使用SVM模型完成分类任务
SVM,即支持向量机(Support Vector Machine),是一种常见的机器学习算法,用于分类和回归分析。SVM的基本思想是将数据集映射到高维空间中,在该空间中找到一个最优的超平面,将不同类别的数据点分开。这个最优的超平面可以最大化不同类别数据点之间的间隔,从而使得分类的边界更加鲁棒和稳定。在实际应用中,SVM的核函数可以使用不同的变换,包括线性核、多项式核和径向基函数(RBF)核等,以适应不同的数据类型和特征空间。SVM算法在分类和回归问题上都具有很好的表现,并且具有较强的泛化能力和鲁棒性。
SVM本身是一个二值分类器,最初是为二分类问题设计的,也就是回答Yes或者是No。而实际上我们要解决的问题,可能是多分类的情况,比如对文本进行分类,或者对图像进行识别。针对这种情况,我们可以将多个二分类器组合起来形成一个多分类器,常见的方法有“一对多法”和“一对一法”两种。
1.一对多法
假设我们要把物体分成A、B、C、D四种分类,那么我们可以先把其中的一类作为分类1,其他类统一归为分类2。这样我们可以构造4种SVM,分别为以下的情况:
(1)样本A作为正集,B,C,D作为负集;
(2)样本B作为正集,A,C,D作为负集;
(3)样本C作为正集,A,B,D作为负集;
(4)样本D作为正集,A,B,C作为负集。
这种方法,针对K个分类,需要训练K个分类器,分类速度较快,但训练速度较慢,因为每个分类器都需要对全部样本进行训练,而且负样本数量远大于正样本数量,会造成样本不对称的情况,而且当增加新的分类,比如第K+1类时,需要重新对分类器进行构造。
2.一对一法
一对一法的初衷是想在训练的时候更加灵活。我们可以在任意两类样本之间构造一个SVM,这样针对K类的样本,就会有C(k,2)类分类器。
比如我们想要划分A、B、C三个类,可以构造3个分类器:
(1)分类器1:A、B;
(2)分类器2:A、C;
(3)分类器3:B、C。
当对一个未知样本进行分类时,每一个分类器都会有一个分类结果,即为1票,最终得票最多的类别就是整个未知样本的类别。这样做的好处是,如果新增一类,不需要重新训练所有的SVM,只需要训练和新增这一类样本的分类器。而且这种方式在训练单个SVM模型的时候,训练速度快。上面介绍了SVM的相关概念,在实际应用中,如果要使用SVM完成分类问题,实际包含5步骤
-
收集数据:收集用于分类的数据集,并将每个数据点标记为其相应的类别。
-
特征选择和数据预处理:选择用于分类的特征,对数据进行预处理,如归一化、缩放或标准化等,以便在训练模型之前使数据更具有可比性和可解释性。
-
分割训练集和测试集:将数据集分为训练集和测试集,以便训练模型并评估其性能。
-
训练模型:使用训练集训练SVM模型,并选择适当的核函数和参数。
-
模型评估:使用测试集评估模型的性能,并根据需要调整模型参数和核函数。
-
应用模型:使用训练好的SVM模型对新数据进行分类,预测其类别,并根据预测结果进行相应的决策或操作。
下面是使用Skitlearn提供的函数,采用SVM模型完成分类任务的demo代码。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import make_pipeline# Load the iris dataset
iris = datasets.load_iris()# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(iris.data,iris.target,test_size=0.3,random_state=42)# Create a pipeline that standardizes the data and applies an RBF kernel SVM
pipeline = make_pipeline(StandardScaler(), SVC(kernel='rbf'))# Train the pipeline on the training data
pipeline.fit(X_train, y_train)# Use the trained pipeline to make predictions on the testing data
y_pred = pipeline.predict(X_test)# Calculate the accuracy of the pipeline
accuracy = accuracy_score(y_test, y_pred)print(f"Accuracy: {accuracy}")在上面的demo代码中,make_pipeline(StandardScaler, SVC(kernel='rbf'))中传入的核函数,SVC是Support Vector Classification的缩写,SVC的构造函数:model = svm.SVC(kernel=‘rbf’, C=1.0, gamma=‘auto’),这里有三个重要的参数kernel、C和gamma。kernel代表核函数的选择,它有四种选择,只不过默认是rbf,即高斯核函数。
-
linear:线性核函数
-
poly:多项式核函数
-
rbf:高斯核函数(默认)
-
sigmoid:sigmoid核函数
这四种函数代表不同的映射方式,线性核函数,是在数据线性可分的情况下使用的,运算速度快,效果好。不足在于它不能处理线性不可分的数据。多项式核函数可以将数据从低维空间映射到高维空间,但参数比较多,计算量大。高斯核函数同样可以将样本映射到高维空间,但相比于多项式核函数来说所需的参数比较少,通常性能不错,所以是默认使用的核函数。sigmoid经常用在神经网络的映射中。因此当选用sigmoid核函数时,SVM实现的是多层神经网络。
上面的Demo是比较简单的一个例子,下面再来看一个稍微复杂的Demo例子。下面这个例子多了数据处理和特征选择的过程,相比较上面的例子,最终还是生成一份特性矩阵和lable的数据。
# -*- coding: utf-8 -*-
# 乳腺癌诊断分类
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn import metrics
from sklearn.preprocessing import StandardScaler# 加载数据集,你需要把数据放到目录中
data = pd.read_csv("./breast_cancer_data/data.csv")# 数据探索
# 因为数据集中列比较多,我们需要把dataframe中的列全部显示出来
pd.set_option('display.max_columns', None)
print(data.columns)
print(data.head(5))
print(data.describe())# 将特征字段分成3组
features_mean = list(data.columns[2:12])
features_se = list(data.columns[12:22])
features_worst = list(data.columns[22:32])# 数据清洗
# ID列没有用,删除该列
data.drop("id", axis=1, inplace=True)
# 将B良性替换为0,M恶性替换为1
data['diagnosis'] = data['diagnosis'].map({'M': 1, 'B': 0})# 将肿瘤诊断结果可视化
sns.countplot(data['diagnosis'], label="Count")
plt.show()
# 用热力图呈现features_mean字段之间的相关性
corr = data[features_mean].corr()
plt.figure(figsize=(14, 14))
# annot=True显示每个方格的数据
sns.heatmap(corr, annot=True)
plt.show()# 特征选择
features_remain = ['radius_mean', 'texture_mean', 'smoothness_mean', 'compactness_mean','symmetry_mean', 'fractal_dimension_mean'
]# 抽取30%的数据作为测试集,其余作为训练集
train, test = train_test_split(data,test_size=0.3) # in this our main data is splitted into train and test
# 抽取特征选择的数值作为训练和测试数据
train_X = train[features_remain]
train_y = train['diagnosis']
test_X = test[features_remain]
test_y = test['diagnosis']# 采用Z-Score规范化数据,保证每个特征维度的数据均值为0,方差为1
ss = StandardScaler()
train_X = ss.fit_transform(train_X)
test_X = ss.transform(test_X)# 创建SVM分类器
model = svm.SVC()
# 用训练集做训练
model.fit(train_X, train_y)
# 用测试集做预测
prediction = model.predict(test_X)
print('准确率: ', metrics.accuracy_score(prediction, test_y))原始数据Data.csv是一份检测乳腺癌特征值的数据,其中Diagnosis为M表示阳性,为B表示阴性。 后面的字段都是特征值,每种特征值包含mean,se,worst三种情况,上面的demo代码中选取了mean作为特性字段,对数据进行降维处理。

