(Python网络爬虫);抓取B站404页面小漫画
目录
一. 分析网页
二. 准备工作
三. 实现爬虫
1. 抓取工作
2. 分析工作
3. 拼接主函数&运行结果
四. 完整代码清单
1.多线程版本spider.py:
2.异步版本async_spider.py:
经常逛B站的同志们可能知道,B站的404页面做得别具匠心:
可以通过https://www.bilibili.com/404来访问这个页面,我们还能换一换:
 不过,能刷出哪个小漫画都是随机的,究竟有多少张我确实不知道。所以我突发奇想,想把这些东西爬下来,正好作为爬虫案例练手也不错呀!
不过,能刷出哪个小漫画都是随机的,究竟有多少张我确实不知道。所以我突发奇想,想把这些东西爬下来,正好作为爬虫案例练手也不错呀!
一. 分析网页
我们先“御驾亲征”看看应该怎么下手,这时就需要用 F12 召唤开发者工具看网页代码了。
通过元素检查,可以发现img对象的src属性包含了一个链接,这就是图片的来源。
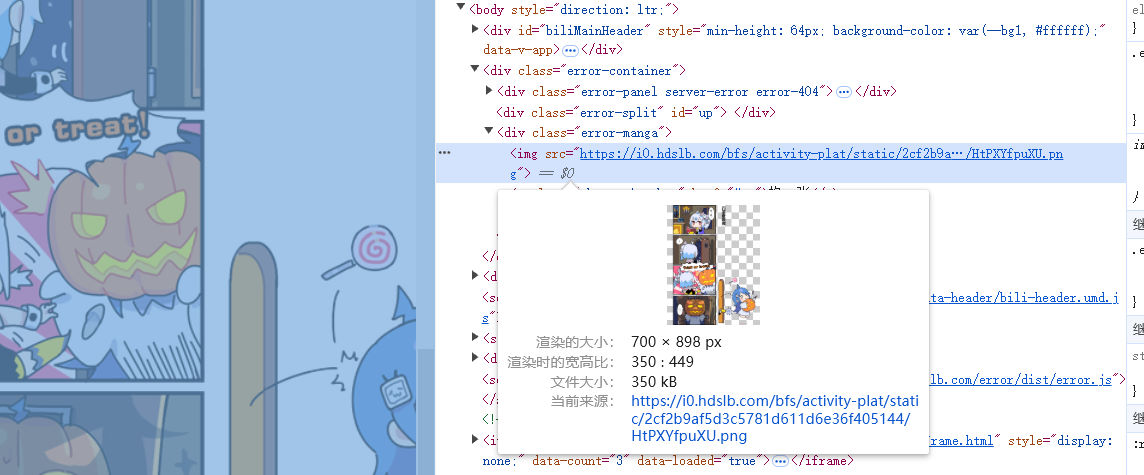
每次换页,这个链接就会变更。说明网页资源是利用JavaScript动态渲染的,不应该像基础爬虫那样直接从网页源代码抓取信息。那么首先,先看看是不是通过Ajax请求动态渲染的,如果是的话,直接模拟Ajax请求即可,不需要用selenium之类的工具。
经过筛查,有三个.xhr类型的请求:
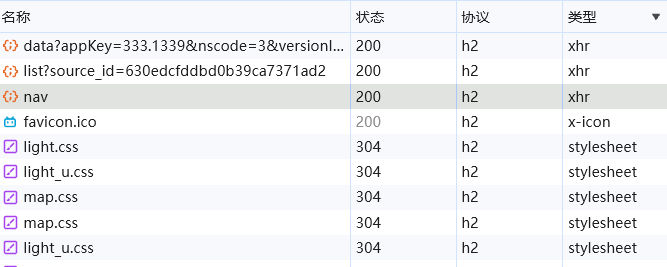
其中中间的那个请求,它的响应是json数据,里面就是我们要找的信息——图片id和链接:
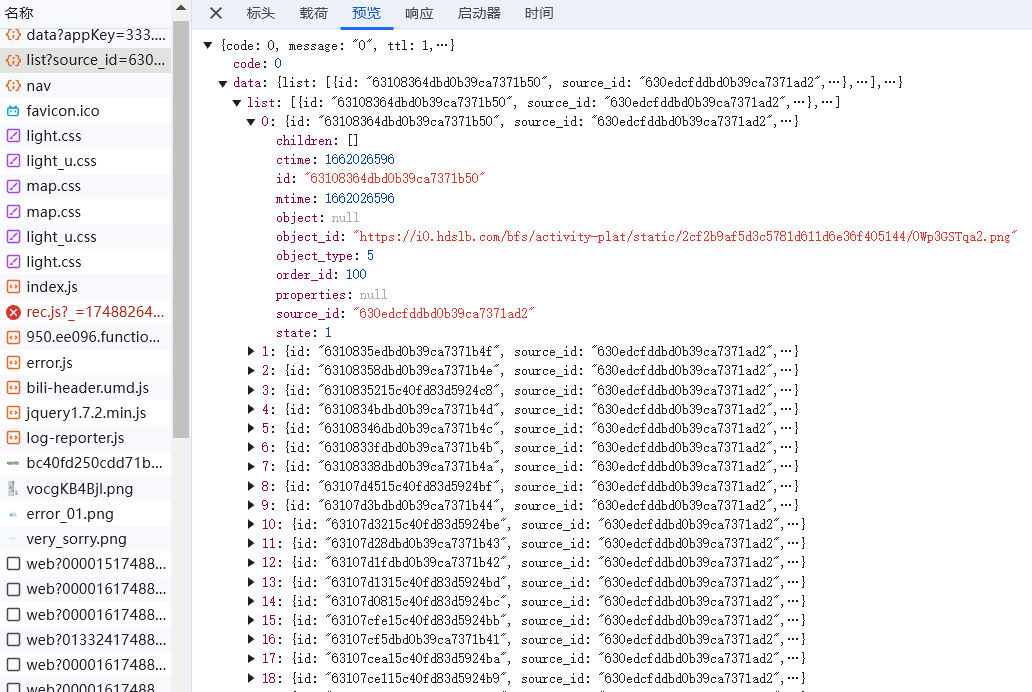
那现在问题就解决了,我们的思路很简单——先模拟这个ajax请求,获取响应的json数据;然后根据数据中的url,请求图片并保存到计算机上。 我看了看一共只有20张图片,所以不强要求异步爬虫。正好我的异步编程水平很拉跨,没个几千条数据我是不会用异步的!
二. 准备工作
那么,用什么工具呢?首先是http库,我们之前看到、这些请求的协议类型清一色都是"h2":
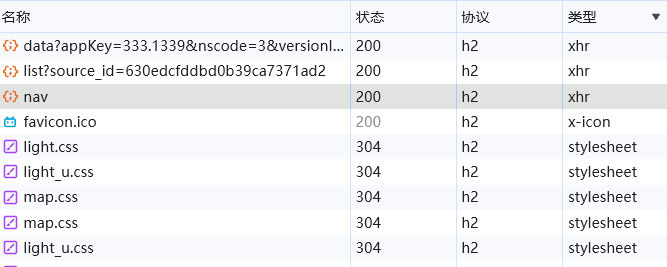
那么我们就不能用requests或者标准库urllib,它们不支持Http/2.0协议,但是可以用httpx这个第三方库。httpx的API和requests很类似,在简单的请求方面几乎是完全一样。不过它可以支持Http/2.0协议,还自带异步框架,确实非常好用。
其次是解析库,这里处理的是json数据不是html数据,什么靓汤呀正则呀都不需要了。不过json库可能会用上,暂时把它考虑上吧。
最后是保存图片,pathlib肯定会有用的,它太棒了。
至于其它的,我会用logging这个日志库。合理记录程序运行情况有助于调试爬虫程序,没个日志还要修爬虫的BUG太折磨了;虽然不用异步,但可能会用concurrent库来进行并发,提高爬取效率。
