【计算机网络】第1章:概述—分组延时、丢失和吞吐量
目录
一、分组延时、丢失
1. 节点处理延时:
2. 排队延时:
3. 传输延时:
4. 传播延时:
5. 节点延时
6. 排队延时
7. 分组丢失
二、吞吐量
三、总结
(一)分组延时
1. 处理延时(Processing Delay)
2. 排队延时(Queuing Delay)
3. 传输延时(Transmission Delay)
4. 传播延时(Propagation Delay)
📌 总延时:
(二)分组丢失
1. 主要原因
2. 影响与应对
3. 丢包率(Loss Rate)
(三)吞吐量(Throughput)
1. 两种定义
2. 瓶颈带宽(Bottleneck Bandwidth)
3. 实际吞吐量影响因素
4. 吞吐量计算示例
(四)关键知识关联
一、分组延时、丢失
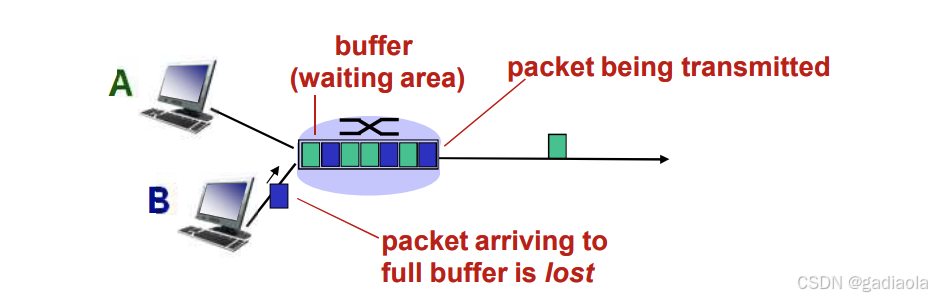
分组丢失和延时是怎样发生的?
在路由器缓冲区的分组队列
☐ 分组到达链路的速率超过了链路输出的能力
☐ 分组等待排到队头、被传输
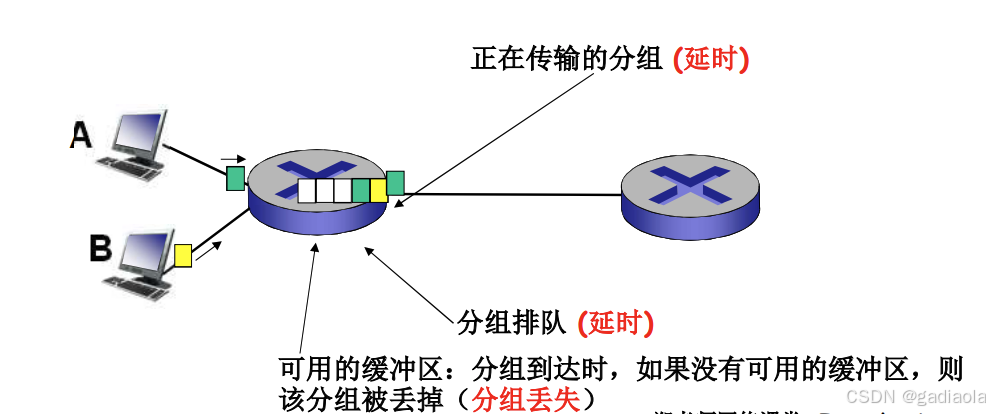
四种分组延时
1. 节点处理延时:
- 检查 bit 级差错
- 检查分组首部和决定将分组导向何处
2. 排队延时:
- 在输出链路上等待传输的时间
- 依赖于路由器的拥塞程度
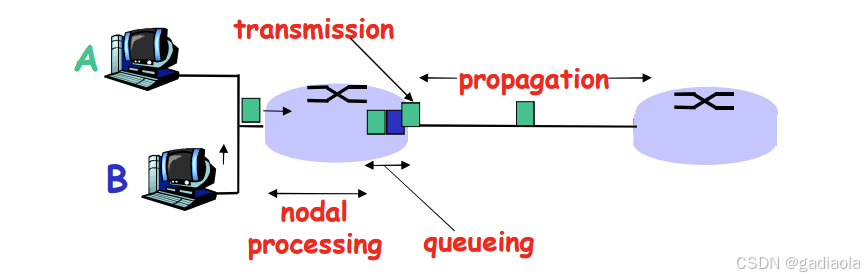
3. 传输延时:
- R = 链路带宽 (bps)
- L = 分组长度 (bits)
- 将分组发送到链路上的时间 = L/R
- 存储转发延时
4. 传播延时:
- d = 物理链路的长度
- s = 在媒体上的传播速度 (~2×10⁸ m/sec)
- 传播延时 = d/s
车队类比
- 汽车以 100 km/hr 的速度传播
- 收费站服务每辆车需 12s (传输时间)
- 汽车~bit; 车队~分组
- Q: 在车队在第二个收费站排列好之前需要多长时间?
- 即:从车队的第一辆车到达第一个收费站开始计时,到这个车队的最后一辆车离开第二个收费站,共需要多少时间
- 将车队从收费站输送到公路上的时间 = 12*10 = 120s
- 最后一辆车从第一个收费站到第二个收费站的传播时间:100km/(100km/hr)= 1 hr
- A: 62 minutes
- 汽车以 1000 km/hr 的速度传播汽车
- 收费站服务每辆车需 1 分钟
- Q: 在所有的汽车被第一个收费站服务之前,汽车会到达第二个收费站吗?
- Yes!7 分钟后,第一辆汽车到达了第二个收费站,而第一个收费站仍有 3 辆汽车
- 在整个分组被第一个路由器传输之前,第一个比特已经到达了第二个路由器!

