[NLP]使用Alpaca-Lora基于llama模型进行微调教程
Stanford Alpaca 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。
[NLP]理解大型语言模型高效微调(PEFT)
因此, Alpaca-Lora 则是利用 Lora 技术,在冻结原模型 LLaMA 参数的情况下,通过往模型中加入额外的网络层,并只训练这些新增的网络层参数。由于这些新增参数数量较少,这样不仅微调的成本显著下降,还能获得和全模型微调(full fine-tuning)类似的效果。
LoRA 的原理其实并不复杂,它的核心思想是在原始预训练语言模型旁边增加一个旁路,做一个降维再升维的操作,来模拟所谓的 intrinsic rank(预训练模型在各类下游任务上泛化的过程其实就是在优化各类任务的公共低维本征(low-dimensional intrinsic)子空间中非常少量的几个自由参数)。训练的时候固定预训练语言模型的参数,只训练降维矩阵 A 与升维矩阵 B。而模型的输入输出维度不变,输出时将 BA 与预训练语言模型的参数叠加。用随机高斯分布初始化 A,用 0 矩阵初始化 B。这样能保证训练开始时,新增的通路BA=0从,而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以,只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原始预训练语言模型的W即可,不会增加额外的计算资源。
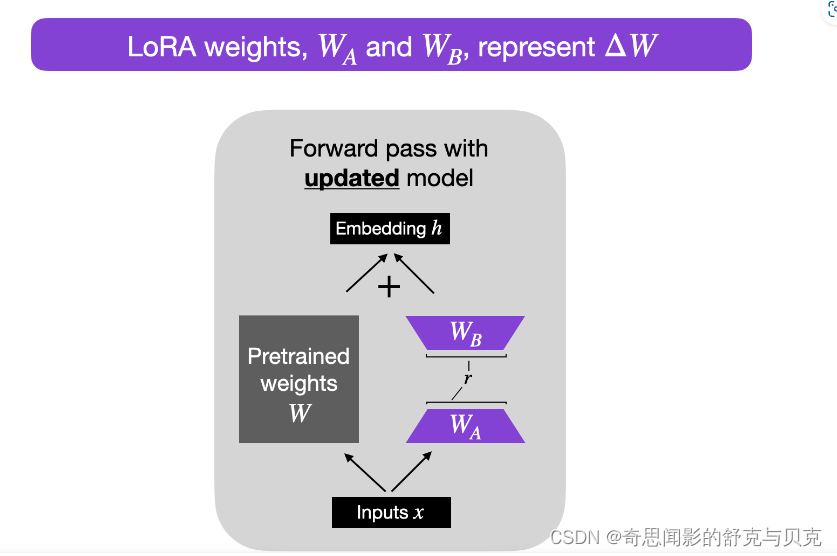
LoRA 的最大优势是速度更快,使用的内存更少;因此,可以在消费级硬件上运行。
准备数据集
fine-tune 的目标通常有两种:
- 像 Alpaca 一样,收集 input/output 生成 prompt 用于训练,让模型完成特定任务
- 语言填充,收集文本用于训练,让模型补全 prompt。
以第一种目标为例,假设我们的目标是让模型讲中文,那么,我们可以通过其他 LLM (如 text-davinci-003)把一个现有数据集(如 Alpaca)翻译为中文来做 fine-tune。实际上这个想法已经在开源社区已经有人实现了。
为了达成这个目标,我使用的数据集是 Luotuo 作者翻译的 Alpaca 数据集,训练代码主要来自 Alpaca-LoRA。
wget https://github.com/LC1332/Chinese-alpaca-lora/blob/main/data/trans_chinese_alpaca_data.jsonAlpach-LoRA 目录中也包含fine-tune的English数据集:

除此之外,可参考GPT-4-LLM项目,该项目还提供了使用Alpaca的Prompt翻译成中文使用 GPT4 生成了 5.2 万条指令跟随数据。
一 环境搭建
基础环境配置如下:
- 操作系统: CentOS 7
- CPUs: 单个节点具有 1TB 内存的 Intel CPU,物理CPU个数为64,每颗CPU核数为16
- GPUs: 4 卡 A100 80GB GPU
- Docker Image: pytorch:1.13.0-cuda11.6-cudnn8-devel
1.在 Alpaca-LoRA 项目中,作者提到,他们使用了 Hugging Face 的 PEFT。PEFT 是一个库(LoRA 是其支持的技术之一,除此之外还有Prefix Tuning、P-Tuning、Prompt Tuning),可以让你使用各种基于 Transformer 结构的语言模型进行高效微调。下面安装PEFT。
#安装peft
git clone https://github.com/huggingface/peft.git
cd peft/
pip install .2. bitsandbytes是对CUDA自定义函数的轻量级封装
特别是针对8位优化器、矩阵乘法(LLM.int8())和量化函数。
#安装bitsandbytes。
git clone git@github.com:TimDettmers/bitsandbytes.git
cd bitsandbytes
CUDA_VERSION=116 make cuda11x
python setup.py install如果安装 bitsandbytes出现如下错误: /usr/bin/ld: cannot find -lcudart
请行执行如下命令
cd /usr/lib
ln -s /usr/local/cuda/lib64/libcudart.so libcudart.so3.Alpaca-Lora微调代码
#下载alpaca-lora
git clone git@github.com:tloen/alpaca-lora.git
cd alpaca-lora
pip install -r requirements.txtrequirements.txt文件具体的内容如下:
accelerate
appdirs
loralib
bitsandbytes
black
black[jupyter]
datasets
fire
git+https://github.com/huggingface/peft.git
transformers>=4.28.0
sentencepiece
gradio二 模型格式转换
将LLaMA原始权重文件转换为Transformers库对应的模型文件格式。可以直接从Hugging Face下载转换好的模型如下:
下载方法可以参考:[NLP]Huggingface模型/数据文件下载方法
decapoda-research/llama-7b-hf · Hugging Face
decapoda-research/llama-13b-hf · Hugging Face
三 模型微调
Alpaca Lora 作者采用了 Hugging Face 的轻量化微调库(Parameter Efficient Fine-Tuning,PEFT)中所支持的 LoRA 方法。LoRA 方法的两项配置会直接影响需要训练的参数量:
1)LoRA 目标模块(lora_target_modules),用于指定要对哪些模块的参数进行微调。比如我们可以对 Q, K, V, O 都进行微调;也可以只对 Q、V 进行微调。不同的设定会影响需要微调的参数量,也会影响训练过程中的计算量。比如当我们设定只对 Q、V 进行微调时,需要训练的参数量(trainable parameters)只占整个模型参数总量的 6% 左右。
2)LoRA 的秩(lora_r)也是影响训练参数量的一个重要因素。客观来说,使用 LoRA 这样的方法训练得到的模型,在效果上必然会和直接在原始大模型基础上进行训练的效果有一定差异。因此,可以结合所拥有的机器配置、可以容忍的最大训练时长等因素,来灵活地配置 LoRA 的使用方法。
python finetune.py \--base_model '/disk1/llama-13b' \--data_path './alpaca_data_cleaned_archive.json' \--output_dir './lora-alpaca' \--batch_size 128 \--micro_batch_size 8 \--num_epochs 1torchrun --nproc_per_node=4 --master_port=29000 finetune.py \--base_model '/disk1/llama-13b' \--data_path './alpaca_data_cleaned_archive.json' \--output_dir './lora-alpaca' \--batch_size 128 \--micro_batch_size 8 \--num_epochs 1Training Alpaca-LoRA model with params:
base_model: /disk1/llama-13b
data_path: ./alpaca_data_cleaned_archive.json
output_dir: ./lora-alpaca
batch_size: 128
micro_batch_size: 8
num_epochs: 1
learning_rate: 0.0003
cutoff_len: 256
val_set_size: 2000
lora_r: 8
lora_alpha: 16
lora_dropout: 0.05
lora_target_modules: ['q_proj', 'v_proj']
train_on_inputs: True
add_eos_token: False
group_by_length: False
wandb_project:
wandb_run_name:
wandb_watch:
wandb_log_model:
resume_from_checkpoint: False
prompt template: alpacaLoading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
Loading checkpoint shards: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:43<00:00, 1.06s/it]
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.warnings.warn(
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.warnings.warn(
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.warnings.warn(
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
/opt/conda/lib/python3.9/site-packages/peft/utils/other.py:102: FutureWarning: prepare_model_for_int8_training is deprecated and will be removed in a future version. Use prepare_model_for_kbit_training instead.warnings.warn(
trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 3%|███▊ | 1330/49759 [00:01<00:39, 1216.23 examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 0%| | 0/49759 [00:00<?, ? examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 1%|▊ | 272/49759 [00:00<00:36, 1350.21 examples/s]trainable params: 6,553,600 || all params: 13,022,417,920 || trainable%: 0.05032552357220002
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1294.31 examples/s]
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1284.04 examples/s]
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:38<00:00, 1283.95 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1221.03 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49759/49759 [00:39<00:00, 1274.42 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1285.16 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1281.27 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 2000/2000 [00:01<00:00, 1290.31 examples/s]