相关文章:
使用SVM模型完成分类任务
SVM,即支持向量机(Support Vector Machine),是一种常见的机器学习算法,用于分类和回归分析。SVM的基本思想是将数据集映射到高维空间中,在该空间中找到一个最优的超平面,将不同类别的数据点分开…...

计算机毕设 深度学习实现行人重识别 - python opencv yolo Reid
文章目录 0 前言1 课题背景2 效果展示3 行人检测4 行人重识别5 其他工具6 最后 0 前言 🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉…...

开发经验分享之:import引入包和@Autowired注入类有什么区别
大家好,我是三叔,很高兴这期又和大家见面了,一个奋斗在互联网的打工人。 import 和 Autowired 想必大家在 Java 开发中使用频率最多的关键字之一了把,这篇博客将解释这两个概念的区别和作用,帮助你更好地理解它们在Ja…...

MySQL和Oracle区别
由于SQL Server不常用,所以这里只针对MySQL数据库和Oracle数据库的区别 (1) 对事务的提交 MySQL默认是自动提交,而Oracle默认不自动提交,需要用户手动提交,需要在写commit;指令或者点击commit按钮 (2) 分页查询 MySQL是直接在SQL…...

QT--day6(人脸识别、图像处理)
人脸识别: /***********************************************************************************头文件****************************************************************************************/#ifndef WIDGET_H #define WIDGET_H#include <QWidget>…...

深度学习:常用优化器Optimizer简介
深度学习:常用优化器Optimizer简介 随机梯度下降SGD带动量的随机梯度下降SGD-MomentumSGDWAdamAdamW 随机梯度下降SGD 梯度下降算法是使权重参数沿着整个训练集的梯度方向下降,但往往深度学习的训练集规模很大,计算整个训练集的梯度需要很大…...

