Innodb底层原理与Mysql日志机制深入刨析
MySQL的内部组件结构
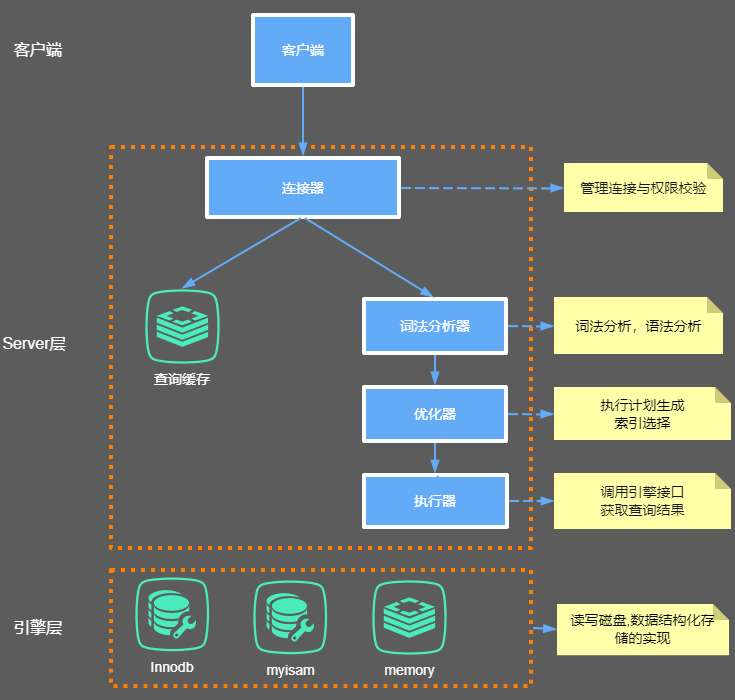
大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。
Server层
主要包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实现,比如存储过程、触发器、视图等。
存储引擎层
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。也就是说如果我们在create table时不指定表的存储引擎类型,默认会给你设置存储引擎为InnoDB。
下面我们来看下Server层的连接器、查询缓存、分析器、优化器、执行器分别主要干了哪些事情。
连接器
我们知道由于MySQL是开源的,他有非常多种类的客户端:navicat,mysql front,jdbc,SQLyog等非常丰富的客户端,包括各种编程语言实现的客户端连接程序,这些客户端要向mysql发起通信都必须先跟Server端建立通信连接,而建立连接的工作就是有连接器完成的。
第一步,你会先连接到这个数据库上,这时候接待你的就是连接器。连接器负责跟客户端建立连接、获取权限、维持和管理连接。连接命令一般是这么写的:
[root@192 ~]# mysql -h host[数据库地址] -u root[用户] -p root[密码] -P 3306
连接命令中的 mysql 是客户端工具,用来跟服务端建立连接。在完成经典的 TCP 握手后,连接器就要开始认证你的身份,这个时候用的就是你输入的用户名和密码。
1、如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
2、如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
这就意味着,一个用户成功建立连接后,即使你用管理员账号对这个用户的权限做了修改,也不会影响已经存在连接的权限。修改完成后,只有再新建的连接才会使用新的权限设置。
查询缓存
连接建立完成后,你就可以执行 select 语句了。执行逻辑就会来到第二步:查询缓存。
MySQL 拿到一个查询请求后,会先到查询缓存看看,之前是不是执行过这条语句。之前执行过的语句及其结果可能会以 key-value 对的形式,被直接缓存在内存中。key 是查询的语句,value 是查询的结果。如果你的查询能够直接在这个缓存中找到 key,那么这个 value 就会被直接返回给客户端。
