【Python】数据分析+数据挖掘——掌握Python和Pandas中的单元格替换操作
1. 前言
数据处理和清洗是数据分析和机器学习中至关重要的步骤。在数据处理过程中,我们经常需要对数据集进行清洗和转换,其中单元格替换是一个常用的技术。Python作为一种功能强大且灵活的编程语言,为数据处理提供了丰富的工具和库。Pandas库是Python中最流行的数据处理库之一,它提供了丰富的功能,包括强大的单元格替换操作。
在本博客中,我们将深入探讨Python和Pandas库中有关单元格替换的知识。我们将首先介绍Python中的基本替换方法,然后重点关注Pandas库中的df.replace()方法,以及如何使用它来进行单元格替换。我们还将学习如何使用df.replace()来实现单元格范围替换,以及如何进行哑变量替换,将分类数据转换为更易于处理的形式。
2. 单元格变量替换
当涉及到数据处理、清洗或转换时,Python原生库和Pandas库都提供了一些功能来进行单元格替换。让我们先介绍一下Python原生库中的替换方法,然后再探讨Pandas库的相关功能。
Python原生库中的单元格替换:
在Python中,主要使用内置的数据结构如列表(List)和字典(Dictionary)来处理数据。对于列表,你可以使用列表推导式或循环来实现单元格替换,而对于字典,可以通过键值对的方式进行替换。
- 例如使用列表推导式替换列表中的特定值:
In[0]:
derive_list = ['a','b','c','d','e'] # 用列表推导来替换的列表例子derive_list = [x if x != 'a' else 'A' for x in derive_list] # 使用列表推导式来替换列表中特定的值
print(derive_list)
注释:
-
derive_list: 这是一个列表变量,它包含了一些元素。假设derive_list是一个字符串列表,例如[‘a’, ‘b’, ‘c’, ‘d’, ‘e’]。
-
for x in derive_list: 这是列表推导式的循环部分。它遍历derive_list中的每个元素,并将当前元素赋值给变量x。
-
x if x != ‘a’ else ‘A’: 这是列表推导式的条件表达式。它表示如果当前元素x不等于’a’,则不做修改,否则替换为’A’。
最终结果: 列表推导式的结果是一个新的列表,其中满足条件的元素已经被替换。该结果会覆盖原始的derive_list,因此derive_list会被修改。
out[0]:
['A', 'b', 'c', 'd', 'e']
- 接下来使用循环替换列表中的特定值:
In[1]:
loop_list = ['h','e','l','l','o',',','p','y','t','h','o','n'] # 用循环来替换列表中特定的值for index,list_item in enumerate(loop_list): # 使用循环来替换列表中特定的值if list_item == 'p':loop_list[index] = 'P'for new_list_item in loop_list: # 使用循环来依次打印新列表里面的元素值print(new_list_item, end="") # end=""的作用是不换行
注释:
enumerate()函数可以用于遍历一个可迭代对象(如列表、元组、字符串等)并返回元素的索引和对应的值。
out[1]:
hello,Python
- 最后在学习一下使用字典替换列表中的特定值:
In[2]:
num_key_dict = {0:'a',1:'b',2:'c',3:'d'} # 键为number类型的dict
str_key_dict = {'0':'a','1':'b','2':'c','3':'d'} # 键为string类型的dictnum_key_dict[1] = 'B' # 替换dict中的特定值
str_key_dict['1'] = 'B' # 替换dict中的特定值print("num_key_dict is:",num_key_dict)
print("str_key_dict is:",str_key_dict)
注释:
- 若将
str_key_dict['1'] = 'B'改为str_key_dict[1] = 'B'那么str_key_dict中的’b‘值并不会被改变,而是字典中多了一个key为1,value为’B’的键值对
out[2]:
num_key_dict is: {0: 'a', 1: 'B', 2: 'c', 3: 'd'}
str_key_dict is: {'0': 'a', '1': 'B', '2': 'c', '3': 'd'}
案例数据表university_rank.csv
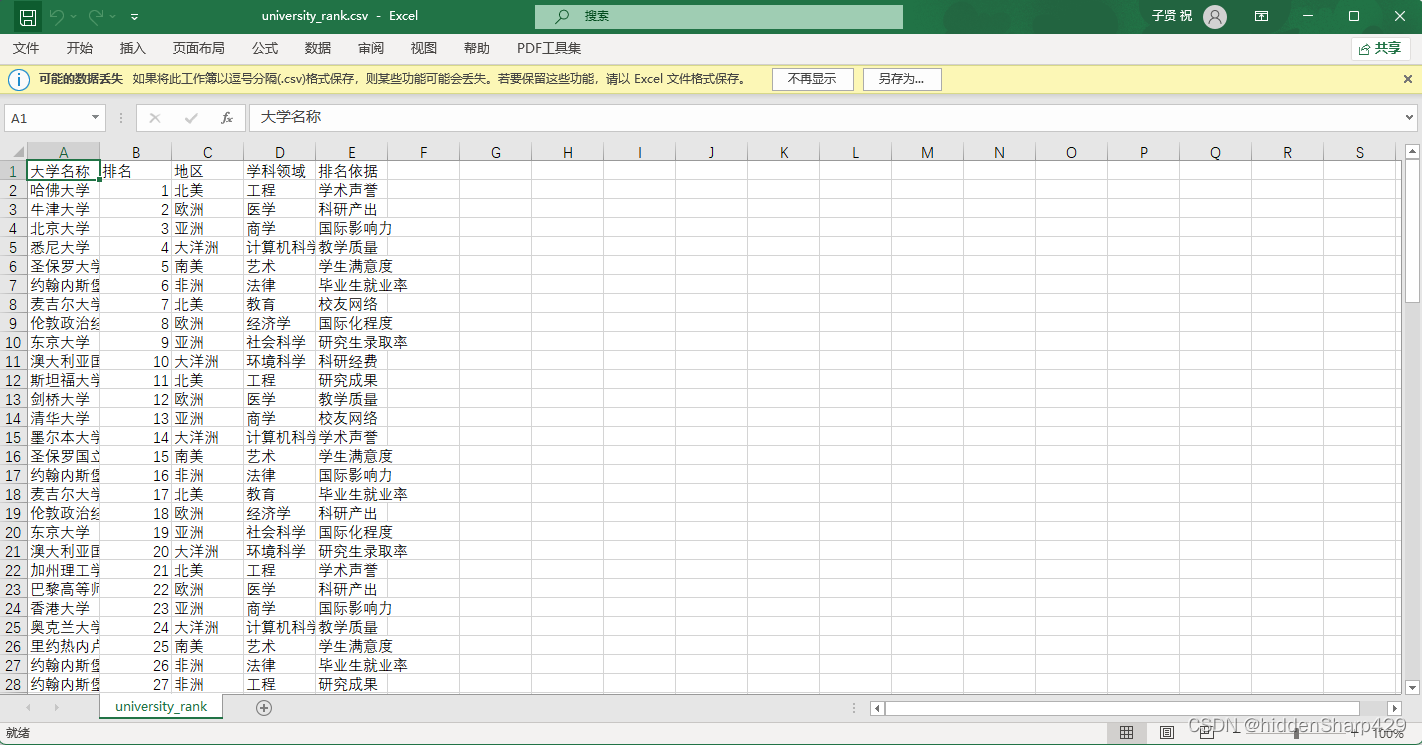
接下来我们将重点放在Pandas中的单元格替换操作,Pandas提供了多种方法来替换DataFrame或Series中的特定值。这些方法可以帮助你快速、灵活地对数据进行替换。下面将详细介绍几种常用的单元格替换方法。
常用的函数是df.inplace来进行某个单元格或者某个列的变量替换
语法:DataFrame.replace(to_replace=None, value=None, inplace=False, limit=None, regex=False, method=‘pad’)
df.replace(# 要替换的值。可以是单个值、一个列表、字典或正则表达式。to_replace# 用于替换的新值。可以是单个值或字典。value# 是否在原df上修改inplace = False# 指定每行替换的最大数量。默认为None,表示不限制。limit = None# 是否启用正则表达式替换。默认为False。regex = False # 当to_replace为字典时,指定如何进行替换。默认为'pad',表示用字典中的值向前填充method = 'pad'
)
In[3]:
import pandas as pddf = pd.read_csv("university_rank.csv") # 读取案例数据表
inplace_set = {'北美': "北美洲", '南美': '南美洲'} # 创建一个替换集合
df.地区.replace(inplace_set, inplace=True) # 将读取到的数据中所有'北美'、'南美'单元格均换成'北美洲'、'南美洲'
df # 展示新的DataFrame
**out[3]:**
大学名称 排名 地区 学科领域 排名依据
0 哈佛大学 1 北美洲 工程 学术声誉
1 牛津大学 2 欧洲 医学 科研产出
2 北京大学 3 亚洲 商学 国际影响力
3 悉尼大学 4 大洋洲 计算机科学 教学质量
4 圣保罗大学 5 南美洲 艺术 学生满意度
.. ... ... ... ... ...
95 圣保罗国立大学 96 南美洲 计算机科学 研究生录取率
96 约翰内斯堡大学 97 非洲 环境科学 学术声誉
97 麦吉尔大学 98 北美洲 艺术 学生满意度
