实证研究在机器学习中的应用
实证研究是一种基于实际数据和事实的科学研究方法,目的是通过观察、测量、分析和解释数据来验证或否定某个假设、理论或研究问题。这种研究方法通常用于社会科学、自然科学和医学等领域。以下是实证研究的详细解释:
-
研究目标:实证研究旨在通过客观观察和测量来收集数据,以验证或验证理论、假设或研究问题。研究者通常制定明确的研究目标,从而使研究具有针对性和可操作性。
-
研究设计:实证研究有不同的设计类型,包括实验研究、调查研究、纵向研究、横断面研究等。研究设计的选择取决于研究问题和可行性。
-
数据收集:实证研究采用系统化的方法来收集数据。数据可以通过观察、问卷调查、实验、采访、文献研究等方式获取。数据应该是客观的、可重复的,并且能够回答研究问题。
-
数据分析:收集到数据后,研究者使用统计学和其他分析方法来处理数据。这些方法帮助研究者识别模式、关联、差异等,从而得出结论并验证假设。
-
结果解释:研究者通过数据分析得出结论,并对结果进行解释。解释过程应该客观、准确,并与研究问题紧密相关。
-
结论:基于实证研究的结果,研究者得出结论,对研究问题作出回答。这些结论可能支持或否定原先的假设或理论,并提供新的见解和认识。
-
可信性:实证研究强调数据的可信性和研究结果的可重复性。为了确保研究的可信性,研究者需要遵循科学研究的严谨性和方法论。
-
应用价值:实证研究的结果对于理论的发展、政策制定、实践应用等有着重要的应用价值。因为这些结果是通过客观数据和科学方法得出的,所以在决策过程中具有较高的可信度。
实证研究是一种强调观察和实际数据的科学研究方法,其目标是为了验证假设、理论或研究问题,并提供客观的结论和认识。通过实证研究,我们能够更好地了解现象背后的规律和关系,从而为社会进步和学科发展做出贡献。
实证研究在许多不同领域和场景中都有广泛的应用。以下列举了一些实证研究的应用场景:
-
社会科学:在社会学、心理学、经济学、教育学、政治学等社会科学领域,实证研究用于研究人类社会行为、社会现象、社会问题等。例如,调查研究用于了解公众对某个问题的态度;实验研究用于测试教育干预措施的有效性;纵向研究用于跟踪社会现象的变化和发展。
-
自然科学:在物理学、化学、生物学等自然科学领域,实证研究用于验证科学理论、探索自然现象和发展新的科技。例如,实验研究用于测试物质的特性;观测研究用于了解动物行为;实证模拟用于研究天体物理现象。
-
医学和健康科学:在医学、流行病学、公共卫生等领域,实证研究用于评估治疗方法的有效性、研究疾病的传播和预防措施。例如,临床试验用于评估药物疗效;流行病学调查用于研究疾病爆发的原因;卫生政策评估用于优化医疗服务。
-
商业和经济:在市场研究、消费者行为、企业管理等领域,实证研究用于了解市场趋势、消费者喜好、企业绩效等。例如,市场调查用于预测产品需求;企业绩效评估用于优化管理策略;经济模型用于预测经济发展。
-
教育和教育评估:在教育学领域,实证研究用于评估教育政策、教学方法和学生学习成果。例如,教育干预研究用于评估教育项目的效果;学生评估用于衡量学生学业水平;教学方法研究用于改进教学质量。
-
环境和可持续发展:在环境科学、资源管理、可持续发展等领域,实证研究用于评估环境影响、资源利用和可持续发展策略。例如,环境影响评估用于衡量工程项目对环境的影响;资源管理研究用于优化资源利用;可持续发展指标研究用于制定可持续发展目标。
这些应用场景只是实证研究的冰山一角,实际上,实证研究在几乎所有学科和领域中都扮演着重要的角色。通过使用实证研究方法,我们能够更好地理解和解决实际问题,推动学科发展和社会进步。
实证研究在机器学习中也有许多应用场景。机器学习是一种利用数据和算法使计算机系统通过学习和优化改进其性能的领域。以下是实证研究在机器学习中的一些常见应用场景:
-
模型评估与比较:实证研究可用于评估不同机器学习模型的性能,并比较它们在特定任务上的表现。研究者可以使用真实数据集对多种模型进行测试,以确定哪种模型更适合解决特定问题。
-
超参数优化:在机器学习中,模型通常有一些需要手动设置的参数,称为超参数。实证研究可以帮助寻找最优的超参数组合,以获得更好的模型性能。
-
特征工程与选择:实证研究可用于选择最具预测性的特征,或者帮助研究者进行特征工程,以提取更有意义的特征。这有助于提高模型的准确性和泛化能力。
-
弱点分析:实证研究可以帮助研究者找出机器学习模型的弱点和局限性。通过了解模型的局限性,可以改进和优化模型,使其更适应实际应用。
-
预测分析:在商业和科学领域,实证研究可以用于建立预测模型,用于预测市场趋势、顾客行为、自然灾害等。这对于决策制定和资源分配有着重要的应用价值。
-
强化学习策略:实证研究在强化学习中也有应用,用于测试和改进强化学习算法的性能,以及确定最佳的策略和动作选择。
-
数据增强和清洗:实证研究可以帮助研究者改进数据增强和数据清洗技术,从而提高训练数据的质量和数量,增强模型的鲁棒性。
-
交叉验证与泛化能力:实证研究可用于测试模型的泛化能力,并确定模型是否过拟合或欠拟合。
以上只是一些机器学习中实证研究的应用场景,实际上,随着机器学习技术的不断发展,实证研究在这个领域中的应用将会越来越广泛。通过实证研究,机器学习领域可以更好地理解模型行为、优化算法和推动技术进步。
下面将为您提供一个实证研究在机器学习中的完整实例:使用实证研究来比较不同分类算法在特定任务上的性能。
假设我们有一个数据集,其中包含一些动物的特征和它们所属的类别(例如狗、猫、鸟等)。我们的目标是建立一个分类模型,能够根据动物的特征将其正确地分类到相应的类别。
-
