Stable Diffusion 硬核生存指南:WebUI 中的 GFPGAN
本篇文章聊聊 Stable Diffusion WebUI 中的核心组件,强壮的人脸图像面部画面修复模型 GFPGAN 相关的事情。
写在前面
本篇文章的主角是开源项目 TencentARC/GFPGAN,和上一篇文章《Stable Diffusion 硬核生存指南:WebUI 中的 CodeFormer》提到的项目在某种程度上算是“开源项目的竞争者”。
有趣的是,上一篇文章中的 CodeFormer 在实现过程中,有非常多的项目代码有借鉴和使用 GFPGAN 主力维护者 xintao 的项目,某种程度上来说,两个项目存在一定的“亲缘”关系。
在去年五月份,我写过一篇《使用 Docker 来运行 HuggingFace 海量模型》,其中就使用了 GFPGAN 做了一期例子,本文中提到的内容,已经更新至之前的开源项目 soulteary/docker-gfpgan。

相关模型文件已经上传到网盘里了,感兴趣可以自取,别忘记“一键三连”。
下面依旧先进入热身阶段。
GFPGAN 相关前置知识
如果你对前置知识不感兴趣,只是想快速上手,可以跳过这个章节,阅读“快速上手”部分。
如果你想系统的了解人脸恢复相关的知识,强烈推荐扩展阅读这篇内容《A Survey of Deep Face Restoration: Denoise, Super-Resolution, Deblur, Artifact Removal》。
本文提到的 GFPGAN 属于 2021 年的“七代目”方案:基于 GAN 网络和预训练模型来进行人脸修复。
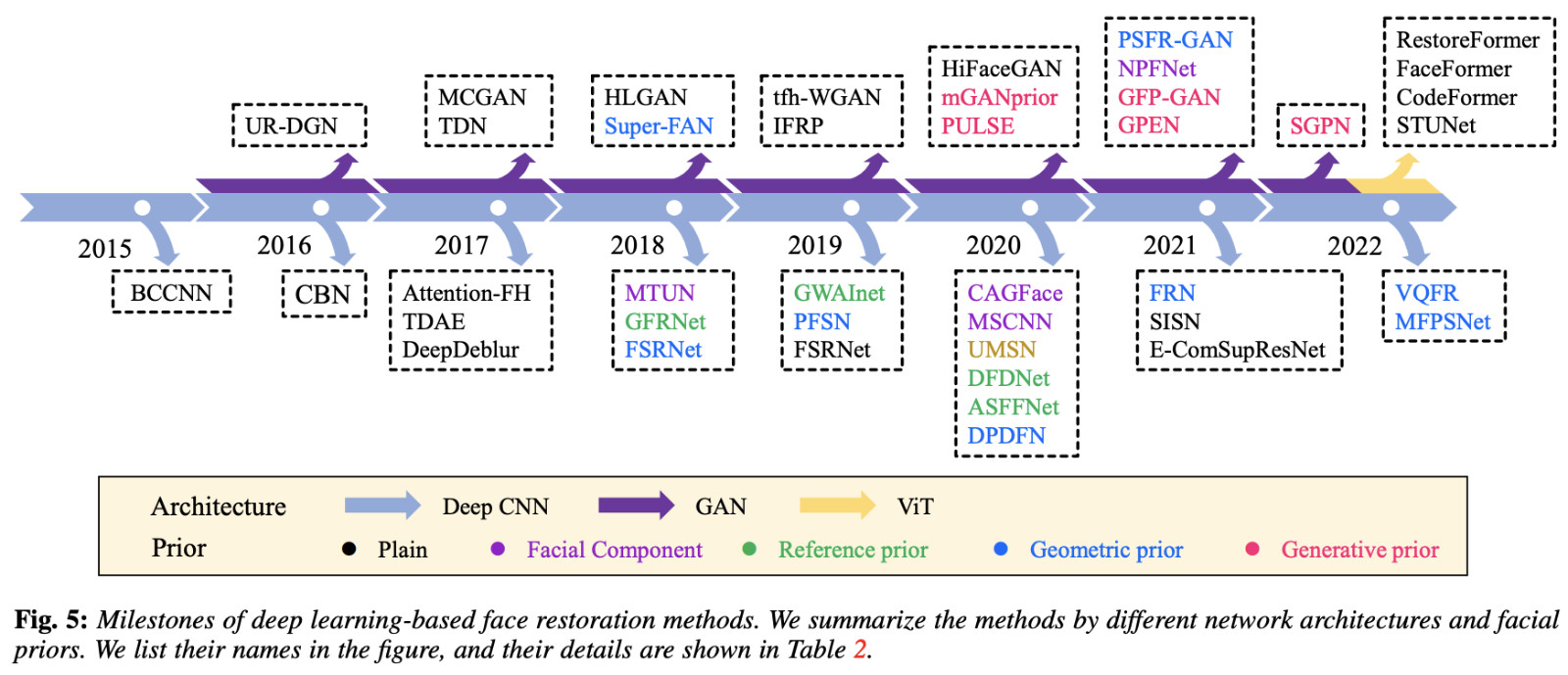
主要思路是先通过 “degradation removal module (U-Net)” 模块对图片进行质量降低,并添加一些模糊和燥点。(看过《Stable Diffusion 硬核生存指南:WebUI 中的 VAE》的同学是不是觉得有相似之处呢。
接着,使用诸如 StyleGAN 方式的预训练人脸 GAN 模型,处理这些获得人脸细节的潜在向量特征,生成具备真实性但细节不完善的图像,并结合一些 “Channel-Split Spatial Feature Transform (CS-SFT) ”通道连接不同模块的潜在向量特征,然后结合其他模块进行数据处理。
在图像变清晰的过程中,主要有四种挑战:“Reconstruction Loss” 使用预训练的 VGG-19 网络来完成分辨率的增强;“Adversarial Loss” 使用 StyleGAN2 中类似的方法来生成逼真的纹理;“Facial Component Loss” 为了让面部细节真实,使用辨别器单独生成和应用面部区块的补丁,特别处理了眼睛、嘴巴等局部细节;“Identity Preserving Loss” 使用预训练的 ArcFace 模型,来帮助将原始图片中的身份特征恢复到 GFPGAN 生成的新图片中。
模型训练过程使用的数据集很有趣,“真真假假” 两种都有:
- 大量的合成数据,在使用时预先对这些图片进行质量降低,模拟真实场景。
- CelebFaces Attributes Dataset (CelebA),包含 20 万张名人的图片数据集。
在 Stable Diffusion WebUI 中的使用
在 Stable Diffusion 图片生成过程中,它和前一篇文章《Stable Diffusion 硬核生存指南:WebUI 中的 CodeFormer》中提到的 CodeFormer 一样,也并不直接参与图片生成工作,而是在图片绘制完毕之后,在“后处理”阶段,进行面部细节恢复操作,这个后处理过程在 Stable Diffusion WebUI 的 process_images_inner 过程中。
同样的,因为本文主角是 GFPGAN,所以,我们就先不过多展开不相关的细节啦。有关于 WebUI 和 GFPGAN 相关需要注意的部分,在本文下面的章节中会聊。
准备工作
准备工作部分,我们依旧只需要做两个工作:准备模型文件和模型运行环境。
关于模型运行环境,可以参考之前的文章《基于 Docker 的深度学习环境:入门篇》,如果你是 Windows 环境的用户,可以参考这篇《基于 Docker 的深度学习环境:Windows 篇》。
如果你不熟悉如何在 Docker 环境中使用 GPU,建议仔细阅读。考虑篇幅问题,本文就不赘述相关的话题啦。
只要你安装好 Docker 环境,配置好能够在 Docker 容器中调用显卡的基础环境,就可以进行下一步啦。
快速封装一个 GFPGAN Docker 容器应用
从 Docker GFPGAN 项目下载代码,并进入项目目录:
git clone https://github.com/soulteary/docker-gfpgan.gitcd docker-gfpgan
执行项目中的镜像构建工具:
scripts/build.sh
耐心等待镜像构建完毕:
# bash scripts/build.sh [+] Building 71.8s (9/9) FINISHED => [internal] load .dockerignore 0.1s=> => transferring context: 2B 0.0s=> [internal] load build definition from Dockerfile 0.1s=> => transferring dockerfile: 277B 0.0s=> [internal] load metadata for nvcr.io/nvidia/pytorch:23.04-py3 0.0s=> CACHED [1/4] FROM nvcr.io/nvidia/pytorch:23.04-py3 0.0s=> [internal] load build context 0.1s=> => transferring context: 5.69kB 0.0s=> [2/4] RUN pip install gfpgan==1.3.8 realesrgan==0.3.0 facexlib==0.3.0 gradio==3.39.0 70.1s=> [3/4] WORKDIR /app 0.1s => [4/4] COPY src/app.py ./ 0.1s => exporting to image 1.5s => => exporting layers 1.5s => => writing image sha256:5ff7f79fe177c581f22c87bf575273ae4710fc604782cdbd5c955b7c27ef3b10 0.0s => => naming to docker.io/soulteary/docker-gfpgan 0.0s
同样,因为项目锁定了 Python 3.8,所以我们暂时只能使用 nvidia/pytorch:23.04-py3 来作为基础镜像。
在完成基础镜像构建之后,可以从网盘下载 models.zip (如果地址失效,请前往项目 issue 反馈)。模型应用运行需要的所有模型都在这里了,下载完毕后,解压缩模型压缩包,将 gfpgan、model 两个目录放置到项目的根目录中,完整的项目结构是这样的:
├── docker
├── gfpgan
│ └── weights
│ ├── detection_Resnet50_Final.pth
│ └── parsing_parsenet.pth
├── LICENSE
├── model
│ ├── GFPGANCleanv1-NoCE-C2.pth
│ ├── GFPGANv1.2.pth
│ ├── GFPGANv1.3.pth
│ ├── GFPGANv1.4.pth
│ ├── GFPGANv1.pth
│ ├── README.md
│ ├── RealESRGAN_x2plus.pth
│ ├── realesr-general-x4v3.pth
│ └── RestoreFormer.pth
├── README.md
├── scripts
└── src
准备好模型文件之后,使用下面的命令启动模型应用:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -v `pwd`/model:/app/model -v `pwd`/gfpgan:/app/gfpgan -p 7860:7860 soulteary/docker-gfpgan
稍等片刻,我们将看到类似下面的日志:
Running on local URL: http://0.0.0.0:7860To create a public link, set `share=True` in `launch()`.
接着,我们就可以打开浏览器访问 http://localhost:7860 或者 http://你的IP地址:7860 来试试看啦。
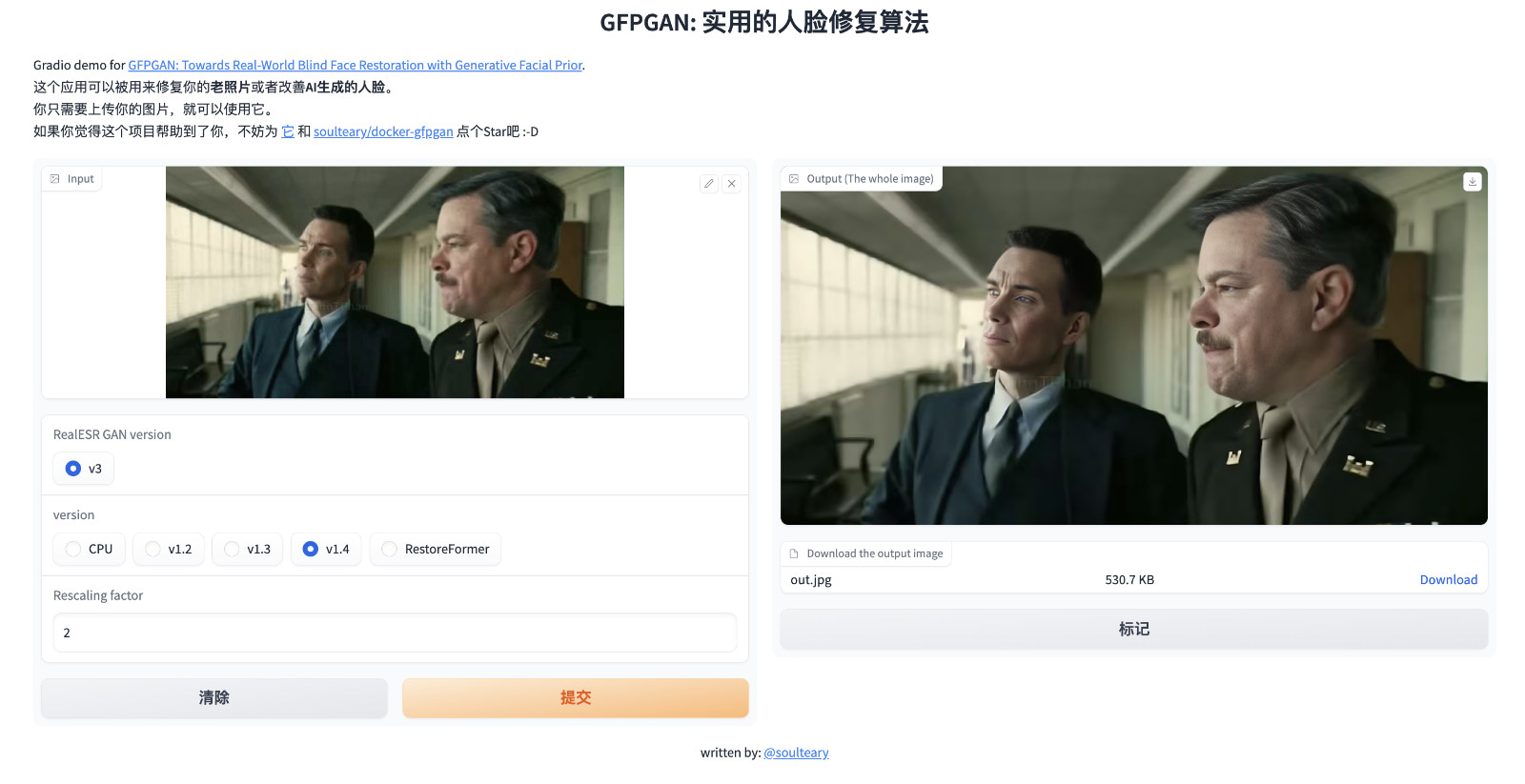
完整的代码和 Docker 封装逻辑,都在 soulteary/docker-gfpgan 里,因为接下来要聊 GFPGAN 的逻辑,所以我们就不展开啦。
如果你想使用包含 v1 最初发布版本模型在内的功能,可以参考文末 Stable Diffusion WebUI 小节中的方法。
显卡资源使用
GFPGAN 和 CodeFormer 类似,显卡资源需求不多,处理过程中一般情况也不需要额外的显存申请:
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.125.06 Driver Version: 525.125.06 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... Off | 00000000:01:00.0 On | Off |
| 32% 41C P2 68W / 450W | 2395MiB / 24564MiB | 4% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------++-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 7156 G /usr/lib/xorg/Xorg 244MiB |
| 0 N/A N/A 7534 G /usr/bin/gnome-shell 142MiB |
| 0 N/A N/A 7551 G ...libexec/mutter-x11-frames 14MiB |
| 0 N/A N/A 8826 G ...AAAAAAAA== --shared-files 20MiB |
| 0 N/A N/A 9756 G /usr/bin/nautilus 24MiB |
| 0 N/A N/A 10042 C python 1944MiB |
+-----------------------------------------------------------------------------+
图片处理简单测试对比

