LangChain-模型输入输出 (Model I/O)
模型输入输出是LangChain的核心组件,负责处理与各种语言模型的交互。本文档详细介绍了这些组件的功能和使用方法。
概述
模型输入输出组件负责:
- 连接各种语言模型:统一不同提供商的模型接口
- 格式化输入:将原始输入转换为模型可理解的格式
- 处理输出:解析和格式化模型的输出内容
这些组件构成了LangChain应用程序的基础,是构建各种AI应用的起点。
主要组件
1. 语言模型 (LLMs)
语言模型组件处理文本到文本的生成任务:
from langchain_openai import OpenAIllm = OpenAI(temperature=0.7)
result = llm.invoke("介绍一下中国的四大发明")
print(result)
主要特点:
- 接收文本输入,返回文本输出
- 支持参数调整(温度、最大生成长度等)
- 提供多种模型类型和供应商选择
支持的主要模型:
- OpenAI - GPT-3.5, GPT-4等
- Anthropic - Claude系列
- 百度文心 - ERNIE-Bot系列
- 阿里通义 - 通义千问系列
- 本地模型 - Hugging Face模型、LLaMA等
2. 聊天模型 (Chat Models)
聊天模型组件专门处理多轮对话交互:
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessagechat = ChatOpenAI()
messages = [SystemMessage(content="你是一位友好的AI助手"),HumanMessage(content="你好!请介绍一下自己")
]
response = chat.invoke(messages)
print(response.content)
主要特点:
- 使用消息列表作为输入(系统消息、用户消息、助手消息)
- 返回结构化消息对象
- 支持多轮对话上下文
消息类型:
- SystemMessage: 设置模型行为和角色的系统指令
- HumanMessage: 用户输入信息
- AIMessage: AI回复内容
- FunctionMessage: 函数调用结果
- ToolMessage: 工具使用的消息
3. 提示模板 (Prompt Templates)
提示模板用于动态构建发送给模型的提示:
from langchain_core.prompts import PromptTemplate, ChatPromptTemplate# 文本提示模板
template = PromptTemplate.from_template("请介绍{country}的{topic}")
prompt = template.format(country="中国", topic="传统节日")# 聊天提示模板
chat_template = ChatPromptTemplate.from_messages([("system", "你是一位{role}专家,擅长解答{field}问题"),("human", "请回答:{question}")
])
messages = chat_template.format_messages(role="历史",field="中国古代文化",question="唐朝的科举制度是怎样的?"
)
主要特点:
- 支持变量插入
- 支持条件逻辑
- 允许组合多个模板
4. 输出解析器 (Output Parsers)
输出解析器将模型输出转换为结构化数据:
from langchain_core.output_parsers import StrOutputParser, PydanticOutputParser
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List# 简单字符串解析
parser = StrOutputParser()# 结构化数据解析
class Movie(BaseModel):title: str = Field(description="电影标题")director: str = Field(description="导演姓名")year: int = Field(description="上映年份")rating: float = Field(description="评分(1-10)")structured_parser = PydanticOutputParser(pydantic_object=Movie)# 在格式化指令中使用
format_instructions = structured_parser.get_format_instructions()
template = """生成一部经典电影的信息。
{format_instructions}
电影类型: {genre}"""prompt = PromptTemplate(template=template,input_variables=["genre"],partial_variables={"format_instructions": format_instructions}
)
主要解析器类型:
- StrOutputParser: 简单字符串提取
- PydanticOutputParser: 将输出解析为Pydantic模型
- JsonOutputParser: 将输出解析为JSON结构
- XMLOutputParser: 将输出解析为XML结构
- CommaSeparatedListOutputParser: 将输出解析为逗号分隔的列表
高级用法
流式处理
流式处理允许逐步接收模型生成的内容:
from langchain_openai import ChatOpenAIchat = ChatOpenAI(streaming=True)for chunk in chat.stream("写一首关于人工智能的短诗"):print(chunk.content, end="")
模型参数调整
调整模型的生成行为:
from langchain_openai import ChatOpenAI# 创造性参数调整
creative_model = ChatOpenAI(model="gpt-4",temperature=0.9, # 提高随机性max_tokens=2000, # 设置最大生成长度top_p=0.95, # 控制词汇多样性frequency_penalty=0.5 # 减少重复
)# 精确模式
precise_model = ChatOpenAI(model="gpt-4",temperature=0.1, # 降低随机性,更确定性的输出max_tokens=500
)
使用多模型
在不同场景使用不同模型:
from langchain_openai import ChatOpenAI
from langchain_anthropic import ChatAnthropic
