【Elasticsearch】内置分词器和IK分词器
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c=1000,移动端可微信小程序搜索“历代文学”)总架构师,
15年工作经验,精通Java编程,高并发设计,Springboot和微服务,熟悉Linux,ESXI虚拟化以及云原生Docker和K8s,热衷于探索科技的边界,并将理论知识转化为实际应用。保持对新技术的好奇心,乐于分享所学,希望通过我的实践经历和见解,启发他人的创新思维。在这里,我希望能与志同道合的朋友交流探讨,共同进步,一起在技术的世界里不断学习成长。
技术合作请加本人wx(注明来自csdn):foreast_sea


【Elasticsearch】内置分词器和IK分词器
引言
在当今数字化信息爆炸的时代,全文搜索技术成为了我们获取所需信息的关键工具。无论是在搜索引擎中查找资料,还是在企业内部系统中检索文档,全文搜索都发挥着至关重要的作用。而在全文搜索的背后,文本分析扮演着核心角色。
文本分析,简单来说,就是将文本内容转换为可被搜索的词项的过程。想象一下,一篇长篇文档包含了大量的文字,搜索引擎如何能快速准确地找到与用户查询相关的内容呢?这就需要通过文本分析,把文档中的文本切割成一个个有意义的词项,建立索引,当用户发起查询时,能够迅速匹配到相应的词项,从而返回相关的文档。
Elasticsearch作为一款强大的分布式搜索和分析引擎,提供了丰富的文本分析功能,其中分词器是关键组件之一。分词器决定了如何将文本拆分成词项,不同的分词器有着不同的工作原理和分词规则,适用于各种不同的场景。同时,为了满足特定语言和业务需求,我们还可以引入第三方分词器,如IK分词器。
在这篇博文中,我们将深入探讨Elasticsearch的内置分词器和IK分词器。首先,我们会详细了解内置分词器的工作原理、使用方式以及它们的特点。然后,我们将一步步介绍如何下载、集成和使用IK分词器,通过实际的Java API案例展示其强大功能。通过本文的学习,你将对Elasticsearch的分词机制有更深入的理解,能够根据具体的业务需求选择合适的分词器,提升全文搜索的效果和性能。
一、Elasticsearch 简介
Elasticsearch是一个基于Lucene的分布式、RESTful风格的搜索和数据分析引擎。它旨在快速地存储、搜索和分析大量的数据,被广泛应用于各种领域,如日志分析、电商搜索、企业内容管理等。
Elasticsearch的核心优势在于其分布式架构,能够处理PB级别的数据,并提供高可用性和可扩展性。它通过将数据分片存储在多个节点上,实现数据的并行处理和容错能力。同时,Elasticsearch提供了简单易用的RESTful API,方便开发者进行数据的索引、搜索和管理。
1.1 核心概念
- 索引(Index):类似于关系型数据库中的数据库概念,是一组文档的集合。每个索引都有自己的映射(Mapping),定义了文档的结构和字段类型。
- 文档(Document):是Elasticsearch中存储的基本数据单元,类似于关系型数据库中的一行记录。文档以JSON格式存储,包含一个或多个字段。
- 类型(Type):在早期版本中,一个索引可以包含多个类型,用于区分不同结构的文档。但从Elasticsearch 7.0开始,逐渐弃用了类型的概念,一个索引通常只包含一种类型的文档。
- 分片(Shard):索引被分成多个分片,每个分片是一个独立的Lucene索引。分片可以分布在不同的节点上,实现数据的并行处理和水平扩展。
- 副本(Replica):为了提高数据的可用性和搜索性能,每个分片可以有多个副本。副本会自动同步主分片的数据,当主分片出现故障时,副本可以自动提升为主分片。
1.2 全文搜索原理
在Elasticsearch中,全文搜索的实现依赖于倒排索引(Inverted Index)。倒排索引是一种数据结构,它将文档中的每个词项映射到包含该词项的文档列表。当用户发起查询时,Elasticsearch首先对查询语句进行分词,然后在倒排索引中查找匹配的词项,最后根据词项找到对应的文档,并根据相关性对文档进行排序,返回给用户。
二、Elasticsearch 内置分词器
Elasticsearch提供了多种内置分词器,每种分词器都有其独特的工作原理和适用场景。下面我们将详细介绍几种常用的内置分词器。
2.1 Standard 分词器
- 工作原理:Standard分词器是Elasticsearch默认的分词器,它基于Unicode文本分割算法,按照词的边界进行分词。它会将文本中的单词、数字、标点符号等分开,同时将所有词项转换为小写形式。
- 分词规则:
- 按照Unicode文本分割算法识别词的边界。
- 将所有词项转换为小写。
- 去除停用词(如“the”、“and”、“is”等),但默认情况下不启用停用词过滤。
- 特点:
- 通用性强,适用于大多数语言的文本分析。
- 简单高效,能够快速地对文本进行分词。
- 对英文文本的分词效果较好,但对于一些特殊语言(如中文),可能需要进一步的处理。
示例:
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;public class StandardAnalyzerExample {public static void main(String[] args) throws Exception {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));SearchRequest searchRequest = new SearchRequest("your_index");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("your_field", "This is a test sentence."));searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest);SearchHits hits = searchResponse.getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}client.close();}
