大数据面试题:HBase的读写缓存
面试题来源:
《大数据面试题 V4.0》
大数据面试题V3.0,523道题,679页,46w字
参考答案:
HBase上RegionServer的cache主要分为两个部分:MemStore & BlockCache。
MemStore是写缓存,BlockCache是读缓存。
当数据写入HBase时,会先写入memstore,RegionServer会给每个region提供一个memstore,memstore中的数据达到系统设置的阈值后,会触发flush将memstore中的数据刷写到磁盘。
客户的读请求会先到memstore中查数据,若查不到就到blockcache中查,再查不到就会从磁盘上读,并把读入的数据同时放入blockcahce。由于BlockCache采用的是LRU策略,因此BlockCache达到上限heapsize*hfile.block.cache .size * 0.85后,会启动淘汰机制,淘汰掉最老的一批数据。
BlockCache
为了高效获取数据,HBase设置了BlockCache机制,内存中缓存block,Block大体来分为两类,一类是JVM的heap内存,一类是heap off内存;第一类的cache策略叫做LRUCache,第二类Cache策略有SlabCache以及BucketCache两类。BlockCache是Region Server级别的,一个Region Server只有一个Block Cache,在Region Server启动的时候完成Block Cache的初始化工作。到目前为止,HBase先后实现了3种Block Cache方案,LRUBlockCache是最初的实现方案,也是默认的实现方案;HBase 0.92版本实现了第二种方案SlabCache;HBase 0.96之后官方提供了另一种可选方案BucketCache。
1、LRUBlockCache
LRUBlockCache是目前hbase默认的BlockCache机制,实现机制也比较简单,是使用一个ConcurrentHashMap管理BlockKey到Block的映射关系,缓存Block只需要将BlockKey和对应的Block放到该HashMap中,查询缓存就根据BlockKey从HashMap中获取即可。同时该方案采用严格的LRU淘汰算法,当BlockCache总量达到一定阈值之后就会启动淘汰机制,最近最少使用的Block会被置换出来。
LRUBlockCache将缓存分为三块:single-access区、mutil-access区、in-memory区,分别占到整个BlockCache大小的25%、50%、25%。Block Cache的实现机制核心思想是将Cache分级,这样的好处是避免Cache之间相互影响,尤其是对HBase来说像Meta表这样的Cache应该保证高优先级。
-
single-access 优先级:当一个数据块第一次从HDFS读取时,它会具有这种优先级,并且在缓存空间需要被回收(置换)时,它属于优先被考虑范围内。它的优点在于:一般被扫描(scanned)读取的数据块,相较于之后会被用到的数据块,更应该被优先清除。
-
mutil-access优先级:如果一个数据块,属于Single Access优先级,但是之后被再次访问,则它会升级为Multi Access优先级。在缓存里的内容需要被清除(置换)时,这部分内容属于次要被考虑的范围。
-
in-memory-access优先级:表示数据可以常驻内存,一般用来存放访问频繁、数据量小的数据,比如元数据,用户也可以在建表的时候通过设置列族属性IN-MEMORY= true将此列族放入in-memory区。
加入Block Cache
-
这里假设不会对同一个已经被缓存的BlockCacheKey重复放入cache操作。
-
根据inMemory标志创建不同类别的CachedBlock对象:若inMemory为true则创建BlockPriority.MEMORY类型,否则创建BlockPriority.SINGLE;注意,这里只有这两种类型的Cache,因为BlockPriority.MULTI在Cache Block被重复访问时才进行创建。
-
将BlockCacheKey和创建的CachedBlock对象加入到全局的ConcurrentHashMap map中,同时做一些更新计数操作。
-
最后判断如果加入后的Block Size大于设定的临界值且当前没有淘汰线程运行,则调用runEviction()方法启动LRU淘汰过程。其中,EvictionThread线程即是LRU淘汰的具体实现线程。
淘汰Block Cache
EvictionThread线程主要用于与主线程的同步,从而完成Block Cache的LRU淘汰过程。EvictionThread线程启动后,调用wait被阻塞住,直到EvictionThread线程的evict方法被主线程调用时执行notify,开始执行LruBlockCache的evict方法进行真正的淘汰过程:
-
首先获取锁,保证同一时刻只有一个淘汰线程运行;