from langchain_qianfan import ChatQianfanmodels = {"general": ChatOpenAI(model="gpt-3.5-turbo"), # 通用对话"complex": ChatOpenAI(model="gpt-4"), # 复杂推理"creative": ChatAnthropic(model="claude-3-opus-20240229"), # 创意写作"chinese": ChatQianfan() # 中文处理优化
}def get_appropriate_model(task):if task == "creative_writing":return models["creative"]elif task == "complex_reasoning":return models["complex"]elif task == "chinese_content":return models["chinese"]else:return models["general"]
函数调用
让模型选择并调用函数:
from langchain_core.tools import tool
from langchain_openai import ChatOpenAI@tool
def get_weather(location: str, unit: str = "celsius"):"""获取指定位置的天气信息"""# 这里应该有实际的API调用,这里用模拟数据weather_data = {"北京": "晴朗,25°C", "上海": "多云,28°C"}return weather_data.get(location, "未知地区")@tool
def calculate(expression: str):"""计算数学表达式"""return eval(expression)# 设置模型和工具
model = ChatOpenAI()
tools = [get_weather, calculate]# 使用函数调用
response = model.invoke("北京今天的天气怎么样?另外,计算一下25乘以4等于多少?",tools=tools
)print(response)
处理上下文窗口限制
处理长文本输入:
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import ChatOpenAI# 长文本处理
def process_long_text(text):# 分割文本为小块splitter = RecursiveCharacterTextSplitter(chunk_size=4000,chunk_overlap=200)chunks = splitter.split_text(text)# 处理各个文本块model = ChatOpenAI()results = []for chunk in chunks:response = model.invoke(f"请总结以下内容:{chunk}")results.append(response.content)# 合并结果combined = "\n\n".join(results)final_summary = model.invoke(f"请将以下多个摘要整合为一个连贯的总结:{combined}")return final_summary.content
集成实例
基本链式处理
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser# 创建基本组件
prompt = ChatPromptTemplate.from_template("请用中文回答:{question}")
model = ChatOpenAI()
output_parser = StrOutputParser()# LCEL组合
chain = prompt | model | output_parser# 执行链
result = chain.invoke({"question": "人工智能的发展历史是什么?"})
print(result)
使用记忆组件
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.memory import ConversationBufferMemory
from langchain_core.runnables.history import RunnableWithMessageHistory# 创建带有历史的提示模板
prompt = ChatPromptTemplate.from_messages([("system", "你是一位友好的AI助手。"),MessagesPlaceholder(variable_name="history"),("human", "{input}")
])# 创建链
chain = prompt | model | output_parser# 添加记忆组件
store = {}
memory = ConversationBufferMemory(return_messages=True,memory_key="history"
)chain_with_history = RunnableWithMessageHistory(chain,lambda session_id: memory,input_messages_key="input",history_messages_key="history"
)# 使用带历史的链
response1 = chain_with_history.invoke({"input": "你好!"},config={"configurable": {"session_id": "user1"}}
)response2 = chain_with_history.invoke({"input": "我们刚才聊了什么?"},config={"configurable": {"session_id": "user1"}}
)
总结
模型输入输出组件是LangChain的基础构建块,它们提供与语言模型交互的标准接口。通过这些组件,您可以:
- 连接各种大语言模型
- 动态构建提示
- 解析和结构化输出
- 处理多轮对话
- 实现高级功能如流式处理、函数调用等
正确使用这些组件是构建高效且可靠的LLM应用的关键。根据不同的应用场景,组合使用这些组件,可以满足各种复杂需求。
后续学习
- 提示模板 - 进一步了解提示工程
- 输出解析器 - 深入学习输出处理
- 记忆系统 - 学习管理对话历史
- 链 - 组合多个组件构建复杂应用
相关文章:
)
LangChain-模型输入输出 (Model I/O)
模型输入输出是LangChain的核心组件,负责处理与各种语言模型的交互。本文档详细介绍了这些组件的功能和使用方法。 概述 模型输入输出组件负责: 连接各种语言模型:统一不同提供商的模型接口格式化输入:将原始输入转换为模型可理…...

