使用 TorchText 进行语言翻译
使用 TorchText 进行语言翻译
本教程说明如何使用torchtext的几个便捷类来预处理包含英语和德语句子的著名数据集的数据,并使用它来训练序列到序列模型,并注意将德语句子翻译成英语 。
它基于 PyTorch 社区成员 Ben Trevett 的本教程,并由 Seth Weidman 在 Ben 的允许下创建。
在本教程结束时,您将能够:
-
Preprocess sentences into a commonly-used format for NLP modeling using the following torchtext convenience classes:- TranslationDataset
- 字段
- BucketIterator
<cite>字段</cite>和 <cite>TranslationDataset</cite>
torchtext具有用于创建数据集的实用程序,可以轻松地对其进行迭代,以创建语言翻译模型。 一个关键类是字段,它指定应该对每个句子进行预处理的方式,另一个关键类是 <cite>TranslationDataset</cite> ; torchtext有几个这样的数据集; 在本教程中,我们将使用 Multi30k 数据集,其中包含约 30,000 个英语和德语句子(平均长度约为 13 个单词)。
注意:本教程中的标记化需要 Spacy 我们使用 Spacy,因为它为英语以外的其他语言的标记化提供了强大的支持。 torchtext提供了basic_english标记器,并支持其他英语标记器(例如摩西),但对于语言翻译(需要多种语言),Spacy 是您的最佳选择。
要运行本教程,请先使用pip或conda安装spacy。 接下来,下载英语和德语 Spacy 分词器的原始数据:
python -m spacy download en
python -m spacy download de安装 Spacy 后,以下代码将根据Field中定义的标记器,标记TranslationDataset中的每个句子。
from torchtext.datasets import Multi30k
from torchtext.data import Field, BucketIteratorSRC = Field(tokenize = "spacy",tokenizer_language="de",init_token = '<sos>',eos_token = '<eos>',lower = True)TRG = Field(tokenize = "spacy",tokenizer_language="en",init_token = '<sos>',eos_token = '<eos>',lower = True)train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'),fields = (SRC, TRG))出:
downloading training.tar.gz
downloading validation.tar.gz
downloading mmt_task1_test2016.tar.gz现在我们已经定义了train_data,我们可以看到torchtext的Field的一个非常有用的功能:build_vocab方法现在允许我们创建与每种语言相关的词汇
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)一旦运行了这些代码行,SRC.vocab.stoi将是一个词典,其词汇表中的标记作为键,而其对应的索引作为值; SRC.vocab.itos将是相同的字典,其中的键和值被交换。 在本教程中,我们不会广泛使用此事实,但这在您将遇到的其他 NLP 任务中可能很有用。
BucketIterator
我们将使用的最后torchtext个特定功能是BucketIterator,它很容易使用,因为它以TranslationDataset作为第一个参数。 具体来说,正如文档所说:定义一个迭代器,该迭代器将相似长度的示例批处理在一起。 在为每个新纪元生产新鲜改组的批次时,最大程度地减少所需的填充量。 有关使用的存储过程,请参阅池。
import torchdevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')BATCH_SIZE = 128train_iterator, valid_iterator, test_iterator = BucketIterator.splits((train_data, valid_data, test_data),batch_size = BATCH_SIZE,device = device)可以像DataLoader``s; below, in the ``train和evaluate函数一样调用这些迭代器,只需使用以下命令即可调用它们:
for i, batch in enumerate(iterator):每个batch然后具有src和trg属性:
src = batch.src
trg = batch.trg定义我们的nn.Module和Optimizer
这大部分是从torchtext角度出发的:构建了数据集并定义了迭代器,本教程的其余部分仅将模型定义为nn.Module以及Optimizer,然后对其进行训练。
具体来说,我们的模型遵循在此处中描述的架构(您可以在此处找到更多注释的版本)。
注意:此模型只是可用于语言翻译的示例模型; 我们选择它是因为它是任务的标准模型,而不是因为它是用于翻译的推荐模型。 如您所知,目前最先进的模型基于“变形金刚”; 您可以在此处看到 PyTorch 的实现 Transformer 层的功能; 特别是,以下模型中使用的“注意”与变压器模型中存在的多头自我注意不同。
import random
from typing import Tupleimport torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch import Tensorclass Encoder(nn.Module):def __init__(self,input_dim: int,emb_dim: int,enc_hid_dim: int,dec_hid_dim: int,dropout: float):super().__init__()self.input_dim = input_dimself.emb_dim = emb_dimself.enc_hid_dim = enc_hid_dimself.dec_hid_dim = dec_hid_dimself.dropout = dropoutself.embedding = nn.Embedding(input_dim, emb_dim)self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True)self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim)self.dropout = nn.Dropout(dropout)def forward(self,src: Tensor) -> Tuple[Tensor]:embedded = self.dropout(self.embedding(src))outputs, hidden = self.rnn(embedded)hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1)))return outputs, hiddenclass Attention(nn.Module):def __init__(self,enc_hid_dim: int,dec_hid_dim: int,attn_dim: int):super().