【深度学习】PyTorch快速入门
【深度学习】学习PyTorch基础

介绍PyTorch
深度学习框架是一种软件工具,旨在简化和加速构建、训练和部署深度学习模型的过程。深度学习框架提供了一系列的函数、类和工具,用于定义、优化和执行各种深度神经网络模型。这些框架帮助研究人员和开发人员专注于模型的设计和创新,而无需过多关注底层的数值计算和优化。
主要的深度学习框架通常具有以下特点:
- 图计算表示: 深度学习框架通常使用图计算来表示神经网络模型,其中节点表示操作,边表示数据流向。这种表示方式有助于优化计算和自动求导。
- 自动微分: 深度学习框架提供自动微分功能,允许用户计算模型中各个参数的梯度,从而进行反向传播和优化。
- 模块化设计: 框架允许用户将神经网络分解为模块,如层(层)、激活函数、优化器等,从而可以灵活地构建和修改模型。
- 优化器: 深度学习框架提供了多种优化算法,如随机梯度下降(SGD)、Adam 等,用于在训练过程中调整模型参数以最小化损失函数。
- 硬件加速: 多数深度学习框架支持使用图形处理单元(GPU)进行加速,这能够显著提升训练和推断性能。
- 预训练模型: 一些框架提供了预训练的模型,这些模型在大型数据集上进行了训练,可以用作迁移学习的起点。
- 部署和推断: 框架通常提供能够将训练好的模型部署到生产环境中的功能,以进行推断和应用。
常见的深度学习框架包括 TensorFlow、PyTorch、Keras、Caffe、MXNet 等。
PyTorch 是一个备受欢迎的开源机器学习库,由 Facebook 的人工智能研究小组开发并维护。它在深度学习领域中被广泛使用,特别适合研究和开发新的神经网络模型,以及进行实验和原型开发。其安装方式请参考官网教程。
张量操作
导入库
import torch
创建张量
创建一个空的张量(包含未初始化的随机值)
empty_tensor = torch.empty(3, 2) # 创建一个3行2列的空张量
创建一个随机初始化的张量
random_tensor = torch.rand(3, 2) # 创建一个3行2列的随机张量,值在0到1之间
创建一个全零的张量
zeros_tensor = torch.zeros(3, 2) # 创建一个3行2列的全零张量
创建一个全一的张量
ones_tensor = torch.ones(3, 2) # 创建一个3行2列的全一张量
从现有数据创建张量
data = [[1, 2], [3, 4]]
tensor_from_data = torch.tensor(data) # 从Python列表创建张量
张量计算
tensor1 = torch.tensor([[1, 2], [3, 4]])
tensor2 = torch.tensor([[5, 6], [7, 8]])# 加法
result_add = tensor1 + tensor2
# tensor([[ 6, 8],
# [10, 12]])# 减法
result_sub = tensor1 - tensor2
# tensor([[-4, -4],
# [-4, -4]])# 乘法(逐元素相乘)
result_mul = tensor1 * tensor2
# tensor([[ 5, 12],
# [21, 32]])# 矩阵乘法
result_matmul = torch.matmul(tensor1, tensor2)
# tensor([[19, 22],
# [43, 50]])
张量索引和切片
tensor = torch.tensor([[1, 2, 3], [4, 5, 6], [7, 8, 9]])# 获取单个元素
element = tensor[1, 2] # 获取第2行第3列的元素,注意索引从0开始
# tensor(6)# 切片操作
slice = tensor[0:2, 1:3] # 获取第1行和第2行,第2列和第3列的切片
# tensor([[2, 3],
# [0, 6]])# 修改元素
tensor[1, 1] = 0 # 将第2行第2列的元素设置为0
# tensor([[1, 2, 3],
# [4, 0, 6],
# [7, 8, 9]])
张量形状操作
tensor = torch.tensor([[1, 2, 3], [4, 5, 6]])# 获取张量的形状
shape = tensor.shape # 返回一个元组,表示张量的形状
# torch.Size([2, 3])# 改变张量的形状
reshaped_tensor = tensor.view(3, 2) # 将原来的2行3列张量转换为3行2列
# tensor([[1, 2],
# [3, 4],
# [5, 6]])
自动微分
PyTorch 的自动微分(Automatic Differentiation)是其在深度学习中的一大亮点,它使得构建和训练神经网络变得更加便捷。自动微分允许你计算函数的导数,特别适用于反向传播算法,它是训练神经网络的核心。
梯度计算和反向传播
在 PyTorch 中,你可以在需要求导的张量上调用 .requires_grad_() 方法,将其标记为需要计算梯度。之后,所有在这个张量上执行的操作都会被记录,以便后续计算梯度。
import torch# 创建一个张量,并标记为需要计算梯度
x = torch.tensor([2.0], requires_grad=True)# 执行一些操作
y = x**2 + 3*x + 1# 计算 y 对 x 的梯度
y.backward()# 输出梯度
print(x.grad) # 输出:tensor([7.]),即 y = x**2 + 3*x + 1 对 x 的导数
在上述示例中,我们创建了一个张量 x,并标记它需要计算梯度。然后我们执行一些操作来计算 y,并使用 y.backward() 计算关于 x 的梯度。最终,我们使用 x.grad 获取梯度值。
上下文管理器 torch.no_grad()
有时候,在进行推断(不需要梯度计算)时,你可以使用 torch.no_grad() 上下文管理器,从而避免不必要的梯度计算,提高性能。
with torch.no_grad():# 在这个上下文中,所有操作都不会计算梯度# 适用于不需要反向传播的情况,如模型推断pass
使用自动微分进行优化
自动微分在优化算法中的应用非常广泛。你可以使用优化器来自动地更新模型参数,以最小化损失函数。
import torch.optim as optim# 创建一个需要优化的张量
weights = torch.tensor([1.0], requires_grad=True)# 定义损失函数
loss_fn = torch.nn.MSELoss()# 创建优化器,如随机梯度下降(SGD)
optimizer = optim.SGD([weights], lr=0.01)# 进行多轮优化
for _ in range(100):optimizer.zero_grad() # 清零梯度predictions = weights * 3 # 假设的模型预测loss = loss_fn(predictions, torch.tensor([10.0])) # 计算损失loss.backward() # 计算梯度optimizer.step() # 更新参数
在上面的示例中,我们首先创建了一个需要优化的权重张量,并定义了损失函数和优化器。在每轮循环中,我们将梯度清零,计算预测,计算损失,然后通过调用 backward() 计算梯度。最后,使用 optimizer.step() 来更新权重。
总之,PyTorch 的自动微分使得计算梯度变得非常简便,为神经网络的训练和优化提供了强大的支持。
利用自动微分梯度下降案例
首先需要计算函数关于自变量的梯度,然后迭代更新自变量以逐步逼近最小值。
import torch
import math# 初始化自变量 x
x = torch.tensor([0.0], requires_grad=True)# 定义优化器,使用随机梯度下降(SGD)
optimizer = torch.optim.SGD([x], lr=0.1)# 定义迭代次数
num_iterations = 1000for i in range(num_iterations):optimizer.zero_grad() # 清零梯度y = x**2 - torch.sin(x) # 定义函数 y = x^2 - sin(x)y.backward() # 计算梯度optimizer.step() # 更新 x# 最终的 x 就是函数的最小值点
minimum = x.item()# 计算最小值对应的 y
