所有读者退出读端临界区,然后写者执行下一步操作。这个函数可能睡眠。
void synchronize_srcu(struct srcu_struct *sp);
(2)使用函数synchronize_srcu_expedited()等待宽限期结束,强制宽限期快速结束。
void synchronize_srcu_expedited(struct srcu_struct *sp);
(3)使用函数call_srcu()注册延后执行的回调函数,把回调函数添加到srcu_struct结构体的回调函数链表中,立即返回,不会睡眠。
void call_srcu(struct srcu_struct *sp, struct rcu_head *head, rcu_callback_t func);
(4)使用函数srcu_barrier()等待所有回调函数执行完。这个函数可能睡眠。
void srcu_barrier(struct srcu_struct *sp);
用完以后,需要使用函数cleanup_srcu_struct()销毁结构体:
void cleanup_srcu_struct(struct srcu_struct *sp);
可以使用下面的宏定义并且初始化数据类型为srcu_struct的变量:
(1)DEFINE_SRCU(name):定义外部全局变量。
(2)DEFINE_STATIC_SRCU(name):定义静态全局变量或静态局部变量。
使用这两个宏定义的变量,不需要使用函数init_srcu_struct()初始化,也不需要使用函数cleanup_srcu_struct()销毁。
4 总结
RCU 涉及面较广,且经历了长时间发展,实现细节复杂,上述概括了其中几个重要的点,这里再次进行一些总结。
首先 rcu 的使用及运转总共分为四步:
(1)rcu 的同步操作
在写端包括 rcu_call, synchronize_rcu 等同步函数及衍生函数的使用。
在读端包括 rcu_read_lock, rcu_read_unlock 等同步函数及衍生函数的使用。
通过同步 api 触发静默/宽限期的推进等。
(2)rcu 静默期的检测和报告
不同变种的 rcu 的静默期检测和报告些许不同,不过有两个重点触发点:
1)schedule 函数
执行 __schedule 函数时在内部 rcu_note_context_switch 中会触发 rcu_qs 上报静默期。
2)时钟中断
在每个时钟中断 tick 中调用 rcu_check_callbacks 检测静默状态并报告。
在静默期上报中,如果检测到所有的 cpu 都经历了静默期则会调用 rcu_gp_kthread_wake 来唤醒 rcu 线程来清理宽限期现场并且根据 flags 标志来等待启动一个新的宽限期或者立即启动一个新的宽限期。
(3)rcu 宽限期的启动与结束
rcu 在启动初始化阶段会创建 rcu_gp_kthread 线程用于启动新的宽限和结束宽限期。
rcu_gp_kthread-> swait_event_idle 等待启动新的宽限期-> rcu_gp_init 启动新的宽限期-> rcu_gp_fqs_loop 等待宽限期结束-> rcu_gp_cleanup 清理宽限期
(4) rcu 软中断处理注册回调
上述同步操作注册的延时回调,或者等待同步的进程将在这里进行调用和唤醒,当然这里面还有许多rcu工作需要处理。
rcu_head 链表的推进加速
rcu_head 链表根据上述可知在 cblist 中分段存储,以便区分不同宽限期的 rcu_head,note_gp_changes 负责 rcu_head 在区间的推进移动。
其中一个 note_gp_changes 在软中断的 rcu_check_quiescent_state 中进行推进移动。
另一个在 __call_rcu_core 中推进移动,上述的同步 api 如 call_rcu,synchronize_rcu 均有机会调用 note_gp_changes 来推进 rcu_head 的移动。
相关文章:
RCU 使用及机制源码的一些分析
》内核新视界文章汇总《 文章目录 1 介绍2 使用方法2.1 经典 RCU2.2 不可抢占RCU2.3 加速版不可抢占RCU2.4 链表操作的RCU版本2.5 slab 缓存支持RCU 3 源码与实现机制的简单分析3.1 数据结构3.2 不可抢占RCU3.3 加速版不可抢占RCU3.4 可抢占RCU3.5 报告禁止状态3.6 宽限期的开…...

【第二套】Java面试题
第二套: 一、JavaScript前端开发 1、下列的代码输出什么? var y 1; if(function f(){}){y typeof f; } console.log(y);正确的答案应该是 1undefined。 JavaScript中if语句求值其实使用eval函数,eval(function f(){}) 返回 function f()…...

