深度学习,神经网络介绍
目录
1.神经网络的整体构架
2.神经网络架构细节
3.正则化与激活函数
4.神经网络过拟合解决方法
1.神经网络的整体构架
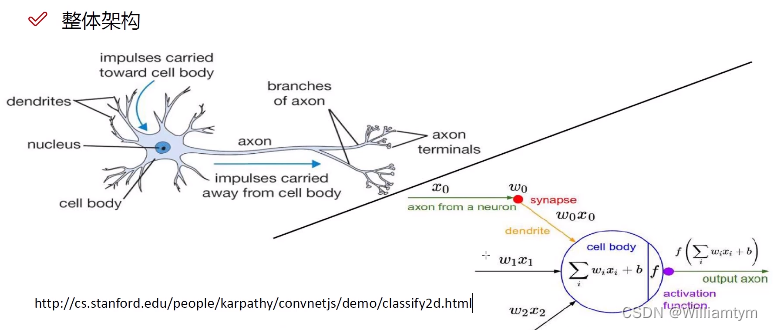
ConvNetJS demo: Classify toy 2D data
我们可以看看这个神经网络的网站,可以用来学习。
神经网络的整体构架如下1:
-
感知器(Perceptron)感知器是所有神经网络中最基本的,也是更复杂的神经网络的基本组成部分。它只连接一个输入神经元和一个输出神经元。
-
前馈(Feed-Forward)网络前馈网络是感知器的集合,其中有三种基本类型的层:输入层、隐藏层和输出层。在每个连接过程中,来自前一层的信号被乘以一个权重,增加一个偏置,然后通过一个激活函数。前馈网络使用反向传播迭代更新参数,直到达到理想的性能。
-
残差网络(Residual Networks/ResNet深层前馈神经网络的一个问题是所谓的梯度消失,即当网络太深时,有用的信息无法在整个网络中反向传播。当更新参。
对于神经网络的整体构架,我们总结为四点:层次结构、神经元、全连接和非线性。
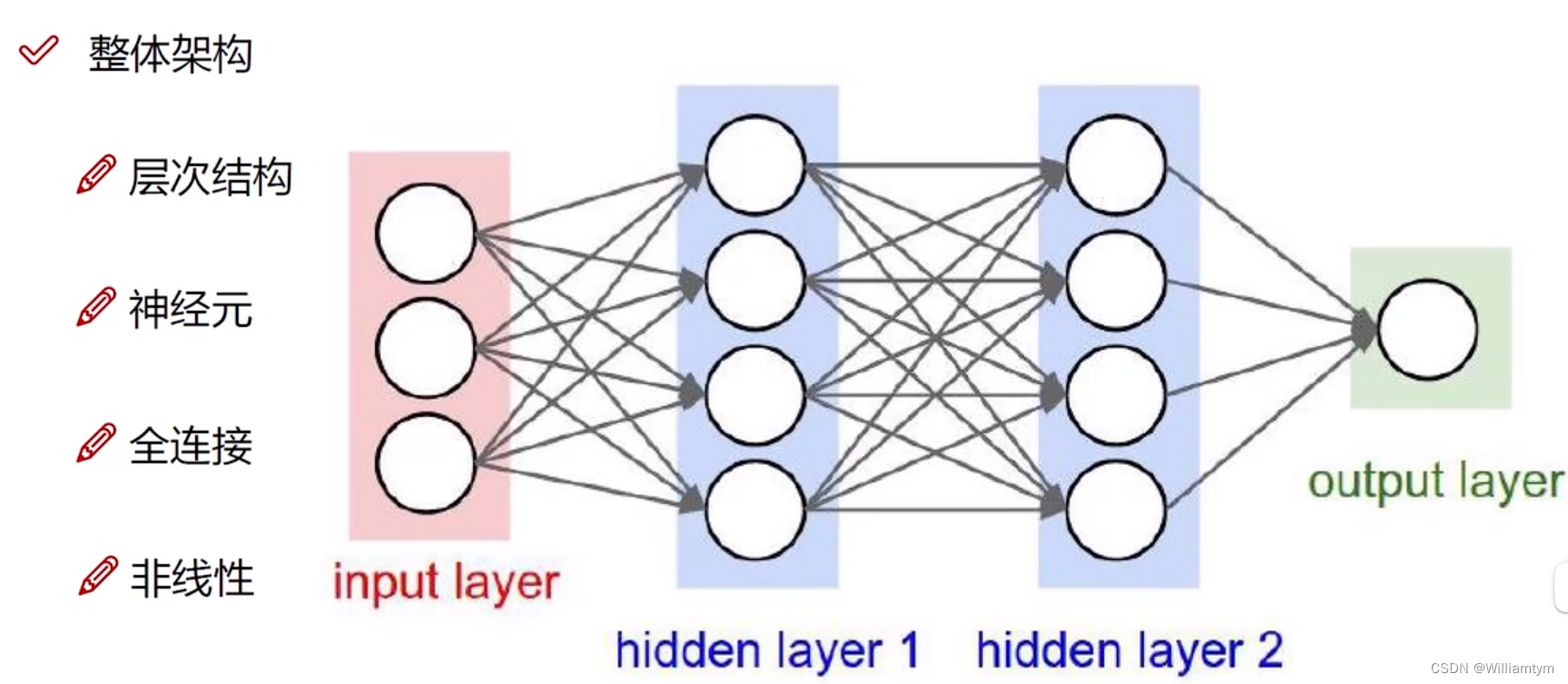
层次结构:
由上图不难看出,在神经网络中神经网络的我们一般分成三个部分:
1:输入层(input layer)
2:隐藏层(hidden layer)
3:输出层(output layer)
ps:要注意的是,中间的隐藏层可以有多层。
神经元:
每个层次中都有许多圆圆的球似的东西,这个东西就是在神经网络中的神经元,就是数据的量或者是矩阵的大小,每一种层次中的神经元中的含量不太一样。
在输入层中的每一个神经元里面是你输入原始数据(一般称为X)的不同特征,比如x为一张图片,这张图片的像素是32323,其中的每一个像素都是它的特征吧,所以有3072个特征对应的输入层神经元个数就是3072个,这些特征以矩阵的形式进行输入的。我们举个例子比如我们的输入矩阵为1*3072(第一维的数字表示一个batch(batch指的是每次训练输入多少个数据)中有多少个输入;第二维数字中的就是每一个输入有多少特征。)
在隐藏层中的每一层神经元表示对x进行一次更新的数据,而每层有几个神经元(比如图中hidden1层中有四个神经元)表示将你的输入数据的特征扩展到几个(比如图中就是四个),就比如你的输入三个特征分别为年龄,体重,身高,而图中hidden1层中第一个神经元中经过变换可以变成这样‘年龄0.1+体重0.4+身高0.5’,而第二个神经元可以表示成‘年龄0.2+体重0.5+身高0.3’,每一层中的神经元都可以有不同的表示形式。
在输出层中的的神经元个数主要取决于你想要让神经网络干什么,比如你想让它做一个10分类问题,输出层的矩阵就可以是’1*10’的矩阵(第一维表示的与输入层表示数字相同,后面10就是10种分类)。
全连接:
我们看到的每一层和下一层中间都有灰色的线,这些线就被称为全连接(因为你看上一层中每个神经元都连接着下一层中的所有神经元),而这些线我们也可以用一个矩阵表示,这个矩阵我们通常称为‘权重矩阵’,用大写的W来表示(是后续我们需要更新的参数)。 权重矩阵W的维数主要靠的是上一层进来数据的输入数据维数和下一层需要输入的维数,可以简单理解为上有一层有几个神经元和下一层有几个神经元,例如图中input layer中有3个神经元,而hidden1 layer中有4个神经元,中的W的维度就为‘3*4’,以此类推。(主要是因为我们全连接层的形式是矩阵运算形式,需要满足矩阵乘法的运算法则。
非线性:
非线性(non-linear),即 变量之间的数学关系,不是直线而是曲线、曲面、或不确定的属性,叫非线性。非线性是自然界的复杂性的典型性质之一;与线性相比,非线性更接近客观事物性质本身,是量化研究认识复杂知识的重要方法之一;凡是能用非线性描述的关系,通称非线性关系。
2.神经网络架构细节
整体构架:
基础构架:f=W2max(0, W1x)
继续堆加一层:f=W3max(0, W2max(0,W1x))
神经网络的强大之处在于用更多的参数来拟合复杂的数据。
神经元个数对结果的影响:
改之前的:
layer_defs = [];
layer_defs.push({type:'input', out_sx:1, out_sy:1, out_depth:2});
layer_defs.push({type:'fc', num_neurons:, activation: 'tanh'});
layer_defs.push({type:'fc', num_neurons:2, activation: 'tanh'});
layer_defs.push({type:'softmax', num_classes:2});
net = new convnetjs.Net();
net.makeLayers(layer_defs);
trainer = new convnetjs.SGDTrainer(net, {learning_rate:0.01, momentum:0.1, batch_size:10, l2_decay:0.001});