minimum_value = minimum**2 - math.sin(minimum)print(f"最小值点:x = {minimum:.4f}, y = {minimum_value:.4f}")
# 最小值点:x = 0.4502, y = -0.2325
在上述代码中,我们首先初始化自变量 x,并使用 SGD 优化器进行梯度下降。在每次迭代中,我们计算函数值 y,然后通过调用 backward() 计算梯度,并使用 optimizer.step() 更新自变量 x。最终,我们可以得到函数的最小值点和对应的最小值。
数据加载和预处理
数据加载
首先,你需要将原始数据加载到内存中。数据可以是图像、文本、音频等类型。PyTorch 提供了 torch.utils.data.Dataset 类来帮助你自定义数据集。
torch.utils.data.Dataset 类: 这个类是一个抽象类,你可以通过继承它来创建自定义数据集。你需要实现 __len__ 方法和 __getitem__ 方法,分别用于获取数据集大小和获取单个样本。
假设你有一组包含图像文件和对应标签的数据,你可以按照以下步骤创建一个自定义的数据集类:
import torch
from torch.utils.data import Dataset
from PIL import Image # 用于图像读取
import osclass CustomDataset(Dataset):def __init__(self, data_dir, transform=None):self.data_dir = data_dirself.transform = transformself.images, self.labels = self.load_data()def load_data(self):# 获取图像文件列表和标签image_list = sorted(os.listdir(os.path.join(self.data_dir, 'images')))label_list = sorted(os.listdir(os.path.join(self.data_dir, 'labels')))images = [os.path.join(self.data_dir, 'images', img) for img in image_list]labels = [os.path.join(self.data_dir, 'labels', lbl) for lbl in label_list]return images, labelsdef __len__(self):return len(self.images)def __getitem__(self, idx):img_path = self.images[idx]lbl_path = self.labels[idx]image = Image.open(img_path)label = torch.load(lbl_path)if self.transform:image = self.transform(image)return image, label
数据预处理
一般来说,原始数据需要经过一些预处理才能被用于模型训练。预处理可能包括图像缩放、剪裁、标准化、数据增强等。PyTorch 提供了各种转换函数,可以在加载数据时对其进行预处理。
torchvision.transforms 模块: 这个模块提供了许多用于图像预处理的函数,比如图像缩放、剪裁、翻转、标准化等。你可以将这些函数应用于数据集的样本。
import torch
from torchvision import transforms
from PIL import Image# 定义数据预处理的转换
transform = transforms.Compose([transforms.Resize((128, 128)), # 将图像缩放为 128x128transforms.RandomHorizontalFlip(), # 随机水平翻转transforms.ToTensor(), # 将图像转换为张量transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]) # 标准化
])# 读取图像
image = Image.open('path_to_image.jpg')# 应用预处理转换
transformed_image = transform(image)
在上面的代码示例中,我们首先导入了 transforms 模块。然后,我们定义了一个数据预处理的转换序列,其中包括了图像缩放、随机水平翻转、转换为张量和标准化。接着,我们使用 Image.open 从文件中读取了一个图像,然后使用 transform 对图像进行预处理。
你可以根据需要组合不同的预处理操作,以适应你的任务和数据集。torchvision.transforms 模块提供了多种函数,如图像剪裁、色彩变换、随机增强等,可以在数据加载前对图像进行灵活的处理。
数据加载器
为了高效地训练模型,你可以使用 torch.utils.data.DataLoader 类,它可以将预处理后的数据划分为小批次,进行随机或顺序加载,同时还可以提供多线程加载。
torch.utils.data.DataLoader 类: 这个类将数据集包装成一个可迭代的对象,每次返回一个小批次的数据。你可以设置批次大小、随机化、多线程等参数。
以下是一些 DataLoader 的常见参数和用法:
pythonCopy codeimport torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 定义数据预处理的转换
transform = transforms.Compose([transforms.Resize((128, 128)),transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])# 创建数据集
dataset = datasets.ImageFolder(root='path_to_dataset', transform=transform)# 创建数据加载器
dataloader = DataLoader(dataset, batch_size=32, shuffle=True, num_workers=4)
在上面的示例中,我们首先定义了数据预处理的转换。然后,我们使用 datasets.ImageFolder 创建了一个图像数据集。接下来,我们使用 DataLoader 创建了一个数据加载器。参数解释如下:
dataset: 你想要加载的数据集。batch_size: 每个批次包含的样本数量。shuffle: 是否在每个 epoch 中随机化数据顺序。num_workers: 加载数据时使用的线程数。
接下来,你可以通过迭代 dataloader 来获取每个批次的数据进行训练:
for batch_images, batch_labels in dataloader:# 在这里进行模型训练pass
在循环中,每个 batch_images 和 batch_labels 都是一个批次的图像和对应的标签。
DataLoader 类在实际训练中非常有用,可以帮助你有效地加载和处理数据,使训练过程更加高效。
构建神经网络
PyTorch 提供了多种方法来构建神经网络,以适应不同的需求和编程风格。
1.继承 nn.Module
这是创建自定义神经网络的常见方法。你可以创建一个类继承自 nn.Module,然后在构造函数中定义网络的层和参数,以及在 forward 方法中定义数据的前向传播过程。这种方法允许你自由地定义和组合各种层。
import torch
import torch.nn as nnclass CustomModel(nn.Module):def __init__(self):super(CustomModel, self).__init__()self.layer1 = nn.Linear(in_features=784, out_features=128)self.layer2 = nn.Linear(in_features=128, out_features=10)def forward(self, x):x = self.layer1(x)x = torch.relu(x)x = self.layer2(x)return x
2.使用 nn.Sequential
这是一种更简单的方法,适用于顺序层的堆叠。你可以使用 nn.Sequential 来创建一个网络,其中每个层按顺序连接。
import torch