【算法心得】二维dp的状态转移狂练
LCS: LCS变式:使两个字符串变成一样的,删除的和最小 https://leetcode.cn/problems/minimum-ascii-delete-sum-for-two-strings/ 建表 m ∗ n m*n m∗n or ( m 1 ) ∗ ( n 1 ) (m1)*(n1) (m1)∗(n1)? 感觉 ( m 1 ) ∗ ( n …...
JMeter常用内置对象:vars、ctx、prev
在前文 Beanshell Sampler 与 Beanshell 断言 中,初步阐述了JMeter beanshell的使用,接下来归集整理了JMeter beanshell 中常用的内置对象及其使用。 注:示例使用JMeter版本为5.1 1. vars 如 API 文档 所言,这是定义变量的类&a…...
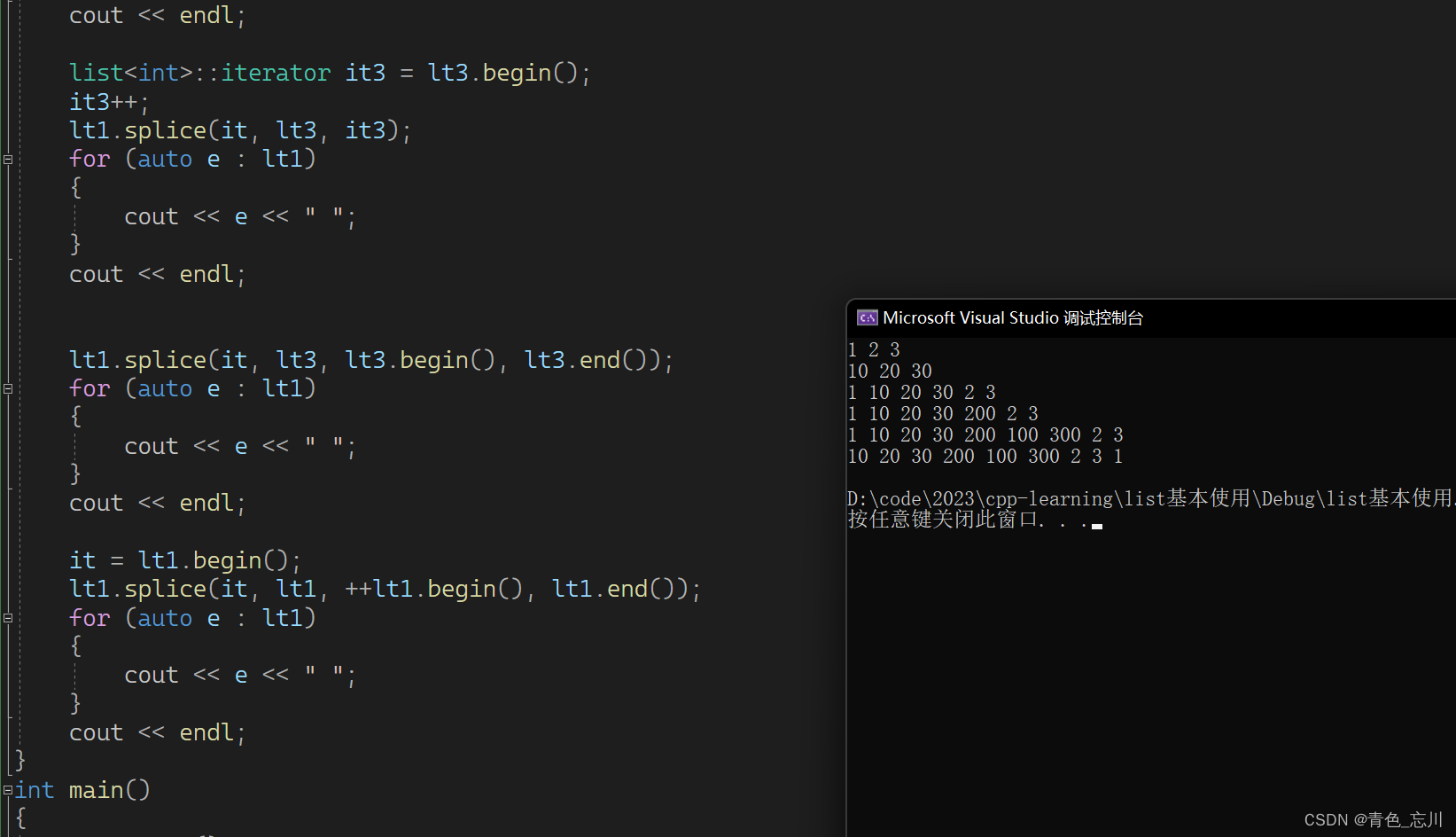
【C++从0到王者】第十四站:list基本使用及其介绍
文章目录 一、list基本介绍二、list基本使用1.尾插头插接口使用2.insert接口使用3.查找某个值所在的位置4.erase接口使用以及迭代器失效5.reverse6.sort7.merge8.unique9.remove11.splice 三、list基本使用完整代码 一、list基本介绍 如下所示,是库里面对list的基本…...