layer_defs = [];
layer_defs.push({type:'input', out_sx:1, out_sy:1, out_depth:2});
layer_defs.push({type:'fc', num_neurons:2, activation: 'tanh'});
layer_defs.push({type:'fc', num_neurons:2, activation: 'tanh'});
layer_defs.push({type:'softmax', num_classes:2});
net = new convnetjs.Net();
net.makeLayers(layer_defs);
trainer = new convnetjs.SGDTrainer(net, {learning_rate:0.01, momentum:0.1, batch_size:10, l2_decay:0.001});
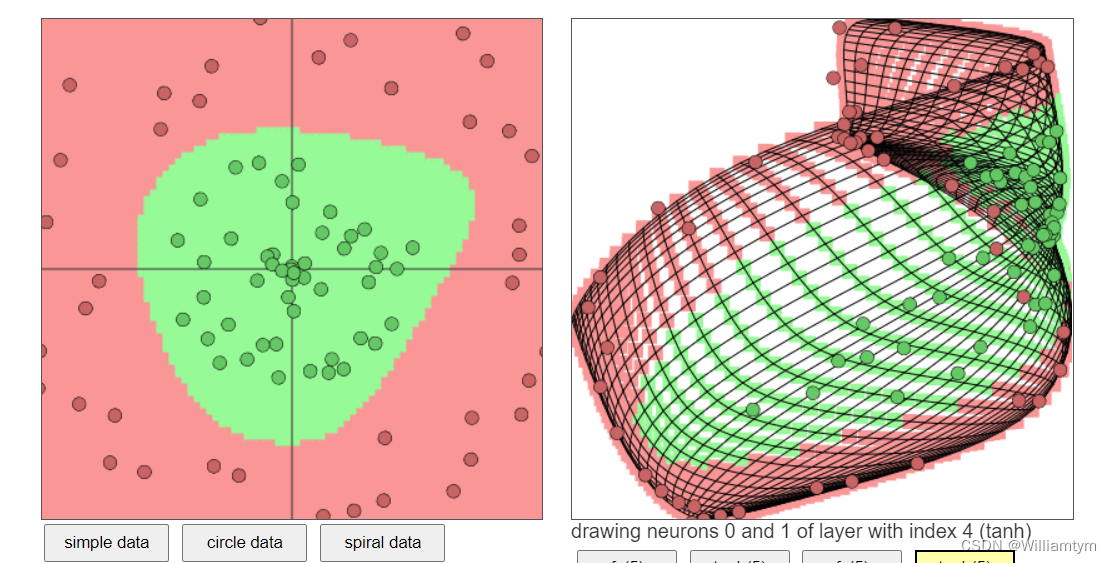
改成2以后的图样
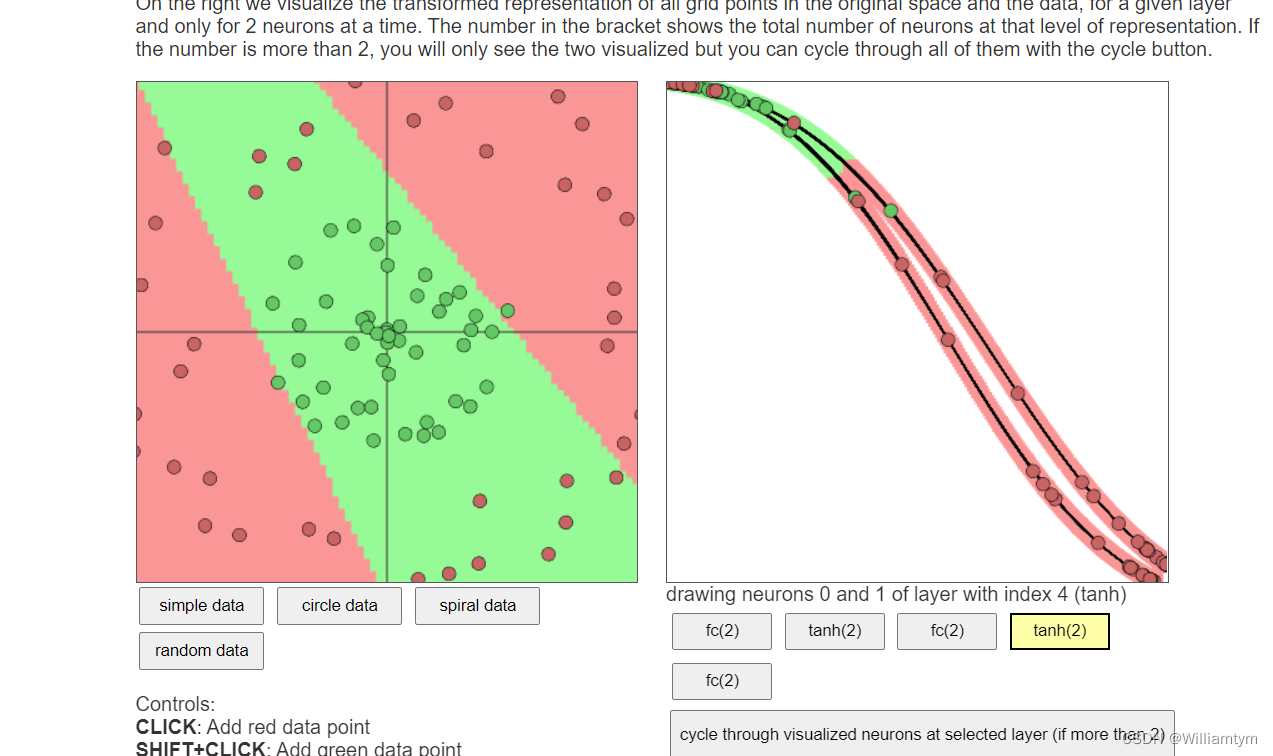
然后神经个数调为5以后的样子:
layer_defs = [];
layer_defs.push({type:'input', out_sx:1, out_sy:1, out_depth:2});
layer_defs.push({type:'fc', num_neurons:5, activation: 'tanh'});
layer_defs.push({type:'fc', num_neurons:5, activation: 'tanh'});
layer_defs.push({type:'softmax', num_classes:2});
net = new convnetjs.Net();
net.makeLayers(layer_defs);
trainer = new convnetjs.SGDTrainer(net, {learning_rate:0.01, momentum:0.1, batch_size:10, l2_decay:0.001});
3.正则化与激活函数
正则化的作用:
机器学习中经常会在损失函数中加入正则项,称之为正则化(Regularize)。防止模型过拟合,也就是说,在损失函数上加上某些规则(限制),缩小解空间,从而减少求出过拟合解的可能性。
激活函数:
常用的激活函数有Sigmoid,Relu,Tanh等,进行相应的非线性变换