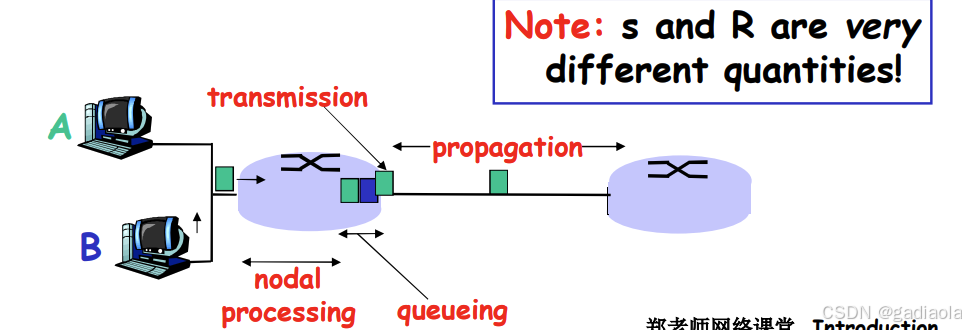
5. 节点延时
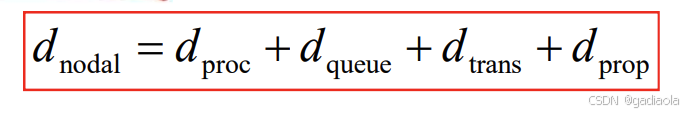
- d-proc = 处理延时
- 通常是微秒数量级或更少
- d-queue = 排队延时
- 取决于拥塞程度
- d-trans = 传输延时
- = L/R,对低速率的链路而言很大(如拨号),通常为微秒级到毫秒级
- d-prop = 传播延时
- 几微秒到几百毫秒
6. 排队延时
- R = 链路带宽 (bps)
- L = 分组长度 (bits)
- a = 分组到达队列的平均速率
流量强度 = La/R
- La/R ~ 0: 平均排队延时很小
- La/R -> 1: 延时变得很大
- La/R > 1: 比特到达队列的速率超过了从该队列输出的速率,平均排队延时将趋向无穷大!
设计系统时流量强度不能大于 1!
7. 分组丢失
- 链路的队列缓冲区容量有限
- 当分组到达一个满的队列时,该分组将会丢失
- 丢失的分组可能会被前一个节点或源端系统重传,或根本不重传
二、吞吐量
- 吞吐量:在源端和目标端之间传输的速率(数据量 / 单位时间)
- 瞬间吞吐量:在一个时间点的速率
- 平均吞吐量:在一个长时间内平均值
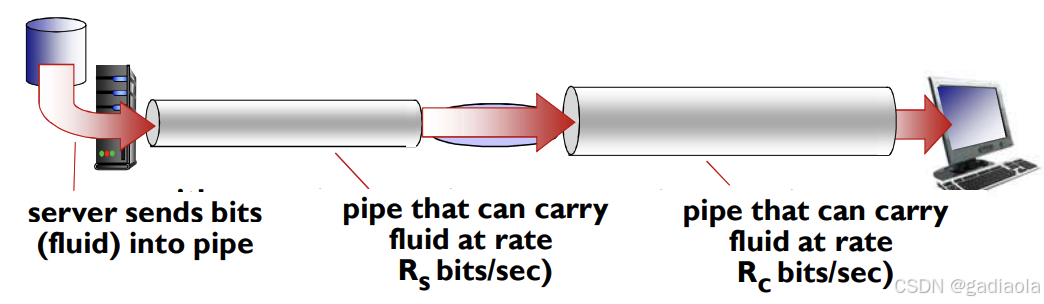
Rs < Rc 端到端平均吞吐是多少?---------------------Rs

