【redis】缓存 更新策略(定期、实时生存),缓存预热、穿透、雪崩、击穿详解
什么是缓存
redis 最常用的场景
核心思路就是把一些常用的数据,放到触手可及(访问速度更快)的地方
- ⽐如我需要去⾼铁站坐⾼铁. 我们知道坐⾼铁是需要反复刷⾝份证的 (进⼊⾼铁站, 检票, 上⻋,乘⻋过程中, 出站…)
- 正常来说, 我的⾝份证是放在⽪箱⾥的(⽪箱的存储空间⼤, ⾜够能装). 但是每次刷⾝份证都需要开⼀次⽪箱找⾝份证, 就⾮常不⽅便.
- 因此我就可以把⾝份证先放到⾐服⼝袋⾥. ⼝袋虽然空间⼩, 但是访问速度⽐⽪箱快很多.
- 这样的话每次刷⾝份证我只需要从⼝袋⾥掏⾝份证就⾏了, 就不必开⽪箱了.
- 此时 “⼝袋” 就是 “⽪箱” 的缓存. 使⽤缓存能够⼤ 提⾼访问效率
速度快的设备,可以作为速度慢的设备的缓存
CPU 寄存器 > 内存 > 硬盘 > 网络
最常见的是,使用内存作为硬盘的缓存(redis 定位)
硬盘也可以作为网络的缓存——浏览器的缓存
- 浏览器通过
http/https从服务器上获取到数据(html、css、js、图片、视频、音频、字体…)并进行展示
- 从服务器上获取:网络
- 图片、音频、视频等等这样体积大,又不太会改变的数据,就可以保存到浏览器本地(浏览器所在主机的硬盘上),后续再打开这个页面,就不必重新从网络获取上述数据了
缓存能够有意义,二八定律
- 缓存虽然快,但是空间小
20%的数据,可以应对80%的请求
使用 redis 作为缓存
通常是使用 redis 作为数据库的缓存(MySQL)
- 数据库是一个非常重要的组件,绝大部分商业项目中都会涉及到
- 并且
MySQL的速度又比较慢
为什么说关系型数据库性能不高?
- 数据库把数据存储在硬盘上,硬盘的 IO 速度并不快,尤其是随机访问
- 如果查询不能命中索引,就需要进行表的遍历,这就会大大增加硬盘 IO 次数
- 关系型数据库对于
SQL的执行会做一系列的解析,校验,优化工作 - 如果是一些复杂查询,比如联合查询,需要进行笛卡尔积操作,效率更是降低很多
- …
因为 MySQL 等数据库,效率比较低,多以承担的并发量就有限,一旦请求数多了,数据库的压力就会很大,甚至很容易就宕机了
- 服务器每次处理一个请求,一定都要消耗一些硬件资源(CPU、内存、硬盘、网络…)任意一种资源的消耗超出了机器能提供的上限,机器就很容易出现故障了
如何提高 MySQL 能承担的并发量?(客观需求)
- 开源:引入更多的机器,构成数据库集群
- 节流:引入缓存,就是典型的方案,把一些频繁读取的数据,保存到缓存上。后续在查询数据的时候,如果缓存中已经存在了,就不再访问
MySQL了
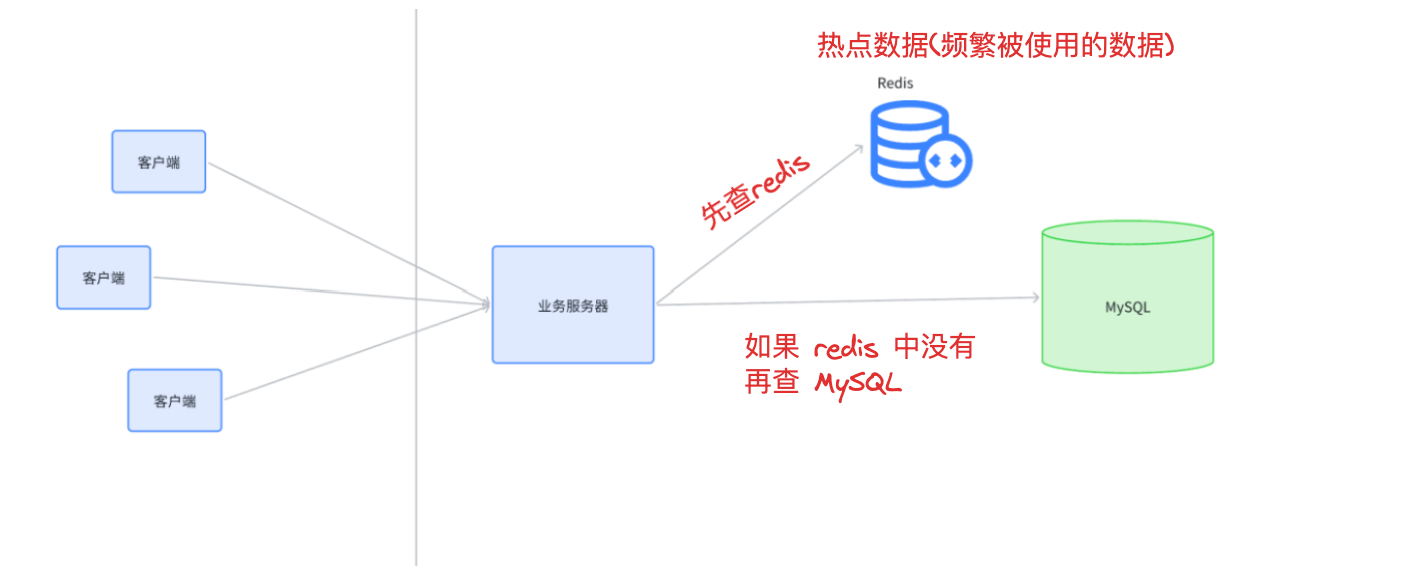
- 虽然
redis上只能存少数数据,但是大部分请求都是使用的这少数的热点数据 - 实际业务中,
3:7,1:9无所谓,基本思想是一致的
缓存更新策略
如何知道 redis 中应该存储哪些数据?
如何知道哪些数据是热点数据呢?