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).
[W socket.cpp:601] [c10d] The client socket cannot be initialized to connect to [localhost]:29005 (errno: 97 - Address family not supported by protocol).0%| | 0/388 [00:00<?, ?it/s]/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantizationwarnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantizationwarnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantizationwarnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
/opt/conda/lib/python3.9/site-packages/bitsandbytes-0.41.0-py3.9.egg/bitsandbytes/autograd/_functions.py:322: UserWarning: MatMul8bitLt: inputs will be cast from torch.float32 to float16 during quantizationwarnings.warn(f"MatMul8bitLt: inputs will be cast from {A.dtype} to float16 during quantization")
{'loss': 2.249, 'learning_rate': 2.9999999999999997e-05, 'epoch': 0.03}
{'loss': 2.1927, 'learning_rate': 5.6999999999999996e-05, 'epoch': 0.05}
{'loss': 2.0813, 'learning_rate': 7.8e-05, 'epoch': 0.08}
{'loss': 1.7206, 'learning_rate': 0.00010799999999999998, 'epoch': 0.1} 11%|████████████████▋ 11%|███████████▋ | 42/388 [10:50<1:27:24卡输出结果如上图,显存占用如下
-------------------------------+----------------------+----------------------+
| 0 NVIDIA A100-SXM... On | 00000000:47:00.0 Off | 0 |
| N/A 60C P0 322W / 400W | 36944MiB / 81920MiB | 89% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 1 NVIDIA A100-SXM... On | 00000000:4B:00.0 Off | 0 |
| N/A 61C P0 321W / 400W | 34204MiB / 81920MiB | 97% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 2 NVIDIA A100-SXM... On | 00000000:89:00.0 Off | 0 |
| N/A 62C P0 349W / 400W | 34200MiB / 81920MiB | 98% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
| 3 NVIDIA A100-SXM... On | 00000000:8E:00.0 Off | 0 |
| N/A 63C P0 261W / 400W | 33882MiB / 81920MiB | 89% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+四 合并模型
1.导出为 HuggingFace 格式:
可以下载: Angainor/alpaca-lora-13b · Hugging Face 的lora_weights
修改export_hf_checkpoint.py文件:
import osimport torch
import transformers
from peft import PeftModel
from transformers import LlamaForCausalLM, LlamaTokenizer # noqa: F402BASE_MODEL = os.environ.get("BASE_MODEL", "/disk1/llama-13b")
LORA_MODEL = os.environ.get("LORA_MODEL", "./alpaca-lora-13b")
HF_CHECKPOINT = os.environ.get("HF_CHECKPOINT", "./hf_ckpt")tokenizer = LlamaTokenizer.from_pretrained(BASE_MODEL)base_model = LlamaForCausalLM.from_pretrained(BASE_MODEL,load_in_8bit=False,torch_dtype=torch.float16,device_map={"": "cpu"},
)first_weight = base_model.model.layers[0].self_attn.q_proj.weight
first_weight_old = first_weight.clone()lora_model = PeftModel.from_pretrained(base_model,LORA_MODEL,device_map={"": "cpu"},torch_dtype=torch.float16,
)lora_weight = lora_model.base_model.model.model.layers[0
].self_attn.q_proj.weightassert torch.allclose(first_weight_old, first_weight)# merge weights - new merging method from peft
lora_model = lora_model.merge_and_unload()lora_model.train(False)# did we do anything?
assert not torch.allclose(first_weight_old, first_weight)lora_model_sd = lora_model.state_dict()
deloreanized_sd = {k.replace("base_model.model.", ""): vfor k, v in lora_model_sd.items()if "lora" not in k
}LlamaForCausalLM.save_pretrained(base_model, HF_CHECKPOINT, state_dict=deloreanized_sd, max_shard_size="400MB"
)python export_hf_checkpoint.py
The tokenizer class you load from this checkpoint is not the same type as the class this function is called from. It may result in unexpected tokenization.
The tokenizer class you load from this checkpoint is 'LLaMATokenizer'.
The class this function is called from is 'LlamaTokenizer'.
You are using the legacy behaviour of the <class 'transformers.models.llama.tokenization_llama.LlamaTokenizer'>. This means that tokens that come after special tokens will not be properly handled. We recommend you to read the related pull request available at https://github.com/huggingface/transformers/pull/24565
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 41/41 [00:26<00:00, 1.56it/s]查看模型输出文件:
hf_ckpt/
├── config.json
├── generation_config.json
