VMware搭建Hadoop集群 for Windows(完整详细,实测可用)
目录
一、VMware 虚拟机安装
(1)虚拟机创建及配置
(2)创建工作文件夹
二、克隆虚拟机
三、配置虚拟机的网络
(1)虚拟网络配置
(2)配置虚拟机 主机名
(3)配置虚拟机hosts
(4)配置DNS、网关等
(5)reboot 重启虚拟机
四、配置SSH服务
(1)确认ssh进程
(2)生成秘钥
(3)秘钥拷贝
五、JDK安装
(1)把JDK安装包传输到虚拟机
(2)把JDK安装包解压到/export/software/
(3)配置JDK环境变量
六、Hadoop安装
(1)安装包上传及解压
(2)Hadoop系统环境配置
(3)Hadoop集群境配置
3.1 修改hadoop-env.sh文件
3.2 修改core-site.xml文件
3.3 修改hdfs-site.xml文件
3.4 修改mapred-site.xml文件
3.5 修改yarn-site.xml文件
3.6 修改workers文件
(4)将集群主节点的配置文件分发到其他子节点
(5)格式化文件系统
(6)集群启动
七、浏览器查看Hadoop集群
(1)修改windows下ip映射
(2)防火墙关闭
(3)浏览器查看
一、VMware 虚拟机安装
(1)虚拟机创建及配置
VMware下载地址
VMware的安装过程比较简单,正常安装就行,打开后是以下页面:

点击文件==》新建虚拟机








这里选择提前下载好的CentOS镜像:

点击开启此虚拟机
Enter回车,开始安装CentOS镜像:
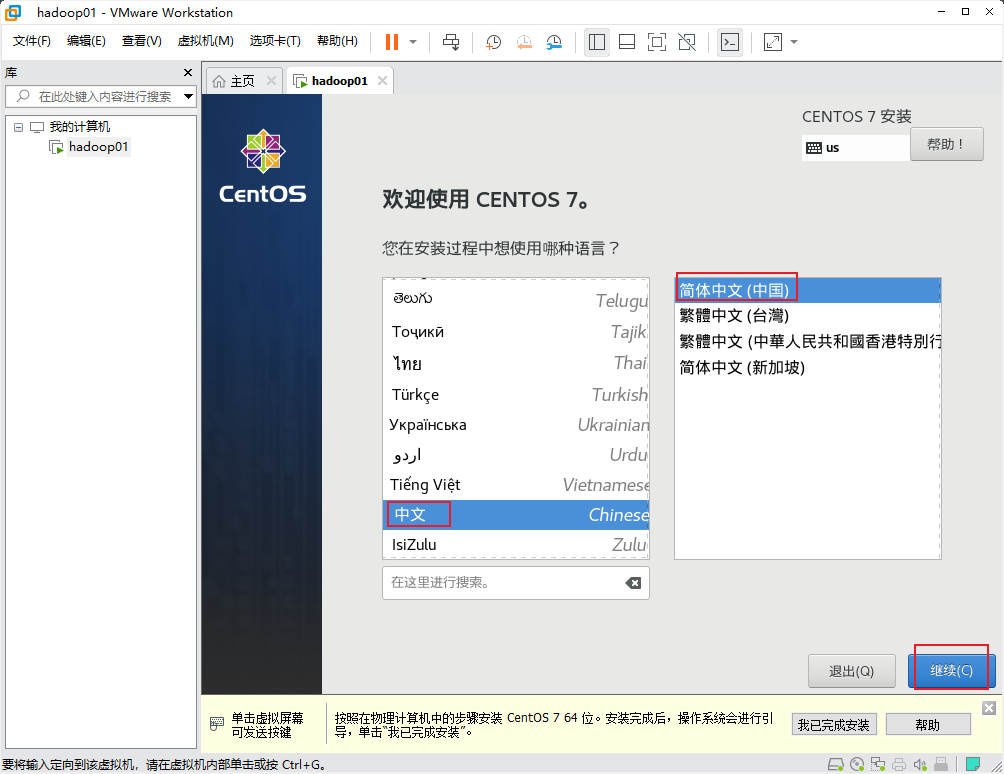
选择语言:
设置日期:

安装位置点进去,点击完成:

KDUMP禁用:

