TTS | VocGAN声码器训练自己的数据集
哈喽,今天给大家介绍的是如何使用VocGAN声码器训练自己的数据集。
原文
VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network
想要论文解读,请参考我的这篇文章~
本博客主要包括以下内容:
目录
1.环境设置
2.数据集处理
2.1.数据集LJSpeech
2.2.数据集KSS
3.训练数据集
3.1.训练LJSpeech
4.训练自定义数据集
推理
过程中遇到的错误及解决
【PS1】AttributeError: module 'torch._C' has no attribute 'DoubleStorageBase'
【PS2】AssertionError: sample rate mismatch. expected 22050, got 48000 at /workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/wavs/72.wav
【PS3】ValueError: num_samples should be a positive integer value, but got num_samples=0
扩展
1.环境设置
git clone https://github.com/rishikksh20/VocGAN
cd VocGANconda create -n gan python=3.8
conda activate gan
pip install -r requirements.txt- 下载数据集进行训练。这可以是任何采样率为 22050Hz 的 wav 文件。(论文中使用了LJSpeech)
- 预处理:
python preprocess.py -c config/default.yaml -d [data's root path] - 编辑配置
yaml文件
修改preprocess.py中的配置文件和数据集路径
2.数据集处理
2.1.数据集LJSpeech
新建一个文件夹data,下载数据集LJSpeech,然后解压缩,新建一个mels文件夹.可参考【LJSpeech数据集下载】13100个语音

python preprocess.py -c config/ljs.yaml -d /workspace/tts/VocGAN/data/LJSpeech-1.1/wavs 运行后出现

然后进入下一步3.训练数据集
2.2.数据集KSS
在kss文件夹下新建了文件夹valid,mels
data: # root path of train/validation data (either relative/absoulte path is ok)train: '/workspace/tts/Fastspeech2-Korean/data/kss/wavs_bak'validation: '/workspace/tts/Fastspeech2-Korean/data/kss/valid'mel_path: '/workspace/tts/Fastspeech2-Korean/data/kss/mels'eval_path: ''
---
train:rep_discriminator: 1discriminator_train_start_steps: 100000num_workers: 8batch_size: 16optimizer: 'adam'adam:lr: 0.0001beta1: 0.5beta2: 0.9
---
audio:n_mel_channels: 80segment_length: 16000pad_short: 2000filter_length: 1024hop_length: 256 # WARNING: this can't be changed.win_length: 1024sampling_rate: 22050mel_fmin: 0.0mel_fmax: 8000.0
---
model:feat_match: 10.0lambda_adv: 1use_subband_stft_loss: Falsefeat_loss: Falseout_channels: 1generator_ratio: [4, 4, 2, 2, 2, 2] # for 256 hop size and 22050 sample ratemult: 256n_residual_layers: 4num_D : 3ndf : 16n_layers: 3downsampling_factor: 4disc_out: 512stft_loss_params:fft_sizes: [1024, 2048, 512] # List of FFT size for STFT-based loss.hop_sizes: [120, 240, 50] # List of hop size for STFT-based losswin_lengths: [600, 1200, 240] # List of window length for STFT-based loss.window: "hann_window" # Window function for STFT-based loss
subband_stft_loss_params:fft_sizes: [384, 683, 171] # List of FFT size for STFT-based loss.hop_sizes: [30, 60, 10] # List of hop size for STFT-based losswin_lengths: [150, 300, 60] # List of window length for STFT-based loss.window: "hann_window" # Window function for STFT-based loss
---
log:summary_interval: 1validation_interval: 5save_interval: 20chkpt_dir: 'chkpt'log_dir: 'logs'
然后运行
python preprocess.py -c config/default.yaml -d /workspace/tts/Fastspeech2-Korean/data/kss/wavs_bak如果出错,请参考【PS1】
3.训练数据集
3.1.训练LJSpeech
复制VocGAN/config/default.yaml,改名为ljs.yaml
修改ljs.yaml中数据(data)中,train的路径和validation的路径(这俩是必须的,eval为空也可以)
所以要把数据集进行划分训练集和验证集,进入data文件夹下新建splitdata.py
import os
import randomdef main():random.seed(0) # 设置随机种子,保证随机结果可复现files_path = "/workspace/tts/VocGAN/data/LJSpeech-1.1/wavs"assert os.path.exists(files_path), "path: '{}' does not exist.".format(files_path)val_rate = 0.3 #验证集比例设置为0.3#获取数据集的名字(不包含后缀),排序后存放到files_name列表中files_name = sorted([file.split(".")[0] for file in os.listdir(files_path)])files_num = len(files_name)val_index = random.sample(range(0, files_num), k=int(files_num*val_rate))train_files = []val_files = []for index, file_name in enumerate(files_name):if index in val_index:val_files.append(file_name)else:train_files.append(file_name)try:train_f = open("train.txt", "x")eval_f = open("val.txt", "x")train_f.write("\n".join(train_files))eval_f.write("\n".join(val_files))except FileExistsError as e:print(e)exit(1)
if __name__ == '__main__':main()然后进行划分
cd data
python splitdata.py结果如图

