DBSCAN聚类
一、概述
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,簇集的划定完全由样本的聚集程度决定。聚集程度不足以构成簇落的那些样本视为噪声点,因此DBSCAN聚类的方式也可以用于异常点的检测。
二、算法原理
1.基本原理
算法的关键在于样本的‘聚集程度’,这个程度的刻画可以由聚集半径和最小聚集数两个参数来描述。如果一个样本聚集半径领域内的样本数达到了最小聚集数,那么它所在区域就是密集的,就可以围绕该样本生成簇落,这样的样本被称为核心点。如果一个样本在某个核心点的聚集半径领域内,但其本身又不是核心点,则被称为边界点;既不是核心点也不是边界点的样本即为噪声点。其中,最小聚集数通常由经验指定,一般是数据维数+1或者数据维数的2倍。
通俗地讲,核心点就是构成一个簇落的核心成员;边界点就是构成一个簇落的非核心成员,它们分布于簇落的边界区域;噪声点是无法归属在任何一个簇集的游离的异常样本。如图所示。

对于聚成的簇集,这里有三个相关的概念:密度直达,密度可达,密度相连。
密度直达: 对一个核心点p,它的聚集半径领域内的有点q,那么称p到q密度直达。密度直达不具有对称性。
密度可达: 有核心点p1,p2,…,pn,非核心点q,如果pi到pi+1(i=1,2,…,n-1)是密度直达的,pn到q是密度直达的,那么称核心点pi(i=1,2,…,n)到其他的点是密度可达的。密度可达不具有对称性。
密度相连: 如果有核心点P,到两个点A和B都密度可达,那么称A和B密度相连。密度相连具有对称性。
简单地讲,核心点到其半径邻域内的点是密度直达的;核心点到其同簇集内的点是密度可达的;同一个簇集里的成员间是密度相连的。

由定义易知,密度直达一定密度可达,密度可达一定密度相连。密度相连就是对聚成的一个簇集最直接的描述。
2.算法描述
输入: 样本集D,聚集半径r,最小聚集数MinPts;
输出: 簇集C1,C2,…,Cn,噪声集O.
根据样本聚集程度,传播式地划定聚类簇,并将不属于任何一个簇的样本划入噪声集合。
(1)随机搜寻一个核心点p,
S1.从样本集D中随机选择一个未归入任何集合的且未被标记的样本对象p
S2.计算p的r邻域大小 ∣ N r ( p ) ∣ \left| N_r(p) \right| ∣Nr(p)∣
若 ∣ N r ( p ) ∣ ≥ M i n P t s \left| N_r(p) \right|\geq MinPts ∣Nr(p)∣≥MinPts ,则标记为核心点;否则,标记为非核心点,并选择其他的点进行判别.
S3.重复上面的步骤,直至找到一个核心点;若未找到,将未归集的样本划入噪声集O.
(2)在核心点p处建立簇C,将r邻域内所有的点加入簇C.
(3)对邻域内所有未被标记的点迭代式进行考察,扩展簇集.
若一个邻域点q为核心点,则将它领域内未归入集合的点加入簇C中.
(4)重复以上步骤,直至所有样本划入了指定集合;
(5)输出簇集C1,C2,…,Cn和噪声集合O。
3.优缺点
优势:
1.可以发现任意形状的簇,适用于非凸数据集;
2.可以进行异常检测;
3.不需要指定簇数,根据样本的密集程度适应性地聚集。
不足:
1.当样本集密度不均匀,不同簇中的平均密度相差较大时,效果较差;
2.聚集半径和最小聚集数两个参数需人工指定。
三、示例
假设二维空间中有下列样本,坐标为
由DBSCAN算法完成聚类操作。
过程演算:
由经验指定参数聚集半径r=2,最小聚集数MinPts=3。
(1)随机搜寻一个核心点,若不存在,返回噪声集合。
考察点(1,2),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(1,2)为核心点。
(2)在核心点(1,2)处建立簇C1,原始簇成员为r邻域内样本:(1,2)、(1,3)、(2,2)。
(3)对簇落C1成员迭代式进行考察,扩展簇集。
先考察(1,3),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(1,3)为核心点,它邻域内的样本均已在簇C1中,无需进行操作。
再考察(2,2),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共四个样本点,达到了MinPts数,因此(2,2)为核心点,将它领域内尚未归入任何一个簇落的点(3,1)加入簇C1。
再考察(3,1),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共两个样本点,因此(3,1)是非核心点。
考察结束,簇集C1扩展完毕。
(4)在其余未归簇的样本点中搜寻一个核心点,若不存在,返回噪声集合。
考察点(9,8),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(9,8)为核心点。
(5)在核心点(9,8)处建立簇C2,原始簇成员为r邻域内样本:(9,8)、(8,9)、(9,9)。
(6)对簇落C2成员迭代式进行考察,扩展簇集。
先考察(8,9),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(8,9)为核心点,它邻域内的样本均已在簇C2中,无需进行操作。
再考察(9,9),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共三个样本点,达到了MinPts数,因此(9,9)为核心点。它邻域内的样本均已在簇C2中,无需进行操作。
考察结束,簇集C2扩展完毕。
(7)在其余未归簇的样本点中搜寻一个核心点,若不存在,返回噪声集合。
其余未归簇的样本点集合为{(18,18)},考察(18,18),它到各点的距离分别为