GFPGAN 的模型版本有许多种,所以这里我就不展开测试了,各种模型的差异就留给有好奇心的你啦。
GFPGAN 代码执行逻辑
GFPGAN 的模型执行逻辑,简单来说和 CodeFormer 类似,也是读取图片,分析人脸使用模型进行处理、替换原图中的人脸,保存图片。
模型的加载和使用逻辑
在 TencentARC/GFPGAN/gfpgan/utils.py 文件中,定义了 GFPGANer 工具类,包含了主要的流程逻辑,默认提取并处理图像中的面部,然后将图片尺寸调整为 512x512,以及包含了对 GFPGAN 项目发布的各版本模型进行了调用上的兼容性处理。
在创建 GFPGAN 模型实例的时候,我们可以选择三种 GFPGAN 架构的模型:
clean适用于第一个版本(v1)模型之外的模型架构,使用 StyleGAN2 Generator 搭配 SFT 模块 (Spatial Feature Transform),这个选项也是程序的默认值,程序文件在 gfpgan/archs/gfpganv1_clean_arch.py。bilinear适用于在第三个版本(v1.3)和之后的模型,双线性算法实现,没有复杂的UpFirDnSmooth,程序文件在 gfpgan/archs/gfpgan_bilinear_arch.py。original第一个版本(v1)模型使用的架构,模型文件在 gfpgan/archs/gfpganv1_arch.py
在实际代码定义中,前两种架构的调用参数是一致的,而第三种 original 在参数 fix_decoder 上和前两者数值有差异,为 True。
还有一种全新的架构:RestoreFormer。这种架构就是我们第一篇硬核生存指南中提到的《Stable Diffusion 硬核生存指南:WebUI 中的 VAE》,相关程序文件在 gfpgan/archs/restoreformer_arch.py
在面部恢复过程中,还会使用到上一篇文章中提到的 facexlib 项目中的 retinaface_resnet50 模型,来对图片进行恢复和保存。
下面是简化后的程序,包含了 GFPGAN 的处图片理流程:
import cv2
import torch
from basicsr.utils import img2tensor, tensor2img
from torchvision.transforms.functional import normalizeclass GFPGANer():"""Helper for restoration with GFPGAN.Args:model_path (str): The path to the GFPGAN model. It can be urls (will first download it automatically).upscale (float): The upscale of the final output. Default: 2.arch (str): The GFPGAN architecture. Option: clean | original. Default: clean.channel_multiplier (int): Channel multiplier for large networks of StyleGAN2. Default: 2.bg_upsampler (nn.Module): The upsampler for the background. Default: None."""def __init__(self, model_path, upscale=2, arch='clean', channel_multiplier=2, bg_upsampler=None, device=None):self.upscale = upscaleself.bg_upsampler = bg_upsampler...self.gfpgan = self.gfpgan.to(self.device)@torch.no_grad()def enhance(self, img, has_aligned=False, only_center_face=False, paste_back=True, weight=0.5):self.face_helper.clean_all()if has_aligned: # the inputs are already alignedimg = cv2.resize(img, (512, 512))self.face_helper.cropped_faces = [img]else:self.face_helper.read_image(img)# get face landmarks for each faceself.face_helper.get_face_landmarks_5(only_center_face=only_center_face, eye_dist_threshold=5)# eye_dist_threshold=5: skip faces whose eye distance is smaller than 5 pixels# TODO: even with eye_dist_threshold, it will still introduce wrong detections and restorations.# align and warp each faceself.face_helper.align_warp_face()# face restorationfor cropped_face in self.face_helper.cropped_faces:# prepare datacropped_face_t = img2tensor(cropped_face / 255., bgr2rgb=True, float32=True)normalize(cropped_face_t, (0.5, 0.5, 0.5), (0.5, 0.5, 0.5), inplace=True)cropped_face_t = cropped_face_t.unsqueeze(0).to(self.device)try:output = self.gfpgan(cropped_face_t, return_rgb=False, weight=weight)[0]# convert to imagerestored_face = tensor2img(output.squeeze(0), rgb2bgr=True, min_max=(-1, 1))except RuntimeError as error:print(f'\tFailed inference for GFPGAN: {error}.')restored_face = cropped_facerestored_face = restored_face.astype('uint8')self.face_helper.add_restored_face(restored_face)if not has_aligned and paste_back:# upsample the backgroundif self.bg_upsampler is not None:# Now only support RealESRGAN for upsampling backgroundbg_img = self.bg_upsampler.enhance(img, outscale=self.upscale)[0]else:bg_img = Noneself.face_helper.get_inverse_affine(None)# paste each restored face to the input imagerestored_img = self.face_helper.paste_faces_to_input_image(upsample_img=bg_img)return self.face_helper.cropped_faces, self.face_helper.restored_faces, restored_imgelse:return self.face_helper.cropped_faces, self.face_helper.restored_faces, None在 GFPGANer 初始化完毕后,就可以调用 enhance 方法,来对图片进行画面增强了,依次会清理之前任务的战场、判断图片是否已经对齐,如果是已经对齐的图片,则直接将扣出来的人脸区域传递给下一个流程,如果尚未进行图片对齐,则读取图片然后获取所有的人脸区域。
接着依次将每一张人脸画面传递给 GFPGAN 模型进行处理,将处理后的结果使用 tensor2img 转换回图片,接着将处理好的人脸图像区域粘贴回原始图片。
这里如果用户设置了背景采样器,则会调用相关模型方法处理背景。整体上和 CodeFormer 的流程差不多。
模型训练
在项目的 gfpgan/train.py 程序中,包含了训练模型的入口。
执行程序实际会调用 gfpgan/models/gfpgan_model.py 文件进行模型训练,这部分不是本文重点,和 WebUI 关联性不大就不展开了。
Stable Diffusion WebUI 中的调用逻辑
在 WebUI 程序入口 webui.py 程序中,能够看到 GFPGAN 在程序初始化时进行了模型的加载,在 SD 主要绘图模型和上一篇文章提到的 CodeFormer 初始化之后:
def initialize():
...modules.sd_models.setup_model()startup_timer.record("setup SD model")codeformer.setup_model(cmd_opts.codeformer_models_path)startup_timer.record("setup codeformer")