基于FPGA实现BPSK 调制
目录 一、 任务介绍二、基本原理三、基于FPGA实现BPSK 调制四、源码 一、 任务介绍 BPSK 调制在数字通信系统中是一种极重要的调制方式,它的抗干扰噪声性能及通频带的利用率均优先于 ASK 移幅键控和 FSK 移频键控。因此,PSK 技术在中、高速数据传输中得…...

深入理解 ResponseBodyAdvice 及其应用
ResponseBodyAdvice 是 Spring MVC 提供的一个强大接口,允许你在响应体被写入 HTTP 响应之前对其进行全局处理。 下面我将全面介绍它的工作原理、使用场景和最佳实践。 基本概念 接口定义 public interface ResponseBodyAdvice<T> {boolean supports(Metho…...
)
Java 基础 - 反射(1)
文章目录 引入类加载过程1. 通过 new 创建对象2. 通过反射创建对象2.1 触发加载但不初始化2.2 按需触发初始化2.3 选择性初始化控制 核心用法示例1. 通过无参构造函数创建实例对象2. 通过有参构造函数创建实例对象3. 反射通过私有构造函数创建对象, 破坏单例模式4. …...

Spring Boot中Spring MVC相关配置的详细描述及表格总结
以下是Spring Boot中Spring MVC相关配置的详细描述及表格总结: Spring MVC 配置项详解 1. 异步请求配置 spring.mvc.async.request-timeout 描述:设置异步请求的超时时间(单位:毫秒)。默认值:未设置&…...

flink Shuffle的总结
关于 ** 5 种 Shuffle 类型** 的区别、使用场景及 Flink 版本支持的总结: * 注意:下面是问AI具体细节与整理学习 1. 核心区别 Shuffle 类型核心特点使用场景Flink 版本支持Pipelined Shuffle流式调度,纯内存交换,低延迟(毫秒级…...
在排序数组中查找元素的第一个和最后一个位置 --- 二分查找
目录 一:题目 二:算法原理分析 三:代码实现 一:题目 题目链接: 34. 在排序数组中查找元素的第一个和最后一个位置 - 力扣(LeetCode) 二:算法原理分析 三:代码实现 c…...
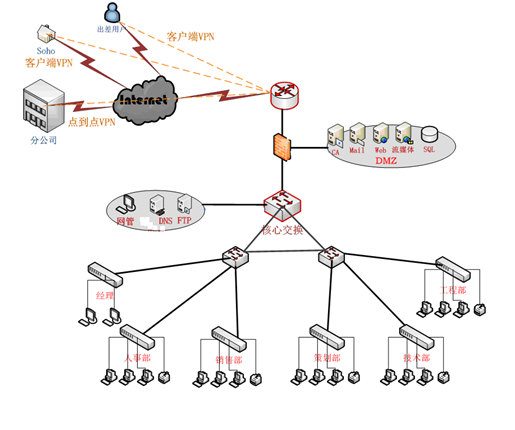
631SJBH中小型企业的网络管理模式的方案设计
1.1、研究现状 我国很多企业信息化水平一直还处在非常初级的阶段,有关统计表明,真正实现了计算机较高应用的企业在全国1000多万中小企业中所占的比例还不足10%幢3。大多数企业还停留在利用互联网进行网上查询(72.9%)、…...
)
NO.85十六届蓝桥杯备战|动态规划-经典线性DP|最长上升子序列|合唱队形|最长公共子序列|编辑距离(C++)
经典线性dp问题有两个:最⻓上升⼦序列(简称:LIS)以及最⻓公共⼦序列(简称:LCS),这两道题⽬的很多⽅⾯都是可以作为经验,运⽤到别的题⽬中。⽐如:解题思路&…...

0410 | 软考高项笔记:项目管理概述
以下是不同组织结构中项目经理的角色、工作特点以及快速记忆的方法: 不同组织结构中项目经理的角色和工作特点 组织结构项目经理的角色工作特点职能型组织项目协调者、辅助管理者权力有限,主要负责协调部门间的工作,项目成员向部门经理汇报…...

