花费7元训练自己的GPT 2模型
在上一篇博客中,我介绍了用Tensorflow来重现GPT 1的模型和训练的过程。这次我打算用Pytorch来重现GPT 2的模型并从头进行训练。
GPT 2的模型相比GPT 1的改进并不多,主要在以下方面:
1. GPT 2把layer normalization放在每个decoder block的前面。
2. 最终的decoder block之后额外添加了一个layer normalization。
3. 残差层的参数初始化根据网络深度进行调节
4. 训练集采用了webtext(45GB),而不是之前采用的bookcorpus(5GB)
5. 更深的网络结构,最大的模型拥有15亿的参数,对比GPT 1是1.2亿的参数
GPT 2有以下四种不同深度的模型架构,如图:
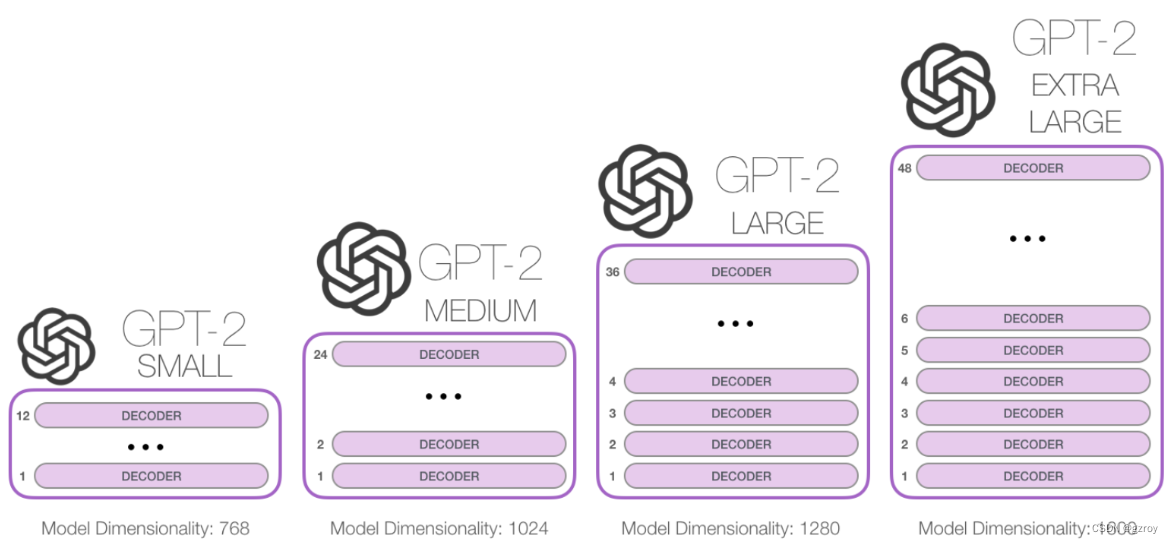
以下我将用pytorch代码来搭建一个GPT 2的模型,以最小的GPT 2为例,采用bookcorpus的数据,在AutoDL平台的一个40G显存的A100显卡上进行训练,看看效果如何。
模型结构
整个模型的结构和GPT 1是基本一致的。
定义一个多头注意力模块,如以下代码:
class MHA(nn.Module):def __init__(self, d_model, num_heads, attn_pdrop, resid_pdrop):super().__init__()self.d_model = d_modelself.num_heads = num_headsself.attn_pdrop = attn_pdropself.resid_dropout = nn.Dropout(resid_pdrop)self.ln = nn.Linear(d_model, d_model*3)self.c_proj = nn.Linear(d_model, d_model)def forward(self, x):B, T, C = x.size()x_qkv = self.ln(x)q, k, v = x_qkv.split(self.d_model, dim=2)q = q.view(B, T, self.num_heads, C//self.num_heads).transpose(1, 2)k = k.view(B, T, self.num_heads, C//self.num_heads).transpose(1, 2)v = v.view(B, T, self.num_heads, C//self.num_heads).transpose(1, 2)y = torch.nn.functional.scaled_dot_product_attention(q, k, v, attn_mask=None, dropout_p=self.attn_pdrop if self.training else 0, is_causal=True)y = y.transpose(1, 2).contiguous().view(B, T, C)y = self.c_proj(y)y = self.resid_dropout(y)return y这个模块接收一个输入数据,大小为(batch_size, seq_len, dimension),然后进行一个线性变换层,把数据映射为(batch_size, seq_len, dimension*3)的维度,这里的dimension*3表示的是qkv这三个值的拼接。接着就把这个数据切分为q,k,v三份,然后每份都把维度调整为(batch_size, seq_len, num_head, dimension/num_head),num_head表示这个自注意力模块包含多少个head。最后就可以调用scaled_dot_product_attention进行qk的相似度计算,进行缩放之后与v值相乘。Pytorch的这个函数提供了最新的flash attention的实现,可以大幅提升计算性能。最后就是对qkv的结果进行一个线性变换,映射为一个(batch_size, seq_len, dimension)的向量。
自注意力模块的输出结果,将通过一个Feed forward层进行计算,代码如下:
class FeedForward(nn.Module):def __init__(self, d_model, dff, dropout):super().__init__()self.ln1 = nn.Linear(d_model, dff)self.ln2 = nn.Linear(dff, d_model)self.dropout = nn.Dropout(dropout)self.layernorm = nn.LayerNorm(d_model)self.gelu = nn.GELU()def forward(self, x):x = self.ln1(x)x = self.gelu(x)x = self.ln2(x)x = self.dropout(x)return x代码很简单,就是做了两次线性变换,第一次把维度扩充到dimension*4,第二次把维度恢复为dimension。
最后定义一个decoder block模块,把多头注意力模块和feed forward模块组合起来,代码如下:
class Block(nn.Module):def __init__(self, d_model, num_heads, dff, attn_pdrop, resid_pdrop, dropout):super().__init__()self.layernorm1 = nn.LayerNorm(d_model)self.attn = MHA(d_model, num_heads, attn_pdrop, resid_pdrop)self.layernorm2 = nn.LayerNorm(d_model)self.ff = FeedForward(d_model, dff, dropout)def forward(self, x):x = x + self.attn(self.layernorm1(x))x = x + self.ff(self.layernorm2(x))return x有了decoder block之后,GPT 2的模型就是把这些block串起来,例如最小的GPT 2的模型结构是定义了12个decoder block。模型接收的是字符序列经过tokenizer之后的数字,然后把这些数字通过embedding层映射为向量表达,例如对每个token id,映射为784维度的一个向量。为了能在embedding的向量里面反映字符的位置信息,我们需要把字符的位置也做一个embedding,然后两个embedding相加。
输入数据经过embedding处理后,通过多个decoder block处理之后,数据的维度为(batch_size, seq_len, dimension), 我们需要通过一个权重维度为(dimension, vocab_size)的线性变换,把数据映射为(batch_size, seq_len, vocab_size)的维度。这里vocab_size表示tokenizer的单词表的长度,例如对于GPT 2所用的tokenizer,有50257个单词。对于输出数据进行softmax计算之后,我们就可以得到每个token的预测概率,从而可以和label数据,即真实的下一个token id进行比较,计算loss值。
GPT 2模型的代码如下:
class GPT2(nn.Module):def __init__(self, vocab_size, d_model, block_size, embed_pdrop, num_heads, dff, attn_pdrop, resid_pdrop, dropout, num_layer):super().