Rs > Rc 端到端平均吞吐是多少?---------------------Rc

瓶颈链路:
端到端路径上,限制端到端吞吐的链路。
其他节点都不传输,吞吐量min{Rs,Rc}。
端到端平均吞吐=min{R1,R2 ,…,Rn }

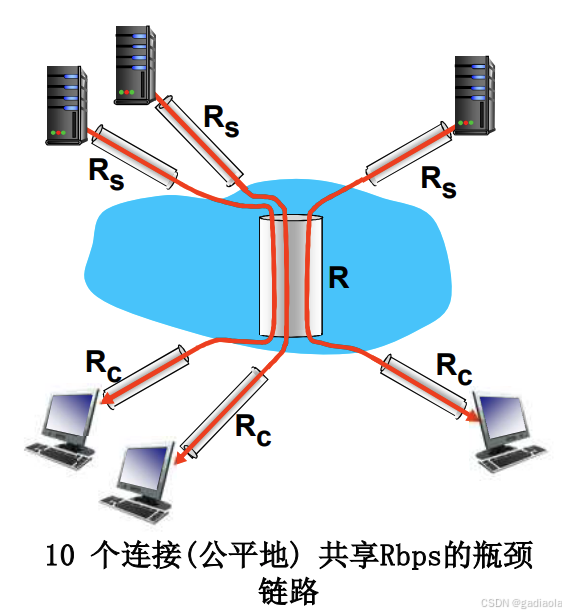
吞吐量:互联网场景
- 链路上的每一段实际可用带宽 Ri ’ = ?
- 端到端吞吐量:min{ Ri ’ }
- 每个连接上的端到端吞吐:min(Rc ,Rs ,R/10)
- 实际上:Rc 或者 Rs 经常是瓶颈
三、总结
(一)分组延时
指数据分组从源主机发送到目的主机所经历的总时间。由四部分构成:
1. 处理延时(Processing Delay)
- 定义:路由器/交换机检查分组头部、决定转发路径、检查比特错误等处理时间。
- 影响因素:硬件性能、路由算法复杂度、安全检查(如防火墙)。
- 典型值:微秒级(μs)。
2. 排队延时(Queuing Delay)
- 定义:分组在输出队列中等待链路空闲的时间。
- 关键公式:
- 平均排队延时 ≈
(流量强度) / (1 - 流量强度)
流量强度 = 分组到达速率 / 链路输出速率- 当流量强度 → 1 时,延时趋近无穷大。
- 影响因素:流量突发性、队列调度策略(FIFO、优先级队列)。
3. 传输延时(Transmission Delay)
- 定义:将分组所有比特推送到链路上的时间。
- 公式:
传输延时 = 分组长度 (L) / 链路带宽 (R)
- 例:1KB 分组,1Gbps 链路 → 延时 = 8μs。
4. 传播延时(Propagation Delay)
- 定义:比特在物理介质中传播的时间。
- 公式:
传播延时 = 距离 (d) / 传播速度 (s)
- 传播速度
s:光纤中 ≈ 2×10⁸ m/s(真空中光速的2/3)。📌 总延时:
总延时 = 处理延时 + 排队延时 + 传输延时 + 传播延时
(二)分组丢失
分组在传输过程中未能到达目的地的现象。
1. 主要原因
- 路由器队列溢出:当流量强度 > 1 时,队列满导致后续分组被丢弃。
- 链路错误:物理介质干扰(如无线网络)、比特错误(CRC校验失败)。
- 路由问题:路由表错误导致分组进入“黑洞”。
2. 影响与应对
- TCP 的应对机制:
- 超时重传(RTO)
- 快速重传(收到3个重复ACK)
- 拥塞控制(如 Tahoe、Reno 算法)
