rbd快照管理、rbd快照克隆原理与实现、rbd镜像开机自动挂载、ceph文件系统、对象存储、配置对象存储客户端、访问Dashboard
day04
day04快照快照克隆开机自动挂载ceph文件系统使用MDS对象存储配置服务器端配置客户端访问Dashborad
快照
- 快照可以保存某一时间点时的状态数据
- 快照是映像在特定时间点的只读逻辑副本
- 希望回到以前的一个状态,可以恢复快照
- 使用镜像、快照综合示例
# 1. 在rbd存储池中创建10GB的镜像,名为img1
[root@client1 ~]# rbd --help # 查看子命令
[root@client1 ~]# rbd help create # 查看子命令create的帮助
[root@client1 ~]# rbd create img1 --size 10G
[root@client1 ~]# rbd list
img1
[root@client1 ~]# rbd info img1
rbd image 'img1':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: fa91208bfdaf
block_name_prefix: rbd_data.fa91208bfdaf
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sat Dec 17 10:44:17 2022
access_timestamp: Sat Dec 17 10:44:17 2022
modify_timestamp: Sat Dec 17 10:44:17 2022
# 2. 在客户端使用镜像img1,将其挂载到/mnt
[root@client1 ~]# rbd list
img1
[root@client1 ~]# rbd map img1
/dev/rbd0
[root@client1 ~]# mkfs.xfs /dev/rbd0
[root@client1 ~]# mount /dev/rbd0 /mnt/
[root@client1 ~]# rbd showmapped
id pool namespace image snap device
0 rbd img1 - /dev/rbd0
[root@client1 ~]# df -h /mnt/
Filesystem Size Used Avail Use% Mounted on
/dev/rbd0 10G 105M 9.9G 2% /mnt
# 3. 向/mnt中写入数据
[root@client1 ~]# cp /etc/hosts /mnt/
[root@client1 ~]# cp /etc/passwd /mnt/
[root@client1 ~]# ls /mnt/
hosts passwd
# 4. 创建img1的快照,名为img1-sn1
[root@client1 ~]# rbd snap create img1 --snap img1-sn1
Creating snap: 100% complete...done.
[root@client1 ~]# rbd snap ls img1
SNAPID NAME SIZE PROTECTED TIMESTAMP
4 img1-sn1 10 GiB Sat Dec 17 10:46:07 2022
# 5. 删除/mnt/中的数据
[root@client1 ~]# rm -f /mnt/*
# 6. 通过快照还原数据
[root@client1 ~]# umount /mnt/
[root@client1 ~]# rbd unmap /dev/rbd0
[root@client1 ~]# rbd help snap rollback # 查看子命令帮助
# 回滚img1到快照img1-sn1
[root@client1 ~]# rbd snap rollback img1 --snap img1-sn1
# 重新挂载
[root@client1 ~]# rbd map img1
/dev/rbd0
[root@client1 ~]# mount /dev/rbd0 /mnt/
[root@client1 ~]# ls /mnt/ # 数据还原完成
hosts passwd
- 保护快照,防止删除
[root@client1 ~]# rbd help snap protect
# 保护镜像img1的快照img1-sn1
[root@client1 ~]# rbd snap protect img1 --snap img1-sn1
[root@client1 ~]# rbd snap rm img1 --snap img1-sn1 # 不能删
- 删除操作
# 1. 取消对快照的保护
[root@client1 ~]# rbd snap unprotect img1 --snap img1-sn1
# 2. 删除快照
[root@client1 ~]# rbd snap rm img1 --snap img1-sn1
# 3. 卸载块设备
[root@client1 ~]# umount /dev/rbd0
# 4. 取消映射
[root@client1 ~]# rbd unmap img1
# 5. 删除镜像
[root@client1 ~]# rbd rm img1
快照克隆
- 不能将一个镜像同时挂载到多个节点,如果这样操作,将会损坏数据
- 如果希望不同的节点,拥有完全相同的数据盘,可以使用克隆技术
- 克隆是基于快照的,不能直接对镜像克隆
- 快照必须是受保护的快照,才能克隆
- 克隆流程
创建
保护
克隆
镜像
快照
受保护的快照
克隆的镜像
- 给多个客户端生成数据相同的数据盘
# 1. 创建名为img2的镜像,大小10GB
[root@client1 ~]# rbd create img2 --size 10G
# 2. 向镜像中写入数据
[root@client1 ~]# rbd map img2
