【MySQL】InnoDB存储引擎详解
InnoDB引擎是MySQL5.5版本之后默认的存储引擎
逻辑存储结构
首先是表空间Tablespace(ibd文件):一个mysql实力可以对应多个表空间,用于存储及记录,索引等数据
这些存储记录,索引等数据中是用段(Segment)来存储的
段分为
- 数据段(Leaf node segment)
- 索引段(Non-leaf node segment)
- 回滚段(Rollback segment)
InnoDB是索引组织表,数据段就是B+树的叶子节点,索引段即为B+树的非叶子节点
段用来管理多个区(Extent)
区:表空间的单元结构,每个区为1MB,默认情况下,InnoDB存储引擎页的大小是16KB,即一个区中又64个页(Page)
页:是InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认是16KB,为了保证页的连续性,InnoDB存储引擎每次从磁盘申请4-5个区
页中存放的是行Row,InnoDB存储引擎数据是按行进行存放的
如表中的隐藏字段:
Trx_id:每次对某条记录进行改动时,都会把对应的十五id赋值给trx_id隐藏列
Roll_pointer:每次对某条印记路进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列相当于一个指针,同故宫他来找到该记录修改前的信息
架构
InnoDB引擎是MySQL5.5版本之后默认的存储引擎,他擅长事务处理,具有崩溃恢复特性,在日常中使用非常广泛
首先介绍InnoDB的内存结构
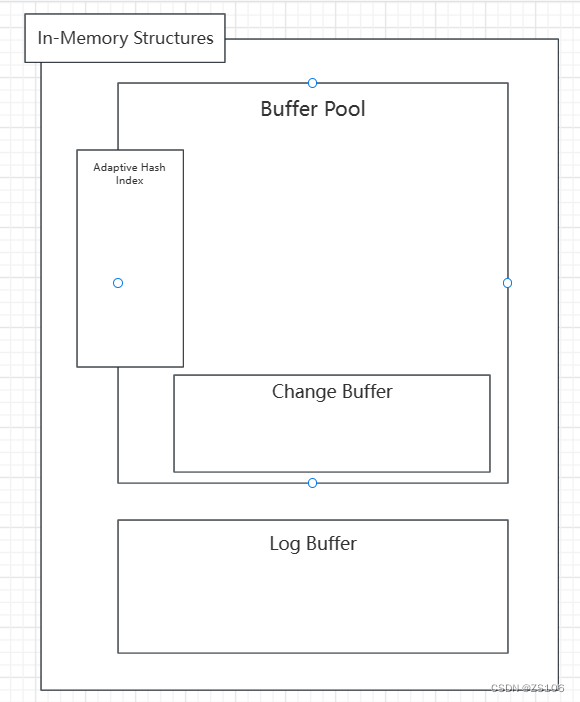
Buffer Pool:
缓冲池时主内存的区域,里面可以缓存磁盘上经常操作的真实区域,在执行CRUD操作时,前操作缓存池中的数据(如果没有,那么久从磁盘上加载并且缓存),然后再以一定频率刷新到磁盘,从而减少磁盘IO,加快处理速度
这么做的原因是,如果每次都是磁盘操作,那么就会出现大量的磁盘IO,而且是随机IO,这样非常消耗性能
缓冲池以Page页为单位,底层采用链表数据结构管理Page,根据状态,将Page分为三种类型
- free page:空闲page ,未被使用过
- clean page:被使用过,但是数据没修改
- dirty page:脏页,被使用过page,数据被修改过,与磁盘内的数据不一致
Change Buffer:
更改缓冲区(针对于非唯一二级缓存页),5.x的版本是一个叫Insert Buffer的东西,8.0才出现的
再执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接操作磁盘,而会将数据变更存在更改缓冲区Change Buffer中,在未来数据被读取时,再将数据合并恢复到缓冲池中,再将合并后的数据刷到磁盘上
Change Buffer的意义:
与聚集索引不同,二级索引通常是非唯一的,并且相对随机的顺序插入二级索引,同样,删除和更新可能会影响所引述中不相邻的二级索引页,如果每一次都操作磁盘,会造成大量的磁盘IO,有了ChangeBuffer之后,我们在缓冲池中进行合并处理,减少IO
Adaptive Hash Index:
自适应Hash索引,用于优化对Buffer Pool数据的查询,InnoDB存储引擎会监控对表上各索引的插叙,如果换查到hash索引可以提升速度,则建立hash索引,称为自适应hash索引
自适应哈希索引无需人工干预,是系统根据情况自动完成
Log Buffer
日志缓冲区,用来保存要写入到磁盘中的log日志数据(redo log,undo log),默认大小为16MB,日志缓冲区的日知会定期刷新到磁盘中,如果需要更新,插入或删除许多行的事务,增加日志缓冲区的大小可以节省磁盘IO;