这里就要谈到“缓存的更新策略“
1. 定期生成
会把访问的数据,以日志的形式记录下来
比如一个搜索引擎,“查询词”就是要关注的“访问的数据”
- 我们可以通过日志,把搜索框里面都用到了哪些词,给记录下来,就可以针对这些日志进行统计了
- 统计这一天,每个词出现的频率,再根据频率降序来排序,再取出前
20%的词,就可以把这些词认为是“热点词”- 数据量可能大到说,一台机器存不下,就需要使用分布式的系统来存储这些日志(HDFS)
- 再使用
Hadoop的map-reduce来写代码进行统计;也可以基于HDFS的HBASE这样的数据库来写SQL统计 - 这些就是大数据工程师的日常工作
- 接下来就可以把这些热点词,涉及到的搜索结果,提前拎出来,就可以放到类似于“
redis”这样的缓存中了
此处的数据,就可以根据当前这里统计的未读,来定期更新
- 按照天级别统计,就每天更新一次
- 按照月级别统计,就每个月更新一次
写一套离线的流程(往往使用shell,Python写脚本代码),可以通过定时任务来触发
- 完成统计热词过程
- 根据热词,找到搜索结果的数据(广告数据)
- 把得到缓存数据同步到缓存服务器上
- 控制这些缓存服务器自动启动
优点:上述过程,实际上实现起来比较简单,过程更可控(缓存中有什么是比较固定的),方便排查问题
缺点:实时性不够。如果出现一些突发性时间,有一些本来不是热词的内容,成了热词了,新的热词就可能会给后面的数据库什么的带来比较大的压力
- 比如,过年的时候,“春节晚会”就是突发性的热词
2. 实时生成
- 如果在
redis查到了,就直接返回 - 如果
redis中不存在,就从数据库查,把查到的结果同时也写入redis
这样不停地写 redis,就会使 redis 的内存占用越来越多,就会逐渐达到内存上限
- 不一定是机器内存上限,
redis中也可以配置,最多使用多少内存(maxmermory参数)
如果继续往里插入数据,就会触发问题,为了解决上述问题,redsi 就引入了“内存淘汰策略”
内存淘汰策略
#高频面试
先关策略
FIFO(First In First Out)先进先出
把缓存中存在时间最久的(也就是先来的数据)淘汰掉
LRU (Least Recently Used) 淘汰最久未使用的
记录每个 key 的最近访问时间,把最近访问时间最老的 key 都淘汰掉
LFU(Least Frequently Used)淘汰访问次数最少的
记录每个 key 最近一段时间的访问次数,把访问次数最少的淘汰掉
Random 随机淘汰
从所有的 key 中抽取幸运儿被随机淘汰
理解上述几种淘汰策略:
想象你是个皇帝,有后宫佳丽三千。虽然你是真龙天子,但是经常宠信的妃子也就那么寥寥数人(后宫佳丽散散,相当于数据库中的全量数据,经常宠信的妃子相当于热点数据,是放在缓存中的)
今年选秀的一批新的小主,其中一个被你看上了,宠信新人,自然就需要有旧人被冷落,到底谁是要被冷落的人呢?