/dev/rbd0
[root@client1 ~]# mkfs.xfs /dev/rbd0
[root@client1 ~]# mount /dev/rbd0 /mnt/
[root@client1 ~]# for i in {1..20}
> do
> echo "Hello World $i" > /mnt/file$i.txt
> done
[root@client1 ~]# ls /mnt/
file10.txt file15.txt file1.txt file5.txt
file11.txt file16.txt file20.txt file6.txt
file12.txt file17.txt file2.txt file7.txt
file13.txt file18.txt file3.txt file8.txt
file14.txt file19.txt file4.txt file9.txt
# 3. 卸载镜像
[root@client1 ~]# umount /mnt/
[root@client1 ~]# rbd unmap img2
# 4. 为img2创建名为img2-sn1快照
[root@client1 ~]# rbd snap create img2 --snap img2-sn1
# 5. 保护img2-sn1快照
[root@client1 ~]# rbd snap protect img2 --snap img2-sn1
# 6. 通过受保护的快照img2-sn1创建克隆镜像
[root@client1 ~]# rbd clone img2 --snap img2-sn1 img2-sn1-1
[root@client1 ~]# rbd clone img2 --snap img2-sn1 img2-sn1-2
# 7. 查看创建出来的、克隆的镜像
[root@client1 ~]# rbd ls
img2
img2-sn1-1
img2-sn1-2
# 8. 不同的客户端挂载不同的克隆镜像,看到的是相同的数据
[root@client1 ~]# rbd map img2-sn1-1
/dev/rbd0
[root@client1 ~]# mkdir /data
[root@client1 ~]# mount /dev/rbd0 /data
[root@client1 ~]# ls /data
file10.txt file15.txt file1.txt file5.txt
file11.txt file16.txt file20.txt file6.txt
file12.txt file17.txt file2.txt file7.txt
file13.txt file18.txt file3.txt file8.txt
file14.txt file19.txt file4.txt file9.txt
[root@ceph1 ~]# yum install -y ceph-common
[root@ceph1 ~]# rbd map img2-sn1-2
/dev/rbd0
[root@ceph1 ~]# mkdir /data
[root@ceph1 ~]# mount /dev/rbd0 /data/
[root@ceph1 ~]# ls /data/
file10.txt file15.txt file1.txt file5.txt
file11.txt file16.txt file20.txt file6.txt
file12.txt file17.txt file2.txt file7.txt
file13.txt file18.txt file3.txt file8.txt
file14.txt file19.txt file4.txt file9.txt
- 查询镜像和快照
# 查看快照信息
[root@client1 ~]# rbd info img2 --snap img2-sn1
rbd image 'img2':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 1
id: d46eed84bb61
block_name_prefix: rbd_data.d46eed84bb61
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sat Dec 17 10:58:05 2022
access_timestamp: Sat Dec 17 10:58:05 2022
modify_timestamp: Sat Dec 17 10:58:05 2022
protected: True # 受保护
# 查看克隆的快照
[root@client1 ~]# rbd info img2-sn1-2
rbd image 'img2-sn1-2':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: d48fe3d6559e
block_name_prefix: rbd_data.d48fe3d6559e
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sat Dec 17 10:59:53 2022
access_timestamp: Sat Dec 17 10:59:53 2022
modify_timestamp: Sat Dec 17 10:59:53 2022
parent: rbd/img2@img2-sn1 # 父对象是rbd池中img2镜像的img2-sn1快照
overlap: 10 GiB
-
合并父子镜像
- img2-sn1-2是基于img2的快照克隆来的,不能独立使用。
- 如果父镜像删除了,子镜像也无法使用。
- 将父镜像内容合并到子镜像中,子镜像就可以独立使用了。
# 把img2的数据合并到子镜像img2-sn1-2中
[root@client1 ~]# rbd flatten img2-sn1-2