__init__()self.enc_hid_dim = enc_hid_dimself.dec_hid_dim = dec_hid_dimself.attn_in = (enc_hid_dim * 2) + dec_hid_dimself.attn = nn.Linear(self.attn_in, attn_dim)def forward(self,decoder_hidden: Tensor,encoder_outputs: Tensor) -> Tensor:src_len = encoder_outputs.shape[0]repeated_decoder_hidden = decoder_hidden.unsqueeze(1).repeat(1, src_len, 1)encoder_outputs = encoder_outputs.permute(1, 0, 2)energy = torch.tanh(self.attn(torch.cat((repeated_decoder_hidden,encoder_outputs),dim = 2)))attention = torch.sum(energy, dim=2)return F.softmax(attention, dim=1)class Decoder(nn.Module):def __init__(self,output_dim: int,emb_dim: int,enc_hid_dim: int,dec_hid_dim: int,dropout: int,attention: nn.Module):super().__init__()self.emb_dim = emb_dimself.enc_hid_dim = enc_hid_dimself.dec_hid_dim = dec_hid_dimself.output_dim = output_dimself.dropout = dropoutself.attention = attentionself.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim)self.out = nn.Linear(self.attention.attn_in + emb_dim, output_dim)self.dropout = nn.Dropout(dropout)def _weighted_encoder_rep(self,decoder_hidden: Tensor,encoder_outputs: Tensor) -> Tensor:a = self.attention(decoder_hidden, encoder_outputs)a = a.unsqueeze(1)encoder_outputs = encoder_outputs.permute(1, 0, 2)weighted_encoder_rep = torch.bmm(a, encoder_outputs)weighted_encoder_rep = weighted_encoder_rep.permute(1, 0, 2)return weighted_encoder_repdef forward(self,input: Tensor,decoder_hidden: Tensor,encoder_outputs: Tensor) -> Tuple[Tensor]:input = input.unsqueeze(0)embedded = self.dropout(self.embedding(input))weighted_encoder_rep = self._weighted_encoder_rep(decoder_hidden,encoder_outputs)rnn_input = torch.cat((embedded, weighted_encoder_rep), dim = 2)output, decoder_hidden = self.rnn(rnn_input, decoder_hidden.unsqueeze(0))embedded = embedded.squeeze(0)output = output.squeeze(0)weighted_encoder_rep = weighted_encoder_rep.squeeze(0)output = self.out(torch.cat((output,weighted_encoder_rep,embedded), dim = 1))return output, decoder_hidden.squeeze(0)class Seq2Seq(nn.Module):def __init__(self,encoder: nn.Module,decoder: nn.Module,device: torch.device):super().__init__()self.encoder = encoderself.decoder = decoderself.device = devicedef forward(self,src: Tensor,trg: Tensor,teacher_forcing_ratio: float = 0.5) -> Tensor:batch_size = src.shape[1]max_len = trg.shape[0]trg_vocab_size = self.decoder.output_dimoutputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device)encoder_outputs, hidden = self.encoder(src)# first input to the decoder is the <sos> tokenoutput = trg[0,:]for t in range(1, max_len):output, hidden = self.decoder(output, hidden, encoder_outputs)outputs[t] = outputteacher_force = random.random() < teacher_forcing_ratiotop1 = output.max(1)[1]output = (trg[t] if teacher_force else top1)return outputsINPUT_DIM = len(SRC.vocab)
OUTPUT_DIM = len(TRG.vocab)
# ENC_EMB_DIM = 256
# DEC_EMB_DIM = 256
# ENC_HID_DIM = 512
# DEC_HID_DIM = 512
# ATTN_DIM = 64
# ENC_DROPOUT = 0.5
# DEC_DROPOUT = 0.5ENC_EMB_DIM = 32
DEC_EMB_DIM = 32
ENC_HID_DIM = 64
DEC_HID_DIM = 64
ATTN_DIM = 8
ENC_DROPOUT = 0.5