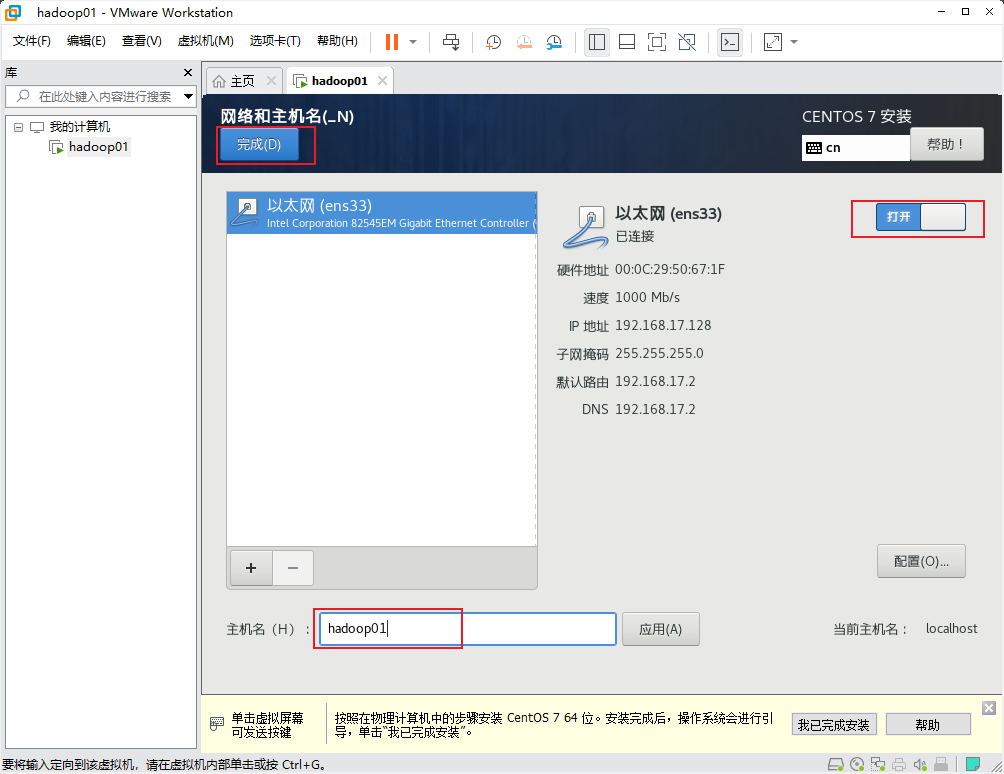
网络和主机名:
点击开始安装:

设置密码

这里要是密码设置过于简单,点击两次完成即可,后面就会继续执行安装了,等待执行完成,店点击重启按钮,重启后进入一下界面:

输入root和密码之后进入虚拟机:

(2)创建工作文件夹
在hadoop01上执行:
mkdir -p /export/data
mkdir -p /export/servers
mkdir -p /export/software二、克隆虚拟机
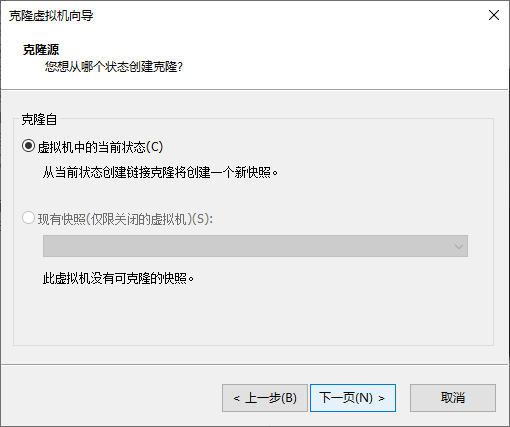
搭建集群需要3个虚拟机,hadoop01,hadoop02,hadoop03,已经安装了hadoop01,剩下两个需要用到虚拟机克隆。
先关闭hadoop01虚拟机:

点击克隆



同理,克隆出hadoop03即可,到这虚拟机创建及配置完毕。
三、配置虚拟机的网络
三台虚拟机的ip和域名映射关系如下:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03
(1)虚拟网络配置
打开虚拟网络编辑器:

选择VMnet8




之后点击确定即可。


(2)配置虚拟机 主机名
在hadoop01虚拟机下执行:
vi /etc/hostnamevi的insert、save等基本操作参考:https://blog.csdn.net/weixin_41231928
修改后如下:
![]()
同理修改hadoop02和hadoop03的hostname为 hadoop02 和 hadoop03,原因是hadoop02和hadoop03是由hadoop01克隆来的,不修改的话,hostname都是hadoop01,修改后如下:
![]()
![]()
(3)配置虚拟机hosts
其实就是配置ip和域名的映射关系。
vi /etc/hosts上面的命令编辑hosts,在3个虚拟机都里面添加:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03

