使用贝叶斯算法完成文档分类问题
贝叶斯原理
贝叶斯原理(Bayes' theorem)是一种用于计算条件概率的数学公式。它是以18世纪英国数学家托马斯·贝叶斯(Thomas Bayes)的名字命名的。贝叶斯原理表达了在已知某个事件发生的情况下,另一个事件发生的概率。具体而言,它可以用来计算某个假设的后验概率,即在已知一些先验概率的情况下,根据新的证据来更新这些概率。贝叶斯原理的数学表达式为:
P(A|B) = P(B|A) * P(A) / P(B)
其中,P(A|B)表示在B发生的条件下A发生的概率,也称为后验概率;P(B|A)表示在A发生的条件下B发生的概率,也称为似然度;P(A)和P(B)分别表示A和B的先验概率,即在考虑任何证据之前,A和B分别发生的概率。上面的解释比较难以理解,下面通过一个实际的例子来看看。
高斯朴素贝叶斯:特征变量是连续变量,符合高斯分布,比如说人的身高,物体的长度。
多项式朴素贝叶斯:特征变量是离散变量,符合多项分布,在文档分类中特征变量体现在一个单词出现的次数,或者是单词的TF-IDF值等。
伯努利朴素贝叶斯:特征变量是布尔变量,符合0/1分布,在文档分类中特征是单词是否出现。
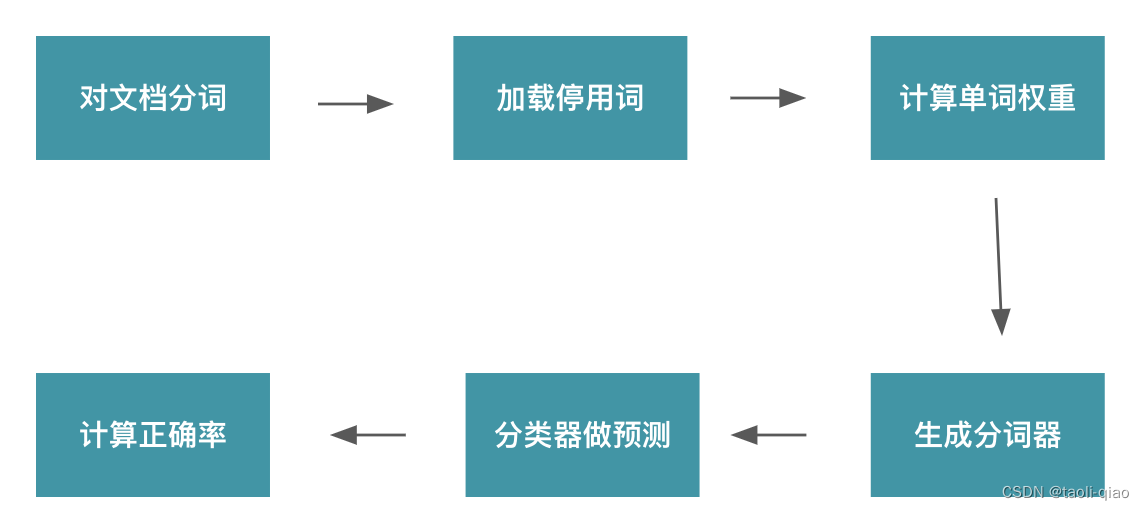
上面介绍了朴素贝叶斯原理,那么如何使用朴素贝叶斯进行文档分类任务呢?下面是使用多项式朴素贝叶斯进行文本分类的demo例子。
# 中文文本分类
import os
import jieba
import warnings
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn import metricswarnings.filterwarnings('ignore')def cut_words(file_path):"""对文本进行切词:param file_path: txt文本路径:return: 用空格分词的字符串"""text_with_spaces = ''text=open(file_path, 'r', encoding='gb18030').read()textcut = jieba.cut(text)for word in textcut:text_with_spaces += word + ' 'return text_with_spacesdef loadfile(file_dir, label):"""将路径下的所有文件加载:param file_dir: 保存txt文件目录:param label: 文档标签:return: 分词后的文档列表和标签"""file_list = os.listdir(file_dir)words_list = []labels_list = []for file in file_list:file_path = file_dir + '/' + filewords_list.append(cut_words(file_path))labels_list.append(label) return words_list, labels_list# 训练数据
train_words_list1, train_labels1 = loadfile('text classification/train/女性', '女性')
train_words_list2, train_labels2 = loadfile('text classification/train/体育', '体育')
train_words_list3, train_labels3 = loadfile('text classification/train/文学', '文学')
train_words_list4, train_labels4 = loadfile('text classification/train/校园', '校园')train_words_list = train_words_list1 + train_words_list2 + train_words_list3 + train_words_list4
train_labels = train_labels1 + train_labels2 + train_labels3 + train_labels4# 测试数据
test_words_list1, test_labels1 = loadfile('text classification/test/女性', '女性')
test_words_list2, test_labels2 = loadfile('text classification/test/体育', '体育')
test_words_list3, test_labels3 = loadfile('text classification/test/文学', '文学')
test_words_list4, test_labels4 = loadfile('text classification/test/校园', '校园')test_words_list = test_words_list1 + test_words_list2 + test_words_list3 + test_words_list4
