【LeetCode】练习习题集【4月 - 7 月】
LEETCODE习题集【4月-7月总结】
简单
数组部分
1.重复数
题目:
在一个长度u为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中任意一个重复的数字
输入:
[2, 3, 1, 0, 2, 5, 3]
输出:2 或 3
代码:
class Solution {
public:int findRepeatNumber(vector<int>& nums) {unordered_map<int,int> mp;for(int i=0;i<nums.size();i++){if(mp.find(nums[i]) != mp.end()) return nums[i]; else mp[nums[i]] ++;}return -1;}
};
9.回文数
题目:
给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数

思路:
- 如果是负数一定不是回文数 直接返回false
- 如果是正数,则将其倒序数值计算出来,然后比较和原数值是否相等
- 如果是回文数相等返回true 不相等返回false
代码:
class Solution {
public:bool isPalindrome(int x) {if(x < 0)return false;long cursor = 0;long number = x;while(number != 0){cursor = cursor * 10 + number % 10;number /= 10;}return (cursor == x);}
};
13. 罗马数字转整数
(https://leetcode.cn/problems/roman-to-integer/)
题目:
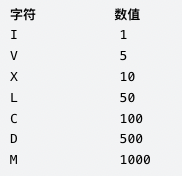
罗马数字包含以下七种字符:
I,V,X,L,C,D和M。
例如, 罗马数字 2 写做 II ,即为两个并列的 1 。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
I 可以放在 V (5) 和 X (10) 的左边,来表示 4 和 9。
X 可以放在 L (50) 和 C (100) 的左边,来表示 40 和 90。
C 可以放在 D (500) 和 M (1000) 的左边,来表示 400 和 900。
给定一个罗马数字,将其转换成整数。来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/roman-to-integer
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
思路:
无序图标记对应的值
每次取两个字母 如果在无序图内有值则直接添加 没有则加上1个字母的值 因为前一次循环中添加了r的值前一个字母的值 所以后面只需要加上减去前一个字母的值 所以无序图是比题目中少给
MXCIV
代码:
class Solution {
public:int romanToInt(string s) {unordered_map<string,int> m ={{"I", 1}, {"IV", 3}, {"IX", 8}, {"V", 5}, {"X", 10}, {"XL", 30}, {"XC", 80}, {"L", 50}, {"C", 100}, {"CD", 300}, {"CM", 800}, {"D", 500}, {"M", 1000}};int r = m[s.substr(0,1)];for(int i = 1; i < s.size(); ++i){string two = s.substr(i-1, 2);string one = s.substr(i,1);r += m[two] ? m[two] : m[one];}return r;}
};
303.区域和检索-数组不可变
题目:
给定一个整数数组 nums,处理以下类型的多个查询:
计算索引 left 和 right (包含 left 和 right)之间的 nums 元素的 和 ,其中 left <= right
实现 NumArray 类:NumArray(int[] nums) 使用数组 nums 初始化对象
int sumRange(int i, int j) 返回数组 nums 中索引 left 和 right 之间的元素的 总和 ,包含 left 和 right 两点(也就是 nums[left] + nums[left + 1] + … + nums[right] )来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/range-sum-query-immutable
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

思路:

#include <bits/stdc++.h>
using namespace std;const int N = 100010;
int a[N];//存放读入数据数组
int s[N];//前缀和数组int main() {int n,m;int l,r;scanf("%d %d",&n,&m);for(int i = 1;i<=n;i++){scanf("%d",&a[i]);s[i] += s[i-1] + a[i];//预处理前缀和}for(int i = 1;i<=m;i++){scanf("%d %d",&l,&r);printf("%d\n",s[r] - s[l-1]);//通过前缀和公式直接访问}system("pause");return 0;
}代码:
class NumArray {
public:
vector<int> sums ;NumArray(vector<int>& nums) {int n = nums.size();sums.resize(n + 1);for(int i = 0; i < n; i++){sums[i + 1] = sums[i] + nums[i];}}int sumRange(int left, int right) {return sums[ right + 1 ] - sums[left];}
};
差分数组
背景:
频繁对数组中某个区间加减,求最终结果
算法讲解:
https://blog.csdn.net/qq_31601743/article/details/105352885?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-105352885-blog-121647156.pc_relevant_recovery_v2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-105352885-blog-121647156.pc_relevant_recovery_v2&utm_relevant_index=2
模板题:
1109. 航班预订统计
题目:
这里有 n 个航班,它们分别从 1 到 n 进行编号。
有一份航班预订表 bookings ,表中第 i 条预订记录 bookings[i] = [firsti, lasti, seatsi] 意味着在从 firsti 到 lasti (包含 firsti 和 lasti )的 每个航班 上预订了 seatsi 个座位。
请你返回一个长度为 n 的数组 answer,里面的元素是每个航班预定的座位总数。
来源:力扣(LeetCode)
链接:https://leetcode.cn/problems/corporate-flight-bookings
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。

思路:

代码:
class Solution {
public:vector<int> corpFlightBookings(vector<vector<int>>& bookings, int n) {vector<int> nums(n);for (auto& booking : bookings){nums[booking[0]-1] += booking[2];if(booking[1]< n){nums[booking[1]] -= booking[2];}}for(int i =1; i< n ; i++){nums[i] += nums[i-1];}return nums;}
};
1094. 拼车 下标问题
双指针:(数组)
016:最接近三数之和
题目大意 #
给定一个数组,要求在这个数组中找出 3 个数之和离 target 最近。
解题思路 #
这一题看似和第 15 题和第 18 题很像,都是求 3 或者 4 个数之和的问题,但是这一题的做法和 15,18 题完全不同。
这一题的解法是用两个指针夹逼的方法。先对数组进行排序,i 从头开始往后面扫。这里同样需要注意数组中存在多个重复数字的问题。具体处理方法很多,可以用 map 计数去重。这里笔者简单的处理,i 在循环的时候和前一个数进行比较,如果相等,i 继续往后移,直到移到下一个和前一个数字不同的位置。j,k 两个指针开始一前一后夹逼。j 为 i 的下一个数字,k 为数组最后一个数字,由于经过排序,所以 k 的数字最大。j 往后移动,k 往前移动,逐渐夹逼出最接近 target 的值。
这道题还可以用暴力解法,三层循环找到距离 target 最近的组合。

018 4Sum
题目大意 #
给定一个数组,要求在这个数组中找出 4 个数之和为 0 的所有组合。
解题思路 #
用 map 提前计算好任意 3 个数字之和,保存起来,可以将时间复杂度降到 O(n^3)。这一题比较麻烦的一点在于,最后输出解的时候,要求输出不重复的解。数组中同一个数字可能出现多次,同一个数字也可能使用多次,但是最后输出解的时候,不能重复。例如 [-1,1,2, -2] 和 [2, -1, -2, 1]、[-2, 2, -1, 1] 这 3 个解是重复的,即使 -1, -2 可能出现 100 次,每次使用的 -1, -2 的数组下标都是不同的。
这一题是第 15 题的升级版,思路都是完全一致的。这里就需要去重和排序了。map 记录每个数字出现的次数,然后对 map 的 key 数组进行排序,最后在这个排序以后的数组里面扫,找到另外 3 个数字能和自己组成 0 的组合