(4)配置DNS、网关等
在3个虚拟机下新增以下ip设置
IPADDR="192.168.121.221"
NETMASK="255.255.255.0"
GATEWAY="192.168.121.2"
DNS1="114.114.114.114"
执行以下命令:
vi /etc/sysconfig/network-scripts/ifcfg-ens33
(5)reboot 重启虚拟机
以上所有配置完成后,执行:
reboot然后可以验证下网络是否通,出现一下说明配置正常:

四、配置SSH服务
SSH服务的作用一般是有两方面:一是便于虚拟机节点之间免密访问,二是传输数据时会有加解密的过程安全性更高。为了这三个节点间免密登录,比如后面在启动hadoop服务时,主节点启动其它从节点,就需要免密去执行。所以3台机器都执行以下流程,这样三台机器就可以使用ssh连接而无需输入密码了。
(1)确认ssh进程
输入以下命令,查看ssh进程是否存在(默认是开启的):
ps -e | grep sshd如下便是开启状态:
![]()
(2)生成秘钥
ssh-keygen -t rsa执行以上命令,不用输入,按3次回车:

(3)秘钥拷贝
三台机器的秘钥分别生成之后,需要将各自的秘钥拷贝到其他2台机器,3台机器都执行以下命令:
ssh-copy-id hadoop01
ssh-copy-id hadoop02
ssh-copy-id hadoop03每条命令中间会有询问,输入“yes”回车,然后输入密码即可:

验证下ssh配置:
在hadoop01下执行ssh hadoop02 和ssh hadoop03,能成功登录:

五、JDK安装
下载一个linux版本的JDK,这里是 jdk-8u161-linux-x64.tar.gz,3台机器均要执行以下。
(1)把JDK安装包传输到虚拟机
这里我们需要借助ftcp文件传输软件,这里使用的是MobaxTerm,也可以使用别的文件传输软件,WinSCP\PuTTY\Xshell都可以。
MobaxTerm新建SFTP类型的session:

可以新建一个root用户,把3个虚拟机的密码输入:

点击ok后:

选择jdk文件,拖入之前建好的/export/software文件夹:


(2)把JDK安装包解压到/export/software/
执行以下命令:
cd /export/software/
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /export/servers/
cd /export/servers/
mv jdk1.8.0_161/ jdk
(3)配置JDK环境变量
执行:
vim /etc/profile在文末添加:
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar

注意:
修改 /etc/profile 文件最后都要执行下
source /etc/profile才能是修改生效。最后执行java -version看下是否配置成功。
六、Hadoop安装
Hadoop下载地址
这里使用的是 hadoop-3.1.3.tar.gz
(1)安装包上传及解压
跟前面JDK一样,先用 mobaxterm 将 hadoop-3.1.3.tar.gz 上传到3台机器的 /export/software:

执行下面解压命令:
tar -zxvf hadoop-3.1.3.tar.gz -C /export/servers/
(2)Hadoop系统环境配置
执行:
vim /etc/profile添加一下内容:
export HADOOP_HOME=/export/servers/hadoop-3.1.3
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root

一样,修改 /etc/profile 文件最后都要执行下 “vim /etc/profile”。
执行验证下:
hadoop version
(3)Hadoop集群境配置
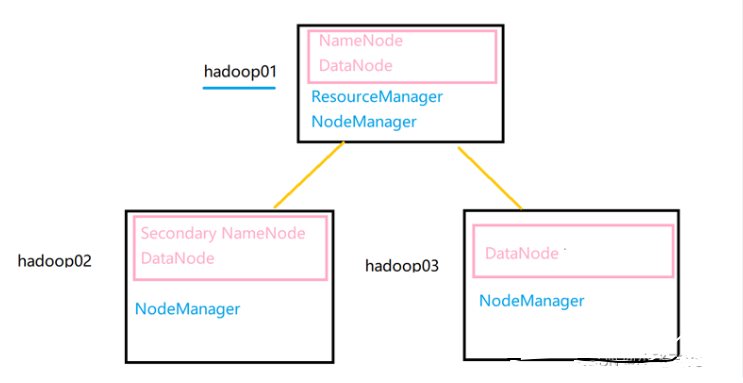
3.1 修改hadoop-env.sh文件
执行:
cd /export/servers/hadoop-3.1.3/etc/hadoop
vim hadoop-env.sh找到export JAVA_HOME的位置修改:
export JAVA_HOME=/export/servers/jdk
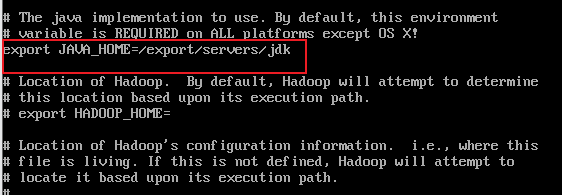
3.2 修改core-site.xml文件
vim core-site.xml添加以下配置:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/export/servers/hadoop-3.1.3/tmp</value>
</property>
</configuration>

