Redis学习---大数据技术之Redis(NoSQL简介、Redis简介、Redis安装、五大数据类型、相关配置、持久化)

星光下的赶路人star的个人主页
毅力是永久的享受
文章目录
- 1、NoSQL
- 1.1 NoSQL数据库
- 1.1.1 NoSQL是什么
- 1.1.2 NoSQL的特点
- 1.1.3 NoSQL的适用场景
- 1.1.4 NoSQL的不适场景
- 1.2 NoSQL家族
- 2、Redis简介
- 2.1 Redis官网
- 2.2 Redis是什么
- 2.3 Redis的应用场景
- 2.3.1 配合关系型数据库做高速缓存
- 2.3.2 大数据场景
- 2.3.3 利用其多样的数据结构储存特定的数据
- 3、Redis安装
- 3.1 关于Redis版本
- 3.2 安装
- 3.3 查看安装目录/home/zhm/bin
- 3.4 Redis的启动
- 3.5 客户端访问
- 3.6 关闭Redis服务
- 3.7 Redis默认16个库
- 4、Redis的五大数据类型
- 4.1 帮助手册
- 4.2 Redis键(key)
- 4.3 String
- 4.3.1 特点
- 4.3.2 常用操作
- 4.4 List
- 4.4.1 特点
- 4.4.2 常用操作
- 4.5 set
- 4.5 1 特点
- 4.5.2 常用操作
- 4.6 Hash
- 4.6.1 特点
- 4.6.2 分析一个问题: 现有一个User 对象,在Redis中如何存?
- 4.6.3 常用操作
- 4.7 zset
- 4.7.1 特点
- 4.7.2 常用操作
- 5、Redis的相关配置
- 6、Jedis
- 6.1 环境准备
- 6.2 基本测试
- 7、Redis持久化
- 7.1 两种方式
- 7.2 RDB(Redis DataBase)
- 7.2.1 RDB是什么
- 7.2.2 如何执行持久化
- 7.2.3 RDB文件
- 7.2.4 RDB保存策略
- 7.2.5 手动保存
- 7.2.6 RDB备份恢复
- 7.2.7 RDB其他配置
- 7.2.8 RDB优缺点
- 7.3 AOF(Append Only File)
- 7.3.1 AOF是什么
- 7.3.2 开启AOF
- 7.3.3 AOF同步频率
- 7.3.4 AOF文件损坏恢复
- 7.3.5 AOF备份
- 7.3.6 Rewrite
- 7.3.7 AOF的优缺点
- 7.4 持久化的优先级
- 7.5 RDB和AOF用哪个号
1、NoSQL
1.1 NoSQL数据库
1.1.1 NoSQL是什么
1、NoSQL(Not Only SQL),意思是“不仅仅是SQL”,泛指非关系型的数据库。
2、NoSQL不拘泥于关系型数据库的设计范式,放弃了通用的技术标准,为某一领域特定场景而设计,从而使性能、容量、扩展性达到了一定程度的突破。
1.1.2 NoSQL的特点
1、不遵循SQL标准
2、不支持ACID
3、远超于SQL的性能
1.1.3 NoSQL的适用场景
1、对数据高并发的读写
2、海量数据的读写
3、对数据高可扩展的
1.1.4 NoSQL的不适场景
1、需要事务支持
2、基于sql的结构化查询储存,处理复杂的关系,需要即时查询
3、用不着sql的和·用了sql也不行的情况,清考虑用NoSQL。
1.2 NoSQL家族
1、Memcached
(1)很早出现的NoSQL数据库
(2)数据都在内存中,一般不持久化
(3)支持简单的key-value模式,数据类型支持单一
(4)一般是作为缓存数据库辅助持久化的数据库
2、Redis
(1)几乎覆盖了Memcached的绝大部分功能
(2)数据都在内存中,支持持久化,主要用作备份恢复
(3)支持丰富的数据类型(value,因为所有key都是String类型),例如string,list,set,zset,hash等
3、mongoDB
(1)高性能、开源、模式自由的文档型数据库
(2)数据都在内存中,如果内存不足,把不常用的数据保存到硬盘
(3)虽然是key-value模式,但是对value(尤其是json)提供了丰富的查询功能
(4)支持二进制数据及大型对象
(5)可以根据数据的特点替代RDBMS(关系数据库管理系统),成为独立的数据库。或者配合RDBMS,存储特定的数据
4、HBase
(1)HBase是Haddop项目的数据库,主要用于对大量数据进行随机、实时的读写操作。
(2)HBase能支持到数十亿行×百万列的数据表
5、Cassandra
(1)Cassandra用于管理由大量商用服务器构建起来的庞大集群上的海量数据集(PB级)
6、Neo4j
(1)Neo4j是基于图结构的数据库,一般用于构建社交网络、交通网络、地图等
2、Redis简介
2.1 Redis官网
1、Redis官方网站 http://Redis.io
2、Redis中文官方网站 http://www.Redis.net.cn
2.2 Redis是什么
1、Redis是一个开源的key-value储存系统。
2、它支持储存的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set)和hash(哈希类型)
3、Redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件
4、支持高可用和集群模式
2.3 Redis的应用场景
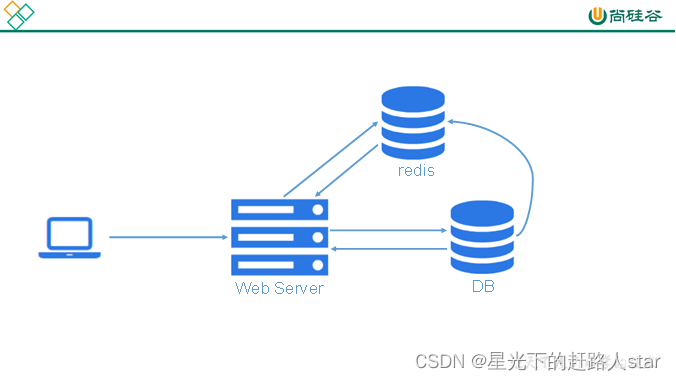
2.3.1 配合关系型数据库做高速缓存
1、高频次,热门访问的数据,降低数据库IO
2、经典的Cache Aside Pattern(旁路缓存模式)
2.3.2 大数据场景
1、缓存数据
(1)需要高频次访问
(2)持久化数据访问较慢
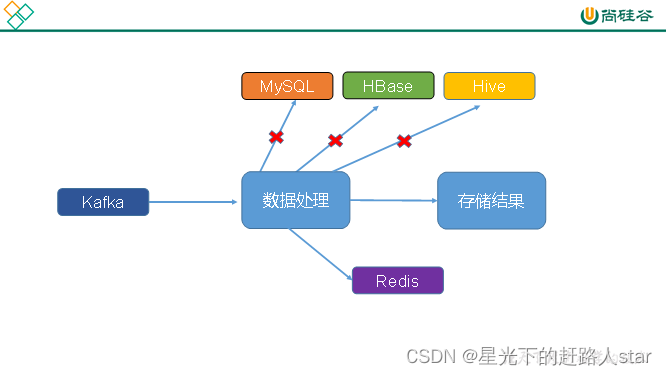
2、临时数据
(1)高频次
(2)读写时效高
(3)总数据量不大
(4)临时性
(5)用key查询