CSS3 实现边框圆角渐变色渐变文字效果
.boder-txt {width: 80px;height: 30px; line-height: 30px;padding: 5px;text-align: center;border-radius: 10px;border: 6rpx solid transparent;background-clip: padding-box, border-box;background-origin: padding-box, border-box;/*第一个linear-gradient表示内填充…...
第二天 kali代理配置
文章目录 环境一、虚拟机网络模式(1)NAT(2)NAT模式(3)桥接模式(4)仅主机模式(5)总结 二、配置代理(桥接模式)1、基础设置2、虚拟机浏览…...
stable-diffusion-webui汉化教程
第一种方法 1.打开stable diffusion webui,进入"Extensions"选项卡 2.点击"Install from URL" 3、注意"URL for extension’s git repository"下方的输入框 4、填入地址:https://github.com/VinsonLaro/stable-diffus…...
热备盘激活失败导致raid5阵列崩溃的服务器数据恢复案例
服务器数据恢复环境: 一台Linux Redhat操作系统服务器上有一组由5块硬盘组建的raid5阵列,包含一块热备盘。上层部署一个OA系统和Oracle数据库。 服务器故障: raid5阵列中的1块磁盘离线,硬盘离线却没有激活热备盘,直到…...
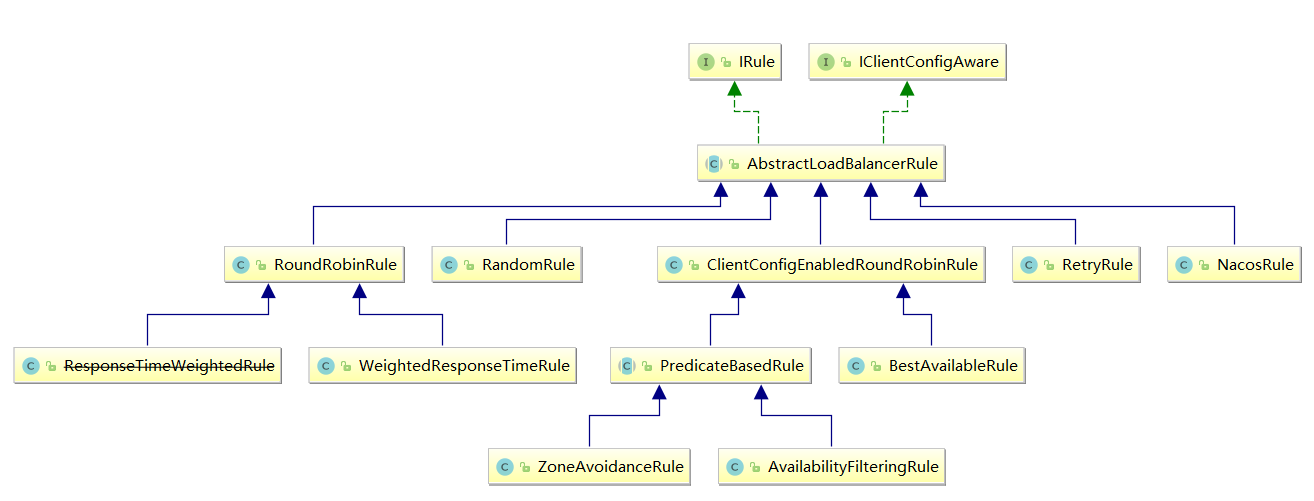
【ribbon】Ribbon的负载均衡和扩展功能
Ribbon的核心接口 参考:org.springframework.cloud.netflix.ribbon.RibbonClientConfiguration IClientConfig:Ribbon的客户端配置,默认采用DefaultClientConfigImpl实现。IRule:Ribbon的负载均衡策略,默认采用ZoneA…...
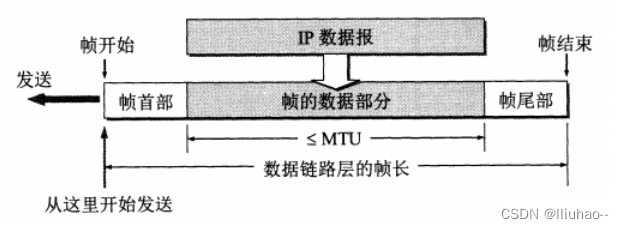
数据链路层是如何传递数据的
数据链路层是如何传递数据的 数据链路层功能概述封装成帧透明传输差错控制 数据链路层功能概述 数据链路层的主要作用就是加强物理层传输原始比特流的功能。其负责将物理层提供的可能出错的物理连接,改造成逻辑上无差错的数据链路。 数据链路层包括三个基本问题&a…...