}
在上述示例中,我们使用Standard分词器对文本“This is a test sentence.”进行分词,它会将其分成“this”、“is”、“a”、“test”、“sentence”等词项。
2.2 Whitespace 分词器
- 工作原理:Whitespace分词器简单地按照空白字符(如空格、制表符、换行符等)对文本进行分词,不会对词项进行任何转换或过滤。
- 分词规则:
- 以空白字符作为分隔符,将文本分割成词项。
- 保留词项的原始大小写形式。
- 特点:
- 非常简单直观,适用于需要保留原始词项格式的场景。
- 不进行词项的转换和过滤,可能会导致分词结果中包含一些无意义的词项(如标点符号)。
示例:
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;public class WhitespaceAnalyzerExample {public static void main(String[] args) throws Exception {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));SearchRequest searchRequest = new SearchRequest("your_index");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("your_field", "This is a test sentence."));searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest);SearchHits hits = searchResponse.getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}client.close();}
}
在这个示例中,Whitespace分词器会将文本“This is a test sentence.”分成“This”、“is”、“a”、“test”、“sentence”,保留了每个词项的原始大小写。
2.3 Keyword 分词器
- 工作原理:Keyword分词器不会对文本进行分词,而是将整个文本作为一个词项。它适用于需要精确匹配的场景,如ID字段、分类标签等。
- 分词规则:
- 将输入的文本作为一个整体词项。
- 不进行任何分词操作,保留原始文本。
- 特点:
- 适用于需要精确匹配的字段,如产品ID、用户ID等。
- 不进行分词,因此在搜索时不会进行词项的拆分和匹配,速度较快。
示例:
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;public class KeywordAnalyzerExample {public static void main(String[] args) throws Exception {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));SearchRequest searchRequest = new SearchRequest("your_index");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("your_field", "This is a test sentence."));searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest);SearchHits hits = searchResponse.getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}client.close();}
}
在这个例子中,Keyword分词器会将整个文本“This is a test sentence.”作为一个词项,在搜索时只有输入完全相同的文本才能匹配到。
2.4 其他内置分词器
除了上述三种分词器外,Elasticsearch还提供了许多其他内置分词器,如:
- Simple分词器:按照非字母字符对文本进行分词,并将词项转换为小写。
- Stop分词器:在Simple分词器的基础上,去除停用词。
- Snowball分词器:支持多种语言的词干提取,能够将单词还原为词干形式,提高搜索的召回率。
不同的分词器适用于不同的语言和业务场景,开发者需要根据具体需求选择合适的分词器。
三、IK分词器
IK分词器是一个开源的、基于Java的轻量级中文分词器,它在Elasticsearch中得到了广泛的应用。IK分词器提供了两种分词模式:细粒度(ik_smart)和粗粒度(ik_max_word),能够满足不同场景下的中文分词需求。
3.1 下载IK分词器
IK分词器的下载和安装步骤如下:
- 首先,确定你使用的Elasticsearch版本,IK分词器需要与Elasticsearch版本兼容。可以在IK分词器的官方GitHub仓库中查看版本对应关系。
- 下载适合你Elasticsearch版本的IK分词器插件。可以从GitHub仓库的发布页面下载对应的zip包。
- 将下载的zip包解压到Elasticsearch的plugins目录下。例如,如果你将Elasticsearch安装在/elasticsearch目录下,那么将解压后的文件放置在/elasticsearch/plugins/ik目录下。
- 重启Elasticsearch服务,使IK分词器插件生效。
3.2 集成IK分词器到Elasticsearch
在Elasticsearch中集成IK分词器非常简单,只需要在索引映射中指定使用IK分词器即可。以下是一个示例:
PUT /your_index