027 移除元素
给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并原地修改输入数组。
元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
示例 1: 给定 nums = [3,2,2,3], val = 3, 函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。 你不需要考虑数组中超出新长度后面的元素。
示例 2: 给定 nums = [0,1,2,2,3,0,4,2], val = 2, 函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。
你不需要考虑数组中超出新长度后面的元素。
#
思路
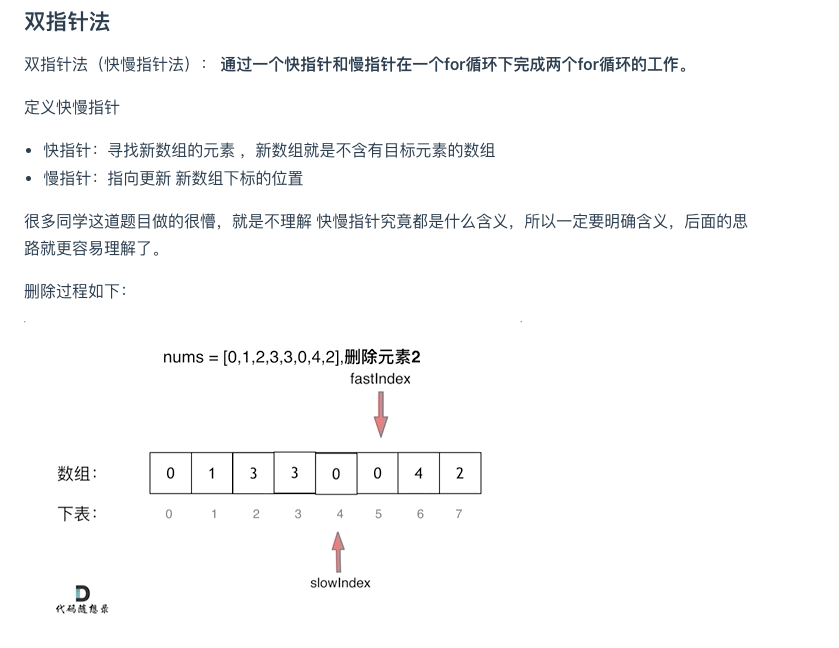
/**
* 相向双指针方法,基于元素顺序可以改变的题目描述改变了元素相对位置,确保了移动最少元素
* 时间复杂度:O(n)
* 空间复杂度:O(1)
*/
class Solution {
public:int removeElement(vector<int>& nums, int val) {int leftIndex = 0;int rightIndex = nums.size() - 1;while (leftIndex <= rightIndex) {// 找左边等于val的元素while (leftIndex <= rightIndex && nums[leftIndex] != val){++leftIndex;}// 找右边不等于val的元素while (leftIndex <= rightIndex && nums[rightIndex] == val) {-- rightIndex;}// 将右边不等于val的元素覆盖左边等于val的元素if (leftIndex < rightIndex) {nums[leftIndex++] = nums[rightIndex--];}}return leftIndex; // leftIndex一定指向了最终数组末尾的下一个元素}
};
相关题目推荐
- 26.删除排序数组中的重复项 √ 第一项是不会改变的 不需要更改
- 283.移动零 √ 思路就是 直接在后面加0
- 844.比较含退格的字符串 √ 调用一个新的字符串 不是需要的字符就直接弹出
- 977.有序数组的平方
vector<int> sortedSquares(vector<int>& nums) {int left =0 ;int right = nums.size()-1;int i = nums.size();vector<int> res(i,0);while(left <= right){i--;if(nums[left] + nums[right] < 0){res[i] = nums[left] * nums[left];left++;}else{res[i] = nums[right] * nums[right];right--;}}return res;}
043 接雨水
题目大意 #
从 x 轴开始,给出一个数组,数组里面的数字代表从 (0,0) 点开始,宽度为 1 个单位,高度为数组元素的值。如果下雨了,问这样一个容器能装多少单位的水?

075 排颜色
题目大意 #
抽象题意其实就是排序。这题可以用快排一次通过。
解题思路 #
题目末尾的 Follow up 提出了一个更高的要求,能否用一次循环解决问题?这题由于数字只会出现 0,1,2 这三个数字,所以用游标移动来控制顺序也是可以的。具体做法:0 是排在最前面的,所以只要添加一个 0,就需要放置 1 和 2。1 排在 2 前面,所以添加 1 的时候也需要放置 2 。至于最后的 2,只用移动游标即可。
这道题可以用计数排序,适合待排序数字很少的题目。用一个 3 个容量的数组分别计数,记录 0,1,2 出现的个数。然后再根据个数排列 0,1,2 即可。时间复杂度 O(n),空间复杂度 O(K)。这一题 K = 3。
这道题也可以用一次三路快排。数组分为 3 部分,第一个部分都是 0,中间部分都是 1,最后部分都是

DFS暴力枚举
题目大意 #
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。说明:解集不能包含重复的子集。
解题思路 #
- 找出一个集合中的所有子集,空集也算是子集。且数组中的数字不会出现重复。用 DFS 暴力枚举即可。
- 这一题和第 90 题,第 491 题类似,可以一起解答和复习。

滑动窗口
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的 连续 子数组,并返回其长度。如果不存在符合条件的子数组,返回 0。
示例:
输入:s = 7, nums = [2,3,1,2,4,3] 输出:2 解释:子数组 [4,3] 是该条件下的长度最小的子数组。
提示:
- 1 <= target <= 10^9
- 1 <= nums.length <= 10^5
- 1 <= nums[i] <= 10^5

