阻塞队列BlockingQueue详解
一、阻塞队列介绍
1、队列

队列入队从队首开始添加,直至队尾;出队从队首出队,直至队尾,所以入队和出队的顺序是一样的
Queue接口
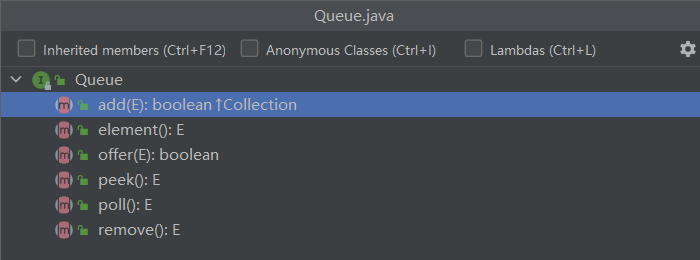
- add(E) :在指定队列容量条件下添加元素,若成功返回true,若当前队列没有可用空间抛出IllegalStateException异常
- offer(E):在指定队列容量条件下添加元素,若成功返回true,若当前队列没有可用空间返回false
- remove():返回并删除此队列的头部元素,若队列为空会抛出异常
- poll():返回并删除此队列的头部元素,若队列为空会返回null
- element():返回头部元素,但不删除,队列为空会抛出异常
- peek():返回头部元素,但不删除,队列为空返回null
2、阻塞队列
BlockingQueue规范定义了添加和删除阻塞队列的方法,很多阻塞队列都是基于BlockingQueue实现的,具体原理:当阻塞队列插入数据时,如果队列已满,线程会阻塞等待直到队列非满;从阻塞队列取数据时,如果队列已空,线程会阻塞等待直到队列非空
1)BlockingQueue接口
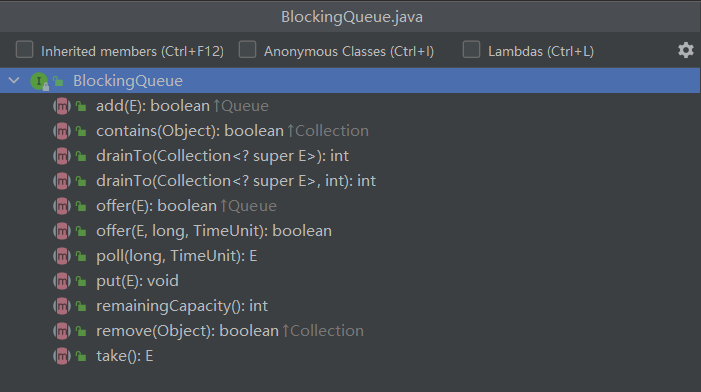
- put():将指定元素插入队列,如果必要等待队列空间变为可用
- take():返回并删除队列中的头部元素,如果必要直到等待某个元素可用
- offer(E, long, TimeUnit):将指定的元素插入此队列,指定的等待时间等待必要的可用空间
- poll(long, TimeUnit):返回并删除此队列的头部元素,指定的等待时间,直到等待某个元素可用
2)应用场景
- 线程池:线程池中线程创建的个数超过核心线程数,会放入到等待队列中,如果队列空了,核心线程又没有要处理的任务,会进入等待,直到队列中有新的任务
- 生产者-消费者模式:当生产者线程发现队列满了会陷入等待,直到有消费者线程进行消费并唤醒生产者线程;当消费者线程发现队列中没有可处理消息会陷入等待,直到生产者线程进行生产并唤醒消费者线程,阻塞队列可以避免线程间的竞争
- 消息队列:可以把消息放到队列中,进行消息的异步处理
- 缓存系统:使用contains()方法判断是否包含某个元素,利用阻塞队列来缓存数据,避免多线程更新缓存的竞争
- 并发任务处理:将任务提交到队列中,消费之后出队,避免重复消费
3、JUC包下的阻塞队列
二、ArrayBlockingQueue
ArrayBlockingQueue采用Object数组方式存储数据,创建ArrayBlockingQueue必须指定容量大小,属于有界队列,采用ReentrantLock保证线程安全,如果生产速度和消费速度基本匹配的情况下,使用ArrayBlockingQueue是个不错选择
1、使用
public class ArrayBlockingQueueTest {private static final int QUEUE_CAPACITY = 5;private static final int PRODUCER_DELAY_MS = 1000;private static final int CONSUMER_DELAY_MS = 2000;public static void main(String[] args) throws InterruptedException {// 创建一个容量为QUEUE_CAPACITY的阻塞队列BlockingQueue<String> queue = new ArrayBlockingQueue<>(QUEUE_CAPACITY);// 创建一个生产者线程Runnable producer = () -> {while (true) {try {// 在队列满时阻塞queue.put("producer");System.out.println("生产了一个元素,队列中元素个数:" + queue.size());Thread.sleep(PRODUCER_DELAY_MS);} catch (InterruptedException e) {e.printStackTrace();}}};new Thread(producer).start();// 创建一个消费者线程Runnable consumer = () -> {while (true) {try {// 在队列为空时阻塞String element = queue.take();System.out.println("消费了一个元素,队列中元素个数:" + queue.size());Thread.sleep(CONSUMER_DELAY_MS);} catch (InterruptedException e) {e.printStackTrace();}}};new Thread(consumer).start();}
}生产者少休眠1s,生产的快,当生产者添加第六个元素时会陷入等待
2、源码分析
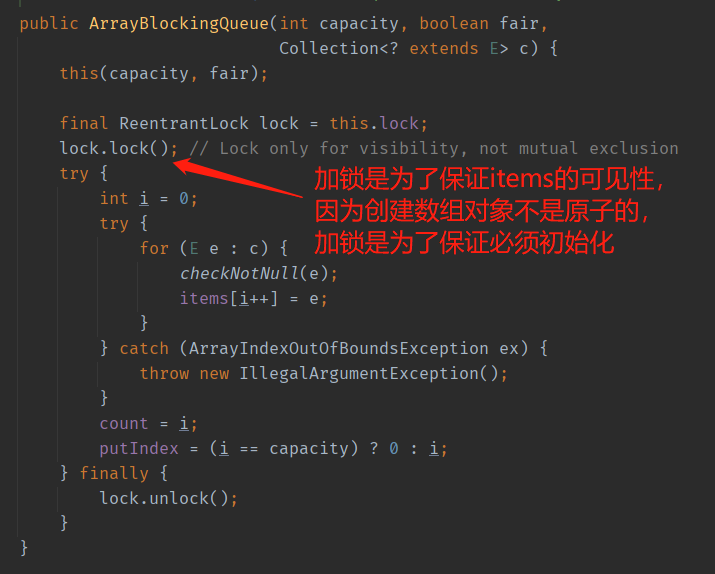