test_labels = test_labels1 + test_labels2 + test_labels3 + test_labels4stop_words = open('text classification/stop/stopword.txt', 'r', encoding='utf-8').read()
stop_words = stop_words.encode('utf-8').decode('utf-8-sig') # 列表头部\ufeff处理
stop_words = stop_words.split('\n') # 根据分隔符分隔# 计算单词权重
tf = TfidfVectorizer(stop_words=stop_words, max_df=0.5)train_features = tf.fit_transform(train_words_list)
# 上面fit过了,这里transform
test_features = tf.transform(test_words_list) # 多项式贝叶斯分类器
from sklearn.naive_bayes import MultinomialNB
clf = MultinomialNB(alpha=0.001).fit(train_features, train_labels)
predicted_labels=clf.predict(test_features)# 计算准确率
print('准确率为:', metrics.accuracy_score(test_labels, predicted_labels))上面的例子中用到了TfidVectorizer来提取特征向量,TfidfVectorizer是Scikit-learn中的一个文本特征提取函数,用于将文本转换为数值特征向量。它的作用是将原始的文本数据集转换为TF-IDF特征向量集。TF-IDF(Term Frequency-Inverse Document Frequency)是一种用于衡量一个词语在文档中的重要性的指标。词频TF计算了一个单词在文档中出现的次数,它认为一个单词的重要性和它在文档中出现的次数呈正比。逆向文档频率IDF,是指一个单词在文档中的区分度。它认为一个单词出现在的文档数越少,就越能通过这个单词把该文档和其他文档区分开。IDF越大就代表该单词的区分度越大。所以TF-IDF实际上是词频TF和逆向文档频率IDF的乘积。这样我们倾向于找到TF和IDF取值都高的单词作为区分,即这个单词在一个文档中出现的次数多,同时又很少出现在其他文档中。这样的单词适合用于分类。TF-IDF的具体计算公式如下:
TF-IDF = TF(t,d) * IDF(t)。 其中,t表示词语,d表示文档,TF(t,d)表示词语t在文档d中出现的频率,IDF(t)表示逆文档频率,可以通过以下公式计算:
IDF(t) = log(N / df(t))。 其中,N表示文档总数,df(t)表示包含词语t的文档数。
TfidfVectorizer函数的主要参数如下:
- stop_words:停用词列表,可以是'english'表示使用Scikit-learn自带的英文停用词列表,也可以是一个自定义停用词列表;
- tokenizer:用于分词的函数,如果不指定,则默认使用Scikit-learn的内置分词器;
- ngram_range:用于控制特征中词语的个数,可以是单个词语(unigram),两个词语(bigram),三个词语(trigram)等;
- max_features:用于控制特征向量的最大维度;
- norm:用于归一化特征向量的方式,可以是'l1'或'l2';
- use_idf:是否使用IDF权重;
- smooth_idf:是否对IDF权重加1平滑处理;
- sublinear_tf:是否使用对数函数对TF进行缩放。
下面是使用TfidfVectorizer将一段文本转换成特征向量的例子。
from sklearn.feature_extraction.text import TfidfVectorizervectorizer = TfidfVectorizer(stop_words='english')
documents = ["This is the first document.","This is the second document.","And this is the third one.",
]
X = vectorizer.fit_transform(documents)
print(X.toarray())
print(X.shape)下面是打印的特征向量结果,使用了X.toarray()方法将稀疏矩阵转换为密集矩阵。,第一个结果是没有传入stop_words的结果,生成的特征向量是一个3行9列的数据,第二个结果是加入stop_words的结果,第二次是一个3行2列的数据。每一行代表一个文档,每一列代表一个特征。可以看到,这些特征是根据词频和逆文档频率计算得到的。

