Reinforcement Learning with Code 【Code 4. DQN】
Reinforcement Learning with Code 【Code 4. DQN】
This note records how the author begin to learn RL. Both theoretical understanding and code practice are presented. Many material are referenced such as ZhaoShiyu’s Mathematical Foundation of Reinforcement Learning.
The code refers to Mofan’s reinforcement learning course and Hands on Reinforcement Learning.
文章目录
- Reinforcement Learning with Code 【Code 4. DQN】
- 1. Theoretical Basis
- 2. Gym Env
- 3. Implement DQN
- 4. Reference
1. Theoretical Basis
Readers can get some insight understanding from (Chapter 8. Value Function Approximation), which is omitted here.
这里还是简要介绍一下DQN的思想,就是用一个神经网络来近似值函数(value function),根据Q-learning的思想,我们已经使用 r + γ max a q ( s , a , w ) r+\gamma\max_a q(s,a,w) r+γmaxaq(s,a,w)来近似了真值,当我们使用神经网络来近似值函数时,我们用符号 q ^ \hat{q} q^来表示对q-value的近似。
则我们需要优化的目标函数是
min w J ( w ) = E [ ( R + γ max a ∈ A ( S ′ ) q ^ ( S ′ , a , w ) − q ^ ( S , A , w ) ) 2 ] {\min_w J(w) = \mathbb{E} \Big[ \Big( R+\gamma \max_{a\in\mathcal{A}(S^\prime)} \hat{q}(S^\prime, a, w) - \hat{q}(S,A,w) \Big)^2 \Big]} wminJ(w)=E[(R+γa∈A(S′)maxq^(S′,a,w)−q^(S,A,w))2]
详细的解释见下图,或则见(Chapter 8. Value Function Approximation)。