# 查看状态,它就没有父镜像了
[root@client1 ~]# rbd info img2-sn1-2
rbd image 'img2-sn1-2':
size 10 GiB in 2560 objects
order 22 (4 MiB objects)
snapshot_count: 0
id: d48fe3d6559e
block_name_prefix: rbd_data.d48fe3d6559e
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
op_features:
flags:
create_timestamp: Sat Dec 17 10:59:53 2022
access_timestamp: Sat Dec 17 10:59:53 2022
modify_timestamp: Sat Dec 17 10:59:53 2022
# 删除父镜像,如果镜像正在被使用,则先取消
[root@client1 ~]# umount /data/
[root@client1 ~]# rbd unmap img2-sn1-1
# 1. 删除镜像img2-sn1-1
[root@client1 ~]# rbd rm img2-sn1-1
# 2. 取消img2-sn1的保护
[root@client1 ~]# rbd snap unprotect img2 --snap img2-sn1
# 3. 删除img2-sn1快照
[root@client1 ~]# rbd snap rm img2 --snap img2-sn1
# 4. 删除img2
[root@client1 ~]# rbd rm img2
# 因为img2-sn1-2已经是独立的镜像了,所以它还可以使用
# ceph1上的镜像没有受到影响
[root@ceph1 ~]# cat /data/file1.txt
Hello World 1
开机自动挂载
# 1. 准备镜像
[root@client1 ~]# rbd create img1 --size 10G
[root@client1 ~]# rbd map img1
/dev/rbd0
[root@client1 ~]# mkfs.xfs /dev/rbd0
# 2. 设置开机自动挂载
[root@client1 ~]# vim /etc/ceph/rbdmap # 指定要挂载的镜像及用户名、密钥
rbd/img1 id=admin,keyring=/etc/ceph/ceph.client.admin.keyring
[root@client1 ~]# vim /etc/fstab # 追加
/dev/rbd/rbd/img1 /data xfs noauto 0 0
# noauto的意思是,等rbdmap服务启动后,再执行挂载
# 3. 启动rbdmap服务
[root@client1 ~]# systemctl enable rbdmap --now
# 4. reboot后查看结果
[root@client1 ~]# df -h /data/
Filesystem Size Used Avail Use% Mounted on
/dev/rbd0 10G 105M 9.9G 2% /data
ceph文件系统
- 文件系统:相当于是组织数据存储的方式。
- 格式化时,就是在为存储创建文件系统。
- Linux对ceph有很好的支持,可以把ceph文件系统直接挂载到本地。
- 要想实现文件系统的数据存储方式,需要有MDS组件
使用MDS
-
元数据就是描述数据的属性。如属主、属组、权限等。
-
ceph文件系统中,数据和元数据是分开存储的
-
新建存储池
- 归置组PG:存储池包含PG。PG是一个容器,用于存储数据。
- 为了管理方便,将数量众多的数据放到不同的PG中管理,而不是直接把所有的数据扁平化存放。
- 通常一个存储池中创建100个PG。
-
创建ceph文件系统
# 1. 新建一个名为data1的存储池,目的是存储数据,有100个PG
[root@client1 ~]# ceph osd pool create data01 100
# 2. 新建一个名为metadata1的存储池,目的是存储元数据
[root@client1 ~]# ceph osd pool create metadata01 100
# 3. 创建名为myfs1的cephfs,数据保存到data1中,元数据保存到metadata1中
[root@client1 ~]# ceph fs new myfs01 metadata01 data01
# 4. 查看存储池
[root@client1 ~]# ceph osd lspools
1 .mgr
2 rbd
3 data01
4 metadata01
[root@client1 ~]# ceph df
--- RAW STORAGE ---
CLASS SIZE AVAIL USED RAW USED %RAW USED
hdd 180 GiB 180 GiB 206 MiB 206 MiB 0.11
TOTAL 180 GiB 180 GiB 206 MiB 206 MiB 0.11
--- POOLS ---
POOL ID PGS STORED OBJECTS USED %USED MAX AVAIL
.mgr 1 1 449 KiB 2 1.3 MiB 0 57 GiB
rbd 2 32 7.1 MiB 43 22 MiB 0.01 57 GiB
data01 3 94 0 B 0 0 B 0 57 GiB
metadata01 4 94 0 B 0 0 B 0 57 GiB
# 5. 查看文件系统
[root@client1 ~]# ceph fs ls
name: myfs01, metadata pool: metadata01, data pools: [data01 ]