老B毕竟是大网站,没个UA伪装它还是会把我们当场擒获的:
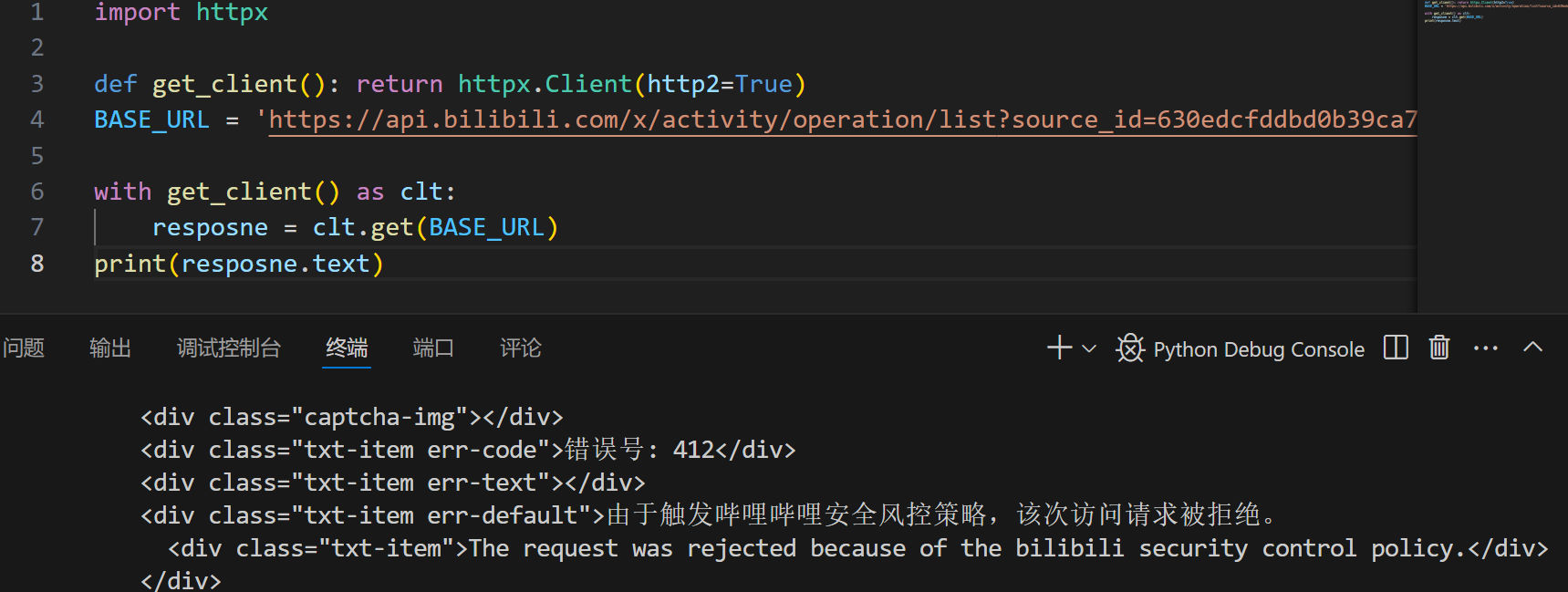
幸好,只加个UA就过了,毕竟404页面没必要下太多功夫防御吧:
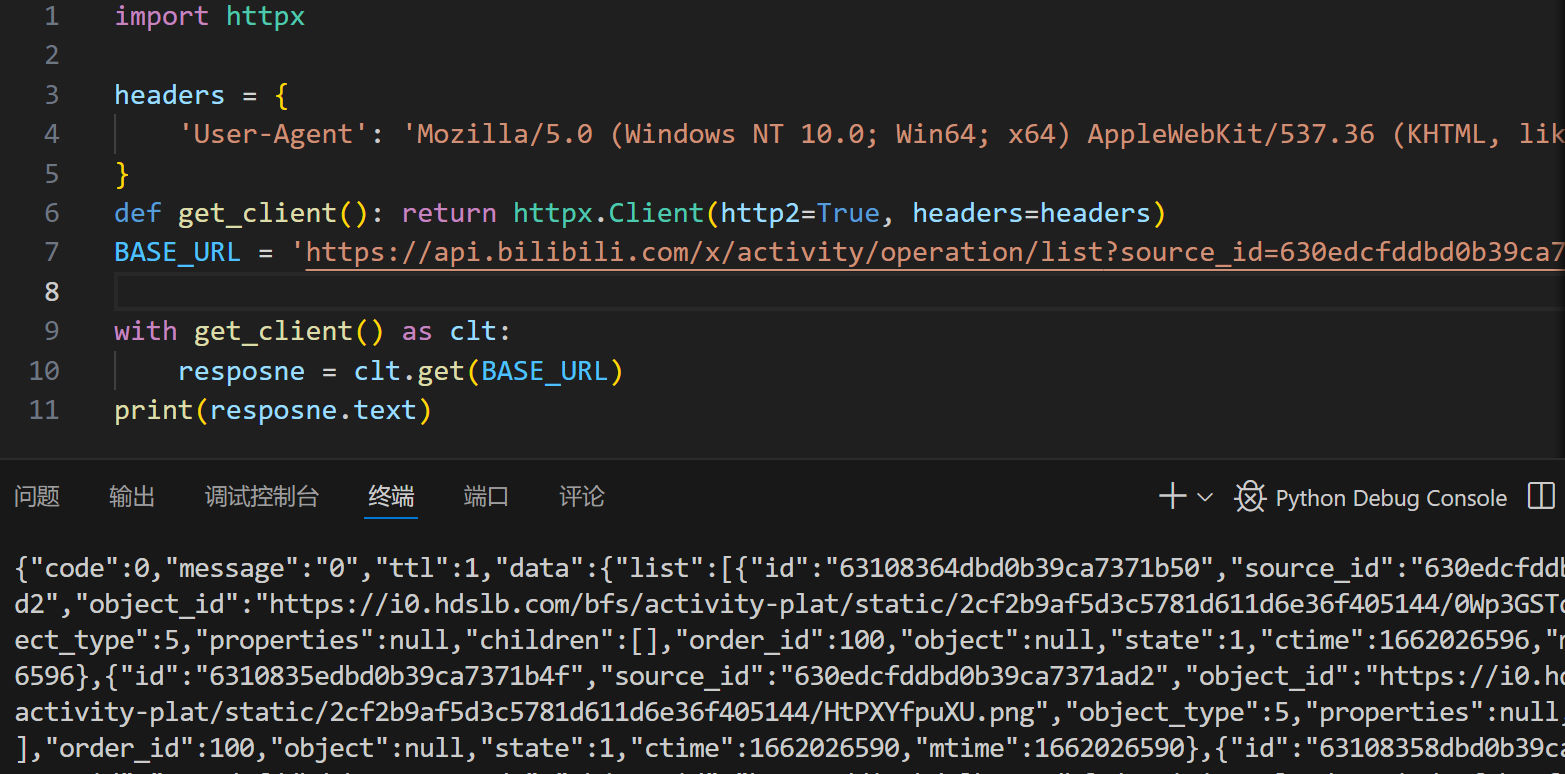
好,有了这些分析,下面我们来实现这个程序。
三. 实现爬虫
新建一个文件夹,在其中创建spider.py文件,现在开始实现它。
1. 抓取工作
首先是导入工作和必要的准备。为了便于阅读,我直接在代码片段中写(部分1)之类的提示,尽管这是不合法的:
(部分1)
import logging
from pathlib import Path
from concurrent import futuresimport httpxfrom my_modules.clock import clock
(部分2)
logging.basicConfig(level=logging.INFO,format='%(asctime)s-%(levelname)s:%(message)s'
)
logging.getLogger('httpx').setLevel(logging.WARNING)
(部分3)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36'
}
def get_client(): return httpx.Client(http2=True, headers=headers, timeout=10)
BASE_URL = 'https://api.bilibili.com/x/activity/operation/list?source_id=630edcfddbd0b39ca7371ad2'
SAVED_DIR = Path('images')(1):这一部分导入要用的库。根据PEP8的建议,在Python中导入模块时,标准库、第三方库、和自己编写的模块要分开写,并用空行隔开。这个clock是个装饰器,用来计时,看看这个爬虫程序的效率如何。
(2):这一部分配置logging。首先,level=logging.INFO指出会报告'info'及以上级别的日志;format规定日志输出的形式;最后那个getLogger('httpx')……是为了阻止httpx库报告warning以下级别的日志,不然它每次请求成功都会自动给我发一个info日志,直接就刷屏了,烦人。
(3):上来就是请求头headers,只做了一下UA伪装。这个get_client()函数返回一个可以执行请求的client对象,为什么我不直接写client = httpx.Client(……)然后在全局使用它呢?
