华为OD机试_2025 B卷_静态扫描(Python,100分)(附详细解题思路)
题目描述
静态扫描可以快速识别源代码的缺陷,静态扫描的结果以扫描报告作为输出:
1、文件扫描的成本和文件大小相关,如果文件大小为N,则扫描成本为N个金币
2、扫描报告的缓存成本和文件大小无关,每缓存一个报告需要M个金币
3、扫描报告缓存后,后继再碰到该文件则不需要扫描成本,直接获取缓存结果
给出源代码文件标识序列和文件大小序列,求解采用合理的缓存策略,最少需要的金币数。
输入描述
第一行为缓存一个报告金币数M,L<= M <= 100
第二行为文件标识序列:F1,F2,F3,…,Fn。
第三行为文件大小序列:S1,S2,S3,…,Sn。
备注:
1 <= N <= 10000
1 <= Fi <= 1000
1 <= Si <= 10
输出描述
采用合理的缓存策略,需要的最少金币数
用例
| 输入 | 5 1 2 2 1 2 3 4 1 1 1 1 1 1 1 |
| 输出 | 7 |
| 说明 | 文件大小相同,扫描成本均为1个金币。缓存任意文件均不合算,因而最少成本为7金币。 |
| 输入 | 5 2 2 2 2 2 5 2 2 2 3 3 3 3 3 1 3 3 3 |
| 输出 | 9 |
| 说明 | 无 |
静态扫描成本优化:缓存策略的贪心解法
核心解题思路
题目要求通过合理的缓存策略最小化静态扫描的总成本,核心问题是:对于重复出现的文件,何时缓存报告最划算? 关键在于权衡扫描成本与缓存成本:
- 扫描成本:每次扫描文件需支付其大小的金币(文件越大成本越高)
- 缓存成本:缓存报告需固定支付M金币(后续相同文件可免扫描)
- 决策关键:对每个文件标识,判断"缓存并复用"还是"每次重新扫描"更经济
贪心策略
对每个文件标识独立决策:
- 若不缓存:总成本 = 文件大小 × 出现次数
- 若缓存:总成本 = 第一次扫描成本 + 缓存成本
- 选择成本更低的方案:
min(文件大小×频次, 文件大小 + M)
为什么贪心有效?每个文件的缓存决策相互独立,缓存一个文件不会影响其他文件的扫描成本。
解题步骤详解
1. 输入处理与参数设置
# 读取缓存成本M
M = int(input().strip())# 读取文件标识序列
file_ids = list(map(int, input().split()))# 读取文件大小序列
file_sizes = list(map(int, input().split()))
2. 构建文件分组统计
from collections import defaultdict# 创建分组字典:记录每个标识的[频次, 总大小, 首次大小]
file_groups = defaultdict(lambda: [0, 0, None])# 遍历所有文件
for fid, size in zip(file_ids, file_sizes):# 更新出现频次file_groups[fid][0] += 1# 累加总大小(用于不缓存方案)file_groups[fid][1] += size# 记录首次出现的大小(用于缓存方案)if file_groups[fid][2] is None:file_groups[fid][2] = size
3. 计算最小成本
total_cost = 0
for fid, (count, total_size, first_size) in file_groups.items():# 不缓存方案:每次扫描cost_no_cache = total_size# 缓存方案:首次扫描+缓存cost_cache = first_size + M# 选择更经济的方案total_cost += min(cost_no_cache, cost_cache)
4. 输出结果
print(total_cost)
关键逻辑解析
1. 分组统计的重要性
- 频次(count):决定重复扫描的成本
- 总大小(total_size):计算不缓存方案的总成本
- 首次大小(first_size):缓存方案只需首次扫描成本
为何记录首次大小而非任意大小?