可以配置缓冲区大小和日志刷新到磁盘的时机
磁盘结构
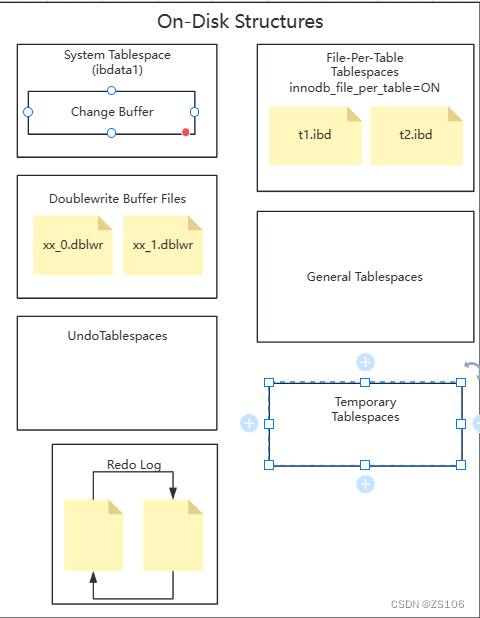
System Tablespace:
系统表空间是更改缓冲区的存储区域,如果是在系统表空间而不是每个表文件或通用表文件创建的,他也可能包含表和索引数据,(在5.X版本中还包含InnoDB数据词典,undolog等)
File-Per-Table Tablespaces:
每个表的文件表空间包含单个InnoDB表的数据和索引,兵存储在文件系统上的单个数据文件中
General Tablespace:
通用表空间,是手动创建的而不是系统自带的,需要通过CREATE TABLESPACE语法创建通用表空间,在创建时,可以指定该表空间
如:
# 创建一个通用表空间ts_xx, 这个表空间对应的磁盘文件xxx.ibd
create tablespace ts_xx add datafile 'xxx.ibd' engine = innodb;# 创建一个表xxx,他的表空间是上面创建的ts_xx
create table xxx(id long primary key auto_increment , name varchar(20)) engine = innodb tablespace ts_xx;
Undo Tablespaces
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志
Temporary Tablespaces
InnoDB使用绘画临时表空间和全局临时表空间,存储用户创建的临时表等数据
Doublewrite Buffer Files:
双写缓冲区,innoDB引擎将数据页从Buffer Pool刷新到磁盘前,先将数据页写入双鞋缓冲区文件中,便于系统异常时恢复数据
Redo Log:
重做日志,是用来实现事务的持久性,该日志文件由两部分组成:重做日志缓冲(redo log buffer) 以及重做日志文件(redo log),前者时在内存中,后者在磁盘中。当事务提交之后会把所有修改信息都会存到该日志中,用于在刷新脏页到磁盘时,发生错误后进行数据回复
事务持久性依赖于该日志
分别介绍了内存和磁盘结构,那么就需要把两个结构连接起来,而后台线程就是把他们连接起来的工具
后台线程
后台线程的作用就是把InnoDB存储引擎缓冲池的数据在合适的时间刷新到磁盘文件中
后台线程分为四种
1. Master Thread:
核心后台线程,负责调度其他线程,还负责将缓冲池中的数据异步刷新到磁盘中,保持数据的一致性,还包括脏页的刷新,合并插入缓存,undo页的回收
2. IO Thread:
在InnoDB存储引擎中大量使用了AIO(异步非阻塞)来处理IO请求,这样可以极大地提高数据库的性能,而IO Thread主要负责这些IO请求的回调
IO Thread又包括四种
- Read Thread: 负责读操作,默认4个
- Write Thread:负责写操作,页默认4个
- Log Thread:负责将日志缓冲区刷新到磁盘,默认1个
- Insert Buffer Thread:负责将缓冲区内容刷新到磁盘,默认1个
下面是如何查看状态
show engine innodb status;
然后直接去找FILE I/O就可以看到IO线程了
3. Purge Thread
主要用于回收事务已经提交了的undo log ,在十五提交之后,undo log 可能不用了,就用它来回收
4. Page Cleaner Thread
协助 Master Thread 刷新脏页到磁盘的线程,可以减轻MT的工作压力,减少阻塞
InnoDB事务的原理
InnoDB引擎很重要的一个功能就是支持了事务