__init__()self.token_embed = nn.Embedding(vocab_size, d_model, sparse=False)self.pos_embed = nn.Embedding(block_size, d_model, sparse=False)self.dropout_embed = nn.Dropout(embed_pdrop)#self.blocks = [Block(d_model, num_heads, dff, attn_pdrop, resid_pdrop, dropout) for _ in range(num_layer)]self.blocks = nn.ModuleList([Block(d_model, num_heads, dff, attn_pdrop, resid_pdrop, dropout) for _ in range(num_layer)])self.num_layer = num_layerself.block_size = block_sizeself.lm_head = nn.Linear(d_model, vocab_size, bias=False)self.token_embed.weight = self.lm_head.weightself.layernorm = nn.LayerNorm(d_model)self.apply(self._init_weights)# apply special scaled init to the residual projections, per GPT-2 paperfor pn, p in self.named_parameters():if pn.endswith('c_proj.weight'):torch.nn.init.normal_(p, mean=0.0, std=0.02/math.sqrt(2 * num_layer))def _init_weights(self, module):if isinstance(module, nn.Linear):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)if module.bias is not None:torch.nn.init.zeros_(module.bias)elif isinstance(module, nn.Embedding):torch.nn.init.normal_(module.weight, mean=0.0, std=0.02)def forward(self, x, targets=None):device = x.deviceb, t = x.size()pos = torch.arange(0, t, dtype=torch.long, device=device) x = self.token_embed(x) + self.pos_embed(pos)x = self.dropout_embed(x)for block in self.blocks:x = block(x)x = self.layernorm(x)if targets is not None:logits = self.lm_head(x)loss = F.cross_entropy(logits.view(-1, logits.size(-1)), targets.view(-1), ignore_index=-1)else:logits = self.lm_head(x[:, -1, :])loss = Nonereturn logits, lossdef configure_optimizers(self, weight_decay, learning_rate, betas, device_type):# start with all of the candidate parametersparam_dict = {pn: p for pn, p in self.named_parameters()}# filter out those that do not require gradparam_dict = {pn: p for pn, p in param_dict.items() if p.requires_grad}# create optim groups. Any parameters that is 2D will be weight decayed, otherwise no.# i.e. all weight tensors in matmuls + embeddings decay, all biases and layernorms don't.decay_params = [p for n, p in param_dict.items() if p.dim() >= 2]nodecay_params = [p for n, p in param_dict.items() if p.dim() < 2]optim_groups = [{'params': decay_params, 'weight_decay': weight_decay},{'params': nodecay_params, 'weight_decay': 0.0}]num_decay_params = sum(p.numel() for p in decay_params)num_nodecay_params = sum(p.numel() for p in nodecay_params)print(f"num decayed parameter tensors: {len(decay_params)}, with {num_decay_params:,} parameters")print(f"num non-decayed parameter tensors: {len(nodecay_params)}, with {num_nodecay_params:,} parameters")# Create AdamW optimizer and use the fused version if it is availablefused_available = 'fused' in inspect.signature(torch.optim.AdamW).parametersuse_fused = fused_available and device_type == 'cuda'extra_args = dict(fused=True) if use_fused else dict()optimizer = torch.optim.AdamW(optim_groups, lr=learning_rate, betas=betas, **extra_args)print(f"using fused AdamW: {use_fused}")return optimizer@torch.no_grad()def generate(self, idx, max_new_tokens, temperature=1.0, top_k=None, block_size=512):for _ in range(max_new_tokens):# if the sequence context is growing too long we must crop it at block_sizeidx_cond = idx if idx.size(1) <= block_size else idx[:, -block_size:]# forward the model to get the logits for the index in the sequencelogits, _ = self(idx_cond)# pluck the logits at the final step and scale by desired temperaturelogits = logits / temperature# optionally crop the logits to only the top k optionsif top_k is not None:v, _ = torch.topk(logits, min(top_k, logits.size(-1)))logits[logits < v[:, [-1]]] = -float('Inf')# apply softmax to convert logits to (normalized) probabilitiesprobs = F.softmax(logits, dim=-1)# sample from the distributionidx_next = torch.multinomial(probs, num_samples=1)# append sampled index to the running sequence and continueidx = torch.cat((idx, idx_next), dim=1)return idx模型训练
定义好模型之后,我们就可以开始训练了。
首先我们需要准备训练数据集。GPT 2采用的是webtext,网上的一些公开网页数据来进行训练。在Huggingface上面有对应的一个公开数据集。不过考虑到我们的资源有限,我这次还是采用GPT 1所用的bookcorpus数据集来训练。
以下代码是下载huggingface的数据集,并用GPT 2的tokenizer来进行编码:
from datasets import load_dataset
from transformers import GPT2Tokenizerdataset = load_dataset("bookcorpusopen", split="train")block_size=513