缓存发生在首次扫描时,后续文件无论大小如何都复用结果
2. 成本比较的数学原理
决策依据的数学表达式:
min( Σsᵢ , s₁ + M )
其中:
Σsᵢ:所有出现位置的大小之和s₁:首次出现的大小M:固定缓存成本
3. 独立决策的正确性
- 文件标识相互独立,缓存决策无耦合
- 缓存文件A不影响文件B的扫描
- 局部最优解之和等于全局最优解
完整代码实现
from collections import defaultdictdef main():# 读取缓存成本M = int(input().strip())# 读取文件标识序列file_ids = list(map(int, input().split()))# 读取文件大小序列file_sizes = list(map(int, input().split()))# 创建分组统计字典# 格式: {文件标识: [出现次数, 总大小, 首次大小]}file_groups = defaultdict(lambda: [0, 0, None])# 遍历所有文件for fid, size in zip(file_ids, file_sizes):# 更新出现次数file_groups[fid][0] += 1# 累加总大小file_groups[fid][1] += size# 记录首次大小if file_groups[fid][2] is None:file_groups[fid][2] = size# 计算最小总成本total_cost = 0for fid, (count, total_size, first_size) in file_groups.items():# 计算两种方案成本cost_no_cache = total_sizecost_cache = first_size + M# 选择更经济的方案total_cost += min(cost_no_cache, cost_cache)print(total_cost)if __name__ == "__main__":main()
复杂度分析
- 时间复杂度:O(N)
- 遍历文件序列:O(N)
- 分组统计:O(N)
- 决策计算:O(K)(K为唯一文件数,K ≤ N)
- 空间复杂度:O(K)
- 存储分组信息:O(K)(K为唯一文件标识数)
示例验证
示例1:
输入:
5
1 2 2 1 2 3 4
1 1 1 1 1 1 1
处理流程:
- 分组统计:
- 文件1: [频次=2, 总大小=2, 首次大小=1]
- 文件2: [频次=3, 总大小=3, 首次大小=1]
- 文件3: [频次=1, 总大小=1, 首次大小=1]
- 文件4: [频次=1, 总大小=1, 首次大小=1]
- 成本决策:
- 文件1: min(2, 1+5)=2
- 文件2: min(3, 1+5)=3
- 文件3: min(1, 1+5)=1
- 文件4: min(1, 1+5)=1
- 总成本:2+3+1+1=7
输出:7
示例2:
输入:
5
2 2 2 2 2 5 2 2 2
3 3 3 3 3 1 3 3 3
处理流程:
- 分组统计:
- 文件2: [频次=8, 总大小=24, 首次大小=3]
- 文件5: [频次=1, 总大小=1, 首次大小=1]
- 成本决策:
- 文件2: min(24, 3+5)=8
- 文件5: min(1, 1+5)=1
- 总成本:8+1=9
输出:9
总结
通过贪心策略解决静态扫描成本优化问题:
- 问题特性:重复文件可复用缓存,决策相互独立
- 核心洞察:缓存的价值 = 后续扫描成本节省 - 缓存成本
- 算法选择:分组统计 + 成本比较(O(N)时间复杂度)
- 优化关键:
- 小文件高频:倾向不缓存(如示例1)
- 大文件高频:倾向缓存(如示例2)
- 低频文件:通常不缓存
实际应用场景:编译器构建系统(如Makefile)、CI/CD流水线,通过缓存中间结果加速重复构建过程。
相关文章:
(附详细解题思路))
华为OD机试_2025 B卷_静态扫描(Python,100分)(附详细解题思路)
题目描述 静态扫描可以快速识别源代码的缺陷,静态扫描的结果以扫描报告作为输出: 1、文件扫描的成本和文件大小相关,如果文件大小为N,则扫描成本为N个金币 2、扫描报告的缓存成本和文件大小无关,每缓存一个报告需要…...
python打卡训练营打卡记录day41
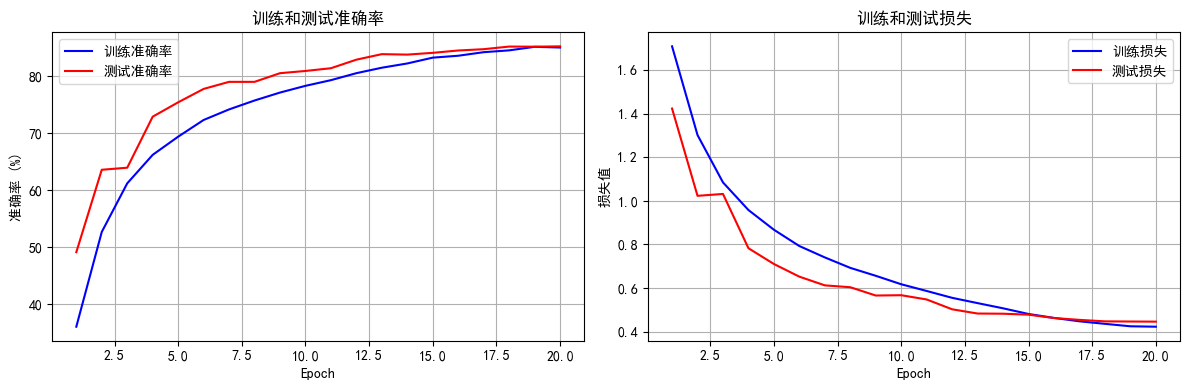
知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 → Batch归一化层…...
