目标识别数据集互相转换——xml、txt、json数据格式互转
VOC数据格式与YOLO数据格式互转
1.VOC数据格式

VOC(Visual Object Classes)是一个常用的计算机视觉数据集,它主要用于对象检测、分类和分割任务。VOC的标注格式,也被许多其他的数据集采用,因此理解这个数据格式是很重要的。下面是一个详细的介绍:
一个典型的VOC数据集主要包括以下两个主要组成部分:
- JPEGImages:这个文件夹包含所有的图片文件,通常都是jpg格式。
- Annotations:这个文件夹包含每张图片对应的标注文件。每个标注文件都是xml格式的,其中包含了图片中每个对象的信息,如类别、位置等。
格式如下:
<annotation><folder>图像文件所在文件夹名称</folder><filename>图像文件名</filename><source>...省略...</source><size><width>图像宽度</width><height>图像高度</height><depth>图像深度,例如RGB图像深度为3</depth></size><segmented>省略...</segmented><object><name>物体类别名称</name><pose>省略...</pose><truncated>是否被截断(0表示未被截断,1表示被截断)</truncated><difficult>是否难以识别(0表示容易识别,1表示难以识别)</difficult><bndbox><xmin>物体边界框左上角的x坐标</xmin><ymin>物体边界框左上角的y坐标</ymin><xmax>物体边界框右下角的x坐标</xmax><ymax>物体边界框右下角的y坐标</ymax></bndbox></object>...其他物体的标注信息...
</annotation>在标注文件中,可以包含多个<object>标签,每个标签都表示图片中的一个物体。每个物体的类别名称和位置信息都包含在这个标签中。位置信息通过一个矩形边界框来表示,该框由左上角和右下角的坐标确定。
2.YOLO数据格式
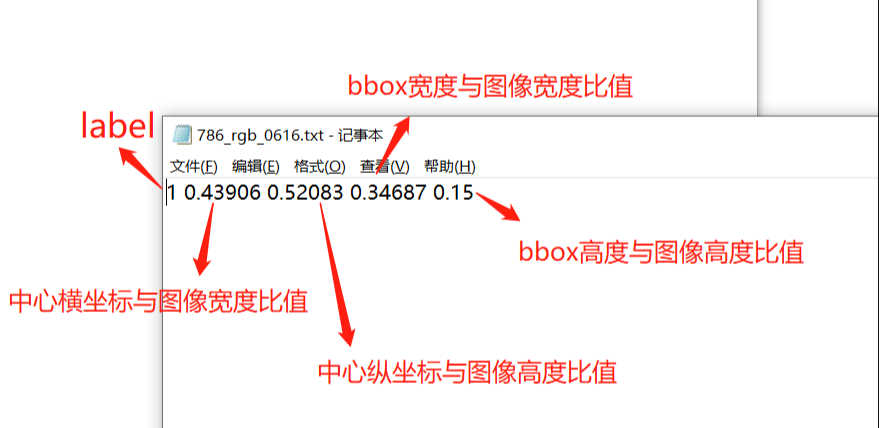
数据格式:label_index,cx, cy,w,h
label_index :为标签名称在标签数组中的索引,下标从 0 开始。
cx:标记框中心点的 x 坐标,数值是原始中心点 x 坐标除以 图宽 后的结果。
cy:标记框中心点的 y 坐标,数值是原始中心点 y 坐标除以 图高 后的结果。
w:标记框的 宽,数值为 原始标记框的 宽 除以 图宽 后的结果。
h:标记框的 高,数值为 原始标记框的 高 除以 图高 后的结果。
xml转txt
import os
import glob
import argparse
import random
import xml.etree.ElementTree as ET
from PIL import Image
from tqdm import tqdmdef get_all_classes(xml_path):xml_fns = glob.glob(os.path.join(xml_path, '*.xml'))class_names = []for xml_fn in xml_fns:tree = ET.parse(xml_fn)root = tree.getroot()for obj in root.iter('object'):cls = obj.find('name').textclass_names.append(cls)return sorted(list(set(class_names)))def convert_annotation(img_path, xml_path, class_names, out_path):output = []im_fns = glob.glob(os.path.join(img_path, '*.jpg'))for im_fn in tqdm(im_fns):if os.path.getsize(im_fn) == 0:continuexml_fn = os.path.join(xml_path, os.path.splitext(os.path.basename(im_fn))[0] + '.xml')if not os.path.exists(xml_fn):continueimg = Image.open(im_fn)height, width = img.height, img.widthtree = ET.parse(xml_fn)root = tree.getroot()anno = []xml_height = int(root.find('size').find('height').text)xml_width = int(root.find('size').find('width').text)if height != xml_height or width != xml_width:print((height, width), (xml_height, xml_width), im_fn)continuefor obj in root.iter('object'):cls = obj.find('name').textcls_id = class_names.index(cls)xmlbox = obj.find('bndbox')xmin = int(xmlbox.find('xmin').text)ymin = int(xmlbox.find('ymin').text)xmax = int(xmlbox.find('xmax').text)ymax = int(xmlbox.find('ymax').text)cx = (xmax + xmin) / 2.0 / widthcy = (ymax + ymin) / 2.0 / heightbw = (xmax - xmin) * 1.0 / widthbh = (ymax - ymin) * 1.0 / heightanno.append('{} {} {} {} {}'.format(cls_id, cx, cy, bw, bh))if len(anno) > 0:output.append(im_fn)with open(im_fn.replace('.jpg', '.txt'), 'w') as f:f.write('\n'.join(anno))random.shuffle(output)train_num = int(len(output) * 0.9)with open(os.path.join(out_path, 'train.txt'), 'w') as f:f.write('\n'.join(output[:train_num]))with open(os.path.join(out_path, 'val.txt'), 'w') as f:f.write('\n'.join(output[train_num:]))def parse_args():parser = argparse.ArgumentParser('generate annotation')parser.add_argument('--img_path', type=str, help='input image directory',default= "data/jpg/")parser.add_argument('--xml_path', type=str, help='input xml directory',default= "data/xml/")parser.add_argument('--out_path', type=str, help='output directory',default= "data/dataset/")args = parser.parse_args()return argsif __name__ == '__main__':args = parse_args()class_names = get_all_classes(args.xml_path)print(class_names)convert_annotation(args.img_path, args.xml_path, class_names, args.out_path)