-
计算得到当前Block Cache总大小currentSize及需要被淘汰释放掉的大小bytesToFree,如果bytesToFree小于等于0则不进行后续操作;
-
初始化创建三个BlockBucket队列,分别用于存放Single、Multi和InMemory类Block Cache,其中每个BlockBucket维护了一个CachedBlockQueue,按LRU淘汰算法维护该BlockBucket中的所有CachedBlock对象;
-
遍历记录所有Block Cache的全局ConcurrentHashMap,加入到相应的BlockBucket队列中;
-
将以上三个BlockBucket队列加入到一个优先级队列中,按照各个BlockBucket超出bucketSize的大小顺序排序(见BlockBucket的compareTo方法);
-
遍历优先级队列,对于每个BlockBucket,通过Math.min(overflow, (bytesToFree - bytesFreed) / remainingBuckets)计算出需要释放的空间大小,这样做可以保证尽可能平均地从三个BlockBucket中释放指定的空间;具体实现过程详见BlockBucket的free方法,从其CachedBlockQueue中取出即将被淘汰掉的CachedBlock对象;
-
进一步调用了LruBlockCache的evictBlock方法,从全局ConcurrentHashMap中移除该CachedBlock对象,同时更新相关计数;
-
释放锁,完成善后工作。
弊端:随着数据从single-access区晋升到multi-access区或者长时间停留在single-access区,对应的内存对象会从young区晋升到old区,晋升到old区的Block被淘汰后变为内存垃圾,最终由CMS回收。使用LRUBlockCache缓存机制会因为CMS GC策略导致内存碎片过多,从而可能引发Full GC,触发stop-the-world。
2、SlabCache
内部结构是划分为两块,80%和20%;缓存的数据如小于等于blocksize,则放在在前面的区域(80%区域);如果block大于1x但是小于2x将会放置到后面区域(20%区域);如果大于2x则不进行缓存。和LRUBlockCache相同,SlabCache也使用LRU算法对过期Block进行淘汰。和LRUBlockCache不同的是,SlabCache淘汰Block的时候只需要将对应的bufferbyte标记为空闲,后续cache对其上的内存直接进行覆盖即可。
线上集群环境中,不同表不同列族设置的BlockSize都可能不同,很显然,默认只能存储两种固定大小Block的SlabCache方案不能满足部分用户场景。因此HBase实际实现中将SlabCache和LRUBlockCache搭配使用,称为DoubleBlockCache。一次随机读中,一个Block块从HDFS中加载出来之后会在两个Cache中分别存储一份;缓存读时首先在LRUBlockCache中查找,如果Cache Miss再在SlabCache中查找,此时如果命中再将该Block放入LRUBlockCache中。
弊端:SlabCache设计中固定大小内存设置会导致实际内存使用率比较低,而且使用LRUBlockCache缓存Block依然会因为JVM GC产生大量内存碎片。因此在HBase 0.98版本之后,该方案已经被不建议使用。
3、BucketCache
BucketCache通过配置可以工作在三种模式下:heap,offheap和file。无论工作在那种模式下,BucketCache都会申请许多带有固定大小标签的Bucket,和SlabCache一样,一种Bucket存储一种指定BlockSize的数据块,但和SlabCache不同的是,BucketCache会在初始化的时候申请14个不同大小的Bucket,而且即使在某一种Bucket空间不足的情况下,系统也会从其他Bucket空间借用内存使用,不会出现内存使用率低的情况。heap模式表示这些Bucket是从JVM Heap中申请,offheap模式使用DirectByteBuffer技术实现堆外内存存储管理,而file模式使用类似SSD的高速缓存文件存储数据块。
弊端:HBase将BucketCache和LRUBlockCache搭配使用,称为CombinedBlockCache。和DoubleBlockCache不同,系统在LRUBlockCache中主要存储Index Block和Bloom Block,而将Data Block存储在BucketCache中。因此一次随机读需要首先在LRUBlockCache中查到对应的Index Block,然后再到BucketCache查找对应数据块。BucketCache通过更加合理的设计修正了SlabCache的弊端,极大降低了JVM GC对业务请求的实际影响,但也存在一些问题,比如使用堆外内存会存在拷贝内存的问题,一定程度上会影响读写性能。
相关文章:

大数据面试题:HBase的读写缓存
面试题来源: 《大数据面试题 V4.0》 大数据面试题V3.0,523道题,679页,46w字 参考答案: HBase上RegionServer的cache主要分为两个部分:MemStore & BlockCache。 MemStore是写缓存,Block…...
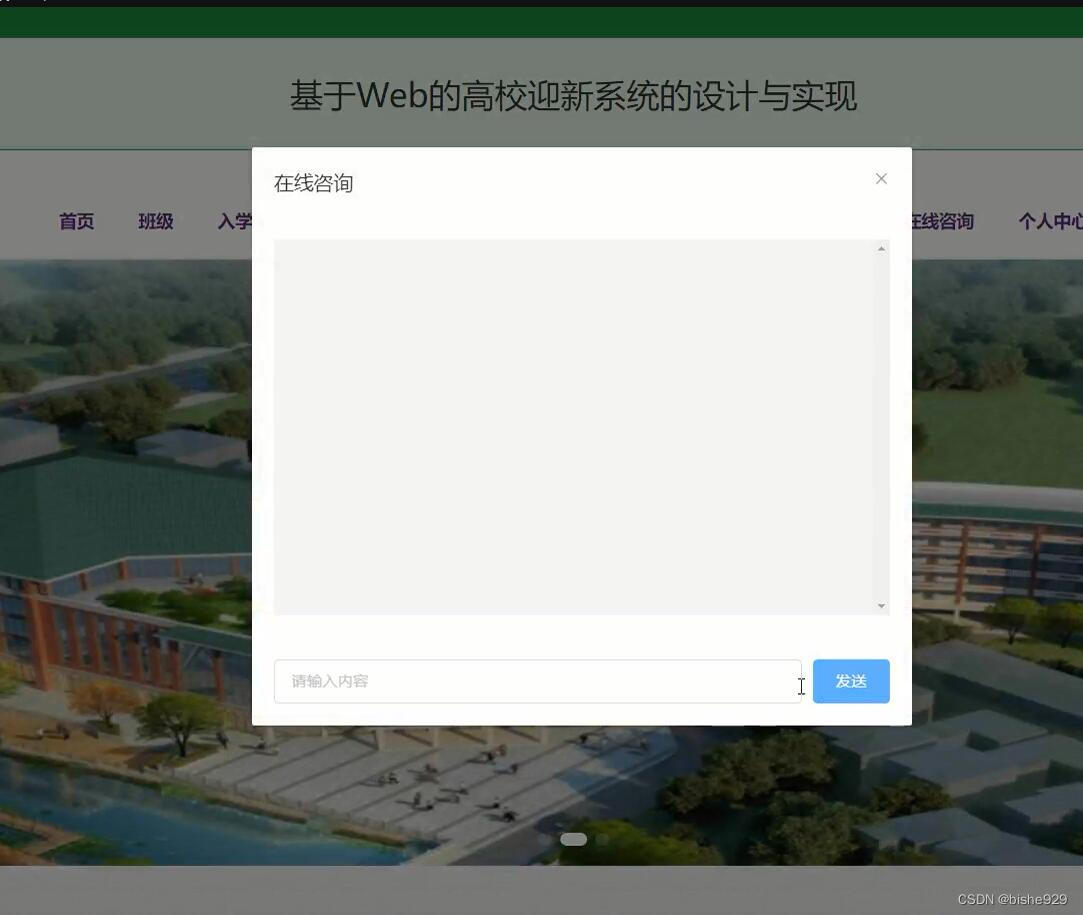
springboot基于vue的高校迎新系统的设计与实现8jf9e
随着时代的发展,人们的生活方式得到巨大的改变,从而慢慢地产生了大量高校迎新信息,高校迎新信息需要一个现代化的管理系统,进行高校迎新信息的管理。 高校迎新系统的开发就是为了解决高校迎新管理的问题,系统开发是基于…...
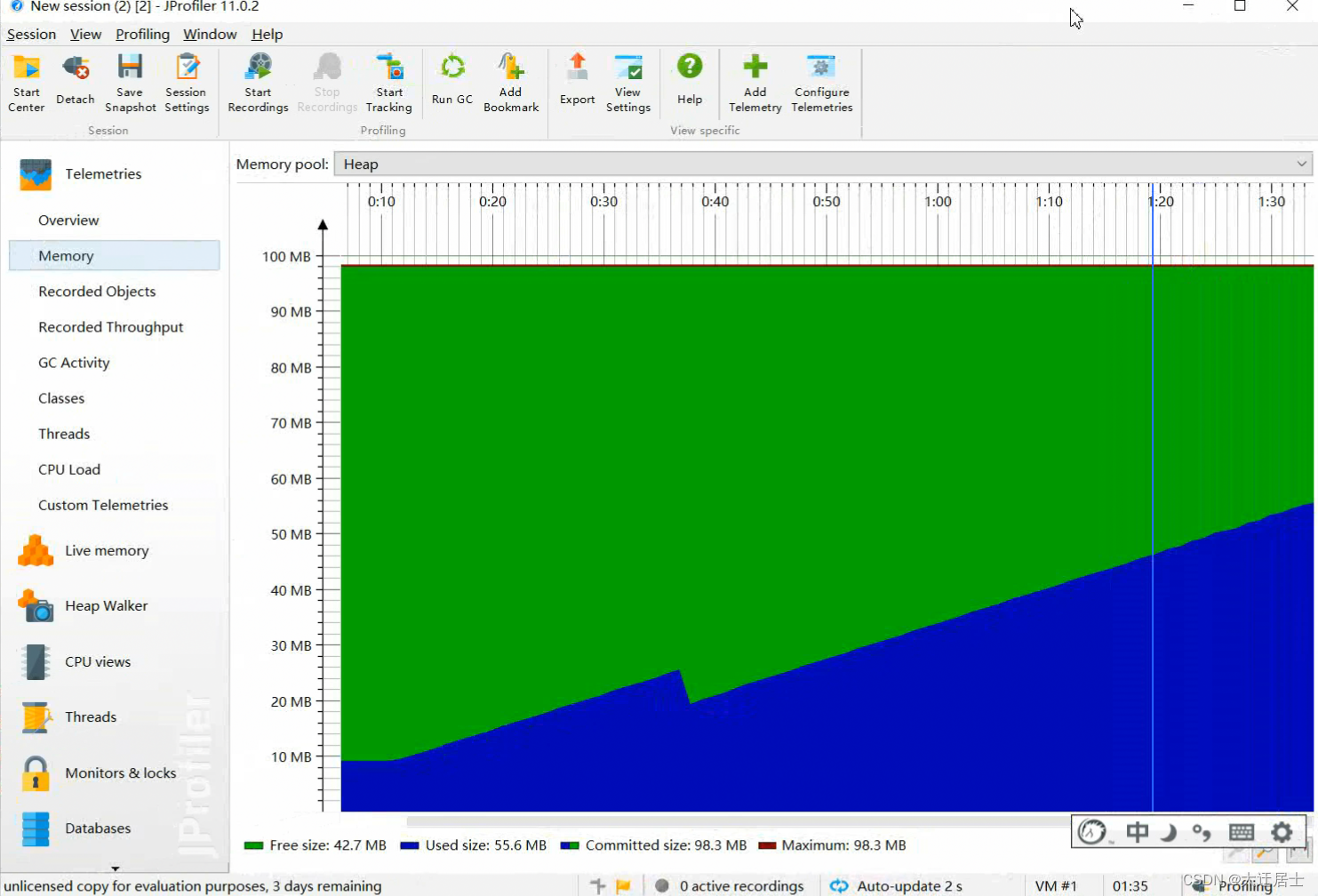
JVM入门到精通
一、JVM概念 1.1、什么是JVM Java Virtual Machine:Java虚拟机,用来保证Java语言跨平台 Java虚拟机可以看做是一台抽象的计算机,如同真实的计算机那样,它有自己的指令集以及各种运行时内存区域 Java虚拟机与Java语言并没有必然…...