{"mappings": {"properties": {"your_field": {"type": "text","analyzer": "ik_smart","search_analyzer": "ik_smart"}}}
}
在上述示例中,我们创建了一个名为your_index的索引,并在映射中定义了一个名为your_field的文本字段,指定使用ik_smart分词器进行索引和搜索时的分词。
3.3 使用IK分词器的Java API调用
在Java中使用IK分词器进行搜索,我们需要使用Elasticsearch的Java客户端。以下是一个完整的示例:
3.3.1 添加Maven依赖
首先,在你的项目的pom.xml文件中添加Elasticsearch的Java客户端依赖:
<dependencies><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.17.4</version></dependency><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.13</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.17.4</version></dependency>
</dependencies>
上述依赖中,elasticsearch-rest-high-level-client是Elasticsearch的高级REST客户端,用于与Elasticsearch进行交互;httpclient是Apache HttpClient库,用于处理HTTP请求;elasticsearch是Elasticsearch的核心库。
3.3.2 代码示例
import org.apache.http.HttpHost;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.SearchHits;
import org.elasticsearch.search.builder.SearchSourceBuilder;public class IKAnalyzerExample {public static void main(String[] args) throws Exception {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("localhost", 9200, "http")));SearchRequest searchRequest = new SearchRequest("your_index");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("your_field", "你好,世界"));searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest);SearchHits hits = searchResponse.getHits();for (SearchHit hit : hits) {System.out.println(hit.getSourceAsString());}client.close();}
}
在上述代码中,我们使用Elasticsearch的Java客户端创建了一个搜索请求,查询名为your_index的索引中your_field字段包含“你好,世界”的文档。由于我们在索引映射中指定了使用ik_smart分词器,因此在搜索时会使用IK分词器对查询语句进行分词。
3.4 IK分词器的两种模式
- ik_smart(细粒度模式):这种模式会尽可能地将文本切分成最细粒度的词项,以提高搜索的准确性。例如,对于文本“中华人民共和国”,ik_smart模式会分成“中华人民共和国”。
- ik_max_word(粗粒度模式):这种模式会将文本切分成尽可能多的词项,以提高搜索的召回率。例如,对于文本“中华人民共和国”,ik_max_word模式会分成“中华”、“中华人民”、“中华人民共和国”、“人民”、“人民共和国”、“共和国”等词项。
开发者可以根据具体的业务需求选择合适的分词模式。
四、总结
在本文中,我们深入探讨了Elasticsearch的文本分析机制以及内置分词器和IK分词器的使用方法。理解文本分析在全文搜索中的核心作用是选择合适分词器的基础。
Elasticsearch的内置分词器提供了多种选择,适用于不同的语言和业务场景。Standard分词器通用性强,适用于大多数语言;Whitespace分词器简单直观,适用于保留原始词项格式的场景;Keyword分词器适用于精确匹配的字段。
而IK分词器则为中文文本分析提供了强大的支持。通过简单的下载、集成步骤,我们可以在Elasticsearch中轻松使用IK分词器,并通过Java API进行灵活的搜索操作。IK分词器的两种模式ik_smart和ik_max_word能够满足不同的搜索需求,提高搜索的准确性和召回率。
在实际项目中,我们需要根据具体的业务需求和数据特点,选择合适的分词器或组合使用多种分词器,以实现高效、准确的全文搜索功能。希望本文能够帮助你更好地理解和应用Elasticsearch的分词技术,提升你的搜索应用开发能力。
参考资料文献
- Elasticsearch官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- IK分词器官方GitHub仓库:https://github.com/medcl/elasticsearch-analysis-ik
- 《Elasticsearch实战》,Ramnivas Laddad著
- 《Lucene实战》,Doug Cutting、Erik Hatcher著
相关文章:
【Elasticsearch】内置分词器和IK分词器
🧑 博主简介:CSDN博客专家,历代文学网(PC端可以访问:https://literature.sinhy.com/#/?__c1000,移动端可微信小程序搜索“历代文学”)总架构师,15年工作经验,精通Java编…...