激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
学高等数学的时候,在不定积分那一块,有个画曲为直思想来近似求解。那么,我们可以来借鉴一下,用无数条直线去近似接近一条曲线。
4.神经网络过拟合解决方法
参数初始化:
参数初始化是很重要的,通常我们都适用随机策略来进行参数初始化
W = 0.01 * np.random.randn(D, H)
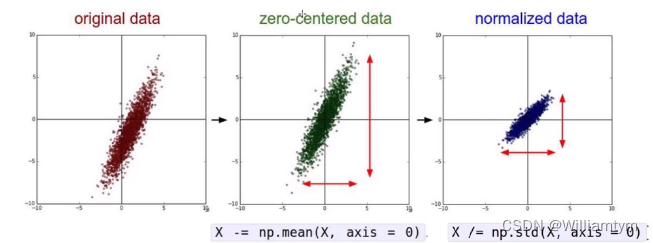
数据预处理:
不同的处理结果会使得模型的效果发生很大的差异
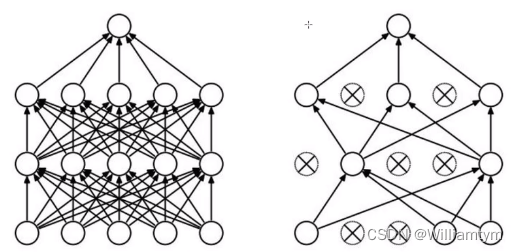
DROP-OUT
这就是传说中的七伤拳
过拟合是神经网络中一个令人非常头疼的大问题
-
一种含义是:在机器学习中,是解决模型过拟合问题的策略。
-
另一种含义是:是dropout技术的实现,让每一层网络的输出被随机选择丢弃一些神经元,这样可以防止梯度消失和爆炸的问题,有助于提升整个网络的泛化能力。

相关文章:
深度学习,神经网络介绍
目录 1.神经网络的整体构架 2.神经网络架构细节 3.正则化与激活函数 4.神经网络过拟合解决方法 1.神经网络的整体构架 ConvNetJS demo: Classify toy 2D data 我们可以看看这个神经网络的网站,可以用来学习。 神经网络的整体构架如下1: 感知器&…...

中国AI大模型峰会“封神之作”!开发者不容错过这场夏季盛会
年度最强大模型顶会来袭!喊话中国数百万AI开发者,速来! 硬核来袭!中国AI大模型峰会“封神之作”,开发者们不容错过! 前瞻大模型发展趋势,紧跟这场大会! 中国科技超级碗,大模型最新前…...
Android Studio多渠道打包
使用环境: Android studio 多渠道打包 使用方法: 1 APP下build.gradle文件 flavorDimensions "default"productFlavors {huawei {dimension "default"manifestPlaceholders [ channel:"huawei" ]}xiaomi {dimension &…...

RK3566 Android11默认客户Launcher修改
前言 客户需要默认自己的Launcher为home,同时保留系统的Launcher3. 解决办法:在启动home应用之前设置一下默认Launcher。查找home app启动相关资料,找到了frameworks/base/services/core/java/com/android/server/wm/RootWindowContainer.java的startHomeOnTaskDisplayA…...

ORB算法在opencv中实现方法
在OPenCV中实现ORB算法,使用的是: 1.实例化ORB orb cv.xfeatures2d.orb_create(nfeatures)参数: nfeatures: 特征点的最大数量 2.利用orb.detectAndCompute()检测关键点并计算 kp,des orb.detectAndCompute(gray,None)参数:…...

vue项目回显文本无法识别换行符
解决方法 1:使用<br/>替换文本中的\n,使用v-html渲染 <template> <div v-html"str"></div> </template> <script> let str 以下内容自动换行\n换行了 // 使用replace截取提换 this.str str.replace(/…...