正则表达式、常用的正则
文章目录 正则表达式字符含意义RegExp函数RegExp属性RegExp对象方法RegExp构造函数的第二个参数 常用的正则例子只包含数字(包括正数、负数、零)只包含中英文数字及键盘上的特殊字符校验密码是否符合规则的正则校验http或者https端口号的正则只校验端口号…...
ST官方基于米尔STM32MP135开发板培训课程(一)
本文将以Myirtech的MYD-YF13X以及STM32MP135F-DK为例,讲解如何使用STM32CubeMX结合Developer package实现最小系统启动。 1.开发准备 1.1 Developer package准备 a.Developer package下载: https://www.st.com/en/embedded-software/stm32mp1dev.ht…...
组件(lvs,keeplive,orm,mysql,分布式事务)
lvs LVS 已经集成到Linux内核系统中,ipvsadm 是 LVS 的命令行管理工具。 目前有三种 IP 负载均衡技术( VS/NAT 网络地址转换 、VS/TUN IP 隧道技术实现虚拟服务器 和 VS/DR 直接路由); 八种调度算法:轮询 …...

《视觉SLAM十四讲》报错信息和解决方案
文章目录 ch4-Sophus编译报错ch5/imageBasics安装opencv4.x报错ch5/joinMap/CMakeLists.txt编译报错ch5/joinMap-pcl_viewer map.pcd报错 ch4-Sophus编译报错 报错信息: error: lvalue required as left operand of assignmentunit_complex_.real() 1.;^~ error:…...