Vue3的Composition API与React Hooks有什么异同?
Vue3的一个重大更新点就是支持Composition API,而且也被业界称为hooks,那么Vue3的“Hooks”与React的Hooks有这么区别呢? 一、核心相似点 1. 逻辑复用与代码组织 都解决了传统类组件或选项式 API 中逻辑分散的问题,允许将相关逻…...
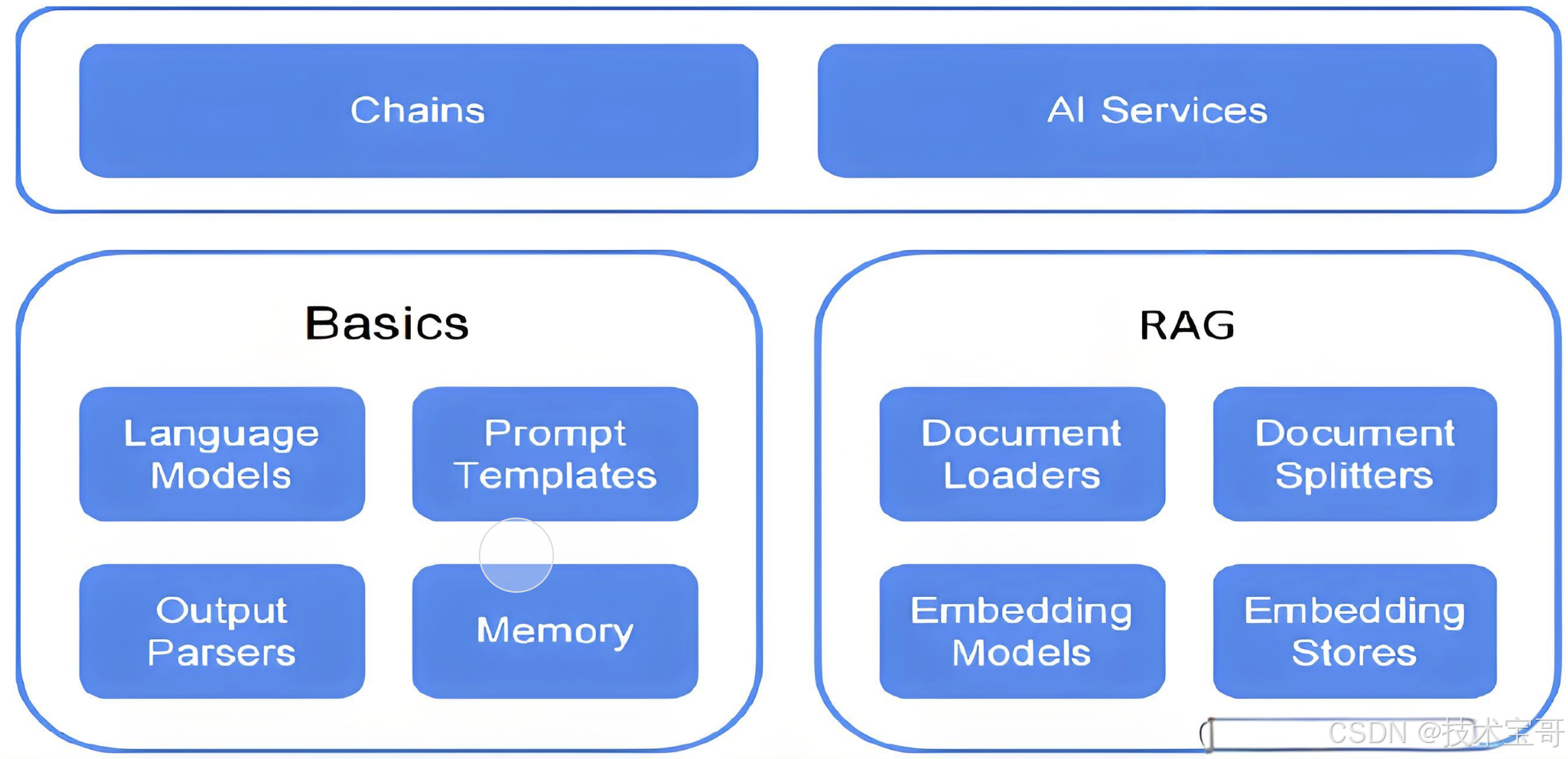
LangChain4j(1):初步认识Java 集成 LLM 的技术架构
LangChain 作为构建具备 LLM 能力应用的框架,虽在 Python 领域大放异彩,但 Java 开发者却只能望洋兴叹。LangChain4j 正是为解决这一困境而诞生,它旨在借助 LLM 的强大效能,增强 Java 应用,简化 LLM 功能在Java应用中的…...