import torch.nn as nnmodel = nn.Sequential(nn.Linear(in_features=784, out_features=128),nn.ReLU(),nn.Linear(in_features=128, out_features=10)
)
3.自定义层
除了使用 nn.Module 创建网络,你还可以自定义层。你可以继承 nn.Module 并实现自己的层的前向传播。
import torch
import torch.nn as nnclass CustomLayer(nn.Module):def __init__(self, in_features, out_features):super(CustomLayer, self).__init__()self.weights = nn.Parameter(torch.randn(in_features, out_features))self.bias = nn.Parameter(torch.randn(out_features))def forward(self, x):return torch.matmul(x, self.weights) + self.bias
4.使用预训练模型
PyTorch 提供了许多预训练的模型,如 VGG、ResNet、BERT 等。你可以使用这些模型作为基础,进行微调或迁移学习。
import torch
import torchvision.models as modelsmodel = models.resnet18(pretrained=True)
num_features = model.fc.in_features
model.fc = nn.Linear(num_features, 10)
训练神经网络模型
模型训练的主要步骤
在 PyTorch 中训练神经网络模型涉及到以下主要步骤:
- 选择网络架构: 首先,你需要选择适合你任务的神经网络架构。你可以使用 PyTorch 提供的预训练模型,也可以自定义网络。
- 定义损失函数: 根据你的问题类型,选择适当的损失函数,如均方误差(MSE)、交叉熵损失(CrossEntropyLoss)等。
- 选择优化器: 选择一个优化算法,如随机梯度下降(SGD)、Adam 等。你可以设置学习率和其他超参数。
- 数据加载: 使用
torch.utils.data.Dataset和torch.utils.data.DataLoader加载和处理训练数据。 - 训练循环: 在训练循环中,你需要进行以下操作:
- 遍历数据加载器,获取输入数据和对应标签。
- 将数据送入网络,得到预测结果。
- 计算损失,反向传播计算梯度。
- 使用优化器更新网络参数。
- 验证: 在训练过程中,你可以定期使用验证数据集评估模型性能,以避免过拟合。
- 保存和加载模型: 在训练完成后,你可以保存模型的权重和参数,以便在未来进行推断或继续训练。
以下是一个基本的训练循环示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms# 数据预处理和加载
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
])
train_dataset = datasets.CIFAR10(root='data', train=True, transform=transform, download=True)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)# 定义网络
class CustomModel(nn.Module):def __init__(self):super(CustomModel, self).__init__()# 定义网络结构# ...def forward(self, x):# 前向传播# ...model = CustomModel()# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)# 训练循环
for epoch in range(num_epochs):for inputs, labels in train_loader:optimizer.zero_grad() # 清零梯度outputs = model(inputs) # 前向传播loss = criterion(outputs, labels) # 计算损失loss.backward() # 反向传播optimizer.step() # 更新参数# 在每个 epoch 结束后,可以进行验证、保存模型等操作
损失函数模块
在 PyTorch 中,损失函数(也称为目标函数)用于度量模型预测与实际标签之间的差异。它是模型训练的关键部分,通过优化损失函数来调整模型的参数,使得模型的预测更加接近真实值。PyTorch 提供了许多常见的损失函数,适用于不同类型的任务。
以下是一些常见的 PyTorch 损失函数:
-
nn.MSELoss: 均方误差损失函数,适用于回归问题。它计算预测值与真实值之间的平方差。criterion = nn.MSELoss() loss = criterion(predictions, targets) -
nn.CrossEntropyLoss: 交叉熵损失函数,适用于多类别分类问题。通常用于分类问题的输出不经过 softmax 激活函数。criterion = nn.CrossEntropyLoss() loss = criterion(predictions, labels) -
nn.BCELoss和nn.BCEWithLogitsLoss: 二元交叉熵损失函数,用于二元分类问题。BCELoss需要在预测值上手动应用 sigmoid 函数,而BCEWithLogitsLoss同时包括 sigmoid 和交叉熵计算。criterion = nn.BCEWithLogitsLoss() loss = criterion(predictions, labels) -
nn.NLLLoss: 负对数似然损失函数,通常与nn.LogSoftmax结合使用,适用于多类别分类问题。criterion = nn.NLLLoss() log_probs = nn.LogSoftmax(dim=1)(predictions) loss = criterion(log_probs, labels) -
自定义损失函数: 你也可以根据任务的特性定义自己的损失函数,只需继承
nn.Module并实现前向传播。
class CustomLoss(nn.Module):def __init__(self):super(CustomLoss, self).__init__()def forward(self, predictions, targets):# 自定义损失计算逻辑return loss_value
注意,选择正确的损失函数取决于任务的性质。不同的损失函数适用于不同的问题类型,你需要根据问题的特点来选择合适的损失函数。
优化器模块
在 PyTorch 中,优化器是用于更新神经网络模型参数以最小化损失函数的工具。PyTorch 提供了多种优化器,每个优化器都使用不同的更新规则来调整模型的参数,以使模型能够更好地拟合训练数据。以下是一些常见的 PyTorch 优化器:
torch.optim.SGD: 随机梯度下降(SGD)优化器是一种基本的优化算法。它在每次迭代中使用每个训练样本的梯度来更新模型参数。
import torch.optim as optim
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
torch.optim.Adam: Adam 优化器结合了自适应学习率和动量的特点,适用于多种问题。它在许多情况下表现良好。
import torch.optim as optim
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
torch.optim.RMSprop: RMSprop 优化器使用移动平均的方式来调整学习率,适用于非平稳目标。
import torch.optim as optim
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate)
- 自定义优化器: 你也可以根据需要定义自己的优化器,只需继承
torch.optim.Optimizer并实现必要的方法。