golang 设置http请求代理
tinypoxy 搭建http代理服务可参考:tinyproxy搭建http代理_wangxiaoangg的博客-CSDN博客 需求背景: 项目需要访问一国外服务接口,地址被墙。购买香港ecs服务器,并在上面搭建http代理服务。 一 使用http和https代理 func main() {pr…...
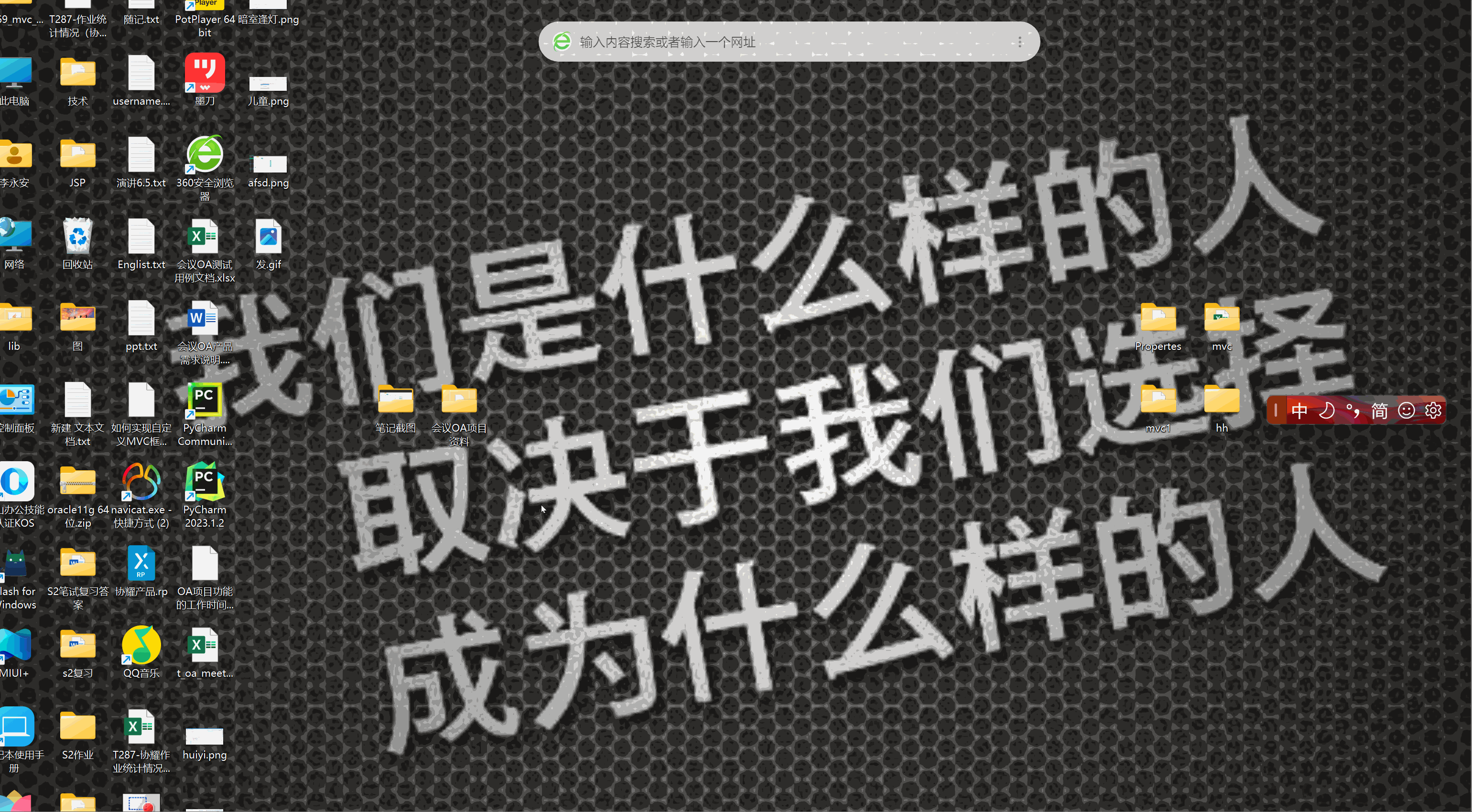