这里涉及到了两个技巧,第一个就是Experience replay,第二个技巧是Two Networks。
-
Experience replay: 主要是需要维护一个经验池,在一般的有监督学习中,假设训练数据是独立同分布的,我们每次训练神经网络的时候从训练数据中随机采样一个或若干个数据来进行梯度下降,随着学习的不断进行,每一个训练数据会被使用多次。在原来的 Q-learning 算法中,每一个数据只会用来更新一次值。为了更好地将 Q-learning 和深度神经网络结合,DQN 算法采用了经验回放(experience replay)方法,具体做法为维护一个回放缓冲区,将每次从环境中采样得到的四元组数据(状态、动作、奖励、下一状态)存储到回放缓冲区中,训练 Q 网络的时候再从回放缓冲区中随机采样若干数据来进行训练。这么做可以起到以下两个作用。
-
使样本满足独立假设。在 MDP 中交互采样得到的数据本身不满足独立假设,因为这一时刻的状态和上一时刻的状态有关。非独立同分布的数据对训练神经网络有很大的影响,会使神经网络拟合到最近训练的数据上。采用经验回放可以打破样本之间的相关性,让其满足独立假设。
-
提高样本效率。每一个样本可以被使用多次,十分适合深度神经网络的梯度学习。
-
-
Two Networks: DQN算法的最终更新目标是让 q ^ ( s , a , w ) \hat{q}(s,a,w) q^(s,a,w)逼近 r + γ max a q ^ ( s , a , w ) r+\gamma\max_a\hat{q}(s,a,w) r+γmaxaq^(s,a,w),由于 TD 误差目标本身就包含神经网络的输出,因此在更新网络参数的同时目标也在不断地改变,这非常容易造成神经网络训练的不稳定性。为了解决这一问题,DQN 便使用了目标网络(target network)的思想:既然训练过程中 Q 网络的不断更新会导致目标不断发生改变,不如暂时先将 TD 目标中的 Q 网络固定住。为了实现这一思想,我们需要利用两套 Q 网络。
- 原来的训练网络 q ^ ( s , a , w ) \hat{q}(s,a,w) q^(s,a,w),用于计算原来的损失函数 q ^ ( S , A , w ) \hat{q}(S,A,w) q^(S,A,w)中的项,并且使用正常梯度下降方法来进行更新。
- 目标网络的参数用 w T w^T wT来表示,训练网络参数用 w w w来表示,目标网络参数 w T w^T wT用于计算原先损失函数中的项。如果两套网络的参数随时保持一致,则仍为原先不够稳定的算法。为了让更新目标更稳定,目标网络并不会每一步都更新。具体而言,目标网络使用训练网络的一套较旧的参数,训练网络 q ^ ( s , a , w ) \hat{q}(s,a,w) q^(s,a,w)在训练中的每一步都会更新,而目标网络的参数每隔 C C C步才会与训练网络 w w w同步一次,即 w T ← w w^T\leftarrow w wT←w。这样做使得目标网络相对于训练网络更加稳定。而训练网络按照一下方式进行更新
w t + 1 = w t + α t [ r t + 1 + γ max a ∈ A ( s t + 1 ) q ^ ( s t + 1 , a , w T ) − q ^ ( s t , a t , w ) ] ∇ w q ^ ( s t , a t , w ) \textcolor{red}{w_{t+1} = w_{t} + \alpha_t \Big[ r_{t+1} + \gamma \max_{a\in\mathcal{A}(s_{t+1})} \hat{q}(s_{t+1},a,w_T) - \hat{q}(s_t,a_t,w) \Big] \nabla_w \hat{q}(s_t,a_t,w)} wt+1=wt+αt[rt+1+γa∈A(st+1)maxq^(st+1,a,wT)−q^(st,at,w)]∇wq^(st,at,w)
2. Gym Env
本文使用gym库中的CartPole-v1作为智能体的交互环境,其目的是左右移动小车,让小车上的木棍能够尽可能保持竖直。所以动作空间为离散值,只有向左 and 向右。但状态空间是连续的,则这种情况下不能使用tabular的表示方式。CartPole-v1的action_space和state_space的设置如下,详见gym官网
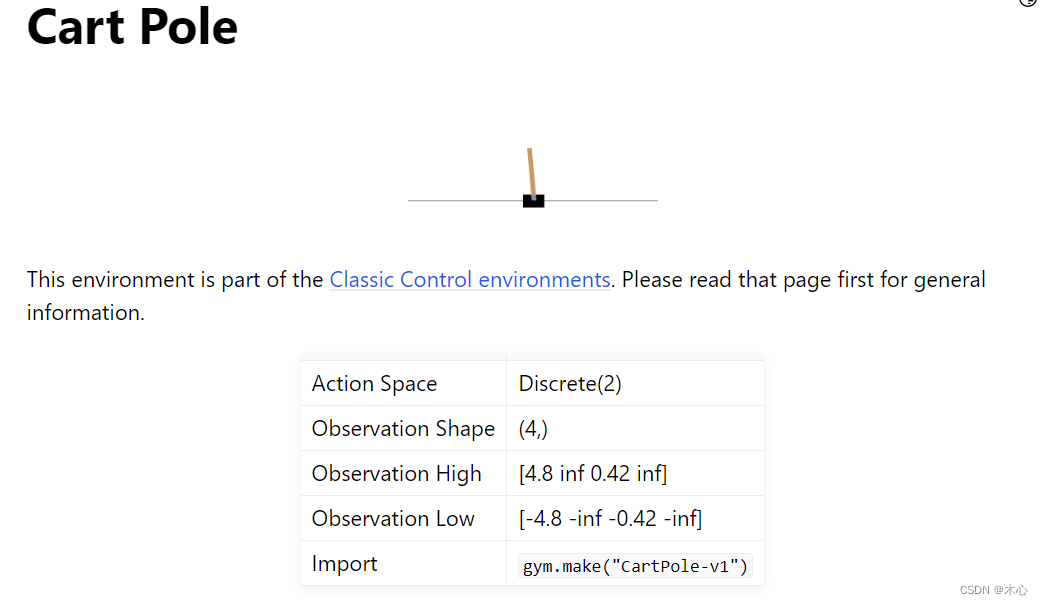
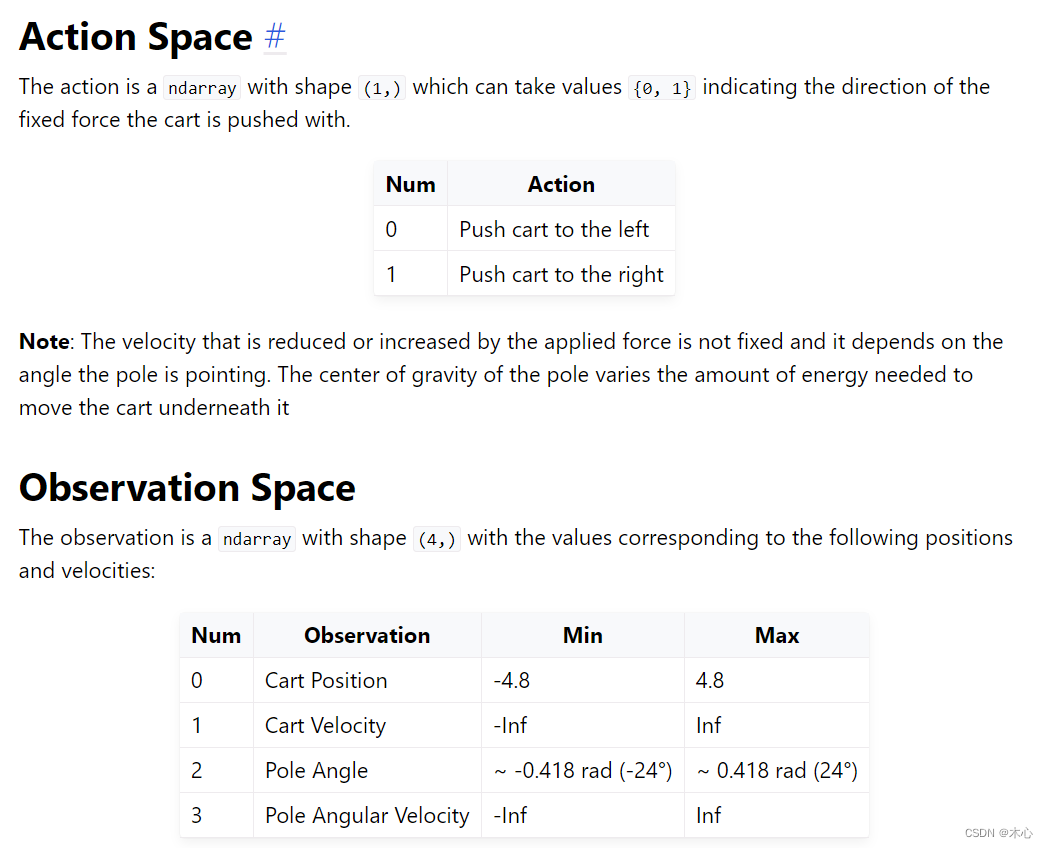
这个环境下,动作空间是离散的二维,状态空间是连续的4维,分别表示小车的位置,小车的速度,杆的角度,杆的角速度。
3. Implement DQN
rl_utils.py中实现了经验回放池。
import random
import numpy as np
import collectionsclass ReplayBuffer:def __init__(self, capacity):self.buffer = collections.deque(maxlen=capacity) # 使用collection中的队列数据结构作为容器def add(self, state, action, reward, next_state, done): #add experience# buffer中的每个experience都是以tuple的形式存在self.buffer.append((state, action, reward, next_state, done))def sample(self, batch_size): # sample batch_size itemtransition = random.sample(self.buffer, batch_size)states, actions, rewards, next_states, dones = zip(*transition)return np.array(states), actions, rewards, np.array(next_states), donesdef size(self): # 获得buffer的维护长度return len(self.buffer)