- items:数组元素数组
- takeIndex:下一个待取出元素索引
- putIndex:下一个待添加元素索引
- count:元素个数
- lock:内置锁
- notEmpty:消费者
- notFull:生产者
入队详解
https://www.processon.com/view/link/64c8c537b9f7806c73dadbb4
出队详解
https://www.processon.com/view/link/64c8c92fb9f7806c73daea85
为什么ArrayBlockingQueue对数组操作要设计成双指针?
如果用一个指针,对数组的删除或者添加操作,数组中的元素都要往前或者往后移动,这样导致时间复杂度为O(n),而使用双指针可以前移后移,可以提升操作的性能,时间复杂度为O(1)
三、LinkedBlockingQueue
LinkedBlockingQueue是基于链表实现的阻塞队列,队列默认大小为Integer.MAX_VALUE,由于这个数值比较大,LinkedBlockingQueue也被称为无界队列,LinkedBlockingQueue每个元素都会占用内存,为防止OOM还是设置一个队列大小
1、使用
和ArrayBlockingQueue使用基本差不多
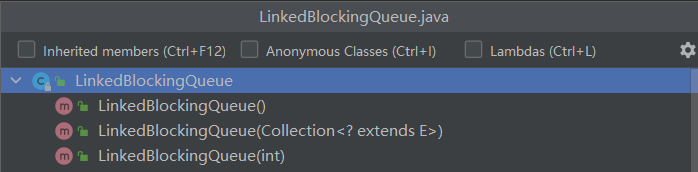
- LinkedBlockingQueue():队列大小为2的32次方减1
- LinkedBlockingQueue(Collection<? extends E>):队列大小为2的32次方减1,按照传入集合初始化队列数据
- LinkedBlockingQueue(int):传入参数指定队列大小
2、源码分析
相比ArrayBlockingQueue读写只一把独占锁的实现,LinkedBlockingQueue读写分了两把锁
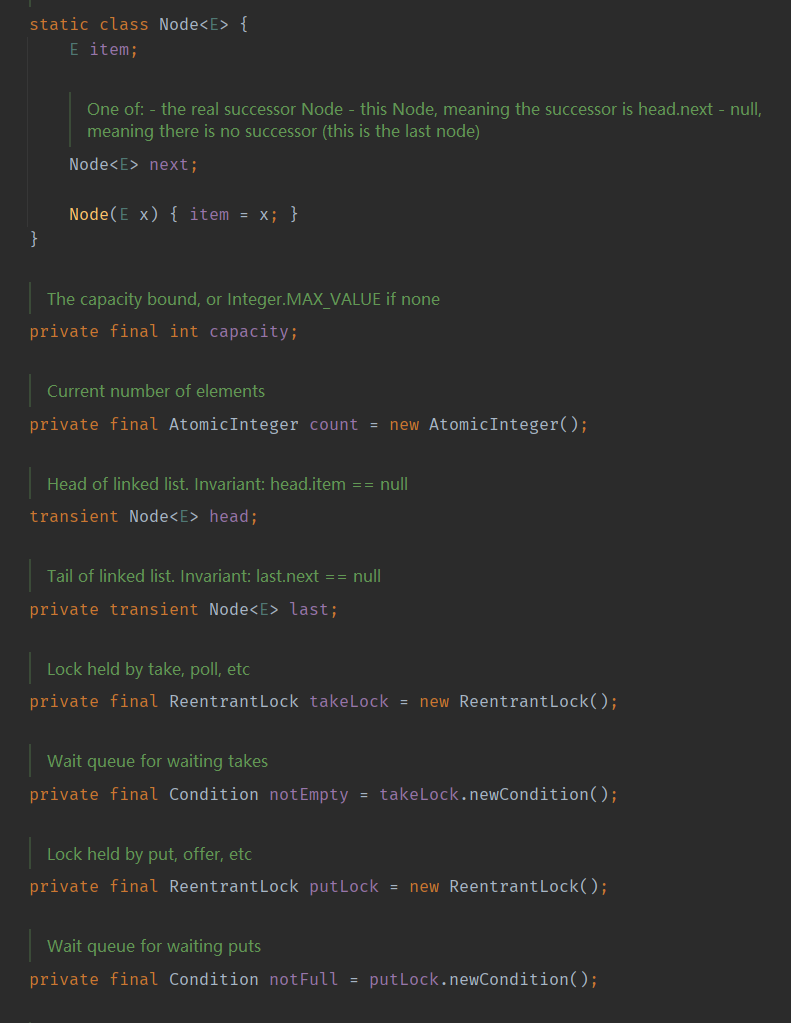
- item:元素存储的数据
- next:下一个节点,单项链表结构
- capacity:队列容量
- count:元素数量
- head:链表表头
- last链表表尾
- takeLock:出队操作竞争的锁对象
- notEmpty:当队列无元素时,会让进行takeLock的线程陷入等待,直到有线程唤醒
- putLock:入队操作竞争的锁对象
- notFull:当队列满了,会让进行putLock的线程陷入等待,直到有线程唤醒
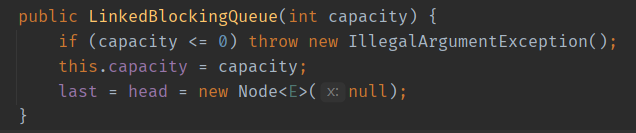
初始化LinkedBlockingQueue对象时,会创建一个属性item为null的Node对象
入队详解
https://www.processon.com/view/link/64c8f6d5b9f7806c73db4fc9
出队详解
https://www.processon.com/view/link/64c8ff0e7807695f1493090f
3、LinkedBlockingQueue和ArrayBlockingQueue对比
- 队列大小:ArrayBlockingQueue必须指定容量大小,LinkedBlockingQueue可以不指定,LinkedBlockingQueue如果添加比删除快会导致OOM
- 数组存储容器不同:ArrayBlockingQueue采用数组存储数据,LinkedBlockingQueue采用对象链表方式存储数据;就因为会产生Node对象,并发量大时会对gc产生较大的影响