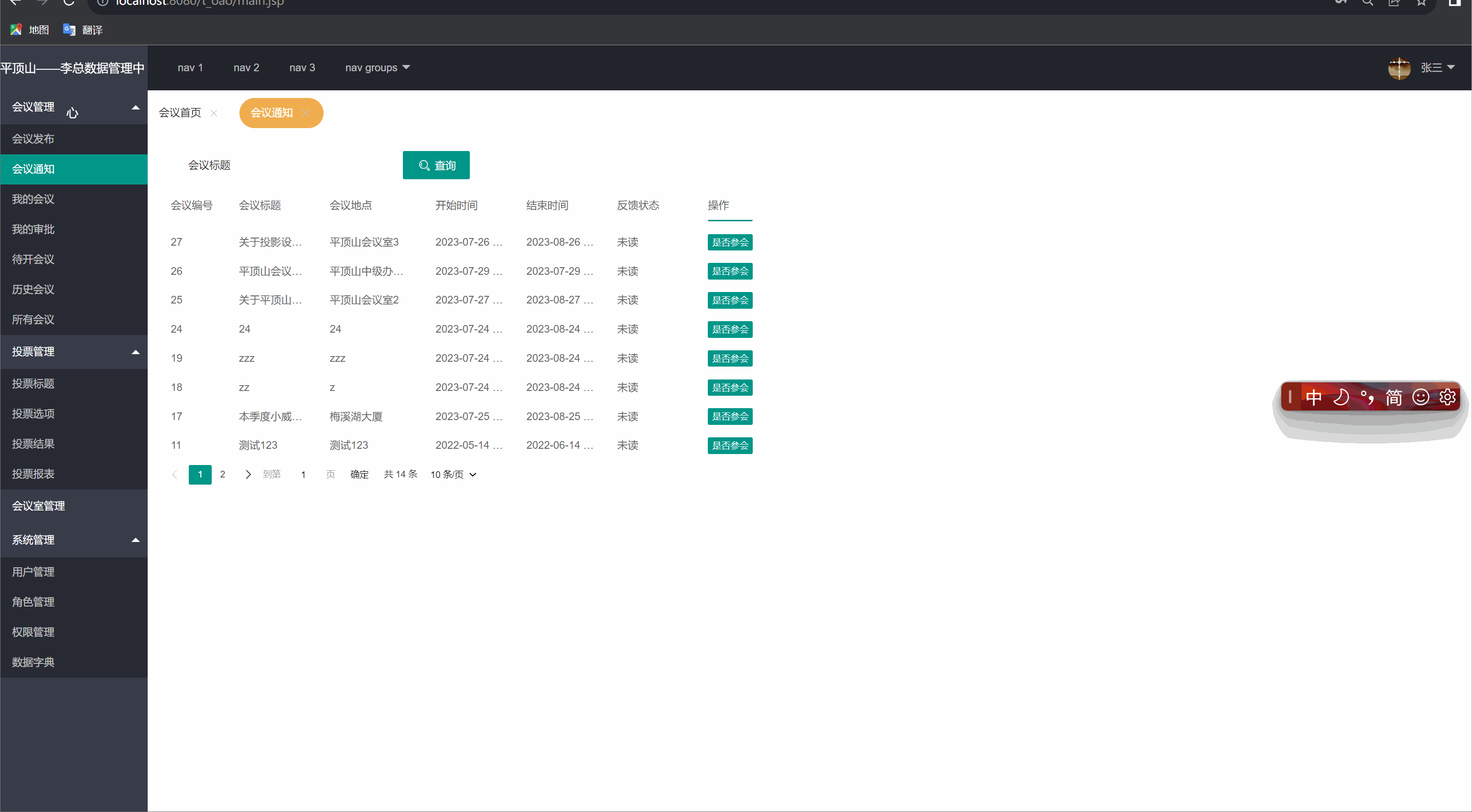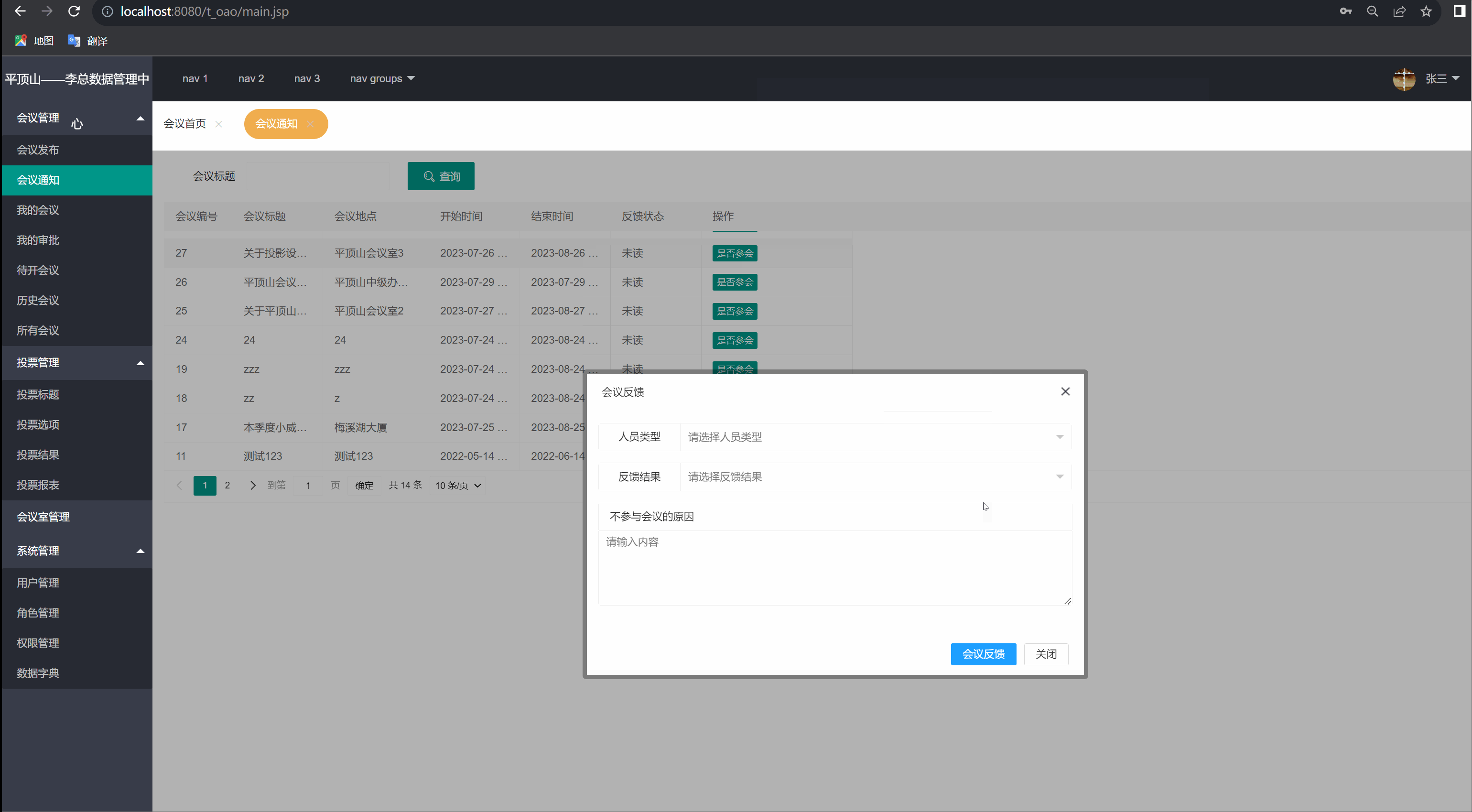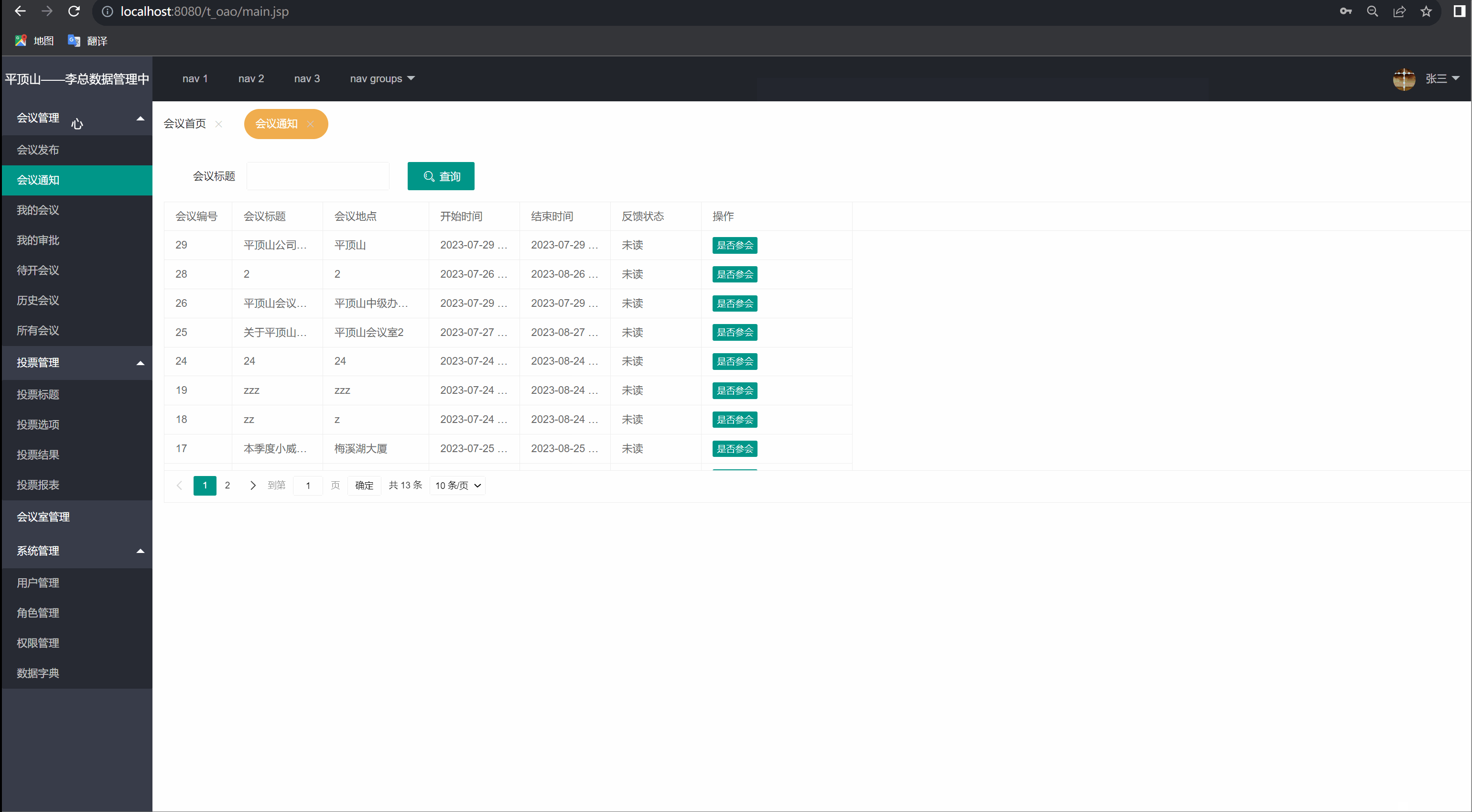
我的会议(会议通知)
前言: 我们在实现了发布会议功能,我的会议功能的基础上,继续来实现会议通知的功能。 4.1实现的特色功能: 当有会议要参加时,通过查询会议通知可以知道会议的内容,以及当前会议状态(未读) 4.2思路…...