3、计算结果
(1)高频次写入
(2)高频次查询
(3)总数据量不大

2.3.3 利用其多样的数据结构储存特定的数据
(1)最新N个数据—>通过List实现按自然事件排序的数据
(2)排行榜,TopN—>利用zset(有序集合)
(3)时效性的数据,比如手机验证码—>Expire过期
(4)计数器,秒杀—>原子性,自增方法INCR、DECR
(5)去除大量数据中的重复数据—>利用set集合
(6)构建队列—>利用list集合
(7)发布订阅消息系统—>pub/sub模式
3、Redis安装
3.1 关于Redis版本
不用考虑在Windows环境下对Redis的支持,Redis官方没有提供对Windows环境的支持,是微软的开源小组开发了对Redis对Windows的支持。
3.2 安装
1、安装新版gcc编译器
sudo yum -y install gcc-c++
2、上传redis-6.2.1.tar.gz安装包到/opt/software目录下
3、解压redis-6.2.1.tar.gz到/opt/module目录下
4、之后进入安装包的src目录,编辑Makefile文件,修改软件安装路径如下:
#修改如下
PREFIX?=/home/zhm#然后执行如下命令make && make install
3.3 查看安装目录/home/zhm/bin
(1)Redis-benchmark:性能测试工具,可以在自己本子运行,看看自己本子性能如何(服务启动起来后执行)
(2)Redis-check-aof:修复有问题的AOF文件
(3)Redis-check-dump:修复有问题的RDB文件
(4)Redis-sentinel:启动Redis哨兵服务
(5)redis-server:Redis服务器启动命令
(6)redis-cli:客户端,操作入口
3.4 Redis的启动
1、拷贝一份redis.conf配置文件到工作目录
mkdir myrediscd myrediscp /opt/module/redis-6.2.1/redis.conf .
2、绑定主机IP,修改bind属性
vim redis.confbind 0.0.0.0
3、指定配置文件进行启动
redis-server redis.conf
3.5 客户端访问
1、使用redis-cli 命令访问启动好的Redis,默认端口为6379
redis-cli
2、如果有多个Redis客户端同时启动,或者端口做了修改,则需要指定端口号访问
redis-cli -p 6379
3、如果访问非本机的Redis,需要指定host来访问
redis-cli -h 127.0.0.1 -p 6379
4、通过ping命令测试验证
127.0.0.1:6379> ping
PONG
3.6 关闭Redis服务
如果还未通过客户端访问,可直接redis-cli shutdown
redis-cli shutdown
如果已经进入客户端,直接shutdown即可
127.0.0.1:6379> shutdown
3.7 Redis默认16个库
1、Redis默认创建16个库,每个库对应一个下标,从0开始。
通过客户端连接默认进入到0号库,推荐只使用0号库
2、使用命令select库的下标来切换数据库
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]>
4、Redis的五大数据类型
4.1 帮助手册
http://redisdoc.com/
4.2 Redis键(key)
1、查看当前库的所有键
127.0.0.1:6379> keys *
2、判断某个键是否存在
127.0.0.1:6379> exists <key>
3、查看键对应的value的类型
127.0.0.1:6379> type <key>
4、删除某个键
127.0.0.1:6379> del <key>
5、设置过期时间
expire <key> <second>
6、查看过期时间,-1表示永不过期,-2表示已过期
ttl <key>
7、查看当前库中key的数量
dbsize
8、清空当前库
flushdb
9、清空所以库
flushall
4.3 String
4.3.1 特点
1、String是Redis最基本的类型,适合保存单值类型,即一个key对应一个value。
2、String类型是二进制安全的,意味着Redis的String可以包含任何数据。比如jpg图片或者序列化得对象。
3、一个Redis中字符串value最多可以是512M。
4.3.2 常用操作
1、添加键值对
set <key> <value>