├── pytorch_model-00001-of-00082.bin
├── pytorch_model-00002-of-00082.bin
├── pytorch_model-00003-of-00082.bin
├── pytorch_model-00004-of-00082.bin
├── pytorch_model-00005-of-00082.bin
├── pytorch_model-00006-of-00082.bin
├── pytorch_model-00007-of-00082.bin
├── pytorch_model-00008-of-00082.bin
├── pytorch_model-00009-of-00082.bin
├── pytorch_model-00010-of-00082.bin
├── pytorch_model-00011-of-00082.bin
├── pytorch_model-00012-of-00082.bin
├── pytorch_model-00013-of-00082.bin
├── pytorch_model-00014-of-00082.bin
├── pytorch_model-00015-of-00082.bin
├── pytorch_model-00016-of-00082.bin
├── pytorch_model-00017-of-00082.bin
├── pytorch_model-00018-of-00082.bin
├── pytorch_model-00019-of-00082.bin
├── pytorch_model-00020-of-00082.bin
├── pytorch_model-00021-of-00082.bin
├── pytorch_model-00022-of-00082.bin
├── pytorch_model-00023-of-00082.bin
├── pytorch_model-00024-of-00082.bin
├── pytorch_model-00025-of-00082.bin
├── pytorch_model-00026-of-00082.bin
├── pytorch_model-00027-of-00082.bin
├── pytorch_model-00028-of-00082.bin
├── pytorch_model-00029-of-00082.bin
├── pytorch_model-00030-of-00082.bin
├── pytorch_model-00031-of-00082.bin
├── pytorch_model-00032-of-00082.bin
├── pytorch_model-00033-of-00082.bin
├── pytorch_model-00034-of-00082.bin
├── pytorch_model-00035-of-00082.bin
├── pytorch_model-00036-of-00082.bin
├── pytorch_model-00037-of-00082.bin
├── pytorch_model-00038-of-00082.bin
├── pytorch_model-00039-of-00082.bin
├── pytorch_model-00040-of-00082.bin
├── pytorch_model-00041-of-00082.bin
├── pytorch_model-00042-of-00082.bin
├── pytorch_model-00043-of-00082.bin
├── pytorch_model-00044-of-00082.bin
├── pytorch_model-00045-of-00082.bin
├── pytorch_model-00046-of-00082.bin
├── pytorch_model-00047-of-00082.bin
├── pytorch_model-00048-of-00082.bin
├── pytorch_model-00049-of-00082.bin
├── pytorch_model-00050-of-00082.bin
├── pytorch_model-00051-of-00082.bin
├── pytorch_model-00052-of-00082.bin
├── pytorch_model-00053-of-00082.bin
├── pytorch_model-00054-of-00082.bin
├── pytorch_model-00055-of-00082.bin
├── pytorch_model-00056-of-00082.bin
├── pytorch_model-00057-of-00082.bin
├── pytorch_model-00058-of-00082.bin
├── pytorch_model-00059-of-00082.bin
├── pytorch_model-00060-of-00082.bin
├── pytorch_model-00061-of-00082.bin
├── pytorch_model-00062-of-00082.bin
├── pytorch_model-00063-of-00082.bin
├── pytorch_model-00064-of-00082.bin
├── pytorch_model-00065-of-00082.bin
├── pytorch_model-00066-of-00082.bin
├── pytorch_model-00067-of-00082.bin
├── pytorch_model-00068-of-00082.bin
├── pytorch_model-00069-of-00082.bin
├── pytorch_model-00070-of-00082.bin
├── pytorch_model-00071-of-00082.bin
├── pytorch_model-00072-of-00082.bin
├── pytorch_model-00073-of-00082.bin
├── pytorch_model-00074-of-00082.bin
├── pytorch_model-00075-of-00082.bin
├── pytorch_model-00076-of-00082.bin
├── pytorch_model-00077-of-00082.bin
├── pytorch_model-00078-of-00082.bin
├── pytorch_model-00079-of-00082.bin
├── pytorch_model-00080-of-00082.bin
├── pytorch_model-00081-of-00082.bin
├── pytorch_model-00082-of-00082.bin
└── pytorch_model.bin.index.json0 directories, 85 files2 导出为PyTorch state_dicts:
同理修改export_state_dict_checkpoint.py文件:
第五步:quantization(可选)
最后,Quantization 可以帮助我们加速模型推理,并减少推理所需内存。这方面也有开源的工具可以直接使用。
第六步:相关问题
保存检查点(checkpoint model)时出现显存溢出OOM(Out Of Memory)
调优过程中,遇到保存检查点model(checkpoint model)时出现显存溢出OOM(Out Of Memory)的问题,经过查看issue-CUDA out of memory中的讨论,发现是 bitsandbytes 的新版0.38.1存在bug,需要将版本退回0.37.2,问题解决。
调优结束后adapter_model.bin 没有参数(大小为443)
这个问题主要是由于alpaca-lora和peft库之间的兼容性问题,根据 fix issues to be compatible with latest peft #359 中的讨论来看,目前最简单的做法是修改 finetune.py文件,具体如下:
model.save_pretrained(output_dir) # 原来275行的代码
model.save_pretrained(output_dir,state_dict=old_state_dict()) # 修改后的275行的代码参考文档:
- LLaMA
- Stanford Alpaca:斯坦福-羊驼
- Alpaca-LoRA
- GPT fine-tune实战
- 使用 LoRA 技术对 LLaMA 65B 大模型进行微调及推理 - 知乎 (zhihu.com)
相关文章:
[NLP]使用Alpaca-Lora基于llama模型进行微调教程
Stanford Alpaca 是在 LLaMA 整个模型上微调,即对预训练模型中的所有参数都进行微调(full fine-tuning)。但该方法对于硬件成本要求仍然偏高且训练低效。 [NLP]理解大型语言模型高效微调(PEFT) 因此, Alpaca-Lora 则是利用 Lora…...
 】)
Linux Shell 脚本编程学习之【第5章 文件的排序、合并与分割 (第四部分之cut命令) 】
第5章 文件的排序、合并与分割 (第四部分之cut命令) 4 cut 命令4.1 选项及其意义4.2 输出字符 (-c)4.3 改变分隔符(-d)和提取特定域(-f) 5 paste 命令5.1 paste 命令选项及其意义5.2…...