JDK 21 的新特性有哪些?带你全面解读 Java 的未来
引言:从 JDK 21 看 Java 的进化之路 Java 是一门历久弥新的语言,每一次版本更新都在强化它的生态体系。2023 年发布的 JDK 21,作为长期支持版本(LTS),带来了许多令人兴奋的新特性。不论你是开发者、架构师…...
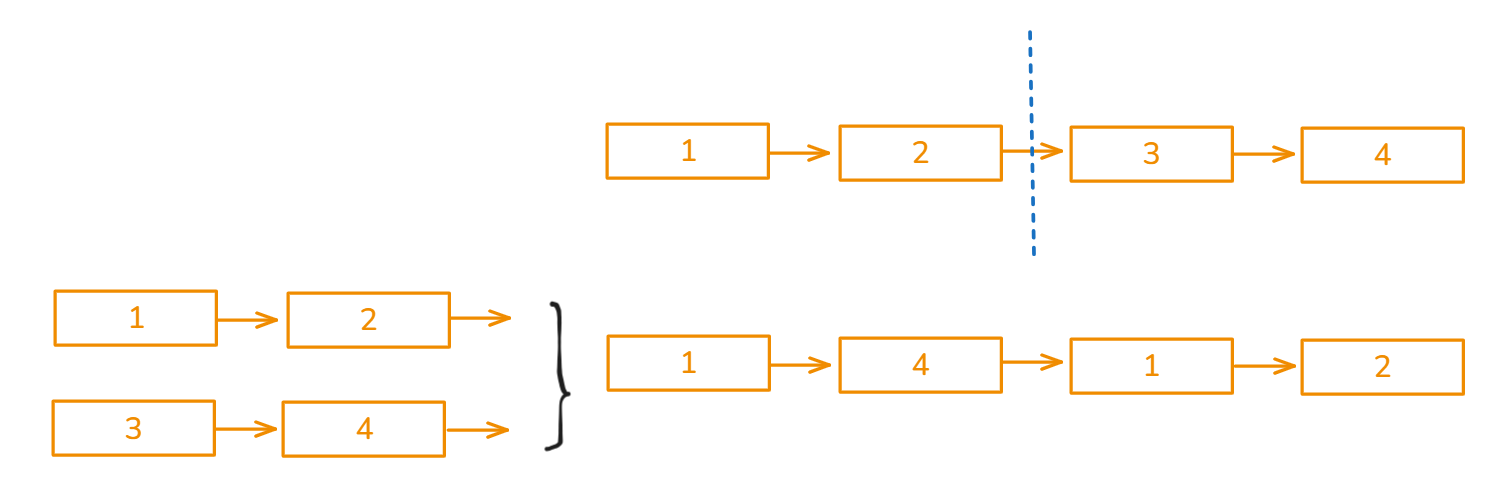
【C++算法】53.链表_重排链表
文章目录 题目链接:题目描述:解法C 算法代码: 题目链接: 143. 重排链表 题目描述: 解法 模拟 找到链表的中间节点 快慢双指针 把后面的部分逆序 双指针,三指针,头插法 合并两个链表 合并两个有…...
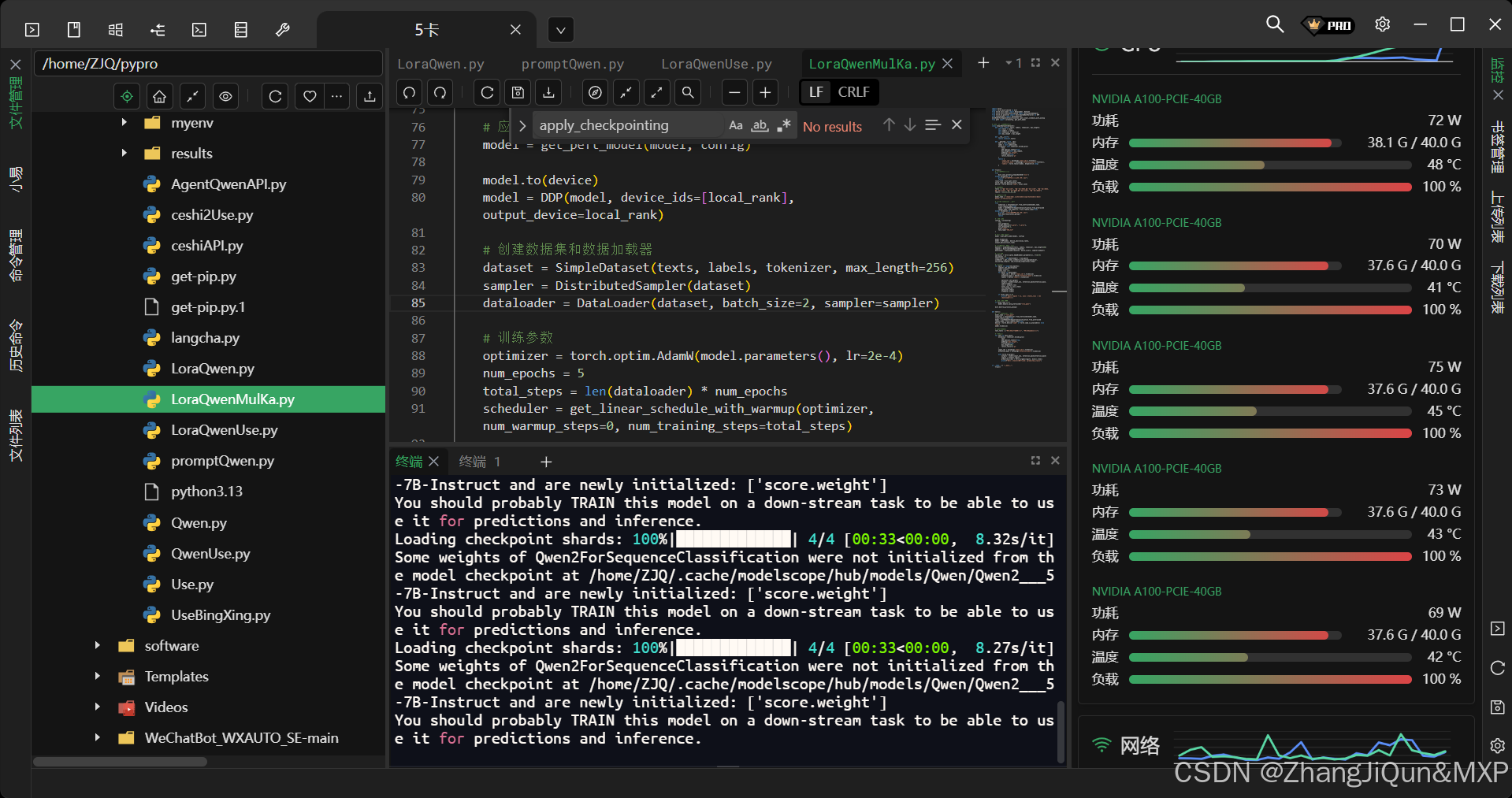
多卡分布式训练:torchrun --nproc_per_node=5
多卡分布式训练:torchrun --nproc_per_node=5 1. torchrun 实现规则 torchrun 是 PyTorch 提供的用于启动分布式训练作业的实用工具,它基于 torch.distributed 包,核心目标是简化多进程分布式训练的启动和管理。以下是其主要实现规则: 进程启动 多进程创建:torchrun 会…...