RL_brain.py中搭建了值函数,并且实现了DQN算法
from rl_utils import ReplayBuffer
import numpy as np
import torch
import torch.nn.functional as Fclass QNet(torch.nn.Module):# 仅包含一层隐藏层的Q value functiondef __init__(self, state_dim, hidden_dim, action_dim):super(QNet, self).__init__()self.fc1 = torch.nn.Linear(state_dim, hidden_dim)self.fc2 = torch.nn.Linear(hidden_dim, action_dim)def forward(self, x):x = F.relu(self.fc1(x))x = self.fc2(x)return xclass DQN():def __init__(self, state_dim, hidden_dim, action_dim, learning_rate, gamma, epsilon, target_update, device):self.action_dim = action_dimself.q_net = QNet(state_dim, hidden_dim, action_dim).to(device) # behavior net将计算转移到cuda上self.target_q_net = QNet(state_dim, hidden_dim, action_dim).to(device) # target netself.optimizer = torch.optim.Adam(self.q_net.parameters(), lr=learning_rate)self.target_update = target_update # 目标网络更新频率 self.gamma = gamma # 折扣因子self.epsilon = epsilon # epsilon-greedyself.count = 0 # record update timesself.device = device # devicedef choose_action(self, state): # epsilon-greedy# state is a list [x1, x2, x3, x4] if np.random.random() < self.epsilon:action = np.random.randint(self.action_dim) # 产生[0,action_dim)的随机数作为actionelse:state = torch.tensor([state], dtype=torch.float).to(self.device)action = self.q_net(state).argmax(dim=1).item()return actiondef learn(self, transition_dict):states = torch.tensor(transition_dict['states'], dtype=torch.float).to(self.device)next_states = torch.tensor(transition_dict['next_states'], dtype=torch.float).to(self.device)actions = torch.tensor(transition_dict['actions'], dtype=torch.int64).view(-1,1).to(self.device)rewards = torch.tensor(transition_dict['rewards'], dtype=torch.float).view(-1,1).to(self.device)dones = torch.tensor(transition_dict['dones'], dtype=torch.float).view(-1,1).to(self.device)q_values = self.q_net(states).gather(dim=1, index=actions)max_next_q_values = self.target_q_net(next_states).max(dim=1)[0].view(-1,1)q_target = rewards + self.gamma * max_next_q_values * (1 - dones) # TD targetdqn_loss = torch.mean(F.mse_loss(q_target, q_values)) # 均方误差损失函数self.optimizer.zero_grad()dqn_loss.backward()self.optimizer.step()# 一定周期后更新target network参数if self.count % self.target_update == 0:self.target_q_net.load_state_dict(self.q_net.state_dict())self.count += 1if __name__ == "__main__":# testqnet = QNet(4, 10, 2)print(qnet)run_dqn.py中实现了主函数即强化学习主循环,设置了超参数,并且绘制return曲线
from rl_utils import ReplayBuffer, moving_average
from RL_brain import DQN, QNet
from tqdm import tqdm