设定研究目标:我们的目标是比较不同分类算法在该任务上的性能。我们想知道哪种算法在这个特定的分类问题上表现最好。
-
数据收集与准备:我们收集了动物特征和对应的类别标签,确保数据集的质量和完整性。我们进行了数据预处理,包括处理缺失值、标准化特征等。
-
选择算法:我们选择了几种常见的分类算法作为研究对象,例如决策树、支持向量机(SVM)、逻辑回归和随机森林。
-
模型训练与测试:我们将数据集划分为训练集和测试集。使用训练集对每个算法进行训练,然后使用测试集来评估它们的性能。我们使用准确率、精确度、召回率等指标来衡量算法的表现。
-
结果分析:通过实际运行实验,我们得到了每个算法在测试集上的性能指标。我们将这些指标进行比较和分析,找出哪个算法在这个特定的任务上表现最好。
-
结论:根据实验结果,我们得出结论,例如哪个算法在准确率方面表现最好,哪个算法对于特定类别的分类效果更好等。我们也可以指出每个算法的优缺点,以及对于不同任务的适用性。
-
可信性:为了确保研究的可信性,我们可以采用交叉验证等技术来验证实验结果的稳健性,并确保实验的重复性。
-
应用价值:基于这个实证研究的结果,我们可以选择最适合该任务的分类算法,并将其应用于实际场景中,比如动物种类的识别、动物保护等领域。
通过这个实证研究实例,我们能够了解不同分类算法在特定任务上的表现,并为实际应用提供了指导和参考。这种方法也可以在其他机器学习任务中得到应用,例如回归、聚类等。实证研究在机器学习中的应用有助于推动该领域的发展,并提高机器学习技术在实际问题中的应用效果。
我们使用Python编程语言和Scikit-learn库来比较不同分类算法在一个虚拟的动物分类任务上的性能。我们将使用决策树、支持向量机(SVM)和逻辑回归算法。
首先,确保您已经安装了Python和Scikit-learn库。然后,按照以下步骤来实现这个实例:
# 导入所需库
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score# 创建虚拟的动物分类数据集
X, y = make_classification(n_samples=1000, n_features=5, n_classes=3, random_state=42)# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 初始化分类算法
decision_tree = DecisionTreeClassifier(random_state=42)
svm = SVC(random_state=42)
logistic_regression = LogisticRegression(random_state=42)# 训练模型
decision_tree.fit(X_train, y_train)
svm.fit(X_train, y_train)
logistic_regression.fit(X_train, y_train)# 预测结果
y_pred_dt = decision_tree.predict(X_test)
y_pred_svm = svm.predict(X_test)
y_pred_lr = logistic_regression.predict(X_test)# 计算模型性能指标
accuracy_dt = accuracy_score(y_test, y_pred_dt)
precision_dt = precision_score(y_test, y_pred_dt, average='weighted')
recall_dt = recall_score(y_test, y_pred_dt, average='weighted')accuracy_svm = accuracy_score(y_test, y_pred_svm)
precision_svm = precision_score(y_test, y_pred_svm, average='weighted')
recall_svm = recall_score(y_test, y_pred_svm, average='weighted')accuracy_lr = accuracy_score(y_test, y_pred_lr)
precision_lr = precision_score(y_test, y_pred_lr, average='weighted')
recall_lr = recall_score(y_test, y_pred_lr, average='weighted')# 打印结果
print("Decision Tree - Accuracy:", accuracy_dt, "Precision:", precision_dt, "Recall:", recall_dt)
print("SVM - Accuracy:", accuracy_svm, "Precision:", precision_svm, "Recall:", recall_svm)
print("Logistic Regression - Accuracy:", accuracy_lr, "Precision:", precision_lr, "Recall:", recall_lr)
请注意,这只是一个简单的示例,实际应用中,您可能需要更大规模和真实的数据集,并且需要进行更复杂的特征工程、超参数优化等工作。
这个示例展示了实证研究如何在机器学习中应用。通过比较不同分类算法在特定任务上的性能,我们可以了解每个算法的优劣,并选择最适合该任务的算法。
相关文章:

实证研究在机器学习中的应用
实证研究是一种基于实际数据和事实的科学研究方法,目的是通过观察、测量、分析和解释数据来验证或否定某个假设、理论或研究问题。这种研究方法通常用于社会科学、自然科学和医学等领域。以下是实证研究的详细解释: 研究目标:实证研究旨在通过…...

IO进程线程day8(2023.8.6)
一、Xmind整理: 管道的原理: 有名管道的特点: 信号的原理: 二、课上练习: 练习1:pipe 功能:创建一个无名管道,同时打开无名管道的读写端 原型: #include <unist…...

【5G NR】逻辑信道、传输信道和物理信道的映射关系
博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持! 博主链接 本人就职于国际知名终端厂商,负责modem芯片研发。 在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。 博客…...

tmux基础教程
tmux基础教程 Mac安装 brew install tmuxubuntu安装 sudo apt-get install tmux入门使用 会话 (Session) Ctrlb d: 分离当前会话。Ctrlb s: 列出所有会话。Ctrlb $: 重命名当前会话。 窗口(Window) Ctrlb c: 创建一个新窗口, 状态栏会显示多个窗…...
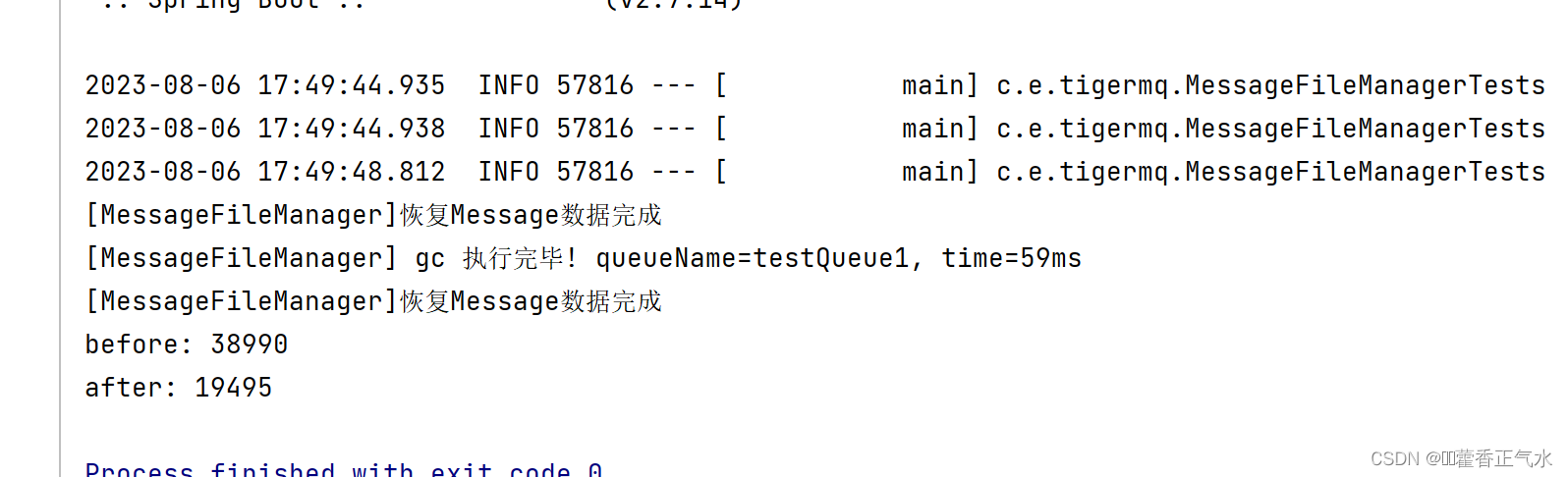
项目实战 — 消息队列(4){消息持久化}
目录 一、消息存储格式设计 🍅 1、queue_data.txt:保存消息的内容 🍅 2、queue_stat.txt:保存消息的统计信息 二、消息序列化 三、自定义异常类 四、创建MessageFileManger类 🍅 1、约定消息文件所在的目录和文件名…...