98 伦敦政治经济学院 99 欧洲 法律 国际影响力
99 东京大学 100 亚洲 教育 毕业生就业率[100 rows x 5 columns]
2.1 范围单元格替换
假如要对某个范围的单元格进行替换就需要搭配df.query、df.loc、df.index来使用来达到目的
若我想要筛选出地区为北美洲和南美洲,同时10<排名<80的所有记录,将其排名依据均设置为空
In[4]:
df.loc[df.query("10<排名<80 and 地区 in ['北美洲','南美洲']").index, '排名依据'] = '' # 筛选出地区为北美洲和南美洲,同时10<排名<80的所有记录,将其排名依据均设置为空
df[10:79] # 查看进行范围单元格替换后的DataFrame
out[4]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 10 | 斯坦福大学 | 11 | 北美洲 | 工程 | |
| 11 | 剑桥大学 | 12 | 欧洲 | 医学 | 教学质量 |
| 12 | 清华大学 | 13 | 亚洲 | 商学 | 校友网络 |
| 13 | 墨尔本大学 | 14 | 大洋洲 | 计算机科学 | 学术声誉 |
| 14 | 圣保罗国立大学 | 15 | 南美洲 | 艺术 | |
| ... | ... | ... | ... | ... | ... |
| 74 | 墨尔本大学 | 75 | 大洋洲 | 商学 | 国际化程度 |
| 75 | 圣保罗国立大学 | 76 | 南美洲 | 计算机科学 | |
| 76 | 约翰内斯堡大学 | 77 | 非洲 | 环境科学 | 学术声誉 |
| 77 | 麦吉尔大学 | 78 | 北美洲 | 艺术 | |
| 78 | 伦敦政治经济学院 | 79 | 欧洲 | 法律 | 国际影响力 |
69 rows × 5 columns
同样的我们也可以使用replace方法,通过条件表达式选择满足条件的行,并将"排名依据"列的值置为空字符串
In[5]:
# 使用replace方法,通过条件表达式选择满足条件的行,并将"排名依据"列的值置为空字符串
condition = (df["排名"].between(11, 79)) & (df["地区"].isin(['北美洲', '南美洲']))
df['排名依据'].replace(to_replace=df.loc[condition, '排名依据'].values, value='', inplace=True)df[10:79] # 查看进行范围单元格替换后的DataFrame
.dataframe tbody tr th {vertical-align: top;
}.dataframe thead th {text-align: right;
}
out[5]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 10 | 斯坦福大学 | 11 | 北美洲 | 工程 | |
| 11 | 剑桥大学 | 12 | 欧洲 | 医学 | 教学质量 |
| 12 | 清华大学 | 13 | 亚洲 | 商学 | 校友网络 |
| 13 | 墨尔本大学 | 14 | 大洋洲 | 计算机科学 | 学术声誉 |
| 14 | 圣保罗国立大学 | 15 | 南美洲 | 艺术 | |
| ... | ... | ... | ... | ... | ... |
| 74 | 墨尔本大学 | 75 | 大洋洲 | 商学 | 国际化程度 |
| 75 | 圣保罗国立大学 | 76 | 南美洲 | 计算机科学 | |
| 76 | 约翰内斯堡大学 | 77 | 非洲 | 环境科学 | 学术声誉 |
| 77 | 麦吉尔大学 | 78 | 北美洲 | 艺术 | |
| 78 | 伦敦政治经济学院 | 79 | 欧洲 | 法律 | 国际影响力 |
69 rows × 5 columns
2.2 哑变量替换
在数据分析和统计学中,哑变量(Dummy Variable),也称为虚拟变量,是用来对分类变量进行编码的一种方法。在许多机器学习算法中,需要将分类数据转换为数值形式才能进行处理,而哑变量就是一种常用的编码方式。
哑变量编码的基本思想是将一个有n个取值的分类变量转换成n个二进制变量,每个二进制变量表示该分类是否出现。对于原始的分类变量,其中某个取值用1表示,而其他取值用0表示。这样做的目的是为了在数值形式上保持分类变量之间的独立性。
例如,假设有一个商品,它具有商品ID、价格、分类三个属性,变量“分类”,包含三个取值:“日常用品”、“蔬果"和"服装”。如下图所示
使用哑变量编码后,将生成三个二进制变量:"日常用品"变量、“蔬果"变量和"服装"变量。如果原始数据中的某一行"分类"是"日常用品”,则"日常用品"变量为1,而"蔬果"和"服装"变量为0。
下面这个表格是正常的商品表
| 商品名称 | 商品ID | 价格 | 分类 |
|---|---|---|---|
| 手帕纸 | 1001 | 1$ | 日常用品 |
| T恤 | 1002 | 10$ | 服装 |
| 火龙果 | 1003 | 5$ | 蔬果 |
下面这个改动后的商品表则是使用分类这个哑变量
| 商品名称 | 商品ID | 价格 | 分类_日常用品 | 分类_服装 | 分类_蔬果 |
|---|---|---|---|---|---|
| 手帕纸 | 1001 | 1$ | 1 | 0 | 0 |
| T恤 | 1002 | 10$ | 0 | 1 | 0 |
| 火龙果 | 1003 | 5$ | 0 | 0 | 1 |
哑变量替换(Dummy Variable Replacement)指的是将原始的分类变量使用哑变量编码替换成数值形式。这种替换方式常用于机器学习模型的训练和其他数据分析任务,因为大部分算法需要处理数值数据。
在Pandas中,使用pd.get_dummies函数可以方便地将包含分类数据的DataFrame或Series转换成哑变量形式。它会自动识别分类数据并生成相应的哑变量。其中某个分类的取值用1表示,其余分类的取值用0表示。
语法:pd.get_dummies(data, prefix=None, prefix_sep=‘_’, columns=None, drop_first=False, dtype=None)
pd.get_dummies(# 转换的变量列,若不指定则为全部列data# 哑变量名称前缀,str或列表,用于指定生成的哑变量列名的前缀。默认为None,即不添加前缀。prefix = None# 用于指定前缀与原始列名之间的分隔符prefix_sep = '_'# 设置空值的哑变量dummy_na = False# 转换的原始列名,若不指定则为全部列columns = None# 是否丢弃第一列,因为若后面的列全为0,反向说明省去的列为1,则第一列可舍去drop_frist = False# 数据类型,用于指定生成哑变量列的数据类型。默认为None,即自动推断数据类型。dtype = None
)
In[6]:
df = pd.read_csv("university_rank.csv") # 读取案例数据表
print(df) # 打印一下案例数据表
print(pd.get_dummies(data=df.学科领域)) # 只打印以学科领域为哑变量列的表
out[6]:
大学名称 排名 地区 学科领域 排名依据
0 哈佛大学 1 北美 工程 学术声誉
1 牛津大学 2 欧洲 医学 科研产出
2 北京大学 3 亚洲 商学 国际影响力
3 悉尼大学 4 大洋洲 计算机科学 教学质量
4 圣保罗大学 5 南美 艺术 学生满意度
.. ... ... ... ... ...
95 圣保罗国立大学 96 南美 计算机科学 研究生录取率
96 约翰内斯堡大学 97 非洲 环境科学 学术声誉
97 麦吉尔大学 98 北美 艺术 学生满意度
98 伦敦政治经济学院 99 欧洲 法律 国际影响力
99 东京大学 100 亚洲 教育 毕业生就业率[100 rows x 5 columns]
| 医学 | 商学 | 工程 | 教育 | 法律 | 环境科学 | 社会科学 | 经济学 | 艺术 | 计算机科学 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 95 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 96 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 97 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 98 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 99 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
100 rows × 10 columns
In[7]:
df = pd.read_csv("university_rank.csv") # 读取案例数据表
print(df) # 打印案例表
print(pd.get_dummies(df, columns=["学科领域"])) # 打印包括学科领域哑变量列的所有数据
out[7]:
大学名称 排名 地区 学科领域 排名依据
0 哈佛大学 1 北美 工程 学术声誉
1 牛津大学 2 欧洲 医学 科研产出
2 北京大学 3 亚洲 商学 国际影响力
3 悉尼大学 4 大洋洲 计算机科学 教学质量
4 圣保罗大学 5 南美 艺术 学生满意度
.. ... ... ... ... ...
95 圣保罗国立大学 96 南美 计算机科学 研究生录取率
96 约翰内斯堡大学 97 非洲 环境科学 学术声誉
97 麦吉尔大学 98 北美 艺术 学生满意度
98 伦敦政治经济学院 99 欧洲 法律 国际影响力
99 东京大学 100 亚洲 教育 毕业生就业率[100 rows x 5 columns]
| 大学名称 | 排名 | 地区 | 排名依据 | 学科领域_医学 | 学科领域_商学 | 学科领域_工程 | 学科领域_教育 | 学科领域_法律 | 学科领域_环境科学 | 学科领域_社会科学 | 学科领域_经济学 | 学科领域_艺术 | 学科领域_计算机科学 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 学术声誉 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 牛津大学 | 2 | 欧洲 | 科研产出 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 北京大学 | 3 | 亚洲 | 国际影响力 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 教学质量 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 圣保罗大学 | 5 | 南美 | 学生满意度 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 研究生录取率 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 学术声誉 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 97 | 麦吉尔大学 | 98 | 北美 | 学生满意度 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 国际影响力 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 99 | 东京大学 | 100 | 亚洲 | 毕业生就业率 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
100 rows × 14 columns
In[8]:
print(pd.get_dummies(df, columns=["学科领域"], drop_first=True)) # 去掉第一列哑变量
out[8]:
| 大学名称 | 排名 | 地区 | 排名依据 | 学科领域_商学 | 学科领域_工程 | 学科领域_教育 | 学科领域_法律 | 学科领域_环境科学 | 学科领域_社会科学 | 学科领域_经济学 | 学科领域_艺术 | 学科领域_计算机科学 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 哈佛大学 | 1 | 北美 | 学术声誉 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 牛津大学 | 2 | 欧洲 | 科研产出 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 北京大学 | 3 | 亚洲 | 国际影响力 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 悉尼大学 | 4 | 大洋洲 | 教学质量 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 4 | 圣保罗大学 | 5 | 南美 | 学生满意度 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 95 | 圣保罗国立大学 | 96 | 南美 | 研究生录取率 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