...gfpgan.setup_model(cmd_opts.gfpgan_models_path)startup_timer.record("setup gfpgan")
...
上一篇文章中,CodeFormer 只能够通过一个参数来改变加载行为,到了 GFPGAN 后,我们能够使用的参数增加到了四个:
parser.add_argument("--gfpgan-dir", type=str, help="GFPGAN directory", default=('./src/gfpgan' if os.path.exists('./src/gfpgan') else './GFPGAN'))
parser.add_argument("--gfpgan-model", type=str, help="GFPGAN model file name", default=None)
parser.add_argument("--unload-gfpgan", action='store_true', help="does not do anything.")
parser.add_argument("--gfpgan-models-path", type=str, help="Path to directory with GFPGAN model file(s).", default=os.path.join(models_path, 'GFPGAN'))
程序在启动过程中,会调用 modules/launch_utils.py 程序中的 prepare_environment 来准备组件代码:
def prepare_environment():
...gfpgan_package = os.environ.get('GFPGAN_PACKAGE', "https://github.com/TencentARC/GFPGAN/archive/8d2447a2d918f8eba5a4a01463fd48e45126a379.zip")
...if not is_installed("gfpgan"):run_pip(f"install {gfpgan_package}", "gfpgan")
...
这里使用的版本,其实是 v1.3.5 版本后发布的一个临时提交 “update cog predict”,而在项目的 requirement 依赖声明文件中,我们能够看到项目会使用 1.3.8 版本的 GFPGAN。
当然,这个代码只会在本地依赖缺失的时候执行,但考虑到一致性,我们可以将其更新,改为相同版本,这里我提交了一个版本修正的 PR,如果作者合并之后,这个不一致的潜在问题就没有啦。
类似的,在模块程序 modules/gfpgan_model.py 中,定义了使用 GFPGAN 的图片处理过程,和上文中的处理逻辑也是一致的:
import modules.face_restoration
from modules import shareddef gfpgann():return modeldef send_model_to(model, device):model.gfpgan.to(device)model.face_helper.face_det.to(device)model.face_helper.face_parse.to(device)def gfpgan_fix_faces(np_image):return np_imagegfpgan_constructor = Nonedef setup_model(dirname):def my_load_file_from_url(**kwargs):return load_file_from_url_orig(**dict(kwargs, model_dir=model_path))def facex_load_file_from_url(**kwargs):return facex_load_file_from_url_orig(**dict(kwargs, save_dir=model_path, model_dir=None))def facex_load_file_from_url2(**kwargs):return facex_load_file_from_url_orig2(**dict(kwargs, save_dir=model_path, model_dir=None))class FaceRestorerGFPGAN(modules.face_restoration.FaceRestoration):def name(self):return "GFPGAN"def restore(self, np_image):return gfpgan_fix_faces(np_image)shared.face_restorers.append(FaceRestorerGFPGAN())
不过,默认的加载模型是 v1.4 版本,如果你有风格上的指定速度,或许也可以切换到 v1.3 版本。
实际调用 GFPGAN 的逻辑在 modules/postprocessing.py 和 scripts/postprocessing_gfpgan.py,依旧是依赖后处理脚本执行逻辑。
当然,因为 GFPGAN 和 CodeFormer 在项目中的作用类似,所以存在选择到底使用哪一种方案的选择题,这个模型选择功能,程序文件在 scripts/xyz_grid.py:
def apply_face_restore(p, opt, x):opt = opt.lower()if opt == 'codeformer':
...elif opt == 'gfpgan':is_active = Truep.face_restoration_model = 'GFPGAN'else:
...p.restore_faces = is_active
Stable Diffusion WebUI 中 GFPGAN 的额外注意事项
GFPGAN 的模型加载策略比 CodeFormer 写的健壮一些。所以不用担心加载不到模型,整个程序无法使用的问题。不过,它在初始化过程中,也不是没有问题,比如初始化过程中,这个模块会无限挂起(如果遇到网络问题)。
默认程序会查找程序目录下的 gfpgan/weights 的两个模型文件,如果下载不到,就会进行下载:
Downloading: "https://github.com/xinntao/facexlib/releases/download/v0.1.0/detection_Resnet50_Final.pth" to .../gfpgan/weights/detection_Resnet50_Final.pthDownloading: "https://github.com/xinntao/facexlib/releases/download/v0.2.2/parsing_parsenet.pth" to .../gfpgan/weights/parsing_parsenet.pth
这段行为的调用逻辑来自 GFPGAN 中的 gfpgan/utils.py:
from basicsr.utils.download_util import load_file_from_url...if model_path.startswith('https://'):model_path = load_file_from_url(url=model_path, model_dir=os.path.join(ROOT_DIR, 'gfpgan/weights'), progress=True, file_name=None)
loadnet = torch.load(model_path)
...
下载函数来自 XPixelGroup/BasicSR/basicsr/utils/download_util.py 程序中,简单封装的 torch.hub 中的方法:
from torch.hub import download_url_to_file, get_dirdef load_file_from_url(url, model_dir=None, progress=True, file_name=None):"""Load file form http url, will download models if necessary.Reference: https://github.com/1adrianb/face-alignment/blob/master/face_alignment/utils.pyArgs:url (str): URL to be downloaded.model_dir (str): The path to save the downloaded model. Should be a full path. If None, use pytorch hub_dir.Default: None.progress (bool): Whether to show the download progress. Default: True.file_name (str): The downloaded file name. If None, use the file name in the url. Default: None.Returns:str: The path to the downloaded file."""if model_dir is None: # use the pytorch hub_dirhub_dir = get_dir()model_dir = os.path.join(hub_dir, 'checkpoints')os.makedirs(model_dir, exist_ok=True)parts = urlparse(url)filename = os.path.basename(parts.path)if file_name is not None:filename = file_namecached_file = os.path.abspath(os.path.join(model_dir, filename))if not os.path.exists(cached_file):print(f'Downloading: "{url}" to {cached_file}\n')download_url_to_file(url, cached_file, hash_prefix=None, progress=progress)return cached_file