AI编程工具Copilot与Codeium的实测对比
csdn原创谢绝转载 简介 现在没有AI编程工具,效率会打一个折扣,如果还没有,赶紧装起来. GitHub Copilot是OpenAi与github等共同开发的的AI辅助编程工具,基于ChatGPT驱动,功能强大,这个没人怀疑…...
webpack基础知识六:说说webpack的热更新是如何做到的?原理是什么?
一、是什么 HMR全称 Hot Module Replacement,可以理解为模块热替换,指在应用程序运行过程中,替换、添加、删除模块,而无需重新刷新整个应用 例如,我们在应用运行过程中修改了某个模块,通过自动刷新会导致…...

Linux从安装到实战 常用命令 Bash常用功能 用户和组管理
1.0初识Linux 1.1虚拟机介绍 1.2VMware Workstation虚拟化软件 下载CentOS; 1.3远程链接Linux系统 &FinalShell 链接finalshell半天没连接进去 他说ip adress 看IP地址是在虚拟机上 win11主机是 终端输入: ifconfig VMware虚拟机的设置 & ssh连接_snge…...
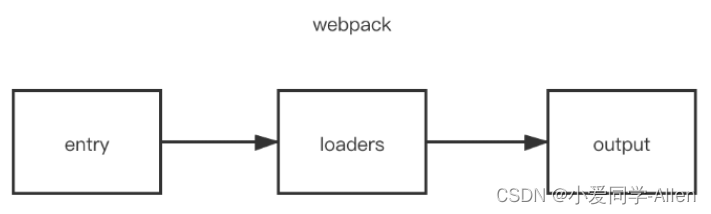
webpack基础知识三:说说webpack中常见的Loader?解决了什么问题?
一、是什么 loader 用于对模块的"源代码"进行转换,在 import 或"加载"模块时预处理文件 webpack做的事情,仅仅是分析出各种模块的依赖关系,然后形成资源列表,最终打包生成到指定的文件中。如下图所示&#…...

深度学习:Pytorch常见损失函数Loss简介
深度学习:Pytorch常见损失函数Loss简介 L1 LossMSE LossSmoothL1 LossCrossEntropy LossFocal Loss 此篇博客主要对深度学习中常用的损失函数进行介绍,并结合Pytorch的函数进行分析,讲解其用法。 L1 Loss L1 Loss计算预测值和真值的平均绝对…...

【Android-java】Parcelable 是什么?
Parcelable 是 Android 中的一个接口,用于实现将对象序列化为字节流的功能,以便在不同组件之间传递。与 Java 的 Serializable 接口不同,Parcelable 的性能更高,适用于 Android 平台。 要实现 Parcelable 接口,我们需…...
)
Spring整合MyBatis小实例(转账功能)
实现步骤 一,引入依赖 <!--仓库--><repositories><!--spring里程碑版本的仓库--><repository><id>repository.spring.milestone</id><name>Spring Milestone Repository</name><url>https://repo.spring.i…...

List集合的对象传输的两种方式
说明:在一些特定的情况,我们需要把对象中的List集合属性存入到数据库中,之后把该字段取出来转为List集合的对象使用(如下图) 自定义对象 public class User implements Serializable {/*** ID*/private Integer id;/*…...