GD32F103系列工程模版创建记录
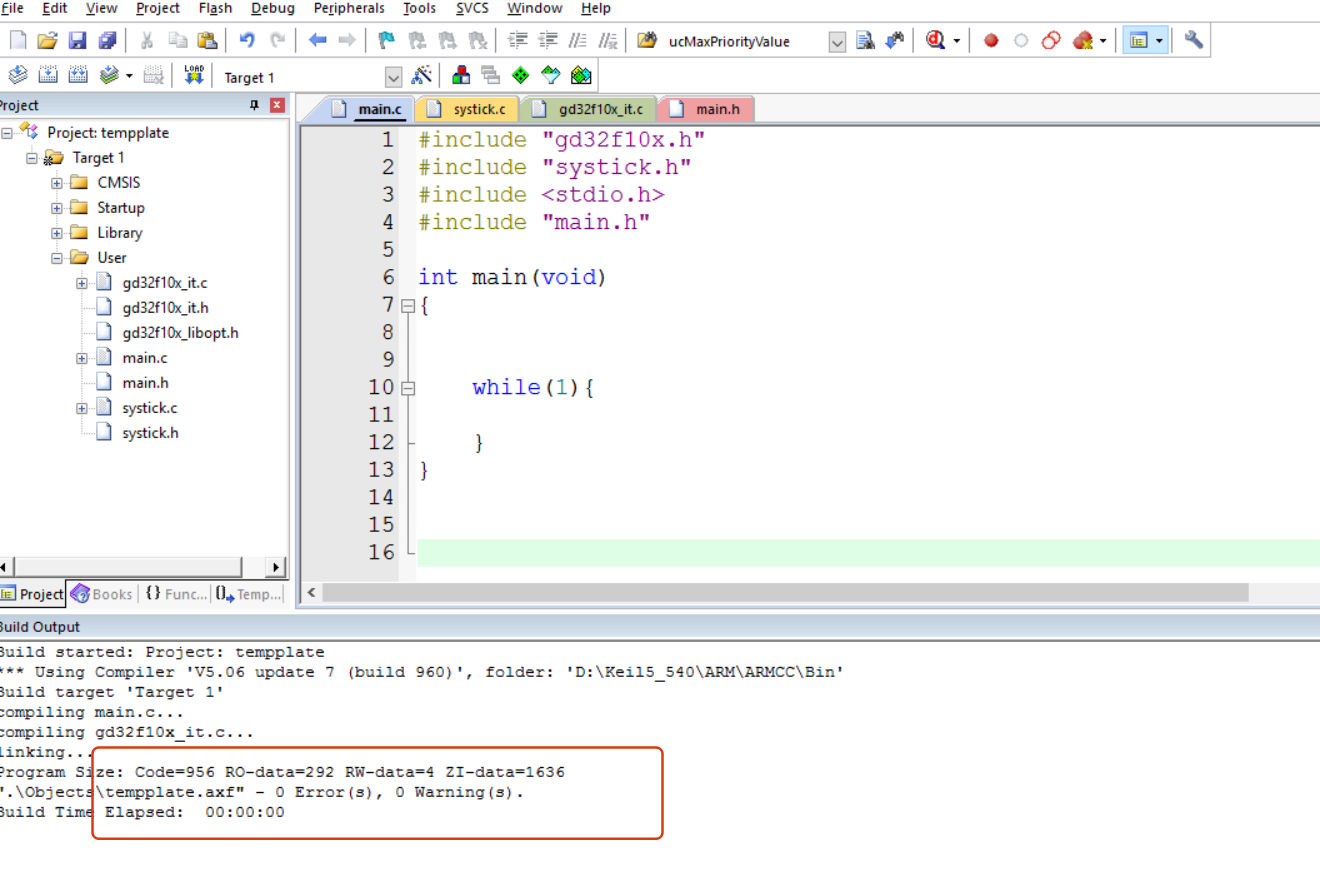
准备条件: 1:首先需要下载GD32F103的官方库 2:GD32F103的软件包 3:KEIL5软件 4:单片机GD32F103C8T6 本文已经默认KEIL5已将安装好GD32F103的软件包了 步骤一 基本模版创建 1 打开KEIL5软件,新建工程&am…...
PH热榜 | 2025-05-24
1. Chance AI: Visual Reasoning 标语:通过视觉推理模型即时进行可视化搜索 介绍:Chance AI 是你的视觉小助手——只需拍一张照片,就能揭示你所看到事物背后的故事。通过我们全新的视觉推理功能,它不仅能识别物体,还…...
 的 详细章节目录)
《高等数学》(同济大学·第7版) 的 详细章节目录
上册 第一章 函数与极限 映射与函数 数列的极限 函数的极限 无穷小与无穷大 极限运算法则 极限存在准则 两个重要极限 无穷小的比较 函数的连续性与间断点 连续函数的运算与初等函数的连续性 闭区间上连续函数的性质 🔹 重点节: 2-3ÿ…...
能源领域新兴技术论坛:EMQ 实时数据引擎构建工业智能中枢
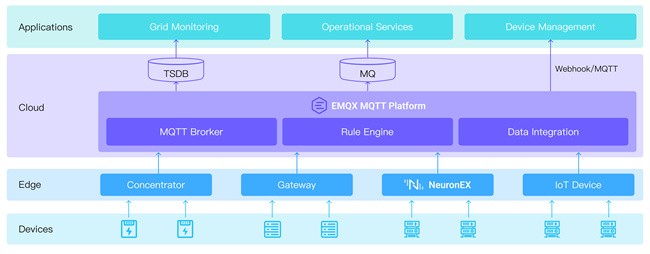
5 月 26 日,由沙特阿美亚洲公司主办的能源领域新兴技术论坛在上海顺利举行。本次论坛聚焦智能工厂、无人机与机器人、可靠性与完整性、先进材料四大技术赛道,吸引了来自全球的能源企业、技术供应商及行业专家。 作为业内知名的 MQ AI 实时数据与智能产…...