Hive执行引擎的区别
执行引擎 Tez、Spark 和 MapReduce 都是用于在大数据处理中执行任务的框架或引擎,它们在性能、优化、适用场景等方面有一些区别。 MapReduce: MapReduce 是 Hadoop 最早引入的批处理计算模型,它将任务分成 Map 和 Reduce 两个阶段,…...
)
分布式 - 服务器Nginx:常见问题总结(二)
文章目录 01. Nginx 虚拟主机怎么配置?02. Nginx location 指令的作用?03. Nginx location 指令如何与其他指令一起使用?04. Nginx root 命令的作用?05. Nginx if 模块的作用?06. Nginx include 指令的作用?07. Nginx…...
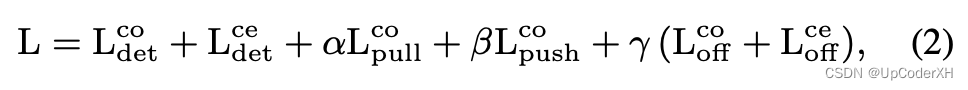
【Paper Reading】CenterNet:Keypoint Triplets for Object Detection
背景 首先是借鉴Corner Net 表述了一下基于Anchor方法的不足: anchor的大小/比例需要人工来确认anchor并没有完全和gt的bbox对齐,不利于分类任务。 但是CornerNet也有自己的缺点 CornerNet 只预测了top-left和bottom-right 两个点,并没有…...
)
【BASH】回顾与知识点梳理(三)
【BASH】回顾与知识点梳理 三 三. 命令别名与历史命令3.1 命令别名设定: alias, unalias3.2 历史命令:history同一账号同时多次登入的 history 写入问题无法记录时间 该系列目录 --> 【BASH】回顾与知识点梳理(目录) 三. 命令…...