- ArrayBlockingQueue添加和删除都是争抢同一个锁资源,LinkedBlockingQueue添加和删除进行了锁分离,LinkedBlockingQueue高并发场景下可以并行的进行入队和出队操作
四、DelayQueue
可以使用队列消息延迟消费,实现接口回调通知、token超时失效、订单超时失效
1、使用
public class DelayQueueTest {public static void main(String[] args) throws InterruptedException {DelayQueue<Order> delayQueue = new DelayQueue<>();delayQueue.put(new Order("order1", System.currentTimeMillis(), 5000));delayQueue.put(new Order("order2", System.currentTimeMillis(), 2000));delayQueue.put(new Order("order3", System.currentTimeMillis(), 3000));while (!delayQueue.isEmpty()) {Order take = delayQueue.take();System.out.println("处理订单:"+take.getOrderId());}}static class Order implements Delayed {private String orderId;private long createTime;private long delayTime;public Order(String orderId, long createTime, long delayTime) {this.orderId = orderId;this.createTime = createTime;this.delayTime = delayTime;}public String getOrderId() {return orderId;}@Overridepublic long getDelay(TimeUnit unit) {// 订单创建时间+延迟时间-当前时间=剩余延迟时间long diff = createTime + delayTime - System.currentTimeMillis();return unit.convert(diff, unit);}@Overridepublic int compareTo(Delayed o) {// 比较两个订单之间差多长时间long diff = this.getDelay(TimeUnit.MILLISECONDS) - o.getDelay(TimeUnit.MILLISECONDS);return Long.compare(diff, 0);}}
}2、源码分析
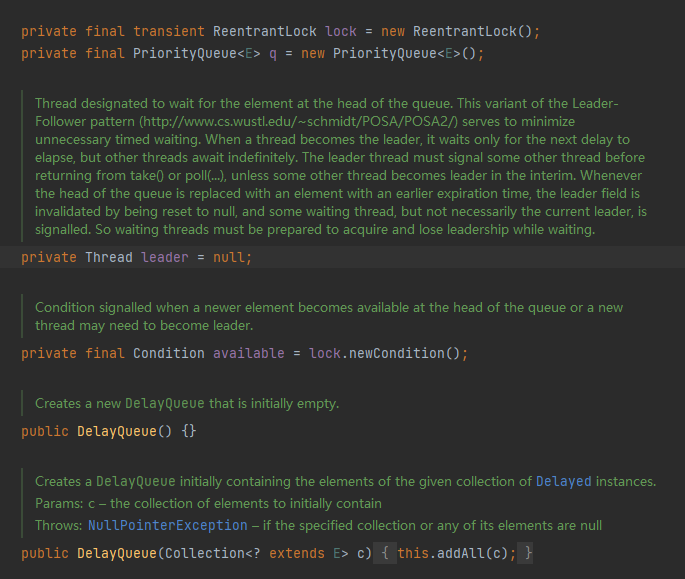
- lock:用于保证线程安全
- q: 优先级队列,存储元素,用于保证延迟低的优先执行
- leader:用于标记当前是否有线程在排队(仅用于取元素时) leader 指向的是第一个从队列获取元素阻塞的线程
- available:条件,用于表示现在是否有可取的元素 当新元素到达,或新线程可能需要成为leader时被通知
入队详解
https://www.processon.com/view/link/64c91879470d721c4e3be985
出队详解
https://www.processon.com/view/link/64c9185fc1af4746895281e7
五、如何选择适合的阻塞队列