- 一来,这样的话client需要用close()关闭,用with语句更好。然而,成品client对象是不能在with中使用的,所以我选择用这个函数动态创建client;
- 二来,我害怕client不是线程安全的,共用一个可能导致意外BUG。为了避免麻烦还是为每个请求动态分配一个吧。不过我没有考证,没准是线程安全的?
当然还有其他策略,还可以参考最后我给出的异步版本的那种方案。那两个常量BASE_URL和SAVED_DIR分别是 Ajax请求的url 和 图片保存的路径。
然后,我们定义一个通用爬取函数,返回的是响应。 这样后面不管是获取text,json()还是content都能复用它:
def scrape_url(url: str) -> httpx.Response|None:"""抓取url的页面,返回响应;超时则返回None"""logging.info('开始抓取:%s', url)try:with get_client() as client:response = client.get(url)except httpx.TimeoutException:logging.warning('警告!请求超时:%s', url)return Noneexcept httpx.RequestError:logging.critical('重大错误!抓取时发生异常:%s', url, exc_info=True)raiseelse:logging.info('抓取成功:%s', url)return response这里关键点只有try-else语句,仅在try语句完美地执行下来没有出错时,才会执行else子句的内容。logging.info()这样的函数以不同的等级进行日志报告,比如warning是警告,critical是严重错误。
然后,复用它来定义两个具体抓取函数,一个模拟ajax请求、一个用来抓取图片。这里的注解用到了Any,需要从typing导入它:
def scrape_ajax(url: str) -> Any|None:"""抓取ajax请求返回的响应,返回其中的json数据"""response = scrape_url(url)if response is not None:return response.json()else:return None
def scrape_img(url: str) -> bytes|None:"""抓取图片url的响应,获取其二进制数据"""response = scrape_url(url)if response is not None:logging.info('获取图片数据成功:%s', url)return response.contentelse:return None下一步我们来看看怎么从scrape_ajax返回的数据中获取我们想要的信息。
2. 分析工作
通过源码观察ajax请求的响应,返回的东西是这样的:

这是个json数据,首先我们应该提取“data”,然后提取里面的“list”,这里面放着的是各个图片的数据。对于每张图片,我想要“id”和“object_id”两个数据,前者拿来在保存时命名,后者供scrape_img使用来获取二进制数据。那么我可以先把“Image”封装为一个数据类,每个Image有id和url两个属性。我喜欢用typing的NamedTuple,它能很方便地创造一个轻量级数据类:
class Image(NamedTuple):"""封装图片数据的类"""id: strurl: str将这段代码写在准备工作那里,现在就可以开始写分析数据的函数了。
def parse_ajax(data: Any) -> list[Image]:"""分析ajax请求的响应数据,封装为Image对象列表返回"""imgs = []img_lst = data.get('data').get('list')for img in img_lst:id = img.get('id')url = img.get('object_id')new_img = Image(id, url)imgs.append(new_img)return imgs这个函数分析ajax响应的json数据,从中提取信息封装为Image对象,并打包为列表返回。
然后,是一个保存图片用的函数,负责消费这些Images对象:
def save_img(image: Image) -> None:"""保存单张图片"""name, url = imagedata = scrape_img(url)if data is not None:(SAVED_DIR / f'{name}.png').write_bytes(data)logging.info('图片保存成功:%s', name)else:logging.error('图片获取失败:%s', name)第一行直接拆包Image对象拿到id和url,然后尝试用scrape_img抓取二进制数据。如果不是None,则保存到SAVED_DIR中并给出一条报告。否则,说明请求超时,也给出一条报告。
最后,我们把这些“积木”拼起来写成主函数,这个程序就完成啦。
3. 拼接主函数&运行结果
下面是主函数,它“奋六世之余烈”,把我们一直以来做的工作协调起来:
@clock(report_upon_exit=True)
def main():"""启动!"""SAVED_DIR.mkdir(exist_ok=True)ajax_json = scrape_ajax(BASE_URL)if ajax_json is None:raise RuntimeError('第一个请求都超时了,还想做爬虫?')images = parse_ajax(ajax_json)with futures.ProcessPoolExecutor() as executor:executor.map(save_img, images)if __name__ == '__main__':main()这里有很多老面孔打赢复活赛了,尤其是concurrent.futures。
- 首先,用了我自己的装饰器来计时。
- 然后,SAVED_DIR.mkdir()函数是让程序创建这个目录。但是如果目录已经存在这一句就会报错,指定exist_ok=True可以避免这种行为。
- 获取ajax请求的响应,如果是None的话说明超时了。要是这么重要的数据都得不到,那我们也没有继续运行程序的理由了,直接报错吧。
- 用parse_ajax来获取封装的图片数据。
- 用concurrent.futures.ProcessPoolExecutor来多进程地执行save_img任务,可以提高效率。
很好,下面我们来运行一下看看,终端的结果如下:
 11秒!这个效率我觉得还是不行。我试了试完全顺序执行,用时15秒。这里多进程的提升确实有限。感觉get_client也有锅,在异步爬虫里必须更改这部分逻辑,否则它会阻塞协程。
11秒!这个效率我觉得还是不行。我试了试完全顺序执行,用时15秒。这里多进程的提升确实有限。感觉get_client也有锅,在异步爬虫里必须更改这部分逻辑,否则它会阻塞协程。
把上面的ProcessPoolExecutor改为ThreadPoolExecutor就能改为多线程版本,它的运行时间如下:
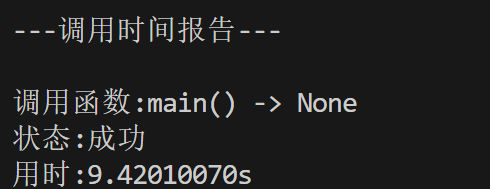
用时9.4s,看来多线程在这里强于多进程。即使因为GIL,多线程常被人诟病,但是它轻量,在这里就超过了开销更大的多进程版本。