import matplotlib.pyplot as plt
import numpy as np
import random
import gym
import torch# super parameters
lr = 2e-3
num_episodes = 500
hidden_dim = 128 # number of hidden layers
gamma = 0.98 # discounted rate
epsilon = 0.01 # epsilon-greedy
target_update = 10 # per step to update target network
buffer_size = 10000 # maximum size of replay buffer
minimal_size = 500 # minimum size of replay buffer
batch_size = 64
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
render = False # render to screen
env_name = 'CartPole-v1'
if render:env = gym.make(id=env_name, render_mode='human')
else:env = gym.make(id=env_name)# env.seed(0)
random.seed(0)
np.random.seed(0)
torch.manual_seed(0)replaybuffer = ReplayBuffer(capacity=buffer_size)
state_dim = env.observation_space.shape[0]
action_dim = env.action_space.nagent = DQN(state_dim, hidden_dim, action_dim, lr, gamma, epsilon, target_update, device)return_list = []for i in range(10):with tqdm(total = int(num_episodes/10), desc='Iteration %d'%i) as pbar:for i_episode in range(int(num_episodes/10)):episode_return = 0state, _ = env.reset() # initial statedone = Falsewhile not done:if render:env.render()action = agent.choose_action(state)next_state, reward, terminated, truncated, _ = env.step(action)done = terminated or truncatedreplaybuffer.add(state, action, reward, next_state, done)state = next_stateepisode_return += rewardif replaybuffer.size() > minimal_size:b_s, b_a, b_r, b_ns, b_d = replaybuffer.sample(batch_size)transition_dict = {'states': b_s,'actions': b_a,'rewards': b_r,'next_states': b_ns,'dones': b_d}agent.learn(transition_dict)return_list.append(episode_return)if (i_episode + 1) % 10 == 0:pbar.set_postfix({'episode':'%d' % (num_episodes / 10 * i + i_episode + 1),'return':'%.3f' % np.mean(return_list[-10:])})pbar.update(1)
env.close()episodes_list = list(range(len(return_list)))
plt.plot(episodes_list, return_list)
plt.xlabel('Episodes')
plt.ylabel('Returns')
plt.title('DQN on {}'.format(env_name))
plt.show()
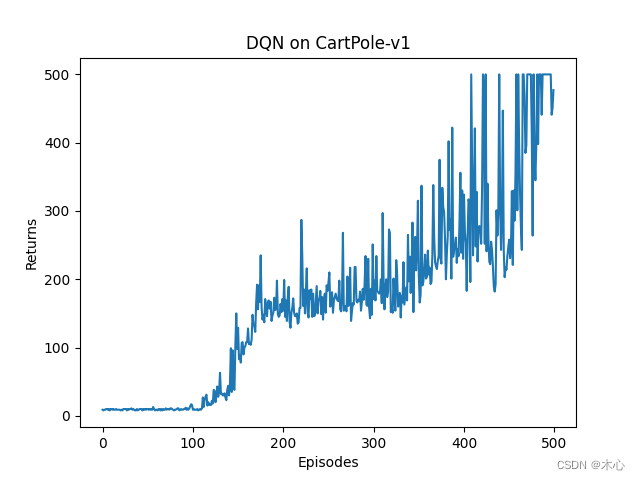
最终学习曲线如图所示
4. Reference
赵世钰老师的课程
莫烦ReinforcementLearning course
Chapter 8. Value Function Approximation
Hands on RL
相关文章:
Reinforcement Learning with Code 【Code 4. DQN】
Reinforcement Learning with Code 【Code 4. DQN】 This note records how the author begin to learn RL. Both theoretical understanding and code practice are presented. Many material are referenced such as ZhaoShiyu’s Mathematical Foundation of Reinforcement…...
)
Python3 高级教程 | Python3 正则表达式(一)
目录 一、Python3 正则表达式 (一)re.match函数 (二)re.search方法 (三)re.match与re.search的区别 二、检索和替换 (一)repl 参数是一个函数 (二)comp…...