螺旋矩阵
排序算法
选择排序
- 算法思想 1:贪心算法
每一次决策只看当前,当前最优,则全局最优。注意:这种思想不是任何时候都适用。
- 算法思想 2:减治思想
外层循环每一次都能排定一个元素,问题的规模逐渐减少,直到全部解决,即「大而化小,小而化了」。运用「减治思想」很典型的算法就是大名鼎鼎的「二分查找」。
- 优点:交换次数最少。
「选择排序」看起来好像最没有用,但是如果在交换成本较高的排序任务中,就可以使用「选择排序」(《算法 4》相关章节课后练习题)。
依然是建议大家不要对算法带有个人色彩,在面试回答问题的时候和看待一个人和事物的时候,可以参考的回答模式是「具体问题具体分析,在什么什么情况下,用什么什么算法」。
class Solution {
public:vector<int> sortArray(vector<int>& nums) {int length = nums.size();int swap=0;for(int i=0;i<length;i++){int min_tag = i;for(int j=i+1;j<length; j++){if(nums[j] <= nums[min_tag]){min_tag = j;}}if(min_tag != i){swap = nums[i];nums[i] = nums[min_tag];nums[min_tag]= swap;} }return nums;}
};
双指针法解决三数之和
- 第一步将数组排序
- i left right
- 和 > 0 right 左移 和 < 0 left 右移 直到left和right相遇为止
-
class Solution { public:vector<vector<int>> threeSum(vector<int>& nums) {vector<vector<int>> result;sort(nums.begin(), nums.end());// for(int i = 0; i < nums.size(); i++){// cout << nums[i];// }for(int i = 0; i < nums.size(); i++){// 排序之后的第一个数组>0 的情况下 那么之后一定是没办法满足if(nums[i] > 0) return result;// 不理解为什么后面的匹配前面的值 就是正确的去重// if(nums[i] == nums[i+1]){// continue;// }// 因为这样前面还是执行 后面一步判断就去重if(i > 0 && nums[i] == nums[i - 1]){continue;}for(int left = i+1,right = nums.size() - 1; left < right;){if(nums[i] + nums[left] + nums[right] > 0){right--;}else if(nums[i] + nums[left] + nums[right] < 0){left++;}else{result.push_back(vector<int>{nums[i] , nums[left], nums[right]});while(right > left && nums[right] == nums[right - 1]) right--;while(right > left && nums[left] == nums[left + 1]) left++;right--;left++;}}}return result;}};
二分查找
题型
二分查找
条件
int a[] = {1,2,3,4,5,6,7,8,9,10}
int a[] = {5,6,7,8,9,10,1,2,3,4}
// 1、数组有序,局部有序
// 2、logn
普通二分查找
1、查target
查第一个target
查最后一个target
2、查大于target的第一个
3、查小于target的第一个
#include <iostream>
#include <vector>
using namespace std;//二分模板,查找target是否存在
int search(vector<int>&nums, int target)
{//step 1int l = 0;int r = nums.size()-1;int mid = 0;//返回值//step 2while(l<=r){mid = l + (r - l)/2;// 结果if(nums[mid] == target){// 结果return mid;}else if(nums[mid] < target){//l = mid+1;}else{//r = mid - 1;}}return -1;
}//查找第一个target
int searchL(vector<int>&nums, int target)
{int l = 0;int r = nums.size() - 1;int res = -1; //结果while(l<=r){int mid = l + (r - l)/2;if(nums[mid] == target){res = mid;r = mid - 1;}else if(nums[mid] < target){l = mid + 1;}else{r = mid - 1;}}return res;
}//查找最后一个target
int searchR(vector<int>&nums, int target)
{int l = 0;int r = nums.size();int res = -1;while(l<=r){int mid = l + (r - l)/2;if(nums[mid] == target){res = mid;l = mid + 1;}else if(nums[mid] < target){l = mid + 1;}else{r = mid - 1;}}return res;}//查找大于target的第一个
int searchR1(vector<int>&nums, int target)
{int l = 0;int r = nums.size() - 1;int res = -1;while(l <= r){int mid = l + (r - l)/2;if(nums[mid] > target){res = mid;r = mid - 1;}else{l = mid + 1;}}return res;
}//查找小于target的第一个
int searchL1(vector<int>&nums, int target)
{int l = 0;int r = nums.size() - 1;int res = -1;while(l <= r){int mid = l + (r - l)/2;if(nums[mid] < target){res = mid;l = mid + 1;}else{r = mid - 1;}}return res;
}//查找小于等于target的第一个
int searchL2(vector<int>&nums, int target)
{int l = 0;int r = nums.size() - 1;int res = -1;while(l <= r){int mid = l + (r - l)/2;if(nums[mid] <= target){res = mid;l = mid + 1;}else{r = mid - 1;}}return res;
}//查找大于等于target的第一个
int searchR2(vector<int>&nums, int target)
{int l = 0;int r = nums.size() - 1;int res = -1;while(l <= r){int mid = l + (r - l)/2;if(nums[mid] >= target){res = mid;r = mid - 1;}else{l = mid + 1;}}return res;
}
int main() {vector<int>nums{1,2,3,4,5,5,5,5,5,7,9};//int target = 5;cout<<searchL1(nums,target)<<endl;return 0;
}
二分
大于、小于、等于、时间复杂度不能为N^2 、时间复杂度为logn 考虑二分
最大值最小、最小值最大 用二分答案
lower_bound(nums.begin(),nums.end(),val) - nums.begin();//查找 大于等于 val的第一个坐标upper_bound(nums.begin(),nums.end(),val) - nums.end();//查找 大于 val的第一个坐标基础模板:
704. 二分查找 √
35. 搜索插入位置 √
34. 在排序数组中查找元素的第一个和最后一个位置 √
367. 有效的完全平方数 √
剑指 Offer II 072. 求平方根 √
374. 猜数字大小 √
进阶:
162. 寻找峰值 l < r写法 √
[6355. 统计公平数对的数目]( 没找到
链表部分
链表基础
翻转链表
题意:反转一个单链表。
示例: 输入: 1->2->3->4->5->NULL 输出: 5->4->3->2->1->NULL
思路:
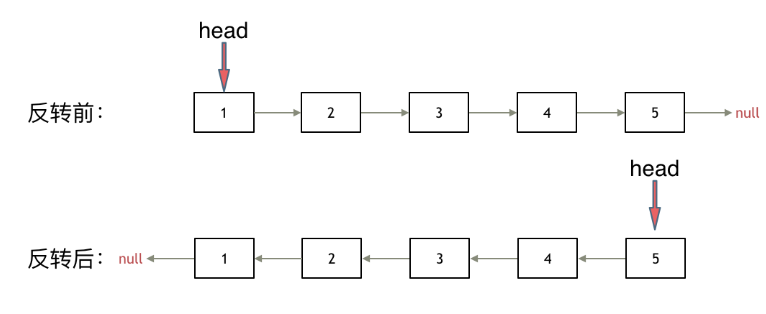