如果语句不在查询缓存中,就会继续后面的执行阶段。执行完成后,执行结果会被存入查询缓存中。你可以看到,如果查询命中缓存,MySQL 不需要执行后面的复杂操作,就可以直接返回结果,这个效率会很高。
大多数情况查询缓存就是个鸡肋,为什么呢?
因为查询缓存往往弊大于利。查询缓存的失效非常频繁,只要有对一个表的更新,这个表上所有的查询缓存都会被清空。因此很可能你费劲地把结果存起来,还没使用呢,就被一个更新全清空了。对于更新压力大的数据库来说,查询缓存的命中率会非常低。
一般建议大家在静态表里使用查询缓存,什么叫静态表呢?就是一般我们极少更新的表。比如,一个系统配置表、字典表,那这张表上的查询才适合使用查询缓存。好在 MySQL 也提供了这种“按需使用”的方式。你可以将my.cnf参数 query_cache_type 设置成 DEMAND。
my.cnf
#query_cache_type有3个值 0代表关闭查询缓存OFF,1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE关键词时才缓存
query_cache_type=2
这样对于默认的 SQL 语句都不使用查询缓存。而对于你确定要使用查询缓存的语句,可以用 SQL_CACHE 显式指定,像下面这个语句一样:
mysql> select SQL_CACHE * from test where ID=5;
查看当前mysql实例是否开启缓存机制
mysql> show global variables like "%query_cache_type%";
mysql 8.0已经移除了查询缓存功能
分析器
如果没有命中查询缓存,就要开始真正执行语句了。首先,MySQL 需要知道你要做什么,因此需要对 SQL 语句做解析。
分析器先会做“词法分析”。你输入的是由多个字符串和空格组成的一条 SQL 语句,MySQL 需要识别出里面的字符串分别是什么,代表什么。
MySQL 从你输入的"select"这个关键字识别出来,这是一个查询语句。它也要把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”。
做完了这些识别以后,就要做“语法分析”。根据词法分析的结果,语法分析器会根据语法规则,判断你输入的这个 SQL 语句是否满足 MySQL 语法。
如果你的语句不对,就会收到“You have an error in your SQL syntax”的错误提醒,比如下面这个语句 from 写成了 “rom”。
mysql>select * fro test where id=1;
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'fro test where id=1' at line 1