Minio 部署
minio 官网:https://www.minio.org.cn/ 部署文档:https://www.minio.org.cn/docs/minio/container/operations/install-deploy-manage/deploy-minio-single-node-single-drive.html# 选择自己的部署环境: 我用的docker: docker pull qua…...
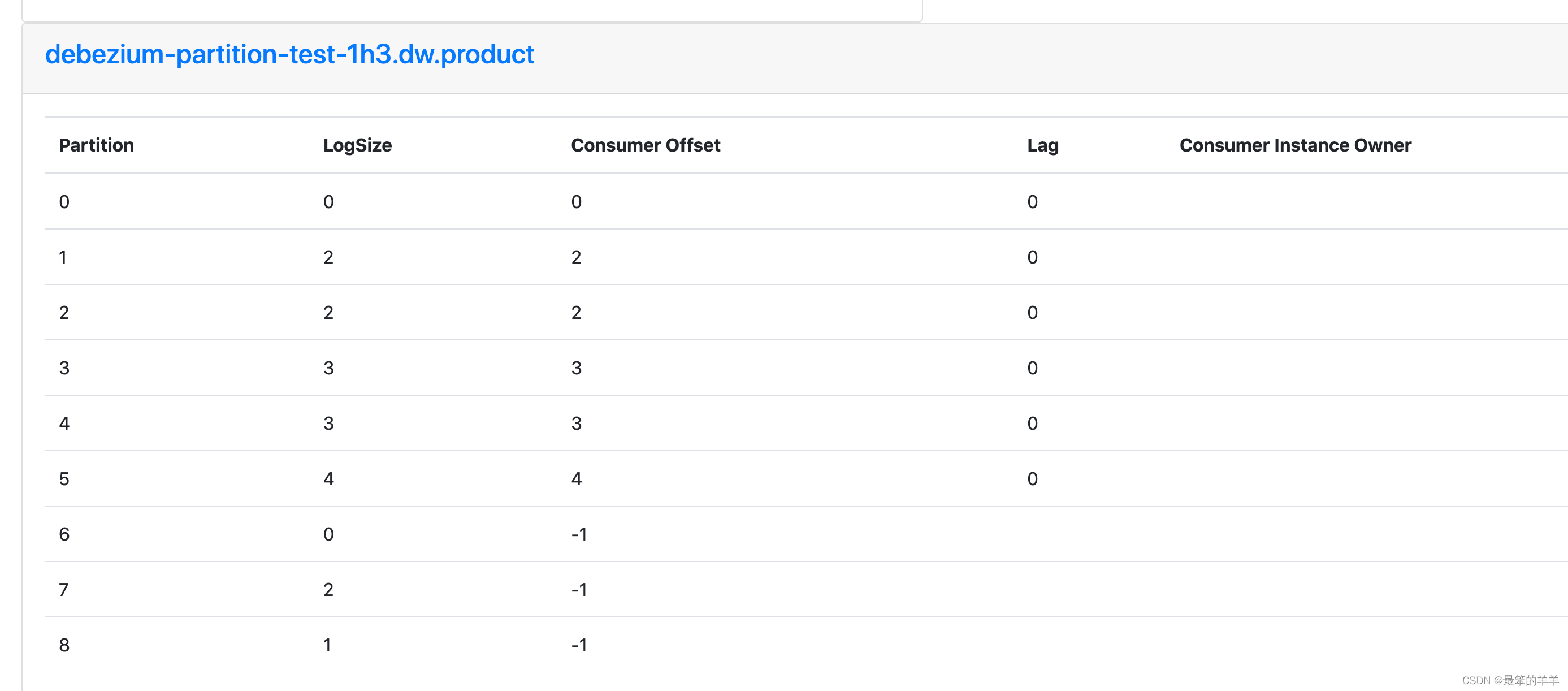
Kafka系列之:记录一次Kafka Topic分区扩容,但是下游flink消费者没有自动消费新的分区的解决方法
Kafka系列之:记录一次Kafka Topic分区扩容,但是下游flink消费者没有自动消费新的分区的解决方法 一、背景二、解决方法三、实现自动发现新的分区一、背景 生产环境Kafka集群压力大,Topic读写压力大,消费的lag比较大,因此通过扩容Topic的分区,增大Topic的读写性能理论上下…...
)
Ansible部署MariaDB galera集群(多主)
文章目录 Ansible部署MariaDB galera集群(多主)介绍节点规划基础环境准备编写剧本文件执行剧本文件查看集群状态测试 Ansible部署MariaDB galera集群(多主) 介绍 MariaDB Galera集群是一套基于同步复制的、多主的MySQL集群解决方案,使用节点没有单点故障ÿ…...

立体库-库龄
split 用法第一种: 1.对单个字符进行分割(注意这里是字符,不是字符串,故只能用单引号‘’) string sabcdeabcdeabcde; string[] sArrays.Split(c) ; foreach(string i in sArray) Console.WriteLine(i.ToString());…...

