Elasticsearch 使用scroll滚动技术实现大数据量搜索、深度分页问题 和 search
基于scroll滚动技术实现大数据量搜索
如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scroll滚动查询,一批一批的查,直到所有数据都查询完为止。
-
scroll搜索会在第一次搜索的时候,保存一个当时的视图快照,之后只会基于该旧的视图快照提供数据搜索,如果这个期间数据变更,是不会让用户看到的
-
采用基于_doc(不使用_score)进行排序的方式,性能较高
-
每次发送scroll请求,我们还需要指定一个scroll参数,指定一个时间窗口,每次搜索请求只要在这个事件窗口内能完成就可以了
# sort默认是相关度排序("sort":[{"FIELD":{"order":"desc"}}]),不按_score排序,按_doc排序 # size设置的是这批查三条 # 第一次查询会生成快照 GET /lib3/user/_search?scroll=1m #这一批查询在一分钟内完成 {"query":{"match":{}},"sort":[ "_doc"],"size":3 }# 第二次查询通过第一次的快照ID来查询,后面以此类推 GET /_search/scroll {"scroll":"1m","scroll_id":"DnF1ZXJ5VGhIbkXIdGNoAwAAAAAAAAAdFkEwRENOVTdnUUJPWVZUd1p2WE5hV2cAAAAAAAAAHhZBMERDTIU3Z1FCT1|WVHdadIhOYVdnAAAAAAAAAB8WQTBEQ05VN2dRQk9ZVIR3WnZYTmFXZw==" }
基于 scroll 解决深度分页问题
原理上是对某次查询生成一个游标 scroll_id , 后续的查询只需要根据这个游标去取数据,直到结果集中返回的 hits 字段为空,就表示遍历结束。
注意:scroll_id 的生成可以理解为建立了一个临时的历史快照,在此之后的增删改查等操作不会影响到这个快照的结果。
使用 curl 进行分页读取过程如下:
-
先获取第一个 scroll_id,url 参数包括 /index/_type/ 和 scroll,scroll 字段指定了scroll_id 的有效生存期,以分钟为单位,过期之后会被es 自动清理。如果文档不需要特定排序,可以指定按照文档创建的时间返回会使迭代更高效。
GET /product/info/_search?scroll=2m {"query":{"match_all":{}},"sort":["_doc"] }# 返回结果 {"_scroll_id": "DnF1ZXJ5VGhIbkXIdGNoAwAAAAAAAAAdFkEwRENOVTdnUUJPWVZUd1p2WE5hV2cAAAAAAAAAHhZBMERDTIU3Z1FCT1|WVHdadIhOYVdnAAAAAAAAAB8WQTBEQ05VN2dRQk9ZVIR3WnZYTmFXZw==","took": 1,"timed_out": false,"_shards": {"total": 1,"successful": 1,"failed": 0},"hits":{...} } -
后续的文档读取上一次查询返回的scroll_id 来不断的取下一页,如果srcoll_id 的生存期很长,那么每次返回的 scroll_id 都是一样的,直到该 scroll_id 过期,才会返回一个新的 scroll_id。请求指定的 scroll_id 时就不需要 /index/_type 等信息了。每读取一页都会重新设置 scroll_id 的生存时间,所以这个时间只需要满足读取当前页就可以,不需要满足读取所有的数据的时间,1 分钟足以。
GET /product/info/_search?scroll=DnF1ZXJ5VGhIbkXIdGNoAwAAAAAAAAAdFkEwRENOVTdnUUJPWVZUd1p2WE5hV2cAAAAAAAAAHhZBMERDTIU3Z1FCT1|WVHdadIhOYVdnAAAAAAAAAB8WQTBEQ05VN2dRQk9ZVIR3WnZYTmFXZw== {"query":{"match_all":{}},"sort":["_doc"] }# 返回结果 {"_scroll_id": "DnF1ZXJ5VGhIbkXIdGNoAwAAAAAAAAAdFkEwRENOVTdnUUJPWVZUd1p2WE5hV2cAAAAAAAAAHhZBMERDTIU3Z1FCT1|WVHdadIhOYVdnAAAAAAAAAB8WQTBEQ05VN2dRQk9ZVIR3WnZYTmFXZw==","took": 106,"_shards": {"total": 1,"successful": 1,"failed": 0},"hits": {"total": 22424,"max_score": 1.0,"hits": [{"_index": "product","_type": "info","_id": "did-519392_pdid-2010","_score": 1.0,"_routing": "519392","_source": {....}}]} } -
所有文档获取完毕之后,需要手动清理掉 scroll_id 。虽然es 会有自动清理机制,但是 srcoll_id 的存在会耗费大量的资源来保存一份当前查询结果集映像,并且会占用文件描述符。所以用完之后要及时清理。使用 es 提供的 CLEAR_API 来删除指定的 scroll_id。
# 删掉指定的多个 srcoll_id DELETE /_search/scroll -d {"scroll_id":["cXVlcnlBbmRGZXRjaDsxOzg3OTA4NDpTQzRmWWkwQ1Q1bUlwMjc0WmdIX2ZnOzA7"] }# 删除掉所有索引上的 scroll_id DELETE /_search/scroll/_all# 查询当前所有的scroll 状态 GET /_nodes/stats/indices/_search?pretty# 返回结果 {"cluster_name" : "200.200.107.232","nodes" : {"SC4fYi0CT5mIp274ZgH_fg" : {"timestamp" : 1514346295736,"name" : "200.200.107.232","transport_address" : "200.200.107.232:9300","host" : "200.200.107.232","ip" : [ "200.200.107.232:9300", "NONE" ],"indices" : {"search" : {"open_contexts" : 0,"query_total" : 975758,"query_time_in_millis" : 329850,"query_current" : 0,"fetch_total" : 217069,"fetch_time_in_millis" : 84699,"fetch_current" : 0,"scroll_total" : 5348,"scroll_time_in_millis" : 92712468,"scroll_current" : 0}}}} }
基于 search_after 实现深度分页
search_after 是 ES5.0 及之后版本提供的新特性,search_after 有点类似 scroll,但是和 scroll 又不一样,它提供一个活动的游标,通过上一次查询最后一条数据来进行下一次查询。
search_after 分页的方式和 scroll 有一些显著的区别,首先它是根据上一页的最后一条数据来确定下一页的位置,同时在分页请求的过程中,如果有索引数据的增删改查,这些变更也会实时的反映到游标上。
-
第一页的请求和正常的请求一样。
GET /order/info/_search {"size": 10,"query": {"match_all" : {}},"sort": [{"date": "asc"}] }# 返回结果 {"_index": "zmrecall","_type": "recall","_id": "60310505115909","_score": null,"_source": {..."date": 1545037514},"sort": [1545037514]} -
第二页的请求,使用第一页返回结果的最后一个数据的值,加上 search_after 字段来取下一页。注意:使用 search_after 的时候要将 from 置为 0 或 -1。
curl -XGET 127.0.0.1:9200/order/info/_search {"size": 10,"query": {"match_all" : {}},"search_after": [1463538857], # 这个值与上次查询最后一条数据的sort值一致,支持多个"sort": [{"date": "asc"}] }
注意:
- 如果 search_after 中的关键字为654,那么654323的文档也会被搜索到,所以在选择 search_after 的排序字段时需要谨慎,可以使用比如文档的id或者时间戳等。
- search_after 适用于深度分页+ 排序,因为每一页的数据依赖于上一页最后一条数据,所以无法跳页请求。
- 返回的始终是最新的数据,在分页过程中数据的位置可能会有变更。这种分页方式更加符合 moa 的业务场景。
相关文章:

Elasticsearch 使用scroll滚动技术实现大数据量搜索、深度分页问题 和 search
基于scroll滚动技术实现大数据量搜索 如果一次性要查出来比如10万条数据,那么性能会很差,此时一般会采取用scroll滚动查询,一批一批的查,直到所有数据都查询完为止。 scroll搜索会在第一次搜索的时候,保存一个当时的视…...

了解Swarm 集群管理
Swarm 集群管理 简介 Docker Swarm 是 Docker 的集群管理工具。它将 Docker 主机池转变为单个虚拟 Docker 主机。 Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。 支持的工具包括但不限…...

【Docker】Docker私有仓库的使用
目录 一、搭建私有仓库 二、上传镜像到私有仓库 三、从私有仓库拉取镜像 一、搭建私有仓库 首先我们需要拉取仓库的镜像 docker pull registry 然后创建私有仓库容器 docker run -it --namereg -p 5000:5000 registry 这个时候我们可以打开浏览器访问5000端口看是否成功&…...

基于arcFace+faiss开发构建人脸识别系统
在上一篇博文《基于facenetfaiss开发构建人脸识别系统》中,我们实践了基于facenet和faiss的人脸识别系统开发,基于facenet后续提出来很多新的改进的网络模型,arcFace就是其中一款优秀的网络模型,本文的整体开发实现流程与前文相同…...
命令模式(Command Pattern))
C#设计模式(15)命令模式(Command Pattern)
命令模式(Command Pattern) 命令模式是一种数据驱动的设计模式,属于行为型模式类别。请求被包装在一个对象中作为命令,并传递给调用对象。调用对象寻找可以处理该命令的合适对象,并将命令传递给相应的对象,…...
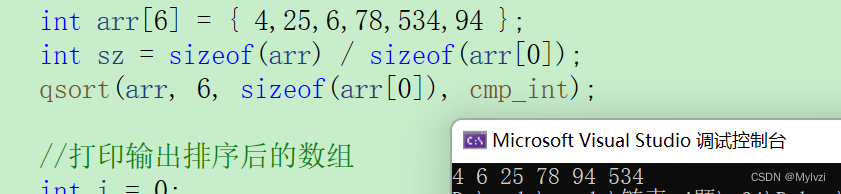
快速排序和qsort函数详解详解qsort函数
💕是非成败转头空,青山依旧在,几度夕阳红💕 作者:Mylvzi 文章主要内容:快速排序和qsort函数详解 前言: 我们之前学习过冒泡排序,冒泡排序尽管很方便,但也存在一些局限性…...

搭建 elasticsearch8.8.2 伪集群 windows
下载windows 版本 elasticsearch8.8.2 以下链接为es 历史版本下载地址: Past Releases of Elastic Stack Software | Elastic windows 单节点建立方案: 下载安装包 elasticsearch-8.8.2-windows-x86_64.zip https://artifacts.elastic.co/download…...
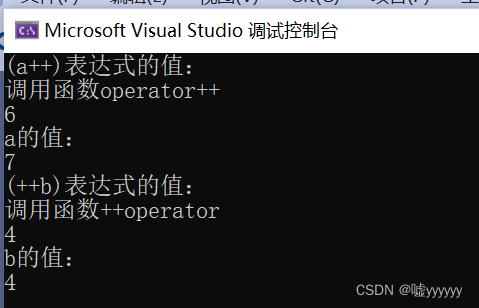
C++ 运算符重载为成员函数
运算符重载实质上就是函数重载,重载为成员函数,他就可以自由访问本类的数据成员。实际使用时,总是通过该类的某个对象来访问重载的运算符。 如果是双目运算符,左操作数是对象本身的数据,由this指针指出,右…...

51单片机程序烧录教程
STC烧录步骤 (1)STC单片机烧录方式采用串口进行烧录程序,连接的方式如下图: (2)所以需要先确保USB转串口驱动是识别到,且驱动运行正常;是否可通过电脑的设备管理器查看驱动是否正常…...

Linux C++ 链接数据库并对数据库进行一些简单的操作
一.引言(写在之前) 在我们进行网络业务代码书写的时候,我们总是避免对产生的数据进行增删改查,为此,本小博主在这里简历分享一下自己在Linux中C语言与数据之间交互的代码的入门介绍。 二.代码书写以及一些变量和函数的…...

Linux进程间通信--msgsnd函数的作用
msgsnd函数用于将消息发送到消息队列中。它的原型如下: int msgsnd(int msqid, const void *msgp, size_t msgsz, int msgflg); 参数解释: msqid:消息队列标识符,由msgget函数返回。msgp:指向要发送的消息的指针&…...