DEC_DROPOUT = 0.5enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT)attn = Attention(ENC_HID_DIM, DEC_HID_DIM, ATTN_DIM)dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn)model = Seq2Seq(enc, dec, device).to(device)def init_weights(m: nn.Module):for name, param in m.named_parameters():if 'weight' in name:nn.init.normal_(param.data, mean=0, std=0.01)else:nn.init.constant_(param.data, 0)model.apply(init_weights)optimizer = optim.Adam(model.parameters())def count_parameters(model: nn.Module):return sum(p.numel() for p in model.parameters() if p.requires_grad)print(f'The model has {count_parameters(model):,} trainable parameters')Out:
The model has 1,856,685 trainable parameters注意:特别是在对语言翻译模型的性能进行评分时,我们必须告诉nn.CrossEntropyLoss函数忽略仅填充目标的索引。
PAD_IDX = TRG.vocab.stoi['<pad>']criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)最后,我们可以训练和评估该模型:
import math
import timedef train(model: nn.Module,iterator: BucketIterator,optimizer: optim.Optimizer,criterion: nn.Module,clip: float):model.train()epoch_loss = 0for _, batch in enumerate(iterator):src = batch.srctrg = batch.trgoptimizer.zero_grad()output = model(src, trg)output = output[1:].view(-1, output.shape[-1])trg = trg[1:].view(-1)loss = criterion(output, trg)loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), clip)optimizer.step()epoch_loss += loss.item()return epoch_loss / len(iterator)def evaluate(model: nn.Module,iterator: BucketIterator,criterion: nn.Module):model.eval()epoch_loss = 0with torch.no_grad():for _, batch in enumerate(iterator):src = batch.srctrg = batch.trgoutput = model(src, trg, 0) #turn off teacher forcingoutput = output[1:].view(-1, output.shape[-1])trg = trg[1:].view(-1)loss = criterion(output, trg)epoch_loss += loss.item()return epoch_loss / len(iterator)def epoch_time(start_time: int,end_time: int):elapsed_time = end_time - start_timeelapsed_mins = int(elapsed_time / 60)elapsed_secs = int(elapsed_time - (elapsed_mins * 60))return elapsed_mins, elapsed_secsN_EPOCHS = 10
CLIP = 1best_valid_loss = float('inf')for epoch in range(N_EPOCHS):start_time = time.time()train_loss = train(model, train_iterator, optimizer, criterion, CLIP)valid_loss = evaluate(model, valid_iterator, criterion)end_time = time.time()epoch_mins, epoch_secs = epoch_time(start_time, end_time)print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s')print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}')print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}')test_loss = evaluate(model, test_iterator, criterion)print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')Out:
Epoch: 01 | Time: 0m 35sTrain Loss: 5.667 | Train PPL: 289.080Val. Loss: 5.201 | Val. PPL: 181.371
Epoch: 02 | Time: 0m 35sTrain Loss: 4.968 | Train PPL: 143.728Val. Loss: 5.096 | Val. PPL: 163.375
Epoch: 03 | Time: 0m 35sTrain Loss: 4.720 | Train PPL: 112.221Val. Loss: 4.989 | Val. PPL: 146.781
Epoch: 04 | Time: 0m 35sTrain Loss: 4.586 | Train PPL: 98.094Val. Loss: 4.841 | Val. PPL: 126.612
Epoch: 05 | Time: 0m 35sTrain Loss: 4.430 | Train PPL: 83.897Val. Loss: 4.809 | Val. PPL: 122.637
Epoch: 06 | Time: 0m 35sTrain Loss: 4.331 | Train PPL: 75.997Val. Loss: 4.797 | Val. PPL: 121.168
Epoch: 07 | Time: 0m 35sTrain Loss: 4.240 | Train PPL: 69.434Val. Loss: 4.694 | Val. PPL: 109.337
Epoch: 08 | Time: 0m 35sTrain Loss: 4.116 | Train PPL: 61.326Val. Loss: 4.714 | Val. PPL: 111.452
Epoch: 09 | Time: 0m 35sTrain Loss: 4.004 | Train PPL: 54.815Val. Loss: 4.563 | Val. PPL: 95.835
Epoch: 10 | Time: 0m 36sTrain Loss: 3.922 | Train PPL: 50.519Val. Loss: 4.452 | Val. PPL: 85.761
| Test Loss: 4.456 | Test PPL: 86.155 |相关文章:

使用 TorchText 进行语言翻译
使用 TorchText 进行语言翻译 本教程说明如何使用torchtext的几个便捷类来预处理包含英语和德语句子的著名数据集的数据,并使用它来训练序列到序列模型,并注意将德语句子翻译成英语 。 它基于 PyTorch 社区成员 Ben Trevett 的本教程,并由 …...

SpringBoot整合SSMP小demo
创建项目 spring web,mybatis,mysql勾选 加入mp和druid,依赖见SpringBoot基础认识_阳光明媚UPUP的博客-CSDN博客 yml数据源 server:port: 81 spring:datasource:druid: #整合方式配置driver-class-name: com.mysql.jdbc.Driverurl: jdbc:m…...

51单片机--红外遥控
文章目录 红外遥控的介绍硬件电路NEC编码外部中断红外遥控实例代码 红外遥控的介绍 红外遥控是一种无线、非接触控制技术,通过使用红外线来传送控制信号。它具有抗干扰能力强、信息传输可靠、功耗低、成本低、易实现等显著优点,因此被广泛应用于各种电子…...

【图像分类】CNN+Transformer结合系列.2
介绍几篇利用CNNTransformer实现图像分类的论文:CMT(CVPR2022),MaxViT(ECCV2022),MaxViT(ECCV2022),MPViT(CVPR2022)。主要是说明Transformer的局限性&#x…...
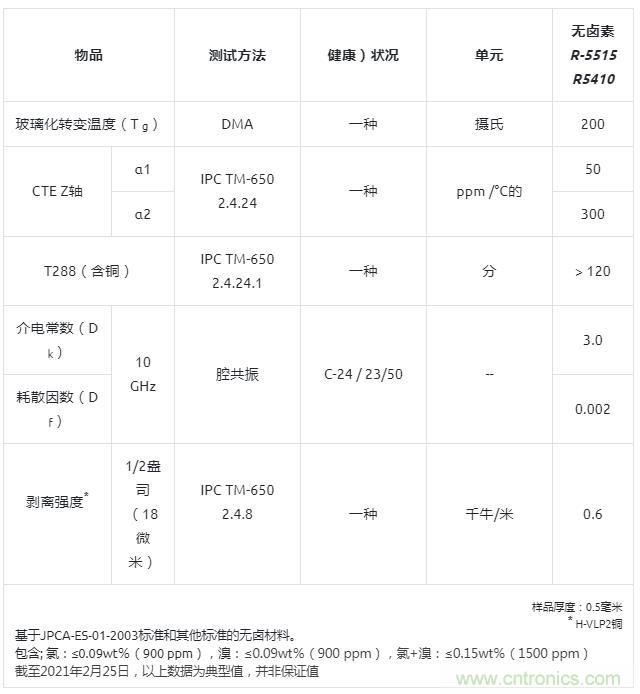
用于毫米波天线的新型无卤素超低传输损耗多层电路板R-5410
3月3日消息,松下公司宣布,其工业解决方案公司已经实现了R-5410的商业化,这是一种无卤素、超低传输损耗的多层电路板(MLCB)材料,适用于毫米波天线。将于2021年3月开始量产。 毫米波雷达是汽车、通信等行业的…...

java数据算法-汉诺塔
1、有三根相邻的柱子,标号为A,B,C。 2、A柱子上从下到上按金字塔状叠放着n个不同大小的圆盘。 3、现在把所有盘子一个一个移动到柱子C上,并且每次移动同一根柱子上都不能出现大盘子在小盘子上方。 题解步骤 1、当n1时; 将1号从A移动到C即…...

[QT编程系列-35]:数据存储 - JSON格式配置数据的存储与通知
目录 1. QJsonObject 2 QJsonDocument 3 JSON本文格式 4. JSON示例 5. JASON配置文件示例 1. QJsonObject QJsonObject 是Qt的类之一,用于表示 JSON 对象。 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式࿰…...