2025美赛数学建模C题:奥运金牌榜,完整论文代码模型目前已经更新
2025美赛数学建模C题:奥运金牌榜,完整论文代码模型目前已经更新,获取见文末名片...
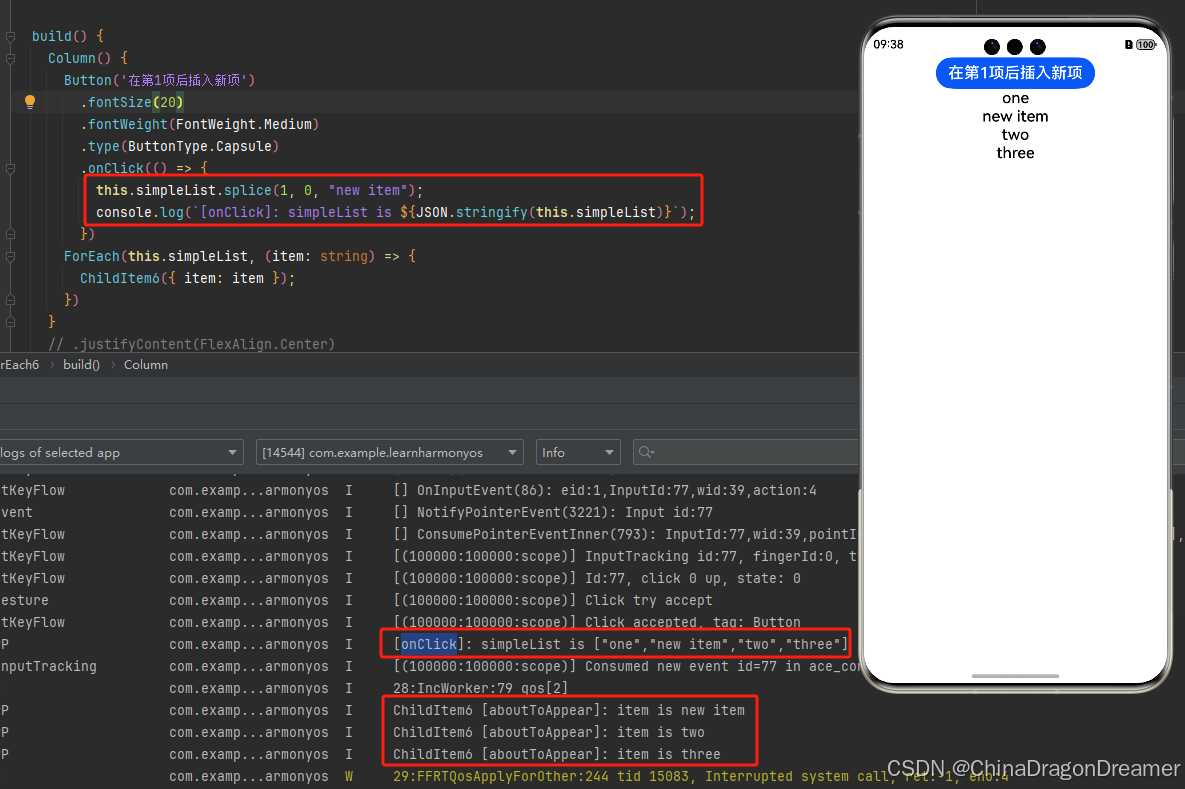
HarmonyOS:ForEach:循环渲染
一、前言 ForEach接口基于数组类型数据来进行循环渲染,需要与容器组件配合使用,且接口返回的组件应当是允许包含在ForEach父容器组件中的子组件。例如,ListItem组件要求ForEach的父容器组件必须为List组件。 API参数说明见:ForEa…...