# 6. 启动MDS服务
[root@client1 ~]# ceph orch apply mds myfs01 --placement="2 ceph1 ceph2"
# 7. 查看部署结果
[root@client1 ~]# ceph -s
cluster:
id: a4b69ab4-79dd-11ed-ae7b-000c2953b002
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1,ceph3,ceph2 (age 92m)
mgr: ceph1.gmqorm(active, since 92m), standbys: ceph3.giqaph
mds: 1/1 daemons up, 1 standby # mds服务信息
osd: 9 osds: 9 up (since 92m), 9 in (since 4d)
...略...
- 客户端使用cephfs
# 挂载文件系统需要密码。查看密码
[root@client1 ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQBmhINh1IZjHBAAvgk8m/FhyLiH4DCCrnrdPQ==
# -t 指定文件系统类型。-o是选项,提供用户名和密码
[root@client1 ~]# mkdir /mydata
[root@client1 ~]# mount.ceph 192.168.88.13:/ /mydata -o name=admin,secret=AQC5u5ZjnTA1ERAAruLAI8F1W1nyOgxZSx0UXw==
[root@client1 ~]# df -h /mydata/
Filesystem Size Used Avail Use% Mounted on
192.168.88.13:/ 57G 0 57G 0% /mydata
对象存储
配置服务器端
- 需要专门的客户端访问
- 键值对存储方式
- 对象存储需要rgw组件
- 安装部署
# 1. 在ceph1/ceph2上部署rgw服务,名为myrgw
[root@client1 ~]# ceph orch apply rgw myrgw --placement="2 ceph1 ceph2" --port 8080
[root@client1 ~]# ceph -s
cluster:
id: a4b69ab4-79dd-11ed-ae7b-000c2953b002
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph1,ceph3,ceph2 (age 101m)
mgr: ceph1.gmqorm(active, since 6h), standbys: ceph3.giqaph
mds: 1/1 daemons up, 1 standby
osd: 9 osds: 9 up (since 6h), 9 in (since 5d); 1 remapped pgs
rgw: 2 daemons active (2 hosts, 1 zones) # rgw信息
...略...
配置客户端
- ceph对象存储提供了一个与亚马逊S3(Amazon Simple Storage Service)兼容的接口
- 在S3中,对象被存储在一个称作桶(bucket)的器皿中。这就好像是本地文件存储在目录中一样。
# 1. 安装amazon S3 cli工具(客户端工具)
[root@client1 ~]# yum install -y awscli
# 2. 在ceph中创建一个用户
[root@client1 ~]# radosgw-admin user create --uid=testuser --display-name="Test User" --email=test@tedu.cn --access-key=12345 --secret=67890
# 3. 初始化客户端
[root@client1 ~]# aws configure --profile=ceph
AWS Access Key ID [None]: 12345
AWS Secret Access Key [None]: 67890
Default region name [None]: # 回车
Default output format [None]: # 回车
# 4. 创建名为testbucket的bucket,用于存储数据
[root@client1 ~]# vim /etc/hosts # 添加以下内容
192.168.88.11 ceph1
192.168.88.12 ceph2
192.168.88.13 ceph
[root@client1 ~]# aws --profile=ceph --endpoint=http://ceph1:8080 s3 mb s3://testbucket
# 5. 上传文件
[root@client1 ~]# aws --profile=ceph --endpoint=http://ceph1:8080 --acl=public-read-write s3 cp /etc/hosts s3://testbucket/hosts.txt
# 6. 查看bucket中的数据
[root@client1 ~]# aws --profile=ceph --endpoint=http://ceph1:8080 s3 ls s3://testbucket
2022-12-17 17:05:58 241 hosts.txt
# 7. 下载数据
[root@client1 ~]# wget -O zhuji http://ceph1:8080/testbucket/hosts.txt
访问Dashborad
- 通过浏览器访问
https://192.168.88.11:8443,用户名为admin,密码是安装时指定的123456。
知识点思维导图:FlowUs 息流 - 新一代生产力工具
相关文章:

rbd快照管理、rbd快照克隆原理与实现、rbd镜像开机自动挂载、ceph文件系统、对象存储、配置对象存储客户端、访问Dashboard
day04 day04快照快照克隆开机自动挂载ceph文件系统使用MDS对象存储配置服务器端配置客户端访问Dashborad 快照 快照可以保存某一时间点时的状态数据快照是映像在特定时间点的只读逻辑副本希望回到以前的一个状态,可以恢复快照使用镜像、快照综合示例 # 1. 在rbd存…...

vue、vuex、vue-router初学导航配合elementui及vscode快捷键
目录 一、vue资源 1.vue知识库汇总 2.vuejs组件 3.Vue.js 组件编码规范 目标 #目录 #基于模块开发...
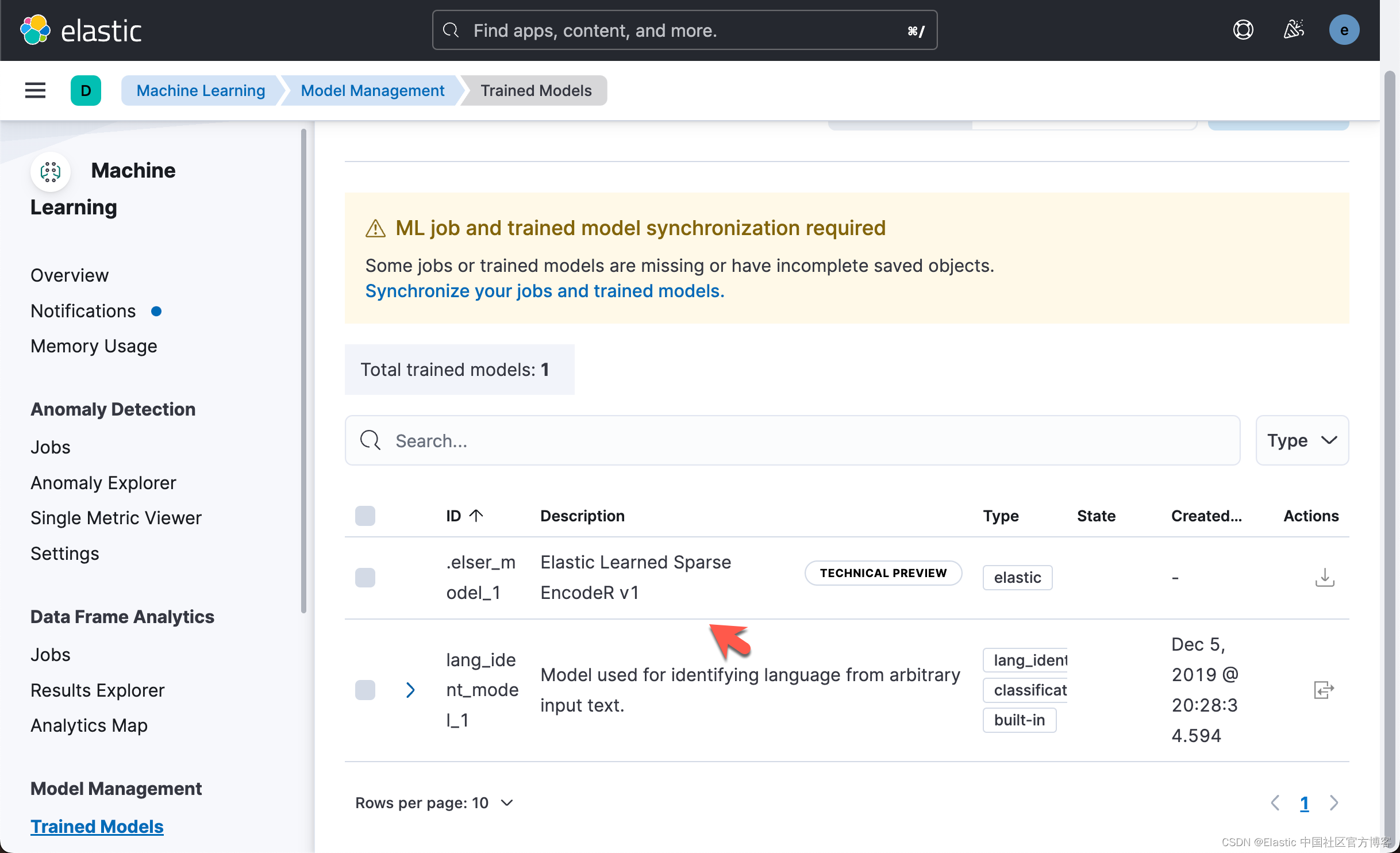
Elasticsearch:使用 ELSER 释放语义搜索的力量:Elastic Learned Sparse EncoderR
问题陈述 在信息过载的时代,根据上下文含义和用户意图而不是精确的关键字匹配来查找相关搜索结果已成为一项重大挑战。 传统的搜索引擎通常无法理解用户查询的语义上下文,从而导致相关性较低的结果。 解决方案:ELSER Elastic 通过其检索模型…...
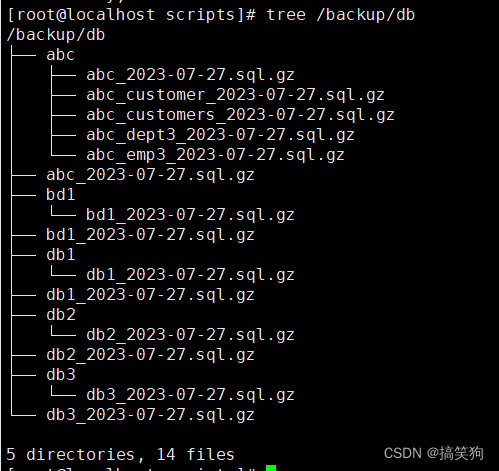
MySQL数据库分库分表备份(shell脚本)
创建目录 mkdir /server/scripts 一、使用脚本实现分库备份 1、创建脚本并编写 [rootlocalhost scripts]# vim bak_db_v1.sh #!/bin/bash ######################################### # File Name:bak_db_v1.sh # Version: V1.0 # Author:Shen QL # Email:17702390000163.co…...