而 PyTorch 中的 _modules/torch/hub.html#download_url_to_file 方法,实现的也非常简单,不包括任何重试、超时、握手错误等处理逻辑:
def download_url_to_file(url, dst, hash_prefix=None, progress=True):r"""Download object at the given URL to a local path.Args:url (str): URL of the object to downloaddst (str): Full path where object will be saved, e.g. ``/tmp/temporary_file``hash_prefix (str, optional): If not None, the SHA256 downloaded file should start with ``hash_prefix``.Default: Noneprogress (bool, optional): whether or not to display a progress bar to stderrDefault: TrueExample:>>> # xdoctest: +REQUIRES(env:TORCH_DOCTEST_HUB)>>> # xdoctest: +REQUIRES(POSIX)>>> torch.hub.download_url_to_file('https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pth', '/tmp/temporary_file')"""file_size = Nonereq = Request(url, headers={"User-Agent": "torch.hub"})u = urlopen(req)meta = u.info()if hasattr(meta, 'getheaders'):content_length = meta.getheaders("Content-Length")else:content_length = meta.get_all("Content-Length")if content_length is not None and len(content_length) > 0:file_size = int(content_length[0])# We deliberately save it in a temp file and move it after# download is complete. This prevents a local working checkpoint# being overridden by a broken download.dst = os.path.expanduser(dst)dst_dir = os.path.dirname(dst)f = tempfile.NamedTemporaryFile(delete=False, dir=dst_dir)try:if hash_prefix is not None:sha256 = hashlib.sha256()with tqdm(total=file_size, disable=not progress,unit='B', unit_scale=True, unit_divisor=1024) as pbar:while True:buffer = u.read(8192)if len(buffer) == 0:breakf.write(buffer)if hash_prefix is not None:sha256.update(buffer)pbar.update(len(buffer))f.close()if hash_prefix is not None:digest = sha256.hexdigest()if digest[:len(hash_prefix)] != hash_prefix:raise RuntimeError('invalid hash value (expected "{}", got "{}")'.format(hash_prefix, digest))shutil.move(f.name, dst)finally:f.close()if os.path.exists(f.name):os.remove(f.name)
所以,在实际使用的过程中,如果存在网络问题,最好预先下载好模型,放在程序读取的到的位置,然后再初始化程序。
另外,在使用 v1 版本最初发布的模型时,如果我们直接在程序中切换使用最初的发布的模型时,会收到类似下面的错误信息:
NameError: name 'fused_act_ext' is not defined
这是因为上文提到的架构不同,除了传递参数有变化之外,我们还需要指定一个环境变量:
BASICSR_JIT=True python app.py
在 Docker 中使用,可以使用下面的命令,将环境变量传递到容器内部:
docker run --gpus all --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -it -e BASICSR_JIT=True -v `pwd`/model:/app/model -v `pwd`/gfpgan:/app/gfpgan -p 7860:7860 soulteary/docker-gfpgan
想比较直接执行,这里会进行 CUDA 插件的编译,所以会需要额外的时间,完成之后,我们熟悉的界面将多两个选项: “v1” 版本的模型和 RealESR GAN 的“v2” 版本,这是项目最初发布时的组合。
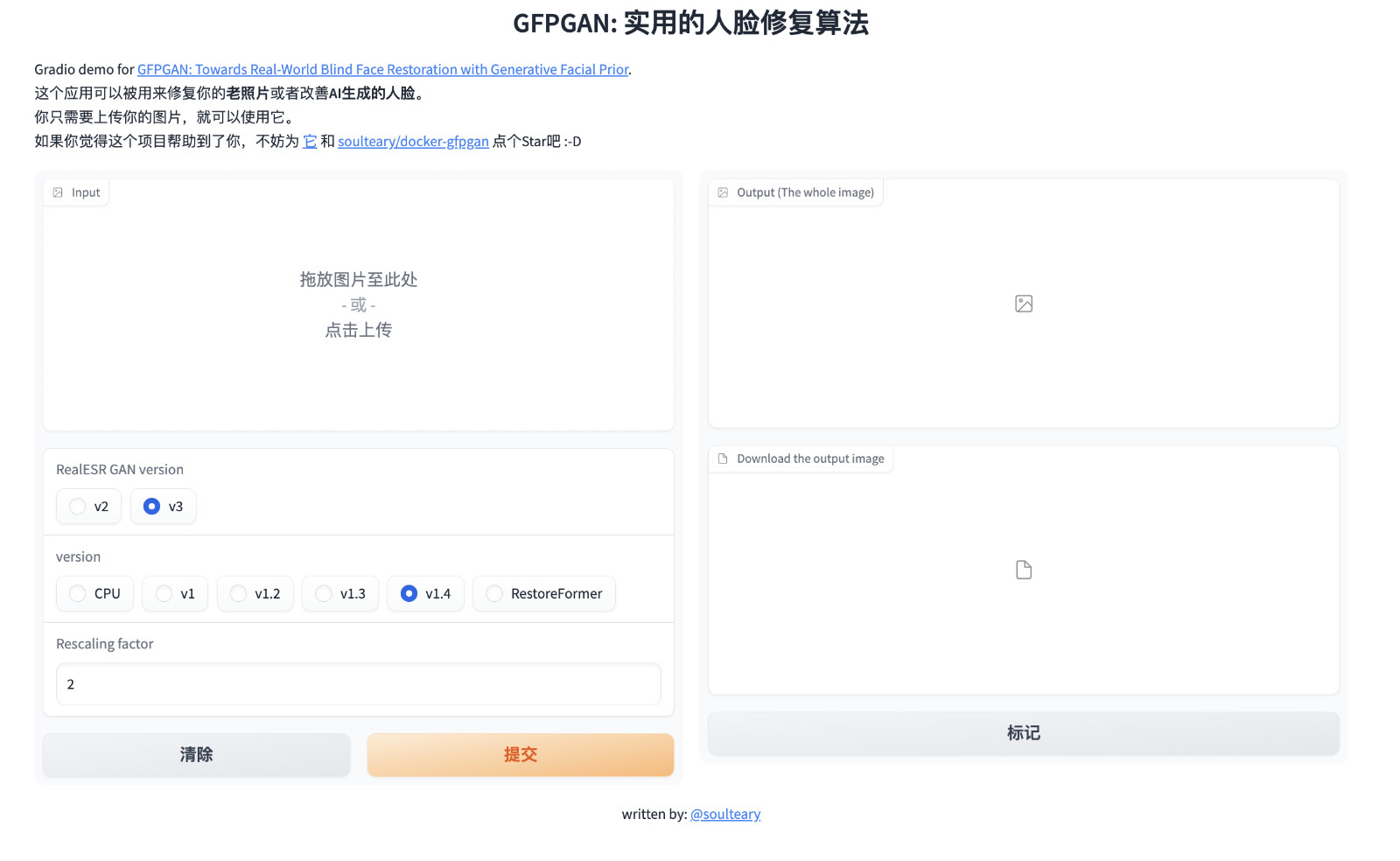
还有几个不影响实际使用的小问题。在安装准备环境过程中因为子依赖版本冲突,报错的问题,因为我们实际代码没有依赖和使用 google-auth-oauthlib 相关功能,可以暂时忽略这个问题:
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts.
tensorboard 2.9.0 requires google-auth-oauthlib<0.5,>=0.4.1, but you have google-auth-oauthlib 1.0.0 which is incompatible.
tensorboard 2.9.0 requires tensorboard-data-server<0.7.0,>=0.6.0, but you have tensorboard-data-server 0.7.1 which is incompatible.
最后
本篇文章就先写到这里吧,下一篇文章再见。
–EOF
我们有一个小小的折腾群,里面聚集了一些喜欢折腾、彼此坦诚相待的小伙伴。
我们在里面会一起聊聊软硬件、HomeLab、编程上的一些问题,也会在群里不定期的分享一些技术资料。
喜欢折腾的小伙伴,欢迎阅读下面的内容,扫码添加好友。
关于“交友”的一些建议和看法
添加好友时,请备注实名和公司或学校、注明来源和目的,珍惜彼此的时间 😄
苏洋:关于折腾群入群的那些事
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年08月04日
统计字数: 19172字
阅读时间: 39分钟阅读
本文链接: https://soulteary.com/2023/08/04/stable-diffusion-hardcore-survival-guide-gfpgan-in-webui.html
相关文章:
Stable Diffusion 硬核生存指南:WebUI 中的 GFPGAN
本篇文章聊聊 Stable Diffusion WebUI 中的核心组件,强壮的人脸图像面部画面修复模型 GFPGAN 相关的事情。 写在前面 本篇文章的主角是开源项目 TencentARC/GFPGAN,和上一篇文章《Stable Diffusion 硬核生存指南:WebUI 中的 CodeFormer》提…...
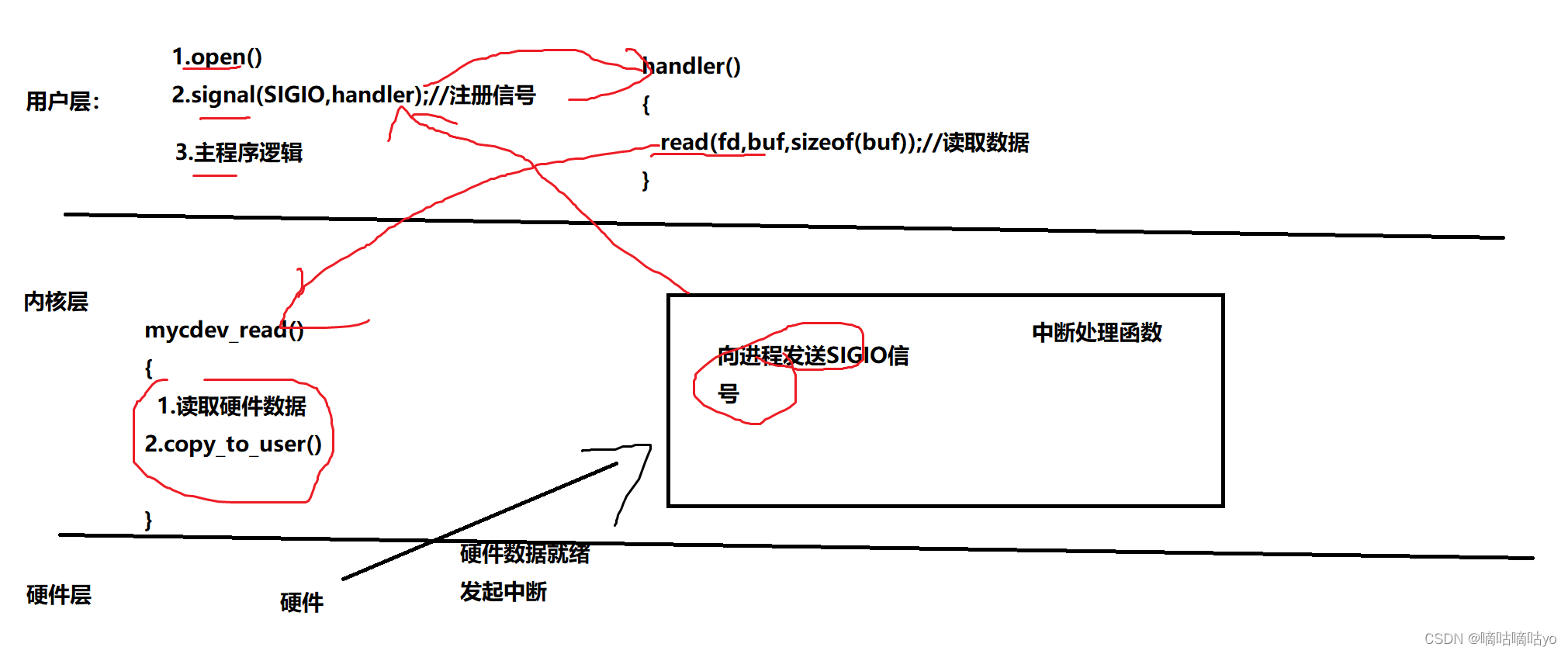
IO模型-信号驱动IO
linux内核中存在一个信号SIGIO,这个信号就是用于实现信号驱动IO的。当应用程序中想要以信号驱动IO的模型读写硬件数据时,首先注册一个SIGIO信号的信号处理函数,当硬件数据就绪,硬件会发起一个中断,在硬件的中断处理函数中向当前进…...
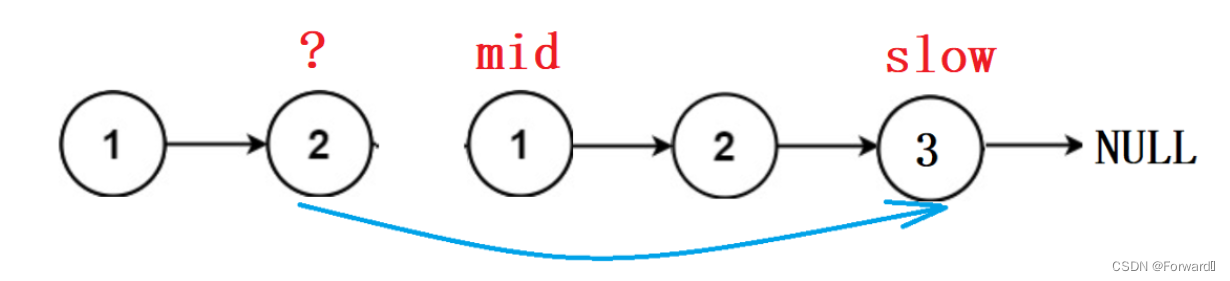
每日一题——回文链表
回文链表 题目链接 回文结构即字符串正序逆序完全一致,如“1 2 3 4 3 2 1”,那么我们就要想办法同时比较链表头和链表尾的元素,看其是否相等。 下面介绍一种最常用的方法: 思路 如果我们仔细观察回文结构,就会得到一…...