系统架构设计师之系统设计模块笔记
一、系统设计概述 定义与目标 系统设计是根据系统分析结果,制定系统构建蓝图的过程,核心目标是合理分配功能需求、优化资源使用、确保系统高内聚低耦合,并满足性能、安全、可扩展等非功能需求。主要内容 概要设计:将功能需求分配…...

Elasticsearch:加快 HNSW 图的合并速度
作者:来自 Elastic Thomas Veasey 及 Mayya Sharipova 过去,我们曾讨论过搜索多个 HNSW 图时所面临的一些挑战,以及我们是如何缓解这些问题的。当时,我们也提到了一些计划中的改进措施。本文正是这项工作的成果汇总。 你可能会问…...
图片中文字无法正确显示的解决方案
图片中文字无法正确显示的解决方案 问题描述 在 Linux 系统中生成图片时,图片中的文字(如中文)未能正确显示,可能表现为乱码或空白。这通常是由于系统缺少对应的字体文件(如宋体/SimSun),或者…...

数据结构:通俗解释AOE 网中事件的最早发生时间和最迟发生时间
1. 事件的最早发生时间 在 AOE 网(Activity On Edge Network,边表示活动的网络)中,事件的最早发生时间指从源点(起点)到该事件结点的最长路径长度(即所需时间)。它决定了所有以该事…...

C# 看门狗策略实现
using System; using System.Threading;public class Watchdog {private Timer _timer;private volatile bool _isTaskAlive;private readonly object _lock new object();private const int CheckInterval 5000; // 5秒检测一次private const int TimeoutThreshold 10000; …...
 操作系统上添加 ollama 作为系统服务的步骤)
在 openEuler 24.03 (LTS) 操作系统上添加 ollama 作为系统服务的步骤
以下是在 openEuler 操作系统上添加 ollama 作为系统服务的步骤: 创建 systemd 服务文件 sudo vi /etc/systemd/system/ollama.service将以下内容写入服务文件(按需修改参数): [Unit] DescriptionOllama Service Afternetwork.…...

