C++ STL:深入探索常见容器
你好呀,欢迎来到 Dong雨 的技术小栈 🌱
在这里,我们一同探索代码的奥秘,感受技术的魅力 ✨。
👉 我的小世界:Dong雨
📌 分享我的学习旅程
🛠️ 提供贴心的实用工具
💡 记录每一个灵感火花

🌟✨ Hello,探索技术的你,这里是本篇的地图指南! ✨🌟
C++ STL:深入探索常见容器
引言:高效编程的核心
C++ 标准模板库(STL)是构建高效程序的强大工具,它提供了多种容器,帮助开发者应对复杂的数据存储和操作需求。STL 容器支持广泛的操作,包括动态内存管理、灵活的元素存储、以及高效的访问与查找能力。本文将深入探讨 STL 中常见的容器,并分析它们的特性、优势和适用场景。
1. vector:动态扩展的数组
概述:
vector 是 STL 中最常用的容器之一,它实现了一个动态数组。vector 具有自动扩容的特性,能够根据实际需求调整内存大小。这使得它特别适合处理需要频繁插入和删除元素的场景,尤其是当元素数量不确定时。
使用场景:
vector 适用于需要频繁访问元素、存储大量数据、并且数据规模动态变化的应用场景,如:
- 存储大量数字数据或对象。
- 图像处理中的像素数据。
- 快速随机访问的应用。
头文件:
#include <vector>
using namespace std;
初始化:
vector<int> vec = {1, 2, 3, 4}; // 使用列表初始化
常用方法:
push_back(value):将元素添加到vector的末尾。pop_back():移除vector末尾的元素。at(index):获取指定位置的元素,提供越界检查。size():返回vector中元素的数量。reserve(n):预先为vector分配内存,以避免在频繁添加元素时导致多次扩容。
深入分析:
vector 提供了 O(1) 时间复杂度的随机访问,且支持 动态扩容。当 vector 的容量不足以容纳新元素时,它会自动扩容,通常扩展为原来的两倍,这样就能确保每次扩容时的操作成本较低(均摊复杂度为 O(1))。然而,vector 的扩容也有其开销,尤其是当容器中的元素非常大时,内存重新分配和元素拷贝可能会影响性能。
示例代码:
#include <iostream>
#include <vector>
using namespace std;int main() {vector<int> numbers = {1, 2, 3, 4}; // 初始化 vectornumbers.push_back(5); // 添加元素// 输出 vector 中的所有元素cout << "Vector contents: ";for (const auto& num : numbers) {cout << num << " ";}cout << endl;cout << "Vector size: " << numbers.size() << endl; // 获取大小return 0;
}
输出:
Vector contents: 1 2 3 4 5
Vector size: 5
2. stack:后进先出(LIFO)容器
概述:
stack 是遵循后进先出(LIFO)原则的容器。stack 只允许从顶端进行插入和删除操作,因此特别适合处理递归问题和需要回溯的任务。
使用场景:
stack 常用于以下场景:
- 深度优先搜索(DFS)算法。
- 撤销操作。
- 表达式求值(如括号匹配问题)。
头文件:
#include <stack>
using namespace std;
初始化:
stack<int> s;
常用方法:
push(value):将元素压入栈顶。pop():移除栈顶元素。top():访问栈顶元素。empty():检查栈是否为空。size():返回栈中元素的数量。
深入分析:
stack 底层通常使用 deque 或 vector 来实现,因此它的时间复杂度是 O(1),无论是入栈还是出栈。stack 只提供对栈顶元素的访问,不支持中间元素的访问。适合用来处理先进后出的操作,但若需要频繁查找其他元素时,应考虑其他数据结构。
示例代码:
#include <iostream>
#include <stack>
using namespace std;int main() {stack<int> s;// 压入元素s.push(1);s.push(2);s.push(3);// 输出栈顶元素cout << "Stack top: " << s.top() << endl;// 弹出栈顶元素s.pop();cout << "New stack top: " << s.top() << endl;return 0;
}
输出:
Stack top: 3
New stack top: 2
3. queue:先进先出(FIFO)队列
概述:
queue 是遵循先进先出(FIFO)规则的容器,常用于需要按顺序处理任务的场景。
使用场景:
queue 常用于:
- 事件驱动程序。
- 任务调度(如操作系统中的进程调度)。