下图是分析器对sql的分析过程步骤:
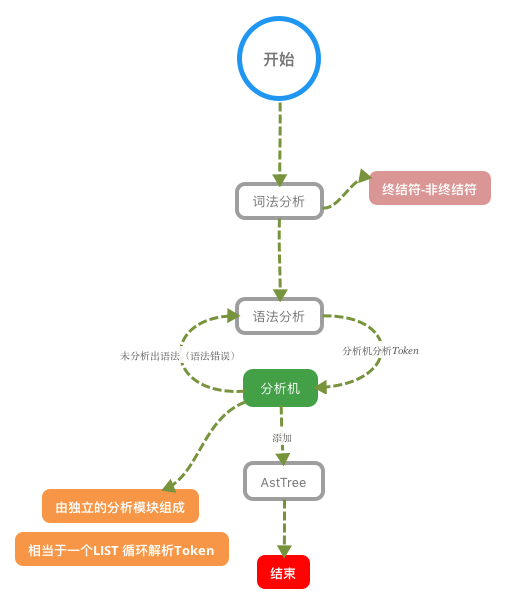
SQL语句经过分析器分析之后,会生成一个这样的语法树
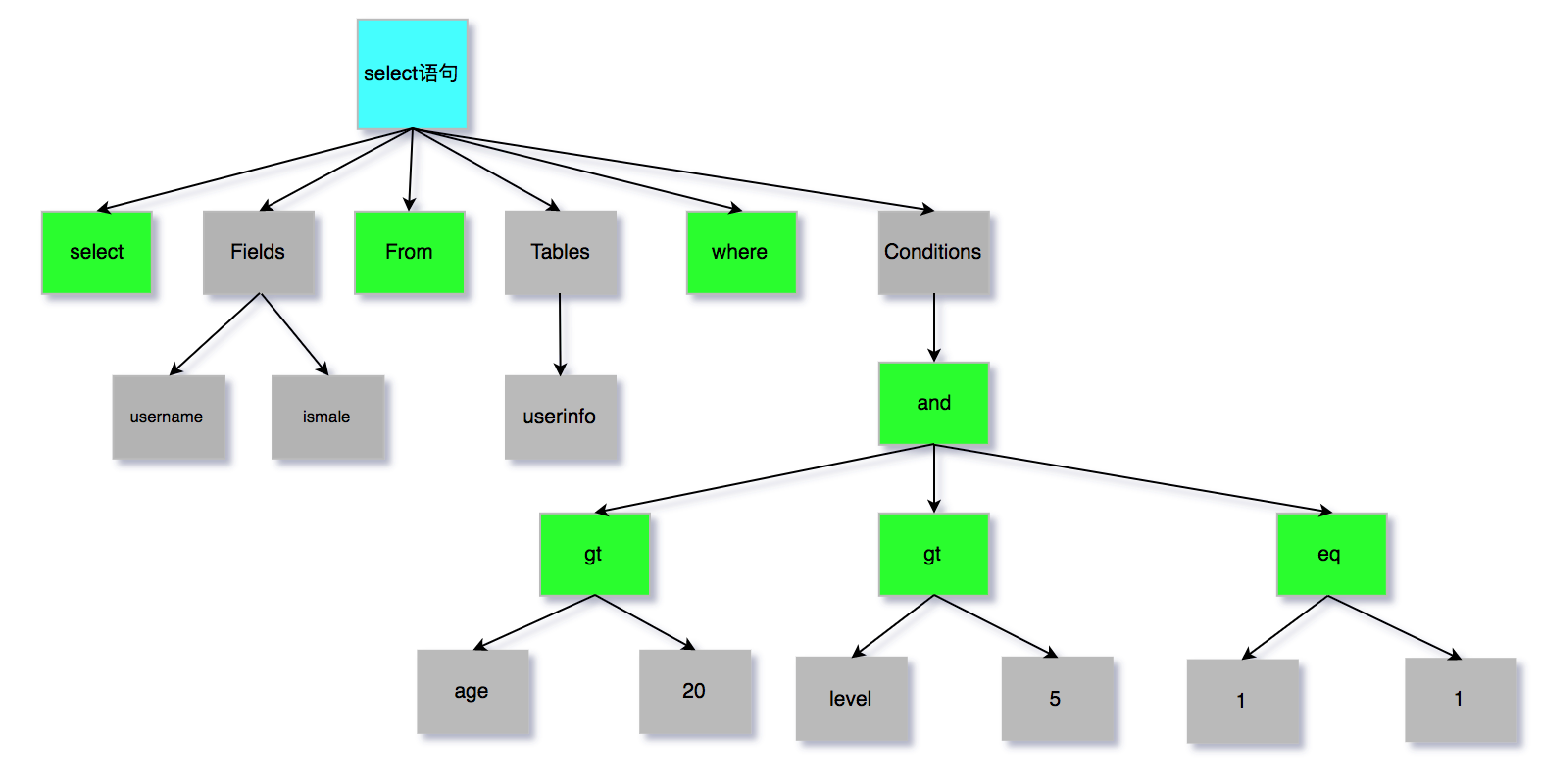
至此我们分析器的工作任务也基本圆满了。接下来进入到优化器
优化器
经过了分析器,MySQL 就知道你要做什么了。在开始执行之前,还要先经过优化器的处理。
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序;以及一些mysql自己内部的优化机制。
执行器
开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限,如果没有,就会返回没有权限的错误,如下所示 (在工程实现上,如果命中查询缓存,会在查询缓存返回结果的时候,做权限验证)。
mysql> select * from test where id=10;
如果有权限,就打开表继续执行。打开表的时候,执行器就会根据表的引擎定义,去使用这个引擎提供的接口。
Innodb底层原理与Mysql日志机制
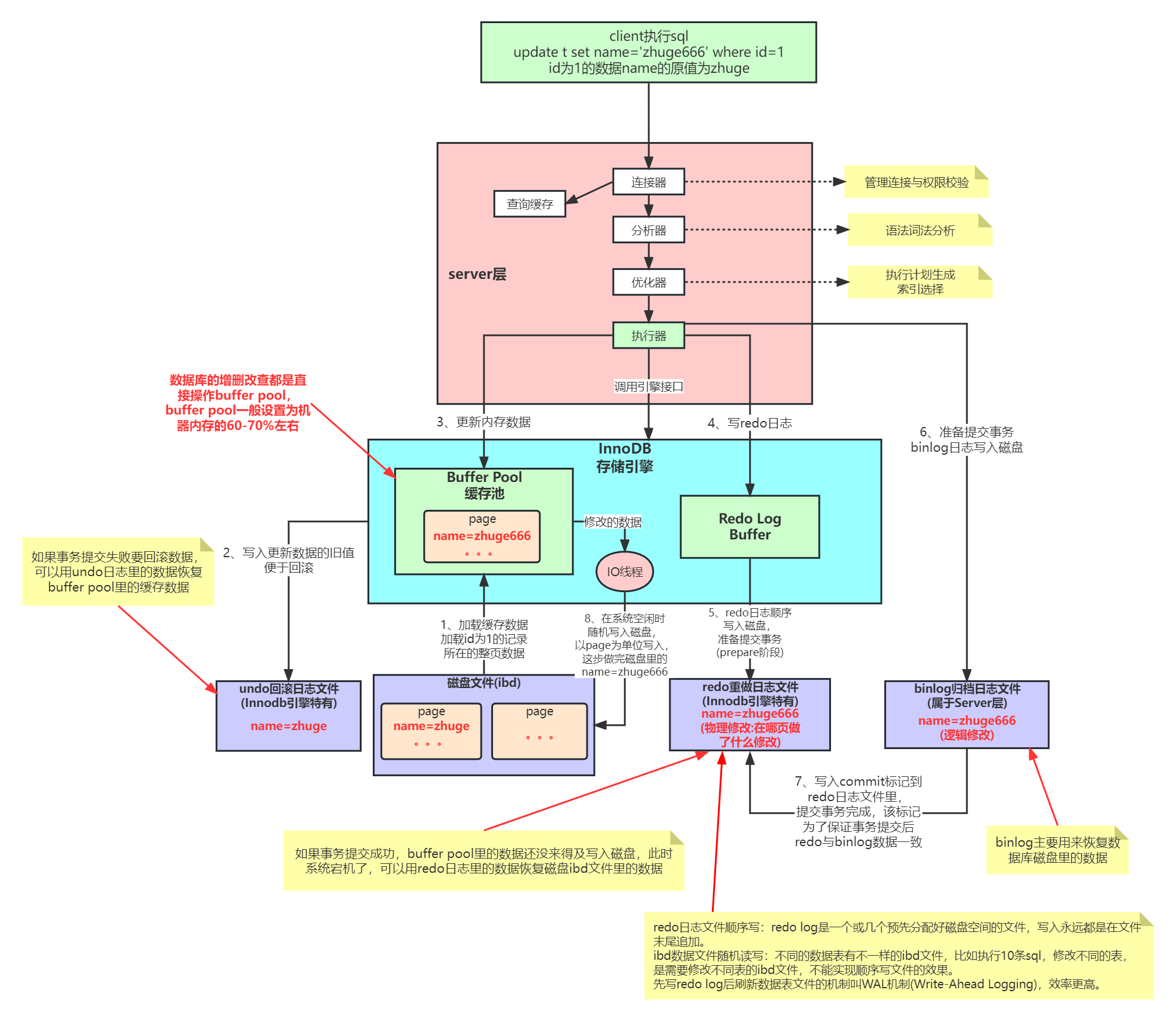
redo log重做日志关键参数
innodb_log_buffer_size:设置redo log buffer大小参数,默认16M ,最大值是4096M,最小值为1M。
show variables like '%innodb_log_buffer_size%';
innodb_log_files_in_group:设置redo log文件的个数,命名方式如: ib_logfile0, iblogfile1… iblogfileN。默认2个,最大100个。
show variables like '%innodb_log_files_in_group%';
innodb_log_file_size:设置单个redo log文件大小,默认值为48M。最大值为512G,注意最大值指的是整个 redo log系列文件之和,即(innodb_log_files_in_group * innodb_log_file_size)不能大于最大值512G。
show variables like '%innodb_log_file_size%';
redo log 写入磁盘过程分析:
redo log 从头开始写,写完一个文件继续写另一个文件,写到最后一个文件末尾就又回到第一个文件开头循环写,如下面这个图所示。
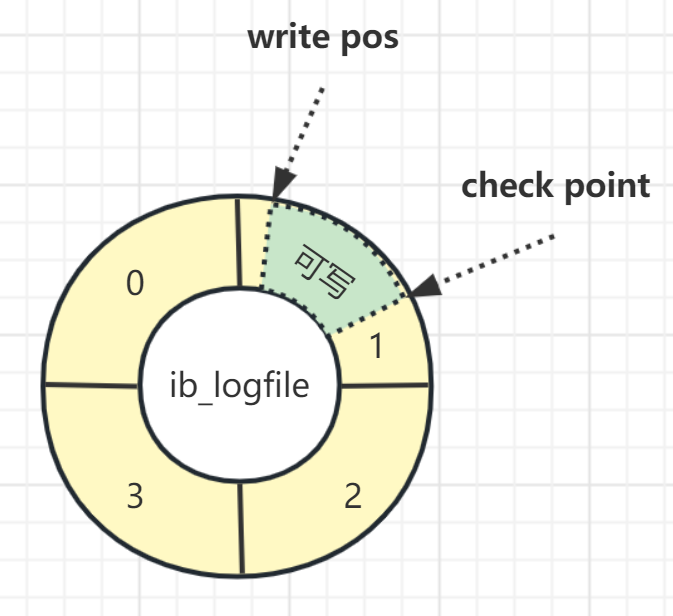
write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。
checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文件里。
write pos 和 checkpoint 之间的部分就是空着的可写部分,可以用来记录新的操作。如果 write pos 追上checkpoint,表示redo log写满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把 checkpoint 推进一下。
innodb_flush_log_at_trx_commit:这个参数控制 redo log 的写入策略,它有三种可能取值:
设置为0:表示每次事务提交时都只是把 redo log 留在 redo log buffer 中,数据库宕机可能会丢失数据。
设置为1(默认值):表示每次事务提交时都将 redo log 直接持久化到磁盘,数据最安全,不会因为数据库宕机丢失数据,但是效率稍微差一点,线上系统推荐这个设置。
设置为2:表示每次事务提交时都只是把 redo log 写到操作系统的缓存page cache里,这种情况如果数据库宕机是不会丢失数据的,但是操作系统如果宕机了,page cache里的数据还没来得及写入磁盘文件的话就会丢失数据。
InnoDB 有一个后台线程,每隔 1 秒,就会把 redo log buffer 中的日志,调用 操作系统函数 write 写到文件系统的 page cache,然后调用操作系统函数 fsync 持久化到磁盘文件。
redo log写入策略参看下图:
相关文章:
Innodb底层原理与Mysql日志机制深入刨析
MySQL的内部组件结构 大体来说,MySQL 可以分为 Server 层和存储引擎层两部分。 Server层 主要包括连接器、查询缓存、分析器、优化器、执行器等,涵盖 MySQL 的大多数核心服务功能,以及所有的内置函数(如日期、时间、数学和加密函数等),所有跨存储引擎的功能都在这一层实…...
JMeter-SSE响应数据自动化
结构图 背景: 需要写一个JMeter脚本来进行自动化测试,主要是通过接口调用一些东西,同时要对响应的数据进行处理,包括不限于错误信息的输出。 1.SSE(摘录) SSE(Server-Sent Events)是一种基于HTTP协议、允许…...
泛型(1)
1.泛型的理解和好处 使用传统方法的问题分析 (1)不能对加入到集合ArrayList中的数据类型进行约束 (2)遍历的时候,需要进行类型装换,如果集合中的数量较大,对效率有影响. 使用泛型的好处 (1)使用泛型添加 (检查元素的类型,提高了安全性.) (2)减少了类型转换的次数,提高效率…...