Elasticsearch中的基本全文搜索和过滤
Elasticsearch中的基本全文搜索和过滤 知识点参考: https://www.elastic.co/guide/en/elasticsearch/reference/current/full-text-filter-tutorial.html#full-text-filter-tutorial-range-query 1. 索引设计与映射 多字段类型(Multi-Fields) ÿ…...

基于VSCode的Qt开发‘#include ui_test.h’报错没有该文件
笔者在基于VSCode进行Qt开发时,test.ui文件是在Qt软件中绘制的,导致本项目无法使用这个ui文件,报错如标题。事实上,本工程中也确实没有生成这个头文件。出现这个错误的原因是ui文件没有被编译为c头文件。 要生成 ui_test.h 文件&…...

Python常用排序算法
1. 冒泡排序 冒泡排序是一种简单的排序算法,它重复地遍历要排序的列表,比较相邻的元素,如果他们的顺序错误就交换他们。 def bubble_sort(arr):# 遍历所有数组元素for i in range(len(arr)):# 最后i个元素是已经排序好的for j in range(0, …...
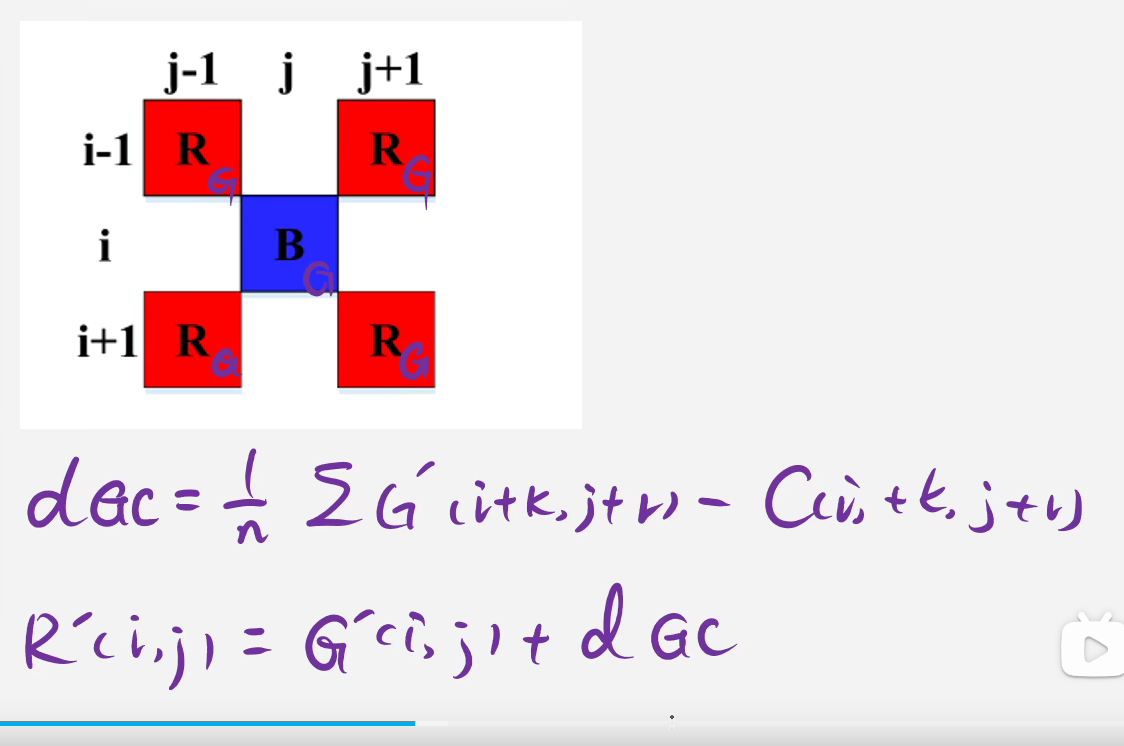
ISP--Demosaicking
文章目录 前言算法解释简单的线性插值代码实现 色差法和色比法基于方向加权的方法RB缺失的G通道的插值RB缺失的BR的插值G缺失的BR的插值代码实现 基于边缘检测的方法计算缺失的G计算缺失的RB值/计算缺失的G值 前言 人眼之所以有能感受到自然界的颜色,是因为人眼的感…...
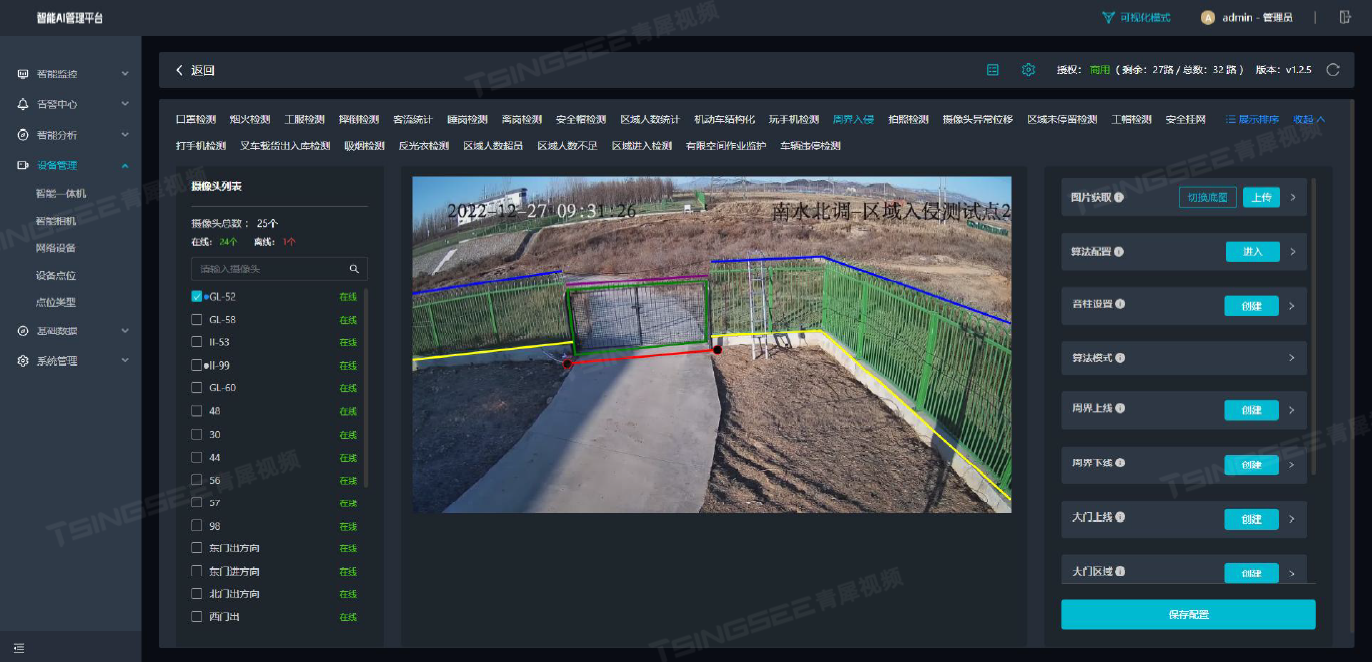
国标GB28181协议EasyCVR视频融合平台:5G时代远程监控赋能通信基站安全管理
一、背景介绍 随着移动通信行业的迅速发展,无人值守的通信基站建设规模不断扩大。这些基站大多建于偏远地区,周边人迹罕至、交通不便,给日常的维护带来了极大挑战。其中,位于空旷地带的基站设备,如空调、蓄电池等&…...