txt转xml
from xml.dom.minidom import Document
import os
import cv2def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径dic = {'0': "ship", # 创建字典用来对类型进行转换'1': "car_trucks", # 此处的字典要与自己的classes.txt文件中的类对应,且顺序要一致'2' :'person','3': 'stacking_area','4': 'car_forklift','5': 'unload_car','6': 'load_car','7': 'car_private',}files = os.listdir(txtPath)for i, name in enumerate(files):xmlBuilder = Document()annotation = xmlBuilder.createElement("annotation") # 创建annotation标签xmlBuilder.appendChild(annotation)txtFile = open(txtPath + name)print(txtFile)txtList = txtFile.readlines()img = cv2.imread(picPath + name[0:-4] + ".png")Pheight, Pwidth, Pdepth = img.shapefolder = xmlBuilder.createElement("folder") # folder标签foldercontent = xmlBuilder.createTextNode("driving_annotation_dataset")folder.appendChild(foldercontent)annotation.appendChild(folder) # folder标签结束filename = xmlBuilder.createElement("filename") # filename标签filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".png")filename.appendChild(filenamecontent)annotation.appendChild(filename) # filename标签结束size = xmlBuilder.createElement("size") # size标签width = xmlBuilder.createElement("width") # size子标签widthwidthcontent = xmlBuilder.createTextNode(str(Pwidth))width.appendChild(widthcontent)size.appendChild(width) # size子标签width结束height = xmlBuilder.createElement("height") # size子标签heightheightcontent = xmlBuilder.createTextNode(str(Pheight))height.appendChild(heightcontent)size.appendChild(height) # size子标签height结束depth = xmlBuilder.createElement("depth") # size子标签depthdepthcontent = xmlBuilder.createTextNode(str(Pdepth))depth.appendChild(depthcontent)size.appendChild(depth) # size子标签depth结束annotation.appendChild(size) # size标签结束for j in txtList:oneline = j.strip().split(" ")object = xmlBuilder.createElement("object") # object 标签picname = xmlBuilder.createElement("name") # name标签namecontent = xmlBuilder.createTextNode(dic[oneline[0]])picname.appendChild(namecontent)object.appendChild(picname) # name标签结束pose = xmlBuilder.createElement("pose") # pose标签posecontent = xmlBuilder.createTextNode("Unspecified")pose.appendChild(posecontent)object.appendChild(pose) # pose标签结束truncated = xmlBuilder.createElement("truncated") # truncated标签truncatedContent = xmlBuilder.createTextNode("0")truncated.appendChild(truncatedContent)object.appendChild(truncated) # truncated标签结束difficult = xmlBuilder.createElement("difficult") # difficult标签difficultcontent = xmlBuilder.createTextNode("0")difficult.appendChild(difficultcontent)object.appendChild(difficult) # difficult标签结束bndbox = xmlBuilder.createElement("bndbox") # bndbox标签xmin = xmlBuilder.createElement("xmin") # xmin标签mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)xminContent = xmlBuilder.createTextNode(str(mathData))xmin.appendChild(xminContent)bndbox.appendChild(xmin) # xmin标签结束ymin = xmlBuilder.createElement("ymin") # ymin标签mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)yminContent = xmlBuilder.createTextNode(str(mathData))ymin.appendChild(yminContent)bndbox.appendChild(ymin) # ymin标签结束xmax = xmlBuilder.createElement("xmax") # xmax标签mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)xmaxContent = xmlBuilder.createTextNode(str(mathData))xmax.appendChild(xmaxContent)bndbox.appendChild(xmax) # xmax标签结束ymax = xmlBuilder.createElement("ymax") # ymax标签mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)ymaxContent = xmlBuilder.createTextNode(str(mathData))ymax.appendChild(ymaxContent)bndbox.appendChild(ymax) # ymax标签结束object.appendChild(bndbox) # bndbox标签结束annotation.appendChild(object) # object标签结束f = open(xmlPath + name[0:-4] + ".xml", 'w')xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')f.close()if __name__ == "__main__":picPath = "data/images/" # 图片所在文件夹路径,后面的/一定要带上txtPath = "data/labels/" # txt所在文件夹路径,后面的/一定要带上xmlPath = "data/xml/" # xml文件保存路径,后面的/一定要带上makexml(picPath, txtPath, xmlPath)json转txt
import os
import numpy as np
import json
from glob import glob
import cv2
from sklearn.model_selection import train_test_split
from os import getcwdclasses = ["0","1","2"]
# 1.标签路径
labelme_path = r"dataset/"
isUseTest = False # 是否创建test集
# 3.获取待处理文件
files = glob(labelme_path + "*.json")
files = [i.replace("\\", "/").split("/")[-1].split(".json")[0] for i in files]
# print(files)
if isUseTest:trainval_files, test_files = train_test_split(files, test_size=0.1, random_state=55)
else:trainval_files = filestrain_files = filesdef convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn (x, y, w, h)wd = getcwd()
# print(wd)def ChangeToYolo5(files, txt_Name):if not os.path.exists('tmp/'):os.makedirs('tmp/')list_file = open('tmp/%s.txt' % (txt_Name), 'w')for json_file_ in files:print(json_file_)json_filename = labelme_path + json_file_ + ".json"imagePath = labelme_path + json_file_ + ".png"list_file.write('%s/%s\n' % (wd, imagePath))out_file = open('%s/%s.txt' % (labelme_path, json_file_), 'w')json_file = json.load(open(json_filename, "r", encoding="utf-8"))height, width, channels = cv2.imread(labelme_path + json_file_ + ".png").shapefor multi in json_file["shapes"]:points = np.array(multi["points"])xmin = min(points[:, 0]) if min(points[:, 0]) > 0 else 0xmax = max(points[:, 0]) if max(points[:, 0]) > 0 else 0ymin = min(points[:, 1]) if min(points[:, 1]) > 0 else 0ymax = max(points[:, 1]) if max(points[:, 1]) > 0 else 0label = multi["label"]if xmax <= xmin:passelif ymax <= ymin:passelse:cls_id = classes.index(label)b = (float(xmin), float(xmax), float(ymin), float(ymax))bb = convert((width, height), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')print(json_filename, xmin, ymin, xmax, ymax, cls_id)ChangeToYolo5(train_files, "train")
相关文章:
目标识别数据集互相转换——xml、txt、json数据格式互转
VOC数据格式与YOLO数据格式互转 1.VOC数据格式 VOC(Visual Object Classes)是一个常用的计算机视觉数据集,它主要用于对象检测、分类和分割任务。VOC的标注格式,也被许多其他的数据集采用,因此理解这个数据格式是很重…...
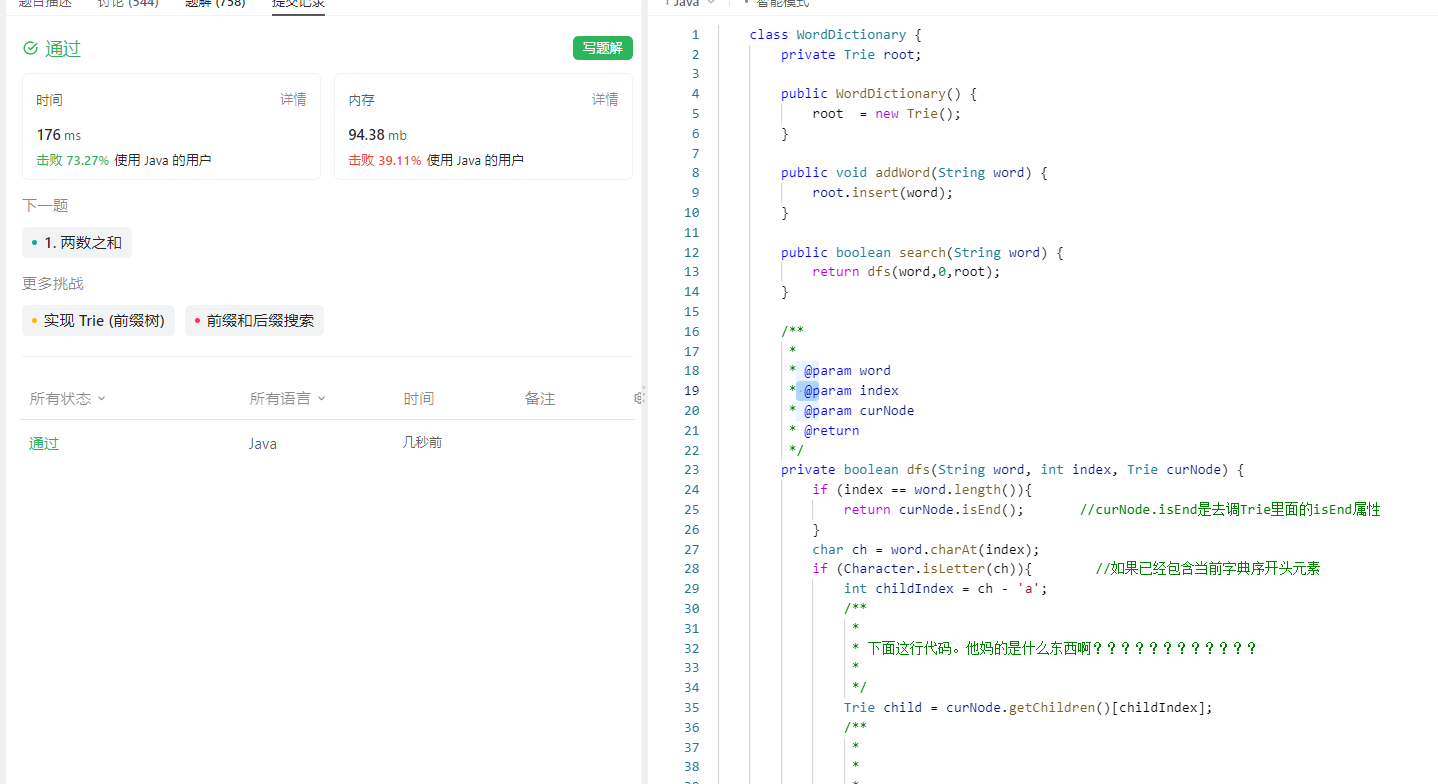
211. 添加与搜索单词 - 数据结构设计---------------字典树
211. 添加与搜索单词 - 数据结构设计 原题链接:完成情况:解题思路:参考代码: 原题链接: 211. 添加与搜索单词 - 数据结构设计 https://leetcode.cn/problems/design-add-and-search-words-data-structure/descriptio…...