| 96 | 约翰内斯堡大学 | 97 | 非洲 | 学术声誉 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 97 | 麦吉尔大学 | 98 | 北美 | 学生满意度 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| 98 | 伦敦政治经济学院 | 99 | 欧洲 | 国际影响力 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| 99 | 东京大学 | 100 | 亚洲 | 毕业生就业率 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
100 rows × 13 columns
2.3 分段单元格替换
分段单元格替换(Binning)是一种在数据处理中常用的技术,它将连续的数值数据划分为若干个离散的区间,然后用相应的区间值来替换原始数据。这样可以将连续的数值数据转换为有序的分类数据,便于数据分析和可视化。
分段单元格替换通常用于数据的离散化,将数值数据按照一定规则划分成若干区间,然后将原始数据映射到相应的区间值。
在Pandas中,可以使用cut()函数来实现分段单元格替换。cut()函数接受一个Series对象和一个表示区间边界的列表,然后将Series中的数值映射到相应的区间。
假如现在我想要将原本1-100的排名替换成1-20,20-40,40-60,60-80,80-100五段来显示,那么我们能使用什么函数来达到这个目的呢?
语法:pandas.cut(x, bins, right=True, labels=None, retbins=False, precision=3, include_lowest=False, duplicates=‘raise’)
pd.cut(# 分段的变量列名称x# 具体的分段设定,表示区间边界的列表,可以是整数表示区间的个数,也可以是自定义的边界值列表bin# 是否包括右边界 '[)'形式right = True# 给分段设置标签lables = None# 第一条记录是否包括左侧界值,当right不为True才有效果include_lowest = False# 是否返回划分后的区间边界值,默认为False。retbins = False # 表示区间边界的精度,默认为3precision = 3# 处理重复的边界值。默认为'raise',即如果有重复的边界值会抛出异常duplicates = 'raise'
)
In[9]:
df = pd.read_csv("university_rank.csv") # 读取案例数据表# 对df的排名列进行分段处理
df['排名'] = pd.cut(x=df['排名'], bins=[1, 20, 40, 60, 80, 100],right=False, labels=["L1", "L2", "L3", "L4", "L5"])
print(df.head(40)) # 打印替换后的新DataFrame
out[9]:
| 大学名称 | 排名 | 地区 | 学科领域 | 排名依据 | |
|---|---|---|---|---|---|
| 0 | 哈佛大学 | L1 | 北美 | 工程 | 学术声誉 |
| 1 | 牛津大学 | L1 | 欧洲 | 医学 | 科研产出 |
| 2 | 北京大学 | L1 | 亚洲 | 商学 | 国际影响力 |
| 3 | 悉尼大学 | L1 | 大洋洲 | 计算机科学 | 教学质量 |
| 4 | 圣保罗大学 | L1 | 南美 | 艺术 | 学生满意度 |
| 5 | 约翰内斯堡大学 | L1 | 非洲 | 法律 | 毕业生就业率 |
| 6 | 麦吉尔大学 | L1 | 北美 | 教育 | 校友网络 |
| 7 | 伦敦政治经济学院 | L1 | 欧洲 | 经济学 | 国际化程度 |
| 8 | 东京大学 | L1 | 亚洲 | 社会科学 | 研究生录取率 |
| 9 | 澳大利亚国立大学 | L1 | 大洋洲 | 环境科学 | 科研经费 |
| 10 | 斯坦福大学 | L1 | 北美 | 工程 | 研究成果 |
| 11 | 剑桥大学 | L1 | 欧洲 | 医学 | 教学质量 |
| 12 | 清华大学 | L1 | 亚洲 | 商学 | 校友网络 |
| 13 | 墨尔本大学 | L1 | 大洋洲 | 计算机科学 | 学术声誉 |
| 14 | 圣保罗国立大学 | L1 | 南美 | 艺术 | 学生满意度 |
| 15 | 约翰内斯堡大学 | L1 | 非洲 | 法律 | 国际影响力 |
| 16 | 麦吉尔大学 | L1 | 北美 | 教育 | 毕业生就业率 |
| 17 | 伦敦政治经济学院 | L1 | 欧洲 | 经济学 | 科研产出 |
| 18 | 东京大学 | L1 | 亚洲 | 社会科学 | 国际化程度 |
| 19 | 澳大利亚国立大学 | L2 | 大洋洲 | 环境科学 | 研究生录取率 |
| 20 | 加州理工学院 | L2 | 北美 | 工程 | 学术声誉 |
| 21 | 巴黎高等师范学院 | L2 | 欧洲 | 医学 | 科研产出 |
| 22 | 香港大学 | L2 | 亚洲 | 商学 | 国际影响力 |
| 23 | 奥克兰大学 | L2 | 大洋洲 | 计算机科学 | 教学质量 |
| 24 | 里约热内卢大学 | L2 | 南美 | 艺术 | 学生满意度 |
| 25 | 约翰内斯堡大学 | L2 | 非洲 | 法律 | 毕业生就业率 |
| 26 | 约翰内斯堡大学 | L2 | 非洲 | 工程 | 研究成果 |
| 27 | 麦吉尔大学 | L2 | 北美 | 医学 | 教学质量 |
| 28 | 伦敦政治经济学院 | L2 | 欧洲 | 社会科学 | 国际化程度 |
| 29 | 东京大学 | L2 | 亚洲 | 艺术 | 学生满意度 |
| 30 | 澳大利亚国立大学 | L2 | 大洋洲 | 法律 | 毕业生就业率 |
| 31 | 斯坦福大学 | L2 | 北美 | 经济学 | 校友网络 |
| 32 | 剑桥大学 | L2 | 欧洲 | 工程 | 科研产出 |
| 33 | 清华大学 | L2 | 亚洲 | 医学 | 学术声誉 |
| 34 | 墨尔本大学 | L2 | 大洋洲 | 商学 | 教学质量 |
| 35 | 圣保罗国立大学 | L2 | 南美 | 计算机科学 | 研究生录取率 |
| 36 | 约翰内斯堡大学 | L2 | 非洲 | 环境科学 | 学术声誉 |
| 37 | 麦吉尔大学 | L2 | 北美 | 艺术 | 学生满意度 |
| 38 | 伦敦政治经济学院 | L2 | 欧洲 | 法律 | 国际影响力 |
| 39 | 东京大学 | L3 | 亚洲 | 教育 | 毕业生就业率 |
3. 结束语
如果有疑问欢迎大家留言讨论,你如果觉得这篇文章对你有帮助可以给我一个免费的赞吗?我们之间的交流是我最大的动力!
相关文章:
【Python】数据分析+数据挖掘——掌握Python和Pandas中的单元格替换操作
1. 前言 数据处理和清洗是数据分析和机器学习中至关重要的步骤。在数据处理过程中,我们经常需要对数据集进行清洗和转换,其中单元格替换是一个常用的技术。Python作为一种功能强大且灵活的编程语言,为数据处理提供了丰富的工具和库。Pandas库…...