vue watch 和 watchEffect的区别和用法
在 Vue.js 里,watch 和 watchEffect 都用于响应式地追踪数据变化并执行相应操作,不过它们在使用方式、应用场景等方面存在差异。 1. watch watch 是 Vue 提供的一个选项,用于监听特定数据的变化。当监听的数据发生变化时,会触发…...

SQL 不走索引的常见情况
在 SQL 查询中,即使表上有索引,某些情况下数据库优化器也可能决定不使用索引。以下是常见的不走索引的情况: 1. 使用否定操作符 NOT IN ! 或 <> NOT EXISTS NOT LIKE 2. 对索引列使用函数或运算 -- 不走索引 SELECT * FROM user…...

git配置 gitcode -- windows 系统
版本 $ git --version git version 2.49.0.windows.1检查现有的 SSH 密钥 打开git-bash终端,执行以下命令查看是否已经生成过 SSH 密钥: ls -al ~/.ssh如果看到类似 id_rsa 和 id_rsa.pub(或者其他命名的密钥对)文件࿰…...

基于Kubeadm实现K8S集群扩缩容指南
一、集群缩容操作流程 1.1 缩容核心步骤 驱逐节点上的Pod 执行kubectl drain命令驱逐节点上的Pod,并忽略DaemonSet管理的Pod: kubectl drain <节点名> --ignore-daemonsets # 示例:驱逐worker233节点 kubectl drain worker233 --ignor…...