C#设计模式之---单例模式
单例模式(Singleton) 单例模式,属于创建类型的一种常用的软件设计模式。通过单例模式的方法创建的类在当前进程中只有一个实例。 1)普通单例模式 using System; namespace SingletonPattern {/// /// 单例模式(非线程安全)/// …...
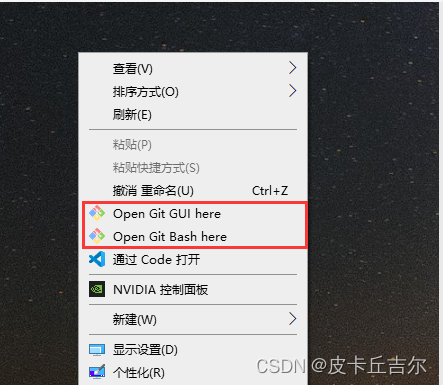
Git工具安装
Git 工具安装 1. 下载Git安装包2. 安装Git工具3. 简单的使用配置用户名 1. 下载Git安装包 打开官网 https://git-scm.com/downloads点击下载 2. 安装Git工具 右击以管理员身份运行 
深度学习——注意力机制、自注意力机制
什么是注意力机制? 1.注意力机制的概念: 我们在听到一句话的时候,会不自觉的捕获关键信息,这种能力叫做注意力。 比如:“我吃了100个包子” 有的人会注意“我”,有的人会注意“100个”。 那么对于机器来说…...

