leetcode 算法每日一题 #1
#1 !
题目
3355. 零数组变换 I
中等
相关标签
相关企业
提示
给定一个长度为 n 的整数数组 nums 和一个二维数组 queries,其中 queries[i] = [li, ri]。对于每个查询 queries[i]:在 nums 的下标范围 [li, ri] 内选择一个下标 子集。
将选中的每个下标对应的元素值减 1。
零数组 是指所有元素都等于 0 的数组。如果在按顺序处理所有查询后,可以将 nums 转换为 零数组 ,则返回 true,否则返回 false。示例 1:输入: nums = [1,0,1], queries = [[0,2]]输出: true解释:对于 i = 0:
选择下标子集 [0, 2] 并将这些下标处的值减 1。
数组将变为 [0, 0, 0],这是一个零数组。
示例 2:输入: nums = [4,3,2,1], queries = [[1,3],[0,2]]输出: false解释:对于 i = 0:
选择下标子集 [1, 2, 3] 并将这些下标处的值减 1。
数组将变为 [4, 2, 1, 0]。
对于 i = 1:
选择下标子集 [0, 1, 2] 并将这些下标处的值减 1。
数组将变为 [3, 1, 0, 0],这不是一个零数组。提示:1 <= nums.length <= 105
0 <= nums[i] <= 105
1 <= queries.length <= 105
queries[i].length == 2
0 <= li <= ri < nums.length题目解读
题目要求判断能否通过一系列区间子集减 1 操作将数组变为零数组。关键是每个元素减少次数需等于初始值且不超过其被查询覆盖次数。用差分数组统计各位置覆盖次数,贪心从左到右分配次数,借前补后,最后检查剩余次数是否为零。
好的!我们再深入一层,从**问题本质**和**算法设计原理**的角度来拆解,帮助你彻底理解这个问题。### **一、问题的本质:流量分配模型**
可以把每个元素的减少次数看作“流量”,每个查询的区间看作“管道”,管道可以在区间内任意分配流量(即选择子集)。我们需要确保:
1. **每个元素的总流量等于初始值**(`nums[i]`)。
2. **每个查询的管道流量总和不超过其容量**(每个查询可以分配任意流量到区间内的元素,但总流量无上限,因为可以多次选择同一元素)。 - 这里的“容量”其实是无限的,因为每个查询可以多次选择同一元素(只要在区间内)。但**每个元素的总流量不能超过其被包含在查询中的次数**(即`count[i]`)。 **核心矛盾**:元素`i`的总流量(`nums[i]`)必须 ≤ 其被包含的查询次数(`count[i]`),并且流量必须能按查询顺序分配。### **二、差分数组的本质:区间覆盖次数统计**
为什么用差分数组?因为它能高效统计**每个元素被多少个查询区间覆盖**。
- 每个查询`[l, r]`相当于对区间`[l, r]`内的所有元素“允许增加一次流量”。
- 差分数组`diff`的作用是: - 在`l`处标记“开始允许流量”, - 在`r+1`处标记“结束允许流量”。
- 通过前缀和计算`count[i]`,得到每个元素被允许的总流量次数(即最多可以被减少多少次)。 **举个例子**:
查询序列`[[1,3], [0,2]]`对应差分数组操作:
```
diff[0] += 1 (允许位置0开始)
diff[3] -= 1 (位置3结束允许,即位置0-2允许)
diff[1] += 1 (允许位置1开始)
diff[4] -= 1 (位置4结束允许,即位置1-3允许)
```
计算前缀和后:
```
count[0] = 1 (被第2个查询覆盖)
count[1] = 1+1=2 (被两个查询覆盖)
count[2] = 2+0=2 (被两个查询覆盖)
count[3] = 2-1=1 (被第1个查询覆盖)
```
这表示:
- 位置0最多可被减少1次(只能在第2个查询中被选),
- 位置1和2最多可被减少2次(在两个查询中都能被选),
- 位置3最多可被减少1次(只能在第1个查询中被选)。### **三、贪心策略的核心:顺序约束与流量传递**
为什么必须从左到右处理?因为**查询是按顺序执行的**,左边元素的流量分配会影响右边元素的可用流量。
- **左边元素的流量只能来自前面的查询**(因为后面的查询还未执行),
- **右边元素的流量可以来自前面或后面的查询**(后面的查询在顺序上更靠后,执行时可以选择右边元素)。 #### **关键变量:borrow的物理意义**
`borrow`表示**前面所有查询中,覆盖当前元素的剩余可用流量**。
- 例如,前面的查询区间包含当前元素`i`,但前面的元素`0~i-1`没有用完这些查询的流量,剩下的流量可以“借给”当前元素`i`使用。
- 注意:这里的“前面查询”指的是所有查询,而不仅仅是顺序上的前几个查询。因为差分数组统计的是所有查询的覆盖次数,`count[i]`是总和,所以`borrow`实际上是**所有查询中覆盖`i`的流量,扣除前面元素已用的部分**。 #### **贪心流程的数学表达**
对于元素`i`:
1. **先使用borrow中的流量**: `used_borrow = min(borrow, nums[i])` `remaining = nums[i] - used_borrow` - 如果`borrow > nums[i]`,说明前面的剩余流量过多(后面的元素无法“归还”流量给前面),直接失败。 2. **再使用当前元素的count[i]流量**: - 如果`remaining > count[i]`,说明总流量不足,失败。 - 否则,当前元素用完`remaining`流量,剩余的`count[i] - remaining`流量可以“借给”后面的元素(因为这些流量来自包含`i`的查询,而这些查询可能还覆盖`i+1~n-1`的元素)。 - 所以,`borrow = count[i] - remaining`。 #### **为什么borrow只能累加,不能递减?**
因为流量只能从左向右传递(前面的查询覆盖当前元素后,剩余流量可以留给后面的元素,但后面的元素无法将流量反传给前面)。例如:
- 元素`i`处理完后,剩余流量`borrow`只能来自包含`i`的查询,而这些查询必然也包含`i+1`(如果查询区间包含`i`,且右端点≥`i`,则可能包含`i+1`)。因此,`borrow`可以安全地传递给`i+1`。### **四、错误示例分析:为什么示例2无法满足?**
#### **示例2的参数**
- `nums = [4,3,2,1]`,
- `queries = [[1,3], [0,2]]`,
- 计算`count`数组: - 第一个查询覆盖1-3 → `diff[1] +=1`, `diff[4]-=1`, - 第二个查询覆盖0-2 → `diff[0] +=1`, `diff[3]-=1`, - 前缀和计算: ```count[0] = 1(仅第二个查询), count[1] = 1+1=2(两个查询), count[2] = 2+0=2(两个查询), count[3] = 2-1=1(仅第一个查询)。```#### **贪心流程**
- `borrow = 0`,遍历每个元素: 1. **元素0(nums[0]=4,count[0]=1)**: - `borrow=0`,`remaining = 4-0=4`。 - `count[0]=1 < 4`,直接失败。 - **结论**:元素0需要4次流量,但只能被包含在1个查询中(第二个查询),无法满足,返回`false`。 这解释了为什么示例2失败:**元素0的初始值超过了其被包含的查询次数**,无论怎么分配都无法满足。### **五、算法的边界条件处理**
1. **nums[i] = 0的情况**: - 该元素不需要任何流量,其`count[i]`可以全部剩余,累加到`borrow`中。 2. **最后一个元素处理完后,borrow必须为0**: - 因为后面没有元素可以接收剩余流量,所有流量必须被用完。例如: - `nums = [0,1]`,`queries = [[0,1]]`, - `count = [1,1]`, - 元素0不需要流量,`borrow`初始为0,处理元素0后,`borrow = 1-0=1`, - 元素1需要1次流量,用`borrow`中的1次,`count[1]=1`剩余`1-1=0`,`borrow=0`,最终成功。 3. **borrow可能为负数吗?** - 不会。因为`remaining = max(0, nums[i] - borrow)`,当`borrow >= nums[i]`时,`remaining=0`,`borrow`只会保留`count[i]`的剩余部分(非负数)。### **六、总结:从暴力到优化的思维路径**
#### **暴力思路(不可行)**
- 对每个查询,记录哪些元素被选中,但时间复杂度太高(`O(mn)`)。 #### **优化思路**
- **差分数组**:将区间操作转化为前缀和问题,快速得到每个元素的总可用流量次数(`count[i]`)。
- **贪心策略**:利用查询的顺序性,从左到右分配流量,确保每个元素的流量需求被满足,且剩余流量可传递给右侧元素。 #### **核心公式**
```
对于每个元素i:
1. remaining = max(0, nums[i] - borrow)
2. if remaining > count[i]: 失败
3. borrow = count[i] - remaining
最后检查borrow == 0
```### **七、代码逐行解析(Java版本)**
```java
public boolean checkArray(int[] nums, int[][] queries) {int n = nums.length;int[] diff = new int[n + 1]; // 差分数组,长度n+1// 处理每个查询,更新差分数组for (int[] q : queries) {int l = q[0];int r = q[1];diff[l]++; // 区间起点+1diff[r + 1]--; // 区间终点+1的位置-1,确保区间[l, r]有效}// 计算前缀和,得到每个位置的查询次数count[i]int[] count = new int[n];count[0] = diff[0]; // 第一个元素的countfor (int i = 1; i < n; i++) {count[i] = count[i - 1] + diff[i]; // 前缀和}long borrow = 0; // 使用long避免整数溢出for (int i = 0; i < n; i++) {int x = nums[i];if (borrow > x) { // 前面剩余的流量超过当前需要,不可能return false;}x -= borrow; // 先用borrow中的流量if (x < 0) { // 防止负数(虽然borrow<=x时x不会负,但保险起见)x = 0;}if (count[i] < x) { // 当前位置的流量不够return false;}borrow = count[i] - x; // 剩余流量借给后面}return borrow == 0; // 确保所有流量用完
}
```### **八、常见误区与解答**
#### **误区1:count[i]是每个查询中必须选i的次数**
- 错误。count[i]是**所有查询中包含i的次数总和**,每次查询可以选择是否选i。例如,count[i]=3表示i出现在3个查询的区间中,每个查询中可以选择选或不选i,总次数不超过3。 #### **误区2:borrow是前面查询剩余的次数,与当前查询无关**
- 正确。borrow是**所有查询中包含i的剩余次数**,无论这些查询在顺序上是前还是后。因为差分数组统计的是总和,贪心策略通过从左到右处理,隐式地将后面查询的次数分配给右侧元素。 #### **误区3:最后borrow可以不为0**
- 错误。如果borrow>0,说明存在未使用的流量,这些流量来自包含最后一个元素的查询,但后面没有元素可以使用它们,因此必须用完(即borrow=0)。
差分数组
贪心策略
相关文章:

leetcode 算法每日一题 #1
#1 ! 题目 3355. 零数组变换 I 中等 相关标签 相关企业 提示 给定一个长度为 n 的整数数组 nums 和一个二维数组 queries,其中 queries[i] [li, ri]。对于每个查询 queries[i]:在 nums 的下标范围 [li, ri] 内选择一个下标 子集。 将选中的…...

用matlab提取abaqus odb文件中的节点信息
在MATLAB中提取Abaqus ODB文件中的节点信息,可以通过以下几种方法实现: 方法1:使用MATLAB的ABAQUS Interface工具箱 https://wenku.csdn.net/answer/77axwtqnys 可以参考这个 MATLAB的ABAQUS Interface工具箱提供了直接读取ODB文件的功能。…...

Spring Bean 注册到容器的方式
Spring Bean 注册到容器的方式主要包括以下几种: 基于 XML 的配置 使用 XML 文件配置 Bean,并定义 Bean 的依赖关系。 基于 Component 注解及其衍生注解 使用注解如 Component、Service、Controller、Repository 等进行配置。 基于 Configuration 和…...
)
1537. 【中山市第十一届信息学邀请赛决赛】未命名 (noname)
题目描述 这是一个独一无二的世界,所以有 N 张写有互不相同的自然数的卡片,第 i 张卡片写着 Ai ,现在你得到了一个未命名的空白卡片,想在上面写上一个自然数 x 满足以下条件: 1.x 不等于任意一张卡片上的数字。 2.x 可…...

