Flume原理剖析
一、介绍
Flume是一个高可用、高可靠,分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。其中Flume-NG是Flume的一个分支,其目的是要明显简单,体积更小,更容易部署,其最基本的架构如下图所示:
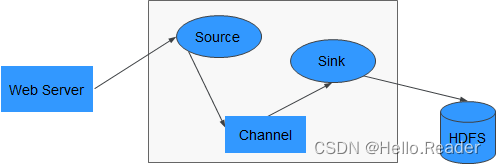
Flume-NG由一个个Agent来组成,而每个Agent由Source、Channel、Sink三个模块组成,其中Source负责接收数据,Channel负责数据的传输,Sink则负责数据向下一端的发送。
二、模块说明
| 名称 | 说明 |
|---|---|
| Source | Source负责接收数据或通过特殊机制产生数据,并将数据批量放到一个或多个Channel。Source的类型有数据驱动和轮询两种。典型的Source类型如下:1.和系统集成的Sources:Syslog、Netcat。2.自动生成事件的Sources:Exec、SEQ。3.用于Agent和Agent之间通信的IPC Sources:Avro。4.Source必须至少和一个Channel关联。 |
| Channel | Channel位于Source和Sink之间,用于缓存来自Source的数据,当Sink成功将数据发送到下一跳的Channel或最终目的地时,数据从Channel移除。Channel提供的持久化水平与Channel的类型相关,有以下三类:1.Memory Channel:非持久化。2.File Channel:基于WAL(预写式日志Write-Ahead Logging)的持久化实现。3.JDBC Channel:基于嵌入Database的持久化实现。Channel支持事务,可提供较弱的顺序保证,可以和任何数量的Source和Sink工作。 |
| Sink | Sink负责将数据传输到下一跳或最终目的,成功完成后将数据从Channel移除。典型的Sink类型如下:1.存储数据到最终目的终端Sink,比如:HDFS、HBase。2.自动消耗的Sink,比如:Null Sink。3.用于Agent间通信的IPC sink:Avro。Sink必须作用于一个确切的Channel。 |
Flume也可以配置成多个Source、Channel、Sink,如下图所示:
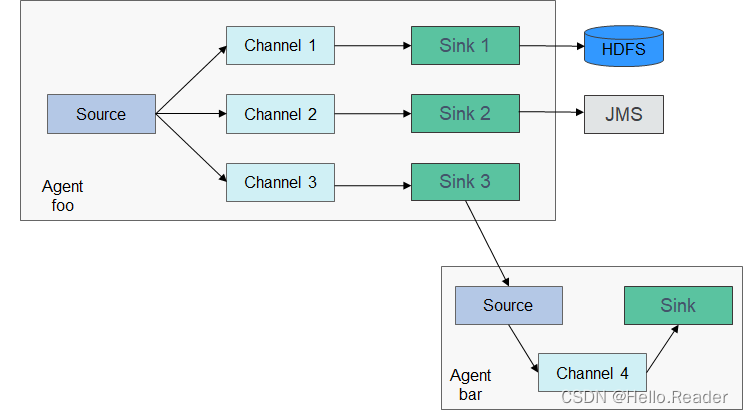 Flume的可靠性基于Agent间事务的交换,下一个Agent down掉,Channel可以持久化数据,Agent恢复后再传输。Flume的可用性则基于内建的Load Balancing和Failover机制。Channel及Agent都可以配多个实体,实体之间可以使用负载分担等策略。每个Agent为一个JVM进程,同一台服务器可以有多个Agent。收集节点(Agent1,2,3)负责处理日志,汇聚节点(Agent4)负责写入HDFS,每个收集节点的Agent可以选择多个汇聚节点,这样可以实现负载均衡。
Flume的可靠性基于Agent间事务的交换,下一个Agent down掉,Channel可以持久化数据,Agent恢复后再传输。Flume的可用性则基于内建的Load Balancing和Failover机制。Channel及Agent都可以配多个实体,实体之间可以使用负载分担等策略。每个Agent为一个JVM进程,同一台服务器可以有多个Agent。收集节点(Agent1,2,3)负责处理日志,汇聚节点(Agent4)负责写入HDFS,每个收集节点的Agent可以选择多个汇聚节点,这样可以实现负载均衡。
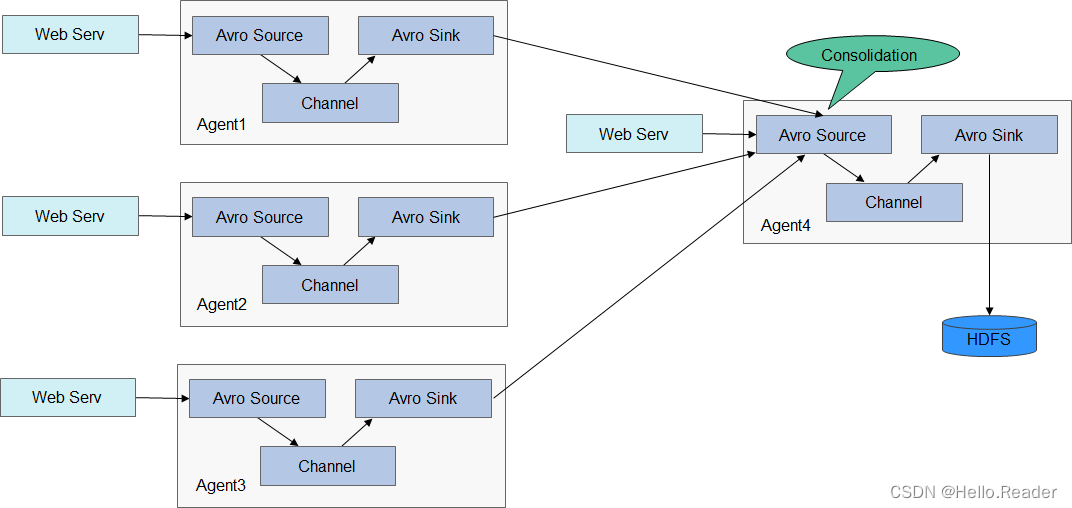
Flume的架构和详细原理介绍,请参见:https://flume.apache.org/releases/1.9.0.html。
三、Flume原理
Agent之间的可靠性
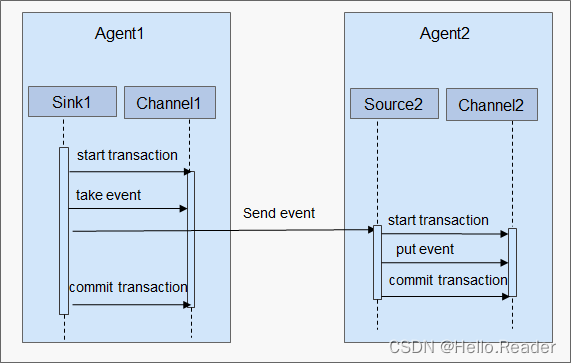
Agent之间数据交换流程如下图所示。
-
Flume采用基于Transactions的方式保证数据传输的可靠性,当数据从一个Agent流向另外一个Agent时,两个Transactions已经开始生效。发送Agent的Sink首先从Channel取出一条消息,并且将该消息发送给另外一个Agent。如果接受消息的Agent成功地接受并处理消息,那么发送Agent将会提交Transactions,标识一次数据传输成功可靠地完成。
-
当接收Agent接受到发送Agent发送的消息时,开始一个新的Transactions,当该数据被成功处理(写入Channel中),那么接收Agent提交该Transactions,并向发送Agent发送成功响应。
-