1、选择策略
通常我们可以从以下 5 个角度考虑,来选择合适的阻塞队列:
功能
第 1 个需要考虑的就是功能层面,比如是否需要阻塞队列帮我们排序,如优先级排序、延迟执行等。如果有这个需要,我们就必须选择类似于 PriorityBlockingQueue 之类的有排序能力的阻塞队列。
容量
第 2 个需要考虑的是容量,或者说是否有存储的要求,还是只需要“直接传递”。在考虑这一点的时候,我们知道前面介绍的那几种阻塞队列,有的是容量固定的,如 ArrayBlockingQueue;有的默认是容量无限的,如 LinkedBlockingQueue;而有的里面没有任何容量,如 SynchronousQueue;而对于 DelayQueue 而言,它的容量固定就是 Integer.MAX_VALUE。所以不同阻塞队列的容量是千差万别的,我们需要根据任务数量来推算出合适的容量,从而去选取合适的 BlockingQueue。
能否扩容
第 3 个需要考虑的是能否扩容。因为有时我们并不能在初始的时候很好的准确估计队列的大小,因为业务可能有高峰期、低谷期。如果一开始就固定一个容量,可能无法应对所有的情况,也是不合适的,有可能需要动态扩容。如果我们需要动态扩容的话,那么就不能选择 ArrayBlockingQueue ,因为它的容量在创建时就确定了,无法扩容。相反,PriorityBlockingQueue 即使在指定了初始容量之后,后续如果有需要,也可以自动扩容。所以我们可以根据是否需要扩容来选取合适的队列。
内存结构
第 4 个需要考虑的点就是内存结构。我们分析过 ArrayBlockingQueue 的源码,看到了它的内部结构是“数组”的形式。和它不同的是,LinkedBlockingQueue 的内部是用链表实现的,所以这里就需要我们考虑到,ArrayBlockingQueue 没有链表所需要的“节点”,空间利用率更高。所以如果我们对性能有要求可以从内存的结构角度去考虑这个问题。
性能
第 5 点就是从性能的角度去考虑。比如 LinkedBlockingQueue 由于拥有两把锁,它的操作粒度更细,在并发程度高的时候,相对于只有一把锁的 ArrayBlockingQueue 性能会更好。另外,SynchronousQueue 性能往往优于其他实现,因为它只需要“直接传递”,而不需要存储的过程。如果我们的场景需要直接传递的话,可以优先考虑 SynchronousQueue。
2、线程池对于阻塞队列的选择
线程池有很多种,不同种类的线程池会根据自己的特点,来选择适合自己的阻塞队列。
Executors类下的线程池类型:
- FixedThreadPool(SingleThreadExecutor 同理)选取的是 LinkedBlockingQueue
- CachedThreadPool 选取的是 SynchronousQueue
- ScheduledThreadPool(SingleThreadScheduledExecutor同理)选取的是延迟队列
相关文章:
阻塞队列BlockingQueue详解
一、阻塞队列介绍 1、队列 队列入队从队首开始添加,直至队尾;出队从队首出队,直至队尾,所以入队和出队的顺序是一样的 Queue接口 add(E) :在指定队列容量条件下添加元素,若成功返回true,若当前…...
pygame贪吃蛇游戏
pygame贪吃蛇游戏 贪吃蛇游戏通过enter键启动,贪吃蛇通过WSAD进行上下左右移动,每次在游戏区域中随机生成一个食物,每次吃完食物后,蛇变长并且获得积分;按空格键暂停。 贪吃蛇 import random, sys, time, pygame from …...