SQL Server通过指令备份数据库和恢复数据库
数据库备份: backup database [MyTestDB]to diskD:\MyTestDB_20200101.bakwith format,init,stats1,compression 数据库恢复: restore database MyTestDB_newfrom diskD:\MyTestDB_20200101.bakwith move MyTestDB to D:\MyTestDB_new.mdf,move MyTest…...
windows如何上架ios应用到app store
Application Uploader iOS App上架工具是一款非常好用的针对iOS苹果应用程序软件开发的实用编程工具,它的主要作用是帮助用户进行快速的程序应用设计和程序应用调试,节省用户进行软件开发耗费的不必要时间! 编辑切换为居中 添加图片注释&…...
Hadoop学习日记-YARN组件
YARN(Yet Another Resource Negotiator)作为一种新的Hadoop资源管理器,是另一种资源协调者。 YARN是一个通用的资源管理系统和调度平台,可为上层应用提供统一的资源管理和调度 YARN架构图 YARN3大组件: (物理层面)…...

汽车过户时,怎么选到理想的好车牌?
在汽车过户的过程中,选到一副理想的好车牌就像买彩票中大奖一样令人兴奋。但是,怎样找到这样一块车牌呢?这就是本文要探讨的问题。 首先,我们来聊聊选车牌的技巧。很多人喜欢选择有特别数字的车牌,如“8888”、“6666”…...
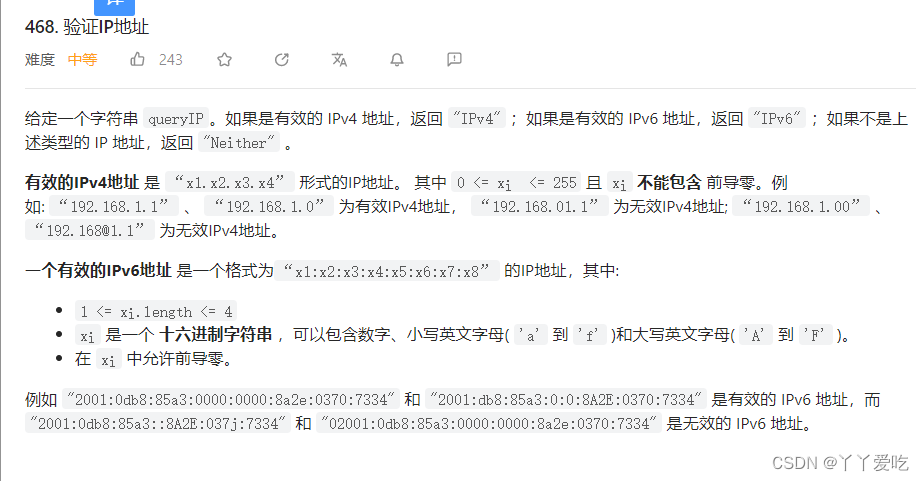
力扣468 验证IP地址
ipv4地址:1.必须是四个非空子串 2.每个非空子串不含前导零 3.子串里字符只能是0~255 ipv6地址:1.必须是八个非空子串 2。每段非空串得长度是否在1~4之间,且不含0-9,a-f,A-F之外得字符。 3.同时0-9也不允许含前导零 cl…...