建造者设计模式go实现尝试
文章目录 前言代码结果总结 前言 本文章尝试使用go实现“建造者”。 代码 package mainimport ("fmt" )// 产品1。可以有不同的毫无相关的产品,这里只举一个 type Product1 struct {parts []string }// 产品1逻辑。打印组成产品的部分 func (p *Product…...

创建交互式用户体验:探索JavaScript中的Prompt功能
使用JavaScript中的Prompt功能:创建交互式用户体验 在前端开发中,JavaScript的prompt()函数是一个强大而有用的工具,它可以创建交互式的用户体验。无论是接收用户输入、进行简单的验证还是实现高级的交互功能,prompt()函数都能胜…...
-[提示模板:基础知识])
自然语言处理从入门到应用——LangChain:提示(Prompts)-[提示模板:基础知识]
分类目录:《自然语言处理从入门到应用》总目录 语言模型以文本作为输入,这段文本通常被称为提示(Prompt)。通常情况下,这不仅仅是一个硬编码的字符串,而是模板、示例和用户输入的组合。LangChain提供了多个…...

OpenPCDet调试出现的问题
Open3d遇到的问题,解决方案 1.ModuleNotFoundError: No module named ‘pcdet’ 原因:没有编译安装pcdet。 解决:进入openpcdet项目根目录,修改setup.py权限,并编译: sudo chmod 777 setup.py python set…...
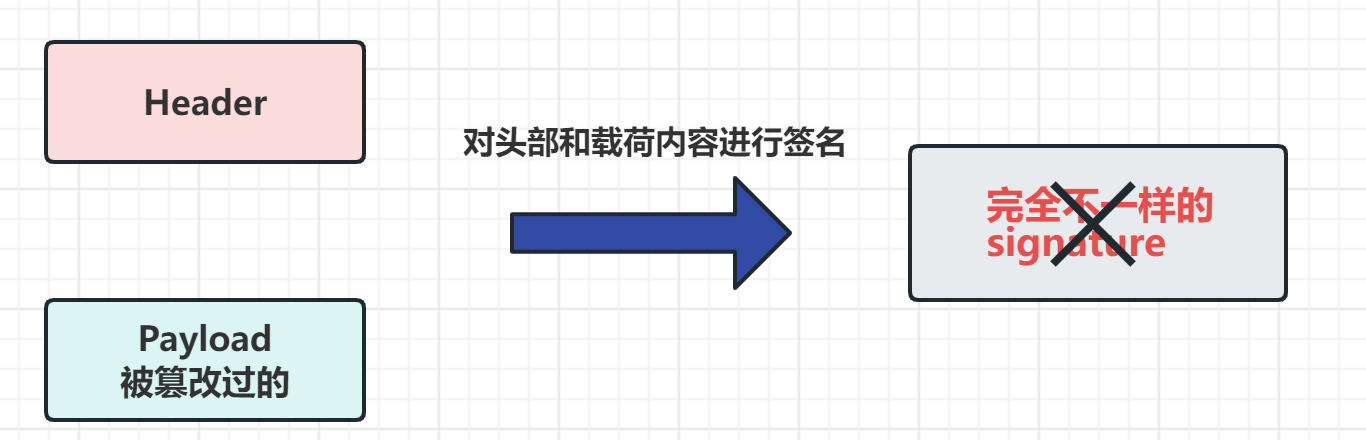
【业务功能篇58】Springboot + Spring Security 权限管理 【下篇】
4.2.2.3 SpringSecurity工作流程分析 SpringSecurity的原理其实就是一个过滤器链,内部包含了提供各种功能的过滤器。这里我们可以看看入门案例中的过滤器。 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KjoRRost-1690534711077)(http…...