- 异步消息传递。
头文件:
#include <queue>
using namespace std;
初始化:
queue<int> q;
常用方法:
push(value):将元素加入队列。pop():移除队列头部元素。front():访问队列头部元素。back():访问队列尾部元素。empty():检查队列是否为空。size():返回队列中元素的数量。
深入分析:
queue 是基于 双端队列(deque)实现的,它的操作复杂度为 O(1)。队列的操作仅限于队首和队尾,因此它在需要保持顺序处理任务的场景中非常高效。但在需要从队列中间插入或删除元素时,队列并不是一个好的选择。
示例代码:
#include <iostream>
#include <queue>
using namespace std;int main() {queue<int> q;// 入队q.push(10);q.push(20);q.push(30);// 输出队列头部元素cout << "Queue front: " << q.front() << endl;// 出队q.pop();cout << "New queue front: " << q.front() << endl;return 0;
}
输出:
Queue front: 10
New queue front: 20
4. deque:双端队列
概述:
deque 是一个可以从两端插入和删除元素的容器。与 vector 相比,deque 更适合需要从两端频繁操作元素的场景。
使用场景:
deque 常用于:
- 滑动窗口问题。
- 双向任务队列。
- 游戏中的消息队列。
头文件:
#include <deque>
using namespace std;
初始化:
deque<int> dq = {1, 2, 3, 4};
常用方法:
push_front(value):将元素添加到队列前端。push_back(value):将元素添加到队列末端。pop_front():移除队列前端的元素。pop_back():移除队列末端的元素。front():访问队列前端元素。back():访问队列末端元素。size():返回队列中元素的数量。
深入分析:
deque 允许在队列两端进行插入和删除操作,因此它比 vector 更适合双向操作。其底层通常是由多个块构成的结构,这使得它的空间效率较高,但相较于 vector,它的访问元素速度稍慢,尤其是对尾端元素的访问。因此,deque 在某些双端任务中表现优越,但若只在一端操作,vector 可能更高效。
示例代码:
#include #include using namespace std;int main() { deque dq = {1, 2, 3, 4};
// 添加元素到队头
dq.push_front(0);
// 添加元素到队尾
dq.push_back(5);// 输出队列元素
cout << "Deque contents: ";
for (const auto& val : dq) {cout << val << " ";
}
cout << endl;return 0;
}
输出:
Deque contents: 0 1 2 3 4 5
5. priority_queue:优先级队列
概述:
priority_queue 是一个根据优先级排序的队列,默认情况下使用最大堆实现。它允许快速访问最大或最小元素,但不像常规队列一样按顺序处理元素。priority_queue 保证每次出队的元素都是当前队列中的最大(或最小)元素。
使用场景:
priority_queue 常用于:
- 排序问题。
- 实现 Dijkstra 算法、A* 算法等图搜索算法。
- 实现事件驱动系统中的优先级任务调度。
头文件:
#include <queue>
using namespace std;
初始化:
priority_queue<int> pq;
常用方法:
push(value):将元素加入优先级队列。pop():移除队列中的最大元素。top():访问优先级队列中的最大元素。empty():检查队列是否为空。size():返回队列中元素的数量。
深入分析:
priority_queue 的底层通常使用最大堆或最小堆(通过自定义比较器来改变堆的顺序)。由于堆的性质,push 和 pop 操作的时间复杂度为 O(log n)。虽然它非常适合用于按优先级处理元素,但它不支持访问中间元素或随机访问,因此如果需要按特定条件查找元素,priority_queue 可能不是最佳选择。
示例代码:
#include <iostream>
#include <queue>
using namespace std;int main() {priority_queue<int> pq;// 向优先级队列中添加元素pq.push(10);pq.push(20);pq.push(15);// 输出优先级队列中的最大元素cout << "Top element: " << pq.top() << endl;// 移除最大元素pq.pop();cout << "New top element: " << pq.top() << endl;return 0;