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")def tokenize_function(examples):token_ids = [tokenizer(text) for text in examples["text"]]total_length = [len(t["input_ids"]) for t in token_ids]total_length = [(l//(block_size+1))*(block_size+1) for l in total_length]result = []label = []for i in range(len(total_length)):result.extend([token_ids[i]["input_ids"][j:j+block_size+1] for j in range(0, total_length[i], block_size+1)])return {"token_ids": result}ds_test = ds['train'].select(range(10000))tokenized_datasets = ds_test.map(tokenize_function, batched=True, num_proc=8, remove_columns=["title", "text"], batch_size=100
)tokenized_datasets.save_to_disk("data/boocorpusopen_10000_512tokens")GPT1采用的bookcorpus有7000多本书,huggingface的bookcorpusopen数据集有14000多本,这里我只采用了10000本书来构建数据集,对于每本书进行tokenizer转化后,每513个token写入为1条记录。这样我们在训练时,每条记录我们采用前1-512个token作为训练,取2-513个token作为label。
以下代码将读取我们处理好的数据集,并转化为pytorch的dataloader
from datasets import load_from_diskdataset = load_from_disk("data/boocorpusopen_10000_512tokens")
dataset = dataset.with_format("torch")
dataloader = DataLoader(dataset, batch_size=args.batch_size, shuffle=True, num_workers=4)然后我们就可以实例化一个GPT 2的model并开始训练,具体的代码可以见repo https://github.com/gzroy/gpt2_torch.git 里面的train.py文件。
如果在本地显卡上训练,对应12层的网络结构需要30多G的显存,我的显卡是2080Ti,只有11G显存,因此只能指定6层decoder。我们可以在autodl上面租用一个40G显存的A100显卡,价格是3.45元每小时,在这个显卡上开启半精度进行训练,大约1个小时可以跑10000个迭代,batch大小为64。我总共训练了2小时,最终在训练集上的Loss值为3.5左右,准确度为35%,花费为7元。
生成文本
最后我们可以基于这个训练了1个小时的GPT 2模型来测试一下,看生成文本的效果如何,如以下代码:
from transformers import GPT2Tokenizer
from model import GPT2
import torch
from torch.nn import functional as F
import argparseif __name__ == '__main__':parser = argparse.ArgumentParser(description='gpt2 predict')parser.add_argument('--checkpoint_path', type=str, default='checkpoints/')parser.add_argument('--checkpoint_name', type=str, default='')parser.add_argument('--d_model', type=int, default=768)parser.add_argument('--block_size', type=int, default=512)parser.add_argument('--dff', type=int, default=768*4)parser.add_argument('--heads', type=int, default=12)parser.add_argument('--decoder_layers', type=int, default=6)parser.add_argument('--device', type=str, default='cuda')parser.add_argument('--input', type=str)parser.add_argument('--generate_len', type=int, default=100)parser.add_argument('--topk', type=int, default=5)args = parser.parse_args()tokenizer = GPT2Tokenizer.from_pretrained("gpt2")vocab_size = len(tokenizer.get_vocab())model = GPT2(vocab_size, args.d_model, args.block_size, 0, args.heads, args.dff, 0, 0, 0, args.decoder_layers)model.to(args.device)model = torch.compile(model)checkpoint = torch.load(args.checkpoint_path+args.checkpoint_name)model.load_state_dict(checkpoint['model_state_dict'])token_id = tokenizer.encode(args.input)input_data = torch.reshape(torch.tensor(token_id, device=args.device), [1,-1])predicted = model.generate(input_data, args.generate_len, 1.0, args.topk, args.block_size)print("Generated text:\n-------------------")print(tokenizer.decode(predicted.cpu().numpy()[0]))运行以下命令,给定一个文本的开头,然后让模型生成200字看看:
python predict.py --checkpoint_name model_1.pt --input 'it was saturday night, the street' --generate_len 200 --topk 10生成的文本如下:
it was saturday night, the street lights blared and the street lights flickered on. A few more houses were visible.The front door opened, and a large man stepped in and handed him one. He handed the man the keys and a small smile. It looked familiar, and then a little too familiar. The door was closed."Hey! You guys out there?" he said, his eyes wide."What are you up to?" the man asked."I'm just asking for you out in my office."The man was about thirty feet away from them."I'm in a serious situation, but it's just the way you are."He looked around at the man, the man looked up and down, and then his eyes met hers. He was a little older than he was, but his eyes were blue with red blood. He looked like a giant. His eyes were blue and red, and his jaw looked like a giant可见生成的文本语法没有问题,内容上也比较连贯,上下文的逻辑也有关联。如果模型继续训练更长时间,相信生成文本的内容会更加好。
相关文章:
花费7元训练自己的GPT 2模型
在上一篇博客中,我介绍了用Tensorflow来重现GPT 1的模型和训练的过程。这次我打算用Pytorch来重现GPT 2的模型并从头进行训练。 GPT 2的模型相比GPT 1的改进并不多,主要在以下方面: 1. GPT 2把layer normalization放在每个decoder block的前…...