海外媒体发稿:软文写作方法方式?一篇好的软文理应合理规划?
不同种类的软文会有不同的方式,下面小编就来来给大家分析一下: 方法一、要选定文章的突破点: 所说突破点就是这篇文章文章软文理应以什么样的视角、什么样的见解、什么样的语言设计理念、如何文章文章的标题来写。不同种类的传播效果&#…...
【秋招】算法岗的八股文之机器学习
目录 机器学习特征工程常见的计算模型总览线性回归模型与逻辑回归模型线性回归模型逻辑回归模型区别 朴素贝叶斯分类器模型 (Naive Bayes)决策树模型随机森林模型支持向量机模型 (Support Vector Machine)K近邻模型神经网络模型卷积神经网络(CNN)循环神经…...
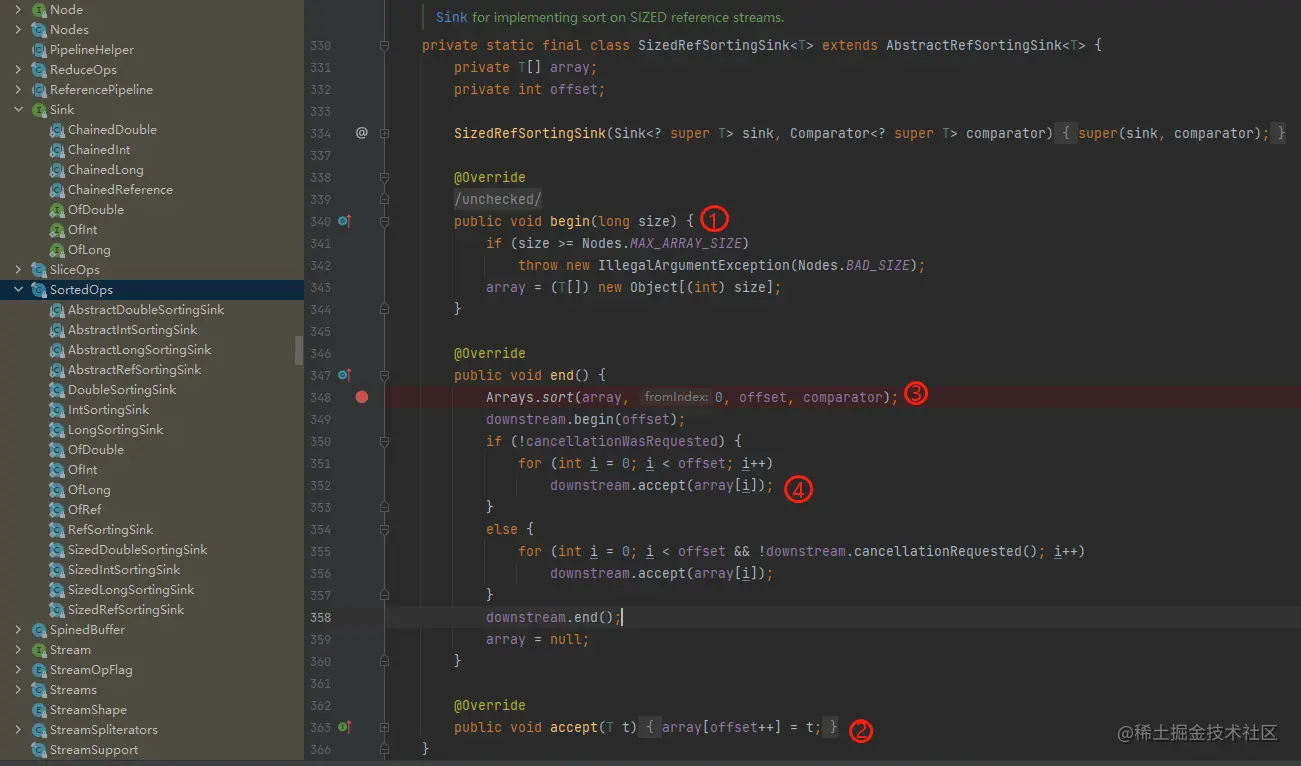
为什么list.sort()比Stream().sorted()更快?
真的更好吗? 先简单写个demo List<Integer> userList new ArrayList<>();Random rand new Random();for (int i 0; i < 10000 ; i) {userList.add(rand.nextInt(1000));}List<Integer> userList2 new ArrayList<>();userList2.add…...

SQL账户SA登录失败,提示错误:18456
错误代码 18456 表示 SQL Server 登录失败。这个错误通常表示提供的凭据(用户名和密码)无法成功验证或者没有权限访问所请求的数据库。以下是一些常见的可能原因和解决方法: 1.错误的凭据:请确认提供的SA账户的用户名和密码是否正…...
Linux 终端操作命令(1)
Linux 命令 终端命令格式 command [-options] [parameter] 说明: command:命令名,相应功能的英文单词或单词的缩写[-options]:选项,可用来对命令进行控制,也可以省略parameter:传给命令的参…...

java与javaw运行jar程序
运行jar程序 一、java.exe启动jar程序 (会显示console黑窗口) 1、一般用法: java -jar myJar.jar2、重命名进程名称启动: echo off copy "%JAVA_HOME%\bin\java.exe" "%JAVA_HOME%\bin\myProcess.exe" myProcess -jar myJar.jar e…...