}
输出:
Top element: 20
New top element: 15
6. map:键值对存储(红黑树)
概述:
map 是一种关联容器,用于存储键值对。map 中的每个元素都由一个唯一的键和一个与之关联的值组成,且元素按键的顺序自动排序。map 默认使用 红黑树 实现,保证了插入、查找、删除操作的时间复杂度为 O(log n)。
使用场景:
map 常用于:
- 需要根据键高效查找值的场景。
- 实现频率计数、符号表等数据结构。
- 数据按键排序的场景。
头文件:
#include <map>
using namespace std;
初始化:
map<int, string> m;
常用方法:
insert({key, value}):向map插入键值对。erase(key):删除指定键的元素。find(key):查找指定键的元素。at(key):访问指定键的值,若键不存在抛出异常。size():返回map中的元素数量。
深入分析:
map 是一个基于红黑树实现的排序容器,因此所有的键值对都保持按键排序的状态。这使得 map 在需要排序数据或进行键查找时非常高效。然而,由于其底层结构的特性,map 中的元素不能像 unordered_map 那样以 O(1) 时间复杂度进行查找。
示例代码:
#include <iostream>
#include <map>
using namespace std;int main() {map<int, string> m;// 向 map 中插入元素m.insert({1, "Apple"});m.insert({2, "Banana"});m[3] = "Cherry";// 输出所有键值对for (const auto& p : m) {cout << p.first << ": " << p.second << endl;}return 0;
}
输出:
1: Apple
2: Banana
3: Cherry
7. set:无重复的有序集合
概述:
set 是一个集合类型的容器,存储的是唯一元素,并且按照升序(或自定义顺序)排列。set 的实现通常基于 红黑树,所以它的插入、删除和查找操作都具有 O(log n) 的时间复杂度。
使用场景:
set 适用于:
- 需要无重复元素的场景。
- 元素按特定顺序进行排序的需求。
- 需要高效查找、插入和删除的场景。
头文件:
#include <set>
using namespace std;
初始化:
set<int> s;
常用方法:
insert(value):将元素插入集合。erase(value):删除指定的元素。find(value):查找元素。size():返回集合中元素的数量。empty():检查集合是否为空。
深入分析:
set 内部使用红黑树保持元素有序,支持自动排序,因此其插入、查找、删除操作的时间复杂度为 O(log n)。但是,set 不允许重复元素,因此在插入元素时,如果元素已经存在,它不会再次插入。
示例代码:
#include <iostream>
#include <set>
using namespace std;int main() {set<int> s;// 插入元素s.insert(1);s.insert(2);s.insert(3);// 输出所有元素cout << "Set contents: ";for (const auto& elem : s) {cout << elem << " ";}cout << endl;return 0;
}
输出:
Set contents: 1 2 3
8. pair:存储两个元素的组合
概述:
pair 是一个简单的容器,用于存储两个相关联的元素。pair 是一个模板类,可以用来存储任何两种类型的值。
使用场景:
pair 常用于:
- 关联两个不同类型的数据。
- 作为返回值,尤其是函数需要返回多个相关的值时。
- 与
map、set一起使用来存储键值对。
头文件:
#include <utility>
using namespace std;
初始化:
pair<int, string> p = {1, "Apple"};
常用方法:
first:访问pair的第一个元素。second:访问pair的第二个元素。
深入分析:
pair 提供了一个简单而有效的方式来将两个不同类型的数据捆绑在一起。它的访问非常方便,直接通过 first 和 second 成员进行访问。pair 在处理关联数据(如键值对)时非常有用。
示例代码:
#include <iostream>
#include <utility>
using namespace std;int main() {pair<int, string> p = {1, "Apple"};// 输出 pair 中的元素cout << "First: " << p.first << ", Second: " << p.second << endl;return 0;