php-golang-rpc jsonrpc和php客户端tivoka/tivoka包实践
golang 代码: package main import ( "fmt" "net" "net/rpc" "net/rpc/jsonrpc" ) type App struct{} type Res struct { Code int json:"code" Msg string json:"msg" Data any json:"…...
flutter 打包iOS安装包
flutter iOS Xcode打包并导出ipa文件安装包 1、 Xcode配置 1、 启动打包 1、 等待打包 1、 打包完成、准备导出ipa 1、 选择模式 1、 选择配置文件 1、 导出 1、 选择导出位置 1、 得到ipa...

二进制重排
二进制重排作用 二进制重排的主要目的是将连续调用的函数连接到相邻的虚拟内存地址,这样在启动时可以减少缺页中断的发生,提升启动速度。目前网络上关于ios应用启动优化,通过XCode实现的版本比较多。MacOS上的应用也是通过clang进行编译的&am…...
【Linux后端服务器开发】MAC地址与其他重要协议
目录 一、以太网 二、MAC地址 三、MTU 四、ARP协议 五、DNS系统 六、ICMP协议 七、NAT技术 八、代理服务器 一、以太网 “以太网”不是一种具体的网路,而是一种技术标准:既包含了数据链路层的内容,也包含了一些物理层的内容…...