FIFO:皇后是最先受宠的,现在已经年老色衰了==>皇后失宠LRU:统计最近宠幸时间,皇后(一周前),熹妃(昨天),安答应(两周前),华妃(一个月前)==>华妃失宠LFU:统计最近一个月的宠幸次数,皇后(3 次),熹妃(15 次),安答应(1 次),华妃(10 次)==>安答应失宠(最合理)Random:随机挑选一个妃子失宠(最不合理)
具体采取哪种策略,要结合实际场景来具体问题具体分析
相关配置项
redis 里面,有一个配置项,就可以设置 redis 采取上述哪种策略淘汰内存数据
-
volatile-lru当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中使⽤LRU(最近最少使⽤)算法进⾏淘汰- 设置了过期时间的就算,包括过期时间还没到的
-
allkeys-lru当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LRU(最近最少使⽤)算法进⾏淘汰. -
volatile-lfu4.0版本新增,当内存不⾜以容纳新写⼊数据时,在过期的key中,使⽤LFU算法进⾏删除key. -
allkeys-lfu4.0版本新增,当内存不⾜以容纳新写⼊数据时,从所有key中使⽤LFU算法进⾏淘汰. -
volatile-random当内存不⾜以容纳新写⼊数据时,从设置了过期时间的key中,随机淘汰数据. -
allkeys-random当内存不⾜以容纳新写⼊数据时,从所有key中随机淘汰数据. -
volatile-ttl在设置了过期时间的key中,根据过期时间进⾏淘汰,越早过期的优先被淘汰.(相当于FIFO, 只不过是局限于过期的key)- 对于其他没有设置过期时间的
key,很可能是没有保存设置时间的
- 对于其他没有设置过期时间的
-
noeviction默认策略,当内存不⾜以容纳新写⼊数据时,新写⼊操作会报错.- 不适合于实时更新策略
经过一段时间的“动态平衡”,redis 中的 key 就逐渐都成了热点数据了
缓存预热(Cache preheating)
#高频面试
缓存中的数据
- 定期生成(这种情况,不涉及“预热”)
- 实时生成
redis 服务器首次接入之后,服务器里面是没有数据的
- 客户端先查询
redis,如果没有查到,就再查一次MySQL,查到了之后,会把数据也写到redis中 - 服务器里没有数据,此时所有的请求都会打给
MySQL,随着时间的推移,redis上的数据越积累越多,MySQL承担的压力就逐渐减小了
缓存预热,就是用来解决上面问题的
把定期生成和实时生成结合一下。先通过离线的方式,通过一些统计的途径,先把热点数据找到一批,导入到 redis 中。此时导入的这批热点数据,就能帮 MySQL 承担很大的压力了。随着时间推移,逐渐就使用新的热点数据淘汰掉旧的数据
缓存穿透(Cache penetration)
#高频面试
查询的某个 key,在 redis 中没有,MySQL 中也没有,这个 key 肯定也不会被更新到 redis 中
- 这次查询:没有;下次查询:仍然没有…
