使用 Go 语言实现二叉搜索树
原文链接: 使用 Go 语言实现二叉搜索树
二叉树是一种常见并且非常重要的数据结构,在很多项目中都能看到二叉树的身影。
它有很多变种,比如红黑树,常被用作 std::map 和 std::set 的底层实现;B 树和 B+ 树,广泛应用于数据库系统中。
本文要介绍的二叉搜索树用的也很多,比如在开源项目 go-zero 中,就被用来做路由管理。
这篇文章也算是一篇前导文章,介绍一些必备知识,下一篇再来介绍具体在 go-zero 中的应用。
二叉搜索树的特点
最重要的就是它的有序性,在二叉搜索树中,每个节点的值都大于其左子树中的所有节点的值,并且小于其右子树中的所有节点的值。
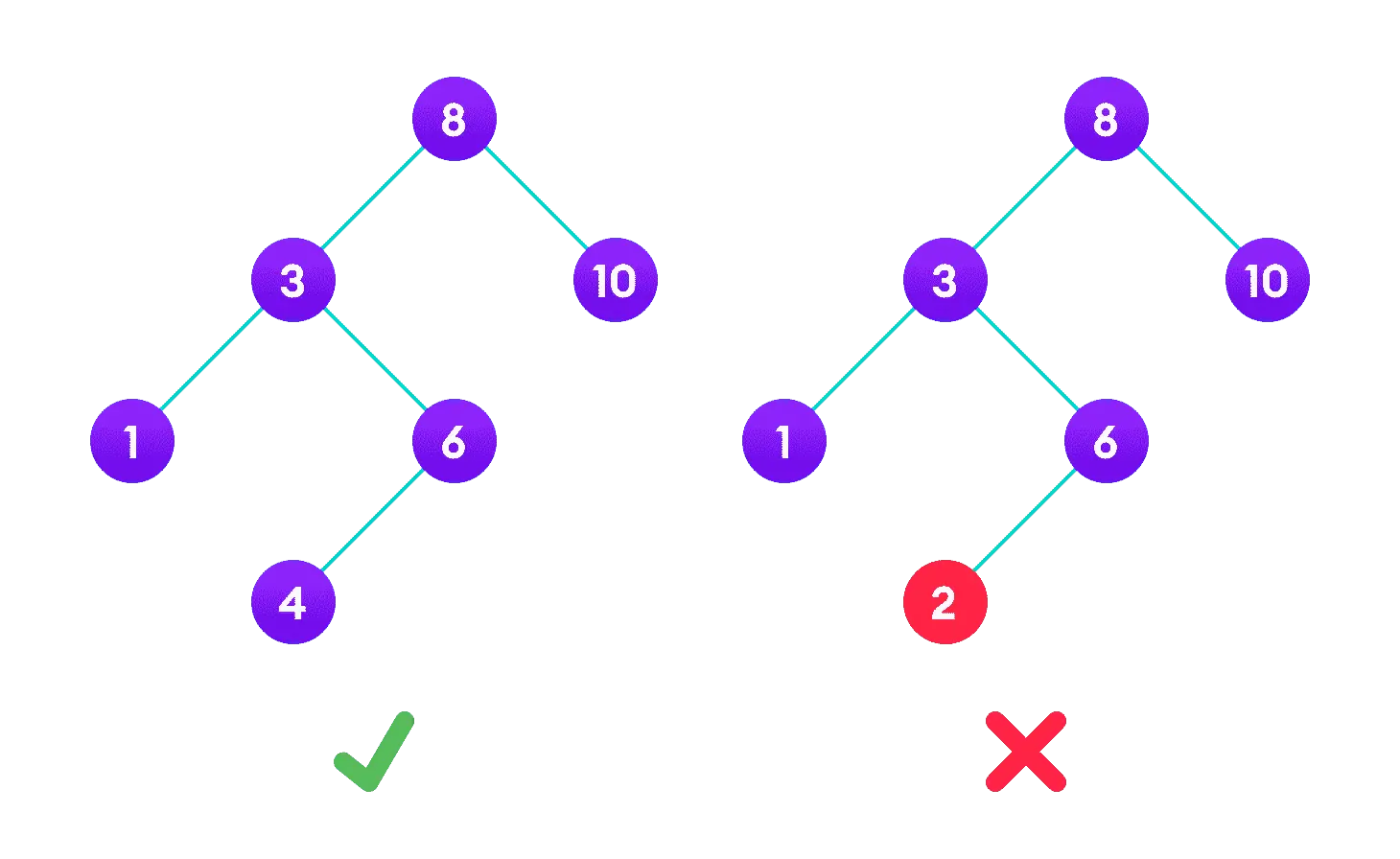
这意味着通过二叉搜索树可以快速实现对数据的查找和插入。
Go 语言实现
本文主要实现了以下几种方法:
Insert(t):插入一个节点Search(t):判断节点是否在树中InOrderTraverse():中序遍历PreOrderTraverse():前序遍历PostOrderTraverse():后序遍历Min():返回最小值Max():返回最大值Remove(t):删除一个节点String():打印一个树形结构
下面分别来介绍,首先定义一个节点:
type Node struct {key intvalue Itemleft *Node //leftright *Node //right
}
定义树的结构体,其中包含了锁,是线程安全的:
type ItemBinarySearchTree struct {root *Nodelock sync.RWMutex
}
插入操作:
func (bst *ItemBinarySearchTree) Insert(key int, value Item) {bst.lock.Lock()defer bst.lock.Unlock()n := &Node{key, value, nil, nil}if bst.root == nil {bst.root = n} else {insertNode(bst.root, n)}
}// internal function to find the correct place for a node in a tree
func insertNode(node, newNode *Node) {if newNode.key < node.key {if node.left == nil {node.left = newNode} else {insertNode(node.left, newNode)}} else {if node.right == nil {node.right = newNode} else {insertNode(node.right, newNode)}}
}
在插入时,需要判断插入节点和当前节点的大小关系,保证搜索树的有序性。
中序遍历:
func (bst *ItemBinarySearchTree) InOrderTraverse(f func(Item)) {bst.lock.RLock()defer bst.lock.RUnlock()inOrderTraverse(bst.root, f)
}// internal recursive function to traverse in order
func inOrderTraverse(n *Node, f func(Item)) {if n != nil {inOrderTraverse(n.left, f)f(n.value)inOrderTraverse(n.right, f)}
}
前序遍历:
func (bst *ItemBinarySearchTree) PreOrderTraverse(f func(Item)) {bst.lock.Lock()defer bst.lock.Unlock()preOrderTraverse(bst.root, f)
}// internal recursive function to traverse pre order
func preOrderTraverse(n *Node, f func(Item)) {if n != nil {f(n.value)preOrderTraverse(n.left, f)preOrderTraverse(n.right, f)}
}
后序遍历:
func (bst *ItemBinarySearchTree) PostOrderTraverse(f func(Item)) {bst.lock.Lock()defer bst.lock.Unlock()postOrderTraverse(bst.root, f)
}// internal recursive function to traverse post order
func postOrderTraverse(n *Node, f func(Item)) {if n != nil {postOrderTraverse(n.left, f)postOrderTraverse(n.right, f)f(n.value)}
}
返回最小值:
func (bst *ItemBinarySearchTree) Min() *Item {bst.lock.RLock()defer bst.lock.RUnlock()n := bst.rootif n == nil {return nil}for {if n.left == nil {return &n.value}n = n.left}