kafka 常用知识点
文章目录 前言kafka 常用知识点1. kafka 概念2. 消息共享和广播3. 分区和副本数量奇偶数 前言 如果您觉得有用的话,记得给博主点个赞,评论,收藏一键三连啊,写作不易啊^ _ ^。 而且听说点赞的人每天的运气都不会太差࿰…...
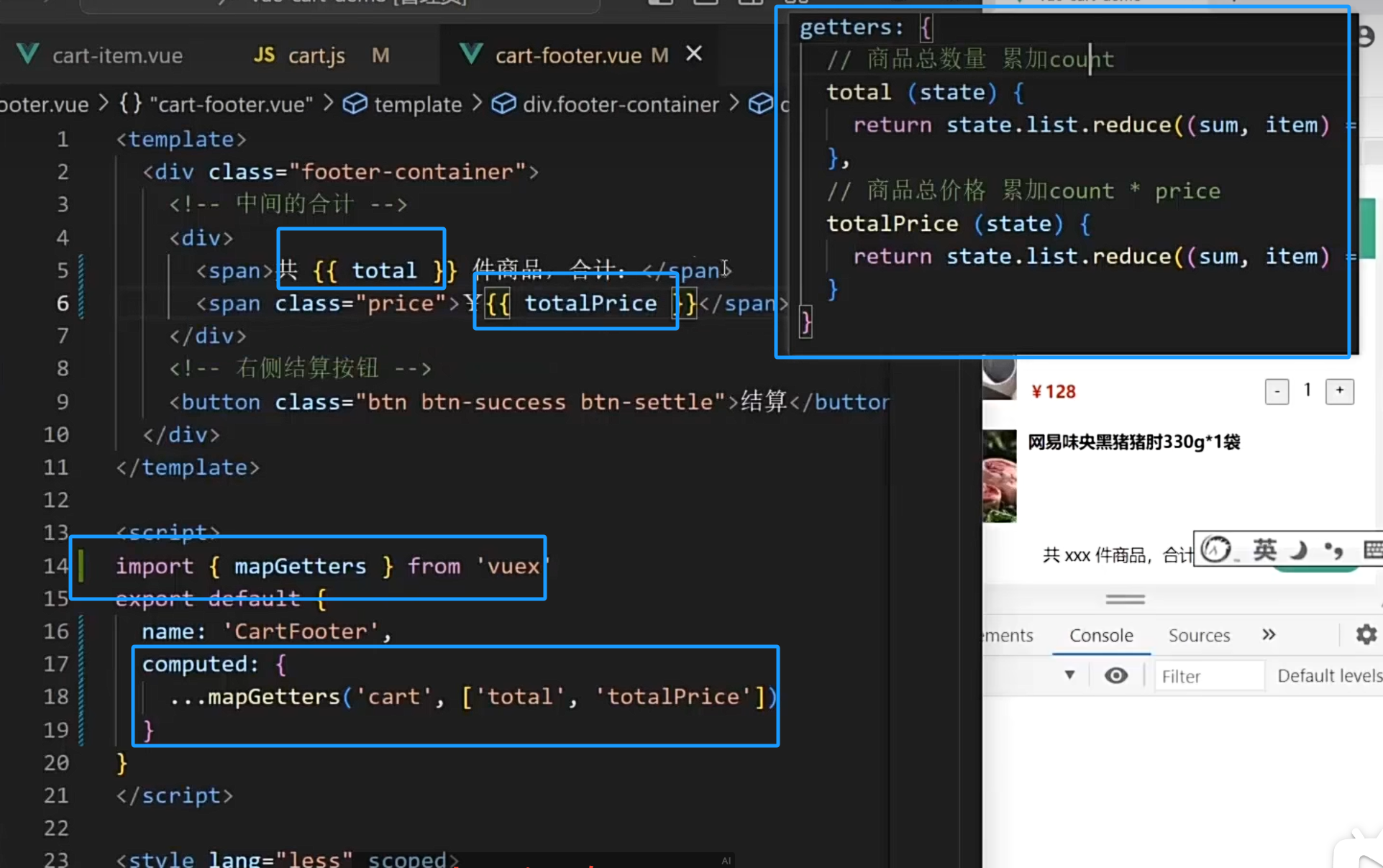
Vue 核心技术与实战day07
1. vuex概述 2. 构建 vuex [多组件数据共享] 环境 <template><div id"app"><h1>根组件- {{ title }}- {{ count }}</h1><input :value"count" input"handleInput" type"text"><Son1></Son1>…...
的过程)
关于5090安装tensorrt(python api)的过程
前提条件 硬件5090 ubuntu24.04 cuda版本12.8 找到适配的tensorrt版本 Nvidia官网 完事了之后找到对应版本tar安装包 tar -xvzf tensorrt-你的安装包.tar 然后记得将路径加入到环境变量中 #在这里插入代码片 gedit ~/.bashrc # 添加 export PATH/PATH/To/TensorRT-你的按安…...