Effective C++ 规则50:了解 new 和 delete 的合理替换时机
1、背景 在 C 中,new 和 delete 是动态分配内存的核心操作符。然而,直接使用它们有时会增加程序的复杂性,甚至导致内存泄漏和其他问题。因此,了解何时替换 new 和 delete 并选择更适合的内存管理策略,是编写高效、健壮…...

C++ STL:深入探索常见容器
你好呀,欢迎来到 Dong雨 的技术小栈 🌱 在这里,我们一同探索代码的奥秘,感受技术的魅力 ✨。 👉 我的小世界:Dong雨 📌 分享我的学习旅程 🛠️ 提供贴心的实用工具 💡 记…...

android12源码中用第三方APK替换原生launcher
一、前言 如何用第三方的apk替换原生launcher呢?我是参考着这位大神的博客https://blog.csdn.net/hyu001/article/details/131044358做的,完美实现。 这边博客中又加入了我个人的一些改变,整理的。 二、步骤 1.在/packages/apps/MyApp文件…...

Java面试题2025-设计模式
1.说一下开发中需要遵守的设计原则? 设计模式中主要有六大设计原则,简称为SOLID ,是由于各个原则的首字母简称合并的来(两个L算一个,solid 稳定的),六大设计原则分别如下: 1、单一职责原则 单一职责原则的定义描述非…...

【设计模式-行为型】备忘录模式
一、什么是备忘录模式 来到备忘录模式了,这个模式我感觉相对简单一些,就是备份,或者快照。跟前面一样为了加深理解,我们引入一个电影情结来说明啥是备忘录模式,以来加深大家对备忘录模式的认识。那么,在电影…...

flink StreamGraph解析
Flink程序有三部分operation组成,分别是源source、转换transformation、目的地sink。这三部分构成DAG。 DAG首先生成的是StreamGraph。 用户代码在添加operation的时候会在env中缓存(变量transformations),在env.execute()执行的…...

本地AI模型:未来智能设备的核心驱动力
标题:“本地AI模型:未来智能设备的核心驱动力” 文章信息摘要: 未来AI设备(如Meta Ray-Bans)的发展将更加依赖本地语言模型的优化与集成,而非仅依靠云端AI模型。本地模型在隐私保护、推理速度和离线访问方…...

基于SpringBoot的网上摄影工作室开发与实现 | 含论文、任务书、选题表
随着互联网技术的不断发展,摄影爱好者们越来越需要一个在线平台来展示和分享他们的作品。基于SpringBoot的网上摄影工作室应运而生,它不仅为用户提供了一个展示摄影作品的平台,还为管理员提供了便捷的管理工具。本文幽络源将详细介绍该系统的…...

数字人+展厅应用方案:开启全新沉浸式游览体验
随着人们生活质量的不断提升,对于美好体验的追求日益增长。在展厅展馆领域,传统的展示方式已难以满足大众日益多样化的需求。而通过将数字人与展厅进行深度结合,可以打造数字化、智能化新型展厅,不仅能提升展示效果,还…...

基于单片机的家用无线火灾报警系统的设计
1 总体设计 本设计家用无线火灾报警系统利用单片机控制技术、传感器检测技术、GSM通信技术展开设计,如图2.1所示为本次系统设计的主体框图,系统包括单片机主控模块、温度检测模块、烟雾检测模块、按键模块、GSM通信模块、液晶显示模块、蜂鸣器报警模块。…...

多级缓存(亿级并发解决方案)
多级缓存(亿级流量(并发)的缓存方案) 传统缓存的问题 传统缓存是请求到达tomcat后,先查询redis,如果未命中则查询数据库,问题如下: (1)请求要经过tomcat处…...

iic、spi以及uart
何为总线? 连接多个部件的信息传输线,是部件共享的传输介质 总线的作用? 实现数据传输,即模块之间的通信 总线如何分类? 根据总线连接的外设属于内部外设还是外部外设将总线可以分为片内总线和片外总线 可分为数…...