- UDP 无恢复机制:需应用层处理(如实时音视频的冗余编码)。
3. 丢包率(Loss Rate)
- 公式:
丢包率 = 丢失分组数 / 发送分组总数- 典型要求:语音通话 <1%,视频流 <5%。
(三)吞吐量(Throughput)
单位时间内通过网络的有效数据量。
1. 两种定义
- 瞬时吞吐量:某一时刻的速率(bps)。
- 平均吞吐量:一段时间内的平均速率(bps)。
2. 瓶颈带宽(Bottleneck Bandwidth)
- 定义:端到端路径中带宽最小的链路速率。
- 公式(N条链路串联):
端到端吞吐量 = min{R1, R2, ..., RN}- 示例:
- 服务器 → 路由器1:100Mbps
- 路由器1 → 路由器2:10Mbps
- 路由器2 → 客户端:1Gbps
- 实际吞吐量 = 10Mbps
3. 实际吞吐量影响因素
- 网络拥塞程度
- 协议开销(TCP头部、ACK确认)
- 接收端窗口大小(TCP流量控制)
4. 吞吐量计算示例
- 文件大小
F,传输时间T→ 吞吐量 =F / T- 若多用户共享链路:公平共享时每个用户获得
R/N(R为总带宽,N为用户数)。
(四)关键知识关联
概念 核心影响因素 典型优化方法 延时 传播距离、链路带宽、队列长度 CDN、协议优化(QUIC)、优先级调度 丢失 队列溢出、信道错误 增大缓冲区、前向纠错(FEC) 吞吐量 瓶颈带宽、并发连接数 多路径传输(MPTCP)、负载均衡 延时 vs 吞吐量权衡:
- 低延时:需小队列(但易丢包)
- 高吞吐量:需大窗口(但增加排队延时)
- TCP拥塞控制(如BBR算法)旨在平衡二者。
完结撒花🎉
相关文章:
【计算机网络】第1章:概述—分组延时、丢失和吞吐量
目录 一、分组延时、丢失 1. 节点处理延时: 2. 排队延时: 3. 传输延时: 4. 传播延时: 5. 节点延时 6. 排队延时 7. 分组丢失 二、吞吐量 三、总结 (一)分组延时 1. 处理延时(Processing Delay) …...

Python Day38
Task: 1.Dataset类的__getitem__和__len__方法(本质是python的特殊方法) 2.Dataloader类 3.minist手写数据集的了解 1. Dataset 类的 __getitem__ 和 __len__ 方法 在 PyTorch (或类似深度学习框架) 中,Dataset 是一个抽象基类&a…...