事务:是一组操作的集合,他是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,及这些操作要么同时成功,要么同时失败
事务的四大特性:ACID
原子性(Atomicity): 事务时不可分割的最小单元,同时成功或同时失败
一致性(Consistency): 事务完成时,必须使所有的数据都保持一致状态
隔离性(Isolation): 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
持久性(Durability): 事务一旦提交或回滚,他对数据库中的数据改变就是永久的
隔离性又涉及到了隔离级别:读未提交,读已提交,可重复读,串行化,默认可重复读
事务的原理
对于原子性,一致性,持久性来说,在InnoDB中是由redo log 和 undo log来保证的
隔离性是由锁机制和MVCC(多版本并发控制)来保证的
redo log保证持久性
redo log :重做日志记录的事务提交时数据页的物理修改,使用来实现事务的持久性的
该日志文件由两部分组成:重做日志缓冲(redo log buffer),以及重做日志文件(redo log),前者是在内存中,后者在磁盘中
当事务提交之后会把所有修改信息都存到日志文件中,用于刷新脏页到磁盘,发生错误时,进行数据恢复使用
过程
当事务的请求发送给数据库时,首先会看看内存的缓冲池有没有相对的数据,没有的话要去磁盘里面读出来加载到缓存中
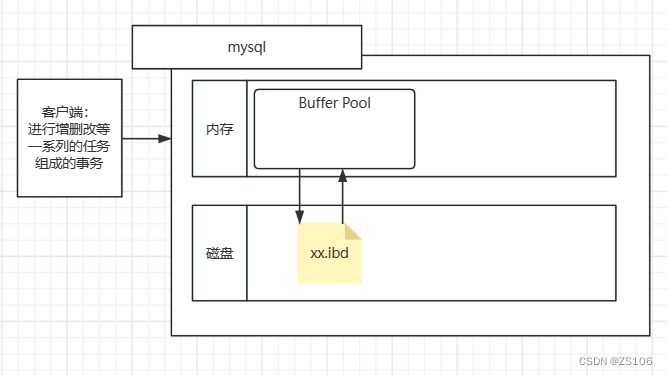
当缓存池中,页的数据被进行了更改,就会形成脏页,会在下次对磁盘进行读写的时候给更改进去
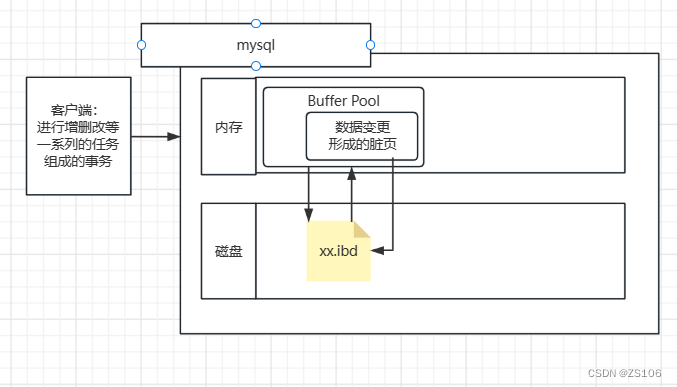
但如果,脏页的数据刷新到磁盘的过程出错了,此时内存数据没刷新进去,但是事务已经提交了,这时候 - 由于磁盘数据与事务的数据不同,那么持久性就没得到保证
为了保证事务一致性,就出现了redo log,与刚才的直接提交的操作不同,他会先把脏页给到内存中的Redolog Buffer一份
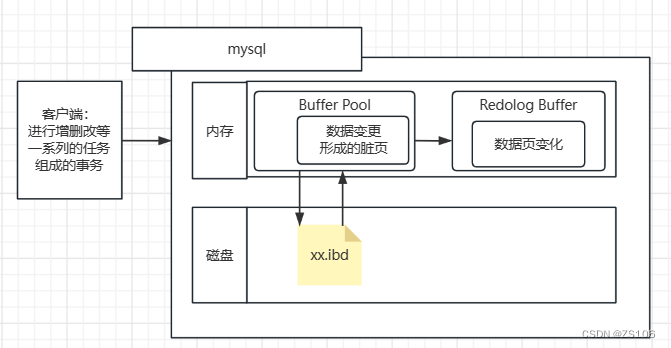
当客户端事务提交之后,RedologBuffer会向磁盘内提交数据页变化,持久性的保持在磁盘文件中
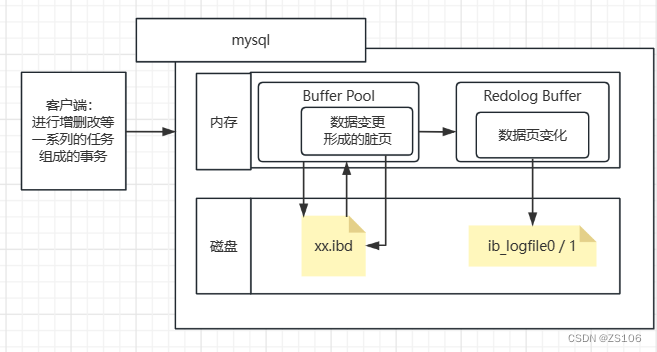
在这之后,如果脏页刷新到磁盘文件失败的话,他可以通过redo log来进行恢复
事务提交时直接刷新ibd和直接redolog记录这个过程看似相同,但其实有很大的差别:
在事务中,我们的操作大多都是随机操作各个数据页的,这其中涉及到了大量的随即磁盘IO,很耗费性能,而log日志时顺序记录的,即顺序磁盘IO,这两者之间相差了很大的性能
这种机制叫做WAL(Write-Ahead Logging)
因为脏页早晚都会正常写入,所以log里就会有很多无用的日志,这时候就需要定时清理,两个log文件循环记录
Undo Log 解决事务原子性
undo log:回滚日志,用于记录数据被修改前的信息,作用有两个:提供回滚和MVCC
undolog 和redolog记录物理日志不一样,他记录的是逻辑日志:
比如我写了一条delete,删除id为1的数据,那么undolog记录的则是相反的,插入一条id为1的数据,数据的内容就是删除的内容
比如我写了一条update ,把id为2的姓名从李四改成张三,那么undolog记录的就是 update - 把id为2的人的姓名改成李四
当执行rollback时,就直接调用对应的undolog,从而实现了内容的回滚。
Undo log销毁:undo log 在事务执行时产生,事务提交时,并不会立即删除undolog,因为这些日志还可能会用在MVCC中