hadoop02、hadoop03修改时,把对于域名修改成hadoop02、hadoop03即可。
3.3 修改hdfs-site.xml文件
vim hdfs-site.xml添加以下配置:
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop02:50090</value>
</property>
</configuration>

dfs.namenode.secondary.http-address这配置在hadoop02、hadoop03不用配置。
3.4 修改mapred-site.xml文件
vim mapred-site.xml添加以下配置:
<configuration>
<!-- 指定MapReduce运行时框架,这里指定在Yarn上,默认是local -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
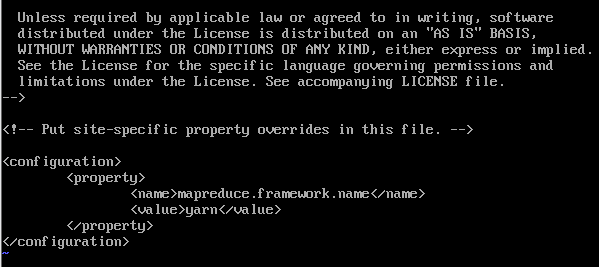
3.5 修改yarn-site.xml文件
vi yarn-site.xml添加以下配置:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
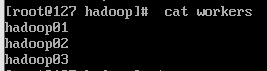
3.6 修改workers文件
vim workers删除默认的localhost,添加以下内容:
hadoop01
hadoop02
hadoop03
(4)将集群主节点的配置文件分发到其他子节点
执行:
scp /etc/profile hadoop02:/etc/profile
scp /etc/profile hadoop03:/etc/profile
scp -r /export/ hadoop02:/
scp -r /export/ hadoop03:/
传完之后要在hadoop02和hadoop03上分别执行 source /etc/profile 命令。
(5)格式化文件系统
hdfs namenode -format
这个执行成功以后,不要二次执行。
(6)集群启动
执行:
start-dfs.sh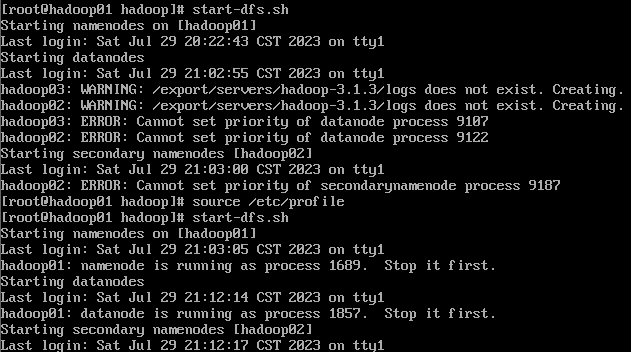
然后3个机器分别 jps 查看进程情况:

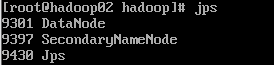
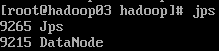
在主节点hadoop01上执行
start-yarn.sh启动resourcemanager和nodemanager:

jps:
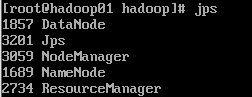
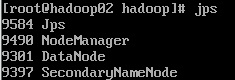
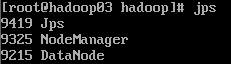
如果想要关闭,输入:
stop-dfs.sh以上hadoop安装配置就完成了。
七、浏览器查看Hadoop集群
(1)修改windows下ip映射
修改 C:\Windows\System32\drivers\etc下的hosts文件,添加以下内容:
192.168.121.221 hadoop01
192.168.121.222 hadoop02
192.168.121.223 hadoop03
这样就可以通过hadoop01、hadoop02、hadoop03这样的域名来访问了。
(2)防火墙关闭
在3台虚拟机上均执行以下命令(一个是临时关闭,一个是开机就关闭即永久关闭,两个命令执行其中一个即可):
systemctl stop firewalld.service
systemctl disable firewalld.service(3)浏览器查看
在浏览器输入:
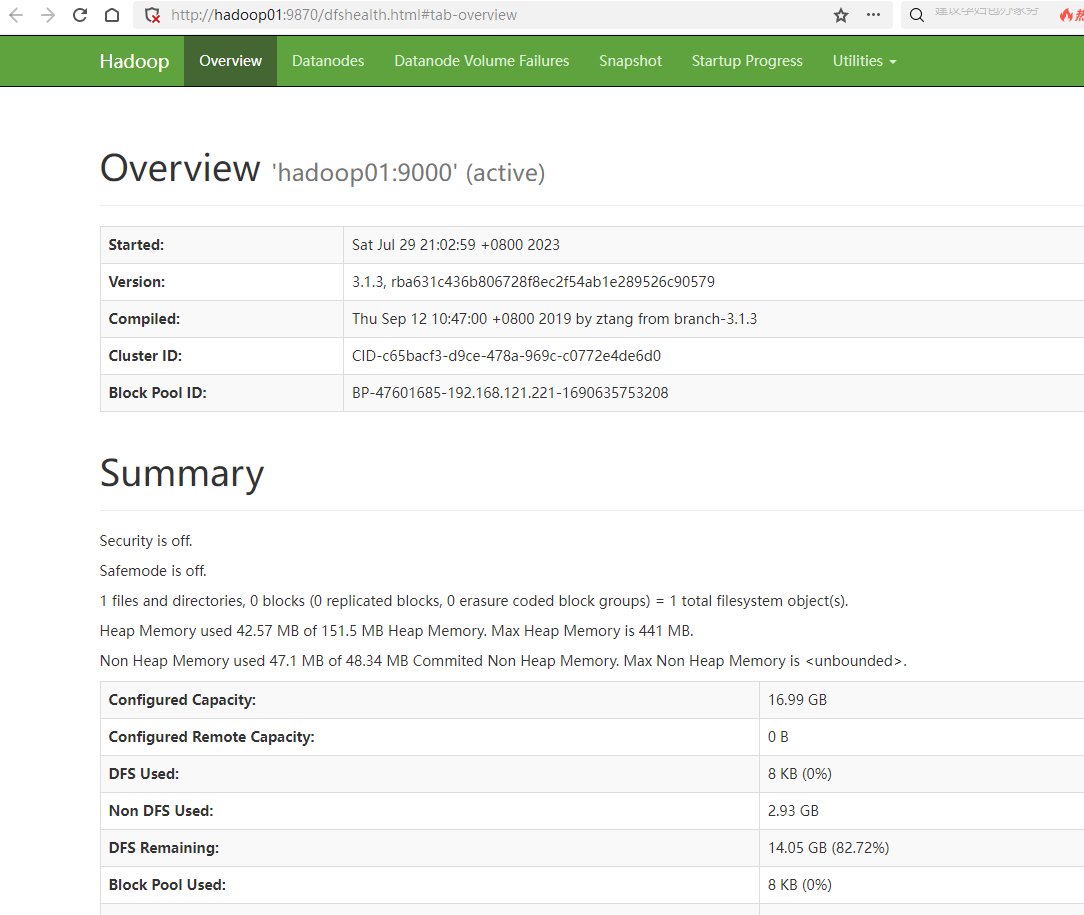
http://hadoop01:9870
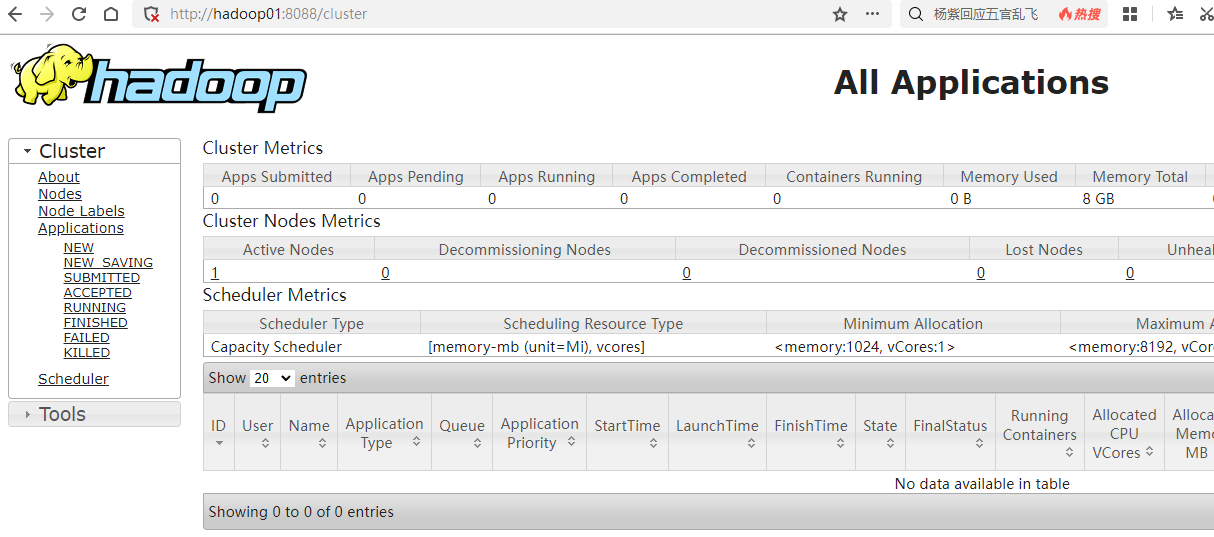
http://hadoop01:8088
即可访问 HDFS 和 Yarn
以上已经将Hadoop集群搭建完毕!
相关文章:
VMware搭建Hadoop集群 for Windows(完整详细,实测可用)
目录 一、VMware 虚拟机安装 (1)虚拟机创建及配置 (2)创建工作文件夹 二、克隆虚拟机 三、配置虚拟机的网络 (1)虚拟网络配置 (2)配置虚拟机 主机名 (3…...