DeepSeek R1 模型小版本升级,DeepSeek-R1-0528都更新了哪些新特性?
DeepSeek-R1‑0528 技术剖析:思维链再进化,推理性能飙升 目录 版本概览深度思考能力再升级基准测试成绩功能与体验更新API 变动与示例模型开源与下载结语 版本概览 DeepSeek 团队今日发布 DeepSeek‑R1‑0528 —— 基于 DeepSeek V3 Base(2…...

线路板厂家遇到的PCB元件放置的常见问题有哪些?
印刷电路板现在无处不在。尽管大多数人认为这是理所当然的,但工程师和设计师们充分意识到这些电路开发和生产背后的巨大努力。传统的PCB生产涉及复杂的机械和高昂的前期成本,因此必须将制造外包给专业工厂。 说到交货时间,你可能需要几周的时…...

【C/C++】无限长有序数组中查找特定元素
在无限长有序数组中查找特定元素,由于数组长度未知,需先定位搜索范围,再进行二分查找。以下是C实现: #include <iostream> #include <vector> #include <climits> using namespace std;// 假设数组访问函数&am…...

SQL正则表达式总结
这里写目录标题 一、元字符二、正则表达函数1、 regexp_like(x,pattern[,match_option])2、 regexp_instr(x,pattern[,start[,occurrence[,return_option[, match_option]]]]) 