Mac系统下使用远程桌面连接Windows系统
一、远程桌面工具 Microsoft Remote Desktop 二、下载地址 https://go.microsoft.com/fwlink/?linkid868963 三、下载并安装 四、添加远程PC PC name:云服务器IP。 User account: 添加系统用户 PC name:远程桌面 IP 地址User account:可以选择是…...

使用 OpenCV 和深度学习对黑白图像进行着色
在本文中,我们将创建一个程序将黑白图像(即灰度图像)转换为彩色图像。我们将为此程序使用 Caffe 着色模型。您应该熟悉基本的 OpenCV 功能和用法,例如读取图像或如何使用 dnn 模块加载预训练模型等。现在让我们讨论实现该程序所遵循的过程。 给定一张灰度照片作为输入,本文…...

从价值的角度看,为何 POSE 通证值得长期看好
PoseSwap 是 Nautilus Chain 上的首个 DEX,基于 Nautilus Chain 也让其成为了首个以模块化构建的 Layer3 架构的 DEX。该 DEX 本身能够以 Dapp 层(Rollup)的形态,与其他应用层并行化运行。...
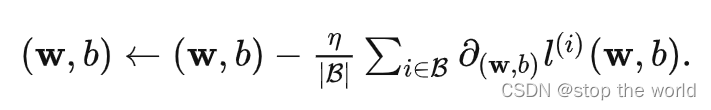
pytorch的CrossEntropyLoss交叉熵损失函数默认reduction是平均值
pytorch中使用nn.CrossEntropyLoss()创建出来的交叉熵损失函数计算损失默认是求平均值的,即多个样本输入后获取的是一个均值标量,而不是样本大小的向量。 net nn.Linear(4, 2) loss nn.CrossEntropyLoss() X torch.rand(10, 4) y torch.ones(10, dt…...