P1629 邮递员送信(最短路)(内附封面)
邮递员送信 题目描述 有一个邮递员要送东西,邮局在节点 1 1 1。他总共要送 n − 1 n-1 n−1 样东西,其目的地分别是节点 2 2 2 到节点 n n n。由于这个城市的交通比较繁忙,因此所有的道路都是单行的,共有 m m m 条道路。这…...
网络安全--原型链污染
目录 1.什么是原型链污染 2.原型链三属性 1)prototype 2)constructor 3)__proto__ 4)原型链三属性之间关系 3.JavaScript原型链继承 1)分析 2)总结 3)运行结果 4.原型链污染简单实验 1)实验一 2࿰…...
Harbor企业镜像仓库部署
目录 一、Harbor 架构构成 二、部署harbor环境 1、安装docker-ce(所有主机) 2、阿里云镜像加速器 3、部署Docker Compose 服务 4、部署 Harbor 服务 5、启动并安装 Harbor 6、创建一个新项目 三、客户端上传镜像 1、在 Docker 客户端配置操作如下…...
:分类问题-softmax回归)
【AI】《动手学-深度学习-PyTorch版》笔记(十一):分类问题-softmax回归
AI学习目录汇总 1、线性回归和softmax回归的区别 1)连续值与离散值 线性回归模型,适用于输出为连续值的情景。 softmax回归模型,适用于输出为离散值的情景。例如图像类别,就需要对离散值进行预测。softmax回归模型引入了softmax运算,使输出更适合离散值的预测和训练。 …...
(含代码)(完工于2023.8.3))
【排序算法略解】(十种排序的稳定性,时间复杂度以及实现思想)(含代码)(完工于2023.8.3)
文章目录 1、冒泡排序/选择排序/插入排序冒泡排序(Bubble Sort)选择排序(Selection Sort)插入排序(Insertion Sort) 2、希尔排序(Shells Sort)3、快速排序(Quick Sort)4、堆排序(Heap Sort)5、归并排序(Merge Sort)6、桶排序/计数排序/基数排序桶排序(Bucket sort)计数排序(Cou…...
学编程实用网站
牛客网:面试刷题和面试经验分享的网站牛客网 - 找工作神器|笔试题库|面试经验|实习招聘内推,求职就业一站解决_牛客网 (nowcoder.com)https://www.nowcoder.com/ 慕课网:在线学习 慕课网-程序员的梦工厂 (imooc.com)https://www.imooc.com/ …...