[蓝桥杯]分考场
题目描述 nn 个人参加某项特殊考试。 为了公平,要求任何两个认识的人不能分在同一个考场。 求是少需要分几个考场才能满足条件。 输入描述 输入格式: 第一行,一个整数 nn (1≤n≤1001≤n≤100),表示参加考试的人数。 第二行…...

CSS专题之层叠上下文
前言 石匠敲击石头的第 15 次 在平常开发的时候,有时候会遇到使用 z-index 调整元素层级没有效果的情况,究其原因还是因为对层叠上下文不太了解,看了网上很多前辈的文章,决定打算写一篇文章来梳理一下,如果哪里写的有问…...
Nginx基础篇(Nginx目录结构分析、Nginx的启用方式和停止方式、Nginx配置文件nginx.conf文件的结构、Nginx基础配置实战)
文章目录 1. Nginx目录结构分析1.1 conf目录1.2 html目录1.3 logs目录1.4 sbin目录 2. Nginx的启用方式和停止方式2.1 信号控制2.1.1 信号2.1.2 调用命令 2.2 命令行控制2.2.1 基础操作类2.2.2 配置测试类2.2.3 进程控制类2.2.4 路径与文件类2.2.5 高级配置类 3. Nginx配置文件…...
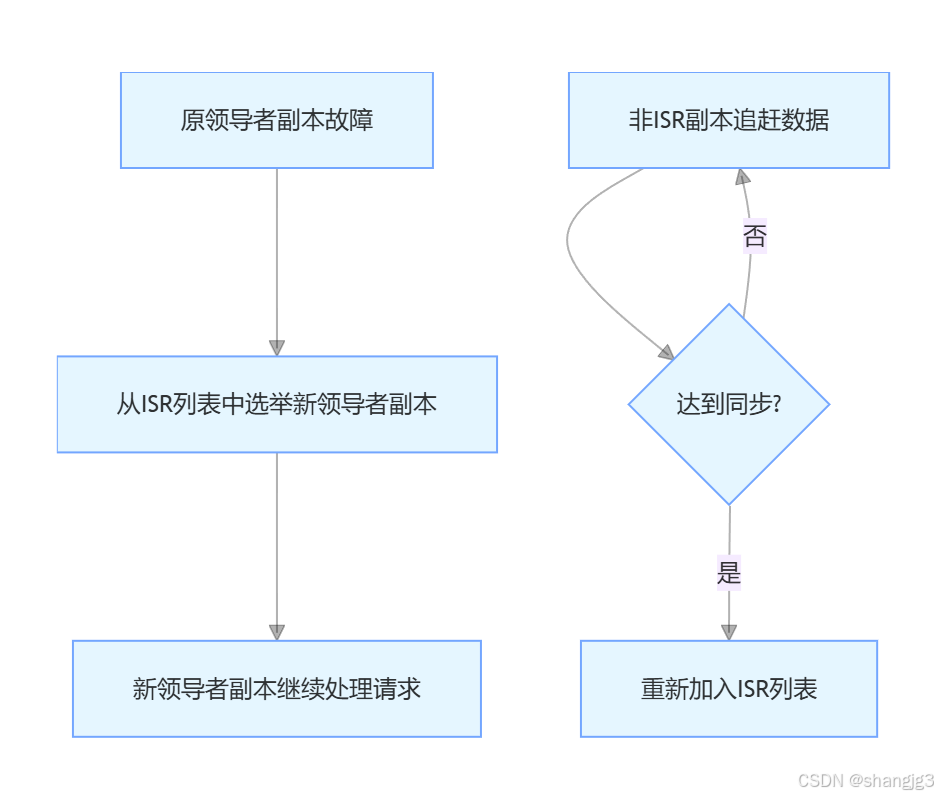
Kafka 的 ISR 机制深度解析:保障数据可靠性的核心防线
在 Kafka 的消息处理体系中,数据的可靠性和高可用性是至关重要的目标。而 ISR(In-Sync Replicas,同步副本)机制作为 Kafka 实现这一目标的关键技术,在消息复制、故障容错等方面发挥着核心作用。接下来,我们…...