我还实现了一版异步爬虫,它的用时如下:
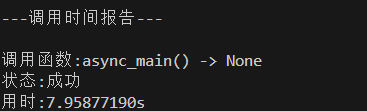
用时7.9s接近8s,可以看到,尽管中间存在阻塞步骤,异步的效率还是更强。它是真适合干这个呀,异步拿了MVP!异步的脚本跟多进程的相比改动有些大、更改了一些逻辑、我就不详细说了,最后我会给出异步的代码清单。
不管怎样,成功把图片下载下来了,这就是成功!还要啥自行车啊?
 好了,完事儿(* ̄▽ ̄)~*。下面我来放一下多线程和异步版本的完整代码清单。
好了,完事儿(* ̄▽ ̄)~*。下面我来放一下多线程和异步版本的完整代码清单。
四. 完整代码清单
1.多线程版本spider.py:
import logging
from pathlib import Path
from concurrent import futures
from typing import Any, NamedTupleimport httpxfrom my_modules.clock import clocklogging.basicConfig(level=logging.INFO,format='%(asctime)s-%(levelname)s:%(message)s'
)
logging.getLogger('httpx').setLevel(logging.WARNING)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36'
}
def get_client(): return httpx.Client(http2=True, headers=headers, timeout=10)
BASE_URL = 'https://api.bilibili.com/x/activity/operation/list?source_id=630edcfddbd0b39ca7371ad2'
SAVED_DIR = Path('images')class Image(NamedTuple):"""封装图片数据的类"""id: strurl: strdef scrape_url(url: str) -> httpx.Response|None:"""抓取url的页面,返回响应;超时则返回None"""logging.info('开始抓取:%s', url)try:with get_client() as client:response = client.get(url)except httpx.TimeoutException:logging.warning('警告!请求超时:%s', url)return Noneexcept httpx.RequestError:logging.critical('重大错误!抓取时发生异常:%s', url, exc_info=True)raiseelse:logging.info('抓取成功:%s', url)return response
def scrape_ajax(url: str) -> Any|None:"""抓取ajax请求返回的响应,返回其中的json数据"""response = scrape_url(url)if response is not None:return response.json()else:return None
def scrape_img(url: str) -> bytes|None:"""抓取图片url的响应,获取其二进制数据"""response = scrape_url(url)if response is not None:logging.info('获取图片数据成功:%s', url)return response.contentelse:return None
def parse_ajax(data: Any) -> list[Image]:"""分析ajax请求的响应数据,封装为Image对象列表返回"""imgs = []img_lst = data.get('data').get('list')for img in img_lst:id = img.get('id')url = img.get('object_id')new_img = Image(id, url)imgs.append(new_img)return imgs
def save_img(image: Image) -> None:"""保存单张图片"""name, url = imagedata = scrape_img(url)if data is not None:(SAVED_DIR / f'{name}.png').write_bytes(data)logging.info('图片保存成功:%s', name)else:logging.error('图片获取失败:%s', name)@clock(report_upon_exit=True)
def main():"""启动!"""SAVED_DIR.mkdir(exist_ok=True)ajax_json = scrape_ajax(BASE_URL)if ajax_json is None:raise RuntimeError('第一个请求都超时了,还想做爬虫?')images = parse_ajax(ajax_json)with futures.ThreadPoolExecutor() as executor:executor.map(save_img, images)if __name__ == '__main__':main()2.异步版本async_spider.py:
import asyncio
import logging
from pathlib import Path
from typing import Any, NamedTupleimport httpxfrom my_modules.clock import clocklogging.basicConfig(level=logging.INFO,format='%(asctime)s-%(levelname)s:%(message)s'
)
logging.getLogger('httpx').setLevel(logging.WARNING)headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36'
}
BASE_URL = 'https://api.bilibili.com/x/activity/operation/list?source_id=630edcfddbd0b39ca7371ad2'
SAVED_DIR = Path('async_images')class Image(NamedTuple):"""封装图片数据的类"""id: strurl: strasync def scrape_url(client: httpx.AsyncClient, url: str) -> httpx.Response|None:"""异步抓取url的页面,返回响应;超时则返回None"""logging.info('开始抓取:%s', url)try:response = await client.get(url)except httpx.TimeoutException:logging.warning('警告!请求超时:%s', url)return Noneexcept httpx.RequestError:logging.critical('重大错误!抓取时发生异常:%s', url, exc_info=True)raiseelse:logging.info('抓取成功:%s', url)return response
async def scrape_ajax(client: httpx.AsyncClient, url: str) -> Any|None:"""异步抓取ajax请求返回的响应,返回其中的json数据"""response = await scrape_url(client, url)if response is not None:return response.json()return None
async def scrape_img(client: httpx.AsyncClient, url: str) -> bytes|None:"""异步抓取图片url的响应,获取其二进制数据"""response = await scrape_url(client, url)if response is not None:logging.info('获取图片数据成功:%s', url)return response.contentreturn None
def parse_ajax(data: Any) -> list[Image]:"""分析ajax请求的响应数据,封装为Image对象列表返回"""imgs = []img_lst = data.get('data', {}).get('list', [])for img in img_lst:id = img.get('id')url = img.get('object_id')if id and url:imgs.append(Image(id, url))return imgs
async def save_img(client: httpx.AsyncClient, image: Image) -> None:"""异步保存单张图片"""name, url = imagedata = await scrape_img(client, url)if data is not None:(SAVED_DIR / f'{name}.png').write_bytes(data)logging.info('图片保存成功:%s', name)else:logging.error('图片获取失败:%s', name)@clock(report_upon_exit=True)
async def async_main():"""启动!异步爬虫"""SAVED_DIR.mkdir(exist_ok=True)async with httpx.AsyncClient(http2=True, headers=headers, timeout=10) as client:ajax_json = await scrape_ajax(client, BASE_URL)if ajax_json is None:raise RuntimeError('第一个请求都超时了,还想做爬虫?')images = parse_ajax(ajax_json)tasks = [save_img(client, image) for image in images]await asyncio.gather(*tasks)if __name__ == '__main__':asyncio.run(async_main()) 
相关文章:
(Python网络爬虫);抓取B站404页面小漫画
目录 一. 分析网页 二. 准备工作 三. 实现爬虫 1. 抓取工作 2. 分析工作 3. 拼接主函数&运行结果 四. 完整代码清单 1.多线程版本spider.py: 2.异步版本async_spider.py: 经常逛B站的同志们可能知道,B站的404页面做得别具匠心&…...