Camunda 7.x 系列【5】 员工请假流程模型
有道无术,术尚可求,有术无道,止于术。 本系列Spring Boot 版本 2.7.9 本系列Camunda 版本 7.19.0 源码地址:https://gitee.com/pearl-organization/camunda-study-demo 文章目录 1. 概述2. 模型设计2.1 基础配置2.2 启动事件2.3 填写请假单2.4 上级领导审批3.5 经理审批3…...
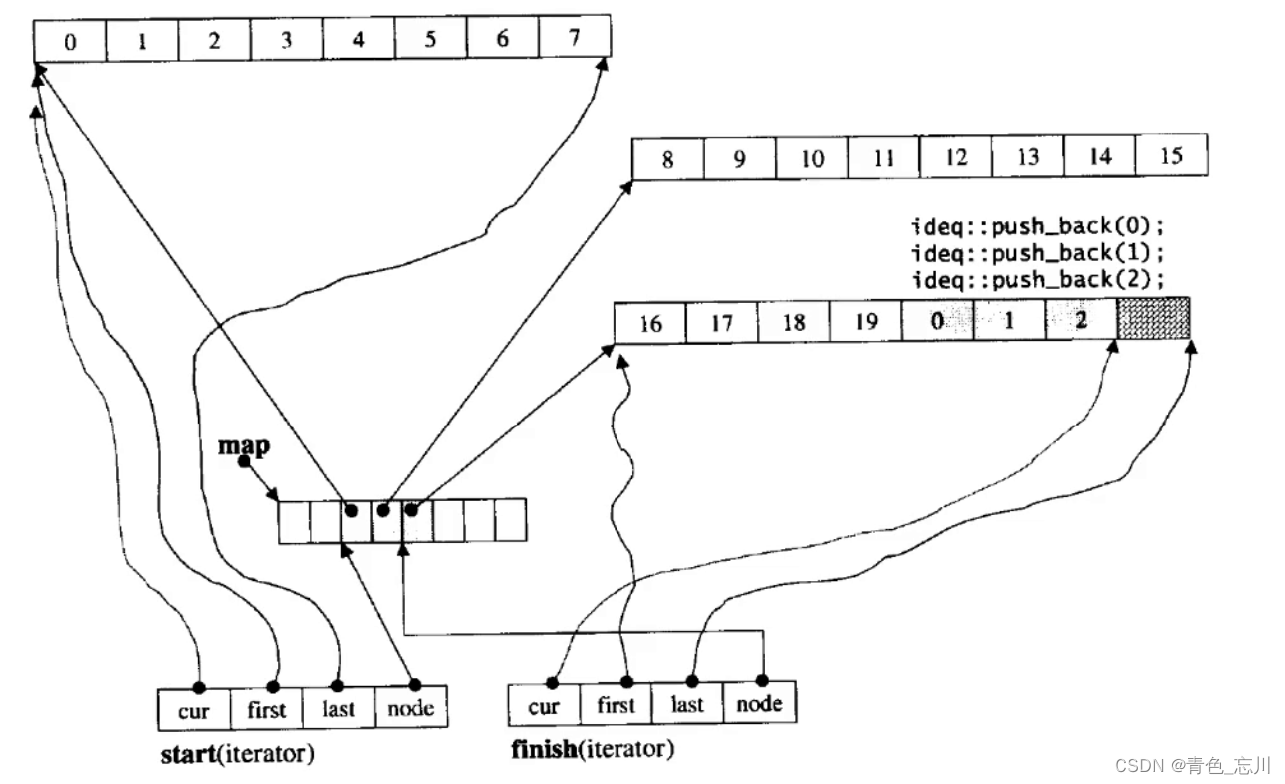
【C++从0到王者】第十七站:手把手教你写一个stack和queue及deque的底层原理