前端静态登录页面实现
<template> <!-- <el-button type="primary" @click="handleLogin">测试登录</el-button>--> <!-- <el-button type="danger" @click="handleUserList">测试获取用户请求</el-button>-->…...
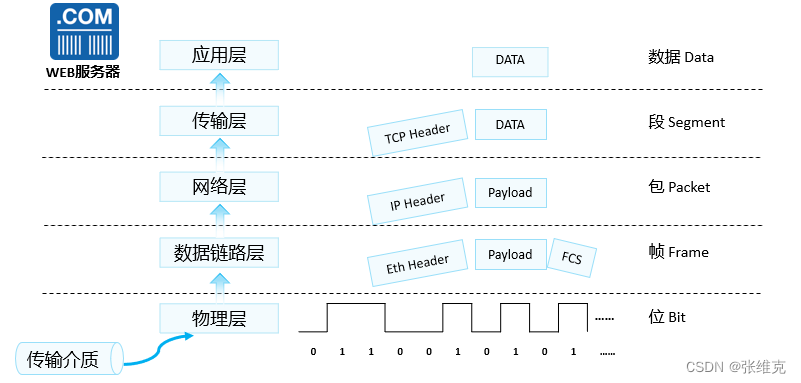
华为数通HCIA-网络参考模型(TCP/IP)
网络通信模式 作用:指导网络设备的通信; OSI七层模型: 7.应用层:由应用层协议(http、FTP、Telnet.)为应用程序产生对应的数据; 6.表示层:将应用层产生的数据转换成网络设备看得懂…...
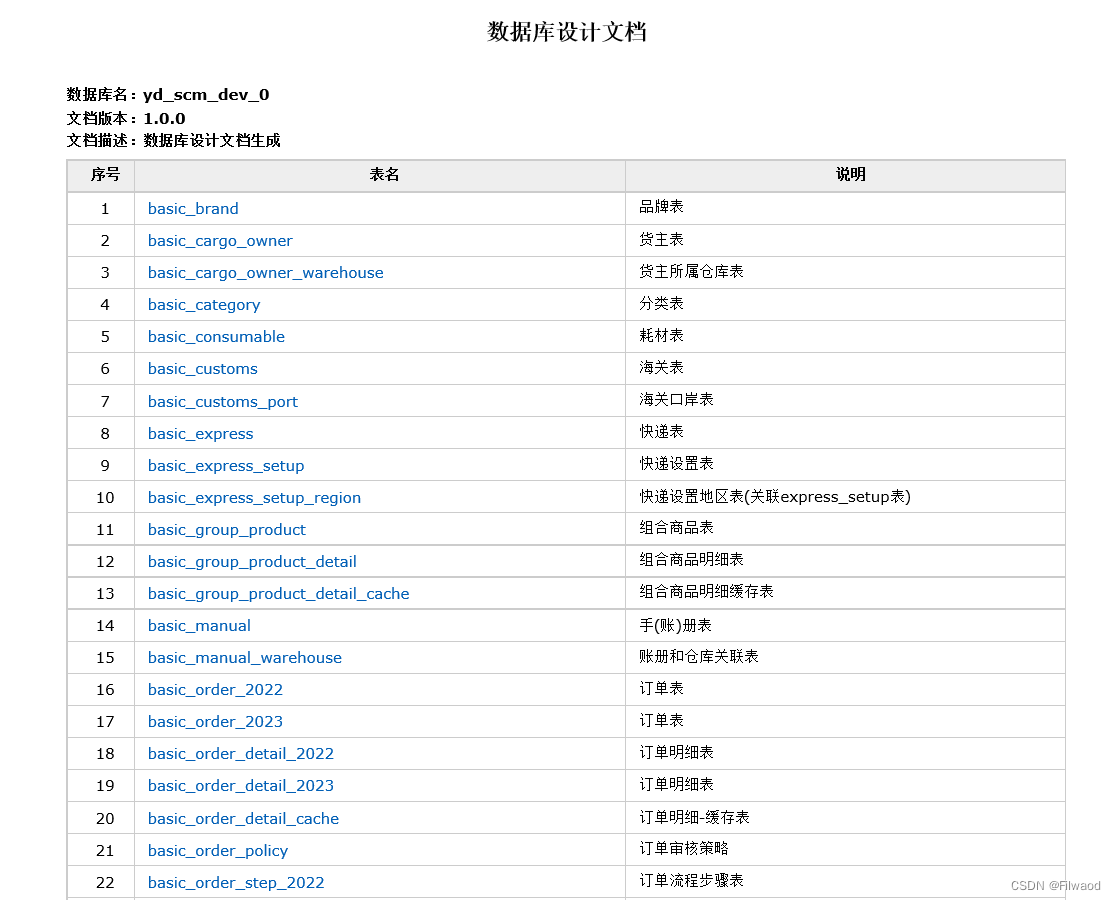
java快速生成数据库表文档(HTML、DOC、MD)
在企业级开发中、我们经常会有编写数据库表结构文档的时间付出,关于数据库表结构文档状态:要么没有、要么有、但都是手写、后期运维开发,需要手动进行维护到文档中,很是繁琐,这里推荐一个开源项目:screw gi…...