【氮化镓】GaN HMETs器件物理失效分析进展
2021 年 5 月,南京大学的蔡晓龙等人在《Journal of Semiconductors》期刊发表了题为《Recent progress of physical failure analysis of GaN HEMTs》的文章,基于多种物理表征技术及大量研究成果,对 GaN HEMTs 的常见失效机制进行了系统分析。文中先介绍失效分析流程,包括使…...

vb.net oledb-Access 数据库本身不支持命名参数,赋值必须和参数顺序一致才行
参数顺序问题:OleDb 通常依赖参数添加的顺序而非名称,为什么顺序要一样? OleDbParameter 顺序依赖性的原因 OleDb 数据提供程序依赖参数添加顺序而非名称,这是由 OLE DB 规范和 Access 数据库的工作机制共同决定的。理解这个问题需要从数据库底层通信…...
Abaqus连接器弹片正向力分析:
.学习重点: • 外部幾何匯入。 • 建立解析剛性面。 • 利用Partition與局部撒點來提高網格品質。 • 材料塑性行為(材料非線性)。 • 考慮大變形(幾何非線性)。 • 接觸(邊界非線性)。 • 平移組裝。 • 設定輸出參數。 • 討論Shear Locking & Hourglassing效應。 1) 設…...

鸿蒙生态再添翼:身份证银行卡识别引领智能识别技术新篇章
随着信创国产化战略的深入推进和鸿蒙操作系统(HarmonyOS Next)的迅速崛起,市场对兼容国产软件生态的需求日益增长。在这一背景下,中安身份证识别和银行卡识别技术应运而生,为鸿蒙生态的发展注入了新的活力。 移动端身份…...

mybatis打印完整的SQL,p6spy
介绍打印完成的SQL,会降低性能,不要在生产环境使用,我只是在本地,自己的代码中设置,不提交。主要是为了方便,在控制台看见SQL的时候,不用去拼接参数,可以直接复制出来执行。 配置方…...
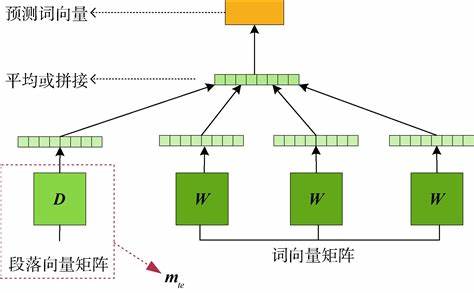
NLP学习路线图(十九):GloVe
自然语言处理(NLP)的核心挑战在于让机器理解人类语言的丰富含义。词向量(Word Embeddings)技术通过将词语映射到高维实数空间,将离散的符号转化为连续的向量,为NLP任务奠定了坚实基础。在众多词向量模型中&…...
如何使用DAXStudio将PowerBI与Excel连接
如何使用DAXStudio将PowerBI与Excel连接 之前分享过一篇自动化文章:PowerBI链接EXCEL实现自动化报表,使用一个EXCEL宏工作薄将PowerBI与EXCEL连接起来,今天分享另一个方法:使用DAX Studio将PowerBI与EXCEL连接。 下面是使用DAX S…...

软考 系统架构设计师系列知识点之杂项集萃(79)
接前一篇文章:软考 系统架构设计师系列知识点之杂项集萃(78) 第141题 软件测试一般分为两个大类:动态测试和静态测试。前者通过运行程序发现错误,包括()等方法;后者采用人工和计算机…...
)
神经网络基础:从单个神经元到多层网络(superior哥AI系列第3期)
🧠 神经网络基础:从单个神经元到多层网络(superior哥AI系列第3期) 哈喽!各位AI探索者们!👋 上期我们把数学"怪兽"给驯服了,是不是感觉还挺轻松的?今天我们要进…...

UVa12298 Super Joker II
UVa12298 Super Joker II 题目链接题意输入格式输出格式 分析AC 代码 题目链接 UVa12298 Super Joker II 题意 有一副超级扑克,包含无数张牌。对于每个正合数p,恰好有4张牌:黑桃p,红桃p,梅花p和方块p(分别…...

面向对象系统中对象交互的架构设计哲学
更多精彩请访问:通义灵码2.5——基于编程智能体开发Wiki多功能搜索引擎-CSDN博客 一、对象交互的本质与设计矛盾 在面向对象范式(OOP)中,对象间的交互实质上是软件组件解耦与功能复用的动态平衡过程。每个对象作为独立的计算单元,既需要维护…...
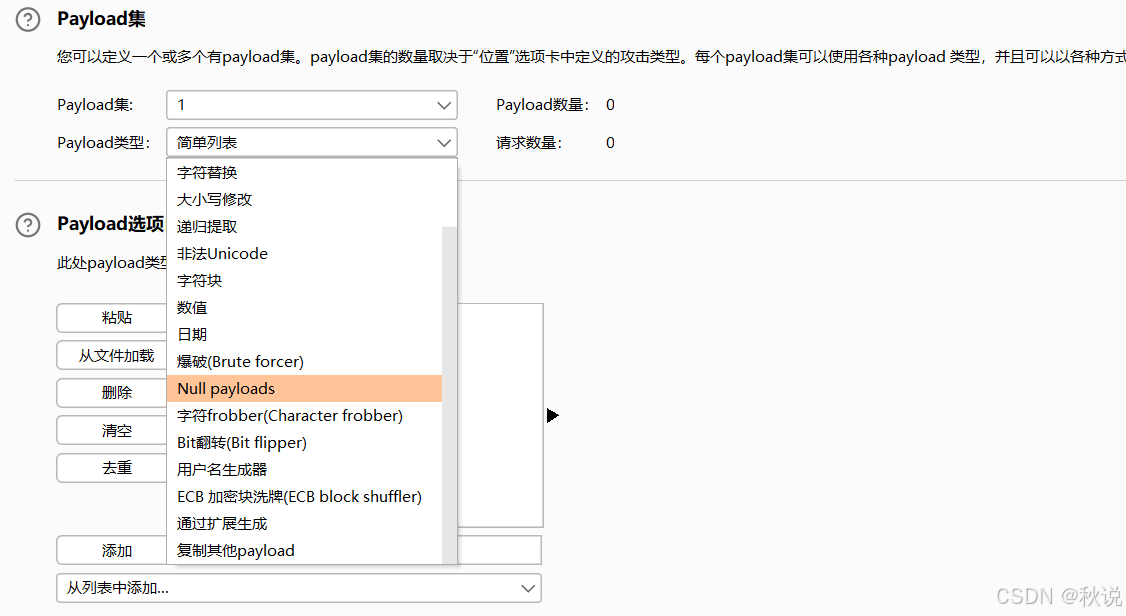
【网络安全】SRC漏洞挖掘思路/手法分享
文章目录 Tip1Tip2Tip3Tip4Tip5Tip6Tip7Tip8Tip9Tip10Tip11Tip12Tip13Tip14Tip15Tip16Tip17Tip18Tip19Tip20Tip21Tip22Tip23Tip24Tip25Tip26Tip27Tip28Tip29Tip30Tip1 “复制该主机所有 URL”:包含该主机上的所有接口等资源。 “复制此主机里的链接”:包括该主机加载的第三…...