如果在某次提交(commit)之前,数据传输出现了失败,将会再次开始上一次Transactions,并将上次发送失败的数据重新传输。因为commit操作已经将Transactions写入了磁盘,那么在进程故障退出并恢复业务之后,仍然可以继续上次的Transactions。
四、Flume与HDFS的关系
当用户配置HDFS作为Flume的Sink时,HDFS就作为Flume的最终数据存储系统,Flume将传输的数据全部按照配置写入HDFS中。
五、Flume与HBase的关系
当用户配置HBase作为Flume的Sink时,HBase就作为Flume的最终数据存储系统,Flume将传输的数据全部按照配置写入HBase中。
相关文章:
Flume原理剖析
一、介绍 Flume是一个高可用、高可靠,分布式的海量日志采集、聚合和传输的系统。Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制&…...
)
【leetcode】202. 快乐数(easy)
编写一个算法来判断一个数 n 是不是快乐数。 「快乐数」 定义为: 对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和。然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果这个过程 结果为 1,…...
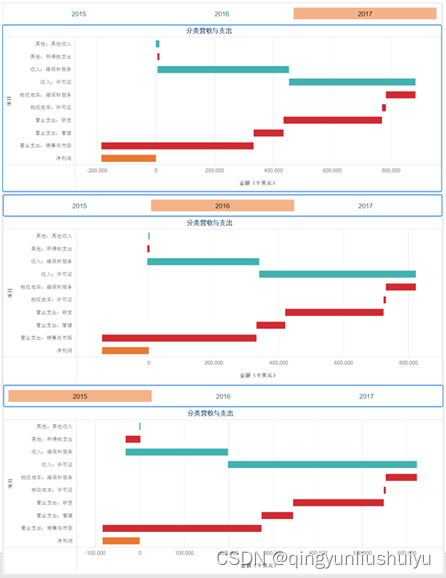
如何用瀑布图分析公司年报
原创: MicroStrategy微策略中国 , Jiping Sun 微策略企业级数据分析与移动应用9月21日2018年 摘要:利用达析报告开箱即用的瀑布图来展示各个度量值如何增加或减少。下载MicroStrategy Desktop 10.11以上版本,自己动手创建瀑布图。 瀑布图是由…...
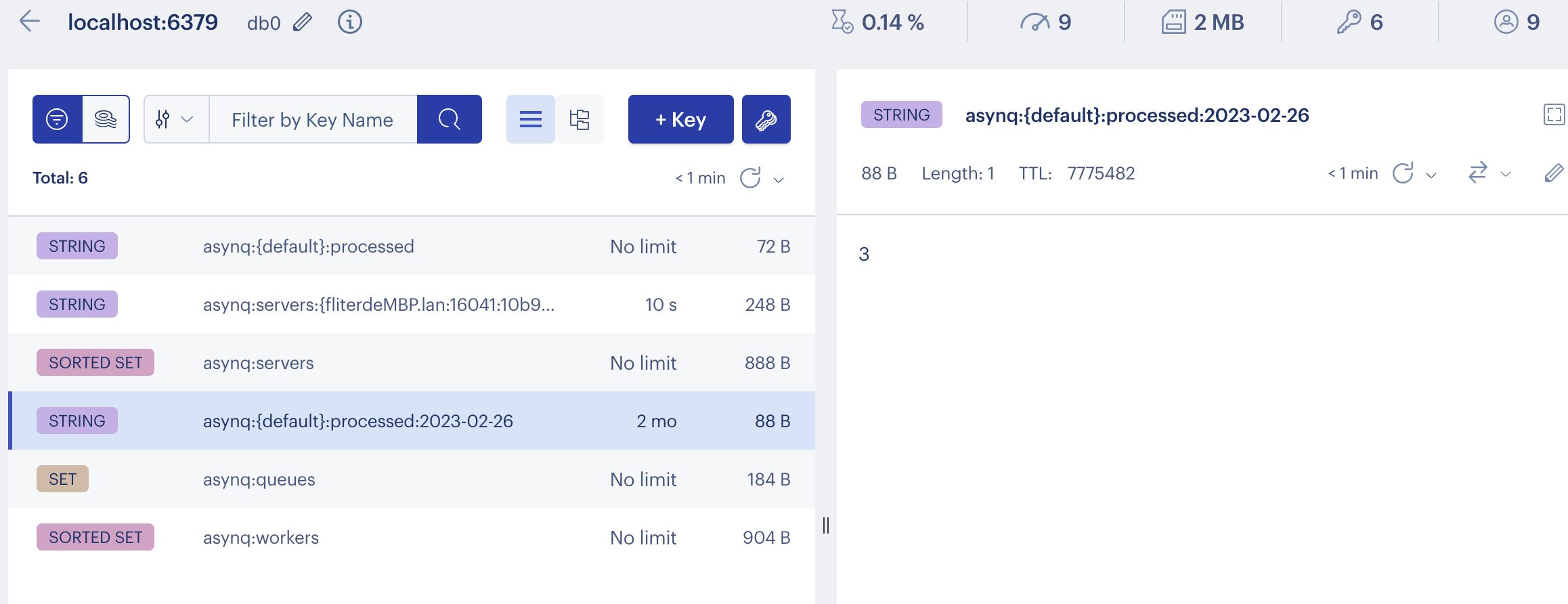
Asynq: 基于Redis实现的Go生态分布式任务队列和异步处理库
Asynq[1]是一个Go实现的分布式任务队列和异步处理库,基于redis,类似Ruby的sidekiq[2]和Python的celery[3]。Go生态类似的还有machinery[4]和goworker 同时提供一个WebUI asynqmon[5],可以源码形式安装或使用Docker image, 还可以和Prometheus…...