- 如果像这样的数据,存在很多,并且还反复查询, 一样也会给
MySQL带来很大的压力
为何产生?
- 业务涉及不合理。比如缺少必要的参数校验环节,导致非法的
key也被进行查询了- 典型情况
- 开发/运维误操作。不小心把部分数据从数据库上误删了
- 没那么典型,表现也是缓存穿透。误删操作,不一定能及时发现
- 黑客恶意攻击
- 比较少见。黑客是很多的,一些中大厂,都有专门负责做安全的团队(有人负重前行)
如何解决?
通过改进业务/加强监控报警等方式,都是亡羊补牢
相比之下更靠谱的方案:(降低问题的严重性**)
- 如果发现这个
key在redis和MySQL上都不存在,仍然写入redis中,value设成一个非法值(比如"") - 还可以引入布隆过滤器。每次查询
redis/MySQL之前,都先判定一下key是否在布隆过滤器上存在(把所有的key都插入到布隆过滤器中)- 布隆过滤器,本质上是结合了
hash+bitmap,以比较小的空间开销,比较快的时间速度,实现针对key是否存在的判定
- 布隆过滤器,本质上是结合了
缓存雪崩(Cache avalanche)
#高频面试
由于在短时间内,redis 上大规模的 key 失效,导致缓存命中率陡然下降,并且 MySQL 的压力迅速上升,甚至直接宕机
redis直接挂了redis宕机/redis集群模式下,大量节点宕机
redis好着呢,但是可能之前短时间内设置了很多key给redis,并且设置的过期时间是相同的- 给
redis里设置key作为缓存的时候,有的时候为了考虑缓存的时效性,就会设置过期时间(和redis内存淘汰机制,是配合使用的)
- 给
如何解决?
- 加强监控报警,加强
redis集群可用性的保证 - 不给
key设置过期时间/过期时间的时候添加随机的因子(避免同一时刻过期)
缓存击穿(Cache breakdown)
#高频面试
相当于缓存雪崩的特殊情况。针对热点 key,突然过期了,导致大量的请求直接访问到数据库上,甚至引起数据库宕机
- 热点
key访问频率高,影响更大
如何解决?
- 基于统计的方式发现热点
key,并设置永不过期- 往往需要服务器结构做出较大的调整
- 进行必要的服务降级。例如访问数据库的时候用分布式锁,限制同时请求数据库的并发数
- 本身服务器的功能有十个,但是在特定的情况下,适当的关闭一些不重要的功能,只保留核心功能(服务降级)==>手机的省点模式
- 通过分布式锁,限制数据库的访问频率
总结
- 缓存的基本概念
- 如何使用
redis作为缓存 - 缓存更新策略==>
redis内存淘汰机制 - 缓存使用的注意事项
相关文章:
【redis】缓存 更新策略(定期、实时生存),缓存预热、穿透、雪崩、击穿详解
什么是缓存 redis 最常用的场景 核心思路就是把一些常用的数据,放到触手可及(访问速度更快)的地方 ⽐如我需要去⾼铁站坐⾼铁. 我们知道坐⾼铁是需要反复刷⾝份证的 (进⼊⾼铁站, 检票, 上⻋,乘⻋过程中, 出站…)正常来说, 我的⾝份证是放在…...