性能分析工具
性能分析工具 valgrind 交叉编译 android arm/arm64 平台 valgrind android32 #!/usr/bin/env bashexport NDKROOT~/opt/android-ndk-r14b/ export AR$NDKROOT/toolchains/arm-linux-androideabi-4.9/prebuilt/linux-x86_64/bin/arm-linux-androideabi-ar export LD$NDKROO…...
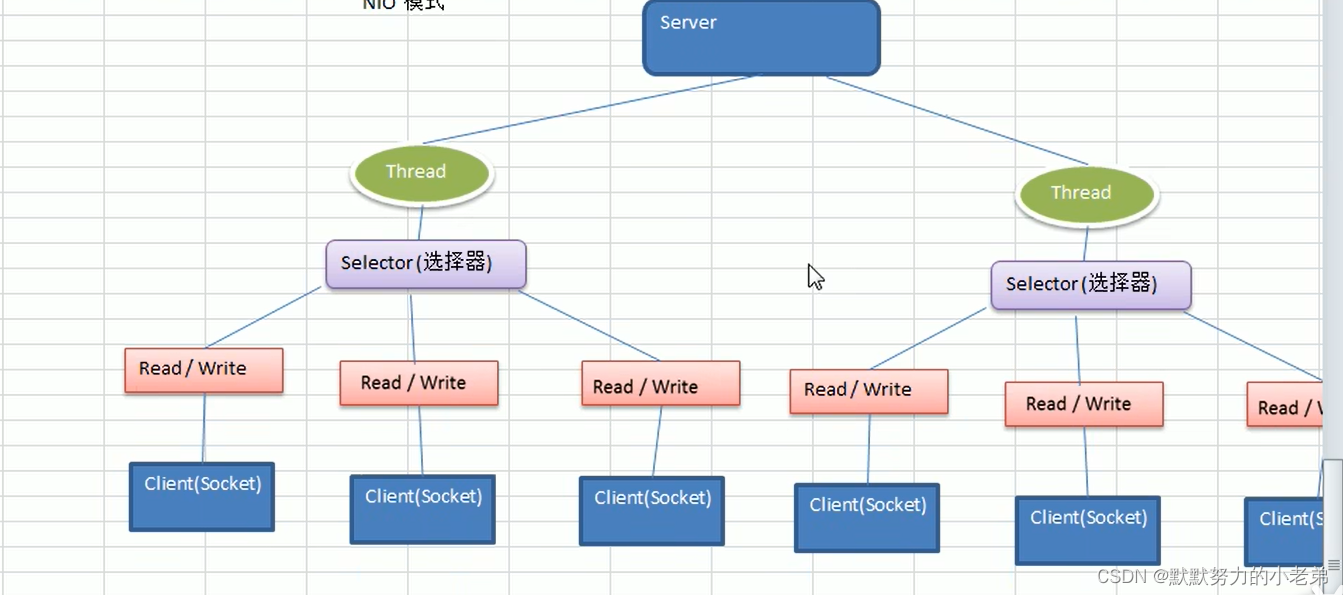
1.netty介绍
1.介绍 是JBOSS通过的java开源框架是异步的,基于事件驱动(点击一个按钮调用某个函数)的网络应用框架,高性能高可靠的网络IO程序基于TCP,面向客户端高并发应用/点对点大量数据持续传输的应用是NIO框架 (IO的一层层封装) TCP/IP->javaIO和网络编程–>NIO—>Netty 2.应用…...