【Spring】Spring 中事务的实现
目录 1.编程式事务(手动编写代码)2.声明式事务(利用注解)2.1 Transactional作用范围2.2 Transactional参数说明2.3 Transactional工作原理 3.Spring 中设置事务隔离级别3.1 事务四大特性ACID3.2 事务的隔离级别3.2 Spring中设置事…...
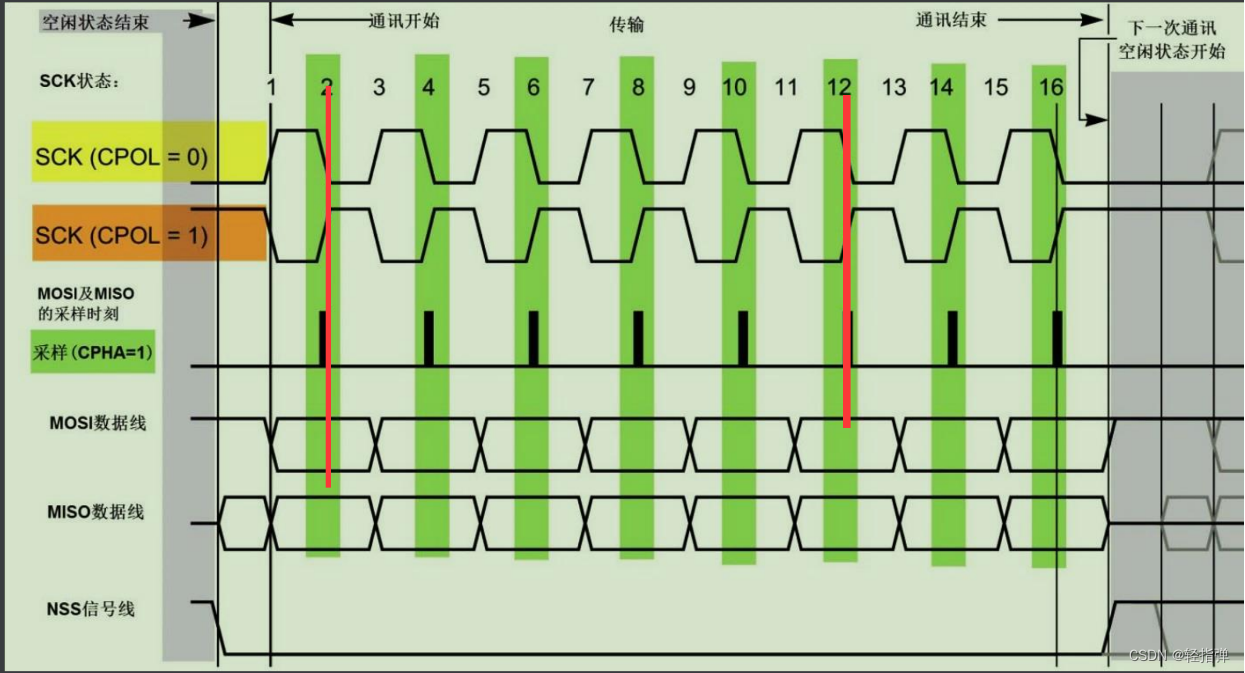
Linux 学习记录60(ARM篇)
Linux 学习记录60(ARM篇) 本文目录 Linux 学习记录60(ARM篇)一、SPI总线1. 概念2. 硬件连接 二、SPI总线协议三、SPI总线通信模式四、对比IIC总线和SPI总线1. 相同点2. 不同点 思维导图 一、SPI总线 1. 概念 1、SPI总结是Motorola首先提出的全双工三线/四线同步串行总线 2、采…...
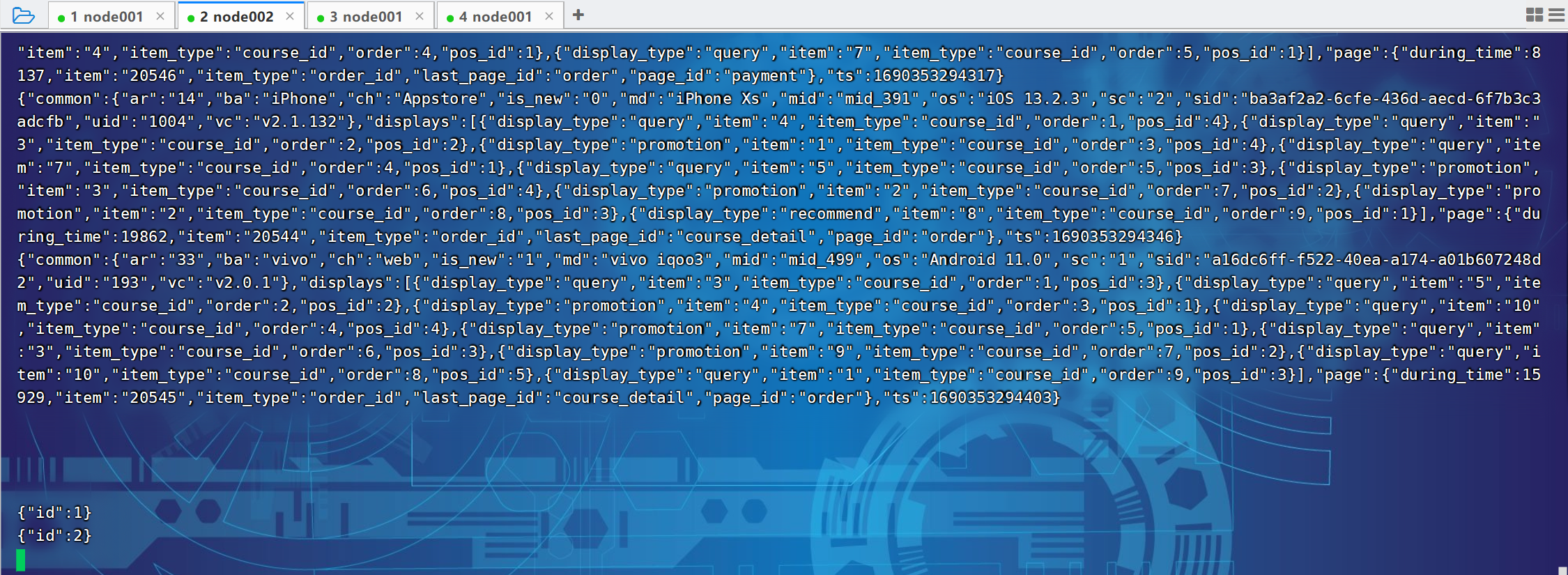
尚硅谷大数据项目《在线教育之采集系统》笔记002
视频地址:尚硅谷大数据项目《在线教育之采集系统》_哔哩哔哩_bilibili 目录 P032 P033 P033 P034 P035 P036 P032 P033 # 1、定义组件,为各组件命名 a1.sources r1 a1.channels c1 a1.sinks - k1# 2、配置sources,描述source a1.sour…...