}
输出:
First: 1, Second: Apple
9. string:动态字符数组
概述:
string 是 C++ 标准库中用于处理文本数据的类。它支持动态调整大小,能够灵活处理字符串的插入、删除、查找和替换等操作。
使用场景:
string 常用于:
- 处理动态长度的文本数据。
- 文件操作、网络协议解析、用户输入等。
头文件:
#include <string>
using namespace std;
初始化:
string s = "Hello, world!";
常用方法:
length():返回字符串的长度。empty():检查字符串是否为空。append(str):向字符串末尾追加内容。find(substr):查找子字符串的位置。substr(start, length):返回子字符串。
深入分析:
string 类是一个非常强大且灵活的容器,提供了大量处理文本数据的函数。string 内部使用动态数组,因此能够自动扩展其容量。字符串操作通常涉及到字符的复制、移动或插入,所以操作时需要特别注意效率和内存管理。
示例代码:
#include <iostream>
#include <string>
using namespace std;int main() {string s = "Hello, world!";// 查找字符串中的字符位置cout << "Found 'world' at position: " << s.find("world") << endl;// 取子字符串string sub = s.substr(7, 5);cout << "Sub-string: " << sub << endl;return 0;
}
输出:
Found 'world' at position: 7
Sub-string: world
10. bitset:固定大小的位集合
概述:
bitset 是一个用于处理固定数量位的容器,提供对位的操作。bitset 可以用来进行二进制操作、实现位掩码等应用。它的大小在编译时就已确定,因此非常高效。
使用场景:
bitset 常用于:
- 位掩码和位操作。
- 存储和操作二进制状态数据。
- 实现某些低级算法(如布尔运算)。
头文件:
#include <bitset>
using namespace std;
初始化:
bitset<8> b1; // 默认值为 00000000
bitset<8> b2("10101010"); // 初始化为二进制字符串
常用方法:
set(pos):将指定位置的位设为 1。reset(pos):将指定位置的位设为 0。flip(pos):翻转指定位置的位。size():返回 bitset 的大小。count():返回 1 的位数。
深入分析:
bitset 是一个非常高效的位操作工具。它使用固定大小的数组来存储位,并提供直接的位操作方法。由于其大小在编译时就已确定,因此对于存储较小二进制数据非常合适。不过,bitset 不适合动态大小的位集合,且无法像 vector 那样随时扩展。
示例代码:
#include <iostream>
#include <bitset>
using namespace std;int main() {bitset<8> b1("10101010");// 输出 bitset 的内容cout << "Initial bitset: " << b1 << endl;// 翻转第 2 位b1.flip(2);cout << "After flipping 2nd bit: " << b1 << endl;// 获取 1 的位数cout << "Number of 1s: " << b1.count() << endl;return 0;
}
输出:
Initial bitset: 10101010
After flipping 2nd bit: 10100010
Number of 1s: 3
11. array:固定大小的数组
概述:
array 是 C++11 引入的一个容器,它是一个固定大小的数组容器。与 C 风格数组不同,array 是一个模板类,它支持 STL 容器的所有常用操作(如迭代器、排序等),但大小在编译时就已经确定。
使用场景:
array 适用于:
- 需要固定大小数组的场景。
- 需要类似于传统数组的性能,且希望获得更强大的 STL 操作支持时。
头文件:
#include <array>
using namespace std;
初始化:
array<int, 5> arr = {1, 2, 3, 4, 5};
常用方法:
at(index):返回指定位置的元素。size():返回数组的大小。fill(value):将所有元素初始化为相同的值。front():返回第一个元素。back():返回最后一个元素。
深入分析:
array 使得 C 风格数组拥有了 STL 容器的一些优势。它的大小固定,因此可以在栈上高效分配。相比于 vector,array 不支持动态扩展,但它提供了更强大的 STL 接口和更高的类型安全性。适合存储大小固定的数据。
示例代码:
#include <iostream>
#include <array>
using namespace std;int main() {array<int, 5> arr = {1, 2, 3, 4, 5};// 输出数组的元素cout << "Array elements: ";for (const auto& elem : arr) {cout << elem << " ";}cout << endl;// 修改第一个元素arr[0] = 10;cout << "After modifying first element: " << arr[0] << endl;return 0;
}
输出:
Array elements: 1 2 3 4 5
After modifying first element: 10
12. tuple:异构容器
概述:
tuple 是一个可以存储多个不同类型元素的容器。与 pair 类似,tuple 可以包含多个不同类型的元素,并且支持访问每个元素。tuple 提供了一种灵活的方式来捆绑多种类型的数据。
使用场景:
tuple 适用于:
- 返回多个不同类型的值的函数。
- 存储多个不同类型的参数或数据。
- 元素数量在编译时已知的场景。
头文件:
#include <tuple>
using namespace std;
初始化:
tuple<int, string, float> t = {1, "Apple", 3.14};
常用方法:
get<index>(tuple):访问指定索引的元素。tuple_size<tuple>::value:返回tuple的大小。make_tuple():创建一个tuple。
深入分析:
tuple 是 C++ 中的一个非常灵活的容器,能够存储不同类型的数据。虽然它不如 vector 或 map 那样高频使用,但在需要处理多种类型的函数返回值或数据组合时非常有用。tuple 支持通过索引和类型访问元素。
示例代码:
#include <iostream>
#include <tuple>
using namespace std;int main() {tuple<int, string, float> t = {1, "Apple", 3.14};// 访问 tuple 中的元素cout << "First: " << get<0>(t) << ", Second: " << get<1>(t) << ", Third: " << get<2>(t) << endl;// 修改 tuple 中的元素get<1>(t) = "Banana";cout << "Modified tuple: " << get<0>(t) << ", " << get<1>(t) << ", " << get<2>(t) << endl;return 0;
}
输出:
First: 1, Second: Apple, Third: 3.14
Modified tuple: 1, Banana, 3.14
总结:
在这篇博客中,我们深入分析了 C++ STL 中的常用容器。每个容器都有其特定的使用场景和优缺点。在实际开发中,选择合适的容器是编写高效和易于维护代码的关键。了解每个容器的工作原理、常用方法以及深入分析将帮助你在复杂的应用中做出更好的选择。
通过对以下容器的详细讲解和示例,你可以清晰地了解每个容器的特性和应用场景:
- vector:动态数组,适用于需要快速随机访问的场景。
- stack:栈,适用于后进先出(LIFO)的场景。
- queue:队列,适用于先进先出(FIFO)的场景。
- deque:双端队列,适用于两端操作都频繁的场景。
- priority_queue:优先级队列,适用于按优先级排序的场景。
- map:键值对容器,适用于根据键查找值的场景。
- set:无重复元素的有序集合,适用于去重和排序的场景。
- pair:存储两个相关元素的组合,常用于
map中。 - string:动态字符串,适用于文本处理的场景。
- bitset:固定大小的位集合,适用于位运算的场景。
- array:固定大小的数组,适用于大小已知且不变的场景。
- tuple:存储多个不同类型元素的容器,适用于函数返回多个不同类型值的场景。
每个容器的底层实现和时间复杂度有所不同,选择正确的容器能显著提高程序的性能和可维护性。希望这篇文章能帮助你更好地理解 C++ STL 容器的使用和选择。
🎉🌈 陪伴至此,感谢有你 🌈🎉
感谢你能坚持看到这里!如果这篇文章对你有一点点帮助,希望能收获你的:
👍 一个赞,⭐ 一个收藏,💬 一条评论 或 🔗 一键分享!
你的支持是我持续输出的最大动力!✨有问题?有灵感?
别犹豫,直接留言和我交流~让我们一起成长、一起突破 💡。最后,祝你:
🍯 生活美满如蜜香
🌞 心情灿烂似朝阳
🌱 成长如树渐成章
🚀 未来闪耀梦飞翔!再次感谢你的阅读!🌟 下次再见~ 🎉