保证率计算公式 正态分布
在正态分布中,如果我们要计算一个给定区间内的保证率,可以使用下面的计算公式: 找到给定保证率对应的标准正态分布的z值。可以使用标准正态分布表或计算器进行查询。例如,对于95%的保证率,对应的z值为1.96。 使用z值和…...
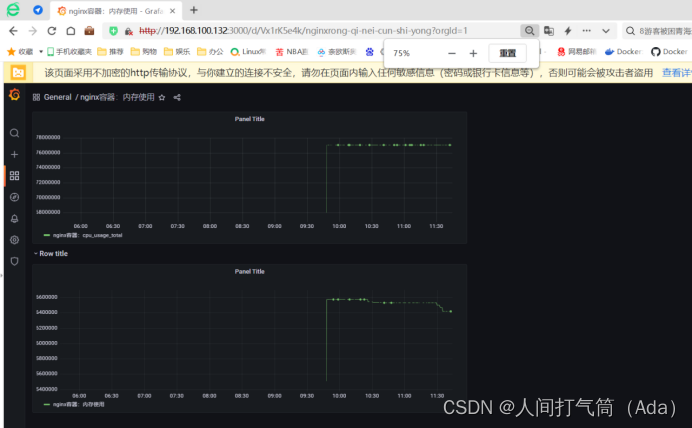
docker容器监控:Cadvisor+InfluxDB+Grafana的安装部署
目录 CadvisorInfluxDBGrafan安装部署 1、安装docker-ce 2、阿里云镜像加速器 3、下载组件镜像 4、创建自定义网络 5、创建influxdb容器 6、创建Cadvisor 容器 7、查看Cadvisor 容器: (1)准备测试镜像 (2)通…...