数据库三范式详解与应用建议
数据库三范式(Normalization)是关系型数据库设计的核心原则,旨在减少数据冗余、提高数据一致性,并避免插入、更新和删除异常。以下是三范式的详细说明: 第一范式(1NF) 核心要求:确保…...

信息学奥赛一本通 1539:简单题 | 洛谷 P5057 [CQOI2006] 简单题
【题目链接】 ybt 1539:简单题 洛谷 P5057 [CQOI2006] 简单题 【题目考点】 1. 树状数组 知识点讲解见:洛谷 P3374 【模板】树状数组 【解题思路】 解法1:树状数组 该有01构成数组初值都为0。 某位置的元素被修改奇数次后值为1&#x…...
C++笔记-封装红黑树实现set和map
1.源码及框架分析 上面就是在stl库中set和map的部分源代码。 通过上图对框架的分析,我们可以看到源码中rb_tree⽤了⼀个巧妙的泛型思想实现,rb_tree是实 现key的搜索场景,还是key/value的搜索场景不是直接写死的,⽽是由第⼆个模板…...

deepseek模拟美团高级java开发工程师面试题
美团高级Java开发工程师面试题及参考答案 一、Java基础部分 1. HashMap实现原理 题目: 请详细描述JDK8中HashMap的实现原理为什么JDK8要将链表转为红黑树?阈值为什么是8?HashMap在多线程环境下会出现什么问题?如何解决&#x…...

留给王小川的时间不多了
王小川,这位头顶“天才少年”光环的清华学霸、搜狗输入法创始人、中国互联网初代技术偶像,正迎来人生中最难啃的硬骨头。 他在2023年创立的百川智能,被称为“大模型六小虎”之一。今年4月,王小川在全员信中罕见地反思过去两年工作…...

回溯算法:解锁多种问题的解决之门
经典回溯算法 回溯算法是一种基于深度优先搜索的算法,通过探索所有可能的候选解来找出所有可能的解。当候选解不满足条件时,会回溯到上一步,尝试其他的候选解。下面将介绍回溯算法在组合问题、切割问题、排列问题、子集问题、棋盘问题和图的…...

国产频谱仪性能如何?矢量信号分析仪到底怎么样?
矢量信号分析仪是一种高性能的电子测量设备,具备频谱分析、矢量信号分析、实时频谱分析、脉冲信号分析、噪声系数测量、相位噪声测量等多种功能。它能够对各类复杂信号进行精确的频谱特性分析、调制质量评估、信号完整性检测以及干扰源定位等操作。广泛应用于通信、…...
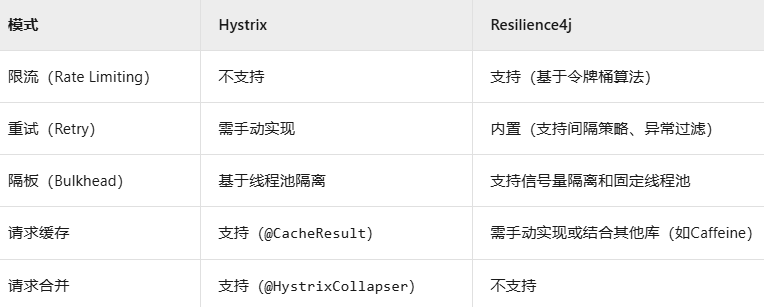
熔断器(Hystrix,Resilience4j)
熔断器 核心原理 熔断器通过监控服务调用失败率,在达到阈值时自动切断请求,进入熔断状态(类似电路保险丝)。其核心流程为: 关闭状态(Closed):正常处理请求,统计失…...

贪心算法套路模板+详细适用场景+经典题目清单
1. 排序 贪心选择 适用场景: 任务调度问题:需要安排多个任务,尽量完成更多任务或最小冲突。 区间调度问题:选出最多互不重叠的区间。 区间覆盖问题:用最少区间覆盖某个范围。 合并区间问题:合并重叠区…...