}
由于树的有序性,想要得到最小值,一直向左查找就可以了。
返回最大值:
func (bst *ItemBinarySearchTree) Max() *Item {bst.lock.RLock()defer bst.lock.RUnlock()n := bst.rootif n == nil {return nil}for {if n.right == nil {return &n.value}n = n.right}
}
查找节点是否存在:
func (bst *ItemBinarySearchTree) Search(key int) bool {bst.lock.RLock()defer bst.lock.RUnlock()return search(bst.root, key)
}// internal recursive function to search an item in the tree
func search(n *Node, key int) bool {if n == nil {return false}if key < n.key {return search(n.left, key)}if key > n.key {return search(n.right, key)}return true
}
删除节点:
func (bst *ItemBinarySearchTree) Remove(key int) {bst.lock.Lock()defer bst.lock.Unlock()remove(bst.root, key)
}// internal recursive function to remove an item
func remove(node *Node, key int) *Node {if node == nil {return nil}if key < node.key {node.left = remove(node.left, key)return node}if key > node.key {node.right = remove(node.right, key)return node}// key == node.keyif node.left == nil && node.right == nil {node = nilreturn nil}if node.left == nil {node = node.rightreturn node}if node.right == nil {node = node.leftreturn node}leftmostrightside := node.rightfor {//find smallest value on the right sideif leftmostrightside != nil && leftmostrightside.left != nil {leftmostrightside = leftmostrightside.left} else {break}}node.key, node.value = leftmostrightside.key, leftmostrightside.valuenode.right = remove(node.right, node.key)return node
}
删除操作会复杂一些,分三种情况来考虑:
- 如果要删除的节点没有子节点,只需要直接将父节点中,指向要删除的节点指针置为
nil即可 - 如果删除的节点只有一个子节点,只需要更新父节点中,指向要删除节点的指针,让它指向删除节点的子节点即可
- 如果删除的节点有两个子节点,我们需要找到这个节点右子树中的最小节点,把它替换到要删除的节点上。然后再删除这个最小节点,因为最小节点肯定没有左子节点,所以可以应用第二种情况删除这个最小节点即可
最后是一个打印树形结构的方法,在实际项目中其实并没有实际作用:
func (bst *ItemBinarySearchTree) String() {bst.lock.Lock()defer bst.lock.Unlock()fmt.Println("------------------------------------------------")stringify(bst.root, 0)fmt.Println("------------------------------------------------")
}// internal recursive function to print a tree
func stringify(n *Node, level int) {if n != nil {format := ""for i := 0; i < level; i++ {format += " "}format += "---[ "level++stringify(n.left, level)fmt.Printf(format+"%d\n", n.key)stringify(n.right, level)}
}
单元测试
下面是一段测试代码:
func fillTree(bst *ItemBinarySearchTree) {bst.Insert(8, "8")bst.Insert(4, "4")bst.Insert(10, "10")bst.Insert(2, "2")bst.Insert(6, "6")bst.Insert(1, "1")bst.Insert(3, "3")bst.Insert(5, "5")bst.Insert(7, "7")bst.Insert(9, "9")
}func TestInsert(t *testing.T) {fillTree(&bst)bst.String()bst.Insert(11, "11")bst.String()
}// isSameSlice returns true if the 2 slices are identical
func isSameSlice(a, b []string) bool {if a == nil && b == nil {return true}if a == nil || b == nil {return false}if len(a) != len(b) {return false}for i := range a {if a[i] != b[i] {return false}}return true
}func TestInOrderTraverse(t *testing.T) {var result []stringbst.InOrderTraverse(func(i Item) {result = append(result, fmt.Sprintf("%s", i))})if !isSameSlice(result, []string{"1", "2", "3", "4", "5", "6", "7", "8", "9", "10", "11"}) {t.Errorf("Traversal order incorrect, got %v", result)}
}func TestPreOrderTraverse(t *testing.T) {var result []stringbst.PreOrderTraverse(func(i Item) {result = append(result, fmt.Sprintf("%s", i))})if !isSameSlice(result, []string{"8", "4", "2", "1", "3", "6", "5", "7", "10", "9", "11"}) {t.Errorf("Traversal order incorrect, got %v instead of %v", result, []string{"8", "4", "2", "1", "3", "6", "5", "7", "10", "9", "11"})}
}func TestPostOrderTraverse(t *testing.T) {var result []stringbst.PostOrderTraverse(func(i Item) {result = append(result, fmt.Sprintf("%s", i))})if !isSameSlice(result, []string{"1", "3", "2", "5", "7", "6", "4", "9", "11", "10", "8"}) {t.Errorf("Traversal order incorrect, got %v instead of %v", result, []string{"1", "3", "2", "5", "7", "6", "4", "9", "11", "10", "8"})}
}func TestMin(t *testing.T) {if fmt.Sprintf("%s", *bst.Min()) != "1" {t.Errorf("min should be 1")}
}func TestMax(t *testing.T) {if fmt.Sprintf("%s", *bst.Max()) != "11" {t.Errorf("max should be 11")}
}func TestSearch(t *testing.T) {if !bst.Search(1) || !bst.Search(8) || !bst.Search(11) {t.Errorf("search not working")}
}func TestRemove(t *testing.T) {bst.Remove(1)if fmt.Sprintf("%s", *bst.Min()) != "2" {t.Errorf("min should be 2")}
}
上文中的全部源码都是经过测试的,可以直接运行,并且已经上传到了 GitHub,需要的同学可以自取。
以上就是本文的全部内容,如果觉得还不错的话欢迎点赞,转发和关注,感谢支持。
源码地址:
- https://github.com/yongxinz/go-example
推荐阅读:
- Go 语言 select 都能做什么?
- Go 语言 context 都能做什么?
参考文章:
- https://flaviocopes.com/golang-data-structure-binary-search-tree/
相关文章:
使用 Go 语言实现二叉搜索树
原文链接: 使用 Go 语言实现二叉搜索树 二叉树是一种常见并且非常重要的数据结构,在很多项目中都能看到二叉树的身影。 它有很多变种,比如红黑树,常被用作 std::map 和 std::set 的底层实现;B 树和 B 树,…...