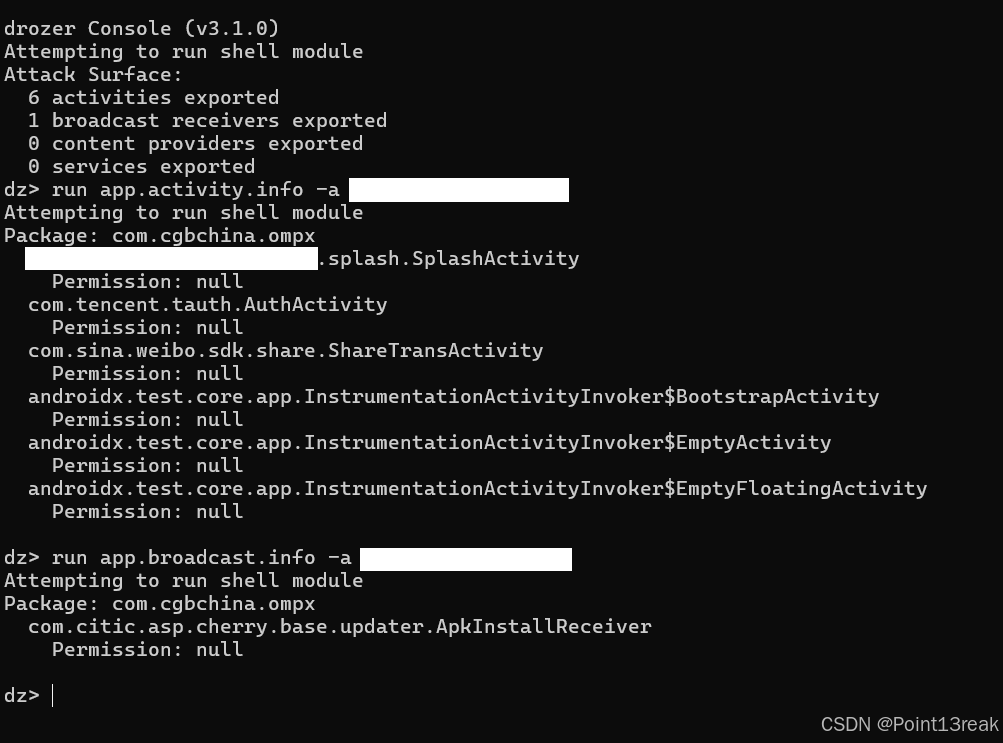
移动安全Android——客户端静态安全
一、反编译保护 测试工具 Jadx GitHub - skylot/jadx: Dex to Java decompiler PKID [下载]PKID-APP查壳工具-Android安全-看雪-安全社区|安全招聘|kanxue.com 测试流程 (1)通过Jadx对客户端APK文件进行反编译,观察是否进行代码混淆 &…...

LeetCode 1524. 和为奇数的子数组数目
好的!让我们详细解释 LeetCode 1524. 和为奇数的子数组数目 这道题的思路和解法。 题目: https://leetcode.cn/problems/number-of-sub-arrays-with-odd-sum/description/ 题目分析 问题描述: 给定一个整数数组 arr,返回其中和…...

Redis最佳实践——安全与稳定性保障之连接池管理详解
Redis 在电商应用的连接池管理全面详解 一、连接池核心原理与架构 1. 连接池工作模型 #mermaid-svg-G7I3ukCljlJZAXaA {font-family:"trebuchet ms",verdana,arial,sans-serif;font-size:16px;fill:#333;}#mermaid-svg-G7I3ukCljlJZAXaA .error-icon{fill:#552222;}…...
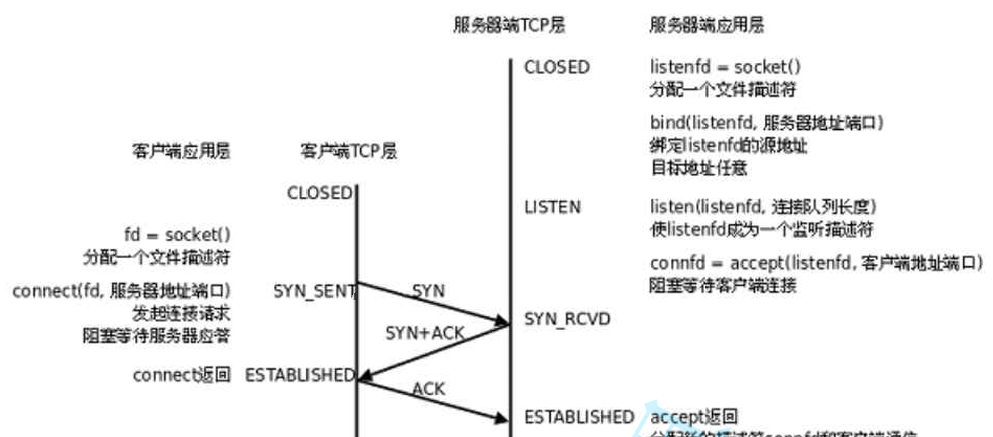
核心机制三:连接管理(三次握手)
核心机制一:确认应答 > 实现可靠传输的核心 接受方给发送方返回"应答报文"(ack) 1)发送方能够感知到对方是否收到 2)如果对方没有收到,发送方采取措施 序号按照字节编排 (连续递增) 确认序号按照收到数据的最后一个字节序号 1 核心机制二:超时重传 > 产生丢包…...

HarmonyOS DevEco Testing入门教程
一、DevEco Testing体系架构 分层测试框架 单元测试层:支持JS/TS/ArkTS语言的JUnit风格测试 UI测试层:基于XCTest框架扩展的视觉化测试工具 云测平台:集成华为云真机调试实验室 核心测试能力 分布式测试引擎:支持跨设备协同测…...