【Jmeter】压测mysql数据库中间件mycat
目录 背景 环境准备 1、下载Jmeter 2、下载mysql数据库的驱动包 3、要进行测试的数据库 Jmeter配置 1、启动Jmeter图形界面 2、加载mysql驱动包 3、新建一个线程组,然后如下图所示添加 JDBC Connection Configuration 4、配置JDBC Connection Configurati…...
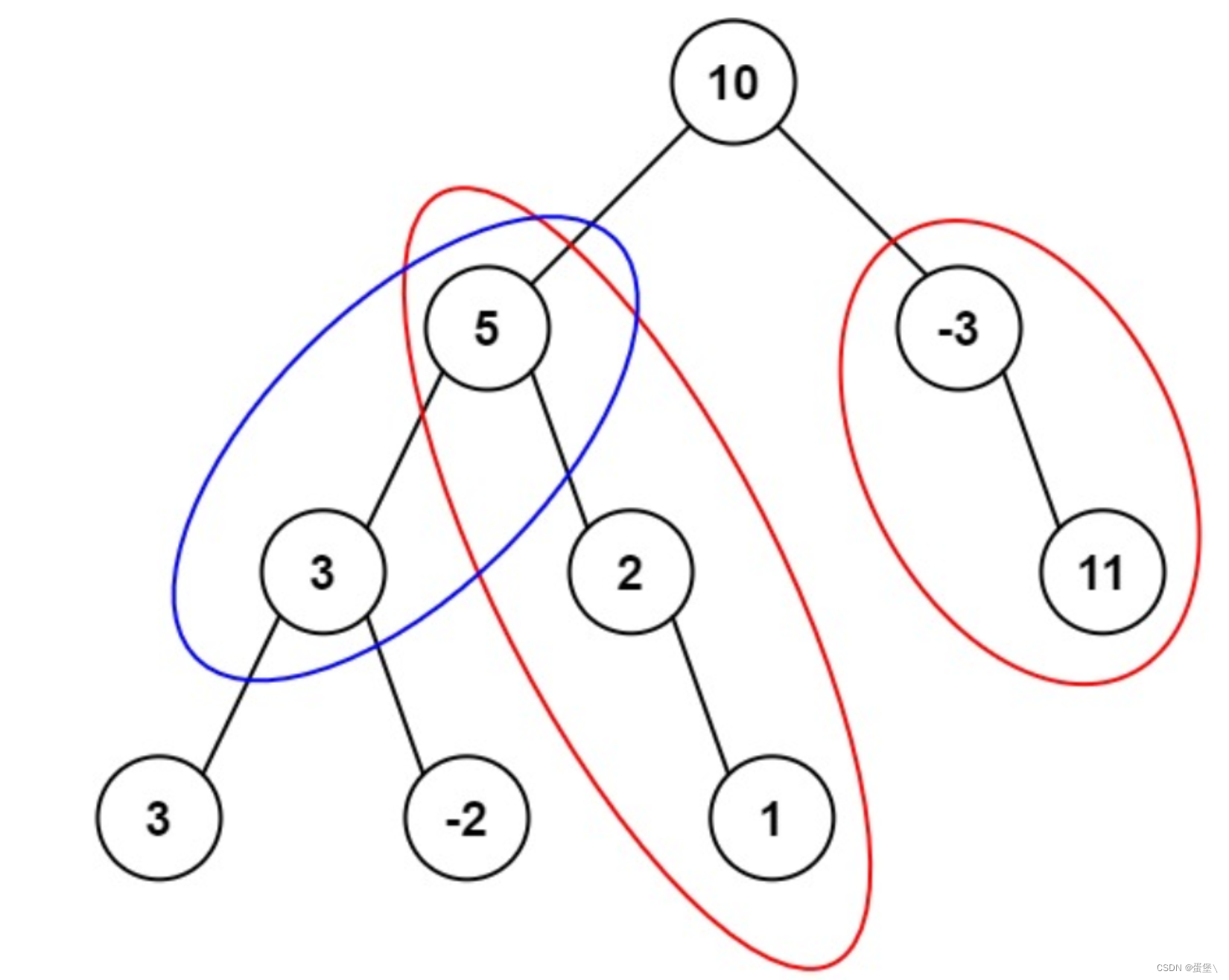
leetcode原题 路径总和 I II III(递归实现)
路径总和 I : 给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。…...