Dojo学习和常用知识
目录 一、Dojo 的基本概念二、Dojo 的组件和模板三、Dojo 的应用场景四、Dojo 的未来发展五、学习 Dojo 的大纲和建议:六、Dojo 代码示例: Dojo 是一个流行的 JavaScript 库,用于开发 Web 应用程序。它提供了许多功能,如 DOM 操作…...

媒体查询详解
引言 媒体查询是 CSS3 的一个新的技术,它使我们可以针对不同的设备(或者说,不同的屏幕尺寸和分辨率)来应用不同的样式。 媒体查询包含一个媒体类型和至少一个使用宽度、高度、颜色等条件限制的表达式。CSS 用于桌面电脑的屏幕可…...
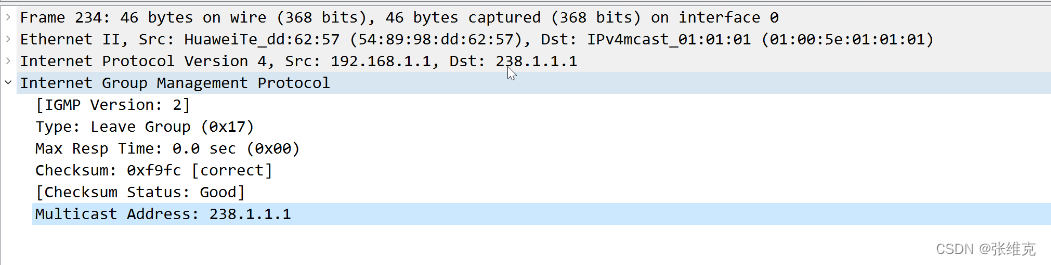
华为数通HCIP-IGMP(网络组管理协议)
IGMP(网络组管理协议) 作用:维护、管理最后一跳路由器以及组播接收者之间的关系; 应用:最后一跳路由器以及组播接收者之间; 原理:当组播接收者需要接收某个组别的流量时,会向最后…...

价格管控有哪些有效的方法
品牌在面对线上店铺的低价、窜货时,需要及时进行干预治理,否则低价效应会蔓延,会有越来越多的店铺跟价,导致渠道更加混乱,但是管控价格也非一时之事,需要品牌按流程治理。 力维网络有多年价格管控经验&…...