系统接口自动化测试方案
XXX接口自动化测试方案 1、引言 1.1 文档版本 版本 作者 审批 备注 V1.0 XXXX 创建测试方案文档 1.2 项目情况 项目名称 XXX 项目版本 V1.0 项目经理 XX 测试人员 XXXXX,XXX 所属部门 XX 备注 1.3 文档目的 本文档主要用于指导XXX-Y…...
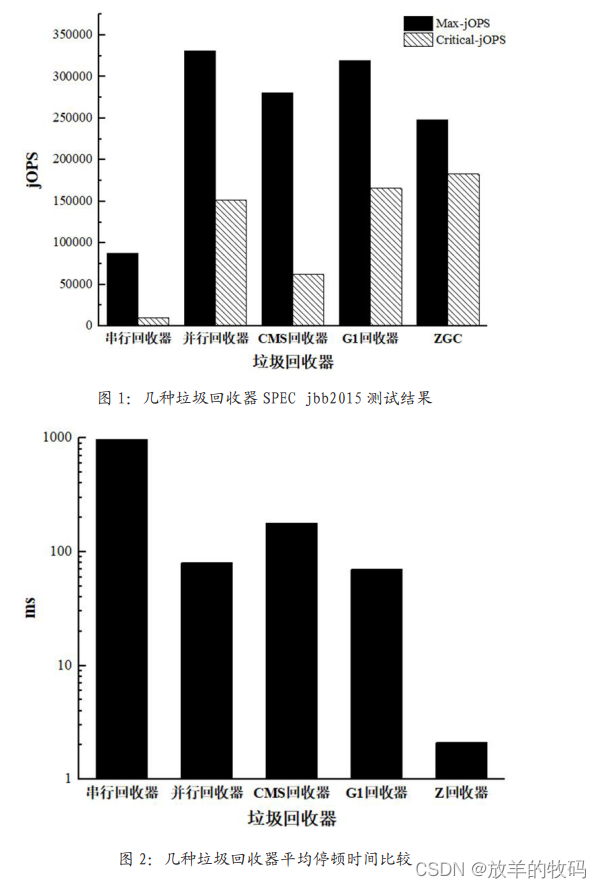
小研究 - JVM 垃圾回收方式性能研究(一)
本文从几种JVM垃圾回收方式及原理出发,研究了在 SPEC jbb2015基准测试中不同垃圾回收方式对于JVM 性能的影响,并通过最终测试数据对比,给出了不同应用场景下如何选择垃圾回收策略的方法。 目录 1 引言 2 垃圾回收算法 2.1 标记清除法 2.2…...
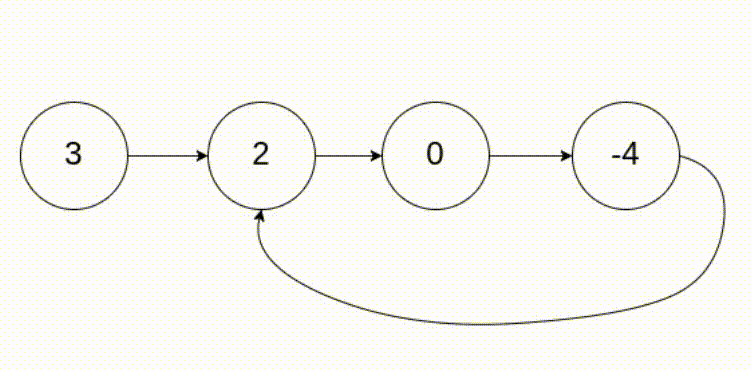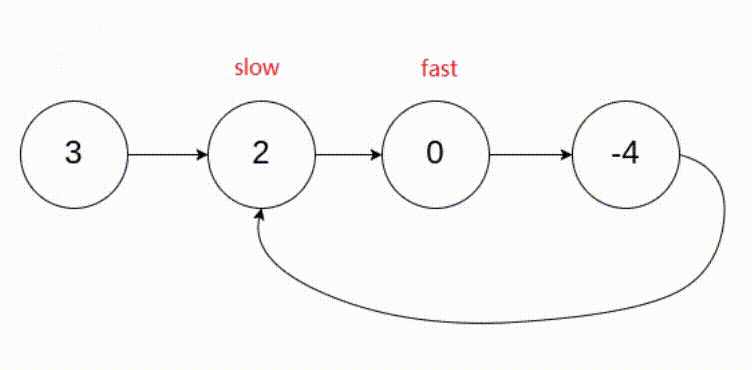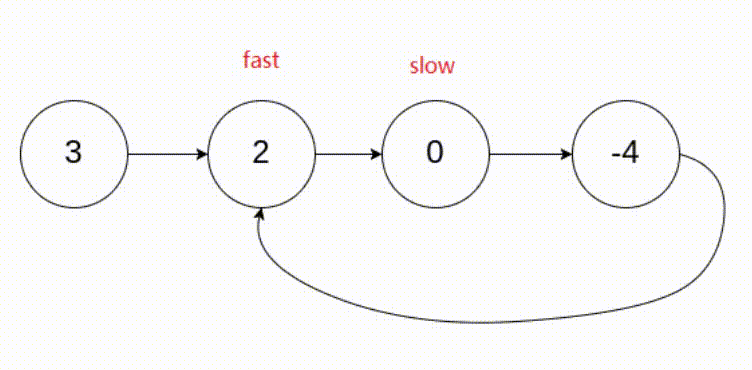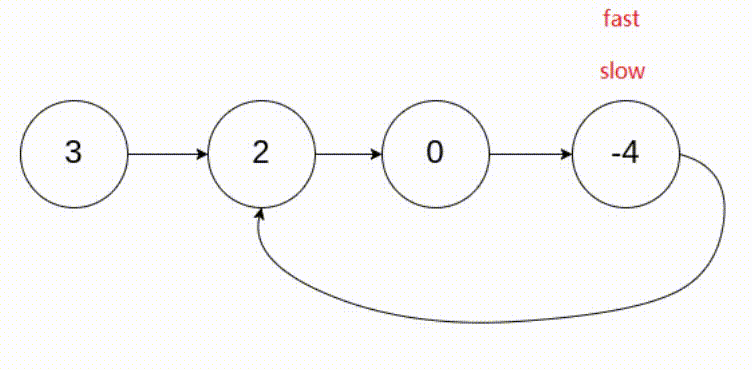
[LeetCode]链表相关题目(c语言实现)
文章目录 LeetCode203. 移除链表元素LeetCode237. 删除链表中的节点LeetCode206. 反转链表ⅠLeetCode92. 反转链表 II思路 1思路 2 LeetCode876. 链表的中间结点剑指 Offer 22. 链表中倒数第k个节点LeetCode21. 合并两个有序链表LeetCode86. 分隔链表LeetCode234. 回文链表Leet…...
] NAND 初始化常用命令:复位 (Reset) 和 Read ID 和 Read UID 操作和代码实现)
[深入理解NAND Flash (操作篇)] NAND 初始化常用命令:复位 (Reset) 和 Read ID 和 Read UID 操作和代码实现
依JEDEC eMMC及经验辛苦整理,原创保护,禁止转载。 专栏 《深入理解Flash:闪存特性与实践》 内容摘要 全文 4400 字,主要内容 复位的目的和作用? NAND Reset 种类:FFh, FCh, FAh, FDh 区别 Reset 操作步骤 和 代码实现 Read ID 操作步骤 和 代码实现 Read Uni…...