最后进行训练
python trainer.py -c config/ljs.yaml -n ljs_ckpt参数:
- -c也就是--config 是要求的配置文件
- - n也就是--name 是要求的训练数据后保存权重文件的文件夹名
训练完后,可查看
tensorboard --logdir logs/4.训练自定义数据集
自己收集的语音数据集,包含语音和语音文本
对语音数据的收集包含了:手机电脑自带录音,利用软件录音
手机录音的采样率是指录制声音时每秒钟采集的样本数。采样率越高,录制声音的准确性越高,但同时也会增加文件的大小。大多数手机录音应用默认的采样率为44.1 kHz,与CD音质相同。然而,一些应用程序允许用户自定义采样率,让用户在文件大小和音质之间做出选择。
对数据进行重命名
import ospath_in = "/workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs" # 待批量重命名的文件夹
class_name = ".wav" # 重命名后的文件名后缀file_in = os.listdir(path_in) # 返回文件夹包含的所有文件名
num_file_in = len(file_in) # 获取文件数目for i in range(0, num_file_in):t = str(i + 1)new_name = os.rename(path_in + "/" + file_in[i], path_in + "/" +t+ class_name) # 重命名文件名file_out = os.listdir(path_in)
print(file_out) # 输出修改后的结果`
因为vocgan要求采样率是22050,
如果是手机录音的话,采样率可能不同,所以要批量将采样率统一为22050。
resamplingrate.py
import os
import librosa
import tqdm
import soundfile as sfif __name__ == '__main__':# 要查找的音频类型audioExt = 'wav'# 待处理音频的采样率input_sample = 22050# 重采样的音频采样率output_sample = 16000# 待处理音频的多个文件夹#audioDirectory = ['/data/orgin/train', '/data/orgin/test']audioDirectory = ['/workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs']# 重采样输出的多个文件夹#outputDirectory = ['/data/traindataset', '/data/testdataset']outputDirectory = ['/workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wav']# for 循环用于遍历所有待处理音频的文件夹for i, dire in enumerate(audioDirectory):# 寻找"directory"文件夹中,格式为“ext”的音频文件,返回值为绝对路径的列表类型clean_speech_paths = librosa.util.find_files(directory=dire,ext=audioExt,recurse=True, # 如果选择True,则对输入文件夹的子文件夹也进行搜索,否则只搜索输入文件夹)# for 循环用于遍历搜索到的所有音频文件for file in tqdm.tqdm(clean_speech_paths, desc='No.{} dataset resampling'.format(i)):# 获取音频文件的文件名,用作输出文件名使用fileName = os.path.basename(file)# 使用librosa读取待处理音频y, sr = librosa.load(file, sr=input_sample)# 对待处理音频进行重采样y_16k = librosa.resample(y, orig_sr=sr, target_sr=output_sample)# 构建输出文件路径outputFileName = os.path.join(outputDirectory[i], fileName)# 将重采样音频写回硬盘,注意输出文件路径sf.write(outputFileName, y_16k, output_sample)
python /workspace/tts/VocGAN/data/resampling.py

先对语音进行预处理,将wav文件转化为mel文件
python preprocess.py -c config/maydata.yaml -d /workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs
划分train和val后
然后训练
python trainer.py -c config/mydata.yaml -n dyon如果出错没请参考【PS3】
运行后结果如图


注意:这里不小心中断后,会从头训练
推理
# python inference.py -p checkpoint路径 -i 输入mel的路径
python inference.py -p /workspace/tts/VocGAN/chkpt/dyon/dyon_2dfbde2_33680.pt -i /workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/mels过程中遇到的错误及解决
【PS1】AttributeError: module 'torch._C' has no attribute 'DoubleStorageBase'

错误原因可能是torch版本和cuda版本不兼容
查询cuda版本:nvcc -v,可以看到cuda11.8

更换版本
conda install pytorch==1.10.0 torchvision==0.11.0 torchaudio==0.10.0 cudatoolkit=11.3 -c pytorch -c conda-forge更换后还是出错
尝试
conda install pytorch torchvision torchaudio pytorch-cuda=11.8 -c pytorch -c nvidia升级后