安装和配置 Home Assistant 教程 HACS Homkit 米家等智能设备接入
安装和配置 Home Assistant 教程 简介 Home Assistant 是一款开源的智能家居自动化平台,可以帮助你集成和控制各种智能设备,从灯光到温度调节器,从摄像头到媒体播放器。本教程将引导你如何在 Docker 环境中安装和配置 Home Assistant&#…...

CoPaw:让AI代码助手深度适配个人项目与团队规范的工程化实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫CoPaw,作者是 alexgzx。光看名字可能有点摸不着头脑,但如果你对 AI 辅助编程、代码生成或者想提升自己的开发效率感兴趣,那这个项目绝对值得你花时间研究一下。简单来说…...

AI应用开发利器:ai-devkit工具包核心功能与工程实践指南
1. 项目概述与核心价值最近在折腾AI应用开发,发现一个挺有意思的项目,叫codeaholicguy/ai-devkit。乍一看名字,你可能会觉得这又是一个“AI开发工具包”,市面上类似的工具已经多如牛毛了。但深入用下来,我发现它不太一…...

百度网盘直链解析工具:3分钟突破限速实现满速下载
百度网盘直链解析工具:3分钟突破限速实现满速下载 【免费下载链接】baidu-wangpan-parse 获取百度网盘分享文件的下载地址 项目地址: https://gitcode.com/gh_mirrors/ba/baidu-wangpan-parse 你是否曾为百度网盘的下载速度而烦恼?非会员用户经常…...
)
保姆级教程:INCA 7.2.3 从新建工程到观测标定的完整流程(附A2L文件处理技巧)
INCA 7.2.3 全流程实战指南:从工程搭建到参数标定的深度解析 在汽车电子开发领域,标定工具链的掌握程度直接影响开发效率。作为行业标准的INCA软件,其7.2.3版本在工程管理、实时观测和参数标定方面提供了更完善的解决方案。本文将采用"操…...

番茄小说下载器终极指南:3分钟打造你的私人数字图书馆
番茄小说下载器终极指南:3分钟打造你的私人数字图书馆 【免费下载链接】fanqienovel-downloader 下载番茄小说 项目地址: https://gitcode.com/gh_mirrors/fa/fanqienovel-downloader 你是否曾在深夜追更小说时,突然发现网络连接中断?…...

基于Arduino与加速度传感器的可穿戴智能徽章制作全解析
1. 项目概述:一个会“走路”的智能徽章几年前,当《Pokemon Go》风靡全球时,我注意到一个有趣的现象:深夜的公园里,总有一群玩家低头盯着手机屏幕,在昏暗的光线下穿梭。这固然是游戏的乐趣,但也带…...

Linux内核升级C11标准:从C89到现代C语言的演进与实战解析
1. 项目概述:一次内核语言的“心脏移植”最近Linux内核社区的一个决定,在开发者圈子里激起了不小的波澜:计划将内核的C语言标准从使用了超过十年的C89/C90,逐步迁移到C11。这听起来可能像是一个枯燥的技术规范更新,但对…...

本地可控 AI 助手搭建|Windows 一键安装 OpenClaw 操作指南
OpenClaw(小龙虾)Windows 一键部署保姆级教程|10 分钟搭建专属数字员工 前言 2026 年备受关注的开源 AI 智能体 OpenClaw(昵称小龙虾),在 GitHub 收获大量关注,凭借本地运行、零代码操作、自动…...

Java源码详解:深入Java并发之AtomicBoolean全景式解析——无锁布尔标志的精妙实现与云原生演进
概述 在高并发编程中,一个看似简单的布尔标志位(如 shutdown、initialized)也可能成为线程安全的隐患。传统的 volatile boolean 虽能保证可见性,却无法保证 “读-改-写” 操作的原子性。为解决这一问题,Java并发包&a…...

【模拟电路】Circuit JS:从零到一,构建你的首个交互式电路实验
1. 初识Circuit JS:你的虚拟电路实验室 第一次接触Circuit JS时,我正为一个简单的LED电路设计发愁。传统仿真软件要么安装复杂,要么收费昂贵,直到发现这个直接在浏览器里运行的免费工具。打开网页的瞬间,就像走进了中学…...