CycleGAN模型解读(附源码+论文)
CycleGAN
论文链接:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
官方链接:pytorch-CycleGAN-and-pix2pix
老规矩,先看看效果

总体流程
先简单过一遍流程,细节在代码里说。CycleGAN有两个生成器和两个判别器。下图可以看到GeneratorA2B和GeneratorB2A,假设A数据集里全是马,B数据集里全是斑马,那这两个分别就是将马生成斑马和斑马生成马的生成器。DiscriminatorA和DiscriminatorB就是用来判别马和斑马的判别器。

上面的流程图很清晰的表示了模型的整体过程。一般生成器将马生成斑马就结束了,但是CycleGAN表示nonono,它还将生成的斑马再还原回马。因为 CycleGAN 强调循环一致性(Cycle Consistency),它通过让生成的斑马再还原回马,确保生成的斑马仍然保留了输入马的基本特征和结构。也就是说,CycleGAN 不仅要生成目标域的图像,还要通过反向转换验证生成图像的合理性。

同样的流程还会再经历一次,只不过这里的马和斑马的位置对调了一下(输入斑马,生成马)。
生成模型的损失函数有三种,拆分为六部分,分别对应对抗损失、循环一致性损失和身份损失。容易想到的,对抗损失用于训练生成器 A2B 和B2A 生成能够欺骗判别器的图像,可以理解为将真马生成为假斑马能不能让判别器判断为真的。上面流程不是有一步生成了假图还要还原回去,没错,还原回去的图与真实的图的差异,即循环一致性损失。身份损失是为了让生成器保留图像的风格或颜色特征,可以理解成除了马变成了斑马,其余背景部分不做变化。
将一匹马变成一匹斑马,我在没看这篇论文之前想的流程是,有一张马的图片,然后再做一张将马变为斑马的标签图,这样可以将生成的图片与这张标签图做损失计算进行训练。但CycleGAN根本不需要标签图,它只需要马的图片与斑马的图片就行,不需要什么人工处理的标签图,简直是福音,人工标注鬼知道有多麻烦。就像下图一样,素描鞋子作为输入,皮鞋作为标签图,需要一一对应。而现在,照片作为输入,标签图是毫不相干的油画图。

数据准备
这里说的详细一点,怎么准备数据。
公开数据集地址:Index of /cyclegan/datasets

下载自己想玩的数据集,比如horse2zebra就是马转斑马的。下载好的数据集放在datasets目录下。
预训练模型地址:Index of /cyclegan/pretrained_models