Undo log存储:undo log采用段的方式进行管理和记录,存放在rollback segment回滚段中,其中包含了1024个undo log segment;
MVCC
当前读:读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁
比如:select lock in share mode,insert,delete
快照读:读取的是记录数据的可见版本,有可能是历史数据,不加锁,是非阻塞读
Read Committed:每次select 都生成一个快照都
Repeatable Read:开启事务后第一个select语句才是快照读的地方
Serializable:快照读都会退化为当前读
MVCC:
全程Multi-Version Concurrency Control ,多版本并发控制,指维护一个数据的多个版本,是的读写操作没有冲突,快照都为MySQL实现MVCC提供了一个非阻塞读的功能
MVCC的具体实现,还需要依赖于数据库记录的三个隐式字段,undolog,readView
MVCC实现原理
记录当中的隐藏字段:
DB_TRX_ID: 最近修改十五ID,记录插入这条记录或最后一次修改该记录的事务ID
DB_ROLL_PTR:回滚指针,指向这条记录的上一个版本,用于配合undo log ,指向下一个版本
DB_ROLL_ID: 隐藏主键,如果表结构没有指定主键,将会生成该隐藏字段
看表结构的方法:
ibd2sdi xx.ibd;
当然也可以用navicat直接看
undo log版本链:
不同或相同事务对同一条数据进行修改,会导致该记录的undolog生成一条记录版本链表,链表的头部是最新的旧记录,尾部是最早的旧记录
而具体要返回哪个版本,需要有readview决定
readview:
读视图,是快照读sql执行时MVCC提取数据的依据,记录并维护系统当前活跃的事务(也就是未提交的事务)id
readview有四个核心字段:
m_ids: 当前活跃的事务ID集合
min_trx_id: 最小活跃事务ID
max_trx_id: 预分配事务ID,也就是当前最大事务ID+1
creator_trx_id: ReadView创建者的事务ID
版本链数据访问规则:
我们令当前事务ID为trx_id
- trx_id == creator_trx_id ? 可以访问该版本 -> 成立则说明数据是这个事务更改的
- trx_id < min_trx_id ? 可以访问该版本 -> 成立则说明该数据已经提交过了
- trx_id > max_trx_id ? 不可以访问该版本 -> 成立则说明该事务时在readview生成之后才开启的
- min_trx_id <= trx_id < max_trx_id ? 如果trx_id不在m_ids中是可以访问该版本的 -> 成立则说明数据已经提交了
不同隔离级别,生成readview的实际不同
读已提交:在事务中每次执行快照读时生成readview
可重复读:仅在事务中第一次执行快照读时生成readview,后续复用该readview
用readview生成后得到的四个核心字段,带入到上面的判断是否能访问的公式中,然后从undolog版本链由上到下依次寻找,那个版本符合就可以访问哪个版本
这就是MVCC,在快照读的时候决定使用哪个版本
而MVCC加上锁,就保证了数据的隔离性
而一致性是由redo log 和 undo log共同保证的
相关文章:
【MySQL】InnoDB存储引擎详解
InnoDB引擎是MySQL5.5版本之后默认的存储引擎 逻辑存储结构 首先是表空间Tablespace(ibd文件):一个mysql实力可以对应多个表空间,用于存储及记录,索引等数据 这些存储记录,索引等数据中是用段(Segment)来…...