esp8266 点灯科技远程控制继电器
手机端安装点灯科技app 打开 Arduino IDE 编辑: #define BLINKER_WIFI #include <Blinker.h> char auth[] "点灯科技 key"; char ssid[] "wifi ID"; char pswd[] "WiFi key"; // 新建组件对象 BlinkerButton Button1(&q…...
MMA: Multi-Modal Adapter for Vision-Language Models论文解读
abstract 预训练视觉语言模型(VLMs)已成为各种下游任务中迁移学习的优秀基础模型。然而,针对少样本泛化任务对VLMs进行微调时,面临着“判别性—泛化性”困境,即需要保留通用知识,同时对任务特定知识进行微…...

Java中Map集合的遍历方式详解
Java中Map集合的遍历方式详解 一、Map 集合概述二、Map 遍历的基础方式1. **使用 KeySet 迭代器遍历**2. **使用 KeySet 的 for-each 循环** 三、EntrySet 遍历:高效的键值对访问1. **EntrySet 迭代器遍历**2. **EntrySet 的 for-each 循环** 四、Java 8 引入的 Lam…...
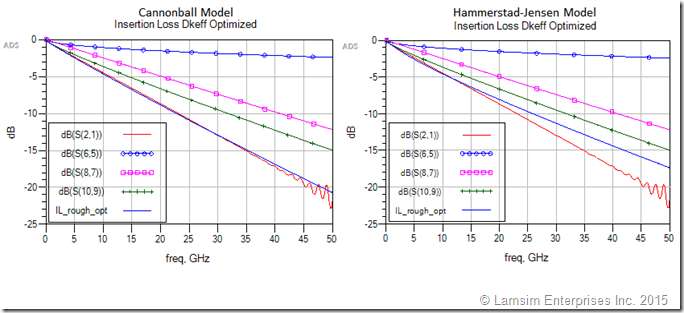
使用 Cannonballs 进行实用导体粗糙度建模
在 GB/s 制度下,导体损耗的精确建模是高速串行链路设计成功的前提。未能对粗糙度效果进行建模可能会毁了您的一天。例如,图 1 显示了与测量数据相比,无粗糙度的 40 英寸印刷电路板 (PCB) 走线的模拟总损耗。总损耗是电…...