下载对应的预训练模型哦,比如horse2zebra.pth就是马转斑马的。下载好的模型放在checkpoints目录下。
别的配置看github上有详细说明。
预警:模型训练需要显卡显存至少8G及以上。
代码
数据处理
运行train.py。先进入unaligned_dataset.py看看数据集怎么处理的。
def __init__(self, opt):BaseDataset.__init__(self, opt)self.dir_A = os.path.join(opt.dataroot, opt.phase + 'A') # create a path '/path/to/data/trainA'self.dir_B = os.path.join(opt.dataroot, opt.phase + 'B') # create a path '/path/to/data/trainB'self.A_paths = sorted(make_dataset(self.dir_A, opt.max_dataset_size)) # load images from '/path/to/data/trainA'self.B_paths = sorted(make_dataset(self.dir_B, opt.max_dataset_size)) # load images from '/path/to/data/trainB'self.A_size = len(self.A_paths) # get the size of dataset Aself.B_size = len(self.B_paths) # get the size of dataset BbtoA = self.opt.direction == 'BtoA'input_nc = self.opt.output_nc if btoA else self.opt.input_nc # get the number of channels of input imageoutput_nc = self.opt.input_nc if btoA else self.opt.output_nc # get the number of channels of output imageself.transform_A = get_transform(self.opt, grayscale=(input_nc == 1))self.transform_B = get_transform(self.opt, grayscale=(output_nc == 1))
先获得训练数据集A和B的路径,然后看看路径下有多少图片,数据集A和B的图片数量可以不一样哦。因为就像我上面说的,不需要一一对应的标签图,所以取出一张A可以从数据集B中随机抽一张作为标签图。然后会通过transform做一些图片处理,比如resize、裁剪、翻转、标准化之类的。
model
进入cycle_gan_model.py看看模型怎么初始化和训练的。
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
self.netG_B = networks.define_G(opt.output_nc, opt.input_nc, opt.ngf, opt.netG, opt.norm,not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)if self.isTrain: # define discriminatorsself.netD_A = networks.define_D(opt.output_nc, opt.ndf, opt.netD,opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)self.netD_B = networks.define_D(opt.input_nc, opt.ndf, opt.netD,opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
在初始化时,最重要的是生成器和判别器的定义,我们去networks.py里看看define_G和define_D的定义。
define_G
def define_G(input_nc, output_nc, ngf, netG, norm='batch', use_dropout=False, init_type='normal', init_gain=0.02, gpu_ids=[]):net = Nonenorm_layer = get_norm_layer(norm_type=norm)if netG == 'resnet_9blocks':net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=9)elif netG == 'resnet_6blocks':net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=6)elif netG == 'unet_128':net = UnetGenerator(input_nc, output_nc, 7, ngf, norm_layer=norm_layer, use_dropout=use_dropout)elif netG == 'unet_256':net = UnetGenerator(input_nc, output_nc, 8, ngf, norm_layer=norm_layer, use_dropout=use_dropout)else:raise NotImplementedError('Generator model name [%s] is not recognized' % netG)return init_net(net, init_type, init_gain, gpu_ids)
图片卷积三件套Conv->BN->relu。不过这里的BN换了一下,上面代码用了norm_layer代替,即nn.BatchNorm2d转为nn.InstanceNorm2d,不同点在于InstanceNorm2d对每个样本的特征通道分别进行归一化。构建网络时用的是resnet_9blocks,我们进ResnetGenerator看一看。
ResnetGenerator
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6,padding_type='reflect'):assert (n_blocks >= 0)super(ResnetGenerator, self).__init__()if type(norm_layer) == functools.partial:use_bias = norm_layer.func == nn.InstanceNorm2delse:use_bias = norm_layer == nn.InstanceNorm2dmodel = [nn.ReflectionPad2d(3),nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),norm_layer(ngf),nn.ReLU(True)]n_downsampling = 2for i in range(n_downsampling): # add downsampling layersmult = 2 ** imodel += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),norm_layer(ngf * mult * 2),nn.ReLU(True)]mult = 2 ** n_downsamplingfor i in range(n_blocks): # add ResNet blocksmodel += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout,use_bias=use_bias)]for i in range(n_downsampling): # add upsampling layersmult = 2 ** (n_downsampling - i)model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),kernel_size=3, stride=2,padding=1, output_padding=1,bias=use_bias),norm_layer(int(ngf * mult / 2)),nn.ReLU(True)]model += [nn.ReflectionPad2d(3)]model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]model += [nn.Tanh()]self.model = nn.Sequential(*model)
在model初始构建时,我们发现卷积三件套上多了一件nn.ReflectionPad2d(3),这是padding的一种方式,不过不同于简单的填充,周围都填充为0,而是通过在输入特征图边界处 镜像反射 填充,如下图所示。