WebGPU入门
1. 引言 前序博客: CUDA入门WebGPUZKP:客户端证明 WebGPU——Draft 2023.7.17 由苹果、谷歌、Mozilla团队发起,当前处于草稿阶段,旨在成为W3C推荐标准。 WebGPU为 在图形处理单元(GPU)上执行诸如渲染和…...
React Dva项目中.roadhogrc.mock.js直接自动导入mock目录下所有文件方式
上文 React Dva项目中模仿网络请求数据方法 中,我们书写了Dva项目模拟后端数据的方式 但是 我们.roadhogrc.mock.js中的这个处理其实并不好用 我们还需要一个一个的引入 我们可以直接靠一段代码 import fs from fs; import path from path; const mock {} fs.re…...
跨境独立站如何应对恶意网络爬虫?
目录 跨境出海独立站纷纷成立 爬虫威胁跨境电商生存 如何有效识别爬虫? 技术反爬方案 防爬虫才能保发展 中国出海跨境电商业务,主要选择大平台开设店铺,例如,亚马逊、eBay、Walmart、AliExpress、Zalando等。随着业务的扩大&…...

C# SourceGenerator 源生成器初探
简介 注意: 坑极多。而且截至2023年,这个东西仅仅是半成品 利用SourceGenerator可以在编译结束前生成一些代码参与编译,比如编译时反射之类的,还有模板代码生成都很好用。 演示仓库传送门-Github-yueh0607 使用 1. 创建项目 …...

网络安全/信息安全—学习笔记
一、网络安全是什么 网络安全可以基于攻击和防御视角来分类,我们经常听到的 “红队”、“渗透测试” 等就是研究攻击技术,而“蓝队”、“安全运营”、“安全运维”则研究防御技术。 无论网络、Web、移动、桌面、云等哪个领域,都有攻与防两面…...

【Visual Studio】无法打开包括文件: “dirent.h”: No such file or directory
VS2017/2019 无法打开包括文件: “dirent.h”: No such file or directory 1 “dirent.h”: No such file or directory 在windows下的VS2017/2019编译器中,发现无法打开“dirent.h”,主要是MSVC并没有实现这个头文件,但是在Linux这个头文件…...

asp.net MVC markdown编辑器
在 ASP.NET MVC 中,你可以使用一些第三方 Markdown 编辑器来让用户在网页上方便地编辑和预览 Markdown 内容。这些编辑器通常提供实时预览功能,将 Markdown 文本转换为实时渲染的 HTML,并支持编辑器工具栏来辅助用户编辑。 以下是一些流行的…...

论文浅尝 | 预训练Transformer用于跨领域知识图谱补全
笔记整理:汪俊杰,浙江大学硕士,研究方向为知识图谱 链接:https://arxiv.org/pdf/2303.15682.pdf 动机 传统的直推式(tranductive)或者归纳式(inductive)的知识图谱补全(KGC)模型都关注于域内(in-domain)数据,而比较少关…...
)
算法工程师-机器学习面试题总结(2)
线性回归 线性回归的基本思想是? 线性回归是一种用于建立和预测变量之间线性关系的统计模型。其基本思想是假设自变量(输入)和因变量(输出)之间存在线性关系,通过建立一个线性方程来拟合观测数据ÿ…...