文章目录 一、stack1.利用适配器2.栈的实现 二、queue三、deque1.deque介绍2.deque的接口3.deque的基本使用4.deque的效率5.deque的原理 一、stack 1.利用适配器 我们不可能写了一份数组栈以后,还要在手写一个链式栈,这样显得太冗余了。于是我们可以利…...
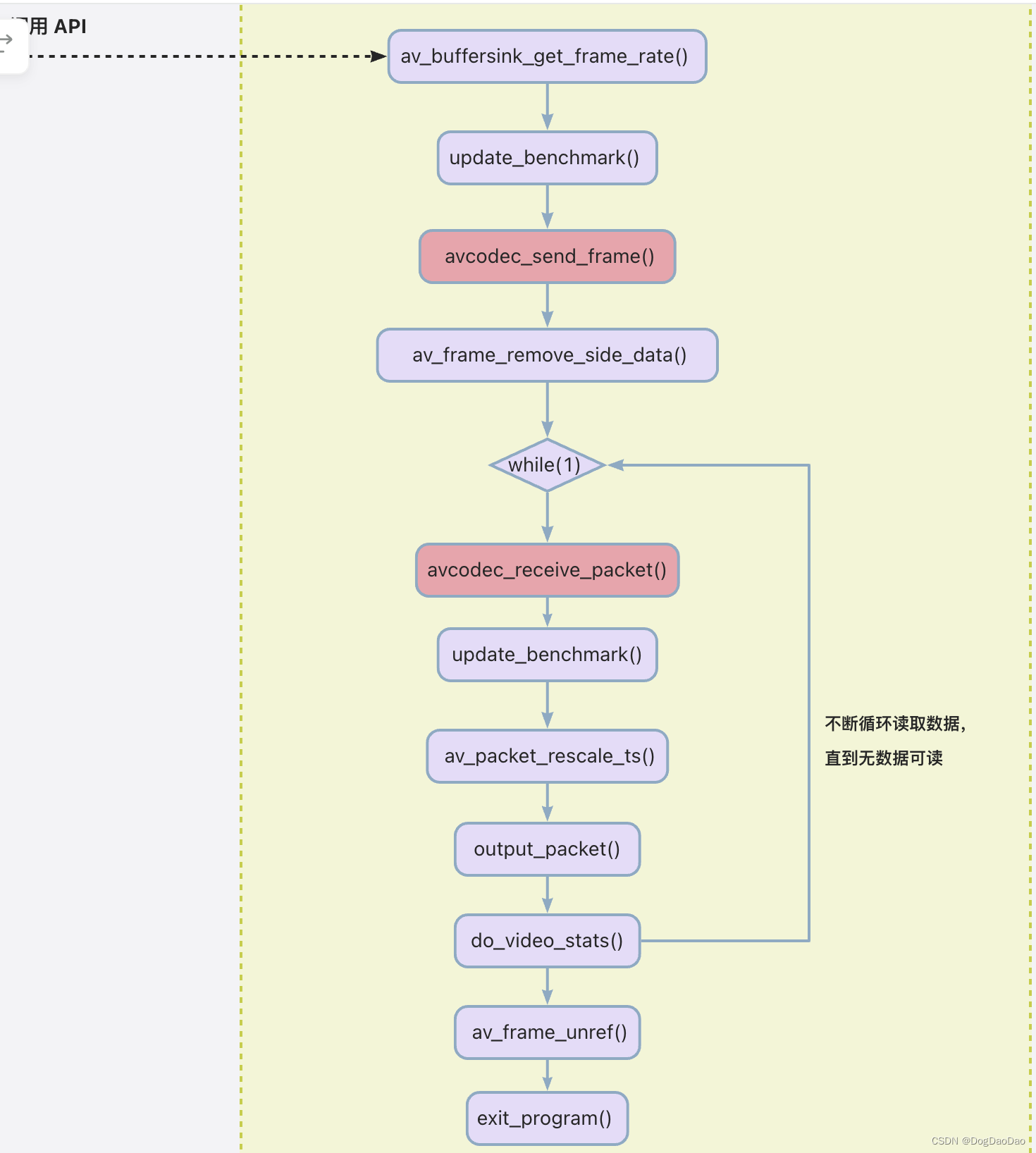
ffmpeg.c源码与函数关系分析
介绍 FFmpeg 是一个可以处理音视频的软件,功能非常强大,主要包括,编解码转换,封装格式转换,滤镜特效。FFmpeg支持各种网络协议,支持 RTMP ,RTSP,HLS 等高层协议的推拉流,…...

抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践
抖音数字资产管理方法论:构建个人内容沉淀系统的技术实践 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback su…...
)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)
双系统Ubuntu磁盘告急?别重装!用GParted无损扩容保姆级教程(附U盘启动盘制作)当你在Windows和Ubuntu双系统环境下工作时,是否遇到过这样的窘境:当初安装时给Ubuntu分配的空间捉襟见肘,而Windows…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

3大技术突破:重新定义Switch游戏安装性能极限
3大技术突破:重新定义Switch游戏安装性能极限 【免费下载链接】Awoo-Installer A No-Bullshit NSP, NSZ, XCI, and XCZ Installer for Nintendo Switch 项目地址: https://gitcode.com/gh_mirrors/aw/Awoo-Installer Awoo Installer是一款专为破解版Nintendo…...

星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南
星露谷物语SMAPI模组加载器:从新手到专家的完整使用指南 【免费下载链接】SMAPI The modding API for Stardew Valley. 项目地址: https://gitcode.com/gh_mirrors/smap/SMAPI 星露谷物语SMAPI模组加载器是官方推荐的模组API,它为玩家和开发者提供…...

Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题
Hitboxer:终极SOCD按键重映射解决方案,彻底解决游戏按键冲突问题 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 在激烈的游戏对战中,你是否曾因同时按下左右方向键而导致角色…...

3分钟快速上手:bilibili-parse视频解析API终极指南
3分钟快速上手:bilibili-parse视频解析API终极指南 【免费下载链接】bilibili-parse bilibili Video API 项目地址: https://gitcode.com/gh_mirrors/bi/bilibili-parse bilibili-parse是一款高效专业的B站视频解析工具,为开发者和内容创作者提供…...

为什么你的辉光总像P图?——拆解Adobe Stock Top 10辉光作品的MJ底层prompt结构,含--v 6.2专属glow injection指令
更多请点击: https://intelliparadigm.com 第一章:辉光效果的视觉认知误区与本质解构 辉光(Glow)常被误认为是“发光物体自身辐射出的光”,实则是一种典型的后处理视觉错觉——它不改变光源物理属性,也不增…...

Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑
Avidemux视频编辑工具终极指南:5个简单步骤快速上手专业剪辑 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 你是否曾经因为复杂的视频编辑软件而头疼?想要一个免费、开源且…...