class CustomOptimizer(optim.Optimizer):def __init__(self, params, lr=0.01):super(CustomOptimizer, self).__init__(params, defaults)# 自定义初始化逻辑def step(self, closure=None):# 自定义参数更新逻辑pass
在训练循环中,你需要执行以下操作来更新模型参数:
optimizer.zero_grad() # 清零梯度
outputs = model(inputs) # 前向传播
loss = criterion(outputs, labels) # 计算损失
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新参数
在实际应用中,选择正确的优化器取决于问题的性质,不同的优化器可能会在不同的任务中表现更好。
保存和加载模型
在 PyTorch 中,你可以使用 torch.save 函数来保存模型的权重、参数和其他相关信息,以及使用 torch.load 函数来加载保存的模型。以下是保存和加载模型的示例代码:
保存模型
import torch# 定义模型
class CustomModel(torch.nn.Module):def __init__(self):super(CustomModel, self).__init__()self.fc = torch.nn.Linear(10, 2)def forward(self, x):return self.fc(x)model = CustomModel()# 保存模型权重和参数
torch.save(model.state_dict(), 'model.pth')
在上面的代码中,我们定义了一个简单的模型 CustomModel,然后使用 model.state_dict() 将模型的权重和参数保存到文件 model.pth 中。
加载模型
import torch# 定义模型
class CustomModel(torch.nn.Module):def __init__(self):super(CustomModel, self).__init__()self.fc = torch.nn.Linear(10, 2)def forward(self, x):return self.fc(x)model = CustomModel()# 加载模型权重和参数
model.load_state_dict(torch.load('model.pth'))
model.eval() # 设置模型为评估模式
在上面的代码中,我们定义了相同的模型结构 CustomModel,然后使用 torch.load 加载之前保存的权重和参数文件 model.pth。注意,加载后的模型需要调用 .eval() 方法来将模型设置为评估模式,以便在推断时使用。
请注意,当你加载模型时,模型的结构也需要保持一致。如果你的模型结构发生了变化,可能需要手动调整或者重新定义模型的结构。
完整项目案例
MNIST数据集是一个经典的手写数字图像数据集,包含了大量0到9的单个手写数字图像样本,每个图像都有对应的标签表示其所代表的数字。这个数据集广泛用于测试和验证机器学习算法,特别是图像分类算法的性能。每个图像都是28x28像素大小的灰度图像,被展平成一维向量,使其适用于各种机器学习模型。
使用卷积神经网络(CNN)来解决MNIST手写数字数据集分类问题的过程涉及数据预处理,构建卷积层、池化层和全连接层的网络结构,定义损失函数和优化器进行模型训练,在训练集上通过梯度下降优化参数,最终在测试集上评估模型性能,以得出一个在数字分类上表现良好的卷积神经网络模型。
下面是一个使用PyTorch的简单卷积神经网络(CNN)模型来解决MNIST手写数字数据集分类问题的基本步骤:
步骤 1: 导入必要的库和模块
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
步骤 2: 准备数据集
# 定义数据预处理的转换
transform = transforms.Compose([transforms.ToTensor(), # 将图像转换为Tensortransforms.Normalize((0.5,), (0.5,)) # 标准化,将像素值映射到[-1, 1]
])# 下载并加载MNIST数据集
train_dataset = torchvision.datasets.MNIST(root='./data', train=True, transform=transform, download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)test_dataset = torchvision.datasets.MNIST(root='./data', train=False, transform=transform, download=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=64, shuffle=False)
步骤 3: 定义卷积神经网络模型
class SimpleCNN(nn.Module):def __init__(self):super(SimpleCNN, self).__init__()self.conv1 = nn.Conv2d(1, 16, kernel_size=3, padding=1)self.pool = nn.MaxPool2d(kernel_size=2, stride=2)self.fc1 = nn.Linear(16 * 14 * 14, 128)self.fc2 = nn.Linear(128, 10)def forward(self, x):x = self.pool(nn.functional.relu(self.conv1(x)))x = x.view(-1, 16 * 14 * 14)x = nn.functional.relu(self.fc1(x))x = self.fc2(x)return x# 创建模型实例
model = SimpleCNN()
步骤 4: 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器
步骤 5: 训练模型
num_epochs = 10for epoch in range(num_epochs):for i, (images, labels) in enumerate(train_loader):optimizer.zero_grad() # 梯度清零outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
步骤 6: 测试模型
model.eval() # 将模型切换到评估模式
correct = 0
total = 0with torch.no_grad():for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the network on the 10000 test images: {100 * correct / total}%')
这个简单的卷积神经网络模型将会在MNIST数据集上实现一个基本的手写数字分类器。你可以根据需要进行更多的调整、优化和改进,例如增加更多的卷积层、调整超参数、添加正则化等来提升性能。
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}')
步骤 6: 测试模型```python
model.eval() # 将模型切换到评估模式
correct = 0
total = 0with torch.no_grad():for images, labels in test_loader:outputs = model(images)_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).sum().item()print(f'Accuracy of the network on the 10000 test images: {100 * correct / total}%')
这个简单的卷积神经网络模型将会在MNIST数据集上实现一个基本的手写数字分类器。你可以根据需要进行更多的调整、优化和改进,例如增加更多的卷积层、调整超参数、添加正则化等来提升性能。
相关文章:
【深度学习】PyTorch快速入门
【深度学习】学习PyTorch基础 介绍PyTorch 深度学习框架是一种软件工具,旨在简化和加速构建、训练和部署深度学习模型的过程。深度学习框架提供了一系列的函数、类和工具,用于定义、优化和执行各种深度神经网络模型。这些框架帮助研究人员和开发人员专注…...