OKR管理策略:为开发团队注入动力
引言 在这个快速变化的世界中,公司需要迅速应对市场变化,并保持其目标和战略的清晰性和一致性。而OKR(Objectives and Key Results)正是这个挑战的解决方案之一。OKR的实施可以帮助开发团队明确目标,关注关键结果&…...

C++二叉搜索树剖析
目录 🍇二叉搜索树概念🍈二叉搜索树查找🍉二叉搜索树的插入🍊二叉搜索树的删除🍍二叉搜索树的查找、插入、删除实现🍋二叉搜索树的应用🥭二叉搜索树的性能分析🍓总结 🍇二…...
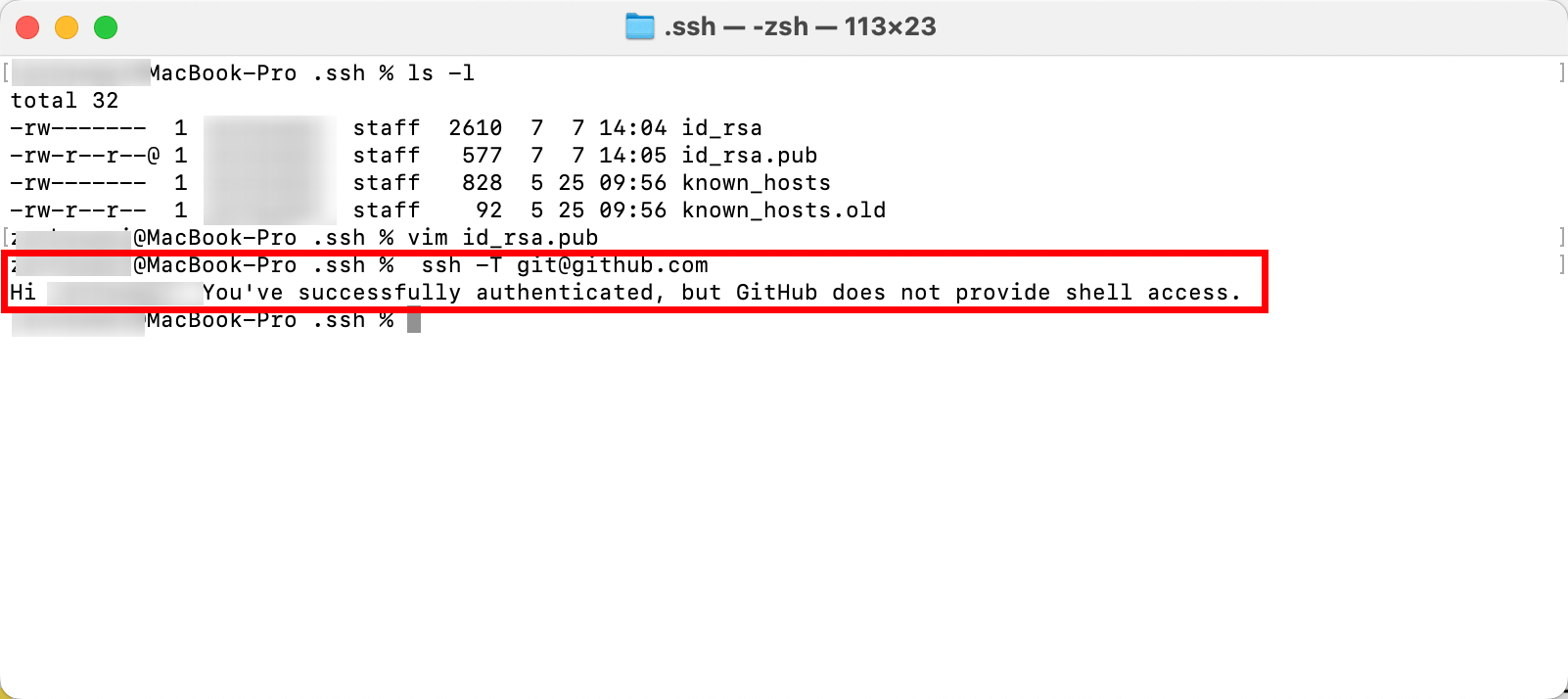
升级你的GitHub终端认证方式:从密码到令牌
升级你的GitHub终端认证方式:从密码到令牌 前言 GitHub官方在2021年8月14日进行了一次重大改变,它将终端推送代码时所需的身份认证方式从密码验证升级为使用个人访问令牌(Personal Access Token)。这个改变引起了一些新的挑战&am…...
【力扣】链表题目总结
文章目录 链表基础题型一、单链表翻转、反转、旋转1.反转链表2.反转链表II——反转部分链表3.旋转链表4.K个一组翻转链表5.反转偶数长度组的节点 二、删除单链表中的结点1.删除链表的结点2.删除未排序链表中的重复节点3.删除已排序链表中的重复元素I——重复元素只剩下一个4.删…...