STM32入门学习之定时器中断
1.STM32的通用定时器是可编程预分频驱动的16位自动装载计数器。 STM32 的通用定时器可以被用于:测量输入信号的脉冲长度 ( 输入捕获 ) 或者产生输出波 形 ( 输出比较和 PWM) 等。 使用定时器预分频器和 RCC 时钟控制器预分频器,脉冲长度和波形 周…...

基本数据类型与包装数据类型的使用标准
Reference:《阿里巴巴Java开发手册》 【强制】所有的 POJO 类属性必须使用包装数据类型。【强制】RPC 方法的返回值和参数必须使用包装数据类型。【推荐】所有的局部变量使用基本数据类型。 比如我们如果自定义了一个Student类,其中有一个属性是成绩score,如果用Integer而不用…...
)
小研究 - 基于 SpringBoot 微服务架构下前后端分离的 MVVM 模型(二)
本文主要以SpringBoot微服务架构为基础,提出了前后端分离的MVVM模型,并对其进行了详细的分析以及研究,以此为相关领域的工作人员提供一定的技术性参考。 目录 4 SpringBoot 4.1 技术发展 4.2 技术特征 4.3 SpringBoot项目构建 4.4 目录结…...

ArmSoM-W3之RK3588安装Qt+opencv+采集摄像头画面
1. 简介 场景:在RK3588上做qt开发工作 RK3588安装Qtopencv采集摄像头画面 2. 环境介绍 这里使用了OpenCV所带的库函数捕获摄像头的视频图像。 硬件环境: ArmSoM-RK3588开发板、(MIPI-DSI)摄像头 软件版本: OS&…...

基于长短期神经网络的风速预测,基于LSTM的风速预测
目录 背影 摘要 LSTM的基本定义 LSTM实现的步骤 基于长短期神经网络LSTM的风速预测 完整代码: https://download.csdn.net/download/abc991835105/88171311 效果图 结果分析 展望 参考论文 背影 风速预测是一种比较难的预测,随机性比较大,长短期神经网络是一种改进党的RNN…...
Mybatis引出的一系列问题-spring多数据源配置
在日常开发中我们都是以单个数据库进行开发,在小型项目中是完全能够满足需求的。但是,当我们牵扯到像淘宝、京东这样的大型项目的时候,单个数据库就难以承受用户的CRUD操作。那么此时,我们就需要使用多个数据源进行读写分离的操作…...

Vue-组件二次封装
本次对el-input进行简单封装进行演示 封装很简单,就给激活样式的边框(主要是功能) 本次封装主要使用到vue自带的几个对象 $attrs:获取绑定在组件上的所有属性$listeners: 获取绑定在组件上的所有函数方法$slots: 获取应用在组件内的所有插槽 …...

[C++]02.选择结构与循环结构
02.选择结构与循环结构 一.程序流程结构1.选择结构1.1.if语句1.2.三目运算符1.3.switch语句 2.循环结构2.1.while语句2.2.do-while语句2.3.for语句2.4.break语句2.5.continue语句2.6.goto语句 一.程序流程结构 C/C支持的最基本的运行结构: 顺序结构, 选择结构, 循环结构顺序结…...
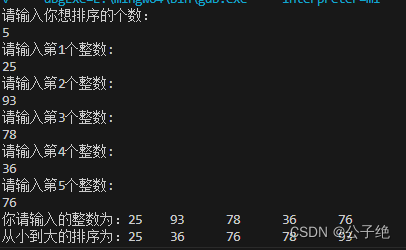
C语言案例 按序输出多个整数-03
难度2复杂度3 题目:输入多个整数,按从小到大的顺序输出 步骤一:定义程序的目标 编写一个C程序,随机输入整数,按照从小到大的顺序输出 步骤二:程序设计 整个C程序由三大模块组成,第一个模块使…...

如何获取vivado IP列表
TCL命令如下: set fid [open "vivado_included_ip_[version -short].csv" w] puts $fid "Name;Version" set ip_catalog [get_ipdefs *] foreach ip $ip_catalog{ set ipname [get_property DISPLAY_NAME [get_ipdefs $ip]]set iplib [get_p…...