Spring Boot 注解 @ConditionalOnMissingBean是什么
一句话总结: ConditionalOnMissingBean 是 Spring Boot 提供的一个 条件注解(Conditional Annotation),意思是: 只有当 Spring 容器中 不存在 某个 Bean 时,当前的 Bean 或配置才会被加载。 这是一种典型的…...
)
国外常用支付流程简易说明(无代码)
一、Xendit Xendit 是一家总部位于印度尼西亚的支付解决方案提供商,业务覆盖东南亚多个国家。它允许企业接受信用卡以及多种本地支付方式: 1、如果需要,创建一个 Xendit 帐户并登录Xendit 仪表板。 2、在页面左上角查看您的账户模式。使用…...
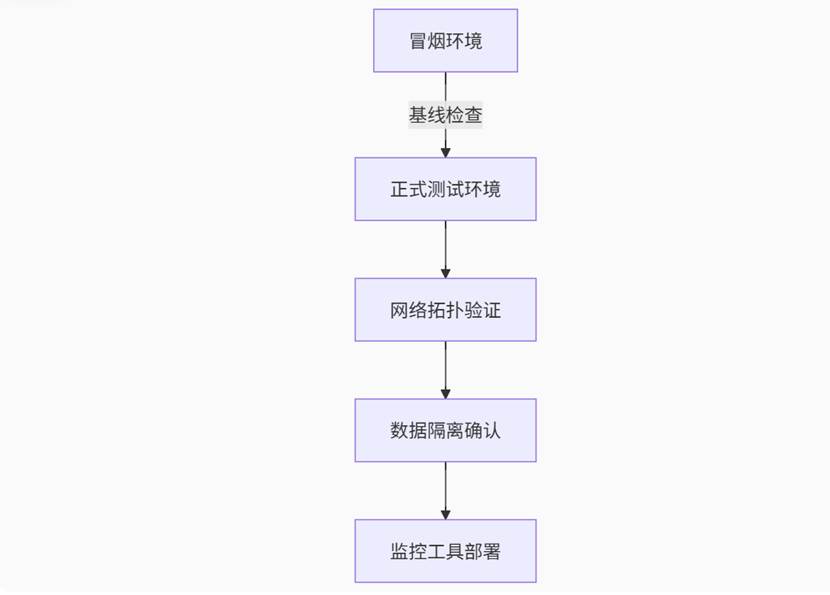
(先发再改)测试流程标准文档
Revision Record 修订记录 序号 修改日期 修改章节 修改描述 拟制 审批 修订版本 1 20250520 初稿 v1.0 目录 1. 文档概述... 7 1.1 文档目的... 7 1.1.1 标准化质量保障流程... 7 1.1.2.…...
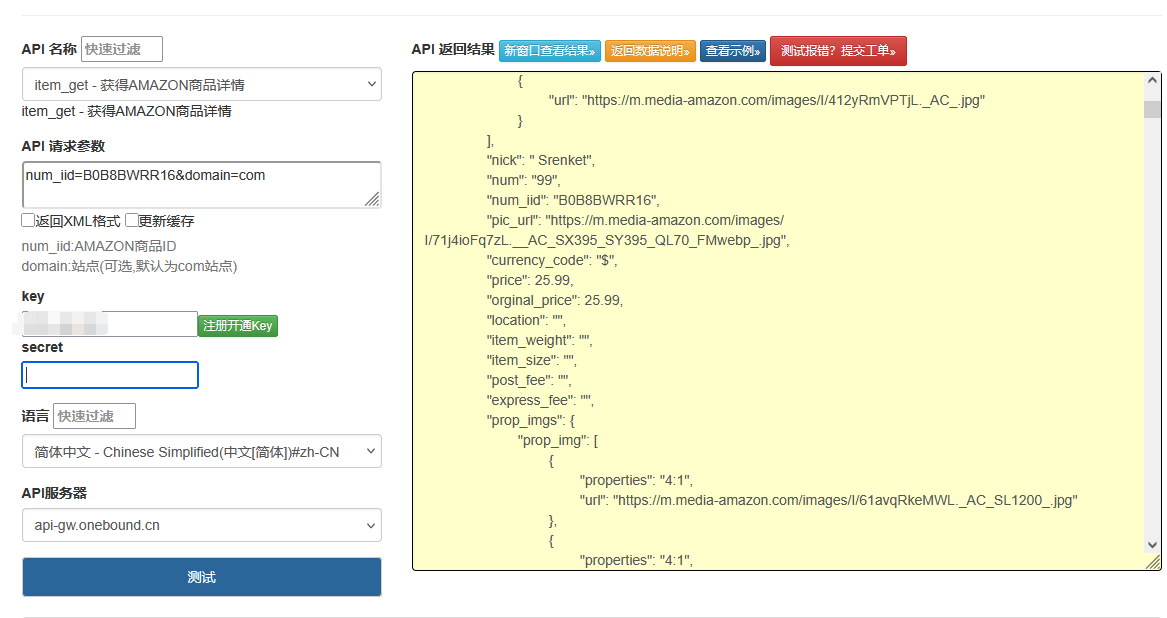
亚马逊SP-API开发实战:商品数据获取与操作
一、API接入准备 开发者注册: 登录亚马逊开发者中心申请SP-API权限 完成MWS迁移(如适用) 认证配置: # OAuth2.0认证示例 import requests auth_url "https://api.amazon.com/auth/o2/token" params { "…...