模型构建下面就比较简单,就是先通过卷积给图像size越卷越小,不过特征图越卷越多(3->64->128->256)。然后来点残差块ResnetBlock。生成器最后生成的图得跟原图一样大小,所以通过反卷积nn.ConvTranspose2d,给图卷回原来大小,就类似上采样。同理特征图数量也得越卷越少,卷回原来的3通道(256->128->64->3)。
define_D
我们再看看判别器怎么定义的。
def define_D(input_nc, ndf, netD, n_layers_D=3, norm='batch', init_type='normal', init_gain=0.02, gpu_ids=[]):net = Nonenorm_layer = get_norm_layer(norm_type=norm)if netD == 'basic': # default PatchGAN classifiernet = NLayerDiscriminator(input_nc, ndf, n_layers=3, norm_layer=norm_layer)elif netD == 'n_layers': # more optionsnet = NLayerDiscriminator(input_nc, ndf, n_layers_D, norm_layer=norm_layer)elif netD == 'pixel': # classify if each pixel is real or fakenet = PixelDiscriminator(input_nc, ndf, norm_layer=norm_layer)else:raise NotImplementedError('Discriminator model name [%s] is not recognized' % netD)return init_net(net, init_type, init_gain, gpu_ids)
跟生成器一样吼,先定义一个norm_layer,然后进入NLayerDiscriminator看看。
NLayerDiscriminator
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):super(NLayerDiscriminator, self).__init__()if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parametersuse_bias = norm_layer.func == nn.InstanceNorm2delse:use_bias = norm_layer == nn.InstanceNorm2dkw = 4padw = 1sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]nf_mult = 1nf_mult_prev = 1for n in range(1, n_layers): # gradually increase the number of filtersnf_mult_prev = nf_multnf_mult = min(2 ** n, 8)sequence += [nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),norm_layer(ndf * nf_mult),nn.LeakyReLU(0.2, True)]nf_mult_prev = nf_multnf_mult = min(2 ** n_layers, 8)sequence += [nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),norm_layer(ndf * nf_mult),nn.LeakyReLU(0.2, True)]sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction mapself.model = nn.Sequential(*sequence)
构建过程也没啥要说的,就是不停卷积给特征图越卷越多,最后输出一个值,判定是真是假(3->64->128->256->512->1)。
初始化好模型后进行训练,主要来看一下model.optimize_parameters()这里的内容。
optimize_parameters
到cycle_gan_model.py看一下optimize_parameters。
def optimize_parameters(self):# forwardself.forward() # compute fake images and reconstruction images.# G_A and G_B 训练生成器 判别器不工作self.set_requires_grad([self.netD_A, self.netD_B], False) # Ds require no gradients when optimizing Gsself.optimizer_G.zero_grad() # set G_A and G_B's gradients to zeroself.backward_G() # calculate gradients for G_A and G_Bself.optimizer_G.step() # update G_A and G_B's weights# D_A and D_B 训练判别器 生成器不工作self.set_requires_grad([self.netD_A, self.netD_B], True)self.optimizer_D.zero_grad() # set D_A and D_B's gradients to zeroself.backward_D_A() # calculate gradients for D_Aself.backward_D_B() # calculate graidents for D_Bself.optimizer_D.step() # update D_A and D_B's weights
简简单单包含了前向传播和反向传播,先看看前向传播forward。
forward
def forward(self):self.fake_B = self.netG_A(self.real_A) # G_A(A)self.rec_A = self.netG_B(self.fake_B) # G_B(G_A(A))self.fake_A = self.netG_B(self.real_B) # G_B(B)self.rec_B = self.netG_A(self.fake_A) # G_A(G_B(B))
四行代码很好理解。将真实图A输入生成器A2B,输出假B;将假B输入生成器B2A,还原回A;同理,将真实图B输入生成器B2A,输出假A;将假A输入生成器A2B,还原回B。
backward_G
看看生成器的反向传播,怎么做损失计算的。
def backward_G(self):"""Calculate the loss for generators G_A and G_B"""lambda_idt = self.opt.lambda_identity # 一些缩放因子lambda_A = self.opt.lambda_Alambda_B = self.opt.lambda_B# Identity lossif lambda_idt > 0:# G_A should be identity if real_B is fed: ||G_A(B) - B||self.idt_A = self.netG_A(self.real_B) # 将真实B传入A->B网络 也能生成假Bself.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt# G_B should be identity if real_A is fed: ||G_B(A) - A||self.idt_B = self.netG_B(self.real_A) # 将真实A传入B->A网络 也能生成假Aself.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idtelse:self.loss_idt_A = 0self.loss_idt_B = 0# GAN loss D_A(G_A(A))self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B), True) # 希望判别器将假B判为真# GAN loss D_B(G_B(B))self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A), True)# Forward cycle loss || G_B(G_A(A)) - A||self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A # 还原A与真实A的差异损失# Backward cycle loss || G_A(G_B(B)) - B||self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B# combined loss and calculate gradientsself.loss_G = self.loss_G_A + self.loss_G_B + self.loss_cycle_A + self.loss_cycle_B + self.loss_idt_A + self.loss_idt_Bself.loss_G.backward()
这里的self.idt_A和self.idt_B就是我上面说的身份损失,公式如下。