相关文章:
使用贝叶斯算法完成文档分类问题
贝叶斯原理 贝叶斯原理(Bayes theorem)是一种用于计算条件概率的数学公式。它是以18世纪英国数学家托马斯贝叶斯(Thomas Bayes)的名字命名的。贝叶斯原理表达了在已知某个事件发生的情况下,另一个事件发生的概率。具体…...

【Kafka】消息队列Kafka进阶
目录 Kafka分区机制生产者分区写入策略轮询策略随机策略(不用)按key分配策略乱序问题自定义分区策略 消费者组Rebalance机制消费者分区分配策略Range范围分配策略RoundRobin轮询策略Stricky粘性分配策略 Kafka副本机制producer的ACKs参数acks配置为0acks…...

学习day55
消息订阅与发布 消息订阅与发布是一种组件间通信的方式,适用于任意组件间通信 使用步骤: 安装pubsub:npm i pubsub-js 引入:import pubsub from pubsub-js 接收数据:A组件想接收数据,则在A组件中订阅消息…...

C++-Rust-一次性掌握两门语言
C-Rust-一次性掌握两门语言 简介特色数据类型声明常量、变量判断与循环函数抽象化的对象:类与接口枚举模板与泛型Lambda匿名函数表达式 简介 本文主要是通过介绍C和Rust的基础语法达成极速入门两门开发语言。 C是在C语言的基础之上添加了面向对象的类、重载、模板等…...

汇编调用C语言定义的全局变量
在threadx移植中,系统的systick通过了宏定义的方式定义,很难对接库函数的时钟频率,不太利于进行维护 所以在C文件中自己定义了一个systick_Div的变量,通过宏定义方式设定systick的时钟频率 在汇编下要加载这个systick分频系数 …...

WEB 文件包含 /伪协议
首先谈谈什么是文件包含 WEB入门——文件包含漏洞与PHP伪协议_文件包含php伪协议_HasntStartIsOver的博客-CSDN博客 文件包含 程序员在编写的时候 可能写了自己的 函数 如果想多次调用 那么就需要 重新写在源代码中 太过于麻烦了只需要写入 funcation.php然后在需要引用的地…...
)
ComPDFKit PDF SDK库(支持Windows、Web、Android、iOS、Mac等平台)
ComPDFKit提供专业、全平台支持的PDF开发库,包括Windows、Mac、Linux、Android、iOS、Web平台。开发者可以快速、灵活整合PDF功能到各开发平台的软件、程序、系统中。丰富的功能,多种开发语言,灵活的部署方案可供选择,满足您对PDF…...