RxJava 复刻简版之二,调用流程分析之案例实现
接上篇:https://blog.csdn.net/da_ma_dai/article/details/131878516 代码节点:https://gitee.com/bobidali/lite-rx-java/commit/05199792ce75a80147c822336b46837f09229e46 java 类型转换 kt 类型: Any Object泛型: 协变: …...

SpringMVC中Model和ModelAndView的区别
SpringMVC中Model和ModelAndView的区别 两者的区别: 在SpringMVC中,Model和ModelAndView都是用于将数据传递到视图层的对象 Model是”模型“的意思,是MVC架构中的”M“部分,是用来传输数据的。 理解成MVC架构中的”M“和”V“…...
Tomcat安装与管理
文章目录 Tomcat安装及管理Tomcat gz包安装:JDK安装:Tomcat安装:修改配置文件(如下):服务启动配置: Tomcat-管理(部署jpress):修改允许访问的主机修改允许管理APP的主机进入管理&…...

React之路由
React之路由 背景: react: 18.2.0 路由:react-router-dom: 6.14.2 1、路由表配置 src下新建router/index.ts import React, { lazy } from react import { Navigate } from react-router-dom import Layout from /layout/Index import { JSX } from rea…...
机器学习深度学习——非NVIDIA显卡怎么做深度学习(坑点排查)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——数值稳定性和模型化参数(详细数学推导) 📚订阅专栏:机器…...