式中,G和F是生成器A2B和B2A。
lambda_idt就是个加权参数,缩放损失用的。生成器A2B的作用不是输入A生成B嘛,不过这里做损失是通过输入B,输出B,这两B之间的差异做损失。论文中说引入这个损失有助于促进映射以保持输入和输出之间的颜色组成。比如莫奈的画作与Flickr照片之间的映射时,生成器经常将 白天 的画作映射到 日落 时拍摄的照片,如下图所示。

self.loss_G_A和self.loss_G_B是我上面说的对抗损失,公式如下。

这个损失很好理解,就是我生成器生成的假图,我希望判别器判为真的。这里的判别是对每个像素点都判别是真是假,然后取平均。如果输入图片size是[256,256],经过判别器输出图片size是[30,30],对这[30,30]的每个点判断是真是假。具体代码可以自己去networks.py的GANLoss看一下。
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device) # define GAN loss.
剩下最后的self.loss_cycle_A和self.loss_cycle_B就是循环一致性损失了,公式如下。

这个更好理解,就是看看还原回去的图与输入的图的差异损失。下图是论文中,输入->输出->还原(重建)的过程。

====================================================================================
train需要电脑配置还挺高的,大家可以试试test,配置一下参数就行,例如下面
python test.py --dataroot datasets/horse2zebra/testA --name horse2zebra_pretrained --model test --no_dropout
数据集放在datasets/horse2zebra/testA目录下,模型放在checkpoints/horse2zebra_pretrained目录下,最后的结果会生成一个result目录下。
相关文章:
CycleGAN模型解读(附源码+论文)
CycleGAN 论文链接:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 官方链接:pytorch-CycleGAN-and-pix2pix 老规矩,先看看效果 总体流程 先简单过一遍流程,细节在代码里说。CycleGAN有…...

线程配置经验
工作时,时常会遇到,线程相关的问题与解法,本人会持续对开发过程中遇到的关于线程相关的问题及解决记录更新记录在此篇博客中。 目录 一、线程基本知识 1. 线程和进程 二、问题与解法 1. 避免乘法级别数量线程并行 1)使用线程池…...
)
动态规划DP 数字三角形模型 传纸条(题目分析+C++完整代码)
传纸条 原题链接 AcWing 275. 传纸条 题目描述 小渊和小轩是好朋友也是同班同学,他们在一起总有谈不完的话题。 一次素质拓展活动中,班上同学安排坐成一个 m行 n 列的矩阵,而小渊和小轩被安排在矩阵对角线的两端,因此&#x…...

Ubuntu二进制部署K8S 1.29.2
本机说明 本版本非高可用,单Master,以及一个Node 新装的 ubuntu 22.04k8s 1.29.3使用该文档请使用批量替换 192.168.44.141这个IP,其余照着复制粘贴就可以成功需要手动 设置一个 固定DNS,我这里设置的是 8.8.8.8不然coredns无法…...

第05章 10 地形梯度场模拟显示
在 VTK(Visualization Toolkit)中,可以通过计算地形数据的梯度场,并用箭头或线条来表示梯度方向和大小,从而模拟显示地形梯度场。以下是一个示例代码,展示了如何使用 VTK 和 C 来计算和显示地形数据的梯度场…...