VBA技术资料MF34:检查Excel自动筛选是否打开
【分享成果,随喜正能量】聪明人,抬人不抬杠;傻子,抬杠不抬人。聪明人,把别人抬得很高,别人高兴、舒服了,看你顺眼了,自然就愿意帮你!而傻人呢?不分青红皂白&a…...

spring扩展点
在Spring框架中,有多个扩展点(Extension Point)可用于自定义和扩展应用程序的行为。这些扩展点允许开发人员介入Spring的生命周期和行为,并提供了灵活性和可定制性。以下是一些常见的Spring扩展点: BeanPostProcessor&…...

Skin Shader 使用自动生成的Thickness
Unity2023.2的版本,Thickness 自动化生成,今天测试了一把,确实不错。 1.Render 设置 在Project Settings->Graphics->HDRP Global Settings中 Frame Setting->Rendering->Compute Thickness 打开 2.Layer设置 2.1添加Layer&…...
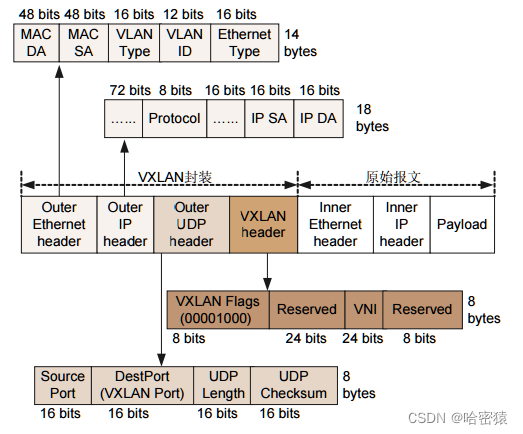
Docker中的网络
文章目录 网络网桥(bridge)创建网桥接口hostnonecontaineroverlayoverlay底层原理 网络 网桥(bridge) 在Docker中,网桥(Bridge)是一种网络驱动,用于实现Docker容器之间和容器与宿主…...

SRS开源代码框架,协程库state-threads的使用
本章内容解读SRS开源代码框架,无二次开发,以学习交流为目的。 SRS是国人开发的流媒体服务器,C语言开发,本章使用版本:https://github.com/ossrs/srs/tree/5.0release。 目录 SRS协程库ST的使用源码ST协程库测试SrsAut…...
【QT 网络云盘客户端】——登录界面功能的实现
目录 1.注册账号 2.服务器ip地址和端口号设置 3. 登录功能 4.读取配置文件 5.显示主界面 1.注册账号 1.点击注册页面,将数据 输入 到 用户名,昵称,密码,确认密码,手机,邮箱 的输入框中, 点…...

【复盘与分享】第十一届泰迪杯B题:产品订单的数据分析与需求预测
文章目录 题目第一问第二问2.1 数据预处理2.2 数据集分析2.2.1 训练集2.2.2 预测集 2.3 特征工程2.4 模型建立2.4.1 模型框架和评价指标2.4.2 模型建立2.4.3 误差分析和特征筛选2.4.4 新品模型 2.5 模型融合2.6 预测方法2.7 总结 结尾 距离比赛结束已经过去两个多月了。 整个过…...
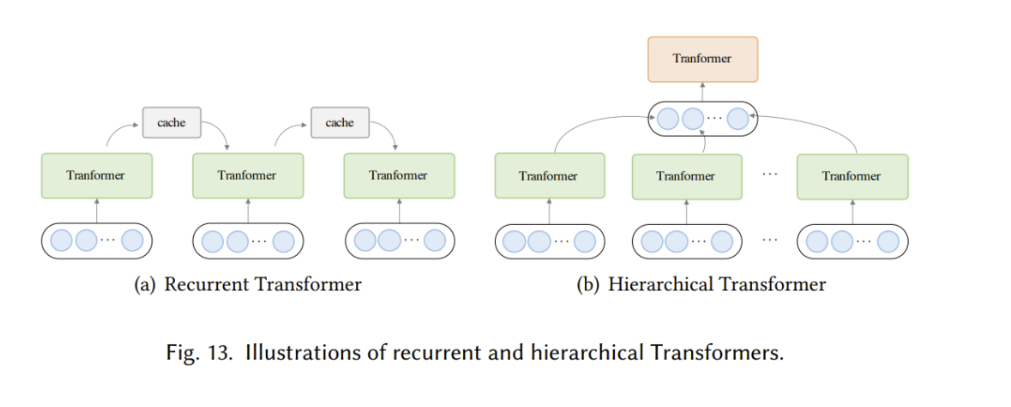
X - Transformer
回顾 Transformer 的发展 Transformer 最初是作为机器翻译的序列到序列模型提出的,而后来的研究表明,基于 Transformer 的预训练模型(PTM) 在各项任务中都有最优的表现。因此,Transformer 已成为 NLP 领域的首选架构&…...
ubuntu下畅玩Seer(via wine)
第一步:安装wine 部分exe文件的运行需要32位的指令集架构,需要向Ubuntu系统中添加一个新的架构(i386),以支持32位的软件包。因为在64位的Ubuntu系统中,默认情况下只能安装和运行64位的软件。 通过添加i386…...