【AFW+GRU(CNN+RNN)】Deepfakes Detection with Automatic Face Weighting
文章目录 Deepfakes Detection with Automatic Face Weighting背景pointsDeepfake检测挑战数据集方法人脸检测面部特征提取自动人脸加权门控循环单元训练流程提升网络测试时间增强实验结果Deepfakes Detection with Automatic Face Weighting 会议/期刊:CVPRW 2020 作者: …...

【面试】音视频面试
C内存模型 H.265(HEVC)相比H.264(AVC)的核心优势 1. 压缩效率显著提升 在相同画质下,H.265的码率比H.264降低约40-50%,尤其适用于4K/8K超高清场景。通过**更大的编码单元(CTU,最大…...

性能优化 - 案例篇:缓冲区
文章目录 Pre1. 引言2. 缓冲概念与类比3. Java I/O 中的缓冲实现3.1 FileReader vs BufferedReader:装饰者模式设计3.2 BufferedInputStream 源码剖析3.2.1 缓冲区大小的权衡与默认值 4. 异步日志中的缓冲:Logback 异步日志原理与配置要点4.1 Logback 异…...

Java编程之建造者模式
建造者模式(Builder Pattern)是一种创建型设计模式,它将一个复杂对象的构建与表示分离,使得同样的构建过程可以创建不同的表示。这种模式允许你分步骤构建一个复杂对象,并且可以在构建过程中进行不同的配置。 模式的核…...

基于TI DSP控制的光伏逆变器最大功率跟踪mppt
基于TI DSP(如TMS320F28335)控制的光伏逆变器最大功率跟踪(MPPT)程序通常涉及以下几个关键部分:硬件电路设计、MPPT算法实现、以及DSP的编程。以下是基于TI DSP的光伏逆变器MPPT程序的一个示例,主要采用扰动…...

Python玩转自动驾驶仿真数据生成:打造你的智能“路测场”
Python玩转自动驾驶仿真数据生成:打造你的智能“路测场” 说到自动驾驶,很多人第一时间想到的是那些造车新势力、激光雷达、传感器、深度学习模型……确实,这些都是自动驾驶的核心硬核。但我今天想和你聊聊一个“幕后功臣”——仿真数据生成。没错,自动驾驶离不开大数据,更…...

从测试角度看待CI/CD,敏捷开发
什么是敏捷开发? 是在高强度反馈的情况下,短周期,不断的迭代产品,满足用户需求,抢占更多的市场 敏捷开发是什么? 是一种产品快速迭代的情况下,降低出错的概率,具体会落实到公司的…...