【Rust 基础篇】Rust关联类型:灵活的泛型抽象
导言 Rust是一种以安全性和高效性著称的系统级编程语言,其设计哲学是在不损失性能的前提下,保障代码的内存安全和线程安全。为了实现这一目标,Rust引入了"所有权系统"、"借用检查器"等特性,有效地避免了常见…...

学习笔记21 list
一、概述 有两种不同的方法来实现List接口。ArrayList类使用基于连续内存分配的实现,而LinkedList实现基于linked allocation。 list接口提供了一些方法: 二、The ArrayList and LinkedList Classes 1.构造方法 这两个类有相似的构造方法:…...

微信小程序弱网监控
前言 在真实的项目中,我们为了良好的用户体验,会根据用户当前的网络状态提供最优的资源,例如图片或视频等比较大的资源,当网络较差时,可以提供分辨率更低的资源,能够让用户尽可能快的看到有效信息…...
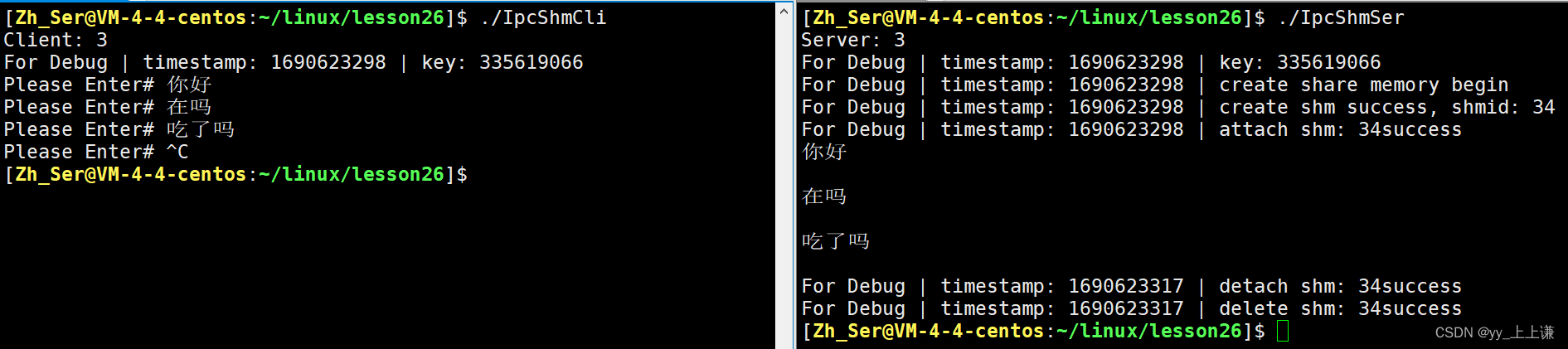
【Linux】进程通信 — 共享内存
文章目录 📖 前言1. 共享内存2. 创建共享内存2.1 ftok()创建key值:2.2 shmget()创建共享内存:2.3 ipcs指令:2.4 shmctl()接口:2.5 shmat()/shmdt()接口:2.6 共享内存没有访问控制:2.7 通过管道对共享内存进…...