行为型:策略模式
目录 1、核心思想 2、实现方式 2.1 模式结构 2.2 实现案例 3、优缺点分析 4、适用场景 5、优化技巧 1、核心思想 目的:将算法(行为)抽象出来作为一系列策略类,使他们可以相互替换,使系统拥有“可插拔”扩展的能…...

知识宇宙-学习篇:开源项目 README 文档该如何写?
名人说:博观而约取,厚积而薄发。——苏轼《稼说送张琥》 创作者:Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder😊) 目录 一、README 文档的重要性1. 项目的第一印象2. 搜索引擎优化的重要载体 二、现代 RE…...

YOLOv12增加map75指标
YOLOv12源码:https://github.com/sunsmarterjie/yolov12 第一步:更改Val.py文件 地址:该文件在yolov12-main\ultralytics\models\yolo\detect下 首先定位到def get_desc(self):这个函数上 代码修正如下: def get_desc(self):&q…...

Avalanche 六期 Workshop 精华合集|Grant 机会、技术深度、项目实战一文回顾!
作为当前区块链技术的前沿代表,Avalanche 以其独特的高吞吐、低延迟、多链架构,为开发者提供了一种颠覆性的 Layer 1 解决方案。不同于传统的 EVM 兼容链,Avalanche 支持开发者自定义执行环境,灵活选择最适合自身业务需求的虚拟机…...

【MySQL】第九弹——索引(下)
文章目录 🌏索引(上)回顾🌏使用索引🪐自动创建索引🪐手动创建索引🚀主键索引🚀普通索引🚀唯一索引🚀复合索引 🪐查看索引🪐删除索引🚀删除主键索引…...

leetcode-295 Find Median from Data Stream
class MaxHeap {private heap: number[];constructor() {this.heap [];}// 插入元素并上浮调整push(num: number): void {this.heap.push(num);this.siftUp(this.heap.length - 1);}// 弹出堆顶元素并下沉调整pop(): number {const top this.heap[0];const last this.heap.p…...

【后端高阶面经:缓存篇】37、高并发系统缓存性能优化:从本地到分布式的全链路设计
一、缓存性能优化的核心价值与分层架构 (一)缓存的多维价值体系 延迟优化 内存访问速度(100ns) vs 磁盘数据库(10ms+),性能提升10万倍+案例:电商详情页通过缓存将响应时间从500ms降至50ms吞吐提升 单机Redis可支撑10万QPS,分担数据库压力案例:秒杀系统通过缓存拦截9…...

西门子 S1500 博途软件舞台威亚 3D 控制方案
西门子 S1500 PLC 是工业自动化领域的主流控制器,适合高精度、高可靠性的舞台威亚控制。下面为你提供基于博途 (TIA Portal) 软件的 3D 控制方案设计。 系统架构设计 舞台威亚 3D 控制系统通常包含以下组件: 硬件层: S1500 PLC 主机伺服驱动…...
)
洛谷 P3374 【模板】树状数组 1(线段树解法)
【题目链接】 洛谷 P3374 【模板】树状数组 1 【题目考点】 1. 线段树 线段树(Segment tree)是一种用来维护区间信息的数据结构。 线段树中每个结点代表一个区间 根结点代表整体区间。 叶子结点代表长为1的单位区间。 对于线段树中的每一个分支结点 [ l , r ] [l, r] [l,r]…...

欣佰特科技| SIL2/PLd 认证 Inxpect毫米波安全雷达:3D 扫描 + 微小运动检测守护工业安全
Inxpect 成立于意大利,专注工业安全技术。自成立起,便致力于借助先进雷达技术提升工业自动化安全标准,解决传统安全设备在复杂环境中的局限,推出获 SIL2/PLd 和 UL 认证的安全雷达产品。 Inxpect 的雷达传感器技术优势明显。相较于…...

大模型量化原理
模型量化的原理是通过降低数值精度来减少模型大小和计算复杂度。让我详细解释其核心原理:我已经为您创建了一个全面的模型量化原理详解文档。总结几个核心要点: 量化的本质 量化的核心是精度换性能的权衡——通过降低数值精度(FP32→INT8&a…...