extern/头文件包含,实现一个函数被两个文件共用
目录 一、extern 1、在a.c文件中定义int add函数 2、在b.c文件中使用extern关键字声明add函数 二、用头文件包含的形式 1、在a.c文件中定义int add函数 2、创建一个名为a.h的头文件,其中包含add函数的函数原型 3、在b.c文件中包含a.c的头文件,并调…...
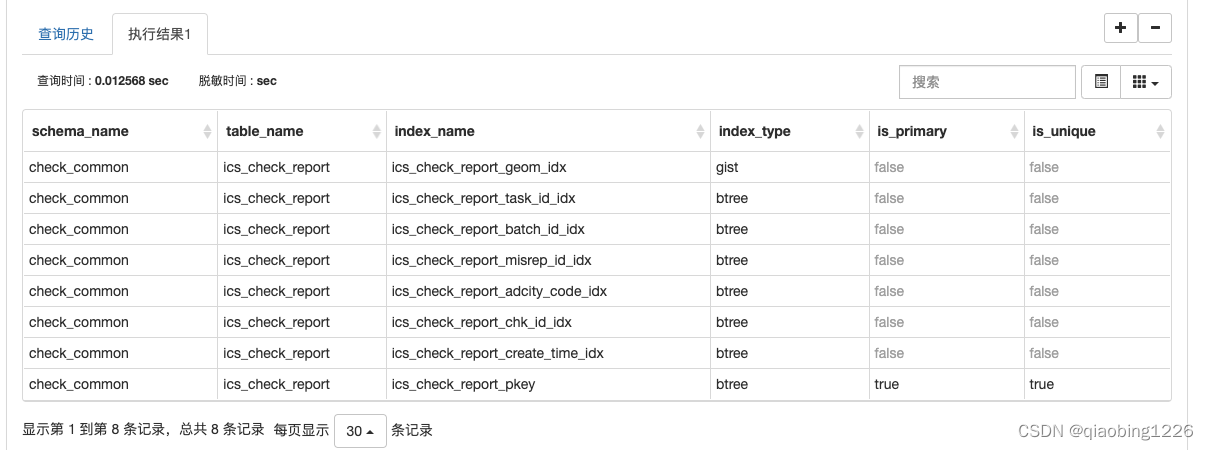
pgsql 查看某个表建立了那些索引sql
执行以下sql: SELECTns.nspname as schema_name,tab.relname as table_name,cls.relname as index_name,am.amname as index_type,idx.indisprimary as is_primary,idx.indisunique as is_unique FROMpg_index idx INNER JOIN pg_class cls ON cls.oididx.indexrel…...

【SCSS】网格布局中的动画
效果 index.html <!DOCTYPE html> <html><head><title> Document </title><link type"text/css" rel"styleSheet" href"index.css" /></head><body><div class"container">&l…...

Docker基础命令(一)
Docker使用1 一、运行终端 打开终端,输入docker images ,如果运行正常,表示docker已经可以在本电脑上使用了 二、docker常用命令 指令说明docker images查看已下载的镜像docker rmi 镜像名称:标签名删除已下载的镜像docker search 镜像从官…...

django4.2 day1Django快速入门
1、创建虚拟环境 打开cmd安装virtualenv pip install virtualenvwrapper-winworkon 查看虚拟环境mkvirtualenv 创建新的虚拟环境删除虚拟环境 rmvirtualenv 进入虚拟环境 workon env 2、创建django虚拟环境并安装django 创建虚拟环境mkvirtualenv django4env进入虚拟环境安…...