Godot 4 源码分析 - 增加格式化字符串功能
Godot 4的主要字符串类型为String,已经设计得比较完善了,但有一个问题,格式化这块没怎么考虑。 String中有一个format函数,但这个函数只有两个参数,这咋用? String String::format(const Variant &va…...
C#中XML文档与Treeview控件操作的数据同步
在前文《C#使用XML和Treeview结合实现复杂数据采集功能》中,使用Treeview展示了XML的数据,问题是如果在Treeview上进行了操作,怎样同步更改XML数据的内容呢? 这个问题看似简单,实现起来有一点小麻烦。 要实现的操作功能…...
【Java Web基础】mvn命令、Maven的安装与配置
本文极大程度上来自Maven安装(超详解),但是担心安的过程中遇到什么不一样的问题,顺便加深印象,所以还是打算自己弄一篇。 目录 第一步:Download Maven第二步:解压与安装2.1 解压2.2 安装 第一步:Download …...
加强Web应用程序安全:防止SQL注入
数据库在Web应用程序中存储和组织数据时起着至关重要的作用,它是存储用户信息、内容和其他应用程序数据的中央存储库。而数据库实现了高效的数据检索、操作和管理,使Web应用程序能够向用户提供动态和个性化的内容。然而,数据库和网络应用程序…...