C++23 容器从其他兼容范围的可构造性与可赋值性 (P1206R7)
文章目录 背景与动机提案内容与实现细节提案 P1206R7实现细节编译器支持 对开发者的影响提高灵活性简化代码向后兼容性 总结 C23标准引入了对容器构造和赋值的新特性,这些特性使得容器能够更灵活地从其他兼容范围初始化,并支持从范围赋值。这些改进由提案…...

多通道振弦式数据采集仪MCU安装指南
设备介绍 数据采集仪 MCU集传统数据采集器与5G/4G,LoRa/RS485两种通信功能与一体的智能数据采集仪。该产品提供振弦、RS-485等的物理接口,能自动采集并存储多种自然资源、建筑、桥梁、城市管廊、大坝、隧道、水利、气象传感器的实时数据,利用现场采集的数…...

Axios中POST、PUT、PATCH用法区别
在 Axios 中,POST、PUT 和 PATCH 是用于发送 HTTP 请求的三种不同方法,它们的核心区别源自 HTTP 协议的设计语义。以下是它们的用法和区别: 1. POST 语义:用于创建新资源。 特点: 非幂等(多次调用可能产生…...

synchronized 实现原理
1. 对象头与 Mark Word 每个 Java 对象在内存中分为三部分:对象头、实例数据 和 对齐填充。 对象头 是核心部分,包含以下信息: Mark Word(标记字段):存储对象的哈希码、分代年龄、锁状态等。Klass Pointe…...