3、 REGEXP_SUBSTR(x,pattern[,start[,occurrence[, match_option]]]) 4、 REGEXP_REPLACE(x,patter…...
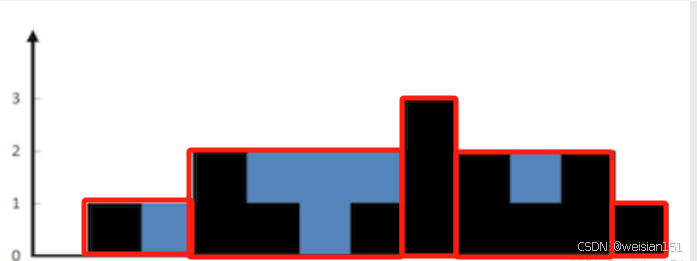
力扣经典算法篇-13-接雨水(较难,动态规划,加法转减法优化,双指针法)
1、题干 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3…...
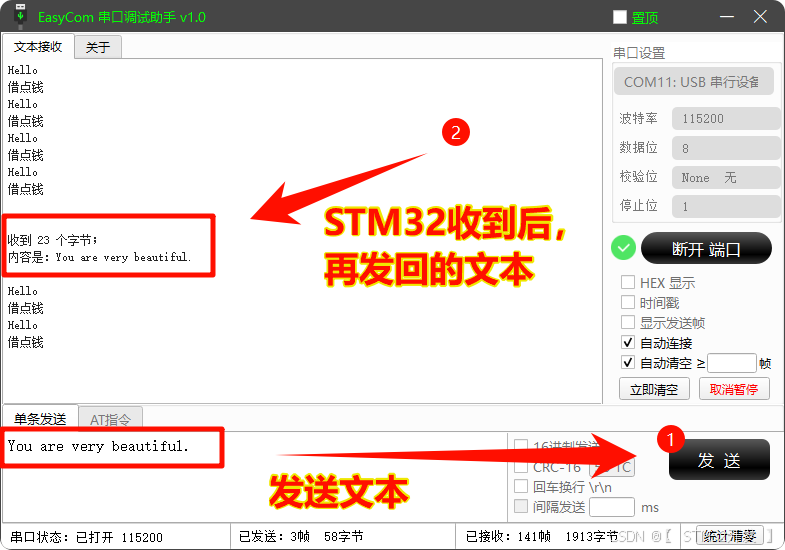
STM32 -- USB虚拟串口通信
本篇操作: 通过CubeMX Keil,配置STM32作为USB设备端,与电脑上位机进行通信(CDC);通用带USB功能的 STM32 芯片 (如F1、F4等,系统时钟配置不同,代码通用)。 目录 一、 S…...
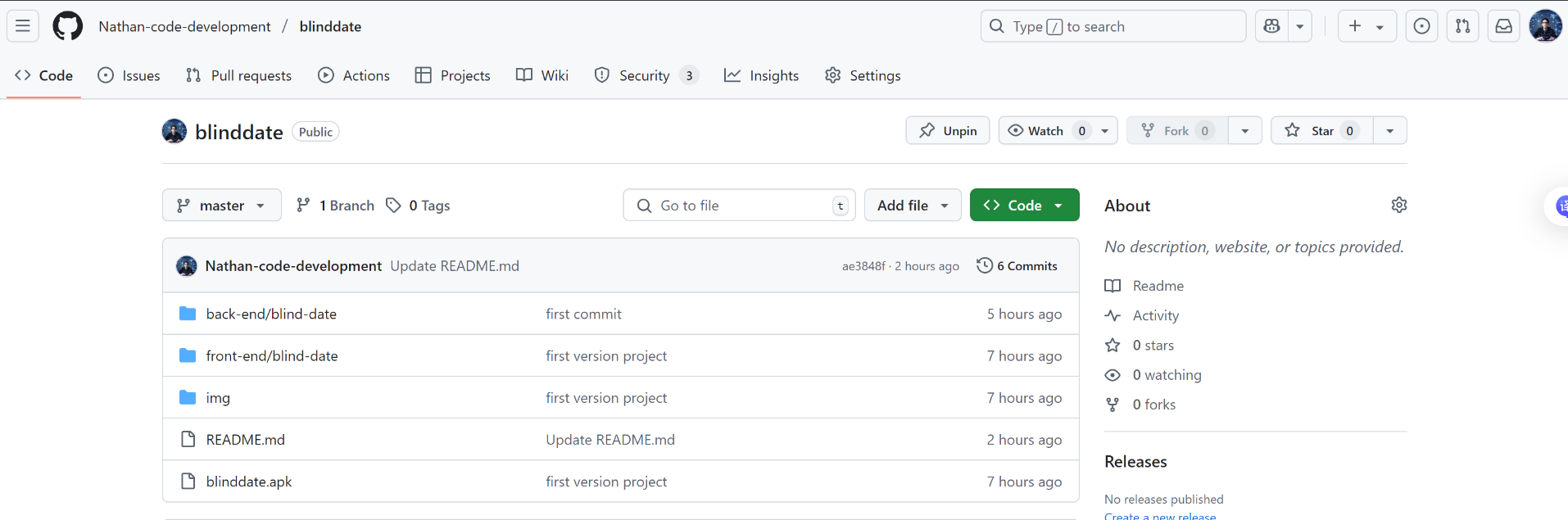
uni-app开发特殊社交APP
uni-app开发特殊社交APP 目录 1.展示APP功能 2.展示项目结构 3.关于我的GitHub 引言 博主最近自己在GitHub上面上传了一个关于社交软件的项目(该项目早已开发完毕), 这个社交软件比较特殊, 被称之为blind-date, blind-date 是基于 uni-…...