全程Kali linux---CTFshow misc入门
图片篇(基础操作) 第一题: ctfshow{22f1fb91fc4169f1c9411ce632a0ed8d} 第二题 解压完成后看到PNG,可以知道这是一张图片,使用mv命令或者直接右键重命名,修改扩展名为“PNG”即可得到flag。 ctfshow{6f66202f21ad22a2a19520cdd…...

[ Spring ] Spring Cloud Alibaba Message Stream Binder for RocketMQ 2025
文章目录 IntroduceProject StructureDeclare Plugins and ModulesApply Plugins and Add DependenciesSender PropertiesSender ApplicationSender ControllerReceiver PropertiesReceiver ApplicationReceiver Message HandlerCongratulationsAutomatically Send Message By …...
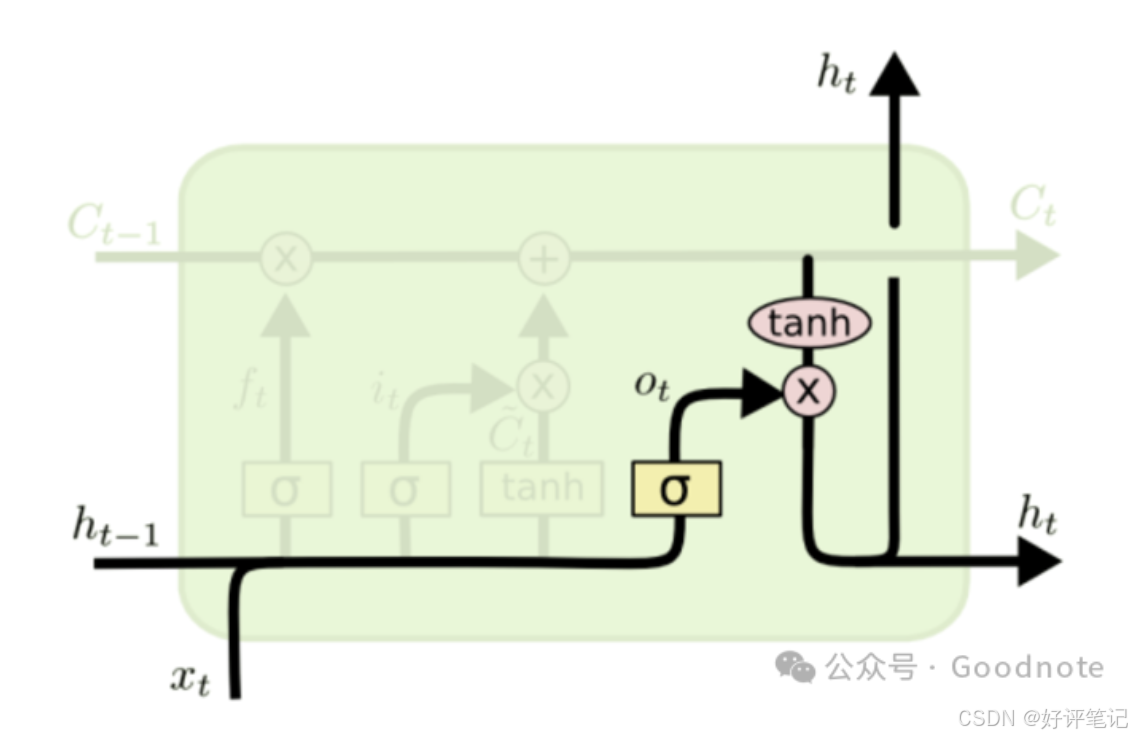
深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...

AI 模型评估与质量控制:生成内容的评估与问题防护
在生成式 AI 应用中,模型生成的内容质量直接影响用户体验。然而,生成式模型存在一定风险,如幻觉(Hallucination)问题——生成不准确或完全虚构的内容。因此,在构建生成式 AI 应用时,模型评估与质…...