导入torch没问题
但是运行时出现
ImportError: cannot import name 'COMMON_SAFE_ASCII_CHARACTERS' from 'charset_normalizer.constant' (/opt/miniconda3/envs/gan/lib/python3.8/site-packages/charset_normalizer/constant.py)导入错误:无法从“charset_normalizer.constant”导入名称“COMMON_SAFE_ASCII_CHARACTERS”
这个报错可能是由于charset_normalizer模块的版本问题引起的。尝试更新charset_normalizer模块到最新版本,或者使用较旧的版本,看看是否可以解决问题。可以尝试以下命令更新模块:
pip install --upgrade charset-normalizer

AttributeError: module 'numpy' has no attribute 'complex'.
点开对应代码

"/opt/miniconda3/envs/gan/lib/python3.8/site-packages/librosa/core/constantq.py", line 1058,
np.complex是内置complex的一个已弃用的别名。
除了np.complex,还可以使用:
complex(1) #output (1+0j)
#or
np.complex128(1) #output (1+0j)
#or
np.complex_(1) #output (1+0j)
#or
np.cdouble(1) #output (1+0j)改完后如图

然后就可以啦~
【PS2】AssertionError: sample rate mismatch. expected 22050, got 48000 at /workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/wavs/72.wav
因为 .wav 文件是立体声,但您需要转换为单声道。使用以下指南将一批文件批量转换为单声道格式。
【PS3】ValueError: num_samples should be a positive integer value, but got num_samples=0
解决方法:
1. 检查dataset中的路径,路径不对,读取不到数据。
2. 检查Dataset的__len__()函数为何输出为零
扩展
train: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/wavs'validation: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/vaild'mel_path: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/mels'eval_path: '/workspace/tts/Korean-FastSpeech2-Pytorch/data/Voice/korean_corpus.csv'python preprocess.py -c config/mydata.yaml -d /workspace/tts/Korean-FastSpeech2-Pytorch/data/DyonVoice/wavs相关文章:
TTS | VocGAN声码器训练自己的数据集
哈喽,今天给大家介绍的是如何使用VocGAN声码器训练自己的数据集。 原文 VocGAN: A High-Fidelity Real-time Vocoder with a Hierarchically-nested Adversarial Network 想要论文解读,请参考我的这篇文章~ 本博客主要包括以下内容: 目录…...