好文和技术网站记录
后续不断记录一些本人觉得的好文和一些技术网站 技术网站 Java 全栈知识体系 https://www.pdai.tech/ 文章 利用 NginxKeepalived 实现高可用技术 https://cloud.tencent.com/developer/article/1647182?policyId1004...

使用STM32CubeMX和Keil在STM32上创建并运行一个简单的FreeRTOS多任务程序
目标 利用FreeRTOS运行两个任务,分别为点灯和OLED屏的显示。 利用STM32CubeMX生成Keil工程和相关初始化代码 知识回顾 之前已经利用STM32CubeMX生成过Keil工程和相关初始化代码了,可以去回顾一下,详情见:https://blog.csdn.ne…...

从查重报告入手的精准论文降重秘籍
每个同学在使用论文查重时,为何同一篇文章,可能重复率从10%—30%不等?归根结底还是使用了不同查重系统。其实不同的论文查重与论文AIGC检测系统的算法、数据及模型都不一样,那如何针对这些系统的“个性”精准降重,这篇…...

车辆控制解决方案
车辆控制解决方案 /* * Purpose: 优化车辆控制的功能 -> 用户在控制车辆状态时,实现控制按钮点击状态改变只触发一次onSwitchChange事件,不再下发控制指令,同时清除加载车辆实时状态的定时器status_interval直到有返回值再开启࿰…...
第14篇:决策树算法,学习目标【附代码文档】)
【机器学习】嘿马机器学习(算法篇)第14篇:决策树算法,学习目标【附代码文档】
本教程的知识点为:机器学习算法定位、 K-近邻算法 1.4 k值的选择 1 K值选择说明 1.6 案例:鸢尾花种类预测--数据集介绍 1 案例:鸢尾花种类预测 1.8 案例:鸢尾花种类预测—流程实现 1 再识K-近邻算法API 1.11 案例2:预测…...

Uubuntu20.04复现SA-ConvONet步骤
项目地址: tangjiapeng/SA-ConvONet: ICCV2021 Oral SA-ConvONet: Sign-Agnostic Optimization of Convolutional Occupancy Networks 安装步骤: 一、系统更新 检查系统是否已经更新到最新版本: sudo apt-get update sudo apt-get upgra…...

设计模式 三、结构型设计模式
一、代理模式 代理设计模式(Proxy Design Pattern)是一种结构型设计模式,它为其他对象提供了一个代理,以控制对这个对象的访问。 代理模式可以用于实现懒加载、安全访问控制、日志记录等功能。简单来说,代理模式 就是通…...
)
C语言函数实战指南:从零到一掌握函数设计与10+案例解析(附源码)
一、函数基础:程序的“积木块” (一)什么是函数? 函数是可重复使用的代码块,用于实现特定功能。如同乐高积木,通过组合不同函数,可快速构建复杂程序。例如: #include <stdio.h>// 函数定义:计算两数之和 int add(int a, int b) {return a + b; }int main() {…...

Prompt攻击是什么
什么是Prompt攻击 Prompt攻击(Prompt Injection/Attack) 是指通过精心构造的输入提示(Prompt),诱导大语言模型(LLM)突破预设安全限制、泄露敏感信息或执行恶意操作的攻击行为。其本质是利用模型对自然语言的理解漏洞,通过语义欺骗绕过防护机制。 Prompt攻击的精髓:学…...

【Linux网络#18】:深入理解select多路转接:传统I/O复用的基石
📃个人主页:island1314 🔥个人专栏:Linux—登神长阶 目录 一、前言:🔥 I/O 多路转接 为什么需要I/O多路转接? 二、I/O 多路转接之 select 1. 初识 select2. select 函数原型2.1 关于 fd_set 结…...