OPENCV C++(一) 二进制和灰度原理 处理每个像素点值的方法
#include <opencv2/opencv.hpp> using namespace std; using namespace cv;必须包含的头文件! 才能开始编写代码 读取相片 一般来说加个保护程序 不至于出error和卡死 Mat image imread("test.webp"); //存放自己图像的路径 if (image.empty()){p…...
Python GUI编程(Tkinter)
Python GUI编程(Tkinter) Python 提供了多个图形开发界面的库,几个常用 Python GUI 库如下: Tkinter: Tkinter 模块(Tk 接口)是 Python 的标准 Tk GUI 工具包的接口 .Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows …...

K8S简介
目录 前言K8S 简介K8S 是什么作用Kubernetes 主要功能如下:Kubernetes 集群架构与组件 核心组件Master 组件Kube-apiserverKube-controller-managerKube-scheduler配置存储中心 etcd Node 组件KubeletKube-Proxydocker 或 rocket Kubernetes 核心概念PodPod控制器La…...
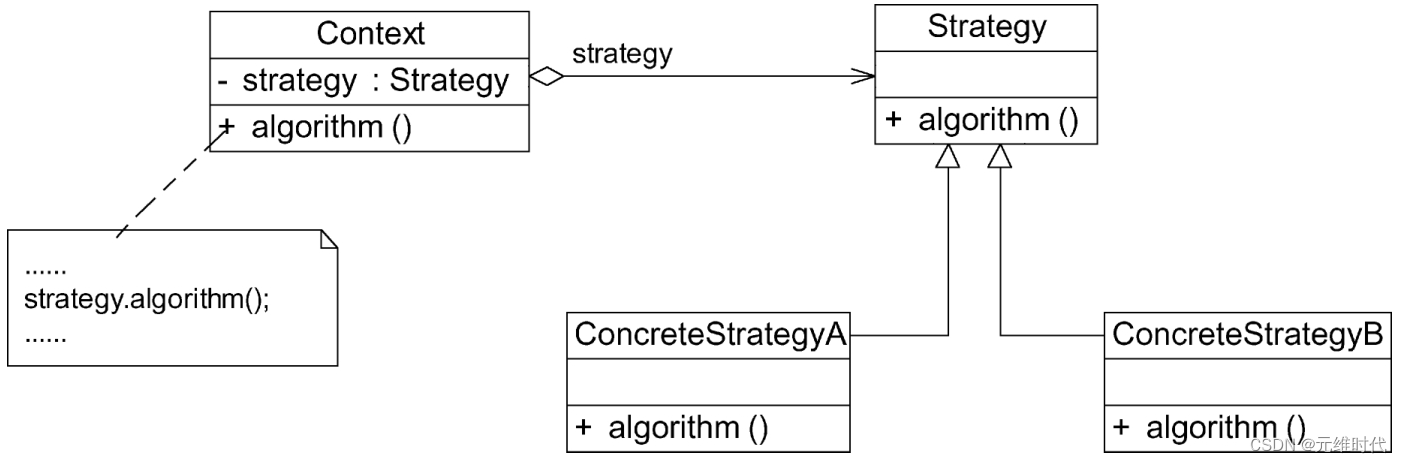
策略模式——算法的封装与切换
1、简介 1.1、概述 在软件开发中,常常会遇到这种情况,实现某一个功能有多条途径。每一条途径对应一种算法,此时可以使用一种设计模式来实现灵活地选择解决途径,也能够方便地增加新的解决途径。为了适应算法灵活性而产生的设计模…...