“从零开始学习Spring Boot:快速搭建Java后端开发环境“
标题:从零开始学习Spring Boot:快速搭建Java后端开发环境 摘要:本文将介绍如何从零开始学习Spring Boot,并详细讲解如何快速搭建Java后端开发环境。通过本文的指导,您将能够快速搭建一个基于Spring Boot的Java后端开发…...
)
行为型-状态模式(State Pattern)
概述 状态模式是一种行为设计模式,它可以让对象在内部状态改变时改变它的行为。简而言之,状态模式允许对象在不同状态下更改其行为,而不需要通过使用大量的条件语句进行手动更改。 优点: 状态模式将与特定状态相关的行为分散到…...

大厂领导为什么喜欢跨层与下属聊天
作为一个在大厂里面浸淫十几年的loser,平时主要精力没用在技术提升上,对于大厂的人情世故各类八卦倒是研究的透彻。 如果你细心观察,会发现一些大的公司里面,领导喜欢跨层与下属去沟通聊天,我待过几家比较大的公司&am…...
三)
Android 面试题 避免OOM(内存优化)三
🔥 OOM介绍(out of memory 内存溢出)🔥 Android和java中都会出现由于不良代码引起的内存泄露,为了使Android应用程序能够快速高效的运行,Android每个应用程序都会有专门Dalvik虚拟机实例来运行,…...

SpringBoot集成Lock4j 底层使用Redission 实现分布锁
Lock4j 在分布式系统中,实现锁的功能对于保证数据一致性和避免并发冲突是非常重要的。Lock4j是一个简单易用的分布式锁框架,而Redisson是一个功能强大的分布式解决方案,可以与Lock4j进行集成。 操作步骤 第一步:添加依赖 首先&…...

TortoiseSVN操作使用
说明 SVN常用于程序代码版本控制,由于业务需求需将生产资料通过SVN进行管控,涉及人员众多,权限分支管理需要细化,特此记录SVN的学习操作. 前言 版本控制是管理信息修改的艺术,它一直是程序员最重要的工具,程序员经常会花时间作出小的修改, 然…...

第五篇-ChatGLM2-6B模型下载
下载chatglm2-6b模型文件 https://huggingface.co/THUDM/chatglm2-6b方法一:huggingface页面直接点击下载 一个一个下载,都要下载方法二:snapshot_download下载文件 可以使用如下代码下载 创建下载环境 conda create --name hfhub pytho…...
)
【Matlab】基于长短期记忆网络的数据分类预测(Excel可直接替换数据)
【Matlab】基于长短期记忆网络的数据分类预测(Excel可直接替换数据) 1.模型原理2.数学公式3.文件结构4.Excel数据5.分块代码6.完整代码7.运行结果1.模型原理 “基于长短期记忆网络的数据分类预测”是一种利用长短期记忆网络(Long Short-Term Memory, LSTM)进行数据分类任务…...

C++网络编程 TCP套接字基础知识,利用TCP套接字实现客户端-服务端通信
1. TCP 套接字编程流程 1.1 概念 流式套接字编程针对TCP协议通信,即是面向对象的通信,分为服务端和客户端两部分。 1.2 服务端编程流程: 1)加载套接字库(使用函数WSAStartup()),创建套接字&…...

苍穹外卖-day07
苍穹外卖-day07 本项目学自黑马程序员的《苍穹外卖》项目,是瑞吉外卖的Plus版本 功能更多,更加丰富。 结合资料,和自己对学习过程中的一些看法和问题解决情况上传课件笔记 视频:https://www.bilibili.com/video/BV1TP411v7v6/?sp…...

简化Java单元测试数据
用EasyModeling简化Java单元测试 EasyModeling 是我在2021年圣诞假期期间开发的一个 Java 注解处理器,采用 Apache-2.0 开源协议。它可以帮助 Java 单元测试的编写者快速构造用于测试的数据模型实例,简化 Java 项目在单元测试中准备测试数据的工作&…...