在它的r邻域内,包括了自身在内的共一个样本点,未达到MinPts数,因此(18,18)为非核心点。其余未归簇的样本中不存在核心点,因此归入噪声集O={(18,18)}。
(8)输出聚类结果
簇类C1:{(1,2),(1,3),(3,1),(2,2)}
簇类C2:{(9,8),(8,9),(9,9)}
噪声集O:{(18,18)}
四、Python实现
示例的Python实现。
'''
功能:用python实现DBSCAN聚类算法。
'''
from sklearn.cluster import DBSCAN
import numpy as np
import matplotlib.pyplot as plt# 初始化数据
data = np.array([(1,2),(1,3),(3,1),(2,2),(9,8),(8,9),(9,9),(18,18)])# 定义DBSCAN模型
dbscan = DBSCAN(eps=2,min_samples=3)# 计算数据,获取标签
labels = dbscan.fit_predict(data)# 定义颜色列表
colors = ['b','r','c']
T = [colors[i] for i in labels]# 输出簇类
print('\n 聚类结果: \n')
ue = np.unique(labels)
for i in range(ue.size):CLS = []for k in range(labels.size):if labels[k] == ue[i]:CLS.append(tuple(data[k]))print('簇类{}:'.format(ue[i]),CLS)# 结果可视化
plt.figure()
plt.scatter(data[:,0],data[:,1],c=T,alpha=0.5) # 绘制数据点
plt.show()运行结果:


End.
资源打包下载:
https://download.csdn.net/download/Albert201605/88152784?spm=1001.2014.3001.5503
相关文章:
DBSCAN聚类
一、概述 DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种基于密度的聚类算法,簇集的划定完全由样本的聚集程度决定。聚集程度不足以构成簇落的那些样本视为噪声点,因此DBSCAN聚类的方式也可以用于异常点的检测。 二、算法…...

java+ssm美食推荐交流系统 7jsw7
随着社会的发展,美食推荐系统的管理形势越来越严峻。越来越多的用户利用互联网获得信息,但美食推荐信息鱼龙混杂,真假难以辨别。为了方便用户更好的获得美食推荐信息,因此,设计一款安全高效的美食推荐系统极为重要。 为…...

基于php雪花算法工具类Snowflake -来自chatGPT
<?phpclass Snowflake {// 定义Snowflake算法的各个参数private $workerIdBits 5;private $datacenterIdBits 5;private $sequenceBits 12;private $workerIdShift;private $datacenterIdShift;private $timestampLeftShift;private $maxWorkerId;private $maxDatacente…...

怎么加密文件夹才更安全?安全文件夹加密软件推荐
文件夹加密可以让其中数据更加安全,但并非所有加密方式都能够提高极高的安全强度。那么,怎么加密文件夹才更安全呢?下面我们就来了解一下那些安全的文件夹加密软件。 文件夹加密超级大师 如果要评选最安全的文件夹加密软件,那么文…...

知识分享和Tomcat简单部署press应用
一、简述静态网页和动态网页的区别。 静态网页: 静态网页是指运行于客户端的程序、网页、组件、纯粹HTML格式的网页; 如果有涉及网页内容的修改,就要修改源文件,重新上传到服务器。而且当网站信息量很大的时候,网页制作和维护都非常困…...

回归预测 | MATLAB实现SO-CNN-BiGRU蛇群算法优化卷积双向门控循环单元多输入单输出回归预测
回归预测 | MATLAB实现SO-CNN-BiGRU蛇群算法优化卷积双向门控循环单元多输入单输出回归预测 目录 回归预测 | MATLAB实现SO-CNN-BiGRU蛇群算法优化卷积双向门控循环单元多输入单输出回归预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 MATLAB实现SO-CNN-BiGRU蛇群算法…...
步入React前厅 - 组件和JSX
目录 扩展学习资料 购物车应用 编写React元素 /src/index.js 创建组件 /src/components/listItem.jsx /src/App.js 理解JSX【JavaScriptXML】 JSX是什么 JSX规则 /src/components/listItem.jsx 使用Fragments /src/App.js 为何要使用Fragments 表格中使用Fragme…...
SpringBoot整合Sfl4j+logback的实践
一、概述 对于一个web项目来说,日志框架是必不可少的,日志的记录可以帮助我们在开发以及维护过程中快速的定位错误。slf4j,log4j,logback,JDK Logging等这些日志框架都是我们常见的日志框架,本文主要介绍这些常见的日志框架关系和SpringBoot…...