论文讲解——TPU-MLIR: A Compiler For TPU Using MLIR
论文讲解——TPU-MLIR: A Compiler For TPU Using MLIR https://arxiv.org/pdf/2210.15016.pdf概览模型转换TranslationCanonicalizeLoweringLayerGroup BufferizationCalibration QuantizationCorrectness Check相关资料 https://arxiv.org/pdf/2210.15016.pdf 本文将对TPU…...
基于最新导则下生态环评报告编制技术暨报告篇、制图篇、指数篇、综合应用篇系统性实践技能提升
查看原文>>>基于最新导则下生态环评报告编制技术暨报告篇、制图篇、指数篇、综合应用篇系统性实践技能提升 目录 专题一、生态环评报告编制规范 专题二、土地利用图 专题三、植被类型及植被覆盖度图 专题四、物种适宜生境分布图 专题五、生物多样性测定 专题六…...

NGZORRO:动态表单/模型驱动 的相关问题
官网的demo的[nzFor]"control.controlInstance",似乎是靠[formControlName]"control.controlInstance"来关联的。 <form nz-form [formGroup]"validateForm" (ngSubmit)"submitForm()"><nz-form-item *ngFor&quo…...

第十七次CCF计算机软件能力认证
第一题:小明种苹果 n , m map(int , input().split()) t , k , p 0 , 0 , -1 for _ in range(n):l list(map(int , input().split()))t sum(l)x -sum(l[i] for i in range(1 , len(l)))if x > p:p xk _ 1 print(t , k , p) 第二题:小明种苹…...

ApplicationContext在Spring Boot中是如何创建的?
一、ApplicationContext在Spring Boot中是如何创建的? 1. SpringApplication ApplicationContextFactory有三个实现类,分别是AnnotationConfigReactiveWebServerApplicationContext.Factory、AnnotationConfigServletWebServerApplicationContext.Facto…...
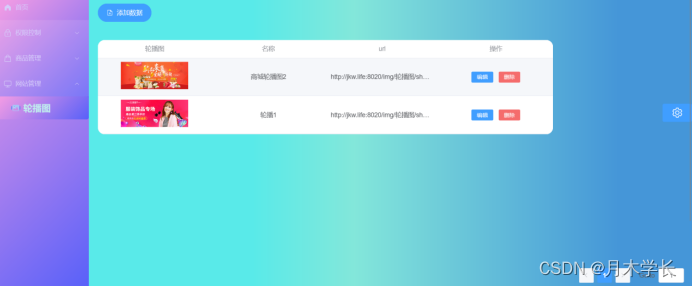
后端开发7.轮播图模块【mongdb开发】
概述 轮播图模块数据库采用mongdb开发 效果图 数据库设计 创建数据库 use sc; 添加数据 db.banner.insertMany([ {bannerId:"1",bannerName:"商城轮播图1",bannerUrl:"http://xx:8020/img/轮播图/shop1.png"}, {bannerId:"2"…...

Linux常用命令(一):创建文件目录
一、touch: 1、作用: 1). 改变已有文件的时间戳属性,修改文件时间戳时,用户必须的文件的属主,或者拥有写文件的权限 2). 创建新的空文件 2、语法: touch [option] 文件名 ,后面可跟多个文件名3、示例 …...

如何创建一个Vue组件?如何在父组件和子组件之间传递数据?如何在子组件中向父组件发送消息?
1、如何创建一个Vue组件? 要创建一个Vue组件,可以按照以下步骤进行: 安装Vue CLI(如果还没有安装): npm install -g vue/cli创建一个新的Vue组件: vue create my-component在 src/component…...
设计模式之适配器模式
一、概述 将一个类的接口转换成客户希望的另外一个接口。Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以一起工作。 二、适用性 1.你想使用一个已经存在的类,而它的接口不符合你的需求。 2.你想创建一个可以复用的类,该类可以与其他不…...
)
让ChatGPT介绍一下ChatGPT(ChatGPT的自我介绍)
ChatGPT是这样介绍自己的: ChatGPT是由OpenAI开发的一种基于大规模预训练的语言模型。它是建立在GPT(Generative Pre-trained Transformer)架构的基础上,经过大量的数据训练而成。 ChatGPT旨在通过对话与用户进行交互࿰…...

CentOS 7 构建 LVS-DR 群集
一、LVS-DR集群摘要 LVS(Linux Virtual Server)是一个用于构建可扩展和高可用性的负载均衡集群的软件。它基于Linux操作系统,并提供了一种将网络流量分发到多个后端服务器的机制。 二、基本工作原理 配置负载均衡器:在LVS集群中…...

MySQL8.0.33二进制包安装与部署
官方文档 https://downloads.mysql.com/archives/community/https://dev.mysql.com/doc/refman/8.1/en/binary-installation.html官方文档操作步骤 # Preconfiguration setup $> groupadd mysql $> useradd -r -g mysql -s /bin/false mysql # Beginning of source-build…...
RocketMQ发送消息失败:error CODE: 14 DESC: service not available now, maybe disk full
在执行业务时,发现MQ控制台没有查询到消息,在日志中发现消息发送失败,报错error CODE: 14 DESC: service not available now, maybe disk full 分析报错应该是磁盘空间不足,导致broker不能进行正常的消息存储刷盘,去查…...
1.Fay-UE5数字人工程导入(UE数字人系统教程)
非常全面的数字人解决方案(含源码) Fay-UE5数字人工程导入 1、工程下载:xszyou/fay-ue5: 可对接fay数字人的ue5工程 (github.com) 2、ue5下载安装:Unreal Engine 5 3、ue5插件安装 依次安装以下几个插件 4、双击运行工程 5、切换中文 6、检…...