2021 Robocom 决赛 第四题
原题链接: PTA | 程序设计类实验辅助教学平台 题面: 在一个名叫刀塔的国家里,有一只猛犸正在到处跑着,希望能够用它的长角抛物技能来撞飞别人。已知刀塔国有 N 座城市,城市之间由 M 条道路互相连接,为了拦…...
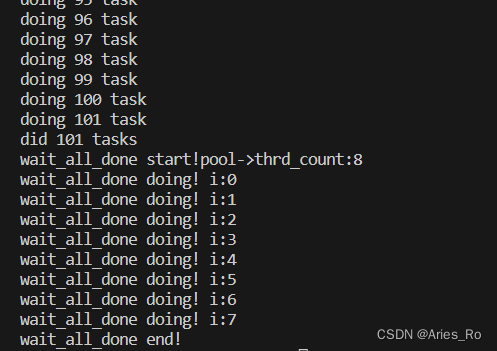
线程池-手写线程池Linux C简单版本(生产者-消费者模型)
目录 简介手写线程池线程池结构体分析task_ttask_queue_tthread_pool_t 线程池函数分析thread_pool_createthread_pool_postthread_workerthread_pool_destroywait_all_donethread_pool_free 主函数调用 运行结果 简介 本线程池采用C语言实现 线程池的场景: 当某些…...

05-向量的意义_n维欧式空间
线性代数 什么是向量?究竟为什么引入向量? 为什么线性代数这么重要?从研究一个数拓展到研究一组数 一组数的基本表示方法——向量(Vector) 向量是线性代数研究的基本元素 e.g. 一个数: 666,…...

交通运输安全大数据分析解决方案
当前运输市场竞争激烈,道路运输企业受传统经营观念影响,企业管理者安全意识淡薄,从业人员规范化、流程化的管理水平较低,导致制度规范在落实过程中未能有效监督与管理,执行过程中出现较严重的偏差,其营运车…...
)
vimrc 配置 (持续跟新中)
vimrc 配置 #显示行号 set nu #自动换行 set autoindent #设置tab键 宽度为四个空格 set tabstop4 set shiftwidth4 set expandtab更多文章,详见我的博客网站...

【集成学习介绍】
1. 引言 在机器学习领域,集成学习(Ensemble Learning)是一种强大的技术,通过将多个弱学习器组合成一个更强大的集成模型,来提升模型的鲁棒性和性能。 2. 集成学习的原理 集成学习的核心思想是“三个臭皮匠ÿ…...

动画制作选择Blender还是Maya
Blender和Maya是两种最广泛使用的 3D 建模和动画应用程序。许多经验丰富的用户表示,Blender 在雕刻工具方面远远领先于 Maya,并且在 3D 建模方面达到了相同的质量水平。对于刚接触动画行业的人来说,您可能会问“我应该使用 Blender 还是 Maya…...
215. 数组中的第K个最大元素
题目链接:力扣 解题思路: 方法一:基于快速排序 因为题目中只需要找到第k大的元素,而快速排序中,每一趟排序都可以确定一个最终元素的位置。 当使用快速排序对数组进行降序排序时,那么如果有一趟排序过程…...