2、获取键的值
get <key>
3、将给定的追加到原值的末尾
append <key> <value>
4、获取值的长度
strlen <key>
5、当key不存在时设置key的值
setnx <key> <value>
6、将key中储存的数据值增1
incr <key>
7、将key中储存的数字值减一
decr <key>
8、将key中储存的数字值安装指定步长增长
incrby <key> <步长>
9、将key中储存的数字值按照指定步长减
decrby <key> <步长>
10、同时添加一个或者多个key
mset <k1> <v1> <k2> <v2>
11、同时获取一个或者多个key的值
mget <k1> <k2> <k3>
12、同时添加一个或者多个key,当且仅当所有给定的key都不存在
msetnx <k1> <v1> <k2> <v2>
13、获取值的子串
getrange <key> <start> <end>
14、从指定的开始位置覆盖旧值
setrange <key> <start> <value>
15、同时设置值和过期时间
setex <key> <seconds> <value>
16、设置新值的同时获取旧值
getset <key> <value>
4.4 List
4.4.1 特点
1、单键多值
2、Redis List是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。
3、它的底层实际是个双向链表,对两端的操作性能很高,通过索引下标的操作中间的节点性能会较差。
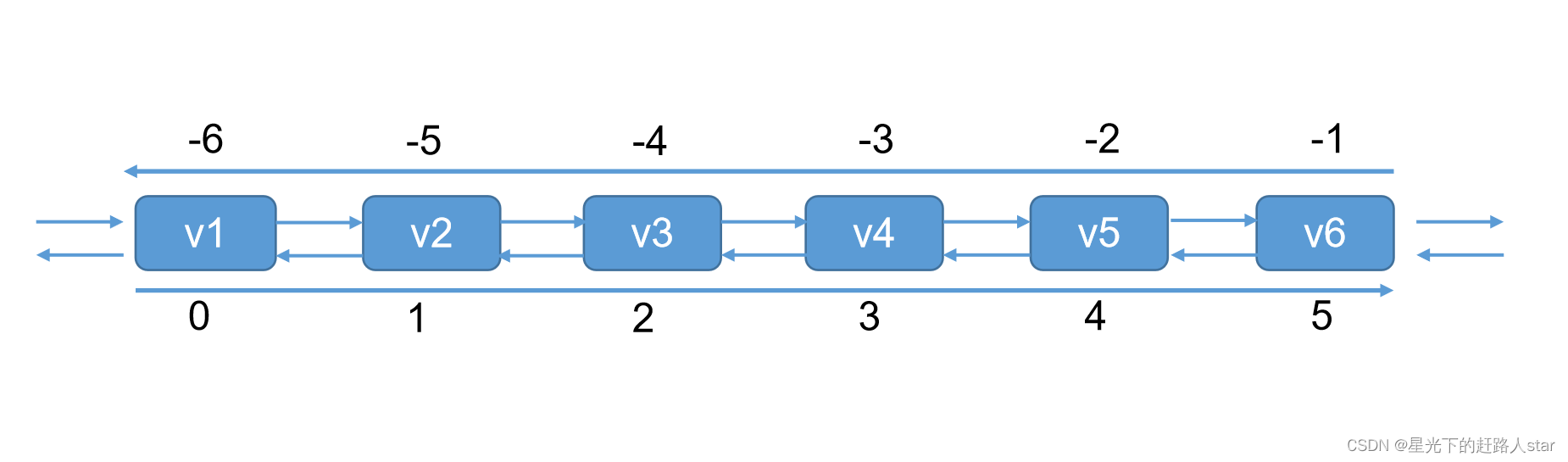
4.4.2 常用操作
1、从左边插入一个或多值
lpush <key> <element...>
2、从右边插入一个或多个值
rpush <key> <element...>
3、从左边删除一个值(值在健在,值光键亡)
lpop <key>
4、从右边删除一个值
rpop <key>
5、从key1列表右边删除一个值,插入到key2列表左边
rpoplpush <key1> <key2>
6、按照索引下标范围获取元素(从左到右)
lrange <key> <start> <stop>
7、按照索引下标获取元素(从左到右)
lindex <key> <index>
8、获取列表长度
llen <key>
9、在指定 的前面或者后面插入
llinsert <key> before|after <pivot> <element>
10、从左边删除count个指定的value
lrem <key> <count> <element>
4.5 set
4.5 1 特点
1、set中的元素是无序不重复的,当你需要存储一个列表数据,又不希望出现重复数据时,set是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的重要接口。
2、Redis的Set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
4.5.2 常用操作
1、将一个或者多个member元素加入到集合中,已经存在的member将被忽略
sadd <key> <member…>
2、取出集合的所有值
smemebers <key>
3、判断集合是否包含指定的member,包含返回1,不包含返回0
sismember <key> <member>
4、返回集合的元素个数
scard <key>
5、从集合中删除指定的元素
srem <key> <member…>
6、随机从集合中删除一个值,会从集合中删除值
spop <key>
7、随机从集合中取出n个值,不会从集合中删除
srandmember <key> <count>
8、返回多个集合的交集元素
sinter <key…>
9、返回多个集合的并集元素
sunion <key…>
10、返回多个集合的差集元素
sdiff <key…>
4.6 Hash
4.6.1 特点
1、Redis hash是一个键值对集合
2、Redis hash的值是由多个field和value组成的映射表
3、类似Java里面的Map<String,String>
4.6.2 分析一个问题: 现有一个User 对象,在Redis中如何存?
1、第一种方案: 用户ID为key ,VALUE为JavaBean序列化后的字符串
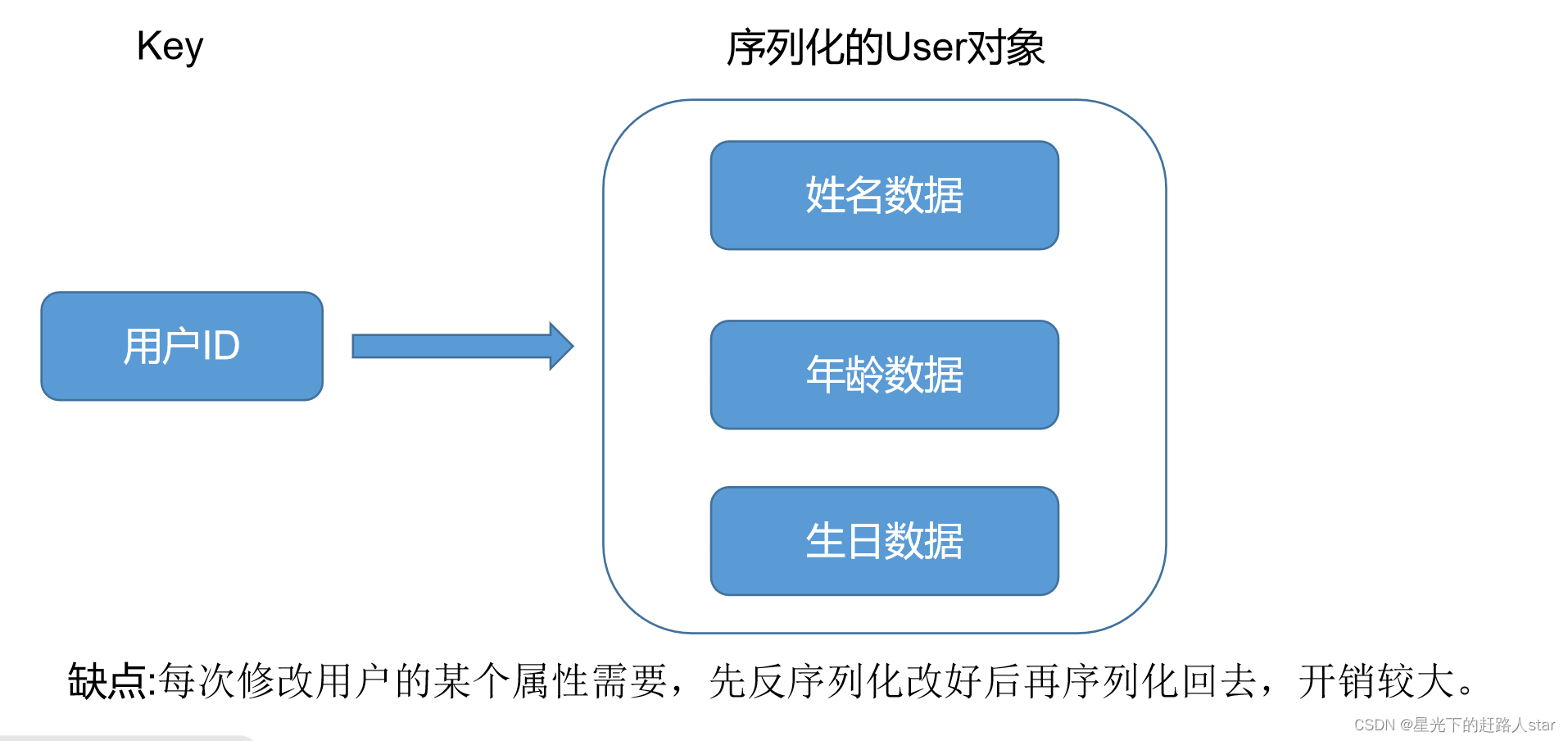
2、第二种方案: 用户ID+属性名作为key, 属性值作为Value.

