4、数据清洗
4、数据清洗
前面我们处理的数据实际上都是已经被处理好的规整数据,但是在大数据整个生产过程中,需要先对数据进行数据清洗,将杂乱无章的数据整理为符合后面处理要求的规整数据。
数据去重
'''
1.删除重复数据groupby().count():可以看到数据的重复情况
'''
df = spark.createDataFrame([(1, 144.5, 5.9, 33, 'M'),(2, 167.2, 5.4, 45, 'M'),(3, 124.1, 5.2, 23, 'F'),(4, 144.5, 5.9, 33, 'M'),(5, 133.2, 5.7, 54, 'F'),(3, 124.1, 5.2, 23, 'F'),(5, 129.2, 5.3, 42, 'M'),
], ['id', 'weight', 'height', 'age', 'gender'])# 查看重复记录
#无意义重复数据去重:数据中行与行完全重复
# 1.首先删除完全一样的记录
df2 = df.dropDuplicates()#有意义去重:删除除去无意义字段之外的完全重复的行数据
# 2.其次,关键字段值完全一模一样的记录(在这个例子中,是指除了id之外的列一模一样)
# 删除某些字段值完全一样的重复记录,subset参数定义这些字段
df3 = df2.dropDuplicates(subset = [c for c in df2.columns if c!='id'])
# 3.有意义的重复记录去重之后,再看某个无意义字段的值是否有重复(在这个例子中,是看id是否重复)
# 查看某一列是否有重复值
import pyspark.sql.functions as fn
df3.agg(fn.count('id').alias('id_count'),fn.countDistinct('id').alias('distinct_id_count')).collect()
# 4.对于id这种无意义的列重复,添加另外一列自增iddf3.withColumn('new_id',fn.monotonically_increasing_id()).show()
缺失值处理
'''
2.处理缺失值
2.1 对缺失值进行删除操作(行,列)
2.2 对缺失值进行填充操作(列的均值)
2.3 对缺失值对应的行或列进行标记
'''
df_miss = spark.createDataFrame([
(1, 143.5, 5.6, 28,'M', 100000),
(2, 167.2, 5.4, 45,'M', None),
(3, None , 5.2, None, None, None),
(4, 144.5, 5.9, 33, 'M', None),
(5, 133.2, 5.7, 54, 'F', None),
(6, 124.1, 5.2, None, 'F', None),
(7, 129.2, 5.3, 42, 'M', 76000),],['id', 'weight', 'height', 'age', 'gender', 'income'])# 1.计算每条记录的缺失值情况df_miss.rdd.map(lambda row:(row['id'],sum([c==None for c in row]))).collect()
[(1, 0), (2, 1), (3, 4), (4, 1), (5, 1), (6, 2), (7, 0)]# 2.计算各列的缺失情况百分比
df_miss.agg(*[(1 - (fn.count(c) / fn.count('*'))).alias(c + '_missing') for c in df_miss.columns]).show()# 3、删除缺失值过于严重的列
# 其实是先建一个DF,不要缺失值的列
df_miss_no_income = df_miss.select([
c for c in df_miss.columns if c != 'income'
])# 4、按照缺失值删除行(threshold是根据一行记录中,缺失字段的百分比的定义)
df_miss_no_income.dropna(thresh=3).show()# 5、填充缺失值,可以用fillna来填充缺失值,
# 对于bool类型、或者分类类型,可以为缺失值单独设置一个类型,missing
# 对于数值类型,可以用均值或者中位数等填充# fillna可以接收两种类型的参数:
# 一个数字、字符串,这时整个DataSet中所有的缺失值都会被填充为相同的值。
# 也可以接收一个字典{列名:值}这样# 先计算均值,并组织成一个字典
means = df_miss_no_income.agg( *[fn.mean(c).alias(c) for c in df_miss_no_income.columns if c != 'gender']).toPandas().to_dict('records')[0]
# 然后添加其它的列
means['gender'] = 'missing'df_miss_no_income.fillna(means).show()
异常值处理
'''
3、异常值处理
异常值:不属于正常的值 包含:缺失值,超过正常范围内的较大值或较小值
分位数去极值
中位数绝对偏差去极值
正态分布去极值
上述三种操作的核心都是:通过原始数据设定一个正常的范围,超过此范围的就是一个异常值
'''
df_outliers = spark.createDataFrame([
(1, 143.5, 5.3, 28),
(2, 154.2, 5.5, 45),
(3, 342.3, 5.1, 99),
(4, 144.5, 5.5, 33),
(5, 133.2, 5.4, 54),
(6, 124.1, 5.1, 21),
(7, 129.2, 5.3, 42),
], ['id', 'weight', 'height', 'age'])
# 设定范围 超出这个范围的 用边界值替换# approxQuantile方法接收三个参数:参数1,列名;参数2:想要计算的分位点,可以是一个点,也可以是一个列表(0和1之间的小数),第三个参数是能容忍的误差,如果是0,代表百分百精确计算。cols = ['weight', 'height', 'age']bounds = {}
for col in cols:quantiles = df_outliers.approxQuantile(col, [0.25, 0.75], 0.05)IQR = quantiles[1] - quantiles[0]bounds[col] = [quantiles[0] - 1.5 * IQR,quantiles[1] + 1.5 * IQR]>>> bounds
{'age': [-11.0, 93.0], 'height': [4.499999999999999, 6.1000000000000005], 'weight': [91.69999999999999, 191.7]}# 为异常值字段打标志
outliers = df_outliers.select(*['id'] + [( (df_outliers[c] < bounds[c][0]) | (df_outliers[c] > bounds[c][1]) ).alias(c + '_o') for c in cols ])
outliers.show()
#
# +---+--------+--------+-----+
# | id|weight_o|height_o|age_o|
# +---+--------+--------+-----+
# | 1| false| false|false|
# | 2| false| false|false|
# | 3| true| false| true|
# | 4| false| false|false|
# | 5| false| false|false|
# | 6| false| false|false|
# | 7| false| false|false|
# +---+--------+--------+-----+# 再回头看看这些异常值的值,重新和原始数据关联df_outliers = df_outliers.join(outliers, on='id')
df_outliers.filter('weight_o').select('id', 'weight').show()
# +---+------+
# | id|weight|
# +---+------+
# | 3| 342.3|
# +---+------+df_outliers.filter('age_o').select('id', 'age').show()
# +---+---+
# | id|age|
# +---+---+
# | 3| 99|
# +---+---+
相关文章:

4、数据清洗
4、数据清洗 前面我们处理的数据实际上都是已经被处理好的规整数据,但是在大数据整个生产过程中,需要先对数据进行数据清洗,将杂乱无章的数据整理为符合后面处理要求的规整数据。 数据去重 1.删除重复数据groupby().count():可以…...

Python-OpenCV 图像的基础操作
图像的基础操作 获取图像的像素值并修改获取图像的属性信息图像的ROI区域图像通道的拆分及合并图像扩边填充图像上的算术运算图像的加法图像的混合图像的位运算 获取图像的像素值并修改 首先读入一副图像: import numpy as np import cv2# 1.获取并修改像素值 # 读…...

test111
step3:多线程task 首先,实现两个UserService和AsyncUserService两个服务接口: package com.example.demospringboot.service;public interface UserService {void checkUserStatus(); }package com.example.demospringboot.service.impl;im…...
17. Spring 事务
目录 1. 事务定义 2. MySQL 中的事务使用 3. 没有事务时的插入 4. Spring 编程式事务 5. Spring 声明式事务 5.1 Transactional 作用范围 5.2 Transactional 参数说明 5.3 Transactional 工作原理 1. 事务定义 将⼀组操作封装成一个执行单元(封装到一起…...

【C# 基础精讲】运算符和表达式
在C#编程中,运算符和表达式是构建复杂逻辑的关键元素。运算符用于执行各种数学、逻辑和其他操作,而表达式则由运算符、变量、常量和函数组成,用于生成计算结果。本文将详细介绍C#中常见的运算符和表达式的概念,以及它们在程序中的…...

【搜索】DFS连通性模型
算法提高课笔记 目录 迷宫题意思路代码 红与黑题意思路代码 DFS 的搜索分为两大部分: 内部搜索:一个图中从一个点搜到另一个点外部搜索:从一张图(状态)搜到另一张图(状态) 在第一个部分里是图…...