第五章:Spring下
第五章:Spring下 5.1:AOP 场景模拟 创建一个新的模块,spring_proxy_10,并引入下面的jar包。 <packaging>jar</packaging><dependencies><dependency><groupId>junit</groupId><artifactI…...
)
在CSDN学Golang云原生(Kubernetes基础)
一,k8s集群安装和升级 安装 Golang K8s 集群可以参照以下步骤: 准备环境:需要一组 Linux 服务器,并在每台服务器上安装 Docker 和 Kubernetes 工具。初始化集群:使用 kubeadm 工具初始化一个 Kubernetes 集群。例如&…...

智能检索新范式,让AIAgent自主决策,提升RAG效率100%!
市面上的 RAG 系统,不管叫什么名字,本质上只有两种做法: 第一种,一次性检索。把用户的 query 向量化,从语料库里捞出 Top-K 个文档片段,拼成一个大 prompt 塞给模型。GraphRAG、HippoRAG、LightRAG 都属于…...

基于LM22678的树莓派硬盘专用电源设计:解决供电不稳与电流冲击
1. 项目概述:为什么我们需要一个“专用”电源?如果你正在用树莓派搭配一块机械硬盘搭建一个家庭服务器或者个人云存储,可能已经遇到了一个不大不小的麻烦:供电不稳。树莓派官方推荐的5V/3A电源,单独带树莓派4B跑满负载…...

13456
12356...
)
37家金融客户紧急启用的DeepSeek扫描辅助加固包(含未公开API调用密钥策略)
更多请点击: https://kaifayun.com 第一章:DeepSeek漏洞扫描辅助的背景与战略价值 近年来,大模型在安全领域的应用正从辅助问答向深度协同防御演进。DeepSeek系列模型凭借其开源、高推理精度及强代码理解能力,成为构建智能化漏洞…...

机器学习驱动储氢材料发现:从特征工程到DFT/MD验证的完整指南
1. 项目概述与核心思路氢能被视为未来清洁能源体系的关键一环,但如何安全、高效、经济地储存氢气,一直是制约其大规模应用的瓶颈。在众多储氢技术路线中,固态储氢,特别是基于金属氢化物的储氢材料,因其高体积储氢密度和…...

MobX社区资源大全:10个必备工具、插件和扩展库推荐 [特殊字符]
MobX社区资源大全:10个必备工具、插件和扩展库推荐 🚀 【免费下载链接】MobX-Docs-CN MobX 中文文档 项目地址: https://gitcode.com/gh_mirrors/mo/MobX-Docs-CN MobX作为一个简单、可扩展的状态管理库,已经成为React开发者不可或缺的…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行
3个步骤彻底解决WSA安装失败问题:从错误代码到完美运行 【免费下载链接】WSABuilds Run Windows Subsystem For Android on your Windows 10 and Windows 11 PC using prebuilt binaries with Google Play Store (MindTheGapps) and/or Magisk or KernelSU (root so…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版
PS5 NOR Modifier深度解析:如何通过Windows工具修复PS5硬件故障与实现光驱版转数字版 【免费下载链接】PS5NorModifier The PS5 Nor Modifier is an easy to use Windows based application to rewrite your PS5 NOR file. This can be useful if your NOR is corru…...