5步构建智能建筑通信系统:BACnet4J纯Java协议栈的架构师指南
5步构建智能建筑通信系统:BACnet4J纯Java协议栈的架构师指南 【免费下载链接】BACnet4J BACnet/IP stack written in Java. Forked from http://sourceforge.net/projects/bacnet4j/ 项目地址: https://gitcode.com/gh_mirrors/ba/BACnet4J 在智能建筑和工业…...

苹果砂不锈钢蜂窝板做出来真的和苹果店一样吗?来自广东优之彩!
当“苹果店质感”成为高级商业空间的隐形标尺,无数人追问:我们能用苹果砂不锈钢蜂窝板,复刻那种极致、均匀、充满科技感的哑光金属美学吗?答案是:可以。但前提是,你选择的不仅是材料,更是一套完…...

告别背包爆满!TQVaultAE:泰坦之旅装备管理的终极解决方案
告别背包爆满!TQVaultAE:泰坦之旅装备管理的终极解决方案 【免费下载链接】TQVaultAE Extra bank space for Titan Quest Anniversary Edition 项目地址: https://gitcode.com/gh_mirrors/tq/TQVaultAE 你是否曾在《泰坦之旅》的冒险中࿰…...
功能仿真)
在 Simulink 中实现并网双向 DC/AC 逆变器的无功补偿(SVG)功能仿真
目录 🛠️ 第一步:系统架构设计与模块搭建 ⚙️ 第二步:SVG 核心控制策略设计(双闭环控制) 📊 第三步:仿真运行与结果分析 手把手教你在 Simulink 中实现并网双向 DC/AC 逆变器的无功补偿(SVG)功能仿真。 在现代电力系统中,并网逆变器(如光伏、储能逆变器)不…...

如何快速实现文献元数据智能转换:Zotero插件终极指南
如何快速实现文献元数据智能转换:Zotero插件终极指南 【免费下载链接】zotero-format-metadata Linter for Zotero. A plugin for Zotero to format item metadata. Shortcut to set title rich text; set journal abbreviations, university places, and item lang…...

Xiaomusic终极指南:如何通过5个技术模块实现小爱音箱智能音乐播放
Xiaomusic终极指南:如何通过5个技术模块实现小爱音箱智能音乐播放 【免费下载链接】xiaomusic 使用小爱音箱播放音乐,音乐使用 yt-dlp 下载。 项目地址: https://gitcode.com/GitHub_Trending/xia/xiaomusic 还在为传统音乐播放器的复杂操作和功能…...

别再被Word折磨了!百考通AI让你像“玩填空”一样搞定本科论文
论文写作不再是一座孤岛,而是一次有条不紊的旅程 又到了一年毕业季,朋友圈里开始交替出现两种状态:一种是晒答辩通过、手捧鲜花与导师合影的“上岸”喜讯,另一种则是深夜凌晨发出的、配着空白 Word 文档截图的“崩溃文学”。 “开…...
)
Python开发被内网卡脖子?5分钟用Docker搭个Pypiserver救急(含避坑指南)
Python内网开发救星:Docker化Pypiserver极速搭建指南 当你在客户现场调试代码时,突然发现内网环境无法连接PyPI官方源;当你在保密项目部署时,发现所有外网访问都被严格限制——这种"被卡脖子"的困境,相信不少…...

终极无人机仿真平台XTDrone:从入门到精通的完整指南
终极无人机仿真平台XTDrone:从入门到精通的完整指南 【免费下载链接】XTDrone UAV Simulation Platform based on PX4, ROS and Gazebo 项目地址: https://gitcode.com/gh_mirrors/xt/XTDrone XTDrone是一款基于PX4飞控、ROS机器人操作系统和Gazebo物理引擎的…...

如何在PC上免费畅玩Switch游戏:yuzu模拟器终极指南
如何在PC上免费畅玩Switch游戏:yuzu模拟器终极指南 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu 想要在电脑上体验任天堂Switch游戏吗?yuzu模拟器是你的完美选择!作为目前最受…...