收藏!逛遍AI论坛发现:京东AI岗薪资竟碾压多家大厂?小白/程序员必看
最近沉迷逛各类AI技术论坛,每天雷打不动翻几十个帖子,其中最吸引我的,就是程序员们分享的AI求职经验帖——尤其是那种薪资爆料、offer选择类的内容,既能看个热闹,更能摸清当下AI岗位的真实市场行情,比单纯看…...

职业倦怠解药:软件测试从业者如何保持长期动力
测试工程师的倦怠困局在敏捷开发与持续交付的浪潮中,软件测试工程师长期面临三重压力:技术迭代焦虑(AI测试工具每月更新)、价值隐形化(自动化脚本掩盖人工贡献)和责任错配(线上事故归咎测试环节…...

LSTM中sigmoid与tanh的协同设计:为何门控与状态更新需要不同激活函数?
1. 为什么LSTM需要两种激活函数? 第一次接触LSTM时,我也被它的结构搞晕了:为什么有的地方用sigmoid,有的地方用tanh?这不是自找麻烦吗?直到我在实际项目中调试模型时才发现,这个看似简单的设计背…...
如何使用Mongoose进行ORM操作?)
MongoDB(90)如何使用Mongoose进行ORM操作?
Mongoose 是一个 MongoDB 对象建模工具,提供了一种在 Node.js 环境中优雅地与 MongoDB 进行交互的方法。它提供了数据验证、查询构建、业务逻辑挂钩等功能。下面详细介绍如何使用 Mongoose 进行 ORM 操作。 一、安装和配置 Mongoose 1. 安装 Mongoose 通过 npm 安装…...

QmlBook深度解析:Qt5与QML的核心概念与架构设计
QmlBook深度解析:Qt5与QML的核心概念与架构设计 【免费下载链接】qmlbook The source code for the upcoming qml book 项目地址: https://gitcode.com/gh_mirrors/qm/qmlbook QmlBook是学习Qt5与QML技术的权威指南,它系统介绍了Qt5的架构设计与Q…...

如何用Dism++快速清理和优化Windows系统:免费工具完整指南
如何用Dism快速清理和优化Windows系统:免费工具完整指南 【免费下载链接】Dism-Multi-language Dism Multi-language Support & BUG Report 项目地址: https://gitcode.com/gh_mirrors/di/Dism-Multi-language Dism是一款强大的Windows系统维护工具&…...
)
C99新特性:变长数组(VLA)
文章目录C99新特性:变长数组(VLA) 🚀什么是变长数组? 🤔为什么需要变长数组? 💡VLA的基本语法和用法 📝在函数内部使用VLAVLA作为函数参数多维VLAVLA的工作原理和内存分配…...

【Day 10 Java转Python】@property——把方法当属性用,Python的封装艺术
Java老兵写Python时最常问的问题:“私有字段呢?getter和setter呢?没有这些,封装还叫封装吗?” 别急,Python告诉你:封装不是为了写一堆getXxx()/setXxx(),而是为了在需要时优雅地插入…...
)
手把手教你从零训练ChatGPT大模型:数据到部署全攻略(内含代码)
想要理解 ChatGPT 背后的原理?想亲手训练一个属于自己的大模型?这篇指南将带你走完从数据搜集到模型部署的完整流程。🎯 前言 ChatGPT、Claude、Kimi……这些大语言模型(LLM)正在改变我们的工作方式。但你有没有想过&a…...

AI编程 - 量化模拟盘实现
用的是vue3-element-admin 开发框架 Go iris web主要实现了实时价格的接入主要是实现了量化择时推入模拟交易 计算收益率以上用Claude code实现...