华院计算3项应用成果入选钢铁行业智能制造解决方案推荐目录(2024年)
近日,中国钢铁工业协会发布《钢铁行业智能制造解决方案推荐目录(2024年)》。由中国钢铁工业协会、钢铁行业智能制造联盟共同开展了2024年钢铁行业智能制造解决方案及数字化转型典型场景应用案例遴选、智能制造创新大赛(钢铁行业赛…...

python使用cookie、session、selenium实现网站登录(爬取信息)
一、使用cookie 这段代码演示了如何使用Python的urllib和http.cookiejar模块来实现网站的模拟登录,并在登录后访问需要认证的页面。 # 导入必要的库 import requests from urllib import request, parse# 1. 导入http.cookiejar模块中的CookieJar类,用…...

vector模拟实现2
文章目录 vector的模拟实现erase函数resize拷贝构造赋值重载函数模版构造及其细节结语 我们今天又见面啦,给生活加点impetus!!开启今天的编程之路 今天我们来完善vector剩余的内容,以及再探迭代器失效! 作者ÿ…...

观察者模式在Java单体服务中的运用
观察者模式主要用于当一个对象发生改变时,其关联的所有对象都会收到通知,属于事件驱动类型的设计模式,可以对事件进行监听和响应。下面简单介绍下它的使用: 1 定义事件 import org.springframework.context.ApplicationEvent;pu…...
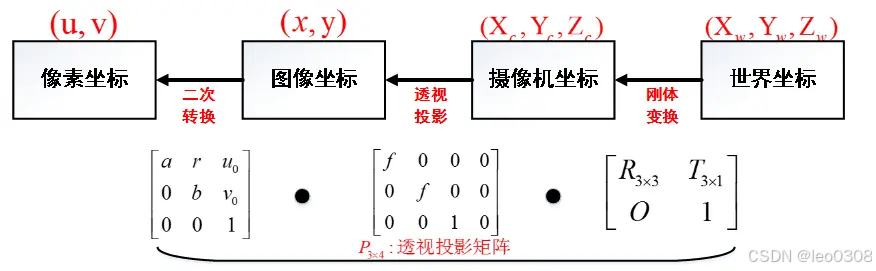
详解相机的内参和外参,以及内外参的标定方法
1 四个坐标系 要想深入搞清楚相机的内参和外参含义, 首先得清楚以下4个坐标系的定义: 世界坐标系: 名字看着很唬人, 其实没什么大不了的, 这个就是你自己定义的某一个坐标系。 比如, 你把房间的某一个点定…...

在线sql 转 rust 模型(Diesel、SeaORM),支持多数据 mysql, pg等
SQL 转 Rust 在 Rust 语言中,常用 Diesel 和 SeaORM 进行数据库操作。手写 ORM 模型繁琐,gotool.top 提供 SQL 转 Diesel、SeaORM 工具,自动生成 Rust 代码,提高开发效率。 特色 支持 Diesel / SeaORM,生成符合规范…...

高并发内存池(二):Central Cache的实现
前言:本文将要讲解的高并发内存池,它的原型是Google的⼀个开源项⽬tcmalloc,全称Thread-Caching Malloc,近一个月我将以学习为目的来模拟实现一个精简版的高并发内存池,并对核心技术分块进行精细剖析,分享在…...
[Windows] VutronMusic v1.6.0 音乐播放器纯净版,可登录同步
VutronMusic-简易好看的PC音乐播放器 链接:https://pan.xunlei.com/s/VOMq7P_fTyhLUXeGerDVhrCTA1?pwduvut# VutronMusic v1.6.0 音乐播放器纯净版,可登录同步...

macvlan 和 ipvlan 实现原理及设计案例详解
一、macvlan 实现原理 1. 核心概念 macvlan 允许在单个物理网络接口上创建多个虚拟网络接口,每个虚拟接口拥有 独立的 MAC 地址 和 IP 地址。工作模式: bridge 模式(默认):虚拟接口之间可直接通信,类似交…...
【蓝桥杯】每日练习 Day19,20
目录 前言 蒙德里安的梦想 分析 最短Hamilton路径 分析 代码 乌龟棋 分析 代码 松散子序列 分析 代码 代码 前言 今天不讲数论(因为上课学数论真是太难了,只学了高斯消元)所以今天就不单独拿出来讲高斯消元了。今天讲一下昨天和…...