奥威BI系统:零编程建模、开发报表,提升决策速度
奥威BI是一款非常实用的、易用、高效的商业智能工具,可以帮助企业快速获取数据、分析数据、展示数据。值得特别注意的一点是奥威BI系统支持零编程建模、开发报表,是一款人人都能用的大数据分析系统,有助于全面提升企业的数据分析挖掘效率&…...
海康威视摄像头二次开发_云台控制_视频画面实时预览(基于Qt实现)
一、项目背景 需求:需要在公司的产品里集成海康威视摄像头的SDK,用于控制海康威视的摄像头。 拍照抓图、视频录制、云台控制、视频实时预览等等功能。 开发环境: windows-X64(系统) + Qt5.12.6(Qt版本) + MSVC2017_X64(使用的编译器) 海康威视提供了设备网络SDK,设备网…...
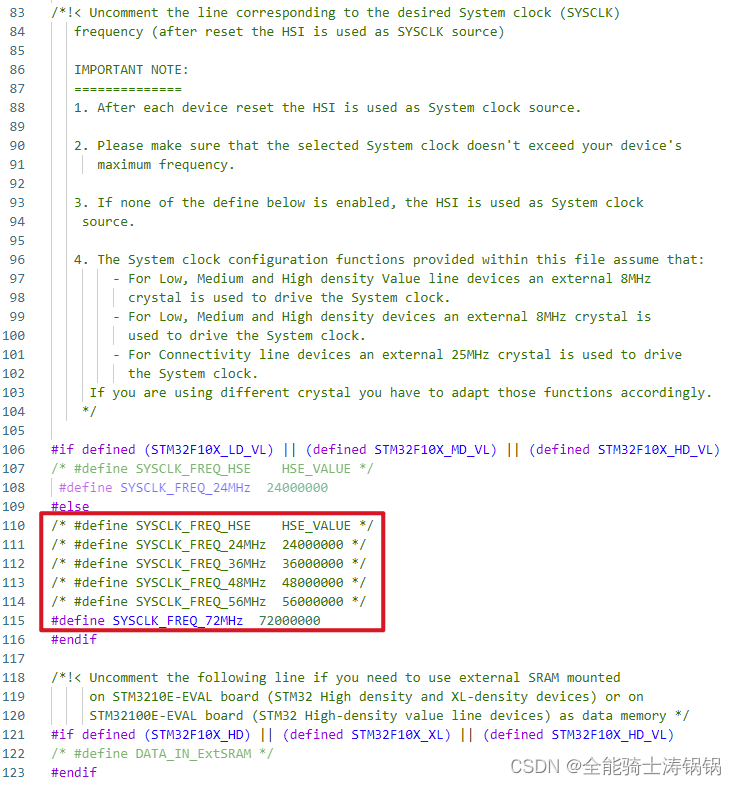
单片机外部晶振故障后自动切换内部晶振——以STM32为例
单片机外部晶振故障后自动切换内部晶振——以STM32为例 作者日期版本说明Dog Tao2023.08.02V1.0发布初始版本 文章目录 单片机外部晶振故障后自动切换内部晶振——以STM32为例背景外部晶振与内部振荡器STM32F103时钟系统STM32F407时钟系统 代码实现系统时钟设置流程时钟源检测…...
)
Matlab实现决策树算法(附上多个完整仿真源码)
决策树是一种常见的机器学习算法,它可以用于分类和回归问题。在本文中,我们将介绍如何使用Matlab实现决策树算法。 文章目录 1. 数据预处理2. 构建决策树模型3. 测试模型4. 可视化决策树5. 总结6. 完整仿真源码下载 1. 数据预处理 在使用决策树算法之前…...