低成本32位单片机空调内风机方案
空调内风机方案主控芯片采用低成本32位单片机MM32SPIN0230,内部集成了具有灵动特色的电机控制功能:高阶4路互补PWM、注入功能的高精度ADC、轨到轨运放、轮询比较器、32位针对霍尔传感器的捕获时钟、以及硬件除法器和DMA等电机算法加速引擎。 该方案具有…...
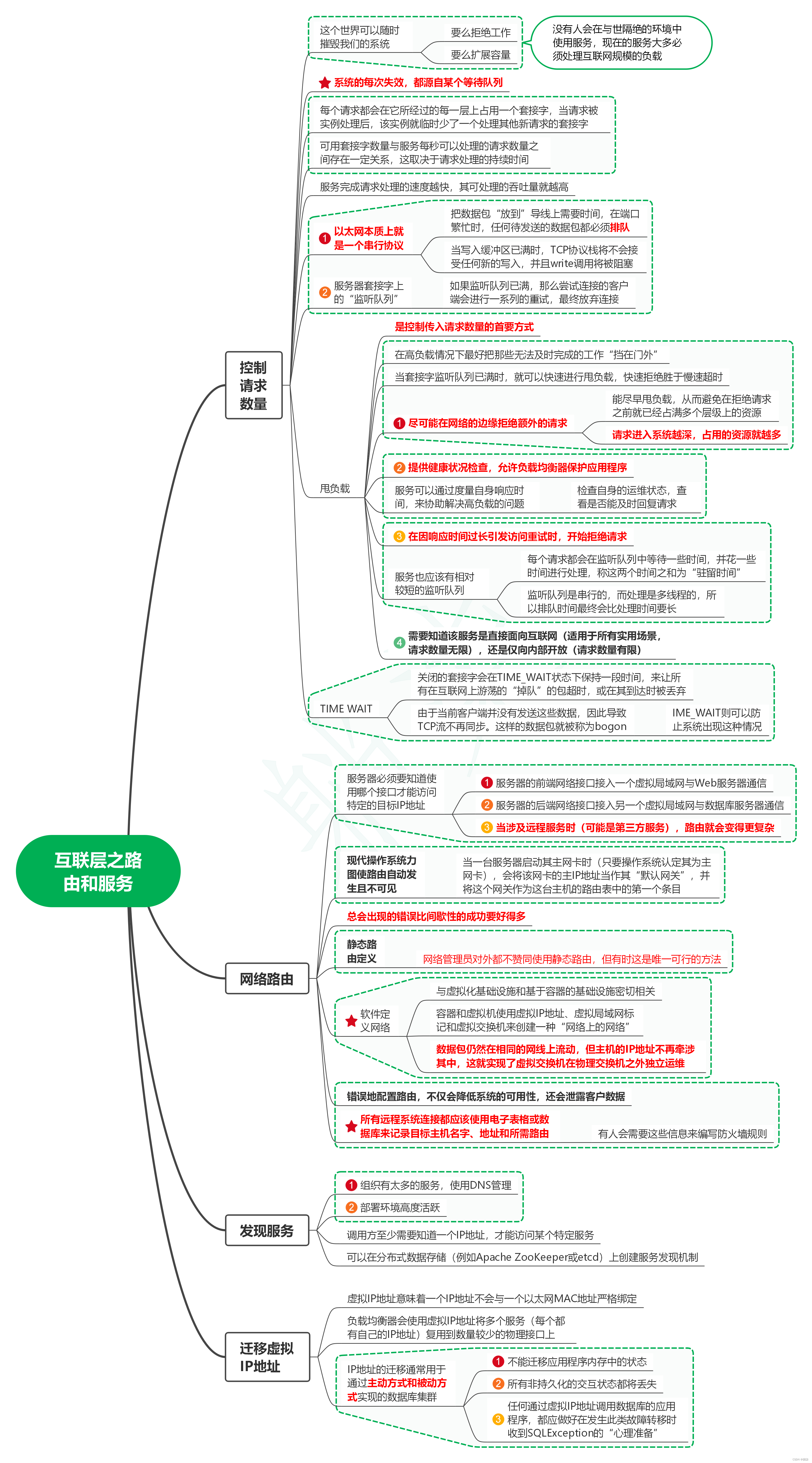
读发布!设计与部署稳定的分布式系统(第2版)笔记25_互联层之路由和服务
1. 控制请求数量 1.1. 这个世界可以随时摧毁我们的系统 1.1.1. 要么拒绝工作 1.1.2. 要么扩展容量 1.1.3. 没有人会在与世隔绝的环境中使用服务,现在的服务大多必须处理互联网规模的负载 1.2. 系统的每次失效,都源自某个等待队列 1.3. 每个请求都会…...
)
AI面试官:LINQ和Lambda表达式(二)
AI面试官:LINQ和Lambda表达式(二) 当面试官面对C#中关于LINQ和Lambda表达式的面试题时,通常会涉及这两个主题的基本概念、用法、实际应用以及与其他相关技术的对比等。以下是一些可能的面试题目,附带简要解答和相关案…...