【云原生】k8s中Contrainer 生命周期回调/策略/指针学习
个人主页:征服bug-CSDN博客 kubernetes专栏:kubernetes_征服bug的博客-CSDN博客 目录 1 容器生命周期 2 容器生命周期回调/事件/钩子 3 容器重启策略 4 自定义容器启动命令 5 容器探针 1 容器生命周期 Kubernetes 会跟踪 Pod 中每个容器的状态&am…...
electron+vue3全家桶+vite项目搭建【25】使用electron-updater自动更新应用
文章目录 引入实现效果实现步骤引入依赖配置electron-buidler文件封装版本升级工具类主进程调用版本更新校验渲染进程封装方法调用 测试版本更新 引入 demo项目地址 electron-updater官网 我们不可能每次发布新的版本都让用户去手动下载安装最新的包,而是应用可以…...
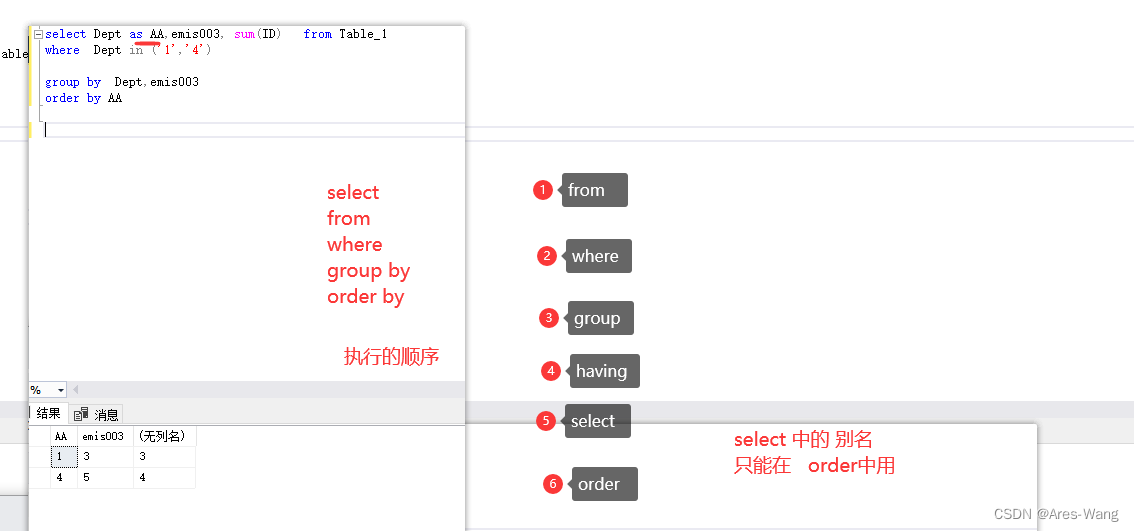
SQL 表别名 和 列别名
列表名 列表名之后 order by 可以用别名 也可以用原名, where 中不能用别名的 SQL语句执行顺序: from–>where–>group by -->having — >select --> order 第一步:from语句,选择要操作的表。 第二步࿱…...