项目优化后续 ,手撸一个精简版VUE项目框架!
之前说过项目之前用的vben框架,在优化完性能后打包效果由原来的纯代码96M变成了56M,后续来啦,通过更换框架,代码压缩到了36M撒花~ 现在就来详细说说是怎么手撸一个框架的! 方案: 搭建一套 vite vue3 a…...
【深度学习笔记】TensorFlow 基础
在 TensorFlow 2.0 及之后的版本中,默认采用 Eager Execution 的方式,不再使用 1.0 版本的 Session 创建会话。Eager Execution 使用更自然地方式组织代码,无需构建计算图,可以立即进行数学计算,简化了代码调试的过程。…...

面试题-springcloud中的负载均衡是如何实现的?
一句话导读 Springcloud中的负载均衡是通过Ribbon实现的,自带有很多负载均衡策略,如:包括轮询(Round Robin)、随机(Random)、加权轮询(Weighted Round Robin)、加权随机&…...

flink的ProcessWindowFunction函数的三种状态
背景 在处理窗口函数时,ProcessWindowFunction处理函数可以定义三个状态: 富函数getRuntimeContext.getState, 每个key每个窗口的状态context.windowState(),每个key的状态context.globalState,那么这几个状态之间有什么关系呢? …...
day50-springboot+ajax分页
分页依赖: <dependency> <groupId>com.github.pagehelper</groupId> <artifactId>pagehelper-spring-boot-starter</artifactId> <version>1.0.0</version> </dependency> 配置: …...
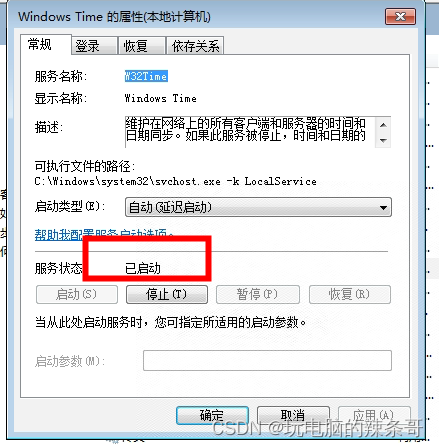
Win7 专业版Windows time w32time服务电脑重启后老是已停止
环境: Win7 专业版 问题描述: Win7 专业版Windows time w32time服务电脑重启后老是已停止 解决方案: 1.检查启动Remote Procedure Call (RPC)、Remote Procedure Call (RPC) Locator,DCOM Server Process Launcher这三个服务是…...
全网最强,接口自动化测试-token登录关联实战总结(超详细)
目录:导读 前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜) 前言 在PC端登录公司的…...
OLAP ModelKit Crack,ADO.NET和IList
OLAP ModelKit Crack,ADO.NET和IList OLAP ModelKit是一个多功能的.NET OLAP组件,用C#编写,只包含100%托管代码。它具有XP主题的外观,并能够使用任何.NET数据源(ADO.NET和IList)。借助任何第三方组件(尤其是图表组件)呈现数据的能力扩展了产品…...
4 三组例子,用OpenCV玩转图像-AI-python
读取,缩放,旋转,写入图像 首先导入包,为了显示导入matplotlib/为了在matplotlib显示 导入CV2/查看版本 导入图片/查看图片类型 图片数组 数组大小 对于opencv通道顺序蓝色B、绿色G、红色R matplotlib通道顺序为 红色R、绿色G、蓝…...

计算机网络-三种交换方式
计算机网络-三种交换方式 电路交换(Circuit Switching) 电话交换机接通电话线的方式称为电路交换从通信资源分配的角度来看,交换(Switching)就是按照某种方式动态的分配传输线路的资源 电话交换机 为了解决电话之间通信两两之间连线过多,所以产生了电话…...
03 制作Ubuntu启动盘
1 软碟通 我是用软碟通制作启动盘。安装软碟通时一定要把虚拟光驱给勾选上,其余两个可以看你心情。 2 镜像文件 我使用清华镜像网站找到的Ubuntu镜像文件。 Index of /ubuntu-releases/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 请自己选择镜像…...