Mysql原理篇--第二章 索引
文章目录 前言一、mysql的索引是什么?1.1 索引的结构:1.2 b树特性:1.3 b树每个节点的结构:1.4 b树 键值的大小排序:1.4 b树 存储(InnoDB): 二、索引类型2.1 主要的索引类型ÿ…...
保姆级系列教程-玩转Fiddler抓包教程(1)-HTTP和HTTPS基础知识
1.简介 有的小伙伴或者童鞋们可能会好奇地问,不是讲解和分享抓包工具了怎么这里开始讲解HTTP和HTTPS协议了。这是因为你对HTTP协议越了解,你就能越掌握Fiddler的使用方法,反过来你越使用Fiddler,就越能帮助你了解HTTP协议。 Fid…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

BLE四大广播模式详解:可连接/不可连接/定向/周期广播
一、前言在低功耗蓝牙(BLE)开发中,广播(Advertising)是设备发现、连接建立、数据广播、设备重连的核心基石,所有BLE交互流程均始于广播报文的收发。不同于传统经典蓝牙,BLE所有广播行为标准化、…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

Unity发行版DLL调试实战:DnSpy无源码IL级断点指南
1. 这不是“反编译”,而是Unity游戏开发者的日常调试手段你有没有遇到过这样的情况:接手一个Unity发行版游戏,想快速验证某个功能逻辑是否按预期执行,或者排查一个偶发的崩溃,但手头只有打包后的Assembly-CSharp.dll&a…...

企业内统一API网关与Taotoken聚合平台对接方案
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业内统一API网关与Taotoken聚合平台对接方案 在推进AI应用落地的过程中,许多中大型企业面临一个共同挑战:…...
)
别再只用鼠标了!用Leap Motion手势控制Unity游戏,保姆级配置避坑指南(2024版)
2024年Unity手势交互开发实战:Leap Motion从配置到游戏逻辑全解析在游戏开发领域,交互方式的创新往往能带来全新的体验。想象一下,玩家不再需要键盘鼠标,仅凭自然的手部动作就能操控游戏角色——这正是Leap Motion手势识别技术为U…...

Log4Shell漏洞深度解析:Spring Boot日志注入原理与四层修复方案
1. 这个漏洞不是“远程执行代码”那么简单——它是一次对Java生态信任链的系统性击穿Log4j CVE-2021-44228,业内常简称为“Log4Shell”,2021年12月爆发时,我正在给一家金融客户的Spring Boot微服务集群做灰度发布前的安全加固。凌晨三点收到告…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

模拟电路实现自主循线机器人:无MCU的硬件逻辑设计
1. 项目概述:用最纯粹的模拟电路,造一台会“思考”的机器人每次看到那些在赛道上灵巧穿梭的循线小车,你是不是也手痒,想自己动手做一个?但一听到“单片机”、“编程”、“Arduino”这些词,又觉得门槛太高&a…...

Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验?
Linux平台终极Jellyfin客户端:如何用Tsukimi打造专业级媒体中心体验? 【免费下载链接】tsukimi A simple third-party Jellyfin client for Linux 项目地址: https://gitcode.com/gh_mirrors/ts/tsukimi 你是否厌倦了网页版Jellyfin的笨重体验&am…...