组合求和-矩阵连乘所有加括号方式_2023_08_12
矩阵链加括号方式总数 前言 矩阵链乘积的瓶颈在于其标量运算的次数,不同的结合次序对其时间性能影响远大于矩阵乘积运算本身,可以看到许多教材上把求解矩阵标量运算的最优解作为动态规划的示例,问题隐含动态规划两大特征: 最优子…...
《3D 数学基础》12 几何图元
目录 1 表达图元的方法 1.1 隐式表示法 1.2 参数表示 1.3 直接表示 2. 直线和射线 2.1 射线的不同表示法 2.1.1 两点表示 2.1.2 参数表示 2.1.3 相互转换 2.2 直线的不同表示法 2.2.1 隐式表示法 2.2.2 斜截式 2.2.3 相互转换 3. 球 3.1 隐式表示 1 表达图元的方…...
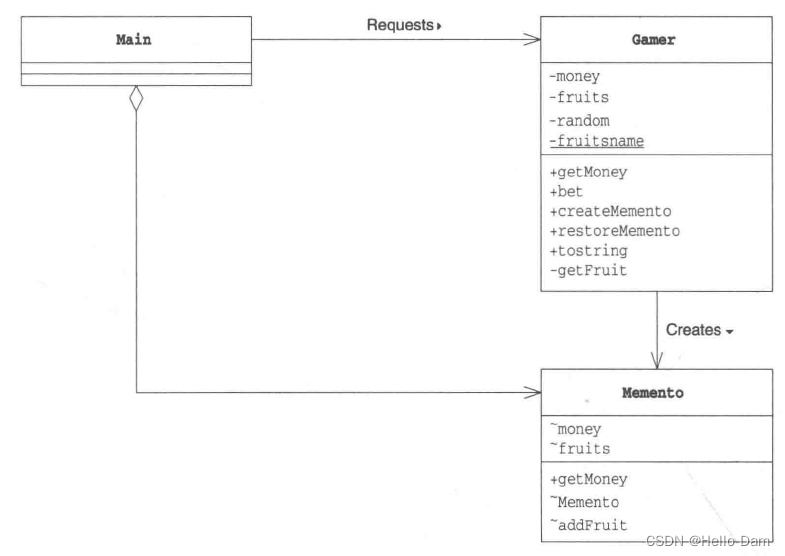
【设计模式——学习笔记】23种设计模式——备忘录模式Memento(原理讲解+应用场景介绍+案例介绍+Java代码实现)
案例引入 游戏角色有攻击力和防御力,在大战Boss前保存自身的状态(攻击力和防御力),当大战Boss后攻击力和防御力下降,可以从备忘录对象恢复到大战前的状态 传统设计方案 针对每一种角色,设计一个类来存储该角色的状态 【分析】…...
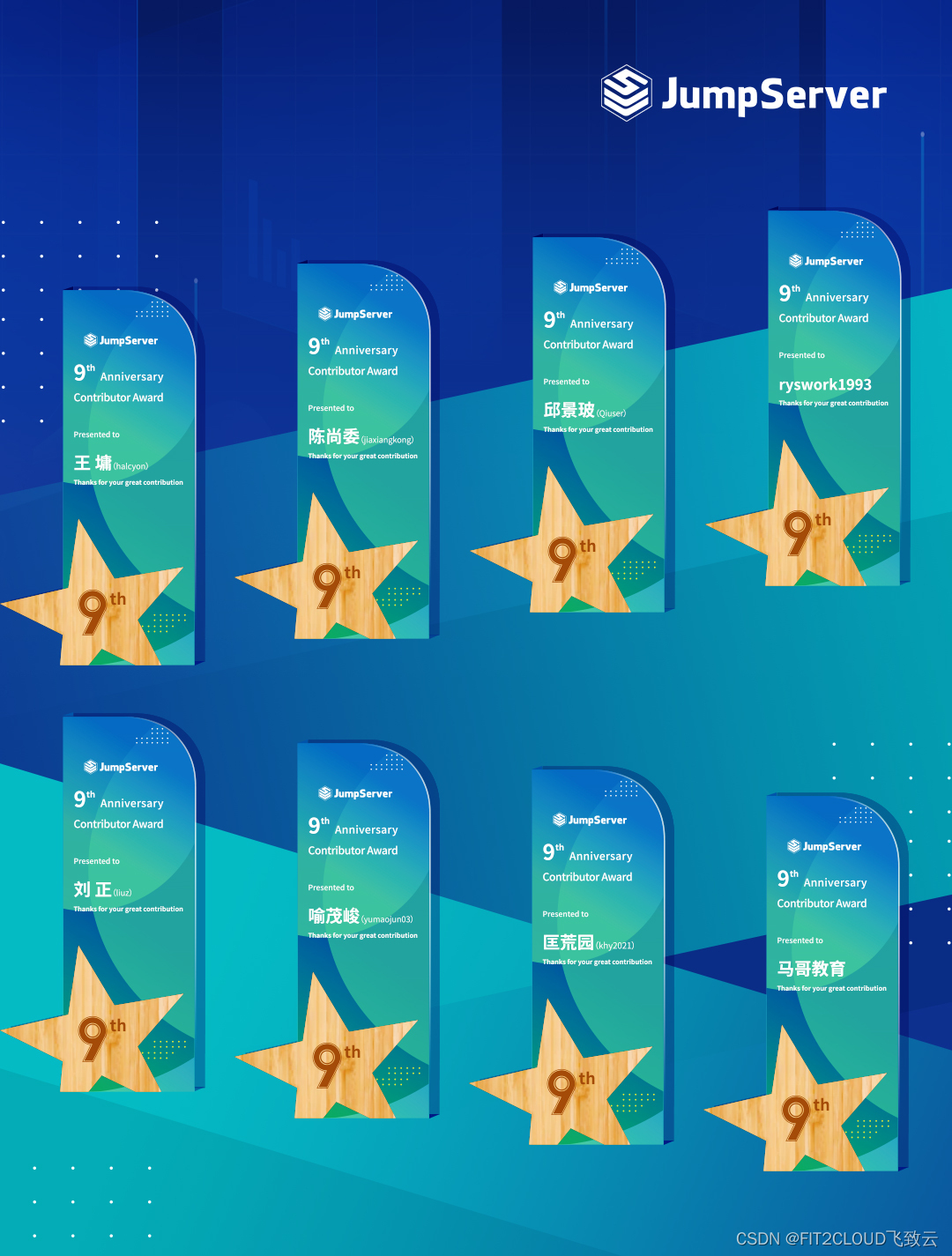
致谢丨感谢有你,JumpServer开源项目九周年致谢名单
2014年到2023年,JumpServer开源项目已经走过了九年的时间。感谢以下社区贡献者对JumpServer项目的帮助和支持。 因为有你,一切才能成真。 JumpServer开源项目贡献者奖杯将于近日邮寄到以上贡献者手中,同时JumpServer开源项目组还准备了一份小…...
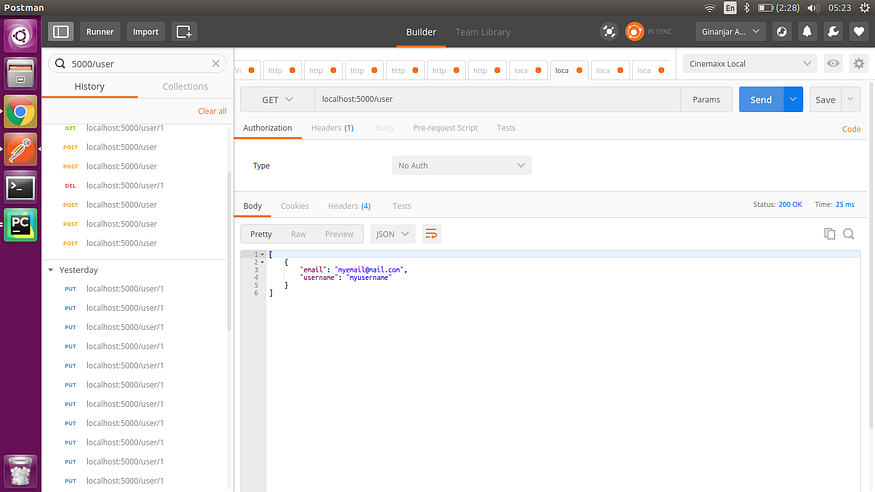
使用 Python 和 Flask 构建简单的 Restful API 第 1 部分
一、说明 我将把这个系列分成 3 或 4 篇文章。在本系列的最后,您将了解使用flask构建 restful API 是多么容易。在本文中,我们将设置环境并创建将显示“Hello World”的终结点。 我假设你的电脑上安装了python 2.7和pip。我已经在python 2.7上测试了本文…...
)
【深度学习所有损失函数】在 NumPy、TensorFlow 和 PyTorch 中实现(2/2)
一、说明 在本文中,讨论了深度学习中使用的所有常见损失函数,并在NumPy,PyTorch和TensorFlow中实现了它们。 (二-五)见 六、稀疏分类交叉熵损失 稀疏分类交叉熵损失类似于分类交叉熵损失,但在真实标签作为整数而不是独热编码提…...