css实现水平居中
代码示例 <div class"box"><div class"box1"></div> </div>1.弹性布局:(推荐) display:flex; 这些要添加在父级的,是父级的属性 //父级添加display:flex; //父级添加jus…...
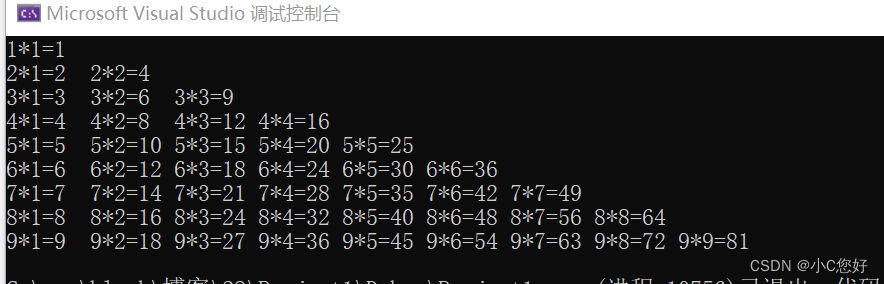
c刷题(一)
目录 1.输出100以内3的倍数 2.将3个数从大到小输出 3.打印100~200素数 方法一 方法二 4.显示printf的返回值 最大公约数 试除法 辗转相除法 九九乘法表 求十个数的最大值 1.输出100以内3的倍数 法一: int n 0; while (n*3 < 100){printf("%d &q…...