[MILP] Logical Constraints 0-1 (Note2)
1. 如果选择了项目1,则项目2,3也要求被选中 表示为: 2. 如果确定了选项目1,则接下来必须选项目2或者项目3 表示为: or 3. 如果同时选择了项目2和项目3,则不可以选择项目1 表示为: 4. 如果…...

DFFormer实战:使用DFFormer实现图像分类任务(二)
文章目录 训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整策略设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法 运行以及结果查看测试完整的代码 在上…...

蓝桥杯例题四
每个人都有无限潜能,只要你敢于去追求,你就能超越自己,实现梦想。人生的道路上会有困难和挑战,但这些都是成长的机会。不要被过去的失败所束缚,要相信自己的能力,坚持不懈地努力奋斗。成功需要付出汗水和努…...

如何复现o1模型,打造医疗 o1?
如何复现o1模型,打造医疗 o1? o1 树搜索一、起点:预训练规模触顶与「推理阶段(Test-Time)扩展」的动机二、Test-Time 扩展的核心思路与常见手段1. Proposer & Verifier 统一视角方法1:纯 Inference Sca…...

PostgreSQL TRUNCATE TABLE 操作详解
PostgreSQL TRUNCATE TABLE 操作详解 引言 在数据库管理中,经常需要对表进行操作以保持数据的有效性和一致性。TRUNCATE TABLE 是 PostgreSQL 中一种高效删除表内所有记录的方法。本文将详细探讨 PostgreSQL 中 TRUNCATE TABLE 的使用方法、性能优势以及注意事项。 什么是 …...

【JavaWeb06】Tomcat基础入门:架构理解与基本配置指南
文章目录 🌍一. WEB 开发❄️1. 介绍 ❄️2. BS 与 CS 开发介绍 ❄️3. JavaWeb 服务软件 🌍二. Tomcat❄️1. Tomcat 下载和安装 ❄️2. Tomcat 启动 ❄️3. Tomcat 启动故障排除 ❄️4. Tomcat 服务中部署 WEB 应用 ❄️5. 浏览器访问 Web 服务过程详…...

【NOI】C++程序结构入门之循环结构三-计数求和
文章目录 前言一、计数求和1.导入2.计数器3.累加器 二、例题讲解问题:1741 - 求出1~n中满足条件的数的个数和总和?问题:1002. 编程求解123...n问题:1004. 编程求1 * 2 * 3*...*n问题:1014. 编程求11/21/3...1/n问题&am…...

[Linux]Shell脚本中以指定用户运行命令
前言 当我们为Linux设置了用户自启动的shel脚本,默认会使用root用户执行启动脚本中的命令,那么我们如何在启动脚本中切换为指定用户指定命令呢。 命令 以下将列出两条命令,两条命令都可以实现以指定用户运行命令,凭喜好选择使用…...

通过 NAudio 控制电脑操作系统音量
根据您的需求,以下是通过 NAudio 获取和控制电脑操作系统音量的方法: 一、获取和控制系统音量 (一)获取系统音量和静音状态 您可以使用 NAudio.CoreAudioApi.MMDeviceEnumerator 来获取系统默认音频设备的音量和静音状态&#…...

新项目上传gitlab
Git global setup git config --global user.name “FUFANGYU” git config --global user.email “fyfucnic.cn” Create a new repository git clone gitgit.dev.arp.cn:casDs/sawrd.git cd sawrd touch README.md git add README.md git commit -m “add README” git push…...

【异步编程基础】FutureTask基本原理与异步阻塞问题
文章目录 一、FutureTask 的桥梁作用二、Future 模式与异步回调三、 FutureTask获取异步结果的逻辑1. 获取异步执行结果的步骤2. 举例说明3. FutureTask的异步阻塞问题 Runnable 用于定义无返回值的任务,而 Callable 用于定义有返回值的任务。然而,Calla…...