IT 基础架构自动化
什么是 IT 基础架构自动化 IT 基础架构自动化是通过使用技术来控制和管理构成 IT 基础架构的软件、硬件、存储和其他网络组件来减少人为干预的过程,目标是构建高效、可靠的 IT 环境。 为什么要自动化 IT 基础架构 为客户和员工提供无缝的数字体验已成为企业的当务…...
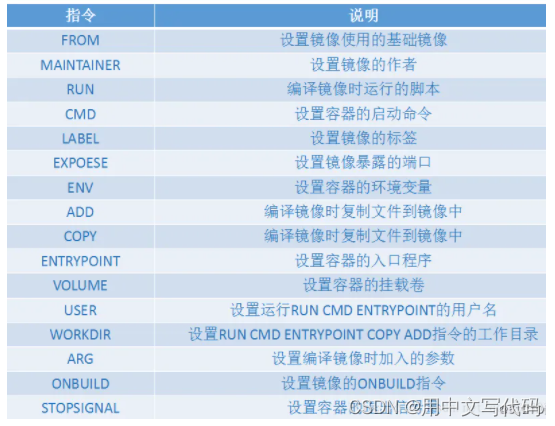
Docker入门——保姆级
Docker概述 —— Notes from WAX through KuangShen 准确来说,这是一篇学习笔记!!! Docker为什么出现 一款产品:开发—上线 两套环境!应用环境如何铜鼓? 开发 – 运维。避免“在我的电脑…...

MONGODB ---- Austindatabases 历年文章合集
开头还是介绍一下群,如果感兴趣polardb ,mongodb ,mysql ,postgresql ,redis 等有问题,有需求都可以加群群内有各大数据库行业大咖,CTO,可以解决你的问题。加群请联系 liuaustin3 ,在新加的朋友会分到2群(共…...
菠萝头 pinia和vuex对比 pinia比vuex更香 Pinia数据持久化及数据加密
前言 毕竟尤大佬都推荐使用pinia,支持vue2和vue3! 如果熟悉vuex,花个把小时把pinia看一下,就不想用vuex了 支持选项式api和组合式api写法pinia没有mutations,只有:state、getters、actionspinia分模块不…...

机器学习笔记 - 关于GPT-4的一些问题清单
一、简述 据报道,GPT-4 的系统由八个模型组成,每个模型都有 2200 亿个参数。GPT-4 的参数总数估计约为 1.76 万亿个。 近年来,得益于 GPT-4 等高级语言模型的发展,自然语言处理(NLP) 取得了长足的进步。凭借其前所未有的规模和能力,GPT-4为语言 AI设立了新标准,并为机…...

sql 参数自动替换
需求:看日志时,有的sql 非常的长,参数比较多,无法直接在sql 客户端工具执行,如果一个一个的把问号占位符替换为参数太麻烦,因此写个html 小工具,批量替换: 代码: <!…...
Linux——设备树
目录 一、Linux 设备树的由来 二、Linux设备树的目的 1.平台识别 2.实时配置 3.设备植入 三、Linux 设备树的使用 1.基本数据格式 2.设备树实例解析 四、使用设备树的LED 驱动 五、习题 一、Linux 设备树的由来 在 Linux 内核源码的ARM 体系结构引入设备树之前&#x…...
网络:从socket编程的角度说明UDP和TCP的关系,http和tcp的区别
尝试从编程的角度解释各种网络协议。 UDP和TCP的关系 从Python的socket编程角度出发,UDP(User Datagram Protocol)和TCP(Transmission Control Protocol)是两种不同的传输协议。 TCP是一种面向连接的协议,…...
大数据技术之Hadoop:HDFS集群安装篇(三)
目录 分布式文件系统HDFS安装篇 一、为什么海量数据需要分布式存储 二、 分布式的基础架构分析 三、 HDFS的基础架构 四 HDFS集群环境部署 4.1 下载安装包 4.2 集群规划 4.3 上传解压 4.4 配置HDFS集群 4.5 准备数据目录 4.6 分发hadoop到其他服务器 4.7 配置环境变…...