【css】css设置表格样式-边框线合并
<style> table, td, th {border: 1px solid black;//设置边框线 }table {width: 100%; }td {text-align: center;//设置文本居中 } </style> </head> <body><table><tr><th>Firstname</th><th>Lastname</th><t…...
使用Flutter的image_picker插件实现设备的相册的访问和拍照
文章目录 需求描述Flutter插件image_picker的介绍使用步骤1、添加依赖2、导入 例子完整的代码效果 总结 需求描述 在应用开发时,我们有很多场景要使用到更换图片的功能,即将原本的图像替换设置成其他的图像,从设备的相册或相机中选择图片或拍…...

数学建模体系
1评价类 主观求权重:层次分析法客观求权重:TOPSIS综合评价:典型相关分析 2预测插值算法拟合多元回归分析时间序列分析、ARCH和garch模型岭回归和lasso回归 3关系相关系数典型相关分析多元回归分析灰色关联分析 4图最短路径:迪杰斯…...
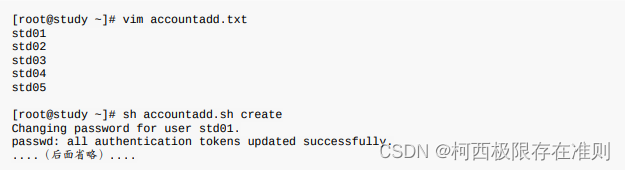
13.7 CentOS 7 环境下大量创建帐号的方法
13.7.1 一些帐号相关的检查工具 pwck pwck 这个指令在检查 /etc/passwd 这个帐号配置文件内的信息,与实际的主文件夹是否存在等信息, 还可以比对 /etc/passwd /etc/shadow 的信息是否一致,另外,如果 /etc/passwd 内的数据字段错…...
HTML5 Canvas(画布)
<canvas>标签定义图形,比如图表和其他图像,你必须用脚本来绘制图形。 在画布上( Canvas )画一个共红色矩形,渐变矩形,彩色矩形,和一些彩色文字。 什么是 Canvas? HTML5<c…...