积分规划:构建全面的会员积分管理系统
在现代私域营销中,会员积分管理系统是提升用户忠诚度和增加用户参与度的关键工具。通过建立全面的会员积分管理系统,企业可以吸引更多用户参与,提高用户活跃度,并在竞争激烈的市场中保持竞争优势。本文将详细介绍如何进行积分规划…...
)
amd的cpu有哪些型号(amd的cpu系列介绍)
1、amd处理器有什么系列? 2、AMD各系列CPU和对应的主板型号有哪些? 3、AMD双核CPU有哪几个型号? amd处理器有什么系列? amd处理器的系列有: 1、锐龙:AMD Ryzen是AMD开发并推出市场的x86微处理器品牌,AMD Zen微架构…...

网络安全(黑客)自学——从0开始
为什么学习黑客知识?有的人是为了耍酷,有的人是为了攻击,更多的人是为了防御。我觉得所有人都应该了解一些安全知识,了解基本的进攻原理。这样才可以更好的保护自己。这也是这系列文章的初衷。让大家了解基本的进攻与防御。 一、怎…...

uniapp使用uni-swipe-action后右侧多了小于1px的间隙
问题:uniapp使用uni-swipe-action后右侧多了小于1px的间隙。且在真机上没有问题,但是在微信开发者工具中有问题。 代码如下:在滑动滑块或者点击这个区域时,就会出现问题。 <scroll-view :scroll-y"true" :style&quo…...

随手笔记——演示如何提取 ORB 特征并进行匹配
随手笔记——演示如何提取 ORB 特征并进行匹配 说明知识点源代码 说明 演示如何提取 ORB 特征并进行匹配 知识点 特征点由关键点(Key-point)和描述子(Descriptor)两部分组成。 ORB 特征亦由关键点和描述子两部分组成。它的关键…...

Python访问者模式介绍、使用
目录 一、Python访问者模式介绍 二、访问者模式使用 一、Python访问者模式介绍 访问者模式(Visitor Pattern)是一种行为型设计模式,它能够将算法与对象结构分离,使得算法可以独立于对象结构而变化。这个模式的主要思想是&#…...

深度学习实际使用经验总结
以下仅是个人在使用过程中的经验总结,请谨慎参考。 常用算法总结 图像分类 常用算法(可作为其他任务的骨干网络):服务端:VGG、ResNet、ResNeXt、DenseNet移动端:MobileNet、ShuffleNet等适用场景&#x…...