参考题目
206 反转链表
两两交换链表中的节点
思路:
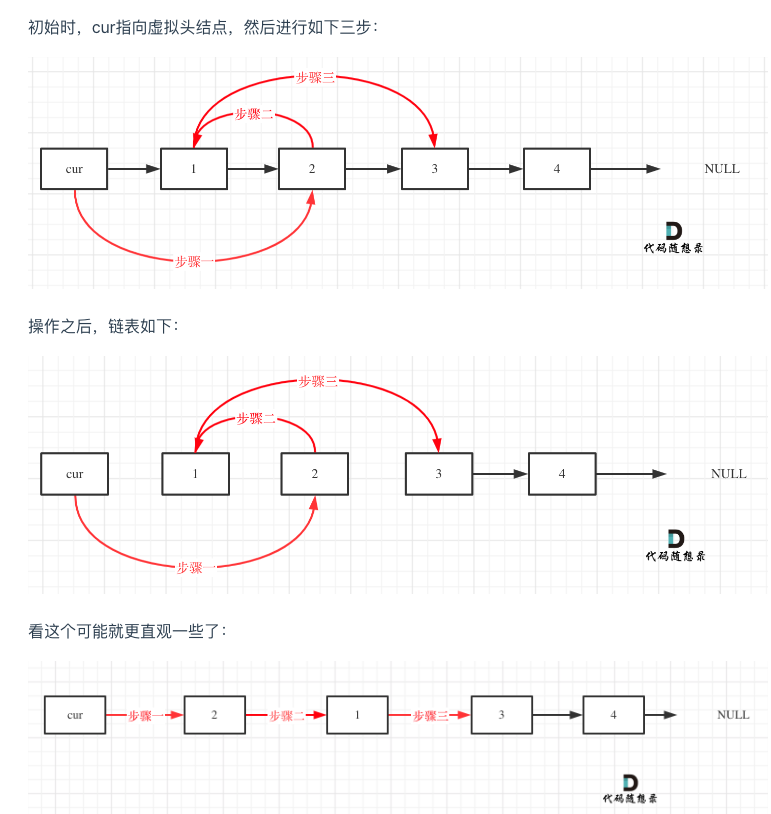
class Solution {
public:ListNode* swapPairs(ListNode* head) {ListNode* dummyHead = new ListNode(0); // 设置一个虚拟头结点dummyHead->next = head; // 将虚拟头结点指向head,这样方面后面做删除操作ListNode* cur = dummyHead;while(cur->next != nullptr && cur->next->next != nullptr) {ListNode* tmp = cur->next; // 记录临时节点ListNode* tmp1 = cur->next->next->next; // 记录临时节点cur->next = cur->next->next; // 步骤一cur->next->next = tmp; // 步骤二cur->next->next->next = tmp1; // 步骤三cur = cur->next->next; // cur移动两位,准备下一轮交换}return dummyHead->next;}
};
参考题目:
- 两两交换链表中的节点
删除链表的倒数第N个节点
思路:
双指针方法 先循环然后再删除
第一步初始化头结点 然后遍历之后的节点 然后fast前移一个指针 为了方便slow可以指向slow前面的节点 可以直接删除
/*** Definition for singly-linked list.* struct ListNode {* int val;* ListNode *next;* ListNode() : val(0), next(nullptr) {}* ListNode(int x) : val(x), next(nullptr) {}* ListNode(int x, ListNode *next) : val(x), next(next) {}* };*/
class Solution {
public:ListNode* removeNthFromEnd(ListNode* head, int n) {// 初始化头结点ListNode* dummyHead = new ListNode(0);dummyHead -> next = head;// 当前虚拟头结点指向头结点指针headListNode* fast = dummyHead;ListNode* slow = dummyHead;// 这里判断当前fast节点必须要在slow节点的n个值前面while(n-- && fast!= nullptr){fast = fast -> next;}// 为什么要fast节点往前一个步骤呢? 我不理解fast = fast -> next;while(fast != nullptr){fast = fast -> next;slow = slow -> next;}// 这里是指当前节点自动执行到最后一个节点的位置slow -> next = slow -> next -> next;ListNode* temp = slow -> next;slow -> next = temp -> next;delete temp;// C++语言必须要释放内存 只有释放了内存才不会内存溢出oom}};
链表相交
思路
先比较大小长度 然后 对齐全部的长度 判断当前位置是否相等 如果相等 直接返回 不相等 就直接返回
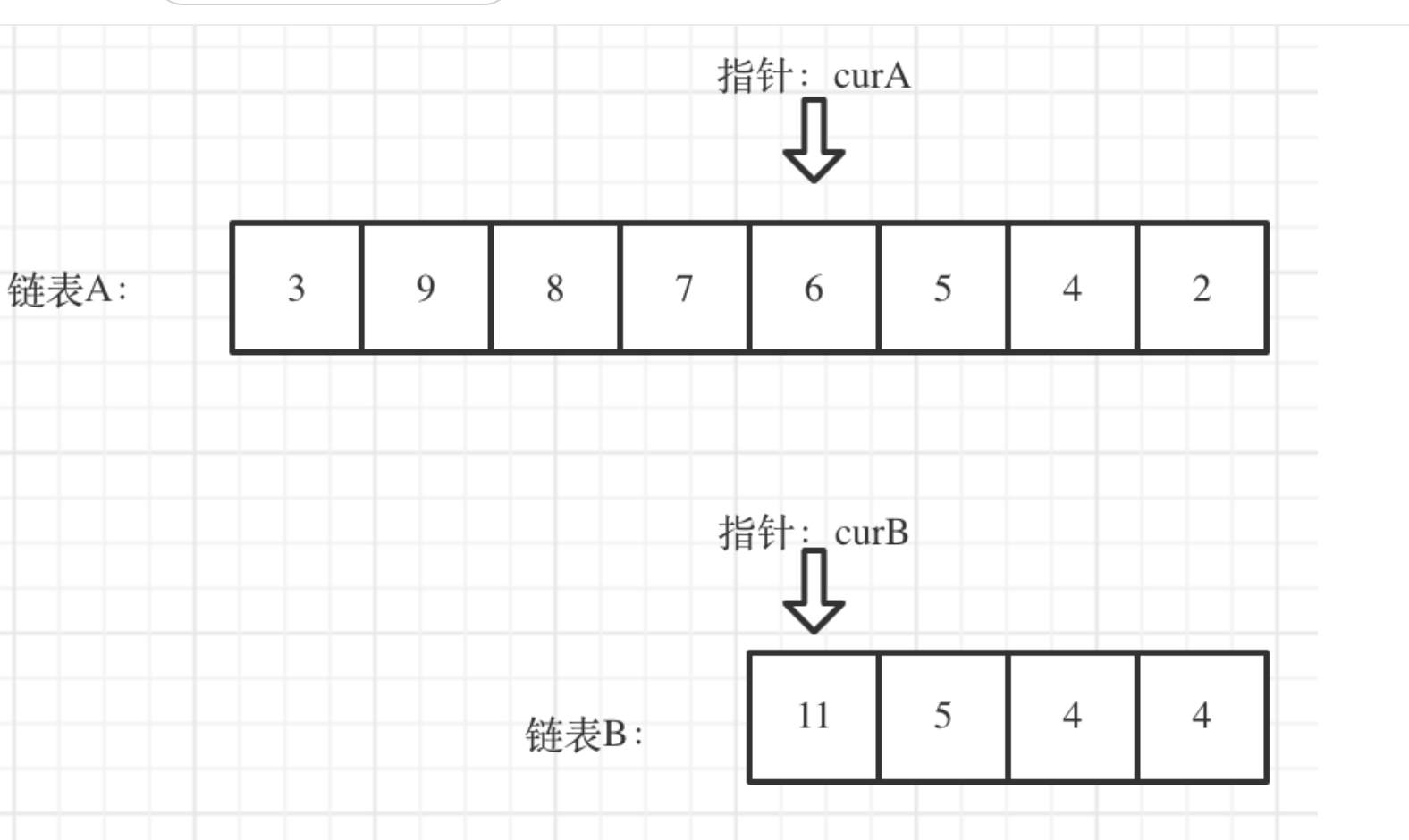
class Solution {
public:ListNode *getIntersectionNode(ListNode *headA, ListNode *headB) {// 判断两个指针头部 以及判断两个链表长度ListNode* curA = headA;ListNode* curB = headB;int lenA = 0, lenB =0;// 求出链表A的长度while(curA != NULL){lenA++;curA = curA -> next;}// 求出链表B的长度while(curB != NULL){lenB++;curB = curB -> next;}// 这一步可以求出链表AB的长度 当前指针指向头部curA = headA;curB = headB;if(lenB > lenA){swap(lenA, lenB);swap(curA, curB);}int gap = lenA - lenB;while(gap--){curA = curA -> next;}// 这时候curA和curB 在同一起点 (末尾位置对齐)while(curA != NULL){if(curA == curB){return curA;}curA = curA -> next;curB = curB -> next;}return NULL; }
};
环形链表
双指针: 使用一个 一个快指针 一个慢指针 慢指针走一步 快指针走两步 进入环形链表之后 快指针相当于走到慢指针追着一步一步 当追上的时候 就是确定有环 此时链表开始从头开始 环内节点开始跳动 然后当两者相遇的时候就可以确定此时就是环形链表相遇的入口
class Solution {
public:ListNode *detectCycle(ListNode *head) {ListNode* fast = head;ListNode* slow = head;while(fast != NULL && fast->next != NULL) {slow = slow->next;fast = fast->next->next;// 快慢指针相遇,此时从head 和 相遇点,同时查找直至相遇if (slow == fast) {ListNode* index1 = fast;ListNode* index2 = head;while (index1 != index2) {index1 = index1->next;index2 = index2->next;}return index2; // 返回环的入口}}return NULL;}
};
哈希
总结一下,当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法。
但是哈希法也是牺牲了空间换取了时间,因为我们要使用额外的数组,set或者是map来存放数据,才能实现快速的查找
判断两个字符的位置
两个数组的交集
思路: 判断数组有交集 主要是需要判定一种无序结构 unordered_set 输出的每一个元素是唯一的 也就是说输出的结果是去重的
std::set和std::multiset底层实现都是红黑树,std::unordered_set的底层实现是哈希表, 使用unordered_set 读写效率是最高的,并不需要对数据进行排序,而且还不要让数据重复,所以选择unordered_set
哈希表的效率比红黑树的效率高
class Solution {
public:vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {unordered_set<int> result_set; // 存放结果,之所以用set是为了给结果集去重unordered_set<int> nums_set(nums1.begin(), nums1.end());for (int num : nums2) {// 发现nums2的元素 在nums_set里又出现过if (nums_set.find(num) != nums_set.end()) {result_set.insert(num);}}return vector<int>(result_set.begin(), result_set.end());}
};
快乐数
题目 202
题目中说了会 无限循环,那么也就是说求和的过程中,sum会重复出现,这对解题很重要!
当我们遇到了要快速判断一个元素是否出现集合里的时候,就要考虑哈希法了。
思路:第一步需要求这个数的平方和
求平方和就是除以对应的元素然后直接进行对应的相加
第二部 判断这个sum总和是不是 == 1 如果是等于1的话就是结束的出口
第三部 判断这个数字是不是原来出现过 如果出现过就是无线循环 如果没有出现过 就继续在无序哈希表插入
class Solution {
public:int getSum(int n){int sum = 0;while(n){sum += (n % 10) *(n % 10);n /= 10;}return sum;} bool isHappy(int n) {unordered_set<int> result_set;while(true){int answer = getSum(n);if(answer == 1){return true;}// 如果这个sum曾经出现过 就说明进入无线循环了 并且 无序哈希表记录的不是单个 而是整个数字if(result_set.find(answer) != result_set.end()){return false;}else{result_set.insert(answer);}n = answer; //这里将n赋予给answer是直接}}
};
两数之和