微服务契约测试框架-Pact
契约测试 契约测试的思想就是将原本的 Consumer 与 Provider 间同步的集成测试,通过契约进行解耦,变成 Consumer 与 Provider 端两个各自独立的、异步的单元测试。 契约测试的优点: 契约测试与单元测试以及其它测试之间没有重复,…...
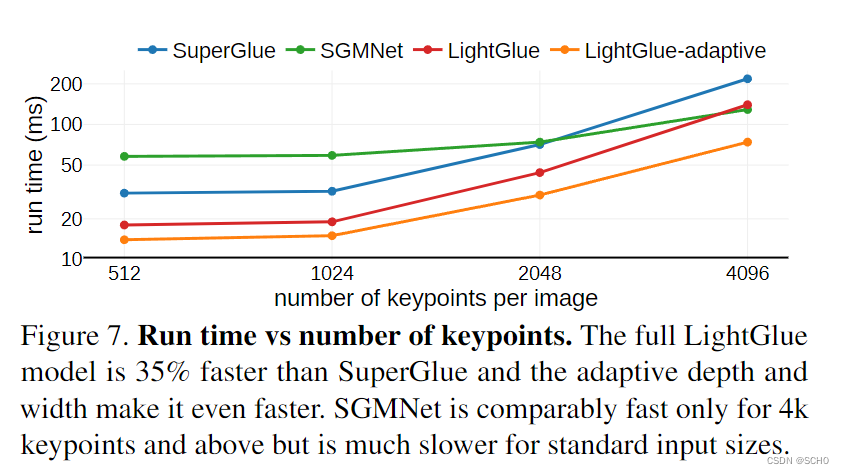
LightGlue论文翻译
LightGlue:光速下的局部特征匹配 摘要 - 我们介绍 LightGlue,一个深度神经网络,学习匹配图像中的局部特征。我们重新审视 SuperGlue 的多重设计决策,稀疏匹配的最新技术,并得出简单而有效的改进。累积起来,它们使 Lig…...

iOS开发-CAShapeLayer与UIBezierPath实现微信首页的下拉菜单效果
iOS开发-CAShapeLayer与UIBezierPath实现微信首页的下拉菜单效果 之前开发中遇到需要使用实现微信首页的下拉菜单效果。用到了CAShapeLayer与UIBezierPath绘制菜单外框。 一、效果图 二、CAShapeLayer与UIBezierPath 2.1、CAShapeLayer是什么? CAShapeLayer继承自…...

《Elasticsearch 源码解析与优化实战》第5章:选主流程
《Elasticsearch 源码解析与优化实战》第5章:选主流程 - 墨天轮 一、简介 Discovery 模块负责发现集群中的节点,以及选择主节点。ES 支持多种不同 Discovery 类型选择,内置的实现称为Zen Discovery ,其他的包括公有云平台亚马逊的EC2、谷歌…...

Spring Cloud Alibaba - Nacos源码分析(三)
目录 一、Nacos客户端服务订阅的事件机制 1、监听事件的注册 2、ServiceInfo处理 serviceInfoHolder.processServiceInfo 一、Nacos客户端服务订阅的事件机制 Nacos客户端订阅的核心流程:Nacos客户端通过一个定时任务,每6秒从注册中心获取实例列表&…...

DOCKER镜像和容器
1.前言 初见DOCKER,感觉和我们常用的虚拟机(VMware,viurebox)类似,是一个独立于宿主机的模块,可以解决程序在各个系统间的移植,但它真的仅仅是这样嘛? 2.容器的优缺点 1.1.容器…...
探索网页原型设计:构建出色的用户体验
在当今数字化时代,用户对网页体验的要求日益提高。在网页设计过程中,扮演着至关重要的角色。通过网页原型设计,产品经理能够更好地展示和传达网页的整体布局、导航结构、元素位置和交互效果,从而使团队成员更清晰地了解设计意图&a…...

48,排序算法merge
功能描述: 两个容器元素合并,并储存到另一容器中 函数原型: merge(iterator beg1,iterator end1,iterator beg2,iterator end2,iterator dest); //容器元素合并,并存储到另一个容器中 //注意:两个容器必须是有序的…...

【MySQL】复合查询
复合查询目录 一、基本查询二、多表查询三、自连接四、子查询4.1 单行子查询4.2 多行子查询4.3 多列子查询4.4 在from子句中使用子查询4.5 合并查询4.5.1 union4.5.2 union all 五、实战OJ 一、基本查询 --查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的…...