面试之快速学习c++11-函数模版的默认模版参数,可变模版,tuple
//学习地址: http://c.biancheng.net/view/3730.html 函数模版的默认模版参数 在 C98/03 标准中,类模板可以有默认的模板参数,如下: template <typename T, typename U int, U N 0> struct TestTemplateStruct {};但是…...

Visual Studio Code 常见的配置、常用好用插件以及【vsCode 开发相应项目推荐安装的插件】
一、VsCode 常见的配置 1、取消更新 把插件的更新也一起取消了 2、设置编码为utf-8:默认就是了,不用设置了 3、设置常用的开发字体:Consolas, 默认就是了,不用设置了 字体对开发也很重要,不同字体,字母形…...

源码编译安装gcc
摘要: 在编译开源的FunASR项目的C代码时,可能要求的gcc版本不符合,需要升级gcc版本,但是从网上搜索升级gcc方式,大部分都是通过简单的yum命令方式升级,我也尝试了这个方式,这种方式并不能升级到…...

pc文件上传
1.代码: <template><div><el-upload:multiple"true":auto-upload"true":headers"headers":action"uploadFileUrl":before-upload"handleBeforeUpload":on-error"handleUploadError":o…...
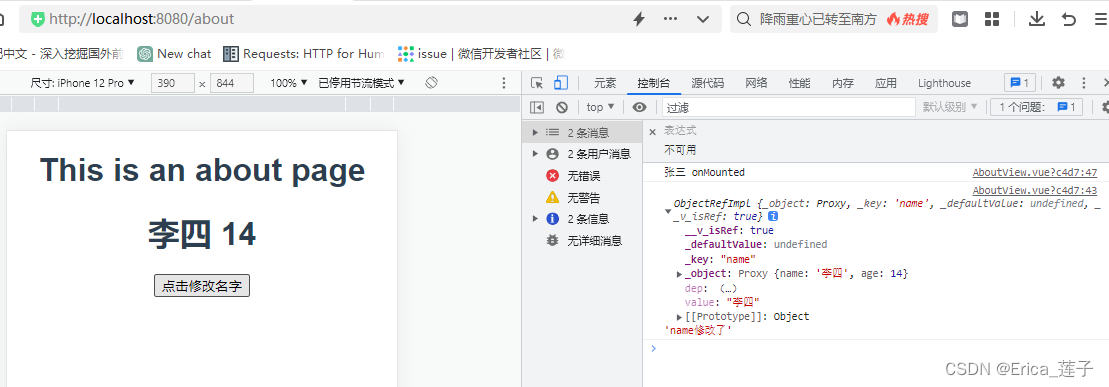
Vue3_对响应式对象解构赋值之后失去响应性
官网toRefs() :响应式 API:工具函数 | Vue.js toRefs 在调用时只会为源对象上可以枚举的属性创建 ref。如果要为可能还不存在的属性创建 ref,请改用 toRef。 setup(){const state reactive({name:"张三"age:14})const stateAsToRefs toRef…...
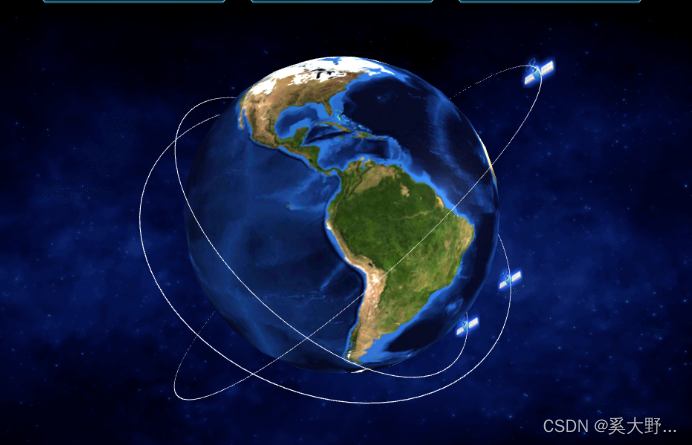
3d 地球与卫星绕地飞行
1 创建场景 2 创建相机 3 创建地球模型 4 创建卫星中心 5 创建卫星圆环及卫星 6 创建控制器 7 创建渲染器 <template><div class"home3dMap" id"home3dMap"></div> </template><script> import * as THREE from three impo…...
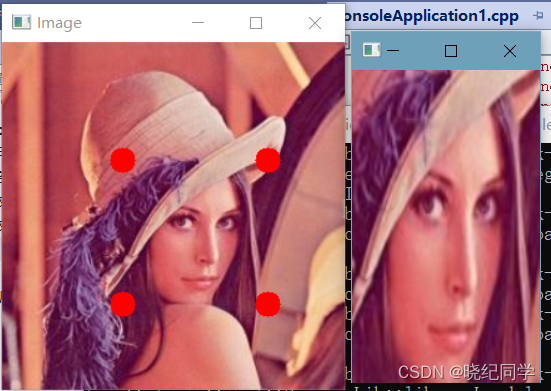
Opencv-C++笔记 (16) : 几何变换 (图像的翻转(镜像),平移,旋转,仿射,透视变换)
文章目录 一、图像平移二、图像旋转2.1 求旋转矩阵2.2 求旋转后图像的尺寸2.3手工实现图像旋转2.4 opencv函数实现图像旋转 三、图像翻转3.1左右翻转3.2、上下翻转3.3 上下颠倒,左右相反 4、错切变换4.1 实现错切变换 5、仿射变换5.1 求解仿射变换5.2 OpenCV实现仿射…...
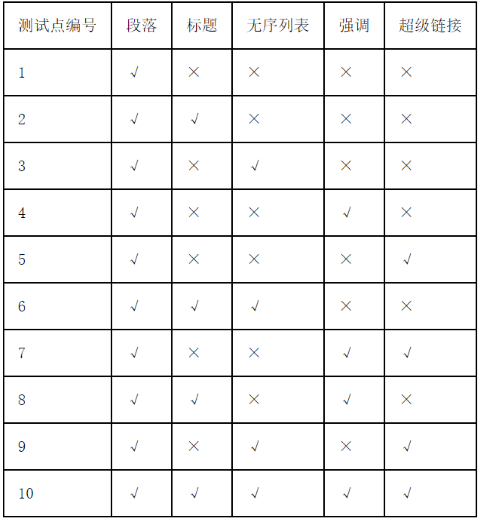
第十次CCF计算机软件能力认证
第一题:分蛋糕 小明今天生日,他有 n 块蛋糕要分给朋友们吃,这 n 块蛋糕(编号为 1 到 n)的重量分别为 a1,a2,…,an。 小明想分给每个朋友至少重量为 k 的蛋糕。 小明的朋友们已经排好队准备领蛋糕,对于每个朋…...
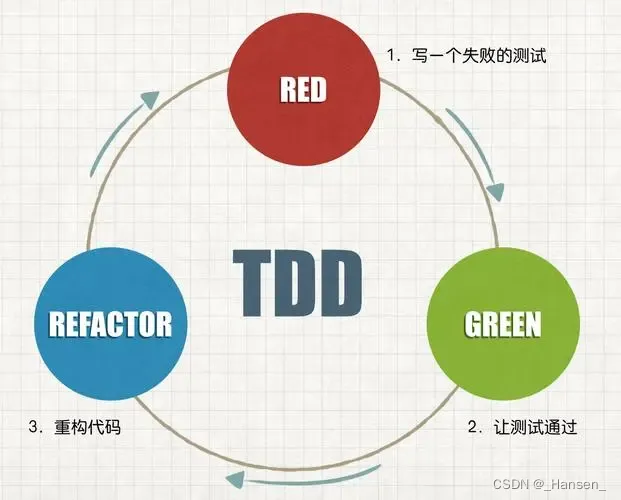
【敏捷开发】测试驱动开发(TDD)
测试驱动开发(Test-Driven Development,简称TDD)是敏捷开发模式中的一项核心实践和技术,也是一种设计方法论。TDD有别于以往的“先编码,后测试”的开发模式,要求在设计与编码之前,先编写测试脚本…...
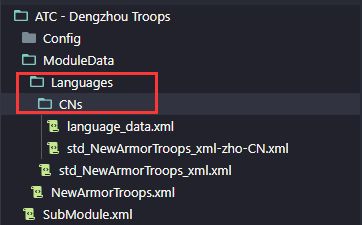
骑砍二 ATC MOD 使用教程与应用案例解析
骑砍二 ATC MOD 使用教程与应用案例解析 作者:blibli-财不外漏 / NEXUSMODS-PuepleKarmen 案例MOD依赖:ATC - Adonnay’s Troop Changer & AEW - Adonnay’s Exotic Weaponry & New Armor 文本编辑工具:VS Code(推荐使用&…...