Q:为什么需要两边遍历:
A:因为这样的时间复杂度是O^2的 而不是三的
然后对应的
赎金信
题目: https://leetcode.cn/problems/ransom-note/
class Solution {
public:bool canConstruct(string ransomNote, string magazine) {// map数组的空间消耗是比数组大一些的 map需要维护红黑树 以及哈希表 而且还需要做哈希函数// 使用record数组记录当前的值// 每次n循环判断当前数组是否存在 直接减去 判断小于0 返回falseint record[26] = {0};// 如果ransomNote 的 长度比magzine的长度长的话 直接返回falseif(ransomNote.length() > magazine.length()){return false;}for(int i = 0; i< magazine.length(); i++){record[magazine[i] - 'a']++;}for(int j = 0 ; j < ransomNote.length(); j++){record[ransomNote[j] - 'a']--;if(record[ransomNote[j] - 'a'] < 0){return false;}}return true;}
};
栈与队列
栈与队列的基础操作 用栈实现队列
class MyQueue {
public:stack<int> stIn;stack<int> stOut;MyQueue() {// 初始化需要的队列}void push(int x) {stIn.push(x);}int pop() {if(stOut.empty()){while(!stIn.empty()){stOut.push(stIn.top());stIn.pop();}}int result = stOut.top();stOut.pop();return result;}int peek() {// 返回当前队列的第一个元素int res = this-> pop();stOut.push(res);return res;}bool empty() {return stIn.empty() && stOut.empty();}
};/*** Your MyQueue object will be instantiated and called as such:* MyQueue* obj = new MyQueue();* obj->push(x);* int param_2 = obj->pop();* int param_3 = obj->peek();* bool param_4 = obj->empty();*/
一定要学会复用 因为功能相近的函数要抽象出来 不要大量的复制粘贴 很容易出问题
1047删除字符串所有相邻的重复项
class Solution {
public:string removeDuplicates(string s) {// 入栈比较栈顶和当前元素的值 相等就直接出栈 并且自增stack<char> st;for(char t:s){if(st.empty() || t != st.top()){st.push(t);}else{st.pop();}}// 现在不能直接返回st 因为st是栈值的意思 不能使用string result = "";// 需要把result的值 把栈里面的值while(!st.empty()){result += st.top();st.pop(); }// 此时放到result的值是反着的 需要进行翻转一下 c++翻转需要使用reversereverse(result.begin(), result.end());return result;}
};
做题步骤
第一步: String数组 使用char进行遍历 删除栈顶元素
第二步: 因为使用stack 但是返回的类型是String的类型需要初始化一个string类型 的使用 栈的相关操作 将stack赋予给string
第三步:因为赋予的string类型是反方向的 所以需要进行反转 这样才能使得返回的string类型是对应的
class Solution {
public:string removeDuplicates(string s) {// 第二种方法直接使用string作为stack 省去第二步骤 和第三步骤的区别string result;for(char t : s){if(result.empty() || result.back() != t){result.push_back(t); }else{result.pop_back();}}return result;}
};
150 逆波兰表达式求值
第一步: 使用longlong 类型 的stack 去处理 需要操作的数据
第二步: 循环判断 如果是字符串 弹出两个数 进行处理
第三步:返回需要的栈顶值
class Solution {
public:int evalRPN(vector<string>& tokens) {stack<long long> st;for(int i = 0; i < tokens.size(); i++){if (tokens[i] == "+" || tokens[i] == "-" || tokens[i] == "*" || tokens[i] == "/") {long long num1 = st.top();st.pop();long long num2 = st.top();st.pop();if (tokens[i] == "+") st.push(num2 + num1);if (tokens[i] == "-") st.push(num2 - num1);if (tokens[i] == "*") st.push(num2 * num1);if (tokens[i] == "/") st.push(num2 / num1);}else{st.push(stoll(tokens[i]));}}return st.top();}
};
二叉树
层次遍历
void order(TreeNode* cur, vector<vector<int>>& result, int depth){if(cur == nullptr) return;if(result.size() == depth) result.push_back(vector<int>());result[depth].push_back(cur -> val);order(cur -> left, result, depth+1);order(cur -> right, result, depth+1);}vector<vector<int>> levelOrder(TreeNode* root) {vector<vector<int>> result;int depth = 0;order(root, result, depth);return result;}
对称二叉树
class Solution {
public:bool compare(TreeNode* left , TreeNode* right){// 第一次判断 判断左右节点是否为空 if(left == NULL && right != NULL) return false;else if(right == NULL && left != NULL) return false;else if(left == NULL && right == NULL) return true;// 排除了空节点 再排除 数值不相同的情况else if(left -> val != right -> val) return false;//目前是左右节点相同 此时确定递归下一层的判断bool outside = compare(left -> left, right -> right);bool inside = compare(left -> right, right -> left);bool issame = outside && inside;return issame; }bool isSymmetric(TreeNode* root) {if(root == NULL) return true;return compare(root -> left, root -> right);}
};
获取树的最大深度
step 1 判断是不是空的 如果是的话 就0
step 2 获取左边的 和 获取右边的
step 3 总 = max(左右 )+1
获取树的最小深度