linux的exec和system函数介绍及选择
在应用程序中有时候需要调用第三方的应用,这是常见的需求。此时可以使用linux下的exec命令或system命令达到目的。但是这两个该选择哪个呢?有什么区别?下面总结介绍下。 exec和system介绍 在Linux中,exec命令用于在当前进程中执行…...
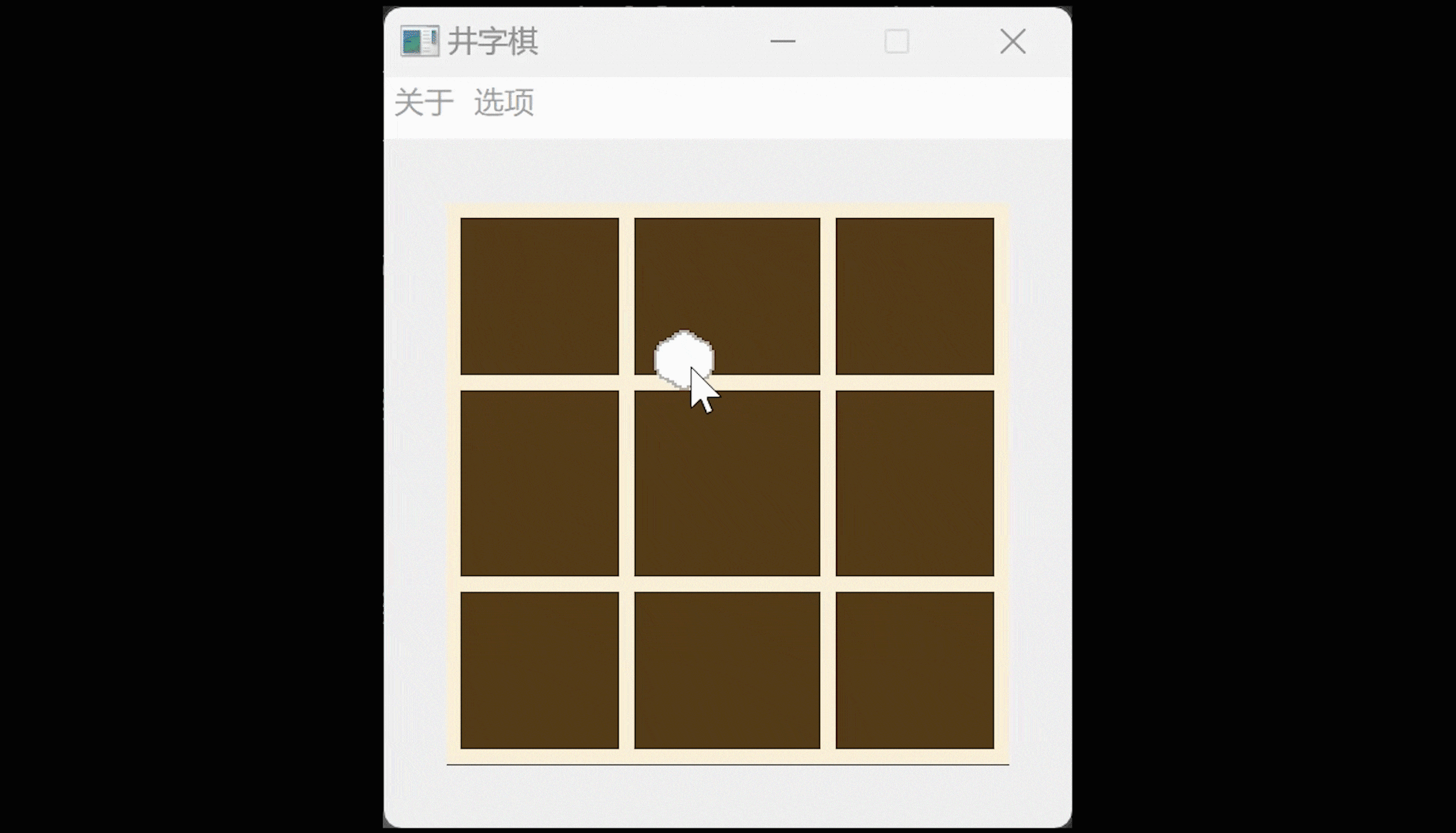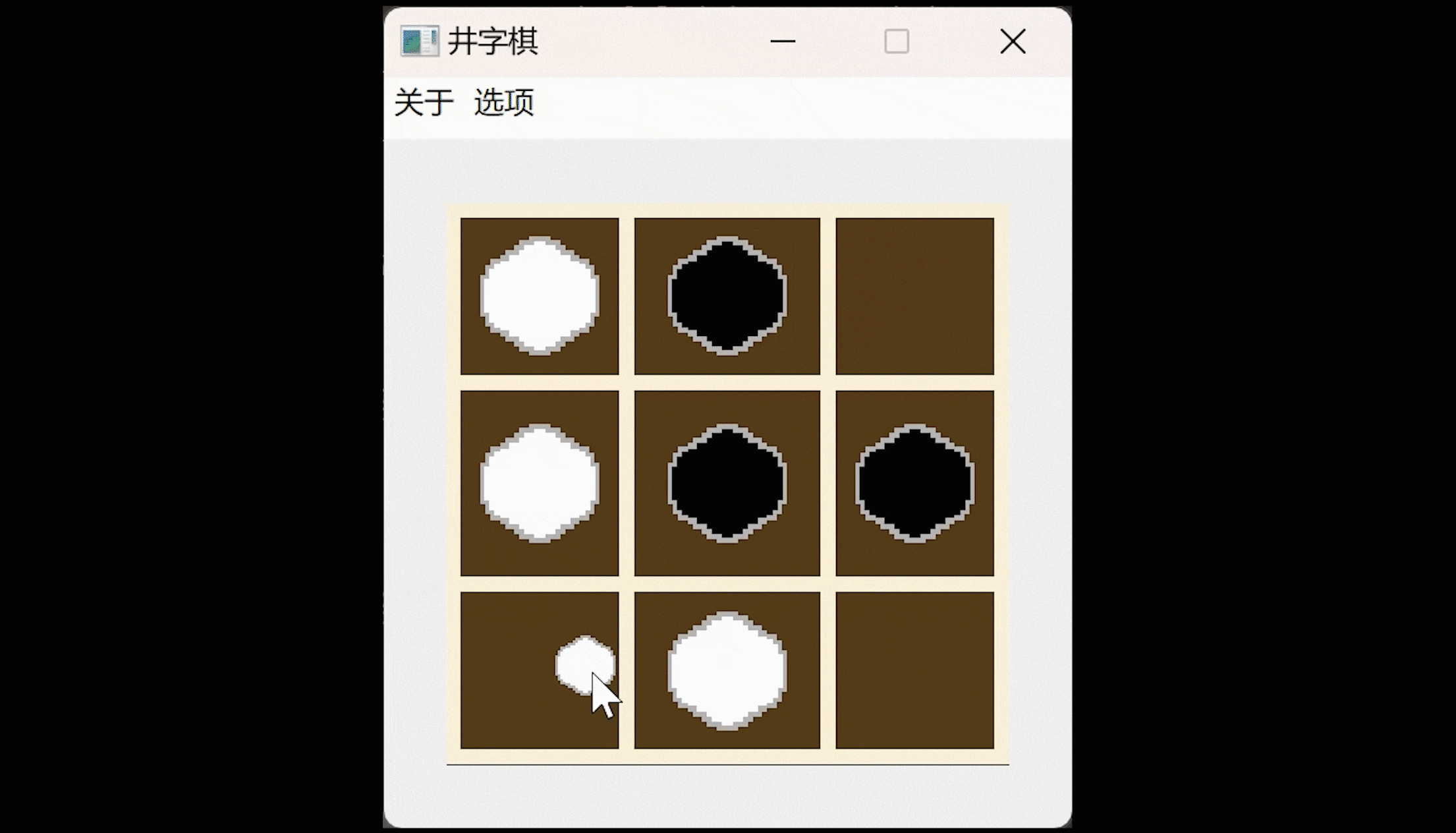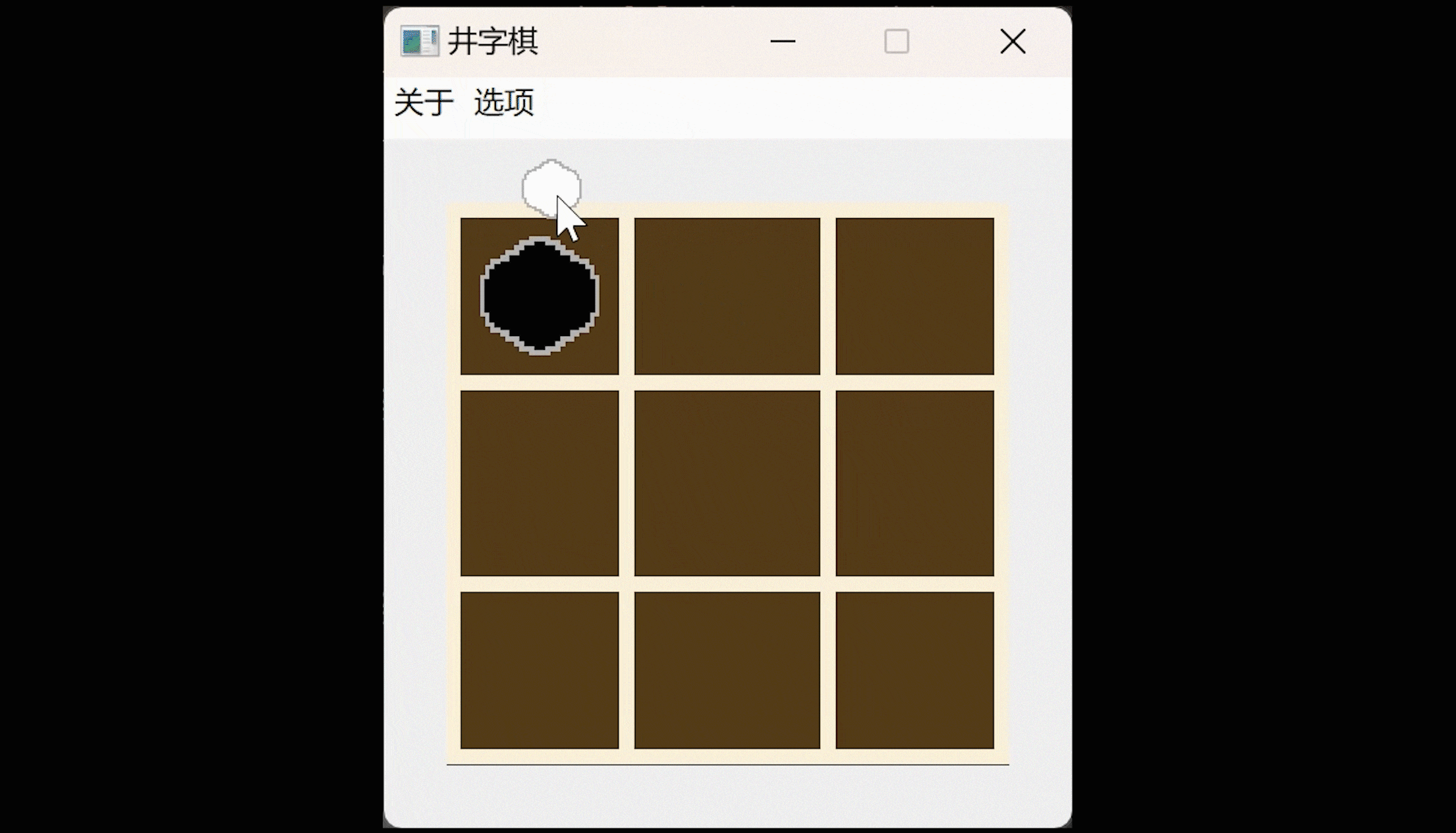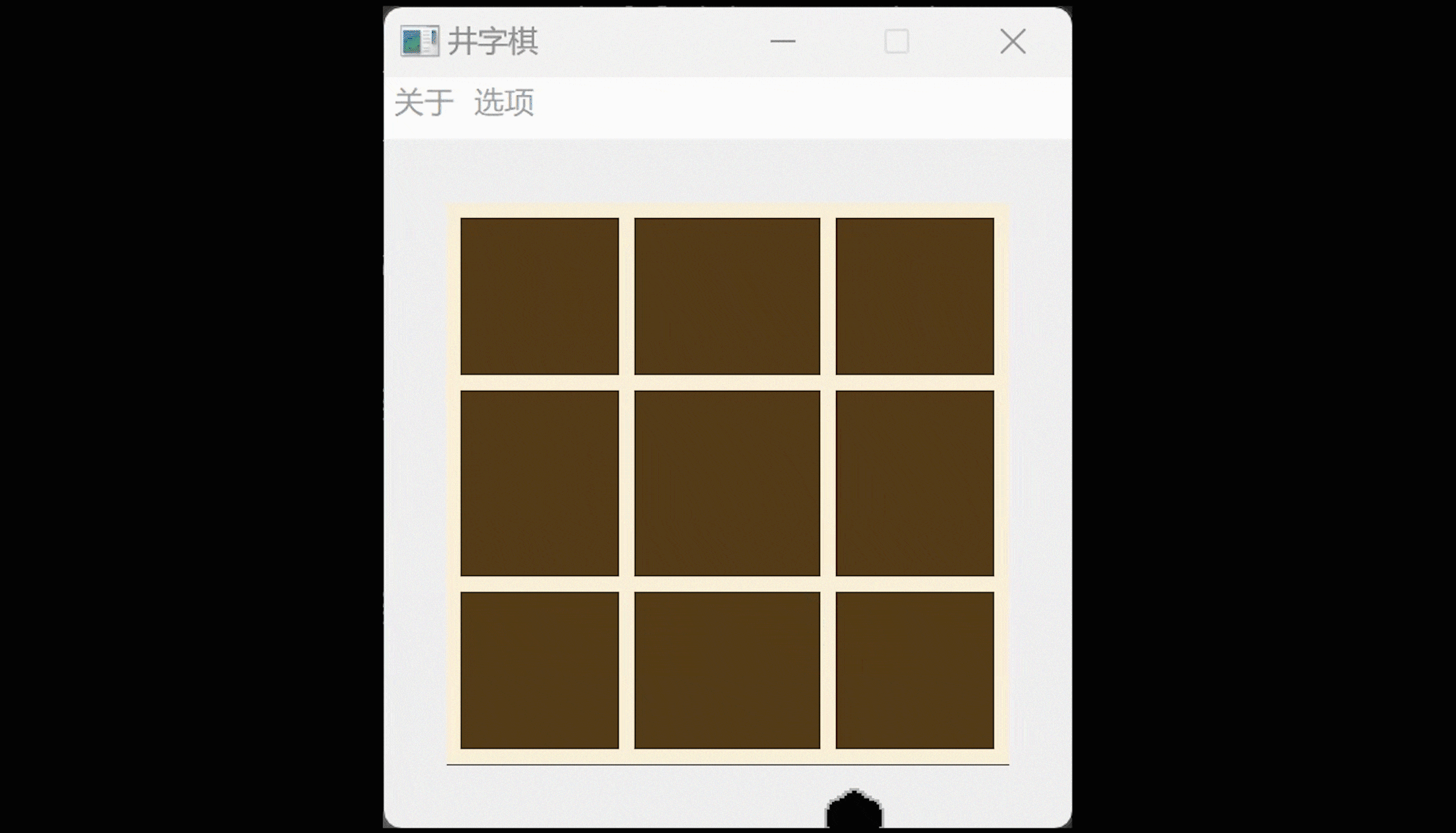
150行代码写一个Qt井字棋游戏
照例先演示一下: QT井字棋游戏,可以悔棋。 会在鼠标箭头处跟随一个下棋方的小棋子图标。 棋盘和棋子是自己画的,可以自行在对应的代码处更换自己喜欢的图片,不过要注意尺寸兼容。 以棋会友: 井字棋最关键的就是下棋了…...