agent mode 代理模式,整体要求,系统要求, 系统指令
1. 起因, 目的: 我发现很多时候,我在重复我的要求。很烦。决定把一些过程记录下来,提取一下。 2. 先看效果 无。 3. 过程: 要求: 这2个文件,是我与 AI 聊天的一些过程记录。 请阅读这2个文件,帮我提取出一些共同…...
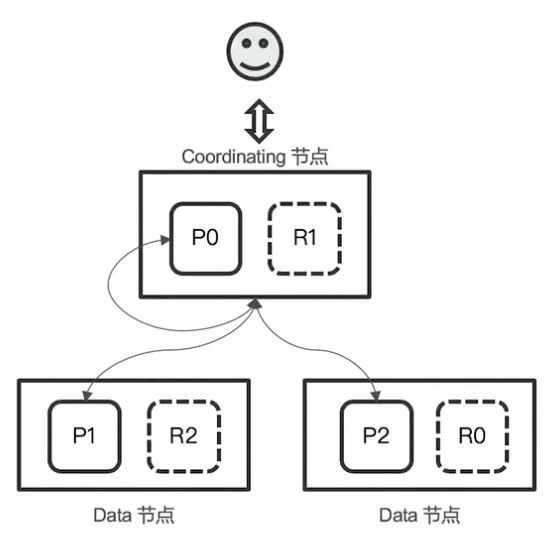
ES101系列07 | 分布式系统和分页
本篇文章主要讲解 ElasticSearch 中分布式系统的概念,包括节点、分片和并发控制等,同时还会提到分页遍历和深度遍历问题的解决方案。 节点 节点是一个 ElasticSearch 示例 其本质就是一个 Java 进程一个机器上可以运行多个示例但生产环境推荐只运行一个…...
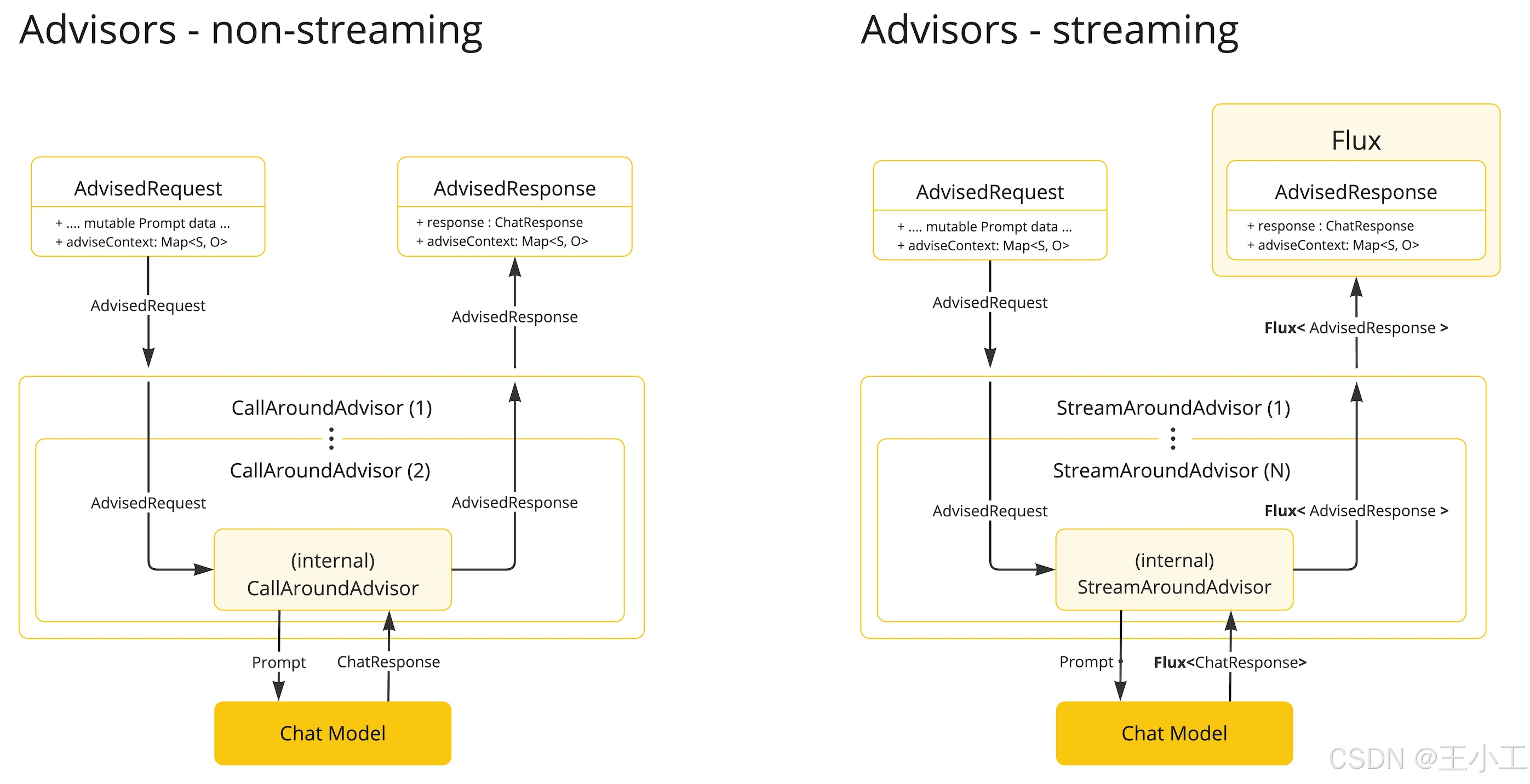
Spring AI Advisor机制
Spring AI Advisors 是 Spring AI 框架中用于拦截和增强 AI 交互的核心组件,其设计灵感类似于 WebFilter,通过链式调用实现对请求和响应的处理5。以下是关键特性与实现细节: 核心功能 1. 请求/响应拦截 通过 AroundAdvisor 接口动态修…...
Vue3 + Vite:我的 Qiankun 微前端主子应用实践指南
前言 实践文章指南 vue微前端qiankun框架学习到项目实战,基座登录动态菜单及权限控制>>>>实战指南:Vue 2基座 Vue 3 Vite TypeScript微前端架构实现动态菜单与登录共享>>>>构建安全的Vue前后端分离架构:利用长Token与短Tok…...

使用ArcPy生成地图系列
设置地图布局 在生成地图系列之前,需要先设置地图布局。这包括定义地图的页面大小、地图框的位置和大小、标题、图例等元素。ArcPy提供了arcpy.mp.ArcGISProject方法来加载ArcGIS Pro项目文件(.aprx),并操作其中的地图布局。 Py…...
日语输入法怎么使用罗马字布局怎么安装日语输入法
今天帮客户安装日语输入法的时候遇到了一个纠结半天的问题,客户一直反馈说这个输入法不对,并不是他要的功能。他只需要罗马字的布局,而不是打出来字的假名。 片假名、平假名,就好像英文26个字母,用于组成日文单词。两…...

U盘挂载Linux
在 只能使用 Telnet 的情况下,如果希望通过 U盘 传输文件到 Linux 系统,可以按照以下步骤操作: 📌 前提条件 U盘已插入 Linux 主机的 USB 接口。Linux 主机支持自动挂载 U盘(大多数现代发行版默认支持)。T…...

数据结构:栈(Stack)和堆(Heap)
目录 内存(Memory)基础 程序是如何利用主存的? 🎯 静态内存分配 vs 动态内存分配 栈(stack) 程序执行过程与栈帧变化 堆(Heap) 程序运行时的主存布局 内存(Memo…...

用 Vue 做一个轻量离线的“待办清单 + 情绪打卡”小工具
网罗开发 (小红书、快手、视频号同名) 大家好,我是 展菲,目前在上市企业从事人工智能项目研发管理工作,平时热衷于分享各种编程领域的软硬技能知识以及前沿技术,包括iOS、前端、Harmony OS、Java、Python等…...

3D Gaussian splatting 05: 代码阅读-训练整体流程
目录 3D Gaussian splatting 01: 环境搭建3D Gaussian splatting 02: 快速评估3D Gaussian splatting 03: 用户数据训练和结果查看3D Gaussian splatting 04: 代码阅读-提取相机位姿和稀疏点云3D Gaussian splatting 05: 代码阅读-训练整体流程3D Gaussian splatting 06: 代码…...