相关文章:
C++ STL:深入探索常见容器
你好呀,欢迎来到 Dong雨 的技术小栈 🌱 在这里,我们一同探索代码的奥秘,感受技术的魅力 ✨。 👉 我的小世界:Dong雨 📌 分享我的学习旅程 🛠️ 提供贴心的实用工具 💡 记…...

android12源码中用第三方APK替换原生launcher
一、前言 如何用第三方的apk替换原生launcher呢?我是参考着这位大神的博客https://blog.csdn.net/hyu001/article/details/131044358做的,完美实现。 这边博客中又加入了我个人的一些改变,整理的。 二、步骤 1.在/packages/apps/MyApp文件…...

Java面试题2025-设计模式
1.说一下开发中需要遵守的设计原则? 设计模式中主要有六大设计原则,简称为SOLID ,是由于各个原则的首字母简称合并的来(两个L算一个,solid 稳定的),六大设计原则分别如下: 1、单一职责原则 单一职责原则的定义描述非…...

【设计模式-行为型】备忘录模式
一、什么是备忘录模式 来到备忘录模式了,这个模式我感觉相对简单一些,就是备份,或者快照。跟前面一样为了加深理解,我们引入一个电影情结来说明啥是备忘录模式,以来加深大家对备忘录模式的认识。那么,在电影…...

flink StreamGraph解析
Flink程序有三部分operation组成,分别是源source、转换transformation、目的地sink。这三部分构成DAG。 DAG首先生成的是StreamGraph。 用户代码在添加operation的时候会在env中缓存(变量transformations),在env.execute()执行的…...

本地AI模型:未来智能设备的核心驱动力
标题:“本地AI模型:未来智能设备的核心驱动力” 文章信息摘要: 未来AI设备(如Meta Ray-Bans)的发展将更加依赖本地语言模型的优化与集成,而非仅依靠云端AI模型。本地模型在隐私保护、推理速度和离线访问方…...

基于SpringBoot的网上摄影工作室开发与实现 | 含论文、任务书、选题表
随着互联网技术的不断发展,摄影爱好者们越来越需要一个在线平台来展示和分享他们的作品。基于SpringBoot的网上摄影工作室应运而生,它不仅为用户提供了一个展示摄影作品的平台,还为管理员提供了便捷的管理工具。本文幽络源将详细介绍该系统的…...

数字人+展厅应用方案:开启全新沉浸式游览体验
随着人们生活质量的不断提升,对于美好体验的追求日益增长。在展厅展馆领域,传统的展示方式已难以满足大众日益多样化的需求。而通过将数字人与展厅进行深度结合,可以打造数字化、智能化新型展厅,不仅能提升展示效果,还…...

基于单片机的家用无线火灾报警系统的设计
1 总体设计 本设计家用无线火灾报警系统利用单片机控制技术、传感器检测技术、GSM通信技术展开设计,如图2.1所示为本次系统设计的主体框图,系统包括单片机主控模块、温度检测模块、烟雾检测模块、按键模块、GSM通信模块、液晶显示模块、蜂鸣器报警模块。…...

多级缓存(亿级并发解决方案)
多级缓存(亿级流量(并发)的缓存方案) 传统缓存的问题 传统缓存是请求到达tomcat后,先查询redis,如果未命中则查询数据库,问题如下: (1)请求要经过tomcat处…...

iic、spi以及uart
何为总线? 连接多个部件的信息传输线,是部件共享的传输介质 总线的作用? 实现数据传输,即模块之间的通信 总线如何分类? 根据总线连接的外设属于内部外设还是外部外设将总线可以分为片内总线和片外总线 可分为数…...

Shell编程(for循环+并发问题+while循环+流程控制语句+函数传参+函数变量+函数返回值+反向破解MD5)
本篇文章继续给大家介绍Shell编程,包括for循环、并发问题,while循环,流程控制语句,函数传参、函数变量、函数返回值,反向破解MD5等内容。 1.for循环 for 变量 in [取值列表] 取值列表可以是数字 字符串 变量 序列…...

深入 Rollup:从入门到精通(三)Rollup CLI命令行实战
准备阶段:初始化项目 初始化项目,这里使用的是pnpm,也可以使用yarn或者npm # npm npm init -y # yarn yarn init -y # pnpm pnpm init安装rollup # npm npm install rollup -D # yarn yarn add rollup -D # pnpm pnpm install rollup -D在…...

CycleGAN模型解读(附源码+论文)
CycleGAN 论文链接:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 官方链接:pytorch-CycleGAN-and-pix2pix 老规矩,先看看效果 总体流程 先简单过一遍流程,细节在代码里说。CycleGAN有…...