【JavaSE】String类中常用的字符串方法(超全)
目录 1.求字符串的长度 2.判断字符串是否为空 3.String对象的比较 3.1 判断字符串是否相同 3.2 比较字符串大小 3.3 忽略大小写比较 4.字符串查找 5.转化 5.1 数值和字符串转化 5.1.1 数字转字符串 valueof 5.1.2 valueOf的其他用法 5.1.3 字符串转数字 5.2 大小写转…...
Bootload U-Boot分析
Bootloader是在操作系统运行之前执行的一段小程序。通过这段小程序可以初始化硬件设备、建立内存空间的映射表,从而建立适当的系统软硬件环境,为最终调用操作系统内核做好准备。 对于嵌入式系统,Bootloader是基于特定硬件平台来实现的。因此…...

以公益之行,筑责任之心——2023年中创算力爱心公益助学活动
捐资助学是一项功在当代、利在千秋的义举。 高考录取工作已经开始,一张张高校录取通知书也陆续送达各位准大学生手中。当他们怀揣着对大学的好奇与憧憬,准备迈进理想的大学时,还有一群人,他们渴望知识,却因经济困难而…...
)
别再乱用npm install了!手把手教你用npx only-allow为项目指定包管理器(支持pnpm/yarn/npm)
用only-allow统一团队包管理器:从配置到CI的全流程指南 你是否曾经在拉取一个新项目后,面对npm install、yarn还是pnpm i的抉择感到困惑?或者更糟的是,团队成员混用不同包管理器导致node_modules结构不一致,引发各种诡…...

告别手写UI!用NXP GUI Guider拖拽设计LVGL界面,5分钟搞定音乐播放器Demo
嵌入式UI开发革命:5分钟用GUI Guider构建LVGL音乐播放器在嵌入式系统开发中,用户界面(UI)设计曾长期是工程师的痛点——既要考虑资源受限的硬件环境,又要实现流畅美观的交互体验。传统手动编写UI代码的方式不仅效率低下,调试过程更…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

告别浪费!SolidWorks企业级共享方案,实现降本增效全攻略
还在为 SolidWorks 高昂的硬件投入和混乱的图纸管理头疼?告别“一人一机”的浪费模式,企业级共享方案才是降本增效的正解。这套攻略基于“1 台高性能服务器 云飞云共享云桌面”架构,帮你把硬件成本砍掉 60%,把软件利用率翻倍。一…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

LaTeX公式一键转Word:3步告别数学公式编辑烦恼
LaTeX公式一键转Word:3步告别数学公式编辑烦恼 【免费下载链接】LaTeX2Word-Equation Copy LaTeX Equations as Word Equations, a Chrome Extension 项目地址: https://gitcode.com/gh_mirrors/la/LaTeX2Word-Equation 还在为Word文档中的数学公式编辑而抓狂…...

十年以上经验的建站公司推荐|策划强、落地稳的网站制作公司盘点
互联网时代,企业官网已从单纯的信息展示窗口升级为集品牌价值传递、用户体验连接与业务高效转化于一体的核心数字阵地。行业报告显示,优质官网可帮助企业线上转化率提升35%-60%,而低效官网则可能导致潜在客户大量流失。面对市场上众多的网站建…...

纯硬件实现I2C协议:从逻辑门到传感器通信的深度实践
1. 项目概述:用纯硬件“解剖”I2C总线很多朋友在玩传感器,尤其是温湿度传感器时,都绕不开I2C这个通信协议。市面上绝大多数的教程和方案,都会告诉你:找个单片机(比如Arduino、STM32),…...

如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器
如何用Nucleus Co-Op让单机游戏变身本地多人分屏神器 【免费下载链接】nucleuscoop Starts multiple instances of a game for split-screen multiplayer gaming! 项目地址: https://gitcode.com/gh_mirrors/nu/nucleuscoop 还在为想和朋友一起玩游戏却只有一台电脑而烦…...
)
Lovable后端集成方案深度拆解(含Spring Boot 3.2+GraalVM+OpenTelemetry完整Demo)
更多请点击: https://kaifayun.com 第一章:Lovable后端集成方案全景概览 Lovable 是一个面向现代 Web 应用的轻量级后端协作框架,其核心设计理念是“可组合、可观测、可演进”。它不绑定特定语言或运行时,而是通过标准化协议与契…...