java中异步socket类的实现和源代码
java中异步socket类的实现和源代码 我们知道,java中socket类一般操作都是同步进行,常常在read的时候socket就会阻塞直到有数据可读或socket连接断开的时候才返回,虽然可以设置超时返回,但是这样比较低效,需要做一个循环来不停扫描…...

ElasticSearch7.6入门学习笔记
在学习ElasticSearch之前,先简单了解一下Lucene: Doug Cutting开发 是apache软件基金会4 jakarta项目组的一个子项目 是一个开放源代码的全文检索引擎工具包不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的…...

《面试1v1》ElasticSearch架构设计
🍅 作者简介:王哥,CSDN2022博客总榜Top100🏆、博客专家💪 🍅 技术交流:定期更新Java硬核干货,不定期送书活动 🍅 王哥多年工作总结:Java学习路线总结…...

tomcat和nginx的日志记录请求时间
当系统卡顿时候,我们需要分析时间花费在哪个缓解。项目的后端接口可以记录一些时间,此外,在我们的tomcat容器和nginx网关上也可以记录一些有关请求用户,请求时间,响应时间的数据,可以提供更多的信息以便于排…...
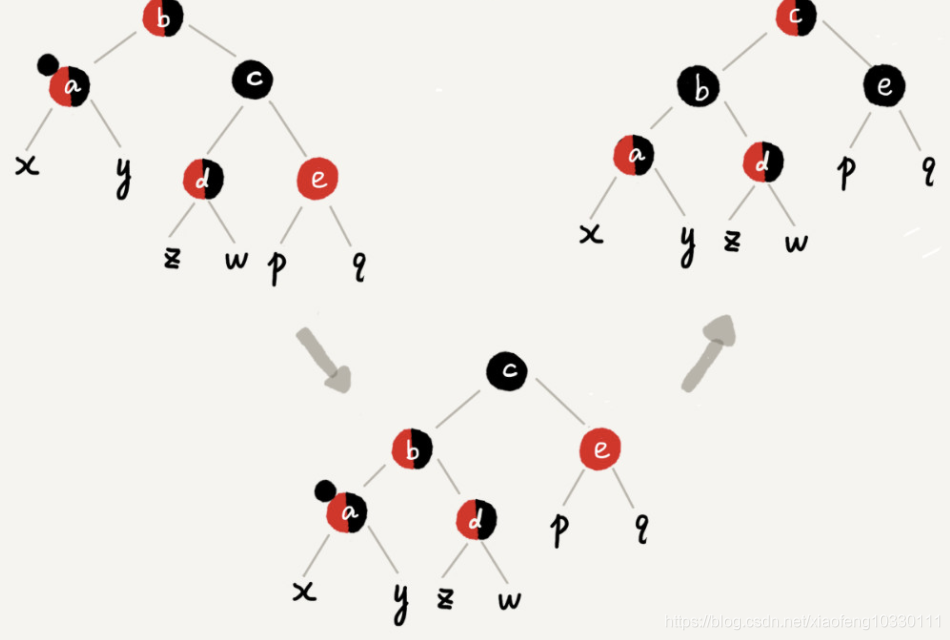
数据结构——红黑树基础(博文笔记)
数据结构在查找这一章里介绍过这些数据结构:BST,AVL,RBT,B和B。 除去RBT,其他的数据结构之前的学过,都是在BST的基础上进行微小的限制。 1.比如AVL是要求任意节点的左右子树深度之差绝对值不大于1,由此引出…...