Hazel 引擎学习笔记
目录 Hazel 引擎学习笔记学习方法思考引擎结构创建工程程序入口点日志系统Premake\MD没有 cpp 文件的项目会出错include 到某个库就要包含这个库的路径,注意头文件展开 事件系统 获取和利用派生类信息预编译头文件抽象窗口类和 GLFWgit submodule addpremake 脚本禁…...
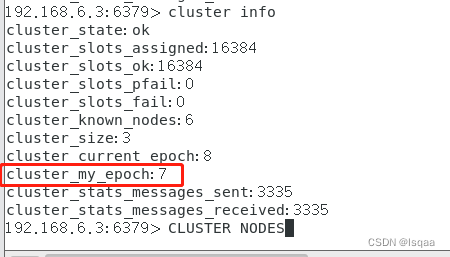
Linux系统下Redis3.2集群
本节主要学习reids主从复制的概念,作用,缺点,流程,搭建,验证,reids哨兵模式的概念,作用,缺点,结构,搭建,验证等。 文章目录 一、redis主从复制 …...
Android图形-合成与显示-SurfaceTestDemo
目录 引言: 主程序代码: 结果呈现: 小结: 引言: 通过一个最简单的测试程序直观Android系统的native层Surface的渲染显示过程。 主程序代码: #include <cutils/memory.h> #include <utils/L…...