【Docker】Docker相关基础命令
目录 一、Docker服务相关命令 1、启动docker服务 2、停止docker服务 3、重启docker服务 4、查看docker服务状态 5、开机自启动docker服务 二、Images镜像相关命令 1、查看镜像 2、拉取镜像 3、搜索镜像 4、删除镜像 三、Container容器相关命令 1、创建容器 2、查…...
掌握Python的X篇_16_list的切片、len和in操作
接上篇掌握Python的X篇_15_list容器的基本使用,本篇进行进一步的介绍。 文章目录 1. list的索引下标可以是负数2. 切片(slice)2.1 切片基础知识2.2 如何“取到尽头”2.3 按照步长取元素2.4 逆序取值 3. len函数获取lis的元素个数4. in操作符…...
给定长度值length,把列表切分成每段长度为length的N段列表,Kotlin
给定长度值length,把列表切分成每段长度为length的N段列表,Kotlin import kotlin.random.Randomfun main(args: Array<String>) {var source mutableListOf<String>()val end Random.nextInt(30) 1for (i in 0 until end) {source.add(i.…...
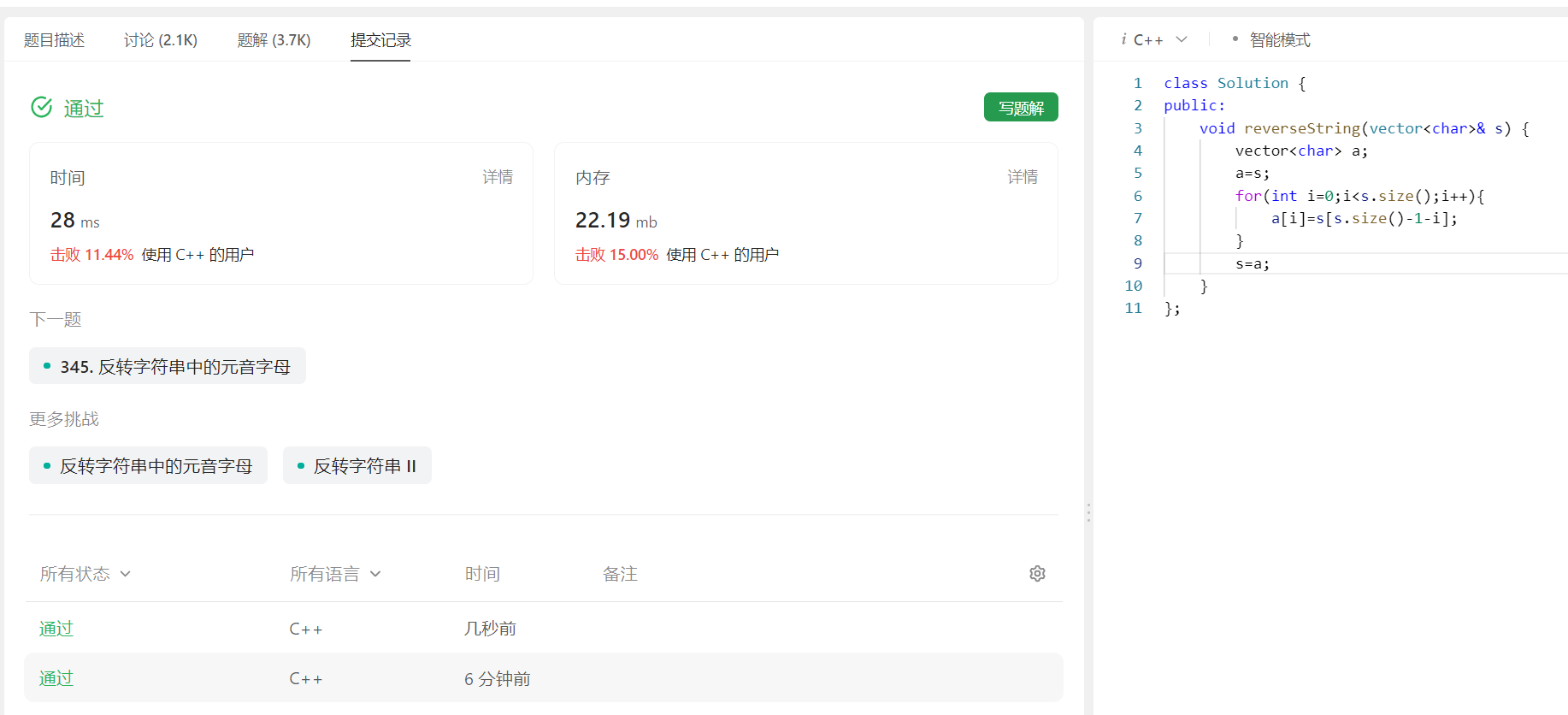
leetcode每日一题Day2——344. 反转字符串
✨博主:命运之光 🦄专栏:算法修炼之练气篇(C\C版) 🍓专栏:算法修炼之筑基篇(C\C版) 🐳专栏:算法修炼之练气篇(Python版) …...