《AI大模型应知应会100篇》第7篇:Prompt Engineering基础:如何与大模型有效沟通
第7篇:Prompt Engineering基础:如何与大模型有效沟通 摘要 Prompt Engineering(提示工程)是与大模型高效沟通的关键技能。通过精心设计的Prompt,可以让模型生成更准确、更有用的结果。本文将从基础知识到高级策略&…...

微服务架构技术栈选型避坑指南:10大核心要素深度拆解
微服务架构的技术栈选型直接影响系统的稳定性、扩展性和可维护性。以下从10大核心要素出发,结合主流技术方案对比、兼容性评估、失败案例及优化策略,提供系统性选型指南。 1. 服务框架与通信 关键考量点 扩展性:框架需支持定制化扩展&#x…...

Elasticsearch 正排索引
一、正排索引基础概念 在 Elasticsearch 中,正排索引用于存储完整的文档内容,以便通过文档ID 快速定位文档的字段值。正排索引通过 Doc Values 和 Store Fields 两种形式,为聚合、排序、脚本计算等场景提供高效支持。Doc Values 的列式存储设…...
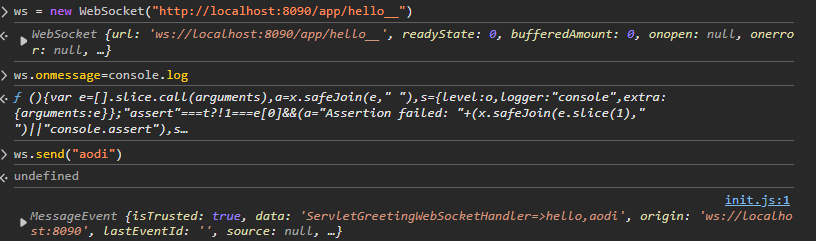
Spring实现WebScoket
SpringWeb编程方式分为Servlet模式和响应式。Servlet模式参考官方文档:Web on Servlet Stack :: Spring Framework,响应式(Reacive)参考官方文档:Web on Reactive Stack :: Spring Framework。 WebSocket也有两种编程方…...

Token是什么?
李升伟 整理 “Token” 是一个多义词,具体含义取决于上下文。以下是几种常见的解释: 1. 计算机科学中的 Token 定义:在编程和计算机科学中,Token 是源代码经过词法分析后生成的最小单位,通常用于编译器和解释器。 …...

odoo-045 ModuleNotFoundError: No module named ‘_sqlite3‘
文章目录 一、问题二、解决思路 一、问题 就是项目启动,本来好好地,忽然有一天报错,不知道什么原因。 背景: 我是在虚拟环境中使用的python3.7。 二、解决思路 虚拟环境和公共环境直接安装 sqlite3 都会报找不到这个库的问题…...

cesium加载CTB生成的地形数据
由于CTB生成的地形数据是压缩的(gzip)格式,需要在nginx加上特殊配置才可以正常加载,NGINX全部配置如下 worker_processes 1; events {worker_connections 1024; } http {include mime.types;default_type application/o…...

前端JS高阶技法:序列化、反序列化与多态融合实战
✨ 摘要 序列化与反序列化作为数据转换的核心能力,与多态这一灵活代码设计的核心理念,在现代前端开发中协同运作,提供了高效的数据通信与扩展性支持。 本文从理论到实践,系统解析: 序列化与反序列化的实现方式、使用…...

TS中的Class
基本用法 implements implements 关键字用于传递对类产生约束的数据类型 interface AnimalInfo{name:stringrace:stringage:number }interface AnimalCls{info:AnimalInfosayName():void} class Animal implements AnimalCls{info:AnimalInfoconstructor(info:AnimalInfo) {t…...