高压放大器怎么设计(高压放大器设计方案)
高压放大器是一种用于将低电压信号转换成高电压信号的电子设备,广泛应用于通信、雷达、医疗设备等领域。在设计高压放大器时,需要考虑多种因素,如输入输出信号的特性、电路结构的选择、电源和负载匹配等。本文将介绍高压放大器的设计方法和注…...

SpringBoot yml配置注入
yaml语法学习 1、配置文件 SpringBoot使用一个全局的配置文件 , 配置文件名称是固定的 application.properties 语法结构 :keyvalue application.yml 语法结构 :key:空格 value 配置文件的作用:修改SpringBoot自动…...

中科亿海微乘法器(LPMMULT)
引言 FPGA(可编程逻辑门阵列)是一种可在硬件级别上重新配置的集成电路。它具有灵活性和可重构性,使其成为处理各种应用的理想选择,包括数字信号处理、图像处理、通信、嵌入式系统等。在FPGA中,乘法器是一种重要的硬件资…...
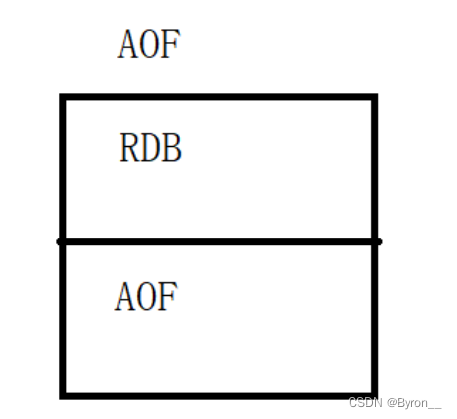
Redis_持久化(AOF、RDB)
6. Redis AOF 6.1 简介 目前,redis的持久化主要应用AOF(Append Only File)和RDF两大机制,AOF以日志的形式来记录每个写操作(增量保存),将redis执行过的所有指令全部安全记录下来(读…...
开源数据库Mysql_DBA运维实战 (部署服务篇)
前言❀ 1.数据库能做什么 2.数据库的由来 数据库的系统结构❀ 1.数据库系统DBS 2.SQL语言(结构化查询语言) 3.数据访问技术 部署Mysql❀ 1.通过rpm安装部署Mysql 2.通过源码包安装部署Mysql 前言❀ 1.数据库能做什么 a.不论是淘宝,吃鸡,爱奇艺…...
【Java学习】System.Console使用
背景 在自学《Java核心技术卷1》的过程中看到了对System.Console的介绍,编写下列测试代码, public class ConsoleTest {public static void main(String[] args) {Console cs System.console();String name cs.readLine("AccountInfo: ");…...