左叶子之和
class Solution {
public:int sumOfLeftLeaves(TreeNode* root) {// 第一步判断终止条件 左叶子的节点就是在判断当前节点不为0 且当前节点的左孩子和右孩子都是空值// 如果根节点是空值的话 那么直接返回return 因为根节点如果是空的值的话 就可以确定当前可以直接返回0if(root == NULL) return 0;// 第二步骤 判断 如果根节点 既没有左边的叶子结点 也没有右边的叶子结点 那么 判断他的左叶子结点之和 那么根节点的判断也一定是0if(root -> left == NULL && root -> right == NULL) return 0;// 这里要确定一下 单层递归 的逻辑// 这里说明当前的子节点的值不是空值 但是确认了 当前节点的左孩子节点是空值并且右孩子节点也是空值 判断到了左叶子节点 // 以下开始进行左叶子结点累加和的操作int leftValue = sumOfLeftLeaves(root -> left);if(root -> left && !root -> left -> left && !root -> left -> right){leftValue = root -> left -> val;}int rightValue = sumOfLeftLeaves(root -> right);// 这里分别使用递归法 判断出了 左边叶子节点 和 右边叶子结点的值 // 那么 需要 判断一下 总和 即可int sum = leftValue + rightValue;return sum;路径总和

class Solution {
private:bool traversal(TreeNode* cur, int count) {if (!cur->left && !cur->right && count == 0) return true; // 遇到叶子节点,并且计数为0if (!cur->left && !cur->right) return false; // 遇到叶子节点直接返回if (cur->left) { // 左count -= cur->left->val; // 递归,处理节点;if (traversal(cur->left, count)) return true;count += cur->left->val; // 回溯,撤销处理结果}if (cur->right) { // 右count -= cur->right->val; // 递归,处理节点;if (traversal(cur->right, count)) return true;count += cur->right->val; // 回溯,撤销处理结果}return false;}public:bool hasPathSum(TreeNode* root, int sum) {if (root == NULL) return false;return traversal(root, sum - root->val);}
};
困难
双端队列239. 滑动窗口最大值
单调队列的解析:
https://blog.csdn.net/qq_53268869/article/details/122870945

题解
-
第一步 滑动窗口 需要保证双端队列 C++里面有直接使用的deque每次pop 先判断里面的值是不是空的 如果空的 就不弹出 如果不是空的 就比较当前弹出的数值是否等于队列出口元素的数值 如果相等就弹出实现双端队列 一共分为三步第一步: push 确定一下当前value的值和队列尾端的值大小 如果是小的值 就弹出来 如果当前没有逼他小的直接入栈第二步:pop 去顶当前value等于 双端队列的队首 只弹队首 也就是最大值第三步:front 返回当前的最大值
class Solution {// 第一步: push 确定一下当前value的值和队列尾端的值大小 如果是小的值 就弹出来 如果当前没有逼他小的直接入栈// 第二步:pop 去顶当前value等于 双端队列的队首 只弹队首 也就是最大值// 第三步:front 返回当前的最大值
private:class SinQueue{// 单调队列 从小的值到大的值public: //不写public默认是privatedeque<int> que;void pop(int value){if(!que.empty() && que.front() == value){que.pop_front();}}void push(int value){while(!que.empty() && value > que.back()){que.pop_back();}que.push_back(value);}int front(){return que.front();}};public:vector<int> maxSlidingWindow(vector<int>& nums, int k) {// 第一步: 初始一个单调队列 然后初始化一个结果向量// 第二步: 把所有的k值放入单调队列里面进去SinQueue que;vector<int> result;for(int i = 0; i < k; i++){que.push(nums[i]);}// 这里需要先存一下 最大值// 第四步 循环移出窗口最前面的元素 然后添加当前的值 每做一步都需要确认当前的最大值result.push_back(que.front());for(int i = k ; i < nums.size(); i++){que.pop(nums[i - k]);que.push(nums[i]);result.push_back(que.front());}return result;}
}
相关文章:
【LeetCode】练习习题集【4月 - 7 月】
LEETCODE习题集【4月-7月总结】 简单 数组部分 1.重复数 题目: 在一个长度u为 n 的数组 nums 里的所有数字都在 0~n-1 的范围内。数组中某些数字是重复的,但不知道有几个数字重复了,也不知道每个数字重复了几次。请找出数组中…...

C# 子类强制转换为父类异常,引出的C#Dll加载机制,以及同类名同命名空间同dll程序集在C#中是否为同一个类的研究。
已知,子类B继承自父类A,但是在代码运行时,B类强制转换为A类,却报代码转换异常。 很奇怪的问题吧,不过这个也是难得机会,去研究C#运行的底层原理。 下面是报错的代码片段。 string className _shapeRefle…...

Go语言进阶
个人笔记,大量摘自Go语言高级编程、Go|Dave Cheney等 更新 go get -u all 在非go目录运行go install golang.org/x/tools/goplslatest更新go tools:在go目录运行go get -u golang.org/x/tools/...,会更新bin目录下的应用; 运行…...