SOC-ESP32S3部分:9-GPIO输入按键状态读取
飞书文档https://x509p6c8to.feishu.cn/wiki/L6IGwHKV6ikQ08kqwAwcAvhznBc 前面我们学习了GPIO的输出,GPIO输入部分其实也是一样的,这里我们使用按键作为GPIO输入例程讲解,分三步走。 查看板卡原理图,确定使用的是哪个GPIO查看G…...
学习笔记(CLASS 2):WXML模板语法与WXSS模板样式)
前端(小程序)学习笔记(CLASS 2):WXML模板语法与WXSS模板样式
1、数据绑定 数据绑定的基本原则 1、在data中定义数据 在页面对应的.js文件中,把数据定义到data对象中即可: Page({data: {//字符串类型的数据info: init data,//数组类型的数据msgList: [{msg: hello}, {msg: world}]} }) 2、在WXML中使用数据(Mus…...
Ubuntu20.04的安装(VMware)
1.Ubuntu20.04.iso文件下载 下载网址:ubuntu-releases-20.04安装包下载_开源镜像站-阿里云 2.创建虚拟环境 2.1打开VMware与创建新虚拟机 点击创建新虚拟机 如果没下好可以点击稍后安装操作系统 选择linux版本选择Ubuntu 64位然后点击下一步。 注意这里需要选择一…...
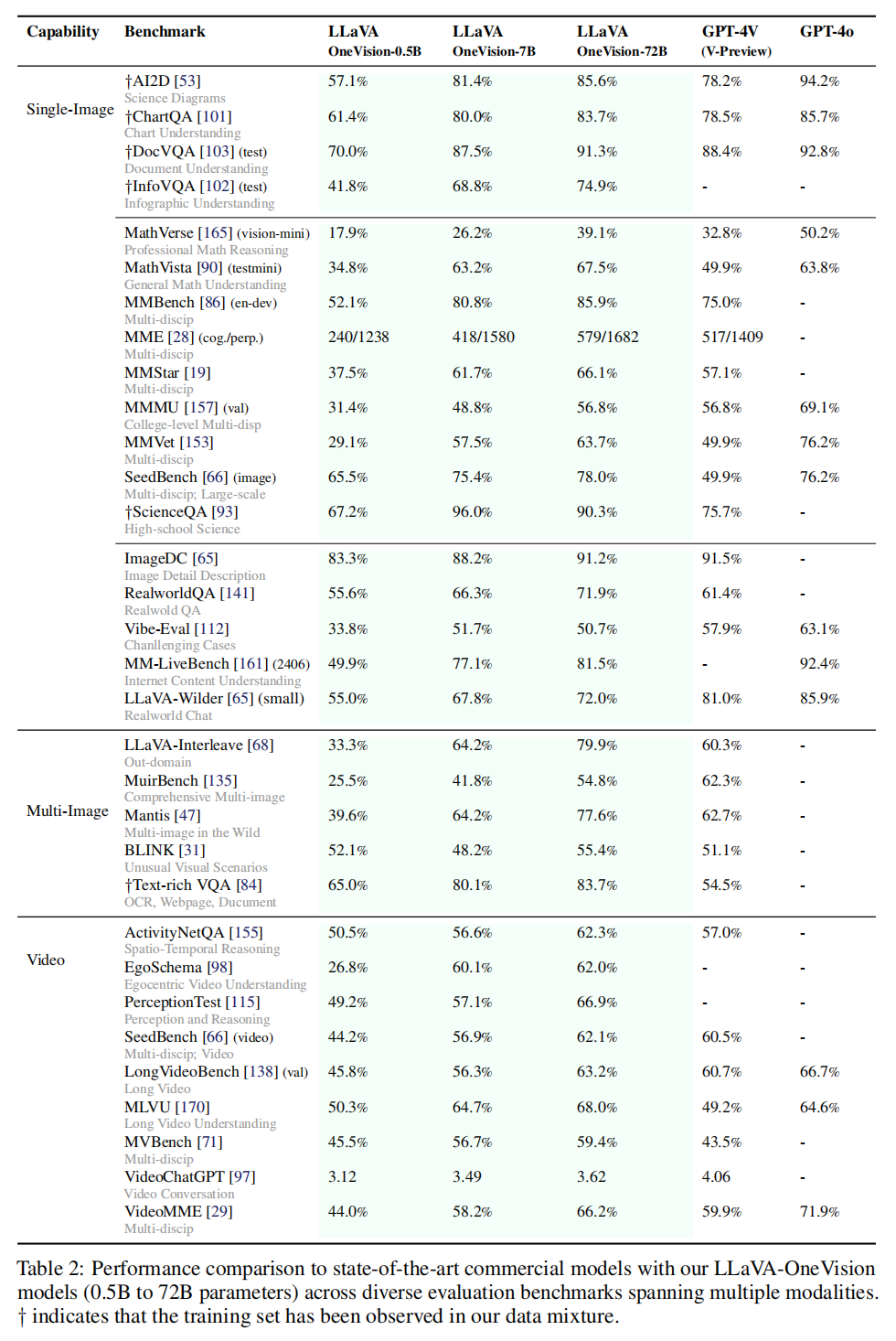
【论文阅读】LLaVA-OneVision: Easy Visual Task Transfer
LLaVA-OneVision: Easy Visual Task Transfer 原文摘要 研究背景与目标 开发动机: 基于LLaVA-NeXT博客系列对数据、模型和视觉表征的探索,团队整合经验开发了开源大型多模态模型 LLaVA-OneVision。 核心目标: 突破现有开源LMM的局限…...
Spring Boot 项目多数据源配置【dynamic datasource】
前言: 随着互联网的发展,数据库的读写分离、数据迁移、多系统数据访问等多数据源的需求越来越多,我们在日常项目开发中,也不可避免的为了解决这个问题,本篇来分享一下在 Spring Boot 项目中使用多数据源访问不通的数据…...
JAVA查漏补缺(2)
AJAX 什么是Ajax Ajax(Asynchronous Javascript And XML),即是异步的JavaScript和XML,Ajax其实就是浏览器与服务器之间的一种异步通信方式 异步的JavaScript 它可以异步地向服务器发送请求,在等待响应的过程中&…...
【Web前端】JavaScript入门与基础(二)
Javascript对象 什么是对象?对象(object)是 JavaScript 语言的核心概念,也是最重要的数据类型。简单说,对象就是一组“键值对”(key-value)的集合,是一种无序的复合数据集合。 var…...