从零学算法154
154.已知一个长度为 n 的数组,预先按照升序排列,经由 1 到 n 次 旋转 后,得到输入数组。例如,原数组 nums [0,1,4,4,5,6,7] 在变化后可能得到: 若旋转 4 次,则可以得到 [4,5,6,7,0,1,4] 若旋转 7 次&#…...

95 | Python 设计模式 —— 策略模式
策略模式(Strategy Pattern) 引言 策略模式是一种行为型设计模式,它定义了一系列的算法,并将每个算法封装在独立的策略类中,使得这些算法可以相互替换,而不影响客户端的使用。策略模式可以让客户端根据不同的需求选择不同的算法,从而使得系统更加灵活和可扩展。 在本…...
)
【BASH】回顾与知识点梳理(十九)
【BASH】回顾与知识点梳理 十九 十九. 循环 (loop)19.1 while do done, until do done (不定循环)19.2 for...do...done (固定循环)19.3 for...do...done 的数值处理(C写法)19.4 搭配随机数与数组的实验19.5 shell script 的追踪与 debug19.6 what_to_eat-2.sh debug结果解析 该…...
Selenium之css怎么实现元素定位?
世界上最远的距离大概就是明明看到一个页面元素站在那里,但是我却定位不到!! Selenium定位元素的方法有很多种,像是通过id、name、class_name、tag_name、link_text等等,但是这些方法局限性太大, 随着自动…...

中兴光猫配置解密工具完整使用指南:5分钟快速上手与深度配置
中兴光猫配置解密工具完整使用指南:5分钟快速上手与深度配置 【免费下载链接】ZET-Optical-Network-Terminal-Decoder 项目地址: https://gitcode.com/gh_mirrors/ze/ZET-Optical-Network-Terminal-Decoder ZET-Optical-Network-Terminal-Decoder是一款专为…...

从手机芯片到自动驾驶:算力单位TOPS/MACs/FLOPS是如何影响你每天使用的技术的?
从手机芯片到自动驾驶:算力单位如何塑造你的数字生活? 清晨的闹钟响起时,你拿起手机用面部识别解锁,语音助手根据指令调整空调温度,通勤路上汽车自动保持车道——这些场景背后都有一场看不见的算力博弈。当我们谈论TO…...

终极指南:如何用免费开源CAD软件LitCAD快速上手二维绘图
终极指南:如何用免费开源CAD软件LitCAD快速上手二维绘图 【免费下载链接】LitCAD A very simple CAD developed by C#. 项目地址: https://gitcode.com/gh_mirrors/li/LitCAD LitCAD是一款基于C#开发的轻量级开源二维CAD绘图平台,为初学者和设计爱…...

Maven配置翻车实录:从JDK15降级到1.8,我的Maven为何‘记忆’犹新?附3.8.4修复方案
Maven环境变量疑难解析:当JDK降级遭遇版本记忆效应 那天深夜,我的IDE突然弹出一连串红色错误——一个早已卸载的JDK15居然阴魂不散地干扰着当前项目。明明系统环境变量显示JAVA_HOME指向JDK1.8,java -version命令也确认运行在1.8环境…...

JavaScript中对象属性存在的四种检测方法性能评估
检测自有属性用hasOwnProperty()最常用高效,检测自有继承属性用in操作符最自然;避免Object.keys().includes()因性能差且语义冗余;安全场景用Object.prototype.hasOwnProperty.call()。在 JavaScript 中检测对象属性是否存在,常用…...

FreeRTOS软件定时器实战避坑:从CubeMX配置到内存溢出排查全记录
FreeRTOS软件定时器深度实战:从CubeMX配置到内存优化全解析 在嵌入式开发中,定时器是控制时序逻辑的核心组件。当硬件定时器资源捉襟见肘时,FreeRTOS提供的软件定时器功能往往能解燃眉之急。但看似简单的API背后,却隐藏着内存管理…...

5分钟快速上手:使用Vectorizer将PNG/JPG转换为高质量SVG的终极指南
5分钟快速上手:使用Vectorizer将PNG/JPG转换为高质量SVG的终极指南 【免费下载链接】vectorizer Potrace based multi-colored raster to vector tracer. Inputs PNG/JPG returns SVG 项目地址: https://gitcode.com/gh_mirrors/ve/vectorizer 想要将PNG或JP…...

华硕笔记本终极控制指南:用G-Helper完全取代臃肿的Armoury Crate
华硕笔记本终极控制指南:用G-Helper完全取代臃肿的Armoury Crate 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF,…...

胆管癌肿瘤免疫微环境特征及免疫治疗策略综述
一、胆管癌概述及其免疫治疗背景胆管癌(Cholangiocarcinoma, CCA)是一种起源于胆管上皮系统的恶性肿瘤,具有高度的异质性。根据肿瘤发生部位,CCA可分为肝内胆管癌(Intrahepatic cholangiocellular carcinoma, iCCA&…...

测试111111111
测试...