校园跑腿小程序功能分享
提起校园跑腿小程序大家都不陌生,尤其是对上大学的伙伴们来说,更是熟悉得不能再熟悉了,和我们的生活息息相关,密不可分。 对于现在的年轻人来说,网购是非常简单和方便的一种购物方式,随之快递也会越来越多。在我们国家…...
PHP8的变量-PHP8知识详解
昨天我们讲解了PHP8的常量,今天讲解PHP8的变量。常量有定义常量和预定义常量,变量呢?那就没有定义变量了,那叫给变量赋值,但是还是有预定义变量的。下面就给大家讲解什么是变量、变量赋值及使用及预定义变量。 一、什么…...
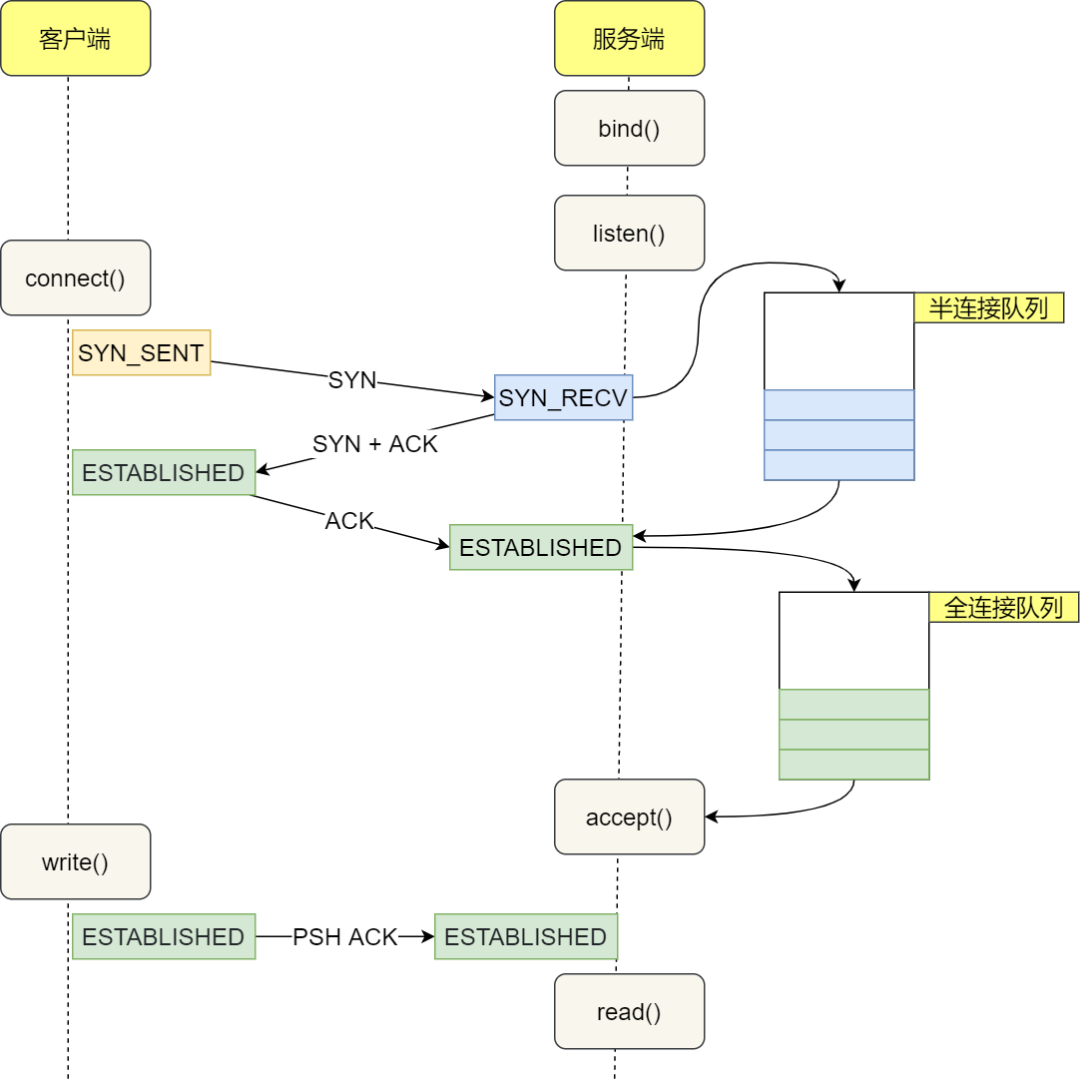
图解TCP 三次握手和四次挥手的高频面试题(2023最新版)
大家好,最近重新整理了一版 TCP 三次握手和四次挥手的面试题(2023最新版)。 ----- 任 TCP 虐我千百遍,我仍待 TCP 如初恋。 巨巨巨巨长的提纲,发车!发车! img TCP 基本认识 TCP 头格式有哪些…...
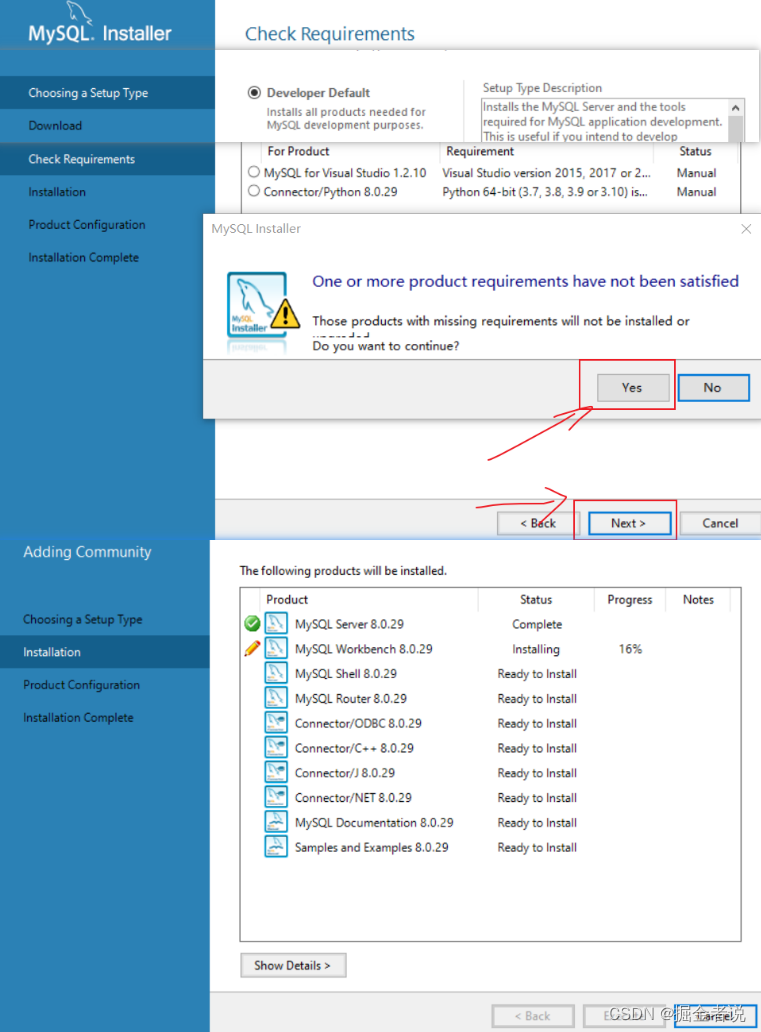
【mysql】Win10安装配置MySQL8.0简要
下载 MySQL官网下载安装包 安装...