io的异常处理以及properties
try(流对象的创建) { 对象的处理逻辑} catch(IOException e) { 异常的处理逻辑} public static void test4(){try(FileWriter fwnew FileWriter("a.txt",true); ){char[] cbuf{a};//写入一个字符串组fw.write(cbuf);}catch(IOException e){e.printStackTrace();}}上面…...
Linux下基于Dockerfile构建镜像应用(1)
目录 基于已有容器创建镜像 Dockerfile构建SSHD镜像 构建镜像 测试容器 可以登陆 Dockerfile构建httpd镜像 构建镜像 测试容器 Dockerfile构建nginx镜像 构建镜像 概述: Docker 镜像是Docker容器技术中的核心,也是应用打包构建发布的标准格式。…...

JS中常见的模块管理规范梳理
一、CommonJS规范 CommonJS规范是一种用于JavaScript模块化开发的规范,它定义了模块的导入、导出方式和加载机制,主要用在Node开发中。 1. 使用场景 服务器端开发:Node.js是使用CommonJS规范的,因此在服务器端开发中࿰…...

3维空间下按平面和圆柱面上排版设计
AR空间中将若干平面窗口排列在指定平面或圆柱体面上 平面排版思路 指定平面方向向量layout_centre ,平面上的一点作为排版版面的中心layout_position float3 layout_position = float3(0,0,-10); float3 layout_centre = float3(0,0,1...
【Spring框架】Spring AOP
目录 什么是AOP?AOP组成Spring AOP 实现步骤Spring AOP实现原理JDK Proxy VS CGLIB 什么是AOP? AOP(Aspect Oriented Programming):⾯向切⾯编程,它是⼀种思想,它是对某⼀类事情的集中处理。⽐如…...