JavaScript中的this指向及绑定规则
在JavaScript中,this是一个特殊的关键字,用于表示函数执行的上下文对象,也就是当前函数被调用时所在的对象。由于JavaScript的函数调用方式多种多样,this的指向也因此而变化。本文将介绍JavaScript中this的指向及绑定规则…...

css中预编译理解,它们之间区别
css预编译? css预编译器用一种专门的编程语言,它可以对web页面样式然后再编译成正常css文件,可以更加方便和高效的编写css代表。主要作用就是为css提供了变量,函数,嵌套,继承,混合等功能&#…...

如何使用Java处理JSON数据?
在Java中,您可以使用许多库来处理JSON数据。以下是使用一种常见的库 Gson 的示例: 首先,确保您已经将 Gson 库添加到您的项目中。您可以在 Maven 中添加以下依赖项: <dependency><groupId>com.google.code.gson<…...
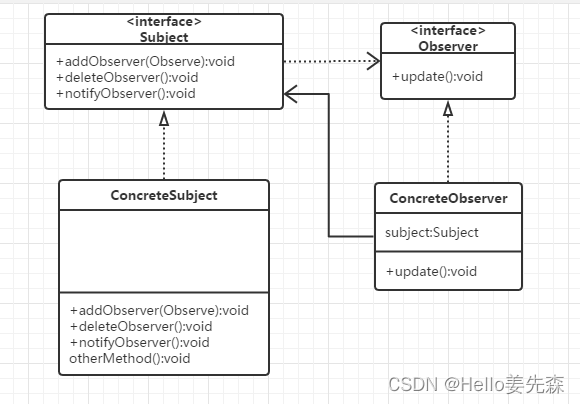
java设计模式-观察者模式
什么是观察者模式 观察者模式(Observer)是软件设计中的一种行为模式。 它定义了对象之间的一对多关系,其中如果一个对象改变了状态,所有依赖它的对象都会自动被通知并更新。 这种模式包含了两种主要的角色,即被观察…...

混合求解器:用神经网络增强传统微分方程数值方法
1. 项目概述:当数值方法遇到机器学习在科学计算和工程仿真领域,求解常微分方程(ODE)和偏微分方程(PDE)是绕不开的核心任务。无论是模拟电路中的电流变化、预测天气系统的演变,还是分析机械结构的…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...
重构)
嘈杂工业场景下的自适应VAD与双码本声纹识别鉴权系统:基于端侧轻量化神经网络与向量量化(VQ)重构
在大型化工车间、能源集控中心以及金融极密隔离库房中,离线声纹识别是物理访问控制和身份安全核验的重要生物特征屏障。然而,在环境本底噪声高达80dB以上的恶劣工业场景下,常规的语音活动检测(VAD)会频繁误触ÿ…...

基于ATtiny84的智能冰箱监控器:低功耗温度与门状态监测方案
1. 项目概述:一个装在树莓派盒子里的智能冰箱管家如果你家里有台老冰箱,或者对食物储存温度特别在意,总担心冰箱门没关严或者突然断电导致内部升温,那么这个自己动手做的“冰箱看门狗”项目就太适合你了。它本质上是一个高度定制化…...

论文润色深度测评:GPT-5.5 + Gemini 3.1 Pro:教你学会1+1>2的论文润色方法
各位同仁好,我是七哥。一个在高校里从事人工智能相关领域研究,钻研用大模型AI实操的学术人。可以和七哥交流学术写作或Gemini、GPT、Claude等大模型学术实操相关问题,多多交流,相互成就,共同进步。 2026年的科研圈,AI工具的选择已经从有没有变成了强不强,七哥评测了GPT…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现
Vue2-Verify:解决前端验证码安全性与用户体验平衡问题的技术方案实现 【免费下载链接】vue2-verify vue的验证码插件 项目地址: https://gitcode.com/gh_mirrors/vu/vue2-verify 在当今Web应用开发中,验证码作为防止自动化攻击的关键安全组件&…...

危急时刻的六条基本安全提示
人机协作,AI模型:Deepseek 仅供参考 危急时刻的六条基本安全提示 以下内容仅为通用性安全建议,供在紧急情况下保持冷静、保护自身安全时参考。所有建议均基于常理和公共安全常识,不包含任何具体操作细节或可能被不当使用的信息…...