SQL SERVER使用发布订阅同步数据库遇到的坑
可能遇到的各种坑 1.在执行 xp_cmdshell 的过程中出错。调用 ‘CreateProcess’ 失败,错误代码: ‘5’ 网上有各种解决办法,包括改本地安全策略,将sql server服务的网络权限改为本机系统,改cmd用户的读写权限,退出360…...
3个命令定位CPU飙高
top 指令找出消耗CPU最厉害的那个进程的pid top -H -p 进程pid 找出耗用CPU资源最多的线程pid printf ‘0x%x\n’ 线程pid 将线程pid转换为16进制 结合jstack 找出哪个代码有问题 jstack 进程pid | grep 16进制的线程pid -A 多少行日志 jstack 进程pid | grep 16进制的线程…...
Java版知识付费 Spring Cloud+Spring Boot+Mybatis+uniapp+前后端分离实现知识付费平台免费搭建
提供职业教育、企业培训、知识付费系统搭建服务。系统功能包含:录播课、直播课、题库、营销、公司组织架构、员工入职培训等。 提供私有化部署,免费售后,专业技术指导,支持PC、APP、H5、小程序多终端同步,支持二次开发…...
使用多数据源dynamic-datasource-spring-boot-starter遇到的问题记录
记录使用多数据源dynamic-datasource-spring-boot-starter遇到的问题: 1、工程启动失败 缺少clickhouse连接驱动,引入对应的maven依赖 <!--ck连接驱动--><dependency><groupId>ru.yandex.clickhouse</groupId><artifactId>…...