学习Vue:组件通信
组件化开发在现代前端开发中是一种关键的方法,它能够将复杂的应用程序拆分为更小、更可管理的独立组件。在Vue.js中,父子组件通信是组件化开发中的重要概念,同时我们还会讨论其他组件间通信的方式。 父子组件通信:Props 和 Events…...

springboot项目打包后读取jar包里面的
ResourcePatternResolver resourcePatternResolver new PathMatchingResourcePatternResolver(); Resource[] resources resourcePatternResolver.getResources("classpath*:templates/*.*"); for ( Resource resource : resources ) {//获取文件,在打成…...

设计模式之七大原则
👑单一职责原则 单一职责原则告诉我们一个类应该只有一个责任或者只负责一件事情。 想象一下,如果一个类承担了太多的责任,就像一个人同时负责做饭、洗衣服和打扫卫生一样,那么这个类会变得非常复杂,难以理解和维护。而…...
pytorch入门-TensorBoard和Transforms
TensorBoard from PIL import Image from torch.utils.tensorboard import SummaryWriter from torchvision import transforms# python的用法 -》 tensor数据类型 # 通过transforms.ToTensor 去解决两个问题 # 1. transforms该如何使用(python) # 2. …...

【java】Java基础——接口和实现
当一个类实现一个接口时,必须提供接口中定义的所有方法的具体实现,除非这个类是抽象类。默认方法:default修饰接口中的方法,可实现方法体,在实现接口的类中可以不重写该方法 // 定义一个接口,接口不关心方…...

JetPack Compose 学习笔记(持续整理中...)
1.为什么要学? 1.命令式和声明式 UI大战,个人认为命令式UI自定义程度较高,能更深入到性能,内存优化方面,而申明式UI 是现在主流的设计,比如React,React Native,Flutter,Swift UI等等,现在性能也逐渐在变得更好 2.还有一个原因compose 是KMM 是完整跨平台的UI基础 3.…...

遍历集合List的五种方法以及如何在遍历集合过程中安全移除元素
一、遍历集合List的五种方法 测试数据 List<String> list new ArrayList<>(); list.add("A");list.add("B");list.add("C");1. 普通for循环 普通for循环,通过索引遍历 for (int i 0; i < list.size(); i) {Syst…...

【SQL应知应会】索引(二)• MySQL版
欢迎来到爱书不爱输的程序猿的博客, 本博客致力于知识分享,与更多的人进行学习交流 本文收录于SQL应知应会专栏,本专栏主要用于记录对于数据库的一些学习,有基础也有进阶,有MySQL也有Oracle 索引 • MySQL版 前言一、索引1.简介2.创建2.1 索引…...

Android 简单的视频、图片压缩工具
首页需要压缩的工具包 1.Gradle implementation com.iceteck.silicompressorr:silicompressor:2.2.3 2.添加相关权限(手机得动态申请权限) <uses-permission android:name"android.permission.READ_EXTERNAL_STORAGE"/> <uses-p…...