线程配置经验
工作时,时常会遇到,线程相关的问题与解法,本人会持续对开发过程中遇到的关于线程相关的问题及解决记录更新记录在此篇博客中。 目录 一、线程基本知识 1. 线程和进程 二、问题与解法 1. 避免乘法级别数量线程并行 1)使用线程池…...
)
动态规划DP 数字三角形模型 传纸条(题目分析+C++完整代码)
传纸条 原题链接 AcWing 275. 传纸条 题目描述 小渊和小轩是好朋友也是同班同学,他们在一起总有谈不完的话题。 一次素质拓展活动中,班上同学安排坐成一个 m行 n 列的矩阵,而小渊和小轩被安排在矩阵对角线的两端,因此&#x…...

Ubuntu二进制部署K8S 1.29.2
本机说明 本版本非高可用,单Master,以及一个Node 新装的 ubuntu 22.04k8s 1.29.3使用该文档请使用批量替换 192.168.44.141这个IP,其余照着复制粘贴就可以成功需要手动 设置一个 固定DNS,我这里设置的是 8.8.8.8不然coredns无法…...

第05章 10 地形梯度场模拟显示
在 VTK(Visualization Toolkit)中,可以通过计算地形数据的梯度场,并用箭头或线条来表示梯度方向和大小,从而模拟显示地形梯度场。以下是一个示例代码,展示了如何使用 VTK 和 C 来计算和显示地形数据的梯度场…...

全程Kali linux---CTFshow misc入门
图片篇(基础操作) 第一题: ctfshow{22f1fb91fc4169f1c9411ce632a0ed8d} 第二题 解压完成后看到PNG,可以知道这是一张图片,使用mv命令或者直接右键重命名,修改扩展名为“PNG”即可得到flag。 ctfshow{6f66202f21ad22a2a19520cdd…...

[ Spring ] Spring Cloud Alibaba Message Stream Binder for RocketMQ 2025
文章目录 IntroduceProject StructureDeclare Plugins and ModulesApply Plugins and Add DependenciesSender PropertiesSender ApplicationSender ControllerReceiver PropertiesReceiver ApplicationReceiver Message HandlerCongratulationsAutomatically Send Message By …...
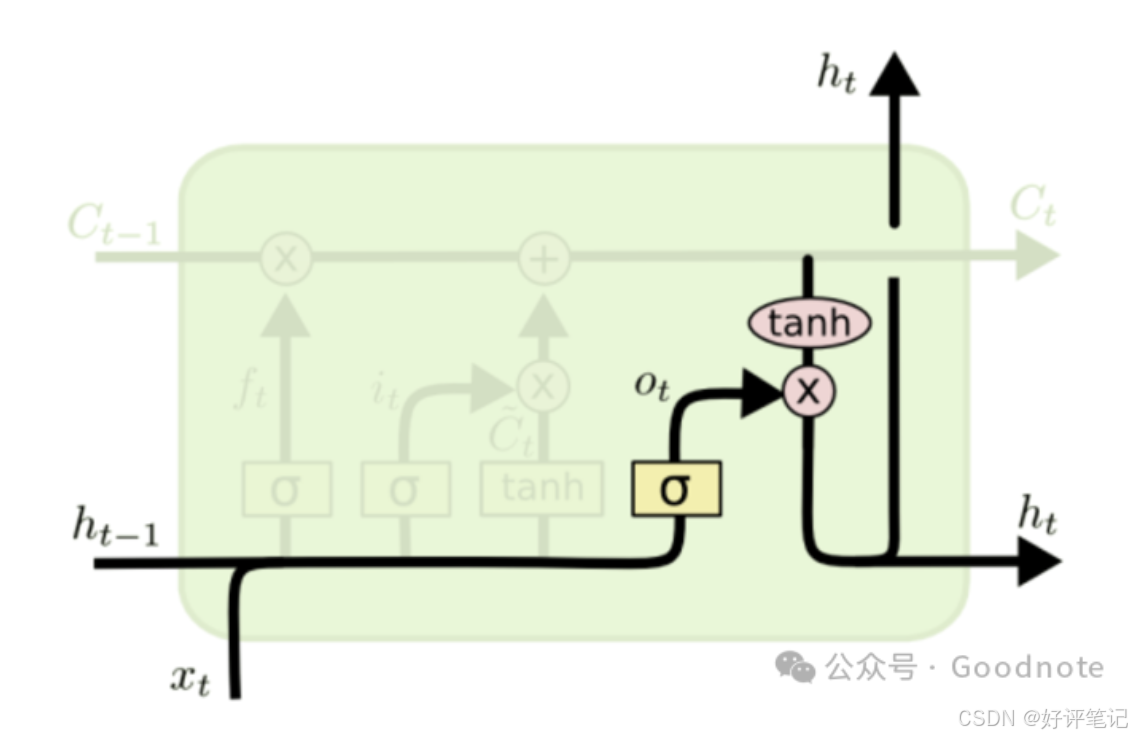
深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...