Thunar配置自定义动作
Add “Copy To” and “Move To” custom actions in Thunar file manager | For the record 1.在此打开终端 图标-应用程序:utilities-terminal 命令:exo-open --working-directory %f --launch TerminalEmulator 文件类型:* 目录 2.右键增…...
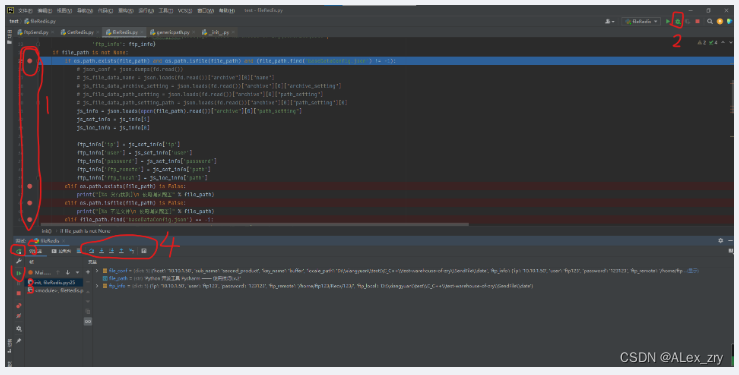
Python 开发工具 Pycharm —— 使用技巧Lv.3
单步执行调试 1: 鼠标左键单击红点是断点行 2:甲虫样式是进行调试方式运行,鼠标左键单击点击 3: 单步运行图标,点击让程序运行一行 4: 步入步出,可以进入当前代码行函数内 5:重新运行…...
51单片机(普中HC6800-EM3 V3.0)实验例程软件分析 实验三 LED流水灯
目录 前言 一、原理图及知识点介绍 二、代码分析 知识点五:#include 中的库函数解析 _crol_,_irol_,_lrol_ _cror_,_iror_,_lror_ _nop_ _testbit_ 前言 第一个实验:51单片机(普中HC6800-EM3 V3.0…...

深度学习与计算机相结合:直播实时美颜SDK的创新之路
时下,实时美颜技术就成为了直播主们的得力工具,它可以在直播过程中即时处理视频画面。而支持实时美颜功能的SDK更是推动了这项技术的发展,让直播主和普通用户都能轻松使用美颜功能。 一、美颜技术的演进 早期的美颜技术主要依赖于简单的图…...

Unity寻找子物体的方法
1.GetComponentsInChildren() 查找单个子物体 GameObject childObjectGetComponentInChildren<Transform>(); 查找多个子物体 Transform[] myTransforms GetComponentsInChildren<Transform>(); foreach (var child in myTransforms){ Debug.Log(child.name…...

车载软件架构 —— 车载软件安全启动关键技术解读
车载软件架构 —— 车载软件安全启动关键技术解读 我是穿拖鞋的汉子,魔都中坚持长期主义的汽车电子工程师。 老规矩,分享一段喜欢的文字,避免自己成为高知识低文化的工程师: 没有人关注你。也无需有人关注你。你必须承认自己的价值,你不能站在他人的角度来反对自己。人生…...

2023-08-05——JVM Method Area(方法区)
方法区 Method Area(方法区) 方法区是指被所有线程共享的,字段和方法字节码,以及一些特殊方法,如构造函数,接口代码在此定义,简单的说就是所有的定义方法信息都保存在此区域,此区域…...
【前端知识】React 基础巩固(四十六)——自定义Hook的应用
React 基础巩固(四十六)——自定义Hook的应用 一、自定义Hook的应用 自定义Hook本质上只是一种函数代码逻辑的抽取,严格意义上而言,它并不算React的特性。 实现组件创建/销毁时打印日志 import React, { memo, useEffect, useState } from "react…...
Swish - Mac 触控板手势窗口管理工具[macOS]
Swish for Mac是一款Mac触控板增强工具,借助直观的两指轻扫,捏合,轻击和按住手势,就可以从触控板上控制窗口和应用程序。 Swish for Mac又不仅仅只是一个窗口管理器,Swish具有28个易于使用的标题栏,停靠栏…...