P1041 [NOIP2003 提高组] 传染病控制
题目 题目背景 本题是错题,后来被证明没有靠谱的多项式复杂度的做法。测试数据非常的水,各种玄学-做法都可以通过,不代表算法正确。因此本题题目和数据仅供参考。 近来,一种新的传染病肆虐全球。蓬莱国也发现了零星感染者&#…...

TypeScript -- 基础类型
文章目录 TypeScript -- 基础类型let 和 const基本类型写法布尔类型 -- boolean数字类型 -- number字符串类型 -- string数组类型元组类型枚举类型 -- enum任意类型 -- any空值 -- voidNull 和 Undefined不存在的类型 -- never对象 -- object类型断言 TypeScript – 基础类型 1…...

Cookie 与 Session 的作用及区别、结合使用
Cookie的作用 在网站中,http请求是无状态的。也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户。 Cookie的出现就是为了解决这个问题,第一次登录后服务器返回一些数据(Cookie&a…...

【Redis】面试题
1. 为什么要用缓存 1. 提高系统的读写性能。 2. 减轻数据库的压力,防止大量的请求到达数据库,让数据库压力剧增,拖垮数据库。redis数据存储在内存中,高效的数据结构,读写数据比数据库快。 将热点数据存储在redis当中&…...

App Inventor蓝牙调试避坑指南:从连接失败到数据乱码,一次讲清所有常见问题
App Inventor蓝牙调试避坑指南:从连接失败到数据乱码的实战解决方案在移动应用开发领域,蓝牙通信一直是实现设备间短距离数据交换的核心技术之一。对于使用App Inventor的开发者而言,蓝牙模块提供了无需复杂编码即可实现无线通信的便捷途径。…...

物联网与云技术赋能咖啡后处理:CeriTech 的实时监控系统实践
1. 项目概述:用物联网与云技术重塑咖啡后处理在印尼的咖啡农场里,传统的发酵与干燥过程很大程度上依赖“感觉”和“经验”。一位有经验的农人可能会用手触摸、用鼻子闻,或者根据天气和日照时间来估算发酵是否完成、干燥是否均匀。这种方法固然…...

ARM PMU性能监控单元原理与实践指南
1. ARM PMU性能监控单元概述性能监控单元(PMU)是现代ARM处理器中用于硬件级性能分析的核心组件。它通过一组可编程的硬件计数器,实现对处理器内部各种关键事件的精确测量。这些事件涵盖了从指令执行、缓存访问到内存子系统行为等处理器活动的…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

FeHelper前端助手:30+开发工具集,让你的浏览器变身效率神器
FeHelper前端助手:30开发工具集,让你的浏览器变身效率神器 【免费下载链接】FeHelper 😍FeHelper--Web前端助手(Awesome!Chrome & Firefox & MS-Edge Extension, All in one Toolbox!) 项目地址:…...

基于MaixCam的延时摄影系统:从硬件选型到Python编程全解析
1. 项目概述:用MaixCam打造你的专属延时摄影工坊延时摄影,这个听起来有点专业、甚至带点“魔法”色彩的词,其实离我们并不遥远。想想看,把一朵花从含苞到绽放的几天时间,压缩成十几秒的惊艳绽放;或者把一座…...

光轮智能 谢晨 访谈总结机器人仿真数据产业
光轮智能 谢晨 访谈总结机器人仿真关于创始人关于数据数据金字塔数据痛点仿真数据的重要性仿真数据的质量b站链接地址公司官网关于创始人 清华物理;哥伦比亚金融;英伟达智驾仿真;小鹏智驾仿真;现为光轮智能CEO 关于数据 数据的…...

独立站内容分层:一层给 SEO,一层给 GEO
你的内容在喂两个完全不同的"阅读者" 你的博客文章,从来都不只有一个读者。 传统认知里,独立站内容的读者只有两类:真人访客和搜索引擎爬虫。SEO 优化的一切工作,本质上都是在讨好后者,顺带服务前者。 但…...

为Claude Code配置稳定API源并解决访问限制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置稳定API源并解决访问限制 Claude Code 作为一款强大的 AI 编程辅助工具,其原生服务在某些情况下可能…...

<背包问题>
背包问题是一类组合优化问题,其基本形式是给定一组物品,每个物品都有一个重量和一个价值,以及一个有限的背包容量,目标是在不超过背包容量的前提下,选择物品使得背包中的物品价值最大化。动态规划是解决背包问题的常用…...