盘点帮助中心系统可以帮到我们什么呢?
在线帮助中心系统是一种强大的软件系统,可以让我们用来组织、管理、发布、更新和维护企业的宝贵知识库和用户文档。今天looklook就详细讲讲,除了大众所熟知的这些,帮助中心系统还有什么特别作用呢? 帮助中心系统的作用 1.快速自助…...
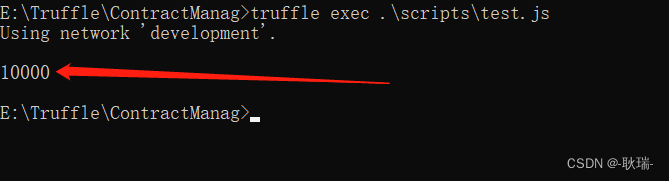
Web3 solidity编写交易所合约 编写ETH和自定义代币存入逻辑 并带着大家手动测试
上文 Web3 叙述交易所授权置换概念 编写transferFrom与approve函数我们写完一个简单授权交易所的逻辑 但是并没有测试 其实也不是我不想 主要是 交易所也没实例化 现在也测试不了 我们先运行 ganache 启动一个虚拟的区块链环境 先发布 在终端执行 truffle migrate如果你跟着我…...
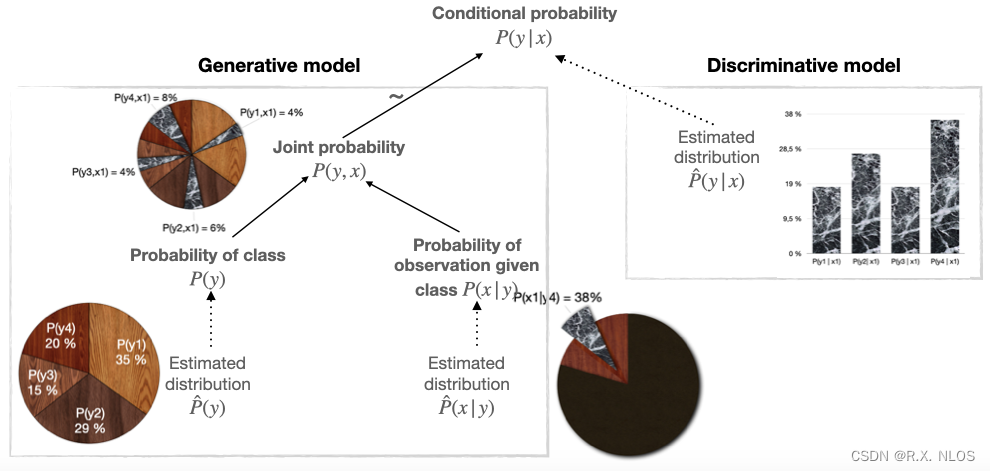
概念解析 | 生成式与判别式模型在低级图像恢复与点云重建中的角力:一场较量与可能性探索
注1:本文系“概念解析”系列之一,致力于简洁清晰地解释、辨析复杂而专业的概念。本次辨析的概念是:生成式模型与判别式模型在低级图像恢复/点云重建任务中的优劣与特性。 生成式与判别式模型在低级图像恢复与点云重建中的角力:一场较量与可能性探索 1. 背景介绍 机器学习…...
【云原生】kubectl命令的详解
目录 一、陈述式资源管理方式1.1基本查看命令查看版本信息查看资源对象简写查看集群信息配置kubectl自动补全node节点查看日志 1.3基本信息查看查看 master 节点状态查看命名空间查看default命名空间的所有资源创建命名空间app删除命名空间app在命名空间kube-public 创建副本控…...
uniapp两个单页面之间进行传参
1.单页面传参:A --> B url: .....?code JSON.stringify(param), 2.单页面传参B–>Auni.$emit() uni.$on()...

uniapp运行项目到iOS基座
2022年9月,因收到苹果公司警告,目前开发者已无法在iOS真机设备使用未签名的标准基座,所以现在要运行到 IOS ,也需要进行签名。 Windows系统,HBuilderX 3.6.20以下版本,无法像MacOSX那样对标准基座进行签名…...
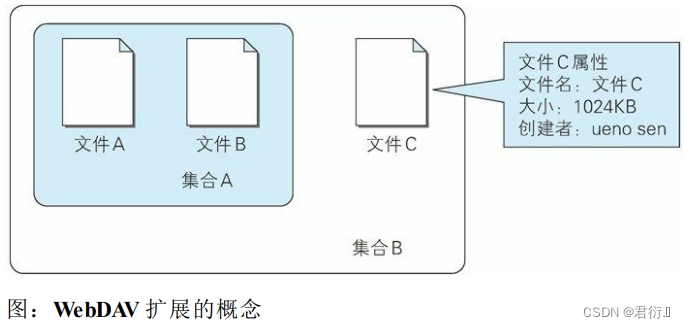
HTTP——九、基于HTTP的功能追加协议
HTTP 一、基于HTTP的协议二、消除HTTP瓶颈的SPDY1、HTTP的瓶颈Ajax 的解决方法Comet 的解决方法SPDY的目标 2、SPDY的设计与功能3、SPDY消除 Web 瓶颈了吗 三、使用浏览器进行全双工通信的WebSocket1、WebSocket 的设计与功能2、WebSocket协议 四、期盼已久的 HTTP/2.01、HTTP/…...