【雕爷学编程】MicroPython动手做(31)——物联网之Easy IoT 2
1、物联网的诞生 美国计算机巨头微软(Microsoft)创办人、世界首富比尔盖茨,在1995年出版的《未来之路》一书中,提及“物物互联”。1998年麻省理工学院提出,当时被称作EPC系统的物联网构想。2005年11月,国际电信联盟发布《ITU互联网…...

【计算机毕业设计】基于Springboot的工作流程管理系统设计与实现+万字文档
博主介绍:✌全网粉丝3W,csdn特邀作者、CSDN新星计划导师、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和学生毕业项目实战,高校老师/讲师/同行前辈交流✌ 技术范围:SpringBoot、Vue、SSM、HLMT、Jsp、PHP、Nodejs、…...

如何用AI语音修复工具VoiceFixer:快速拯救受损音频的完整指南
如何用AI语音修复工具VoiceFixer:快速拯救受损音频的完整指南 【免费下载链接】voicefixer General Speech Restoration 项目地址: https://gitcode.com/gh_mirrors/vo/voicefixer 还在为嘈杂的录音、失真的语音或老旧音频而烦恼吗?VoiceFixer是一…...

DepHell与Docker集成:容器化Python应用开发的终极指南
DepHell与Docker集成:容器化Python应用开发的终极指南 【免费下载链接】dephell :package: :fire: Python project management. Manage packages: convert between formats, lock, install, resolve, isolate, test, build graph, show outdated, audit. Manage ven…...

3分钟彻底解决Cursor试用限制:设备标识重置技术深度解析
3分钟彻底解决Cursor试用限制:设备标识重置技术深度解析 【免费下载链接】go-cursor-help 解决Cursor在免费订阅期间出现以下提示的问题: Your request has been blocked as our system has detected suspicious activity / Youve reached your trial request limit…...

30分钟搞定黑苹果:OpCore Simplify如何让Hackintosh配置从专业难题变成简单操作
30分钟搞定黑苹果:OpCore Simplify如何让Hackintosh配置从专业难题变成简单操作 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 还在为复杂…...

90%的人只用了Superpowers 10%的能力,实战案例带你走通全流程
装了Superpowers还是不会用?这套完整工作流,让你的AI从“工具”变“搭档”你可能已经在 GitHub 上给 Superpowers 点过 Star 了,甚至在本地环境里跑了一遍安装流程。但说实话,你大概率只触发了其中一两个 Skill——写代码时偶尔触…...

【SRC漏洞挖掘系列】第04期:文件上传与解析——把图片变成“特洛伊木马”
上期回顾:我们刚用 SQL 注入把数据库翻了个底朝天。本期我们来聊聊更暴力的漏洞——文件上传。如果说 SQL 注入是“偷”,那文件上传就是直接往人家服务器里安炸弹。💣一、为什么文件上传是“高危”?在 SRC 评级里,GetS…...

C51内存优化:DATA段间隙问题解决方案
1. C51内存空间中的DATA段间隙问题解析作为一名长期使用Keil C51开发工具链的嵌入式工程师,我经常遇到内存空间利用率问题。最近在调试一个使用bit变量的项目时,发现链接器在寄存器组和bit区域之间留下了15字节的间隙。这种内存浪费在资源紧张的8051系统…...
)
Allegro PCB设计自查清单:用Quick Reports快速搞定投板前的关键检查(附Dangling Line定位技巧)
Allegro PCB设计投板前终极自查指南:用Quick Reports构建高效质检流水线 在PCB设计领域,最后的5%往往消耗50%的精力。当设计进入投板前的关键阶段,工程师们常陷入两难:要么因过度谨慎反复全盘检查导致项目延期,要么因遗…...

3步掌握HTTrack:免费网站离线下载工具终极指南
3步掌握HTTrack:免费网站离线下载工具终极指南 【免费下载链接】httrack HTTrack Website Copier, copy websites to your computer (Official repository) 项目地址: https://gitcode.com/gh_mirrors/ht/httrack 你是否经常遇到网络不稳定,却急需…...