Java的枚举
枚举 对应英文(enumeration, 简写enum) 枚举是一组常量的集合,属于一种特殊的类,里面只包含一组有限的特定的对象。 自定义类实现枚举 1.不需要提供setXxx方法,因为枚举对象值通常为只读. 2.对枚举对象/属性使用 final static共同修饰…...
Pytest测试框架3
目录: pytest结合数据驱动-yamlpytest结合数据驱动-excelpytest结合数据驱动-csvpytest结合数据驱动-jsonpytest测试用例生命周期管理(一)pytest测试用例生命周期管理(二)pytest测试用例生命周期管理(三&a…...
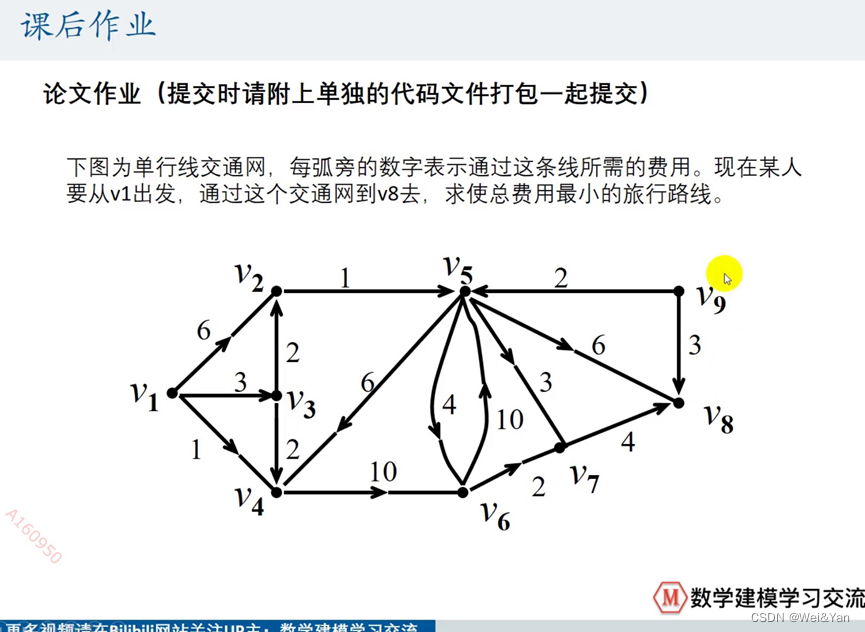
【数学建模】-- Matlab中图的最短路径
前言: 图的基本概念: 若想简单绘制图可以利用此网站: 左上角Undirected/Directed是无向图/有向图 左边 0-index ,1-index为0下标,1下标。 Node Count为节点个数 Graph Data:最初尾节点的名称ÿ…...

中国月入过万的人多不多
Q:中国月入过万的人多不多 单从这个问题来看,这是个费米问题啊: 估算中国月入过万的有多少人? 要解决费米问题,其实也很好办,就是逻辑拆解,这篇文章也分为3个部分,先从公开数据中估…...

苹果电脑图像元数据编辑器:MetaImage for Mac
MetaImage for Mac是一款功能强大的照片元数据编辑器,它可以帮助用户编辑并管理照片的元数据信息,包括基本信息和扩展信息。用户可以根据需要进行批量处理,方便快捷地管理大量照片。 MetaImage for Mac还提供了多种导入和导出格式࿰…...
 详解)
BeanUtils.copyProperties() 详解
BeanUtils.copyProperties会进行类型转换; BeanUtils.copyProperties方法简单来说就是将两个字段相同的对象进行属性值的复制。如果 两个对象之间存在名称不相同的属性,则 BeanUtils 不对这些属性进行处理,需要程序手动处理。 这两个类在不同…...

基于CentOS 7构建LVS-DR集群
DIPVIPRIPClient192.169.41.139 LVS 192.168.41.134192.169.41.10RS1192.168.41.135RS2192.168.41.138 要求: node4为客户端,node2为LVS,node3和node4为RS。 1.配置DNS解析(我这里使用本地解析) 192.168.41.134 www.y…...

openEuler-OECA考试报名火热开启,尊享半价优惠 作者:HopeInfra 发布时间:2023-08-10
近日,润和软件人才评定报名系统已成功上线运行,现openEuler-OECA人才评定考试报名优惠活动火热开启,欢迎大家报名咨询! 关于openEuler人才评定 随着openEuler及其发行版本在各个行业使用量逐年增多,相关人才的评定诉求…...
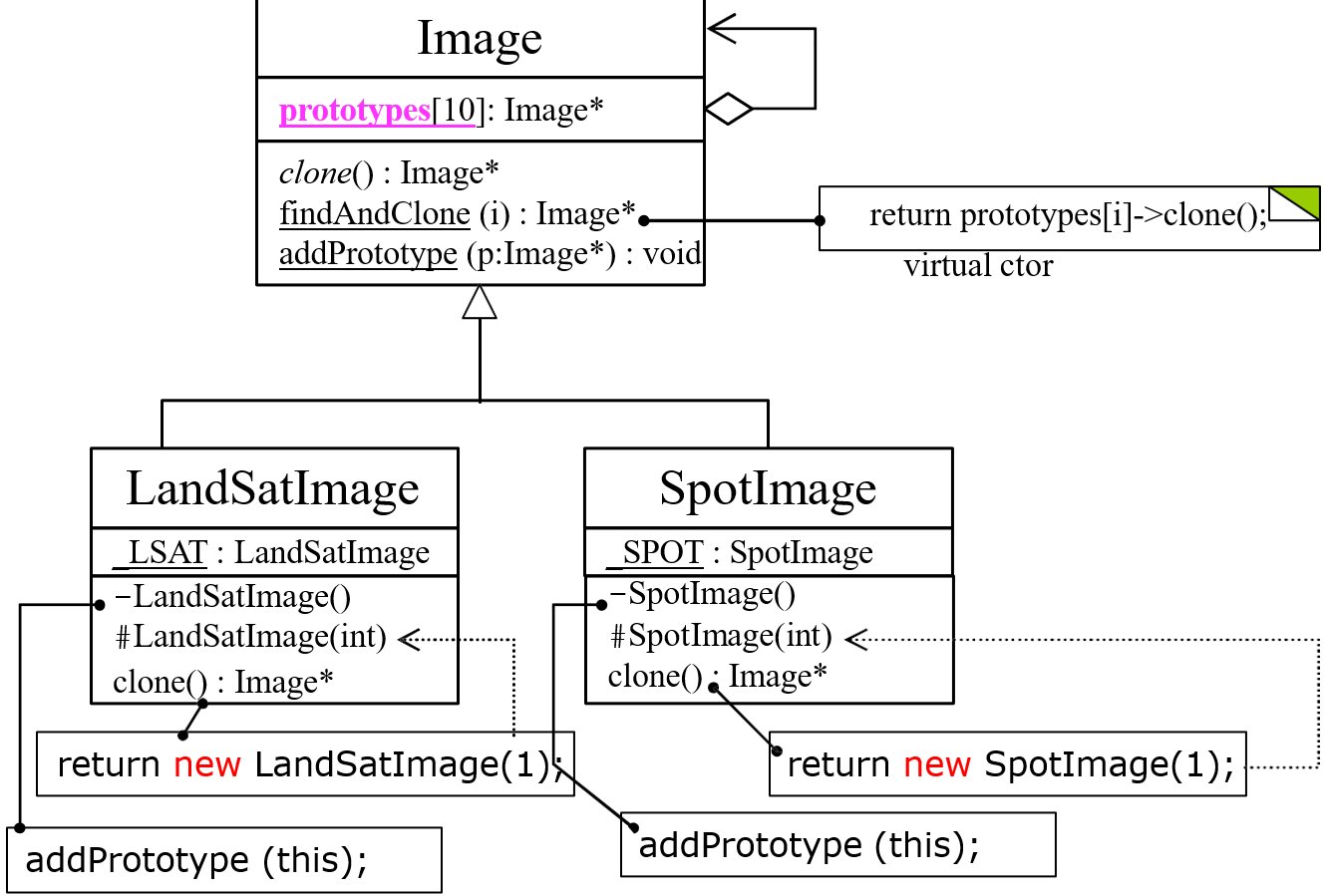
侯捷 C++面向对象编程笔记——10 继承与虚函数
10 继承与虚函数 10.1 Inheritance 继承 语法::public base_class_name public 只是一种继承的方式,还有protect,private 子类会拥有自己的以及父类的数据 10.1.1 继承下的构造和析构 与复合下的构造和析构相似 构造是由内而外 Container …...
、计算日期之间的天数等))
mysql日期函数(查询最近n(天/月/年)、计算日期之间的天数等)
mysql日期函数 目录 mysql查询最近一个月数据返回当前日期和时间将字符串转变为日期日期 d 减去 n 天后的日期计时间差,返回 datetime_expr2 − datetime_expr1 的时间差算查询当天数据 ADDDATE(d,n)计算起始日期 d 加上 n 天的日期 SELECT ADDDATE("2017-06…...