Linux中Shell脚本的常用命令
一、设置主机名称 1、通过修改系统文件来修改主机名称 [rootsakura1 桌面]# vim /etc/hostname sakura /etc/hostname:Linux 系统中存储主机名的配置文件。修改完文件后,在当前的shell中是不生效的,需要关闭当前shell后重新开启才能看到效…...

RabbitMQ项目实战
先参考文章:(必看) 06-MQ基础_mq服务-CSDN博客 07-MQ高级(幂等性)-CSDN博客 https://cloud.iocoder.cn/message-queue/rabbitmq/#_2-0-%E5%BC%95%E5%85%A5%E4%BE%9D%E8%B5%96%E4%B8%8E%E9%85%8D%E7%BD%AE 1、Rabbi…...

安卓开发用到的设计模式(3)行为型模式
安卓开发用到的设计模式(3)行为型模式 文章目录 安卓开发用到的设计模式(3)行为型模式1. 命令模式(Command Pattern)2. 策略模式(Strategy Pattern)3. 观察者模式(Observ…...

生成模型:从数据学习到创造的 AI 新范式
一、生成模型:定义与核心逻辑 生成模型是一类通过学习数据潜在分布来创造新样本的机器学习模型。其核心目标是构建数据的概率分布模型 P(X),使生成的样本 X^ 与真实数据 X 具有相似的统计特征。 1.1 与判别模型的本质区别 维度生成模型判别模型核心目…...

尚硅谷redis7 90-92 redis集群分片之集群扩容
90 redis集群分片之集群扩容 三主三从不够用了,进行扩容变为4主4从 问题:1.新建两个redis实例,怎么加入原有集群?2.原有的槽位分3段,又加进来一个槽位怎么算? 新建6387、6388两个服务实例配置文件新建后启…...

RabbitMQ性能调优:关键技术、技巧与最佳实践
RabbitMQ作为一款高可靠、高扩展性的消息中间件,其性能表现直接影响到分布式系统的吞吐量和响应延迟。本文基于RabbitMQ官方文档和最佳实践,结合核心性能优化方向,详细探讨RabbitMQ性能调优的关键技术、技巧和策略。 通过以下优化策略&#…...

系统架构中的组织驱动:康威定律在系统设计中的应用
康威定律(Conway’s Law) 是由计算机科学家 Melvin Conway 在1967年提出的理论,其核心观点是:“系统的架构设计会不可避免地反映其开发组织的沟通结构。换句话说,软件系统的结构会与构建它的团队的组织结构高度相似。 …...

TypeScript 中高级类型 keyof 与 typeof的场景剖析。
文章目录 前言一、typeof:从值到类型的映射1. 核心概念2. 类型推导示例3. 常见用途 二、keyof:从类型到键的映射1. 核心概念2. 常见用途 三、typeof keyof:强强联合的实战场景1. 场景一:对象属性的安全访问2. 场景二:…...

Android LiveData 详解
一、LiveData 核心概念与特性 1.1 定义与基本功能 LiveData 是 Android Jetpack 架构组件中的一个可观察数据持有者类,其核心功能是实现数据与 UI 的响应式绑定。与传统观察者模式不同,LiveData 具有生命周期感知能力,能够自动根据观察者…...

为什么共现矩阵是高维稀疏的
为什么共现矩阵是高维稀疏的? 共现矩阵(Co-occurrence Matrix)的高维稀疏性是其固有特性,主要由以下原因导致: 1. 高维性的根本原因 词汇表大小决定维度: 共现矩阵的维度为 ( V \times V ),其…...

离散化算法的二分法应用
我们思考一个问题:其实这里的二分法回归本源也是基于下标映射的原理,只是实现是借助二分的形式。 在排序好的数组中对目标数值进行二分搜索,在 O(logn) 的时间复杂度内找到该数值是整体数据中的第几个。 具体的我们可以如下操作: …...

IntelliJ IDEA 中进行背景设置
🎨 一、全局主题切换 操作路径 File → Settings → Appearance & Behavior → Appearance → Theme可选主题: Darcula:深色模式(默认暗黑主题)IntelliJ Lightÿ…...

Dart语言学习指南「专栏简介」
Dart 是 Google 开发的一款开源通用编程语言,它不仅支持客户端和服务器端的应用开发,还因其与 Flutter 框架的深度集成,在移动端和 Web 开发中广受欢迎。Dart 适用于 Android 应用、iOS 应用、物联网(IoT)项目以及 Web…...

AWS之AI服务
目录 一、AWS AI布局 1. 底层基础设施与芯片 2. AI训练框架与平台 3. 大模型与应用层 4. 超级计算与网络 与竞品对比 AI服务 1. 机器学习平台 2. 预训练AI服务 3. 边缘与物联网AI 4. 数据与AI…...