webpack
文章目录 webpack概念打包的场景为什么要打包在打包之外 - 翻译在打包之外 - 小动作 课程重点模块化利用立即执行函数来改变 作用域模块化的优点模块化方案的进化史AMD(成型比较早,应用不是很广泛)COMMONJSES6 MODULE webpack 的打包机制webp…...

反复 Failed to connect to github.com port 443 after xxx ms
前提:使用了代理,浏览器能稳定访问github,但git clone一直超时 解决方案: 1. git config --global http.proxy http://127.0.0.1:1080 2. 代理设置端口1080 3. 1080可自定义 感谢来自这篇博客和评论区的提醒:解决…...

ARM裸机-11
1、安装交叉编译工具工具 1.1、windows中装软件的特点 windows中装软件使用安装包,安装包解压后有两种情况:一种是一个安装文件 (.exe/.msi),双击进行安装,下一步直到安装完毕。安装完毕后会在桌面上生成快捷方式,我们平时使用快…...

c++ 端口扫描程序实现案例
第一、原理端口扫描的原理很简单,就是建立socket通信,切换不通端口,通过connect函数,如果成功则代表端口开发者,否则端口关闭。所有需要多socket程序熟悉,本内容是在window环境下的第二、单线程实现方式123…...

企业AI Agent安全防护体系
企业AI Agent安全防护体系:构建智能时代的安全长城 前言:智能革命与安全挑战 当我们站在21世纪第三个十年的门槛上回望,人工智能(AI)的发展速度可谓惊人。从早期的专家系统到今天的大语言模型(LLM),AI已经从实验室走向了企业生产的核心。而在这一波浪潮中,AI Agent(…...

FreeMove:拯救C盘空间的智能文件迁移工具,告别存储焦虑
FreeMove:拯救C盘空间的智能文件迁移工具,告别存储焦虑 【免费下载链接】FreeMove Move directories without breaking shortcuts or installations 项目地址: https://gitcode.com/gh_mirrors/fr/FreeMove 你是否曾因C盘爆满而被迫删除重要文件&…...

LibreOffice Online 终极指南:如何在浏览器中实现免费办公协作
LibreOffice Online 终极指南:如何在浏览器中实现免费办公协作 【免费下载链接】online Read-only Mirror - no pull request (use https://gerrit.libreoffice.org instead) 项目地址: https://gitcode.com/gh_mirrors/onl/online 还在为昂贵的在线办公软件…...

3分钟完成B站缓存视频转换:m4s-converter完整使用指南
3分钟完成B站缓存视频转换:m4s-converter完整使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站视频下架后&…...

避开无感FOC的那些坑:我的STM32F103 SMO观测器调试心得与波形分析
避开无感FOC的那些坑:我的STM32F103 SMO观测器调试心得与波形分析 在无感FOC驱动开发中,观测器的调试往往是整个项目中最具挑战性的环节。当电机出现抖动、观测角度不准或启动失败时,如何快速定位问题并优化参数,成为工程师们必须…...

重塑AI资源管理范式:HAMi异构计算虚拟化的架构革命
重塑AI资源管理范式:HAMi异构计算虚拟化的架构革命 【免费下载链接】HAMi Heterogeneous GPU Sharing on Kubernetes 项目地址: https://gitcode.com/GitHub_Trending/ha/HAMi 在AI计算资源日益紧张的今天,企业面临着一个严峻的挑战:昂…...

ColorBrewer终极指南:快速掌握专业地图配色方案
ColorBrewer终极指南:快速掌握专业地图配色方案 【免费下载链接】colorbrewer 项目地址: https://gitcode.com/gh_mirrors/co/colorbrewer ColorBrewer是一个基于Cynthia Brewer博士研究成果的专业颜色方案工具,专门为地图制图和数据可视化提供科…...
 终极指南:显卡驱动彻底清理解决方案)
Display Driver Uninstaller (DDU) 终极指南:显卡驱动彻底清理解决方案
Display Driver Uninstaller (DDU) 终极指南:显卡驱动彻底清理解决方案 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirrors/di/display-driv…...

【YOLO目标检测全栈实战】36 TensorRT部署实战:YOLOv8n在Jetson Orin上实现5ms推理
上周,我帮一家做无人机巡检的客户部署模型。他们的算法工程师在PC上用ONNX Runtime跑YOLOv8n,推理速度30ms,觉得“挺快”。 结果一上Jetson Orin NX,直接崩到120ms——无人机飞一圈,画面卡得像幻灯片。客户急了:“同样的模型,怎么差这么多?”我看了眼代码,发现他们还…...