【广州华锐互动】AR智慧机房设备巡检系统
AR智慧机房设备巡检系统是一种新型的机房巡检方式,它通过使用增强现实技术将机房设备、环境等信息实时呈现在用户面前,让巡检人员可以更加高效地完成巡检任务。 首先,AR智慧机房设备巡检系统具有极高的智能化程度。该系统可以根据用户设定的…...
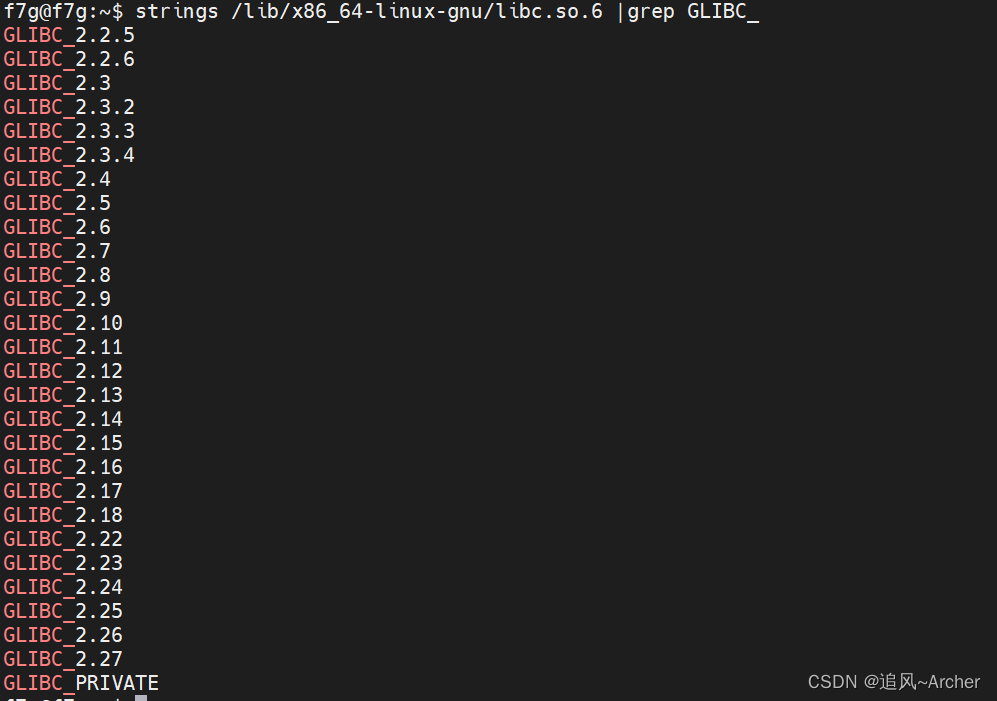
关于Ubuntu 18.04 LTS环境下运行程序出现的问题
关于Ubuntu 18.04 LTS环境下运行程序出现的问题 1.运行程序时出现以下情况 2.检查版本 strings /lib/x86_64-linux-gnu/libc.so.6 |grep GLIBC_ 发现Ubuntu18.04下的glibc版本最高为2.27,而现程序所使用的是glibc2.34,所以没办法运行, 3.解决办法 安装glibc2.34库, …...
「苹果安卓」手机搜狗输入法怎么调整字体大小及键盘高度?
手机搜狗输入法怎么调整字体大小及键盘高度? 1、在手机上准备输入文字,调起使用的搜狗输入法手机键盘; 2、点击搜狗输入法键盘左侧的图标,进入更多功能管理; 3、在搜狗输入法更多功能管理内找到定制工具栏,…...
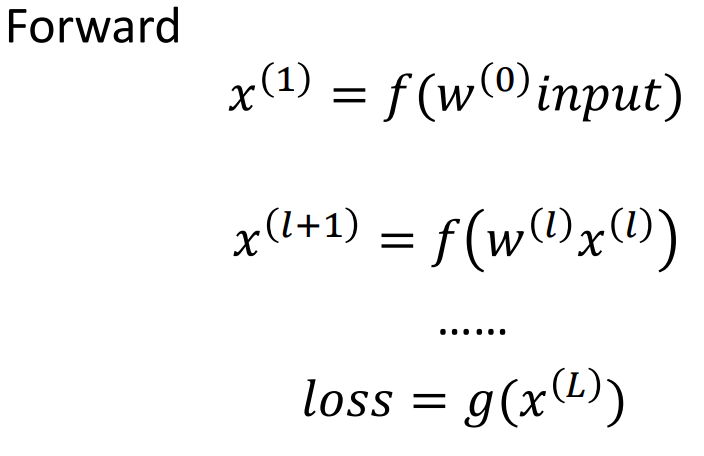
【人工智能】神经网络、前向传播、反向传播、梯度下降、局部最小值、多层前馈网络、缓解过拟合的策略
神经网络、前向传播、反向传播 文章目录 神经网络、前向传播、反向传播前向传播反向传播梯度下降局部最小值多层前馈网络表示能力多层前馈网络局限缓解过拟合的策略前向传播是指将输入数据从输入层开始经过一系列的权重矩阵和激活函数的计算后,最终得到输出结果的过程。在前向…...

一个tomcat部署两个服务的server.xml模板
一个服务的文件夹名字叫hospital,一个服务的文件夹叫ROOT,一个tomcat运行两个服务如何配置呢?注意一个appBase为webapps,另一个appBase为webapps1,当然也可以放在一个webappps里面。 <Service name"Catalina">&l…...