python和c语言哪个好上手,c语言和python语言哪个难
大家好,本文将围绕python和c语言哪个更值得学展开说明,python语言和c语言哪个简单是一个很多人都想弄明白的事情,想搞清楚c语言和python语言哪个难需要先了解以下几个事情。 前言 新手最容易拿来讨论的三个语言,具体哪个好&#x…...
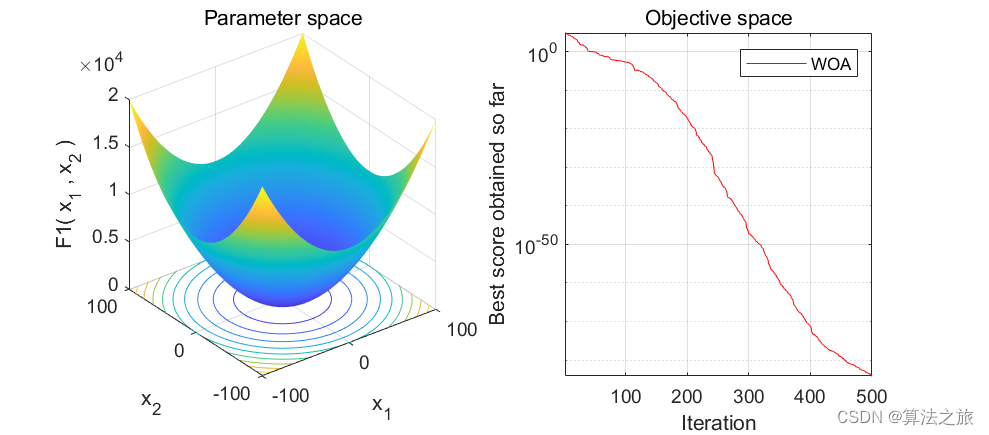
智能优化算法 | Matlab实现鲸鱼优化算法(Whale Optimization Algorithm)(内含完整源码)
文章目录 效果一览文章概述研究内容源码设计参考资料效果一览 文章概述 智能优化算法 | Matlab实现鲸鱼优化算法(Whale Optimization Algorithm)(内含完整源码) 研究内容 步骤 1:设置鲸鱼数量 N 和算法的最大迭代次数 tmax,初始化位置信息; 步骤 2:计算每条鲸鱼的适应度,…...
的优缺点与选型指南)
别再只认Revit了!盘点7种主流BIM数据格式(RVT/IFC/FBX...)的优缺点与选型指南
建筑数字化进阶指南:7大BIM数据格式深度解析与实战选型策略 在建筑信息模型(BIM)与地理信息系统(GIS)加速融合的今天,数据格式的选择直接影响着项目协同效率与成果交付质量。当设计院的Revit模型需要与施工…...

RDMA网络调试实战:当你的应用卡顿时,如何定位是哪种Error导致了重传?
RDMA网络性能调优实战:从重传Error定位到精准修复 RDMA(Remote Direct Memory Access)技术凭借其超低延迟和高吞吐量的特性,已经成为高性能计算、分布式存储和金融交易系统的核心网络架构。但在实际生产环境中,即使是经…...

【NotebookLM知识图谱构建权威白皮书】:基于127个企业POC验证的4层语义对齐框架
更多请点击: https://intelliparadigm.com 第一章:NotebookLM知识图谱构建概览 NotebookLM 是 Google 推出的面向研究者与开发者、基于用户自有文档构建可推理知识体的 AI 工具。其核心能力并非依赖通用语料,而是围绕上传文档(PD…...

Linux编译OpenSSL 3.0.1时,那个烦人的‘Can‘t locate IPC/Cmd.pm’错误,我是这样解决的
解决Linux编译OpenSSL 3.0.1时的Perl模块依赖问题 在Linux环境下从源码编译安装OpenSSL时,开发者常会遇到各种依赖问题,其中Cant locate IPC/Cmd.pm错误尤为常见。这个错误看似简单,却可能让不熟悉Perl模块管理机制的用户陷入困境。本文将深入…...

终极Windows APK安装器:3分钟学会在电脑上安装Android应用
终极Windows APK安装器:3分钟学会在电脑上安装Android应用 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否想在Windows电脑上直接运行Android应用&am…...

Bubble Navigation实战:构建现代化电商App导航系统的终极指南
Bubble Navigation实战:构建现代化电商App导航系统的终极指南 【免费下载链接】bubble-navigation 🎉 [Android Library] A light-weight library to easily make beautiful Navigation Bar with ton of 🎨 customization option. 项目地址…...

[具身智能-791]:NAV2 全局规划层 A*算法的本质是距离最短,而不是时间最短算法
核心定论A 算法本质:优先求解几何物理距离最短路径,天生不是「通行耗时最短」算法*一、直白区分A 追求目标*以栅格空间长度为核心权重,算出纯路程最短的路线,只看走了多少米,不看好不好走、堵不堵、快慢如何。时间最短…...

从游戏显卡到专业GIS:如何为你的SuperMap三维场景挑选并调校一张合适的显卡
从游戏显卡到专业GIS:如何为你的SuperMap三维场景挑选并调校一张合适的显卡 在数字孪生和智慧城市建设的浪潮中,三维GIS平台正成为空间数据分析的核心工具。SuperMap作为国产GIS软件的领军者,其三维模块对硬件性能的需求常常让技术决策者陷入…...

SKNet核心机制解析与PyTorch实战:从Split-Fuse-Select到完整网络构建
1. SKNet核心机制解析:从Split-Fuse-Select到多尺度特征融合 SKNet(Selective Kernel Networks)是CVPR 2019提出的创新性网络结构,它在传统卷积神经网络的基础上引入了动态选择机制。这个机制的核心在于让网络能够自适应地选择不同…...

终极Gerber文件查看器Gerbv:免费开源PCB设计验证的5大优势
终极Gerber文件查看器Gerbv:免费开源PCB设计验证的5大优势 【免费下载链接】gerbv Maintained fork of gerbv, carrying mostly bugfixes 项目地址: https://gitcode.com/gh_mirrors/ge/gerbv 还在为PCB设计文件的查看和验证而烦恼吗?Gerbv这款强…...