3、第三种方案: 通过 key(用户ID) + field(属性标签) 就可以操作对应属性数据了,既不需要重复存储数据,也不会带来序列化和并发修改控制的问题

4.6.3 常用操作
1、给集合中添加指定的 -
hset <key> [<field> <value> …]
2、给集合中添加指定的 - ,当指定的field不存在时
hsetnx <key> <field> <value>
3、取出集合中指定field的value
hget <key> <field>
4、判断集合中是否存在指定的field
hexists <key> <field>
5、列出集合中所有的field
hkeys <key>
6、列出集合中所有的value
hvals <key>
7、给集合中指定filed的value值增加increment
hincrby <key> <field> <increment>
4.7 zset
4.7.1 特点
1、Redis有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集合。不同之处是有序集合的每个成员都关联了一个评分(score) ,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了 。
2、因为元素是有序的, 所以你也可以很快的根据评分(score)或者次序(position)来获取一个范围的元素。访问有序集合的中间元素也是非常快的,因此你能够使用有序集合作为一个没有重复成员的智能列表。
4.7.2 常用操作
1、往集合中添加指定的 member 及score
zadd <key> [<score> <member> … ]
2、从集合中取出指定下标范围的数据,正序取
zrange <key> <start> <stop> [WITHSCORES]
3、从集合中取出指定下标范围的数据,倒序取
zrevrange <key> <start> <stop> [WITHSCORES]
4、从集合中取出指定score范围的数据,默认从小到大
zrangebyscore <key> <min> <max> [WITHSCORES]
5、从集合中取出指定score范围的数据,从大到小
zrevrangebyscore <key> <max> <min> [WITHSCORES]
6、给集合中指定member的score增加increment
zincrby <key> <increment> <member>
7、删除集合中指定的member
zrem <key> <member…>
8、统计指定score范围的元素个数
zcount <key> <min> <max>
9、返回集合中指定member的排名,排名从0开始
zrank <key> <member>
5、Redis的相关配置
1、计量单位说明,大小写不敏感
# 1k => 1000 bytes
# 1kb => 1024 bytes
# 1m => 1000000 bytes
# 1mb => 1024*1024 bytes
# 1g => 1000000000 bytes
# 1gb => 1024*1024*1024 bytes
#
# units are case insensitive so 1GB 1Gb 1gB are all the same.
2、bind
默认情况bind=127.0.0.1只能接受本机的访问请求
不写的情况下,无限制接受任何ip地址的访问,产环境肯定要写你应用服务器的地址
如果开启了protected-mode,那么在没有设定bind ip且没有设密码的情况下,Redis只允许接受本机的请求
#bind 127.0.0.1
protected-mode no
3、port服务端口号
port 6379
4、damonize
是否为后台进程
port 6379
5、pidfile
存放pid文件的位置,每个实例会产生一个不同的pid文件
pidfile /var/run/redis_6379.pid
6、log file
日志文件存储位置
logfile ""
7、Database
设定库的数量默认16
databases 16
8、requirepass
设置密码
requirepass 123456127.0.0.1:6379> set k1 v1
(error) NOAUTH Authentication required.
127.0.0.1:6379> auth "123456"
OK
127.0.0.1:6379> set k1 v1
OK
127.0.0.1:6379> get k1
"v1"
9、maxmemory
设置Redis可以使用的内存量。一 旦到达内存使用上限,Redis将会试图移除内部数据,移除规则可以通过maxmemory-policy来指定。如果Redis无法根据移除规则来移除内存中的数据,或者设置了“不允许移除”,
那么Redis则会针对那些需要申请内存的指令返回错误信息,比如SET、LPUSH等。
# maxmemory <bytes>
10、maxmemory-policy
移除策略
# maxmemory-policy noeviction #volatile-lru:使用LRU算法移除key,只对设置了过期时间的键
#allkeys-lru:使用LRU算法移除key
#volatile-lfu :使用LFU策略移除key,只对设置了过期时间的键.
#allkeys-lfu :使用LFU策略移除key
#volatile-random:在过期集合中移除随机的key,只对设置了过期时间的键
#allkeys-random:移除随机的key
#volatile-ttl:移除那些TTL值最小的key,即那些最近要过期的key
#noeviction:不进行移除。针对写操作,只是返回错误信息
11、Maxmemory-samples
设置样本数量,LRU算法和最小TTL算法都并非是精确的算法,而是估算值,所以你可以设置样本的大小。一般设置3到7的数字,数值越小样本越不准确,但是性能消耗也越小。
# maxmemory-samples 5
6、Jedis
Jedis是Redis的Java客户端,可以通过Java代码的方式操作Redis
6.1 环境准备
1、添加依赖
<dependency><groupId>redis.clients</groupId><artifactId>jedis</artifactId><version>3.3.0</version>
</dependency>
6.2 基本测试
1、测试连通
public class JedisTest {public static void main(String[] args) {Jedis jedis = new Jedis("hadoop102",6379);String ping = jedis.ping();System.out.println(ping);}
}
2、连接池
连接池主要用来节省每次连接redis服务带来的连接消耗,将连接好的实例反复利用
public static JedisPool pool = null ;public static Jedis getJedis(){if(pool == null ){//主要配置JedisPoolConfig jedisPoolConfig =new JedisPoolConfig();jedisPoolConfig.setMaxTotal(10); //最大可用连接数jedisPoolConfig.setMaxIdle(5); //最大闲置连接数jedisPoolConfig.setMinIdle(5); //最小闲置连接数jedisPoolConfig.setBlockWhenExhausted(true); //连接耗尽是否等待jedisPoolConfig.setMaxWaitMillis(2000); //等待时间jedisPoolConfig.setTestOnBorrow(true); //取连接的时候进行一下测试 ping pongpool = new JedisPool(jedisPoolConfig,"hadoop102",6379) ;}return pool.getResource();
} public static void main(String[] args) {//Jedis jedis = new Jedis("hadoop202",6379);Jedis jedis = getJedis();String ping = jedis.ping();System.out.println(ping);}
7、Redis持久化
7.1 两种方式
Redis提供了两个不同形式的持久化方式RDB和AOF。
RDB为快照备份,会在备份时将内容中的所有数据持久化到磁盘的一个文件中。
AOF为日志备份,会将所有写操作命令记录在一个日志文件中。
7.2 RDB(Redis DataBase)
7.2.1 RDB是什么
在指定的时间间隔将内存中的数据集快照写入磁盘,也就是行话讲的Snapshot快照,
它恢复时是将快照文件直接读到内存里。
7.2.2 如何执行持久化
Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,待持久化过程都结束了,再用这个临时文件替换上次持久化好的文件。整个过程中,主进程是不进行然后IO操作的,这就确保了极高的性能如果需要进行大规模数据的恢复,且对数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效。RDB的缺点是最后一次持久化的数据可能丢失。
7.2.3 RDB文件
1、RDB保存的文件
在redis.conf中配置文件名称,默认为dump.rdb
2、RDB文件的保存路径
默认为Redis启动时命令行所在的目录下,也可以修改
7.2.4 RDB保存策略
# save <seconds> <changes># Will save the DB if both the given number of seconds and the given
# number of write operations against the DB occurred.
#
# In the example below the behaviour will be to save:
# after 900 sec (15 min) if at least 1 key changed
# after 300 sec (5 min) if at least 10 keys changed
# after 60 sec if at least 10000 keys changed
# Note: you can disable saving completely by commenting out all "save" lines.
save 900 1
save 300 10
save 60 10000
7.2.5 手动保存
1、save: 只管保存,其它不管,全部阻塞
2、bgsave:按照保存策略自动保存
3、shutdown时服务会立刻执行备份后再关闭
4、flushall时会将清空后的数据备份
7.2.6 RDB备份恢复
1、备份
将dump.rdb文件拷贝到要备份的位置
2、恢复
关闭Redis,把备份的文件拷贝到工作目录下,启动redis,备份数据会直接加载。
7.2.7 RDB其他配置
1、进行rdb保存时,将文件压缩
rdbcompression yes
2、文件校验
在存储快照后,还可以让Redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能
rdbchecksum yes
7.2.8 RDB优缺点
1、优点
节省磁盘空间,恢复速度快.
2、缺点
虽然Redis在fork时使用了写时拷贝技术,但是如果数据庞大时还是比较消耗性能。在备份周期在一定间隔时间做一次备份,所以如果Redis意外down掉的话,就会丢失最后一次快照后的所有修改
7.3 AOF(Append Only File)
7.3.1 AOF是什么
以日志的形式来记录每个写操作,将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不可以改写文件,Redis启动之初会读取该文件重新构建数据,换言之,Redis重启的话就根据日志文件的内容将写指令从前到后执行一次以完成数据的恢复工作。
7.3.2 开启AOF
1、AOF默认不开启,需要手动在配置文件中配置
appendonly no
2、AOF文件
appendfilename "appendonly.aof"
3、AOF文件保存的位置与RDB的路径一致
dir ./
7.3.3 AOF同步频率
# no: don't fsync, just let the OS flush the data when it wants. Faster.
# always: fsync after every write to the append only log. Slow, Safest.
# everysec: fsync only one time every second. Compromise.
7.3.4 AOF文件损坏恢复
redis-check-aof --fix appendonly.aof
7.3.5 AOF备份
AOF的备份机制和性能虽然和RDB不同, 但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝到Redis工作目录下,启动系统即加载
7.3.6 Rewrite
AOF采用文件追加方式,文件会越来越大为避免出现此种情况,新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的重写,只保留可以恢复数据的最小指令集.可以使用命令bgrewriteaof手动开始重写。
重写虽然可以节约大量磁盘空间,减少恢复时间。但是每次重写还是有一定的负担的,因此设定Redis要满足一定条件才会进行重写。
系统载入时或者上次重写完毕时,Redis会记录此时AOF大小,设为base_size,如果Redis的AOF当前大小>= base_size +base_size*100% (默认)且当前大小>=64mb(默认)的情况下,Redis会对AOF进行重写。
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
7.3.7 AOF的优缺点
1、优点:
(1)备份机制更稳健,丢失数据概率更低。
(2)可读的日志文本,通过操作AOF文件,可以处理误操作。
2、缺点:
(1)比起RDB占用更多的磁盘空间
(2)恢复备份速度要慢
(3)每次写都同步的话,有一定的性能压力
(4)存在个别bug,造成恢复不能
7.4 持久化的优先级
AOF的优先级大于RDB,如果同时开启了AOF和RDB,Redis服务启动时恢复数据以AOF为准.
7.5 RDB和AOF用哪个号
1、官方推荐两个都启用。
2、如果对数据不敏感,可以选单独用RDB
3、不建议单独用 AOF,因为可能会出现Bug。
4、如果只是做纯内存缓存,可以都不用
![]()
您的支持是我创作的无限动力
![]()
希望我能为您的未来尽绵薄之力
![]()
如有错误,谢谢指正;若有收获,谢谢赞美
相关文章:

Redis学习---大数据技术之Redis(NoSQL简介、Redis简介、Redis安装、五大数据类型、相关配置、持久化)
星光下的赶路人star的个人主页 毅力是永久的享受 文章目录 1、NoSQL1.1 NoSQL数据库1.1.1 NoSQL是什么1.1.2 NoSQL的特点1.1.3 NoSQL的适用场景1.1.4 NoSQL的不适场景 1.2 NoSQL家族 2、Redis简介2.1 Redis官网2.2 Redis是什么2.3 Redis的应用场景2.3.1 配合关系型数据库做高速…...
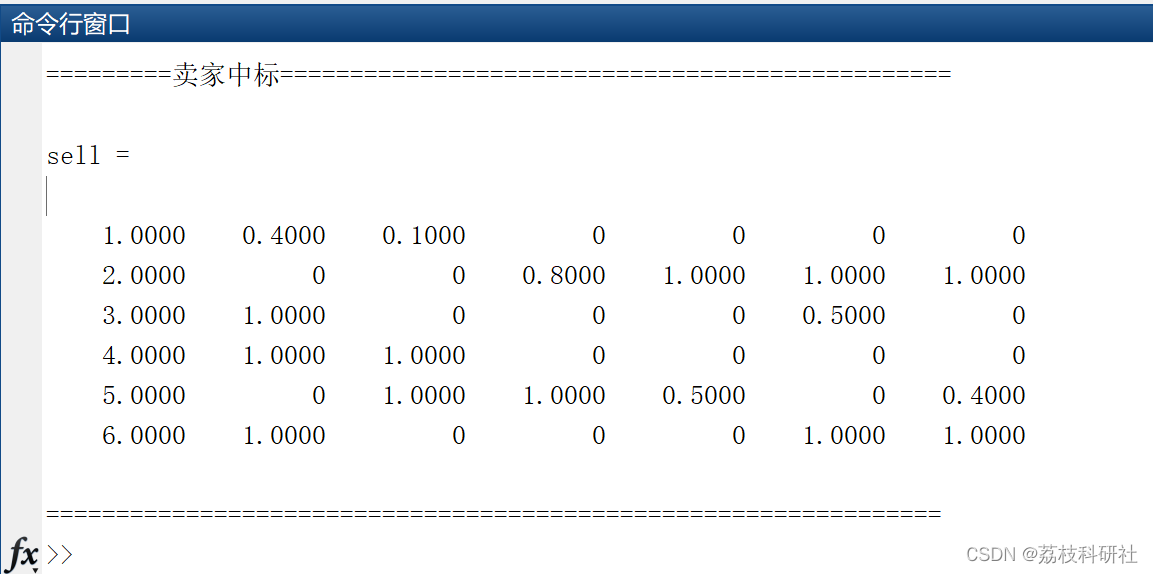
基于组合双向拍卖的共享储能机制研究(Matlab代码实现)
目录 💥1 概述 📚2 运行结果 2.1 算例数据 2.2 买家中标 2.3 卖家中标 🎉3 文献来源 🌈4 Matlab代码实现 💥1 概述 文献来源: 摘要:为满足共享储能中储能用户的互补性和替代性需求、解决常规单…...