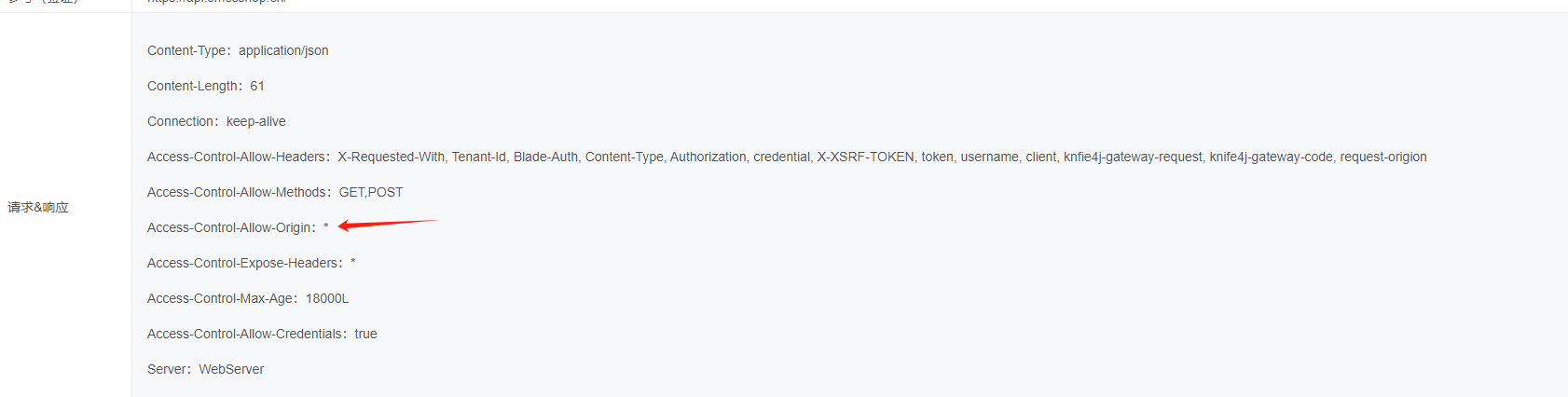
记录一次apisix上cros配置跨域失败的问题
安全要求不允许跨域请求,但是业务侧由于涉及多个域名,并且需要共享cookie,所以需要配置跨域。 在apisix上配置了cors如下。 结果安全漏扫还是识别到了跨域请求的漏洞。 调试了cors.lua的插件脚本,发现apisix上是如果不在allowOri…...

Spring Data Redis 实战指南
Spring Data Redis 核心特性 Spring Data Redis 是基于 Redis 的 NoSQL 内存数据结构存储解决方案,为 Spring 应用程序提供与 Redis 交互的高级抽象层。其核心架构设计体现了对现代应用需求的深度适配,主要技术特性可归纳为以下维度: 数据结构支持体系 作为多模型数据存储…...

服务器数据恢复—EMC存储raid5阵列故障导致上层应用崩了的数据恢复案例
服务器存储数据恢复环境: EMC某型号存储中有一组由8块硬盘组建的raid5磁盘阵列。 服务器存储故障: raid5阵列中有2块硬盘离线,存储不可用,上层应用崩了。 服务器存储数据恢复过程: 1、将存储中的所有硬盘编号后取出&a…...

如何保护网络免受零日漏洞攻击?
零日漏洞(Zero-Day Vulnerability)是指软件或系统中尚未被厂商发现或修补的安全漏洞。这个名称中的“零日”意味着,从漏洞被发现到厂商发布修复补丁的时间是零天,也就是说,黑客可以利用这个漏洞进行攻击,而…...
Python打卡训练营-Day13-不平衡数据的处理
浙大疏锦行 知识点: 不平衡数据集的处理策略:过采样、修改权重、修改阈值交叉验证代码 过采样 过采样一般包含2种做法:随机采样和SMOTE 过采样是把少的类别补充和多的类别一样多,欠采样是把多的类别减少和少的类别一样 一般都是缺…...
)
【专题】神经网络期末复习资料(题库)
神经网络期末复习资料(题库) 链接:https://blog.csdn.net/Pqf18064375973/article/details/148332887?sharetypeblogdetail&sharerId148332887&sharereferPC&sharesourcePqf18064375973&sharefrommp_from_link 【测试】 Th…...