k8s概念-controller
Controller作用和分类 controller用于控制pod 参考: 工作负载资源 | Kubernetes 控制器主要分为: Deployments 部署无状态应用,控制pod升级,回退 ReplicaSet 副本集,控制pod扩容,裁减 ReplicationController(相当于ReplicaSet的老版本,现在建议使用Deployments…...
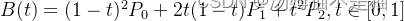
Gis入门,根据起止点和一个控制点计算二阶贝塞尔曲线(共三个控制点组成的线段转曲线)
前言 本章讲解如何在gis地图中使用起止点和一个控制点(总共三个控制点)生成二阶贝塞尔曲线。 三阶贝塞尔曲线请参考下一章《Gis入门,使用起止点和两个控制点生成三阶贝塞尔曲线(共四个控制点)》 贝塞尔曲线(Bezier curve)介绍 贝塞尔曲线(Bezier curve)是一种数学…...
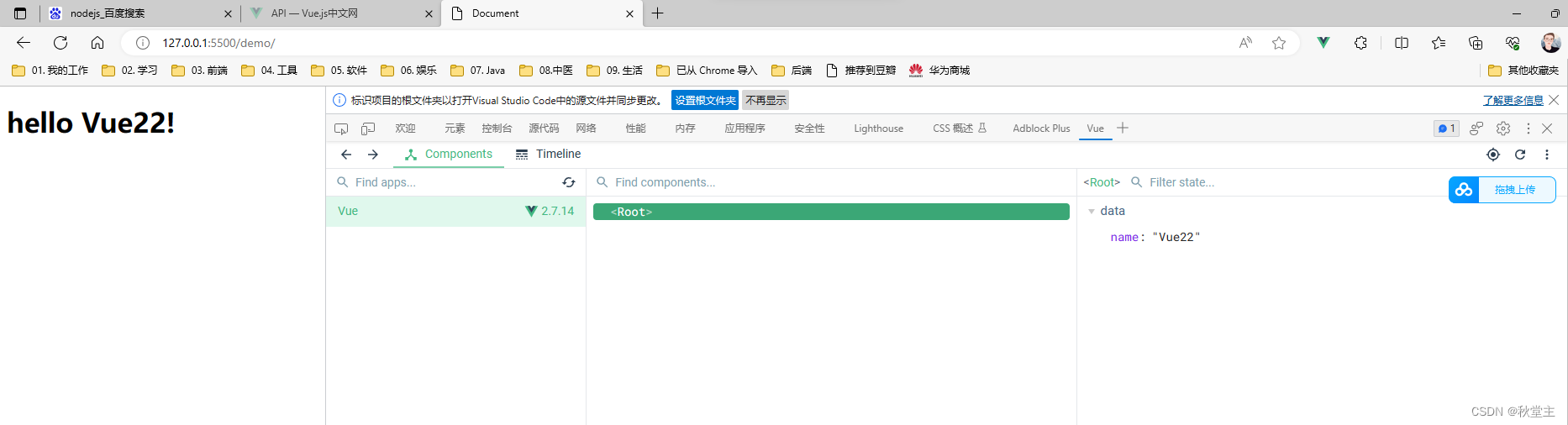
第1集丨Vue 江湖 —— Hello Vue
目录 一、简介1.1 参考网址1.2 下载 二、Hello Vue2.1 创建页面2.2 安装Live Server插件2.4 安装 vue-devtools2.5 预览效果 一、简介 Vue(读音 /vjuː/, 类似于 view) 是一套用于构建用户界面的渐进式框架。与其它大型框架不同的是,Vue 被设…...