构建语言模型:BERT 分步实施指南
学习目标 了解 BERT 的架构和组件。了解 BERT 输入所需的预处理步骤以及如何处理不同的输入序列长度。获得使用 TensorFlow 或 PyTorch 等流行机器学习框架实施 BERT 的实践知识。了解如何针对特定下游任务(例如文本分类或命名实体识别)微调 BERT。为什么我们需要 BERT? 正…...
⛳ Java多线程 一,线程基础
线程基础 ⛳ Java多线程 一,线程基础🐾 一,线程基础💭 1.1,什么是程序,进程,线程🏭 1.2,什么是并行和并发👣 1.3,线程使用的场景🎨 1.…...

【行为检测】基于matlab和交互多模型IMM过滤进行自动驾驶异常行为检测【含Matlab源码 15448期】含报告
💥💥💥💥💥💥💞💞💞💞💞💞💞💞欢迎来到海神之光博客之家💞💞💞Ὁ…...

高效检索句子:基于 SQLite FTS5 的关键词快速匹配方案
std::filesystem::replace_extension 仅修改路径对象的逻辑表示,不更改磁盘文件;真正改后缀需配合 fs::rename,且须检查目标是否存在、文件是否为常规文件,并注意跨卷、文件占用等系统限制。std::filesystem::replace_extension 为…...

基于MCP协议构建AI驱动的企业安全自动化平台
1. 项目概述:一个连接AI与安全工具的桥梁最近在折腾AI助手(比如Claude Desktop、Cursor)的扩展能力时,发现了一个挺有意思的项目:sanyambassi/thales-cdsp-crdp-mcp-server。乍一看这个仓库名,又是Thales&a…...

数据笔记:LargeST——如何构建与评估一个面向未来的大规模交通预测基准数据集
1. 为什么我们需要LargeST这样的交通预测基准数据集 交通预测是智慧城市建设的核心技术之一,但长期以来这个领域面临一个尴尬局面:算法模型越来越复杂,却缺乏足够规模和质量的数据来验证其真实效果。这就像给赛车手一辆玩具车来测试性能——模…...

Python异步编程与Discord机器人开发:pincer库实战指南
1. 项目概述与核心价值最近在折腾一个游戏服务器的后端,发现处理实时通信和状态同步这块儿,用传统的HTTP轮询或者WebSocket裸写,代码很快就变得又臭又长,维护起来简直是噩梦。就在我头疼的时候,社区里一个叫pincer的项…...

避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战
避开这5个坑,你的癫痫脑电AI模型准确率能翻倍:从数据标注到特征工程实战 在医疗AI领域,癫痫脑电信号分析一直是个充满挑战的课题。许多开发者满怀信心地构建模型,却在验证阶段遭遇性能瓶颈——准确率停滞不前,误报率居…...

终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹
终极macOS清理神器:Pearcleaner 3步彻底卸载应用不留痕迹 【免费下载链接】Pearcleaner A free, source-available and fair-code licensed mac app cleaner 项目地址: https://gitcode.com/gh_mirrors/pe/Pearcleaner 你是否曾将macOS应用拖入废纸篓后&…...

别再死记硬背了!用Python模拟超前进位加法器,直观理解其速度优势
用Python模拟超前进位加法器:从硬件原理到算法思维的跨越 在计算机科学和电子工程交叉领域,加法器是最基础却又最精妙的设计之一。传统教学中,我们往往通过抽象的电路图来理解超前进位加法器(CLA)的速度优势࿰…...

深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化
深度解析:Performance-Fish如何通过四级缓存架构实现《环世界》400%性能优化 【免费下载链接】Performance-Fish Performance Mod for RimWorld 项目地址: https://gitcode.com/gh_mirrors/pe/Performance-Fish Performance-Fish是《环世界》(Rim…...

Applite:告别命令行!macOS软件管理的图形化终极解决方案
Applite:告别命令行!macOS软件管理的图形化终极解决方案 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为Homebrew复杂的命令行操作而头疼吗&…...