NLP From Scratch: 生成名称与字符级RNN
NLP From Scratch: 生成名称与字符级RNN 这是我们关于“NLP From Scratch”的三个教程中的第二个。 在<cite>第一个教程< / intermediate / char_rnn_classification_tutorial ></cite> 中,我们使用了 RNN 将名称分类为来源语言。 这次ÿ…...

Spring MVC程序开发
目录 1.什么是Spring MVC? 1.1MVC定义 1.2MVC和Spring MVC的关系 2.为什么要学习Spring MVC? 3.怎么学Spring MVC? 3.1Spring MVC的创建和连接 3.1.1创建Spring MVC项目 3.1.2RequestMapping 注解介绍 3.1.3 RequestMapping 是 post 还是 get 请求? …...

量子计算中Loschmidt回声相位测量的创新方法
1. 量子计算中的Loschmidt回声相位测量方法概述Loschmidt回声是量子动力学中一个重要的概念,它描述了量子系统在时间反演演化后与初始状态的相似程度。在量子计算领域,精确测量Loschmidt回声的相位信息对于理解量子系统的非平衡态行为、计算能量本征值以…...

软阴影:那个让虚拟世界“温柔起来“的光影小秘密
一、从一只小猫的影子说起 前几天我在朋友家做客,他家养了一只胖乎乎的橘猫,正趴在阳台的窗边晒太阳。我无意间瞥了一眼那只猫脚边的影子,突然被一个细节震撼了—— 那只猫的影子——并不是一片均匀的黑。 仔细看——猫肚子紧贴地板的地方——…...

为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析
更多请点击: https://intelliparadigm.com 第一章:为什么92%的DeepSeek二次开发团队在6个月内遭遇交付延迟?——基于17个真实项目的技术债务归因分析 在对17个采用DeepSeek-R1/VL模型开展定制化开发的工业级项目进行回溯审计后,我…...

【紧急预警】Lindy衰减临界点已提前至第8.3个月!2024最新《营销自动化寿命健康度白皮书》限时开放前500份
更多请点击: https://kaifayun.com 第一章:Lindy衰减临界点的理论重构与实证突破 Lindy效应传统上描述“越老越长寿”的非线性生存规律,但其在现代软件系统、开源生态与协议层技术栈中的适用边界正遭遇结构性挑战。本文首次将Lindy模型从静…...

当 AI Coding 进入复杂企业系统,为什么提效远没有宣传里那么美好 ?
以 Claude Code、Codex 为代表的自主编码智能体(Coding Agents),正在以惊人的速度席卷软件开发者生态。与此同时,类似“10 倍开发效率”“普通人也能随手构建软件”“程序员即将失业”的说法,也随处可见。这种不分场景…...
)
别再死磕USB HID了!用ESP32的Arduino框架手把手教你实现蓝牙鼠标键盘(附完整代码)
ESP32蓝牙HID实战:零基础打造自定义键盘鼠标 手里那块吃灰的ESP32开发板终于能派上用场了!上周我用它做了个无线演示控制器,在会议室里走着就能翻PPT,同事们都问是怎么实现的。其实秘诀就在于ESP32的蓝牙HID功能——不需要任何USB…...

ZMJS,把 JavaScript 解释器放进 SAP ABAP 应用服务器之后,很多扩展思路会变得不一样
我今天看这个 oisee/zmjs 仓库时,最吸引人的不是它把 JavaScript 语法做进了 ABAP,而是它选择了一条非常 SAP 的路线,纯 ABAP、无外部依赖、无 Kernel Module、以类和接口的形式运行在 SAP 应用服务器内部。仓库自己的定位很直接,ZMJS 是一个面向 SAP ABAP 的 Mini JavaScr…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

避坑指南:Unity动态加载模型时,TriLib插件材质丢失、缩放异常的5个常见问题解决
Unity动态加载模型避坑指南:TriLib插件材质丢失与缩放异常的深度解决方案当你在Unity项目中尝试使用TriLib插件动态加载外部模型时,是否遇到过这些令人抓狂的情况:模型加载后材质全部变成刺眼的粉红色,贴图神秘消失,或…...

解锁你的音乐收藏:浏览器端音频解密完整指南
解锁你的音乐收藏:浏览器端音频解密完整指南 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gitcod…...