Redis 在电商秒杀场景中的应用
Redis 在电商秒杀场景中的应用 一、简介1.1 简介1.2 场景应用 二、Redis 优势与挑战2.1 优势2.2 秒杀场景的挑战 三、应用场景分析3.1 库存预热代码示例 3.2 分布式锁3.3 消息队列 四、系统设计方案4.1 架构设计4.2 技术选型4.3 数据结构设计 五、Redis 性能优化5.1 集群部署5.…...
大麦订单生成器 大麦一键生成订单
后台一键生成链接,独立后台管理 教程:修改数据库config/Conn.php 不会可以看源码里有教程 下载源码程序:https://pan.baidu.com/s/16lN3gvRIZm7pqhvVMYYecQ?pwd6zw3...

浅聊26上半年软考架构师
2026年上半年架构师考试已然落幕,大家都考的如何?架构师共有三门考试,上午综合知识(75道选择题)案例分析,时间为8.30-12.30;下午论文,时间为14.30-16.30。下面说说我整体的备考过程。…...

飞书远程控机:OpenClaw配置全攻略
本文详细介绍如何通过 OpenClaw 工具对接飞书开放平台,配置智能机器人实现 Windows 电脑的远程控制。主要内容涵盖文件管理和程序启动等核心功能的实现方法,并提供完整的配置指南与常见问题解决方案。 一、使用前提说明 1. 系统要求 仅适用于 Windows…...

2026年LLM推理加速全景:量化、投机解码与KV Cache工程实战
大语言模型推理速度慢、成本高,是阻碍AI大规模落地的核心障碍之一。一个7B参数的模型,在标准配置下每秒只能生成约30个token,对于需要实时响应的应用来说几乎无法接受。但2026年,一系列推理加速技术的成熟,让这一局面发…...

如何快速解锁中兴光猫权限:zteOnu工具完整使用指南
如何快速解锁中兴光猫权限:zteOnu工具完整使用指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 中兴光猫作为家庭网络的核心设备,其强大的硬件性能常常被默认…...

Unity项目DrawCall降不下来?试试用Mesh Baker合并贴图集,保姆级图文教程
Unity性能优化实战:用Mesh Baker合并贴图集降低DrawCall全流程解析当你的Unity项目帧率开始卡顿,Profiler里DrawCall数字居高不下时,合并贴图集往往是解决问题的关键一步。本文将以一个实际项目为例,带你从零开始使用Mesh Baker的…...

基于MAX78000与CNN的智能螺栓巡检小车:嵌入式AI实战解析
1. 项目概述与核心思路在轨道交通的日常运维中,螺栓的紧固状态检查是一项繁重且关键的任务。无论是轨道上的紧固螺栓,还是列车转向架、轮对轴承上的关键螺栓,其松动或失效都可能引发严重的安全事故。传统的人工巡检方式不仅效率低下ÿ…...

抖音内容批量下载实战:从零开始构建个人视频资料库
抖音内容批量下载实战:从零开始构建个人视频资料库 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback support.…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...

基于Arduino与蓝牙模块的六路无线开关控制系统设计与实现
1. 项目概述:用手机蓝牙控制六路LED想不想把手机变成一个无线遥控器,随手一点就能开关家里的灯带、氛围灯,甚至是其他电器?这个项目就是为你准备的。它基于一块功能增强的Arduino兼容板——GlowDuino Uno,配合一个极其…...

理想二极管控制器:用MOSFET实现毫伏级压降的电源管理方案
1. 理想二极管控制器:告别传统二极管的压降损耗 在电源设计、电池保护、太阳能板并联这些领域里,二极管是个再常见不过的元件。我们用它来防反接、做整流、实现“或”逻辑供电,几乎不假思索。但如果你设计过一个需要处理大电流、低电压的系统…...