取消 Conda 默认进入 Base 环境
在安装 Conda 后,每次打开终端时默认会进入 base 环境。可以通过以下方法取消这一默认设置。 方法一:使用命令行修改配置 在终端中输入以下命令,将 auto_activate_base 参数设置为 false: conda config --set auto_activate_ba…...
Electron+vite+vue3 从0到1搭建项目,开发Win、Mac客户端
随着前端技术的发展,出现了所谓的大前端。 大前端则是指基于前端技术延伸出来的各种终端平台及应用场景,包括APP、桌面端、手表终端、服务端等。 本篇文章主要是和大家一起学习一下使用Electron 如何打包出 Windows 和 Mac 所使用的客户端APPÿ…...

《深度揭秘:解锁智能体大模型自我知识盲区探测》
当面对超出其训练数据边界和固有知识范畴的问题时,智能体大模型往往会陷入困境,却浑然不知,这便是知识盲区带来的隐患。如何构建能够自动发现自身知识盲区的智能体大模型,成为当下人工智能领域亟待攻克的前沿难题,它关…...

打卡Day33
简单的神经网络 数据的准备 # 仍然用4特征,3分类的鸢尾花数据集作为我们今天的数据集 from sklearn.datasets import load_iris from sklearn.model_selection import train_test_split import numpy as np# 加载鸢尾花数据集 iris load_iris() X iris.data # …...

计算机组成原理-基本运算部件定点数的运算
2.2基本运算部件 整理自up主beokayy_ 1.加法器 一位全加器 全加器是最基本的加法单元: 三个输入端:加数Ai,加数Bi,低位传进来的进位C1-1两个输出端:本位和S,向高位的进位C 全加器的逻辑表达式: SiAi⊕Bi⊕Ci-1CiAiBi(Ai⊕Bi)C…...
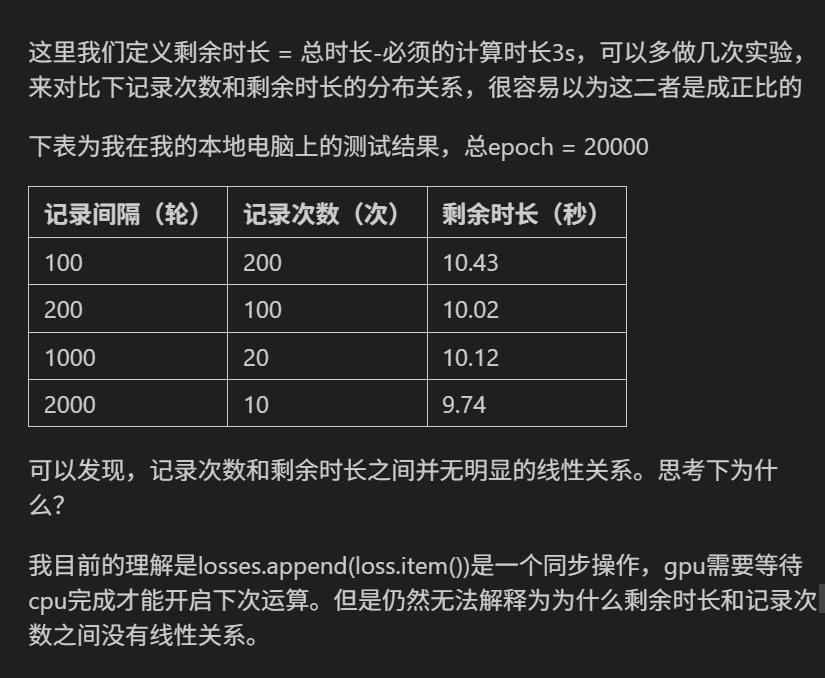
python打卡day34@浙大疏锦行
知识点回归: CPU性能的查看:看架构代际、核心数、线程数GPU性能的查看:看显存、看级别、看架构代际GPU训练的方法:数据和模型移动到GPU device上类的call方法:为什么定义前向传播时可以直接写作self.fc1(x) ①CPU性能查…...