Shell编程(for循环+并发问题+while循环+流程控制语句+函数传参+函数变量+函数返回值+反向破解MD5)
本篇文章继续给大家介绍Shell编程,包括for循环、并发问题,while循环,流程控制语句,函数传参、函数变量、函数返回值,反向破解MD5等内容。 1.for循环 for 变量 in [取值列表] 取值列表可以是数字 字符串 变量 序列…...

深入 Rollup:从入门到精通(三)Rollup CLI命令行实战
准备阶段:初始化项目 初始化项目,这里使用的是pnpm,也可以使用yarn或者npm # npm npm init -y # yarn yarn init -y # pnpm pnpm init安装rollup # npm npm install rollup -D # yarn yarn add rollup -D # pnpm pnpm install rollup -D在…...

CycleGAN模型解读(附源码+论文)
CycleGAN 论文链接:Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks 官方链接:pytorch-CycleGAN-and-pix2pix 老规矩,先看看效果 总体流程 先简单过一遍流程,细节在代码里说。CycleGAN有…...

线程配置经验
工作时,时常会遇到,线程相关的问题与解法,本人会持续对开发过程中遇到的关于线程相关的问题及解决记录更新记录在此篇博客中。 目录 一、线程基本知识 1. 线程和进程 二、问题与解法 1. 避免乘法级别数量线程并行 1)使用线程池…...
)
动态规划DP 数字三角形模型 传纸条(题目分析+C++完整代码)
传纸条 原题链接 AcWing 275. 传纸条 题目描述 小渊和小轩是好朋友也是同班同学,他们在一起总有谈不完的话题。 一次素质拓展活动中,班上同学安排坐成一个 m行 n 列的矩阵,而小渊和小轩被安排在矩阵对角线的两端,因此&#x…...

Ubuntu二进制部署K8S 1.29.2
本机说明 本版本非高可用,单Master,以及一个Node 新装的 ubuntu 22.04k8s 1.29.3使用该文档请使用批量替换 192.168.44.141这个IP,其余照着复制粘贴就可以成功需要手动 设置一个 固定DNS,我这里设置的是 8.8.8.8不然coredns无法…...

第05章 10 地形梯度场模拟显示
在 VTK(Visualization Toolkit)中,可以通过计算地形数据的梯度场,并用箭头或线条来表示梯度方向和大小,从而模拟显示地形梯度场。以下是一个示例代码,展示了如何使用 VTK 和 C 来计算和显示地形数据的梯度场…...

全程Kali linux---CTFshow misc入门
图片篇(基础操作) 第一题: ctfshow{22f1fb91fc4169f1c9411ce632a0ed8d} 第二题 解压完成后看到PNG,可以知道这是一张图片,使用mv命令或者直接右键重命名,修改扩展名为“PNG”即可得到flag。 ctfshow{6f66202f21ad22a2a19520cdd…...