c++转换构造,拷贝构造,operator=
c转换构造,拷贝构造,operator 一.转换构造 定义一个类 class CTest { public:int m_a;CTest(int m_a):m_a(0){} };在主函数中定义对象 CTest tes1(1); CTest tes2 5;//我们发现这种定义对象的方式不符合常理,这里其实是发生了隐式类型转…...

支付宝蜻蜓设备abs调试
蜻蜓设备系统日志调试 1、蜻蜓设备进入开发者模式 长按关键键直到屏幕上出现设置按钮,点击设置按钮,选择关于本机,找到系统版本,连续点击8次,选择进入调试模式 2、找到小程序容器,连续点击8次࿰…...

论memset的时间代价
论memset的时间代价 众所周知,memset是一个常用的数组赋值方式,几乎每个OI player全都使用过,但是这个函数从来不要脸,也不给你脸。 大家耳顺能详的几个例子: ①memset(a,0,sizeof(a));把a全赋值成0。 ②memset(a,…...
linux下绑定进程到指定CPU的操作方法
taskset简介 # taskset Usage: taskset [options] [mask | cpu-list] [pid|cmd [args...]] Show or change the CPU affinity of a process. Options: -a, --all-tasks operate on all the tasks (threads) for a given pid -p, --pid operate on ex…...
springboot+maven插件调用mybatis generator自动生成对应的mybatis.xml文件和java类
mybatis最繁琐的事就是sql语句和实体类,sql语句写在java文件里很难看,字段多的表一开始写感觉阻力很大,没有耐心,自动生成便成了最称心的做法。自动生成xml文件,dao接口,实体类,虽一直感觉不太优…...

C# 根据前台传入实体名称,动态查询数据
前言: 项目中时不时遇到查字典表等数据,只需要返回数据,不需要写其他业务,每个字典表可能都需要写一个接口给前端调用,比较麻烦,所以采用下面这种方式,前端只需传入实体名称即可,例…...
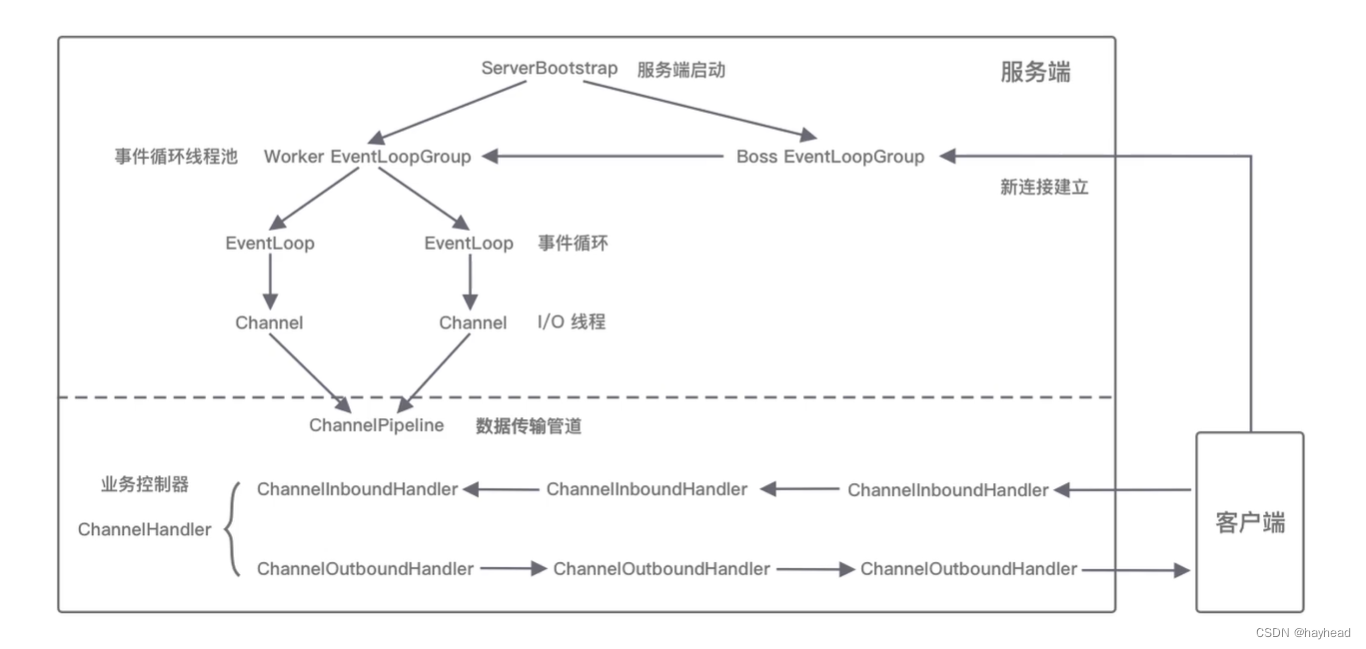
Netty入门学习
目录 为什么要学习nettynetty学习导图学习netty前需要知道的知识I/O模型主要I/O模型 netty框架的整体结构netty的逻辑架构网络通信层事件调度层服务编排层 为什么要学习netty Netty是由JBOSS提供的一个Java开源框架,现为Github上的独立项目。Netty本质是一个NIO框架…...