AI 模型评估与质量控制:生成内容的评估与问题防护
在生成式 AI 应用中,模型生成的内容质量直接影响用户体验。然而,生成式模型存在一定风险,如幻觉(Hallucination)问题——生成不准确或完全虚构的内容。因此,在构建生成式 AI 应用时,模型评估与质…...

[MILP] Logical Constraints 0-1 (Note2)
1. 如果选择了项目1,则项目2,3也要求被选中 表示为: 2. 如果确定了选项目1,则接下来必须选项目2或者项目3 表示为: or 3. 如果同时选择了项目2和项目3,则不可以选择项目1 表示为: 4. 如果…...

DFFormer实战:使用DFFormer实现图像分类任务(二)
文章目录 训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整策略设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法 运行以及结果查看测试完整的代码 在上…...

蓝桥杯例题四
每个人都有无限潜能,只要你敢于去追求,你就能超越自己,实现梦想。人生的道路上会有困难和挑战,但这些都是成长的机会。不要被过去的失败所束缚,要相信自己的能力,坚持不懈地努力奋斗。成功需要付出汗水和努…...

如何复现o1模型,打造医疗 o1?
如何复现o1模型,打造医疗 o1? o1 树搜索一、起点:预训练规模触顶与「推理阶段(Test-Time)扩展」的动机二、Test-Time 扩展的核心思路与常见手段1. Proposer & Verifier 统一视角方法1:纯 Inference Sca…...

PostgreSQL TRUNCATE TABLE 操作详解
PostgreSQL TRUNCATE TABLE 操作详解 引言 在数据库管理中,经常需要对表进行操作以保持数据的有效性和一致性。TRUNCATE TABLE 是 PostgreSQL 中一种高效删除表内所有记录的方法。本文将详细探讨 PostgreSQL 中 TRUNCATE TABLE 的使用方法、性能优势以及注意事项。 什么是 …...

【JavaWeb06】Tomcat基础入门:架构理解与基本配置指南
文章目录 🌍一. WEB 开发❄️1. 介绍 ❄️2. BS 与 CS 开发介绍 ❄️3. JavaWeb 服务软件 🌍二. Tomcat❄️1. Tomcat 下载和安装 ❄️2. Tomcat 启动 ❄️3. Tomcat 启动故障排除 ❄️4. Tomcat 服务中部署 WEB 应用 ❄️5. 浏览器访问 Web 服务过程详…...

【NOI】C++程序结构入门之循环结构三-计数求和
文章目录 前言一、计数求和1.导入2.计数器3.累加器 二、例题讲解问题:1741 - 求出1~n中满足条件的数的个数和总和?问题:1002. 编程求解123...n问题:1004. 编程求1 * 2 * 3*...*n问题:1014. 编程求11/21/3...1/n问题&am…...

[Linux]Shell脚本中以指定用户运行命令
前言 当我们为Linux设置了用户自启动的shel脚本,默认会使用root用户执行启动脚本中的命令,那么我们如何在启动脚本中切换为指定用户指定命令呢。 命令 以下将列出两条命令,两条命令都可以实现以指定用户运行命令,凭喜好选择使用…...