通过anvt X6和vue3实现图编辑
通过anvt X6 X6地址:https://x6.antv.antgroup.com/tutorial/about; 由于节点比较复杂,使用vue实现的节点; x6提供了一个独立的包 antv/x6-vue-shape 来使用 Vue 组件渲染节点。 VUE3的案例: <template><div…...

win2012 IIS8.5 安装PHP教程,一些版本不能用
因为一直用win2003IIS6.0PHP的环境,所以搭建PHP自认为非常熟悉了,但是最近在搭建win2012IIS8.5PHP的环境时,我遇到了一些问题,经过4个小时的折腾,终于搞定了,本文记录一些经验,可能不少朋友也会…...

sqlalchemy执行原生sql
# 有的复杂sql 用orm写不出来---》用原生sql查询 # 原生sql查询,查出的结果是对象 # 原生sql查询,查询结果列表套元组 准备工作 from sqlalchemy.orm import sessionmaker, relationship from sqlalchemy import create_engineengine create_engine(&…...

Python-OpenCV中的图像处理-图像平滑
Python-OpenCV中的图像处理-图像平滑 图像平滑平均滤波高斯模糊中值模糊双边滤波 图像平滑 使用低通滤波器可以达到图像模糊的目的。这对与去除噪音很有帮助。其实就是去除图像中的高频成分(比如:噪音,边界)。所以边界也会被模糊…...
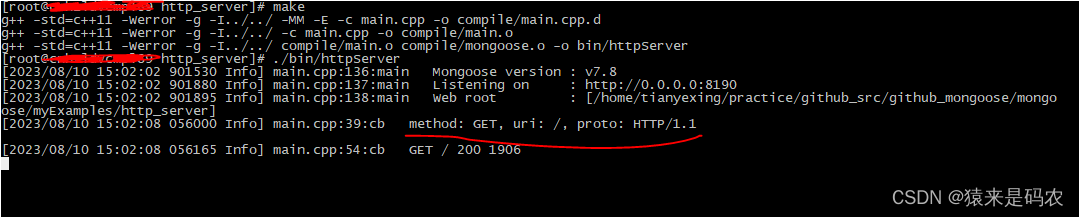
Mongoose http server 例子
今天抽了点时间看了一下 mongoose的源码, github 地址,发现跟以前公司内部使用的不太一样,这里正好利用其 http server 例子来看一下。以前的 http message 结构体是这样的: /* HTTP message */ struct http_message {struct mg_…...

1、初识HTML
1、初识HTML 前端就是写一些基本的页面,HTML即超文本标记语言:Hyper Text Markup Language,超文本包括,文字、图片、音频、视频、动画等,HTML5,提供了一些新的元素和一些有趣的新特性,同时也建…...

线性代数(三) 线性方程组
前言 如何利用行列式,矩阵求解线性方程组。 线性方程组的相关概念 用矩阵方程表示 齐次线性方程组:Ax0;非齐次线性方程组:Axb. 可以理解 齐次线性方程组 是特殊的 非齐次线性方程组 如何判断线性方程组的解 其中R(A)表示矩阵A的…...

从 Scaffolding 到 Harness:AI Coding Agent 真正难的,不是写代码,而是把系统跑起来
🤵♂️ 个人主页:小李同学_LSH的主页 ✍🏻 作者简介:LLM学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

终极指南:MediaCMS无缝集成第三方系统——SAML认证与API对接全攻略
终极指南:MediaCMS无缝集成第三方系统——SAML认证与API对接全攻略 【免费下载链接】mediacms MediaCMS is a modern, fully featured open source video and media CMS, written in Python/Django and React, featuring a REST API. 项目地址: https://gitcode.c…...

如何让每首歌曲都拥有完美的歌词同步体验
如何让每首歌曲都拥有完美的歌词同步体验 【免费下载链接】LDDC 简单易用的精准歌词(逐字歌词/卡拉OK歌词)下载匹配工具|A simple and user-friendly tool for downloading and matching precise lyrics (word-by-word lyrics/Karaoke lyrics) 项目地址: https://gitcode.com…...
)
FPGA数字时钟设计进阶:如何优化你的Verilog代码(以Vivado为例)
FPGA数字时钟设计进阶:如何优化你的Verilog代码(以Vivado为例) 当你的FPGA数字时钟项目已经能够正常运行,却发现代码冗长、维护困难时,是时候考虑代码优化了。本文将带你从初级实现跃升到专业级设计,通过Ve…...

从代码到灶台:测试思维在厨房的降维打击
作为一名软件测试工程师,我习惯于用边界值分析、异常流覆盖和迭代优化思维拆解系统问题。当这种思维迁移到厨房,一场关于“炒菜算法”的重构悄然开始——V1.0基础版:最小可行菜品(MVP)的诞生就像测试需先建立基础用例,我的厨艺从番…...

Arduino ESP32开发板终极安装指南:从零开始快速上手物联网开发 [特殊字符]
Arduino ESP32开发板终极安装指南:从零开始快速上手物联网开发 🚀 【免费下载链接】arduino-esp32 Arduino core for the ESP32 项目地址: https://gitcode.com/GitHub_Trending/ar/arduino-esp32 还在为ESP32开发板安装配置而烦恼吗?…...

TensorFlow Lite 实战宝典:解锁移动端AI部署的五大核心策略
1. 模型量化:让AI模型在移动端"瘦身"的魔法 第一次把ResNet50模型塞进手机时,我盯着那个178MB的大家伙直发愁——这体积都快赶上半个App了!直到发现TensorFlow Lite的量化工具,才明白原来模型也能像减肥一样"瘦身&…...

中文文本查重不求人:StructBERT相似度计算WebUI快速上手指南
中文文本查重不求人:StructBERT相似度计算WebUI快速上手指南 你是不是经常遇到这样的烦恼?面对一堆用户评论,不知道哪些是重复的;客服系统里,用户问的问题千奇百怪,但知识库里的标准答案就那么几个&#x…...

Tabula:从PDF数据囚笼到结构化自由的革命性解放工具
Tabula:从PDF数据囚笼到结构化自由的革命性解放工具 【免费下载链接】tabula Tabula is a tool for liberating data tables trapped inside PDF files 项目地址: https://gitcode.com/gh_mirrors/ta/tabula 在信息爆炸的时代,PDF文档已成为数据交…...

安卓加固被破解怎么办?揭秘性能下降与源码泄露风险的真实原因
在选择安卓加固服务时,企业决策者最担心的几个问题往往是:花了钱,方案会不会很快被绕过?加固后,APP会不会变得又卡又慢甚至崩溃?把源码上传到云端加固,数据安全如何保障?这些并非杞人…...