服务机器人有哪些品类
服务机器人是指具备自主运动、感知环境、实现人机交互等能力的机器人,它可以被应用于不同的场景,如餐饮、医疗、物流等行业。根据其功能和应用场景的不同,服务机器人可以分为以下几类:1. 餐饮服务机器人 随着社会发展和人们需…...

3.netty和protobuf
1.ChannelGroup可以免遍历由netty提供,覆盖remove方法即可触发删除channel\ 2.群聊私聊 13.群聊私聊简单原理图 3.netty心跳检测机制,客户端对服务器有没有读写(读,写空闲) //IdleStateHandler(3,5,7,TimeUnite.SECONDS)是netty提供的检测状态的处理器,也加到pipeline,读,写,…...

NLP实践——Llama-2 多轮对话prompt构建
NLP实践——Llama-2 多轮对话prompt构建 1. 问题提出2. prompt的正确形式3. 效果测试4. 结尾 1. 问题提出 最近,META开源了Llama-2模型,受到了广泛的关注和好评,然而,在官方给的使用说明中,并没有对使用方法进行特别细…...
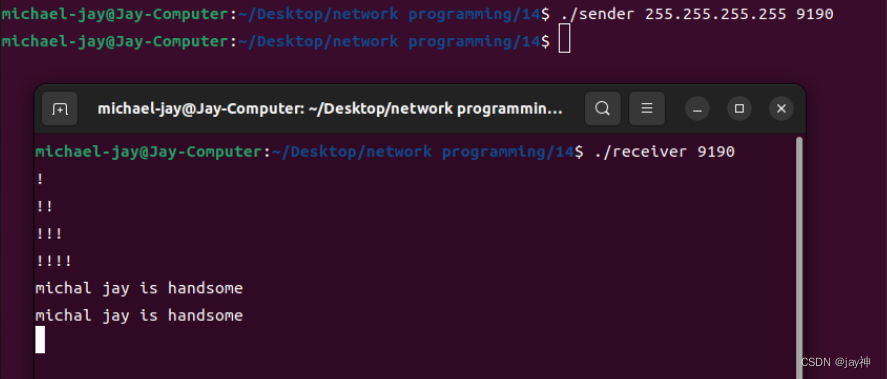
《TCP IP网络编程》第十四章
第 14 章 多播与广播 14.1 多播 多播(Multicast)方式的数据传输是基于 UDP 完成的。因此 ,与 UDP 服务器端/客户端的实现方式非常接近。区别在于,UDP 数据传输以单一目标进行,而多播数据同时传递到加入(注…...
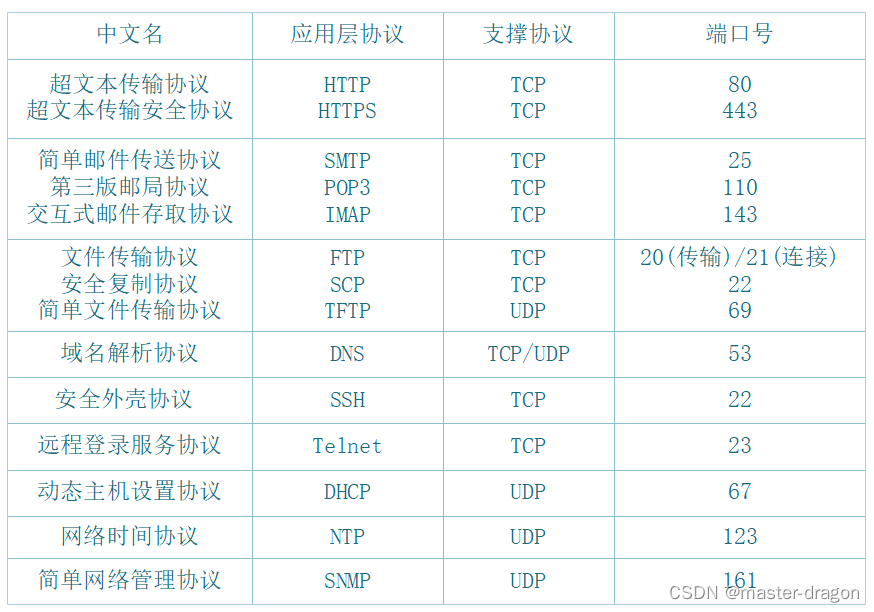
网络基础-认识每层的设备和每层的特点用途
目录 网络层次常见设备各层介绍数据链路层网络层传输层应用层 网络层次 常见设备 各层介绍 数据链路层 有了MAC地址。数据链路层工作在局域网中的,以帧为单位进行传输和处理数据。 网络层 网络层有了IP。不同的网络通过路由器连接成为互联网 路由器的功能: …...