[ Spring ] Spring Cloud Alibaba Message Stream Binder for RocketMQ 2025
文章目录 IntroduceProject StructureDeclare Plugins and ModulesApply Plugins and Add DependenciesSender PropertiesSender ApplicationSender ControllerReceiver PropertiesReceiver ApplicationReceiver Message HandlerCongratulationsAutomatically Send Message By …...
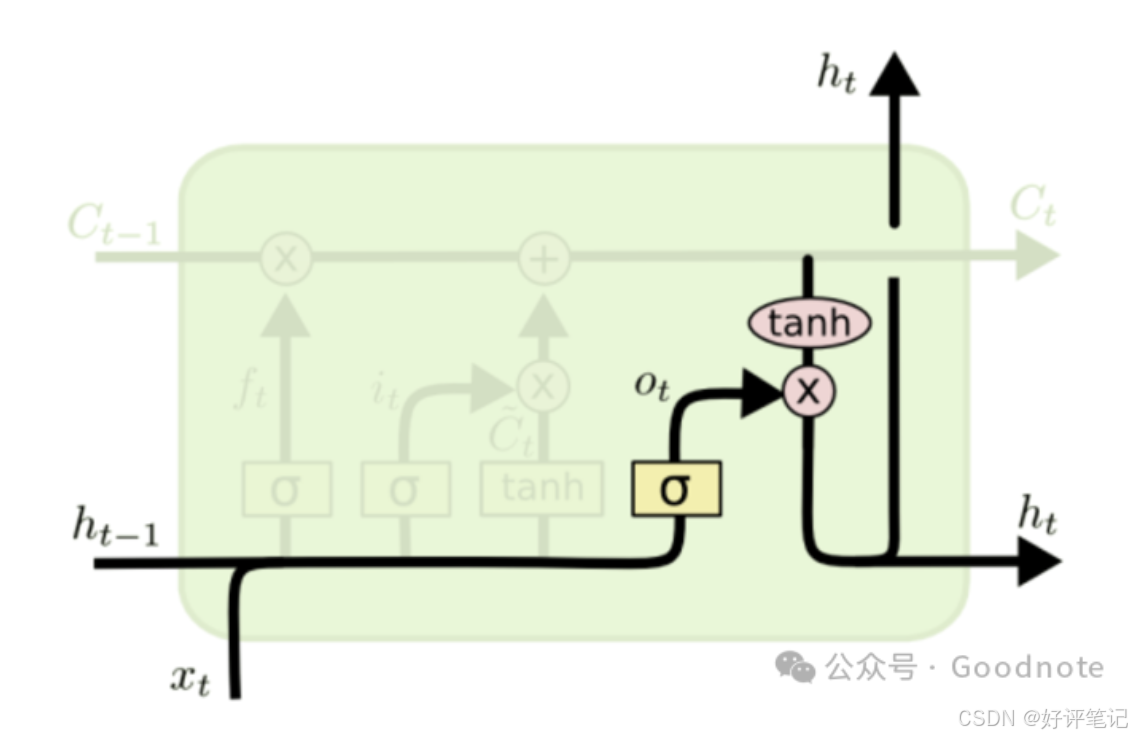
深度学习笔记——循环神经网络之LSTM
大家好,这里是好评笔记,公主号:Goodnote,专栏文章私信限时Free。本文详细介绍面试过程中可能遇到的循环神经网络LSTM知识点。 文章目录 文本特征提取的方法1. 基础方法1.1 词袋模型(Bag of Words, BOW)工作…...

AI 模型评估与质量控制:生成内容的评估与问题防护
在生成式 AI 应用中,模型生成的内容质量直接影响用户体验。然而,生成式模型存在一定风险,如幻觉(Hallucination)问题——生成不准确或完全虚构的内容。因此,在构建生成式 AI 应用时,模型评估与质…...

[MILP] Logical Constraints 0-1 (Note2)
1. 如果选择了项目1,则项目2,3也要求被选中 表示为: 2. 如果确定了选项目1,则接下来必须选项目2或者项目3 表示为: or 3. 如果同时选择了项目2和项目3,则不可以选择项目1 表示为: 4. 如果…...

DFFormer实战:使用DFFormer实现图像分类任务(二)
文章目录 训练部分导入项目使用的库设置随机因子设置全局参数图像预处理与增强读取数据设置Loss设置模型设置优化器和学习率调整策略设置混合精度,DP多卡,EMA定义训练和验证函数训练函数验证函数调用训练和验证方法 运行以及结果查看测试完整的代码 在上…...

蓝桥杯例题四
每个人都有无限潜能,只要你敢于去追求,你就能超越自己,实现梦想。人生的道路上会有困难和挑战,但这些都是成长的机会。不要被过去的失败所束缚,要相信自己的能力,坚持不懈地努力奋斗。成功需要付出汗水和努…...

如何复现o1模型,打造医疗 o1?
如何复现o1模型,打造医疗 o1? o1 树搜索一、起点:预训练规模触顶与「推理阶段(Test-Time)扩展」的动机二、Test-Time 扩展的核心思路与常见手段1. Proposer & Verifier 统一视角方法1:纯 Inference Sca…...