信息论、推理和机器学习算法之间交叉的经典例子
信息论、推理和机器学习算法之间交叉的经典例子: 熵和信息增益在决策树学习中的应用。信息增益利用熵的概念来评估特征的分类能力,从而指导决策树的增长。 交叉熵在神经网络训练中的广泛使用。它结合信息论与最大似然推断,用于度量预测分布与真实分布之间的距离。 变分推断常被…...
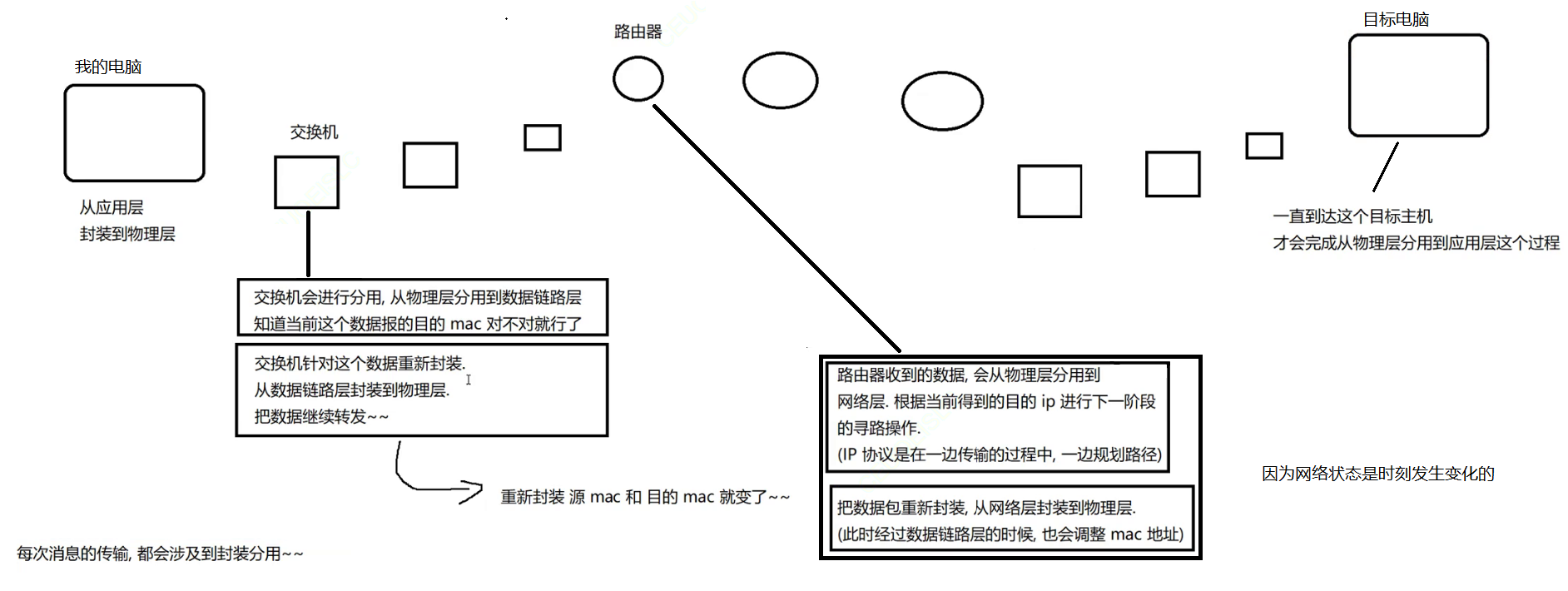
【多线程】网络原理初识
网络原理初识 1. 网络发展史1.2 独立模式1.3 网络互联1.3 局域网1.4 广域网 2. 网络通信基础2.1 IP地址2.2 端口号2.3 认识协议2.4 五元组2.5 协议分层2.5.1 什么是协议分层2.5.2 协议分层的好处2.5.2 OSI七层模型2.5.3 TCP/IP五层模型 2.6 封装和分用2.6.1 封装2.6.1.1 应用层…...

Android之ADB常用命令
15、查看ipv6 是否使能 sysctl -a | grep ipv6 | grep disable 13、以太网获取Ip、网关、子网掩码、域名等 adb shell 网卡信息:ifconfig eth0 dns1:getprop net.dns1 dns2:getprop net.dns2 12、屏幕分辨率:wm size 11、…...
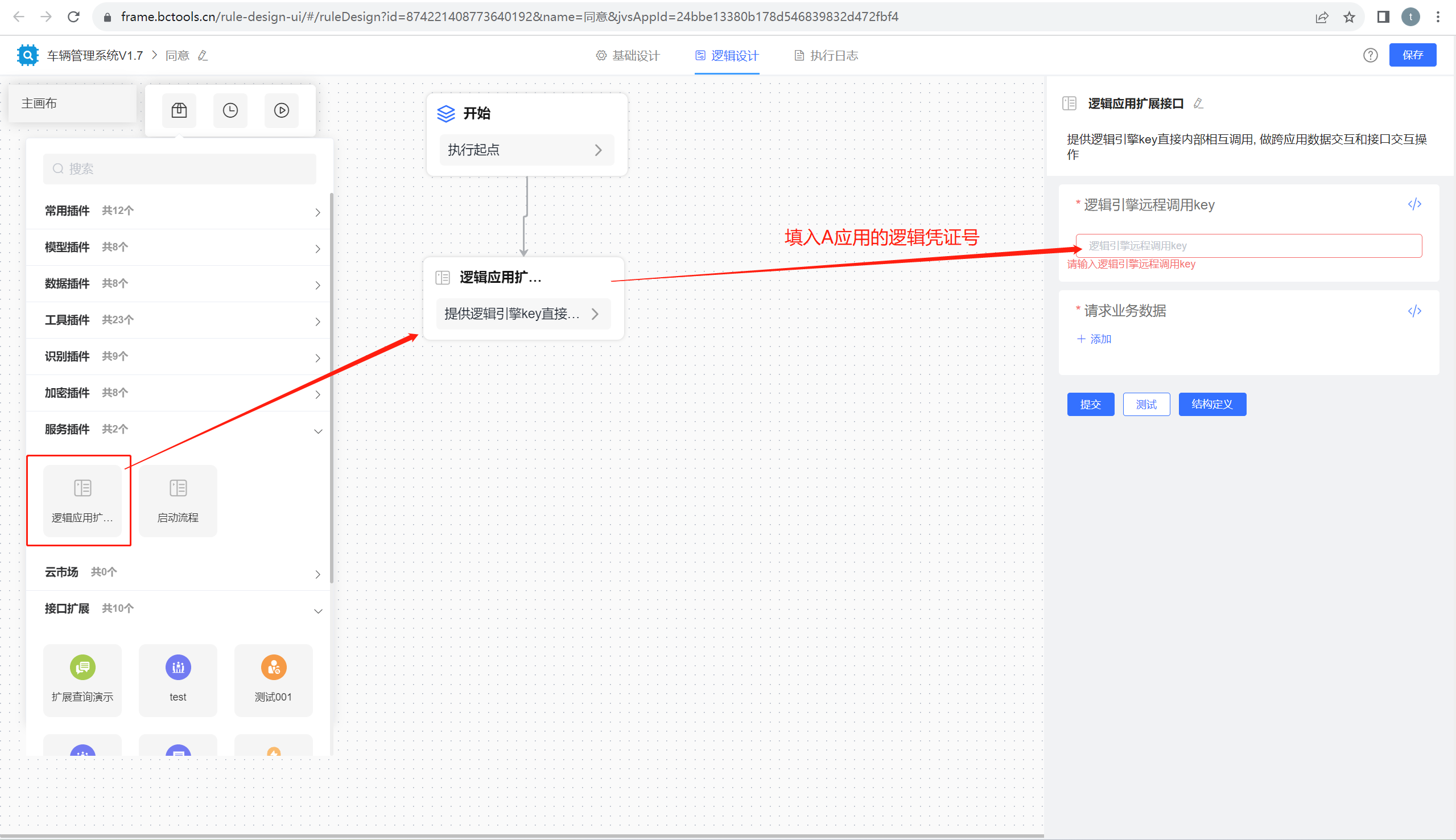
低代码开发工具:JVS轻应用之间如何实现数据的调用?
在低代码开发平台中,如何实现应用之间的数据共享呢?最标准的方式是通过接口,本文介绍JVS轻应用如何实现将数据通过API输出、轻应用如何实现体内API数据的获取?实现方式如下图所示,不管是数据提供方,还是数据…...
在Java中对XML的简单应用
XML 数据传输格式1 XML 概述1.1 什么是 XML1.2 XML 与 HTML 的主要差异1.3 XML 不是对 HTML 的替代 2 XML 语法2.1 基本语法2.2 快速入门2.3 组成部分2.3.1 文档声明格式属性 2.3.2 指令(了解):结合CSS2.3.3 元素2.3.4 属性**XML 元素 vs. 属…...