代客泊车对HUT功能交互规范
目录 1. 版本记录... 7 2. 文档范围和控制... 8 2.1 目的/范围... 8 2.2 文档冲突... 8 2.3 文档授权... 8 2.4 文档更改控制... 8 3. 系统组成... 9 3.1 IPAS系统(环视和超声波雷达)...…...

mysql的update_time
CREATE TABLE users (id INT AUTO_INCREMENT PRIMARY KEY,name VARCHAR(50) NOT NULL,age INT,update_time TIMESTAMP NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT 更新时间 );具体解释如下: DEFAULT CURRENT_TIMESTAMP: 这部分表示当插入…...

避免安装这5种软件,手机广告频繁弹窗且性能下降
在我们使用手机的日常生活中,选择合适的应用软件对于保持良好的使用体验至关重要。然而,有些软件可能会给我们带来不必要的麻烦和困扰。特别是那些频繁弹窗广告、导致手机性能下降的应用程序,我们应该尽量避免安装它们。 首先第一种…...

kafka-事务
1. 事务的5个API // 1初始化事务 void initTransactions();// 2开启事务 void beginTransaction() throws ProducerFencedException;// 3在事务内提交已经消费的偏移量(主要用于消费者) void sendOffsetsToTransaction(Map<TopicPartition, OffsetAn…...
【安装】阿里云轻量服务器安装Ubuntu图形化界面(端口号/灰屏问题)
阿里云官网链接 https://help.aliyun.com/zh/simple-application-server/use-cases/use-vnc-to-build-guis-on-ubuntu-18-04-and-20-04 网上搜了很多教程,但是我没在界面看到有vnc连接,后面才发现官网有教程。 其实官网很详细了,不过这里还是…...

Python 扩展 快捷贴士:os模块下的创建目录的方式
Python3 os.makedirs() 方法 概述 os.makedirs() 方法用于递归创建多层目录。 如果子目录创建失败或者已经存在,会抛出一个 OSError 的异常,Windows上Error 183 即为目录已经存在的异常错误。 如果第一个参数 path 只有一级,即只创建一层目…...
)
别再只烧SD卡了!IMX6ULL的BOOT_CFG引脚配置详解(附正点原子核心板电路图)
IMX6ULL启动配置全解析:从BOOT_CFG引脚到多介质启动实战 当你在深夜调试IMX6ULL开发板时,是否遇到过这样的困境——明明按照教程操作,系统却始终无法从EMMC启动?问题的根源往往藏在那些容易被忽略的硬件细节中。今天,我…...

Label Studio终极指南:高效构建多模态数据标注平台
Label Studio终极指南:高效构建多模态数据标注平台 【免费下载链接】label-studio Label Studio is a multi-type data labeling and annotation tool with standardized output format 项目地址: https://gitcode.com/GitHub_Trending/la/label-studio 在人…...

终极免费解锁Cursor Pro高级功能:完整解决方案深度解析
终极免费解锁Cursor Pro高级功能:完整解决方案深度解析 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your tr…...

贝壳季报图解:营收189亿 经调整净利16亿同比增15.7%
雷递网 雷建平 5月19日贝壳(纽交所代码:BEKE;香港联交所代号:2423)今日公布其截至2026年3月31日止第一季度未经审计财务业绩。财报显示,贝壳2026年第一季度贝壳实现净收入189亿元,净利润12.55亿…...

TTK插件系统扩展指南:自定义Golden生成函数和输入数据生成函数的完整教程
TTK插件系统扩展指南:自定义Golden生成函数和输入数据生成函数的完整教程 【免费下载链接】ops-test-kit TTK(Ops Test Tool Kit)是CANN算子库提供的全链路、自动化、批量化算子测试框架,帮助开发者快速完成算子批量功能验证、性能…...
)
用GNU Radio和USRP N310/X310手把手搭建一个雷达通信一体化系统(附完整GRC流程图)
从零构建基于GNU Radio与USRP的雷达通信融合系统实战指南 在软件定义无线电(SDR)技术蓬勃发展的今天,将雷达探测与无线通信功能集成到同一硬件平台已成为可能。这种一体化设计不仅能降低设备成本,还能实现频谱资源共享,…...

燃油车的“催命符”还是环保的“里程碑”?2026年Euro 7标准下的汽车变局
如果你正打算换车,或者对汽车行业的未来走向充满好奇,那么“Euro 7”(欧7排放标准)绝对是你绕不开的一个关键词。这项被业内称为“史上最严”的排放法规,将于2026年11月29日正式对新车型实施强制认证。它不仅给内燃机戴…...

Figma界面3分钟变中文:设计师必备的完整汉化终极指南
Figma界面3分钟变中文:设计师必备的完整汉化终极指南 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?作为一名中文设计师&#x…...

c++生产者消费者者模式笔记-1阻塞问题
生产者消费者模式是并发编程的核心模式之一,核心是想要提高程序的运行效率。 这里记录一下自己的思考,使用通俗易懂的语言,和以日志记录为例,解读生产者消费者模式,并实现生产者消费者模式。 将生产者消费者模式的核心…...

AArch64虚拟内存系统架构与64KB粒度地址转换详解
1. AArch64虚拟内存系统架构概述现代处理器架构通过虚拟内存机制实现物理内存与虚拟地址空间的隔离映射,AArch64作为ARMv8/ARMv9架构的64位执行状态,其虚拟内存系统架构(VMSA)采用多级页表机制实现地址转换。与传统x86架构相比&am…...