原生 Node 开发 Web 服务器
一、创建基本的 HTTP 服务器 使用 http 模块创建 Web 服务器 const http require("http");// 创建服务器const server http.createServer((req, res) > {// 设置响应头res.writeHead(200, { "Content-Type": "text/plain" });// 发送响应…...
—— 1.两数之和)
LeetCode热题100(一)—— 1.两数之和
LeetCode热题100(一)—— 1.两数之和 题目描述代码实现思路解析 你好,我是杨十一,一名热爱健身的程序员在Coding的征程中,不断探索与成长LeetCode热题100——刷题记录(不定期更新) 此系列文章用…...

二叉树高频题目——下——不含树型dp
一,普通二叉树上寻找两个节点的最近的公共祖先 1,介绍 LCA(Lowest Common Ancestor,最近公共祖先)是二叉树中经常讨论的一个问题。给定二叉树中的两个节点,它的LCA是指这两个节点的最低(最深&…...

vue事件总线(原理、优缺点)
目录 一、原理二、使用方法三、优缺点优点缺点 四、使用注意事项具体代码参考: 一、原理 在Vue中,事件总线(Event Bus)是一种可实现任意组件间通信的通信方式。 要实现这个功能必须满足两点要求: (1&#…...

PyCharm介绍
PyCharm的官网是https://www.jetbrains.com/pycharm/。 以下是在PyCharm官网下载和安装软件的步骤: 下载步骤 打开浏览器,访问PyCharm的官网https://www.jetbrains.com/pycharm/。在官网首页,点击“Download”按钮进入下载页面。选择适合自…...

《CPython Internals》读后感
一、 为什么选择这本书? Python 是本人工作中最常用的开发语言,为了加深对 Python 的理解,更好的掌握 Python 这门语言,所以想对 Python 解释器有所了解,看看是怎么使用C语言来实现Python的,以期达到对 Py…...

音频入门(一):音频基础知识与分类的基本流程
音频信号和图像信号在做分类时的基本流程类似,区别就在于预处理部分存在不同;本文简单介绍了下音频处理的方法,以及利用深度学习模型分类的基本流程。 目录 一、音频信号简介 1. 什么是音频信号 2. 音频信号长什么样 二、音频的深度学习分…...
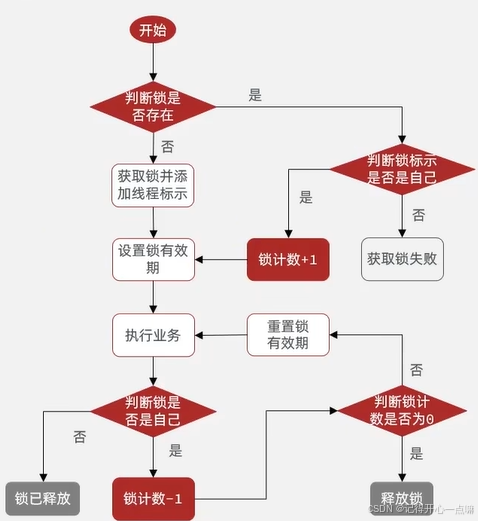
Redis --- 分布式锁的使用
我们在上篇博客高并发处理 --- 超卖问题一人一单解决方案讲述了两种锁解决业务的使用方法,但是这样不能让锁跨JVM也就是跨进程去使用,只能适用在单体项目中如下图: 为了解决这种场景,我们就需要用一个锁监视器对全部集群进行监视…...

用C++编写一个2048的小游戏
以下是一个简单的2048游戏的实现。这个实现使用了控制台输入和输出,适合在终端或命令行环境中运行。 2048游戏的实现 1.游戏逻辑 2048游戏的核心逻辑包括: • 初始化一个4x4的网格。 • 随机生成2或4。 • 处理玩家的移动操作(上、下、左、…...

【设计模式-行为型】状态模式
一、什么是状态模式 什么是状态模式呢,这里我举一个例子来说明,在自动挡汽车中,挡位的切换是根据驾驶条件(如车速、油门踏板位置、刹车状态等)自动完成的。这种自动切换挡位的过程可以很好地用状态模式来描述。状态模式…...