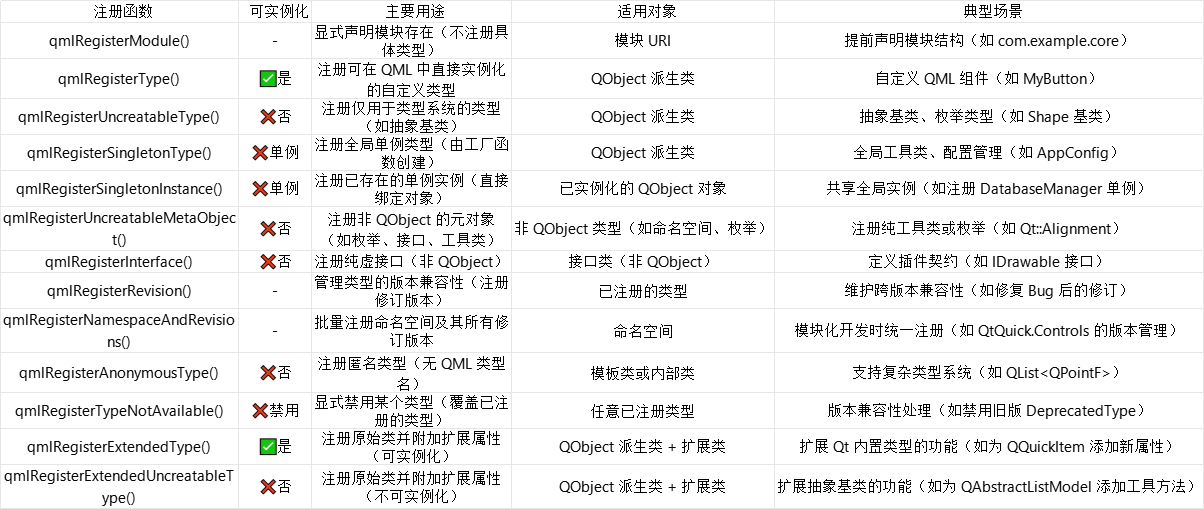
2.qml使用c++
目录 1.概述2.注册方式3. 分类①枚举类②工具类③数据类④资源类②视图类 1.概述 qml是用来干嘛的? 当然是提高UI开发效率的 为什么要混合C? 因为qml无法处理密集型数据逻辑 而加入c则兼顾了性能 达到11>2 总结就是 qml 开发UI, C 实现逻辑 而js的用…...
)
【数据结构】字符串操作整理(C++)
1. 字符串长度与容量 size() / length() 定义:返回字符串的当前长度(字符数)。用法: string s "hello"; cout << s.size(); // 输出:5提示:size() 和 length() 功能完全相同࿰…...

PostgreSQL的扩展 dblink
PostgreSQL的扩展 dblink dblink 是 PostgreSQL 的一个核心扩展,允许在当前数据库中访问其他 PostgreSQL 数据库的数据,实现跨数据库查询功能。 一、dblink 扩展安装与启用 1. 安装扩展 -- 使用超级用户安装 CREATE EXTENSION dblink;2. 验证安装 -…...
c++5月31日笔记
题目:水龙头 时间限制:C/C 语言 1000MS;其他语言 3000MS 内存限制:C/C 语言 65536KB;其他语言 589824KB 题目描述: 小明在 0 时刻(初始时刻)将一个空桶放置在漏水的水龙头下。已知桶…...
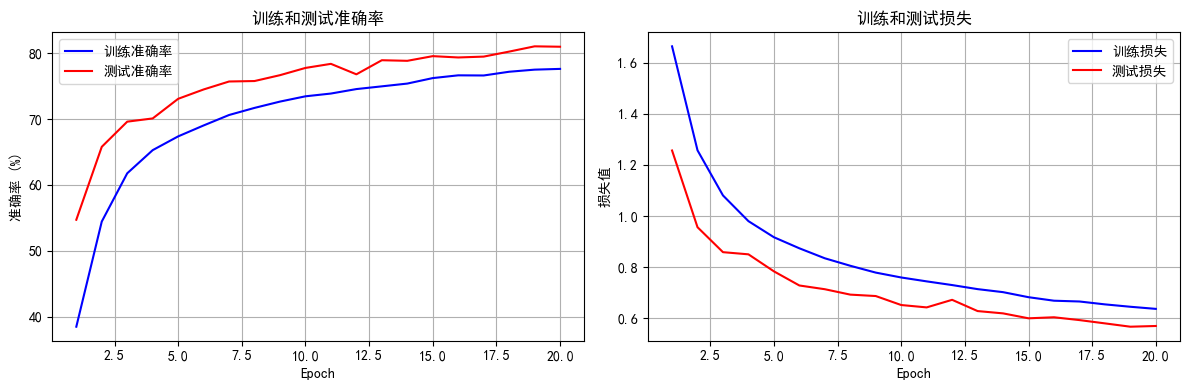
Python打卡训练营Day41
DAY 41 简单CNN 知识回顾 数据增强卷积神经网络定义的写法batch归一化:调整一个批次的分布,常用与图像数据特征图:只有卷积操作输出的才叫特征图调度器:直接修改基础学习率 卷积操作常见流程如下: 1. 输入 → 卷积层 →…...

【Java进阶】图像处理:从基础概念掌握实际操作
一、核心概念:BufferedImage - 图像的画布与数据载体 在Java图像处理的世界里,BufferedImage是当之无愧的核心。你可以将它想象成一块内存中的画布,所有的像素数据、颜色模型以及图像的宽度、高度等信息都存储在其中。 BufferedImage继承自…...