Docker 部署项目
使用 Docker 部署项目是一个很好的选择,可以避免服务器环境不兼容的问题,并且能够实现一致性和可移植性。我会给你一个详细的步骤,帮你从零开始理解 Docker,最终在服务器上部署 Roop 项目。 1. 安装 Docker 首先,你需…...
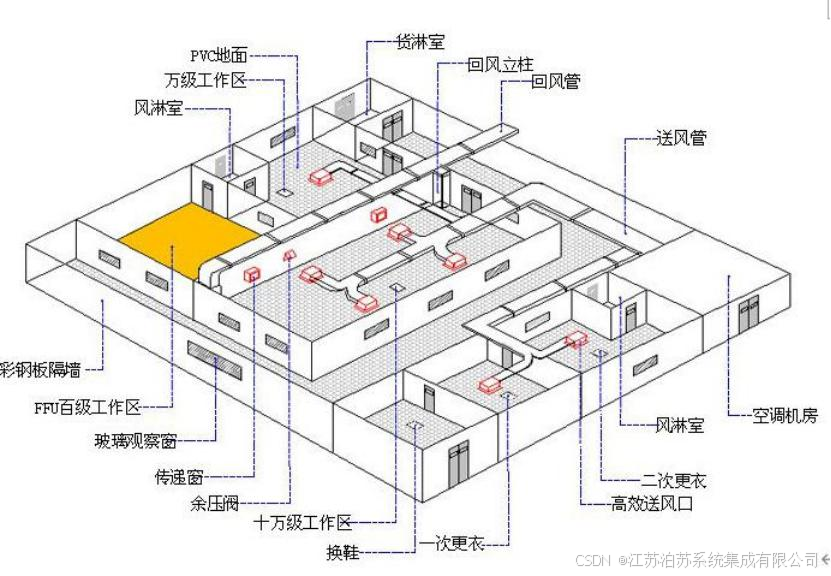
半导体厂房设计建造流程、方案和技术要点-江苏泊苏系统集成有限公司
半导体厂房设计建造流程、方案和技术要点-江苏泊苏系统集成有限公司 半导体厂房的设计建造是一项高度复杂、专业性极强的系统工程,涉及洁净室、微振动控制、电磁屏蔽、特殊气体/化学品管理等关键技术。 一、设计建造流程: 1.需求定义与可行性分析 &a…...
string的模拟实现)
(c++)string的模拟实现
目录 1.构造函数 2.析构函数 3.扩容 1.reserve(扩容不初始化) 2.resize(扩容加初始化) 4.push_back 5.append 6. 运算符重载 1.一个字符 2.一个字符串 7 []运算符重载 8.find 1.找一个字符 2.找一个字符串 9.insert 1.插入一个字符 2.插入一个字符串 9.erase 10…...
一种通用图片红色印章去除的工具设计
朋友今天下午需要处理个事情,问我有没有什么好的办法能够去除,核心问题是要去除图片上的印章。记得以前处理过类似的需求,photoshop操作比较简单,本质是做运算。这种处理方式有很多,比如现在流行的大模型,一…...

企业应用AI对向量数据库选型思考
一、向量数据库概述 向量数据库是一种专门用于存储和检索高维向量数据的数据库系统,它能够高效地处理基于向量相似性的查询,如最近邻搜索等,在人工智能、机器学习等领域的应用中发挥着重要作用,为处理复杂的向量数据提供了有力的…...

时序数据库IoTDB安装学习经验分享
1. JDK安装问题 在安装IoTDB时,我遇到了“无法加载主类”的错误,这通常表明Java环境存在问题。尽管我能正确输出classpath和查询JDK版本,但问题依旧存在。经过查阅相关资料,我发现问题出在多余的classpath设置上。Java编译器和虚…...

RapidOCR集成PP-OCRv5_det mobile模型记录
该文章主要摘取记录RapidOCR集成PP-OCRv5_mobile_det记录,涉及模型转换,模型精度测试等步骤。原文请前往官方博客: https://rapidai.github.io/RapidOCRDocs/main/blog/2025/05/26/rapidocr%E9%9B%86%E6%88%90pp-ocrv5_det%E6%A8%A1%E5%9E%8B…...