【Linux操作系统】深入解析Linux定时任务调度机制-cronat指令
在Linux操作系统中,定时任务调度是一项重要的功能,它可以让用户在指定的时间或周期性地执行特定的任务。这种机制使得用户能够自动化地执行一些重复性工作,提高工作效率。本文将详细介绍Linux定时任务调度的原理、常用指令和代码示例…...
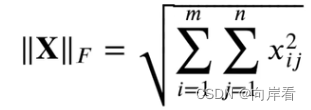
动手学深度学习(一)预备知识
目录 一、数据操作 1. N维数组样例 2. 访问元素 3. 基础函数 (1) 创建一个行向量 (2)通过张量的shape属性来访问张量的形状和元素总数 (3)reshape()函数 (4)创建全0、全1、…...
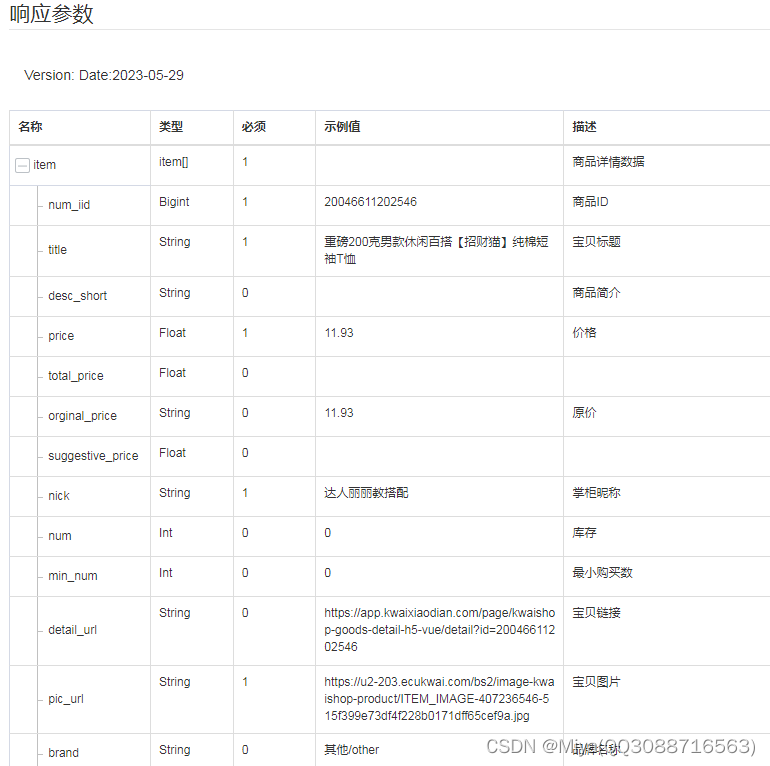
item_get-KS-获取商品详情
一、接口参数说明: item_get-根据ID取商品详情 ,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/ks/item_get 名称类型必须描述keyString是调用key(http://o0b.cn/…...
)
[华为OD] 最小传输时延(dijkstra算法)
明天就要面试了我也太紧张了吧 但是终于找到了一个比较好理解的dijkstra的python解法,让我快点把它背下来!!!! 文章目录 题目dijkstra算法的python实现python解答dfs解法dijkstra解法 题目 先把题目放出来 某通信网络…...

问道管理:总资产大于总市值好吗?
在财政领域,总财物和总市值是两个非常重要的指标。总财物是指公司所有的财物,包括固定财物、流动财物、无形财物等,而总市值则是指公司股票在商场上的总价值。当总财物大于总市值时,这是否是一个好的信号呢?咱们将从多…...
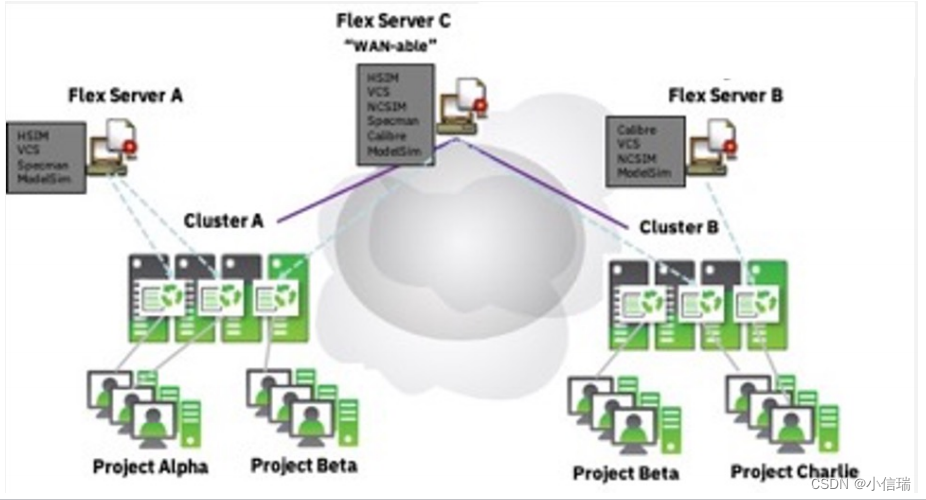
IBM Spectrum LSF (“LSF“ ,简称为负载共享设施) 用户案例
IBM Spectrum LSF (“LSF” ,简称为负载共享设施) 用户案例 IBM Spectrum LSF (“LSF” ,简称为负载共享设施) 软件是业界领先的企业级软件。 LSF 在现有异构 IT 资源之间分配工作,以创建共享,可扩展且容错的基础架构,…...
Pytorch深度学习-----神经网络之非线性激活的使用(ReLu、Sigmoid)
系列文章目录 PyTorch深度学习——Anaconda和PyTorch安装 Pytorch深度学习-----数据模块Dataset类 Pytorch深度学习------TensorBoard的使用 Pytorch深度学习------Torchvision中Transforms的使用(ToTensor,Normalize,Resize ,Co…...
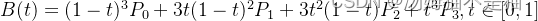
Gis入门,使用起止点和两个控制点生成三阶贝塞尔曲线(共四个控制点,线段转曲线)
前言 本章讲解如何在gis地图中使用起止点和两个控制点(总共四个控制点)生成三阶贝塞尔曲线。 二阶贝塞尔曲线请参考上一章《Gis入门,如何根据起止点和一个控制点计算二阶贝塞尔曲线(共三个控制点)》 贝塞尔曲线(Bezier curve)介绍 贝塞尔曲线(Bezier curve)是一种…...
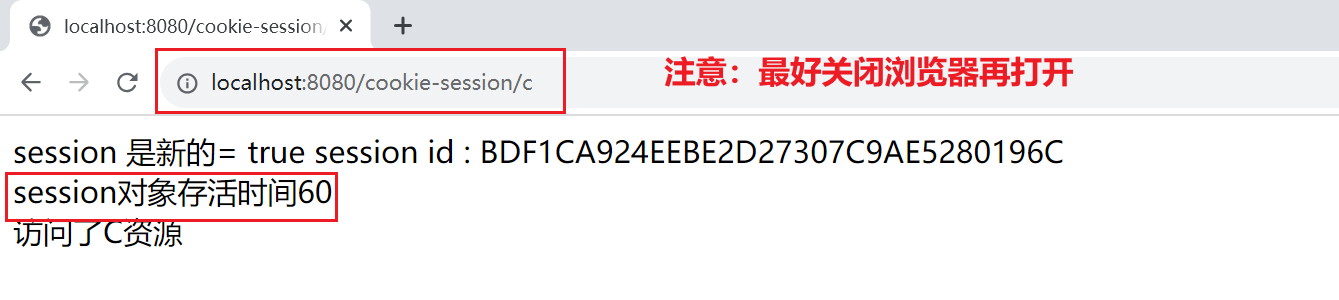
Web-7-深入理解Cookie与Session:实现用户跟踪和数据存储
深入理解Cookie与Session:实现用户跟踪和数据存储 今日目标 1.掌握客户端会话跟踪技术Cookie 2.掌握服务端会话跟踪技术Sesssion 1.会话跟踪技术介绍 会话:用户打开浏览器,访问web服务器的资源,会话建立,直到有一方断…...