dify-api的.env配置文件
源码位置:dify\api\.env 本文使用Dify v1.3.1。配置文件中各变量的详细信息表,如下所示: 变量英文名变量中文名默认值变量功能SECRET_KEY秘密密钥XXX用于安全地签署会话cookie的应用秘密密钥。确保在部署时使用强密钥。CONSOLE_API_URL控制…...
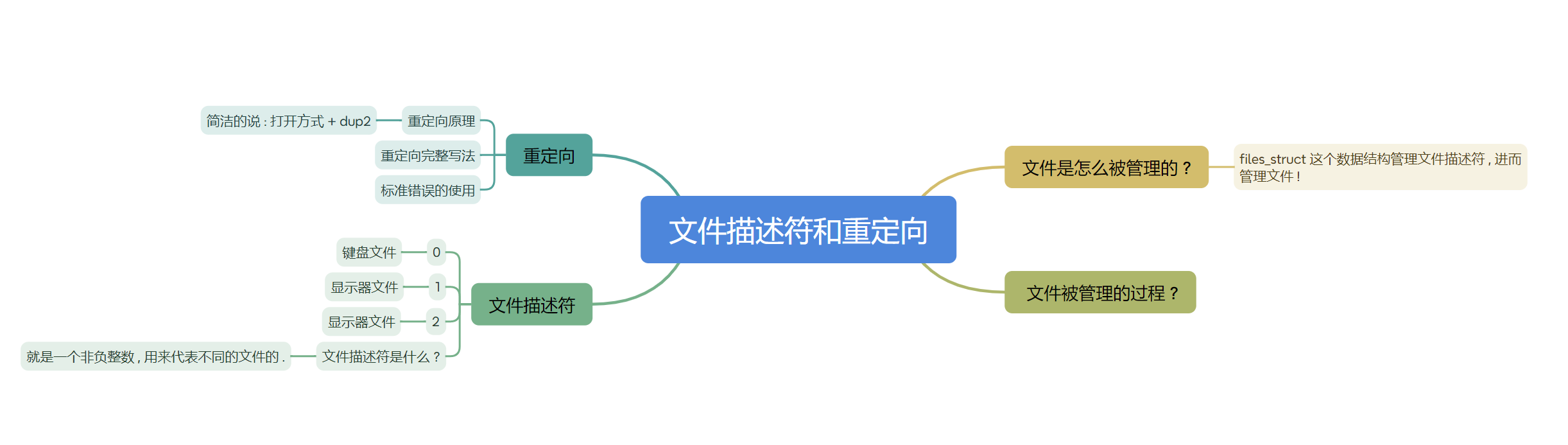
【Linux】Linux 操作系统 - 18 , 重谈文件(二) ~ 文件描述符和重定向原理 , 手把手带你彻底理解 !!!
文章目录 ● 文件描述符一 、Linux 系统对文件的管理(要知道)二 、什么是文件描述符 fd ?三 、再探文件被管理过程(重要)四 、文件描述符 0 、1、21. 文件描述符的分配原则2. 提前认识三个默认打开的文件 ● 重定向原理(重要)一 、重定向现象二 、深入剖析重定向现象(重要)1…...
第五十三节:综合项目实践-车牌识别系统
一、项目背景与意义 车牌识别系统(LPR)是智能交通领域的核心技术之一,广泛应用于停车场管理、违章抓拍、高速公路收费等场景。本文将通过Python+OpenCV实现一个完整的车牌识别系统,涵盖图像预处理→车牌定位→字符分割→字符识别四大核心环节。 二、系统架构设计 技术栈组…...
)
AI时代新词-AI伦理(AI Ethics)
一、什么是AI伦理? AI伦理(AI Ethics)是指在人工智能(AI)的设计、开发、部署和使用过程中,涉及的道德、法律和社会问题的综合考量。它关注AI技术对人类社会、文化、价值观以及个人权利的影响,并…...

湖北理元理律师事务所债务优化服务中的“四维平衡“之道
债务问题解决需要兼顾多方利益,湖北理元理律师事务所通过独特的服务模式,在法律、经济、心理、社会四个维度建立平衡点。 一、法律维度的专业把控 合规性审查: 合同效力认定 诉讼时效核查 担保责任界定 程序合法性: 所有协…...

Git Push 失败:HTTP 413 Request Entity Too Large
Git Push 失败:HTTP 413 Request Entity Too Large 问题排查 在使用 Git 推送包含较大编译产物的项目时,你是否遇到过 HTTP 413 Request Entity Too Large 错误?这通常并不是 Git 的问题,而是 Web 服务器(如 Nginx&am…...
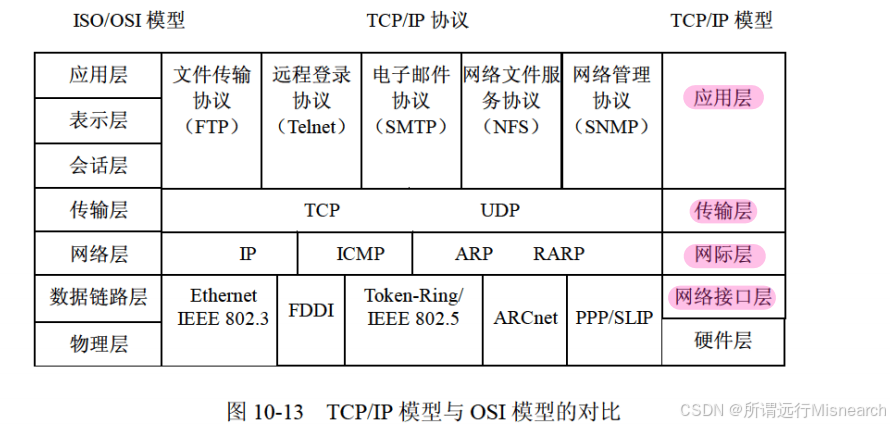
第10章 网络与信息安全基础知识
网络概述 多模光纤的特点:成本低,宽芯线,聚光好,耗散大,低效,用于低速度、短距离的通信。 单模光纤的特点:成本高,窄芯线,需要激光源,耗散小,高效…...
)
GO语言学习(九)
GO语言学习(九) 上一期我们了解了实现web的工作中极为重要的net/http抱的细节讲解,大家学会了实现web开发的一些底层基础知识,在这一期我来为大家讲解一下web工作的一个重要方法,:使用数据库,现…...