NaViL-9B图文理解教程:从上传图片到获取结构化描述的完整步骤
NaViL-9B图文理解教程:从上传图片到获取结构化描述的完整步骤 1. 认识NaViL-9B多模态模型 NaViL-9B是一款原生支持多模态交互的大语言模型,能够同时处理文本和图像信息。与传统的纯文本模型不同,它可以直接"看懂"图片内容&#x…...
)
别再死记硬背了!用Python+OpenCV动手复现计算机视觉核心算法(边缘检测/图像分割实战)
用PythonOpenCV实战复现计算机视觉核心算法:从理论到代码的跨越 计算机视觉作为人工智能领域最炙手可热的方向之一,其核心算法构成了这门学科的骨架。但很多学习者在掌握理论知识后,面对实际项目仍感到无从下手——公式记住了,原理…...

ai辅助开发,让快马智能生成centos下openclaw安装与配置的疑难解决方案
在CentOS系统上安装和配置OpenClaw这类工具时,经常会遇到各种依赖冲突、环境配置问题,以及需要定制化爬取规则的情况。传统方式下,我们需要手动查阅文档、调试命令,甚至反复尝试不同版本的依赖包,过程相当耗时。而借助…...

别怕C++!手把手拆解TinyML测试框架:用micro_test.h给你的嵌入式AI代码加个‘保险丝’
嵌入式AI开发者的测试实战指南:用micro_test.h构建TinyML质量防线 在资源受限的微控制器上开发AI应用时,一个被反复验证的真理是:没有自动化测试的代码就像没有安全网的走钢丝。当你的神经网络模型需要在仅有几KB内存的设备上运行时ÿ…...
)
手把手教你用TI F28P65X开发板实现LED定时闪烁(基于CPU Timer2,含完整源码)
从零玩转TI F28P65X开发板:CPU Timer2实现可调频LED闪烁实战指南 刚拿到TI F28P65X开发板时,面对密密麻麻的引脚和复杂的开发环境,很多嵌入式新手会感到无从下手。本文将带你用最直观的方式,通过控制LED闪烁这个经典入门项目&…...

云容笔谈在自媒体内容生产中的提效实践:日更国风配图效率提升300%
云容笔谈在自媒体内容生产中的提效实践:日更国风配图效率提升300% 1. 自媒体内容创作的痛点与挑战 作为自媒体创作者,每天最头疼的就是配图问题。特别是做国风内容的账号,既要保持东方美学韵味,又要保证日更频率,传统…...

不止于超市:用QGIS缓冲区+叠置分析,为你的奶茶店、自习室找个好位置
从奶茶店到自习室:QGIS空间分析赋能小微商业选址决策 走在街头,你是否好奇为什么某些奶茶店总是门庭若市,而几步之隔的同类店铺却冷冷清清?商业选址从来不是简单的"地段好"三个字能概括的。对于资金有限的小微创业者来说…...

电源管理入门-5 arm-scmi和mailbox核间通信
上篇介绍了电源管理入门-4子系统reset,提到子系统reset的执行为了安全可以到SCP里面去执行,但是怎么把这个消息传递过去呢,答案就是mailbox。Mailbox是核间通信软硬件的统称。在软件上可以使用SCMI协议共享内存报文头,在硬件上可以…...

别再只会看原理图了!用Multisim仿真带你深入理解运放的“虚短虚断”与反馈
用Multisim仿真破解运放"虚短虚断"的底层逻辑 在电子电路设计中,运算放大器就像一位沉默的魔术师,用"虚短"和"虚断"两个基本概念演绎着各种精妙的信号处理戏法。但很多工程师在学习阶段只是机械记忆这两个术语,…...

『NAS』在绿联部署One API,统一管理你的所有大模型服务
点赞 关注 收藏 学会了 💡整理了一个 NAS 专属玩法专栏,感兴趣的工友可以戳这里关注 👉 《NAS邪修》 One API 是一个开源的接口管理与分发系统,它能将各种大模型的非标接口(如 DeepSeek、Kimi、LongCat 等ÿ…...