Springboot设置Https
1、修改配置文件application.yml,并将*.jks放到resource目录下。 server:port: 8080ssl:key-store: classpath:*.jkskey-store-password: *key-store-type: JKSenabled: truekey-alias: boe.com.cn2、添加http转https的配置 Configuration public class TomcatCon…...
Windows 使用 Linux 子系统,轻轻松松安装多个linux
Windows Subsystem for Linux WSL 简称WSL,是一个在Windows 10\11上能够运行原生Linux二进制可执行文件(ELF格式)的兼容层。它是由微软与Canonical公司合作开发,其目标是使纯正的Ubuntu、Debian等映像能下载和解压到用户的本地计算机&#…...
中级课程——弱口令(认证崩溃)
文章目录 什么是弱口令密码生成器分类暴力破解万能密码测试环境工具 什么是弱口令 密码生成器 分类 暴力破解 万能密码 or true --测试环境 工具 九头蛇,超级弱口令爆破工具,bp,...

web自动化测试进阶篇05 ——— 界面交互场景测试
😏作者简介:博主是一位测试管理者,同时也是一名对外企业兼职讲师。 📡主页地址:【Austin_zhai】 🙆目的与景愿:旨在于能帮助更多的测试行业人员提升软硬技能,分享行业相关最新信息。…...

函数递归调用原理
1. 什么是递归 2. 递归的举例 3. 递归与迭代1. 什么是递归递归就是一种解决方法,在C语言中,递归就是函数调用自己。下面是一个简单的递归C语言程序:#include <stdio .h>int main(){printf("hello world\n");main();//main函数…...

NotebookLM时间线创建全解析,手把手教你用AI自动生成可交互知识图谱
更多请点击: https://intelliparadigm.com 第一章:NotebookLM时间线创建的核心价值与适用场景 NotebookLM 的时间线(Timeline)功能并非简单的时间戳罗列,而是将文档片段、引用来源与用户思考按真实发生顺序动态编织成…...

+86环境下“纸飞机“登录异常排查:第三方开源客户端的认证与网络适配测试
近期在针对一款基于 MTProto 协议的即时通讯工具进行客户端适配测试时,发现其官方版本在 86 号段环境下存在较为突出的登录与连接稳定性问题。本文记录问题复现过程,以及基于开源代码二次开发的优化实践。一、登录异常现象在 86 手机号、新设备登录场景下…...

用MATLAB手把手仿真超外差混频:从160MHz射频到40MHz中频的完整信号处理流程
MATLAB实战:超外差混频从160MHz射频到40MHz中频的工程级仿真指南 在无线通信系统设计中,超外差接收机架构因其优异的灵敏度和选择性,至今仍是射频前端的主流方案。本文将带您用MATLAB完整复现这一经典结构中的混频与滤波过程,特别…...

COCO数据集到底怎么用?从PyTorch和TensorFlow加载到可视化标注的完整代码示例
COCO数据集实战指南:从数据加载到可视化标注的全流程解析 计算机视觉领域的研究者和开发者们,当你开始构建目标检测或图像分割模型时,COCO数据集无疑是你最重要的训练资源之一。这个由微软发起的大规模数据集已经成为行业标准,但许…...

软件工程方法论与敏捷开发
软件工程方法论与敏捷开发 1. 技术分析 1.1 软件工程概述 软件工程是系统化的软件开发方法: 软件工程要素过程: 开发流程方法: 技术手段工具: 辅助工具核心目标:高质量软件按时交付可控成本1.2 软件开发方法论 方法论分类传统方法: 瀑布模型敏捷方法: Scrum、Kanban…...

技术人被裁员时,除了N+1还有哪些权益可以争取?
一、 核心概念澄清:你的赔偿基准是 N、N1 还是 2N?在挖掘附加权益之前,我们必须像制定测试策略一样,先明确基准。很多测试同学对赔偿的理解存在“Bug”,必须优先修复。N:指经济补偿金,计算方式是…...

对比官方价Taotoken活动价在长期使用中的成本优势感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比官方价,Taotoken活动价在长期使用中的成本优势感受 效果展示类,基于一段时间的实际使用数据࿰…...
)
OpenClaw 自动处理核心逻辑(流程图+关键配置清单)
OpenClaw 自动处理核心逻辑(流程图关键配置清单) 说明:流程图可直接复制到支持Mermaid的工具(如Typora、Mermaid Live Editor)生成可视化图表;配置清单可直接用于部署、优化,适配所有自动处理场…...

ML模型生产部署:从Jupyter到高可用推理服务的工程化实践
1. 项目概述:当模型走出Jupyter,真正开始呼吸真实世界空气“From Notebook to Production: Running ML in the Real World (Part 4)”——这个标题本身就像一句暗号,专为那些在Jupyter里调通了模型、画出了漂亮ROC曲线、却在部署时被生产环境…...