Linu学习笔记——常用命令
Linux 常用命令全拼: Linux 常用命令全拼 | 菜鸟教程 一、切换root用户 1.给root用户设置密码 sudo passwd root 2.输入密码,并确认密码 3.切换到root用户 su:Swith user(切换用户) su root 二、切换目录 目录结构:Linux 系…...
PLUS操作流程、应用与实践,多源不同分辨率数据的处理、ArcGIS的应用、PLUS模型的应用、InVEST模型的应用
PLUS模型是由中国地质大学(武汉)地理与信息工程学院高性能空间计算智能实验室开发,是一个基于栅格数据的可用于斑块尺度土地利用/土地覆盖(LULC)变化模拟的元胞自动机(CA)模型。PLUS模型集成了基于土地扩张分析的规则挖掘方法和基于多类型随机…...
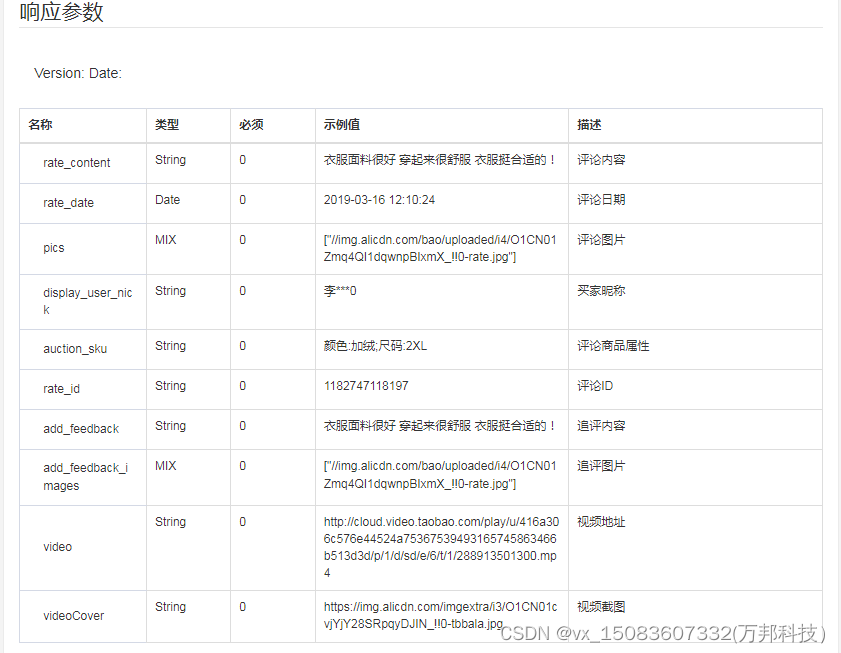
item_review-获得淘宝商品评论
一、接口参数说明: item_review-获得淘宝商品评论,点击更多API调试,请移步注册API账号点击获取测试key和secret 公共参数 请求地址: https://api-gw.onebound.cn/taobao/item_review 名称类型必须描述keyString是调用key(点击获…...
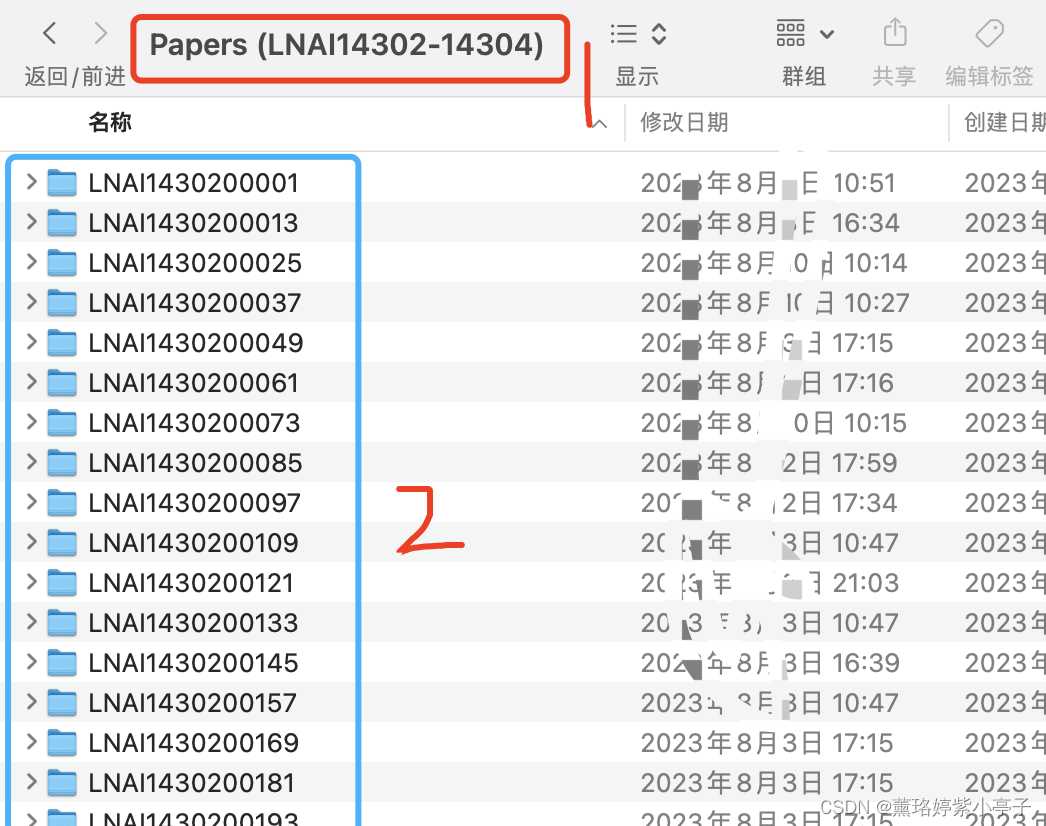
如何读取文件夹内的诸多文件,并选择性的保留部分文件
目录 问题描述: 问题解决: 问题描述: 当前有一个二级文件夹,第一层是文件夹名称是“Papers(LNAI14302-14304)",第二级文件夹目录名称如下图蓝色部分所示。第三层为存放的文件,如下下图所示,每一个文件中,均存放三个文件,分别为copyright.pdf, submission.pdf, s…...
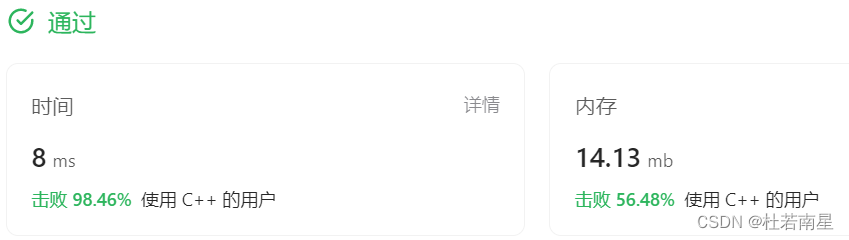
每天一道leetcode:1129. 颜色交替的最短路径(图论中等广度优先遍历)
今日份题目: 给定一个整数 n,即有向图中的节点数,其中节点标记为 0 到 n - 1。图中的每条边为红色或者蓝色,并且可能存在自环或平行边。 给定两个数组 redEdges 和 blueEdges,其中: redEdges[i] [ai, bi…...

HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器
HiveWE终极指南:快速掌握魔兽争霸III现代化地图编辑器 【免费下载链接】HiveWE A Warcraft III world editor. 项目地址: https://gitcode.com/gh_mirrors/hi/HiveWE 还在为传统魔兽争霸III地图编辑器缓慢的加载速度和复杂的操作界面而烦恼吗?Hiv…...

独立开发者利用taotoken模型广场为不同任务选择性价比最优模型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 独立开发者利用taotoken模型广场为不同任务选择性价比最优模型 对于独立开发者而言,在有限的预算内高效完成多样化的开…...

WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件
WarcraftHelper:让魔兽争霸3在现代电脑上完美运行的关键插件 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 你是否还在为《魔兽争霸3》这…...

Godot 2D随机地图三大静默故障:黑屏、穿墙、寻路失败的根源与修复
1. 为什么刚上手Godot做2D随机地图就总卡在“生成出来是黑的”“角色穿墙”“房间连不通”这三件事上?如果你是刚从Unity或GameMaker转来Godot,或者第一次用GDScript写程序逻辑的新手,大概率已经在2D随机地图生成这个环节反复摔过跟头——不是…...

掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南
掌握OpenCore Legacy Patcher:3步让老旧Mac焕发新生的实用指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher OpenCore Legacy Patcher是一款开源…...

服务器数据下载安全:实时加密与动态访问控制实战
1. 这不是又一个“加个密码”的方案,而是服务器数据流动的实时安检闸机IP-guard安全网关——这个名字在企业IT运维圈里,常被误读为“桌面端U盘管控工具”或“员工上网行为审计系统”。但真正用过它来守服务器的人,会立刻意识到:它…...

免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南
免费解锁AMD Ryzen隐藏性能:SMUDebugTool终极指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcod…...

5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南
5分钟掌握AutoClicker:Windows鼠标点击自动化的终极指南 【免费下载链接】AutoClicker AutoClicker is a useful simple tool for automating mouse clicks. 项目地址: https://gitcode.com/gh_mirrors/au/AutoClicker AutoClicker是一款专为Windows设计的鼠…...

UE5 GPU崩溃终极解决方案:Windows TDR注册表调优指南
1. 这不是玄学,是显卡驱动与UE引擎的底层握手失败 你刚点下Play,编辑器还没完全加载完场景,屏幕突然黑一下,然后弹出“GPU has stopped responding and has recovered”——或者更糟,直接蓝屏、黑屏死机、编辑器无响应…...

别再只会用spline了!MATLAB csape函数详解:从自然边界到夹持边界的实战选择
MATLAB csape函数深度解析:从自然边界到夹持边界的工程实践 在工程仿真和科学计算领域,数据插值是一个永恒的话题。当我们面对一组离散的实验数据或仿真结果时,如何构建一条光滑的曲线来准确反映数据背后的物理规律?这个问题困扰…...