AI VTuber技术栈全解析:从Live2D到GPT-SoVITS的实战搭建指南
1. 项目概述:为什么我们需要一份AI VTuber的“Awesome”清单? 如果你最近在GitHub、B站或者一些技术社区里逛过,大概率会看到一个词反复出现: AI VTuber 。它不再是科幻电影里的概念,而是正在快速渗透到直播、内容创…...

基于RAG的个人知识库AI助手:从原理到部署实战
1. 项目概述:当RAG遇上个人知识库最近几年,大语言模型(LLM)的能力边界不断被拓展,但一个核心痛点始终存在:它无法记住你私有的、非公开的、不断更新的知识。比如,你想让AI助手帮你分析上周的团队…...

魔兽争霸3兼容性修复终极指南:5步解决现代系统闪退问题
魔兽争霸3兼容性修复终极指南:5步解决现代系统闪退问题 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为魔兽争霸3在现代Windo…...

RAG落地方案
1. RAG分析1.1 为什么需要 Rerank?要理解 Rerank 的价值,得先理解向量检索到底"差"在哪。RAG 的第一阶段检索,通常用的是双塔(Bi-Encoder)架构的 Embedding 模型。它的工作方式是把 Query 和每个文档分别独立…...

为什么92%的团队在ElevenLabs多角色对话项目中3周内失败?——基于17个真实SaaS客户日志的根因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的团队在ElevenLabs多角色对话项目中3周内失败?——基于17个真实SaaS客户日志的根因分析 ElevenLabs 的 VoiceLab API 虽然提供了强大的多说话人语音合成能力,但其多角…...

朋友学过都说好的家电清洗培训 行业前景与培训内容科普解读
家电清洗培训行业前景随着人们生活水平的提高,家电的普及率越来越高,对家电清洗的需求也日益增长。据相关数据显示,近年来家电清洗市场规模呈现逐年上升的趋势。在城市中,越来越多的家庭开始重视家电的清洁与保养,以延…...

AI编码工作流实战:从工具整合到工程落地的系统指南
1. 项目概述:从“AI编码工作流”说起 最近在GitHub上看到一个挺有意思的项目,叫 nicksp/ai-coding-workflow 。光看名字,你可能觉得这又是一个关于“如何用AI写代码”的泛泛而谈。但作为一个在软件工程一线摸爬滚打了十多年的老码农&#x…...

嵌入式游戏开发实战:在4x8 LED点阵上用CircuitPython复刻FlappyBird
1. 项目概述:在4x8的像素矩阵上“复活”FlappyBird如果你玩过嵌入式开发,尤其是用那些小巧的微控制器板子,可能会觉得游戏开发离它们很远——资源有限,没有图形库,怎么搞?但恰恰是这种限制,最能…...

信号净化实战:从基础平滑到智能去噪
1. 信号净化入门:为什么我们需要处理噪声? 第一次接触传感器数据时,我被现实狠狠上了一课——实验室里漂亮的平滑曲线在真实场景中根本不存在。记得去年处理工厂振动传感器数据时,原始信号看起来就像心电图叠加了摇滚乐节奏。这种…...
)
基于AI的MRI图像超分辨率重建与去噪,当AI遇见MRI:基于深度学习的超分辨率重建与去噪实战(从SwinIR到Diffusion)
目录 1. 问题的起点:MRI为什么需要超分和去噪? 2. 最新技术选型:为什么不用简单CNN? 3. 数据准备:模拟MRI的退化过程 4. SwinIR核心原理与MRI适配 简化的SwinIR模型结构(PyTorch实现) 5. 去噪专用:Restormer(Transformer for Restoration) 关键组件:MDTA(Mu…...