移动开发最佳实践:为 Android 和 iOS 构建成功应用的策略
您可以将本文作为指南,确保您的应用程序符合可行的最重要标准。请注意,这份清单远非详尽无遗;您可以加以利用,并添加一些自己的见解。 了解您的目标受众 要制作一个成功的应用程序,你需要了解你是为谁制作的。从创建…...
)
2023年第二届网络安全国际会议(CSW 2023)
会议简介 Brief Introduction 2023年第二届网络安全国际会议(CSW 2023) 会议时间:2023年10月13日-15日 召开地点:中国杭州 大会官网:www.cybersecurityworkshop.org 2023年第二届网络安全国际会议(CSW 2023)由杭州电子科技大学,国…...
【100天精通python】Day23:正则表达式,基本语法与re模块详解示例
目录 专栏导读 1 正则表达式概述 2 正则表达式语法 2.1 正则表达式语法元素 2.2 正则表达式的分组操作 3 re 模块详解与示例 4 正则表达式修饰符 专栏导读 专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html 1 正则表达式概述 python 的…...

都在喊难,它却狂赚!深度扒开长鑫科技底牌:什么才是决定生死的产业势?
2026年的商业世界,正在经历一场冰火两重天的考验。 一边,是无数传统企业在需求萎缩、价格内卷的泥潭里苦苦挣扎,老板们每天为了几毛钱的利润拼得头破血流;而另一边,一份堪称“核弹级”的财报,直接炸翻了整个…...

AI Agent与RPA的融合:智能自动化新范式
AI Agent与RPA的融合:智能自动化新范式 关键词:AI Agent、RPA、智能自动化、融合技术、自主决策、业务流程优化、人机协作 摘要:本文深入探讨了AI Agent与RPA(机器人流程自动化)的融合,揭示了这一技术组合如何开创智能自动化的新范式。我们将通过生动的类比和详细的技术解…...

AI Agent Harness Engineering 技术选型指南:根据场景选择合适的大模型与框架
AI Agent Harness Engineering 技术选型指南:根据场景选择合适的大模型与框架 引言 痛点引入 你是否遇到过这样的场景?产品经理拍板要做一个**“能帮企业HR自动筛选简历、邀约面试、生成入职指南并跟进试用期转正材料”**的“超级HR助手”AI Agent——…...

免费在线去水印软件怎样选择?2026 优缺点对比及推荐指南
随着内容创作和素材收集的日常化,去水印的需求越来越普遍。一张素材上的水印、一段视频中的平台标志,都可能影响二次创作或个人使用的体验。市面上的去水印方案从专业软件到在线工具五花八门,选择合适的工具需要了解各自的特点和适用场景。本…...

Python数据流式处理:Streaming深度解析与实战
Python数据流式处理:Streaming深度解析与实战 引言 在Python开发中,数据流式处理是处理大数据和实时数据的关键技术。作为一名从Rust转向Python的后端开发者,我深刻体会到流式处理在处理海量数据时的优势。Python提供了多种流式处理工具&…...

RAG 和 NotebookLM 都试过后,我才发现数据库知识库真正缺的不是搜索
很多数据库知识库不好用,不是模型不会答,而是知识没有被整理成可调用、可校验、可维护的资产。 前面几篇一直在聊 DB Agent。 聊 Skill,聊记忆,聊告警风暴,聊编排,也聊到了系统画像、历史案例和当前证据。…...

CMake基础:常用内部变量和环境变量的引用
目录 1.常用 CMake 变量 1.1.编译与构建控制 1.2.路径与目录变量 1.3.项目信息变量 1.4.系统与平台变量 1.5.工具链与交叉编译 1.6.测试与安装变量 1.7.高级编译选项 2.常用环境变量 2.1.编译器与工具链 2.2.依赖库路径 2.3.CMake 专用环境变量 2.4.系统环境变量P…...

前 DeepMind 研究员反思:评测,而非算力或数据,才是下一阶段的瓶颈
一线后训练研究员的技术随笔与动态评测管线启示当你还在为某项主流基准的分数微涨而讨论时,模型可能已悄悄学会“只说真话但战略性隐瞒”。前 Google DeepMind 高级研究员 Lun Wang 在近期的技术长文中抛出一个反直觉观察:如果下一代大模型跨进了全新的能…...

【巴洛克AI生成合规白皮书】:基于梵蒂冈档案馆高清藏品训练的192个版权安全Prompt模板
更多请点击: https://codechina.net 第一章:巴洛克AI生成合规白皮书导论 巴洛克AI生成合规白皮书旨在为组织在部署和运营生成式人工智能系统时,提供一套可落地、可审计、可演进的合规治理框架。该白皮书聚焦于中国《生成式人工智能服务管理暂…...
)
告别Excel!用Python复现地理探测器(附完整代码与示例数据)
告别Excel!用Python复现地理探测器(附完整代码与示例数据) 地理探测器作为分析空间分异性的重要工具,长期以来依赖Excel插件实现计算。但对于需要批量处理、自定义分析流程的研究者而言,这种封闭式操作存在明显局限。…...