寻找旋转排序数组中的最小值——力扣153
文章目录 题目描述解法 二分法 题目描述 解法 二分法 int findMin(vector<int>& nums){int l0, rnums.size()-1;while(l<r){int mid (lr)/2;if(nums[mid]<nums[r]) rmid;else lmid1;}return nums[l];}...
安卓逆向 - 基础入门教程
一、引言 1、我们在采集app数据时,有些字段是加密的,如某麦网x-mini-wua x-sgext x-sign x-umt x-utdid等参数,这时候我们需要去分析加密字段的生成。本篇将以采集的角度讲解入门安卓逆向需要掌握的技能、工具。 2、安卓(Androi…...
验证码安全志:AIGC+集成环境信息信息检测
目录 知己知彼,黑灰产破解验证码的过程 AIGC加持,防范黑灰产的破解 魔高一丈,黑灰产AIGC突破常规验证码 双重防护,保障验证码安全 黑灰产经常采用批量撞库方式登录用户账号,然后进行违法违规操作。 黑灰产将各种方…...
R-Meta分析教程
详情点击链接:R-Meta模型教程 一:Meta分析的选题与文献计量分析CiteSpace应用 1、Meta分析的选题与文献检索 1)什么是Meta分析? 2)Meta分析的选题策略 3)文献检索数据库 4)精确检索策略,如何检索全、检索准 5)文献的管理与…...
【3维视觉】3D空间常用算法(点到直线距离、面法线、二面角)
3D空间点到直线的距离 3D空间点到直线的距离 3D空间的曲率 三维空间有三个基本元素,点,线,面。那么曲率是如何定义的呢? 点的曲率? 线的曲率? 面的曲率? 法曲率 设曲面上的曲线在某一点处的切…...

Buzz音频转录完全指南:3大核心功能+5个实战场景,快速掌握本地语音转文字技术
Buzz音频转录完全指南:3大核心功能5个实战场景,快速掌握本地语音转文字技术 【免费下载链接】buzz Buzz transcribes and translates audio offline on your personal computer. Powered by OpenAIs Whisper. 项目地址: https://gitcode.com/GitHub_Tr…...

基于2D工程图几何特征与梯度提升模型的制造成本智能预测
1. 项目概述:从图纸到报价的智能革命在制造业,尤其是像汽车零部件这样的离散制造领域,报价速度直接决定了订单的生死。传统上,拿到一张新的2D工程图(DWG格式),成本工程师需要花上几天甚至几周时…...

Taurus多执行器对比实战:JMeter/Gatling/Locust统一压测方案
1. 为什么选Taurus做多执行器对比——不是为了炫技,而是为了少踩坑在性能测试领域,我见过太多团队卡在“选型”这一步:刚招来一个会写JMeter脚本的工程师,项目突然要压测WebSocket接口,发现JMeter原生支持弱、插件维护…...
)
蓝牙抓包不求人:从HCI日志里‘挖’出Link Key的两种实用方法(附安卓路径)
蓝牙安全逆向实战:从HCI日志中提取Link Key的深度解析在蓝牙协议安全研究领域,Link Key作为设备配对认证的核心凭证,其获取方式一直是逆向工程师关注的焦点。许多安全审计场景下,我们往往只能获得加密后的HCI通信日志,…...

信息系统项目管理师核心知识点精讲
一、项目整合管理(重点:项目章程与项目管理计划) 知识点详解: 项目整体管理是项目管理知识体系的核心,它确保项目各要素协调统一。在考试中,特别要掌握项目章程和项目管理计划的区别与联系。 项目章程是项目的“出生证明”,由项目发起人发布。它正式授权项目,赋予项…...

BLE蓝牙扫描深度剖析:扫描原理、核心参数、前后台差异
一、前言BLE设备交互分为两大角色:广播端(外设Peripheral)与扫描端(中心Central)。上一篇博客详解了四大广播模式,本文聚焦配套核心能力——BLE扫描机制。绝大多数蓝牙开发疑难问题:前台能扫后台…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...
)
Sora 2原生接入Unity 6.0:5步完成神经渲染管线嵌入,实测帧率提升47%(附GitHub认证插件)
更多请点击: https://kaifayun.com 第一章:Sora 2与Unity整合 Sora 2作为新一代AI视频生成引擎,其开放API设计天然支持与实时3D引擎的深度协同。Unity 2023.2版本通过URP(Universal Render Pipeline)与C# Job System提…...

【MySQL数据库 | 第一篇】 概述
数据库相关概念: 数据库(Database):数据库是指一组有组织的数据的集合,通过计算机程序进行管理和访问。数据库管理系统:操纵和管理数据库的大型软件SQL:操作关系型数据库的编程语言,定义了一套操作关系型数…...

独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者如何利用Taotoken Token Plan,以更低成本启动AI项目 对于独立开发者或小型团队而言,启动一个集成…...