ISP记1
噪声分类 空间区域 分布模型分类:Gaussian噪声、瑞利噪声、泊松噪声、乘性噪声、脉冲噪声、均匀分布噪声 频域谱波形分类:均匀分布噪声、白噪声(噪声的功率谱为参数,且与图像线性无关)1/f噪声、a f 2 f^{2} f2噪声&a…...

无线蓝牙耳机有什么值得耳机买的?几款值得买的口碑品牌盘点
蓝牙耳机是一种无线耳机,其通过蓝牙技术与其他设备进行连接,例如手机、电脑、平板电脑等。蓝牙耳机使得用户可以在不受线缆限制的情况下享受音频体验,而且还可以方便地进行通话,目前市场上有许多不同种类和品牌的蓝牙耳机…...

基于Claude的AI编程助手:从代码生成到自动化审查的全流程实践
1. 项目概述:当Claude遇上代码,一个全能型AI编程助手的诞生最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“everything-claude-code”。光看名字,你可能会觉得这又是一个普通的AI代码生成工具,但实际深入…...

合肥工业大学LaTeX论文模板:5分钟解决格式难题的专业方案
合肥工业大学LaTeX论文模板:5分钟解决格式难题的专业方案 【免费下载链接】HFUT_Thesis LaTeX Thesis Template for Hefei University of Technology 项目地址: https://gitcode.com/gh_mirrors/hf/HFUT_Thesis 还在为论文格式调整而烦恼吗?合肥工…...
)
STM32CubeMX实战:FSMC高效驱动ILI9488 LCD屏(基于STM32F407)
1. 环境准备与硬件连接 在开始配置FSMC驱动ILI9488 LCD屏之前,我们需要准备好开发环境和硬件设备。我使用的是STM32F407VET6核心板搭配3.5寸320x480分辨率的ILI9488控制器TFT LCD屏幕。这种组合在工业控制和消费电子领域非常常见,性价比高且性能稳定。 硬…...

Vivado工程实战:在ZCU102上配置MIG控制器时,SLEW属性设置成SLOW还是FAST?
Vivado工程实战:ZCU102平台MIG控制器SLEW属性深度解析 在Xilinx ZCU102开发板上进行DDR4接口设计时,MIG控制器的配置往往成为项目成败的关键。许多工程师能够顺利完成基础配置,却在面对诸如SLEW属性这类"细微"参数时陷入选择困境。…...

不只是画图:用Design Entry CIS画原理图符号,你真的理解引脚属性吗?
不只是画图:用Design Entry CIS画原理图符号,你真的理解引脚属性吗? 在电子设计自动化(EDA)领域,原理图符号的创建常被视为"简单绘图",但真正影响设计质量的往往是那些被忽视的细节。…...

为什么OpenVSP是航空航天工程师的“参数化建模瑞士军刀“?5个实战场景深度解析
为什么OpenVSP是航空航天工程师的"参数化建模瑞士军刀"?5个实战场景深度解析 【免费下载链接】OpenVSP A parametric aircraft geometry tool 项目地址: https://gitcode.com/gh_mirrors/ope/OpenVSP 在飞机设计领域,传统CAD软件的复杂…...

【职场】那些把公司当家的人,最先被扫地出门
那些把公司当家的人,最先被扫地出门“你爱公司爱得越深,离开的时候就摔得越惨。因为公司从一开始,就没打算和你谈感情。”一、那种人,你一定见过 他是第一个到公司的,也是最后一个离开的。 他的工位永远是最乱的那个&a…...

8岁小学生idea直接变应用,秒哒3.0刚刚把AI应用门槛打没了
允中 发自 凹非寺量子位 | 公众号 QbitAI“做应用”这件事,现在真的老少咸宜了:一个二年级小朋友,做了个“拼伞小程序”和操作系统。一个4人团队,没写过代码,7天搭出了覆盖9万老人的智慧养老平台。还有人靠AI做依恋类型…...

电路设计效率革命:Draw.io电子工程库的专业绘图方案
电路设计效率革命:Draw.io电子工程库的专业绘图方案 【免费下载链接】Draw-io-ECE Custom-made draw.io-shapes - in the form of an importable library - for drawing circuits and conceptual drawings in draw.io. 项目地址: https://gitcode.com/gh_mirrors/…...

AGV中上位机
在 AGV 系统里,“上位机”一般就是调度/监控系统,负责:全局任务分配、路径规划、交通管制、与 MES/WMS 对接、人机界面等;车上的 PLC / 控制器则作为下位机,负责实时运动控制、传感器采集和执行指令。两者通过以太网 /…...