nuxt3--prisma配置
目录 一、初始化二、修改配置三、创建数据库表四、安装Prisma客户端五、查询数据库 一、初始化 npm install prisma typescript ts-node types/node --save-devts-node 用来执行main函数更新数据库 根据实际情况安装,如果不需要的话只需要安装prisma tsconfig.json…...
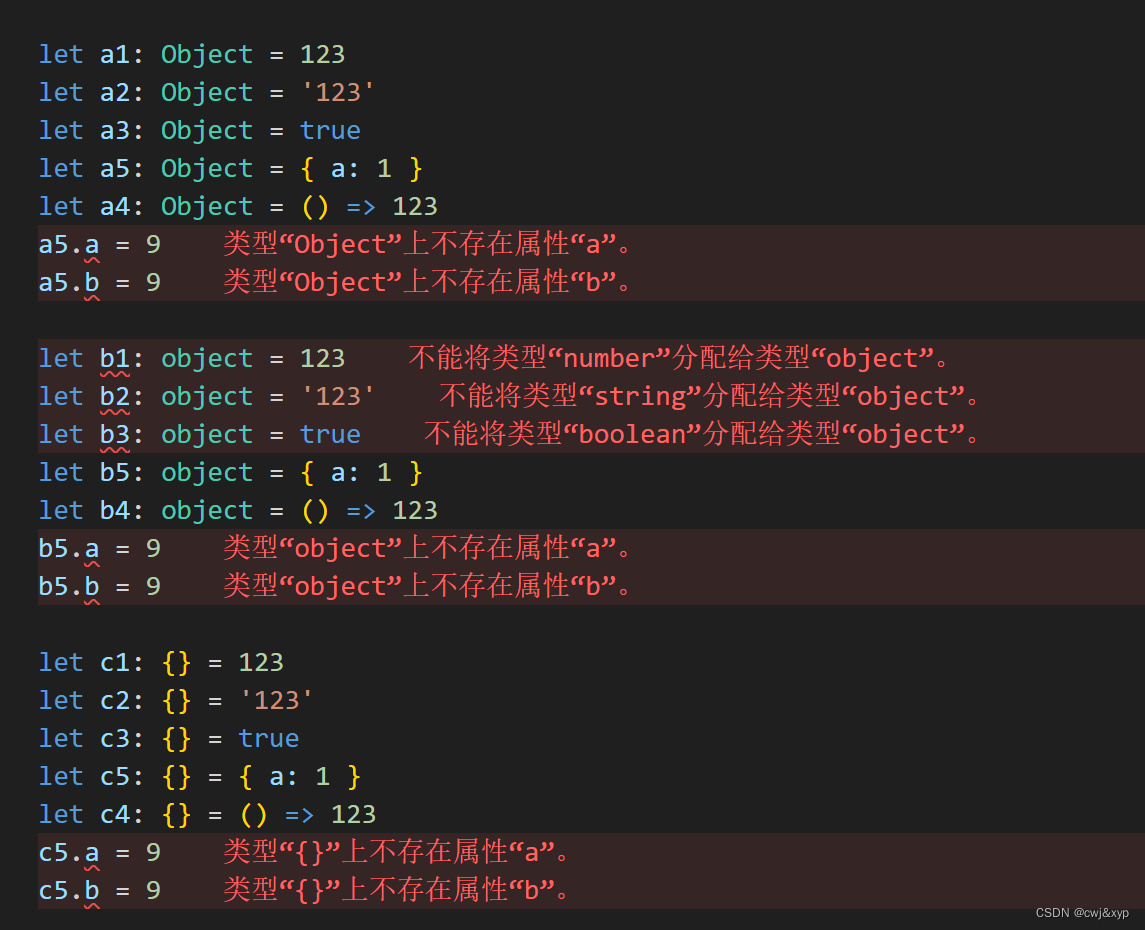
学习ts(一)数据类型(基础类型和任意类型)
运行 起步安装 npm install typescript -g 运行tsc index.ts生成对应的js文件,然后使用node index.js执行js文件 为了方便运行还可以安装插件,ts-node index.ts运行即可 npm i ts-node -g npm init -y npm i types/node -D基本数据类型 // 1.字符…...
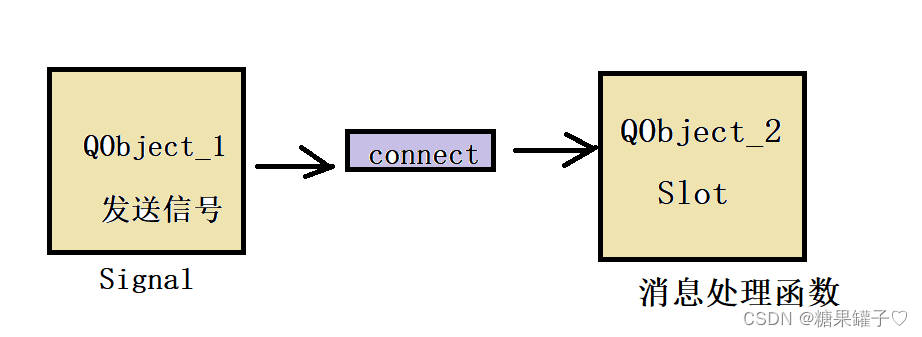
Qt 之 QPushButton,信号与槽机制
文章目录 前言一、QPushButton二、信号与槽机制总结 前言 一、QPushButton 当我们开发基于Qt框架的图形用户界面(GUI)应用程序时,经常需要在界面上添加按钮来实现用户交互。Qt提供了一个名为 QPushButton 的类作为按钮控件的实现。QPushButt…...

MySQL面试题一
MySQL 索引使用有哪些注意事项呢? 可以从两个维度回答这个问题: 索引哪些情况会失效,索引不适合哪些场景 索引哪些情况会失效 查询条件包含or,会导致索引失效。隐式类型转换,会导致索引失效, 例如age字…...

【Java】2021 RoboCom 机器人开发者大赛-高职组(复赛)题解
7-8 人工智能打招呼 号称具有人工智能的机器人,至少应该能分辨出新人和老朋友,所以打招呼的时候应该能有所区别。本题就请你为这个人工智能机器人实现这个功能:当它遇到陌生人的时候,会说:“Hello X, how are you?”其…...

使用electron-vue获取文件夹的路径
使用electron-vue获取文件夹的路径 记录一次开发过程中遇到的bug,我们的项目中需要将vue项目打包为桌面应用软件,为此我们引入了electron框架,在这个过程中,我们需要获取到用户电脑上面文件夹的绝对路径,用这篇文章记…...

剑指Offer14-II.剪绳子II C++
1、题目描述 给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]…k[m - 1] 。请问 k[0]k[1]…*k[m - 1] 可能的最大乘积是多少?例如&am…...
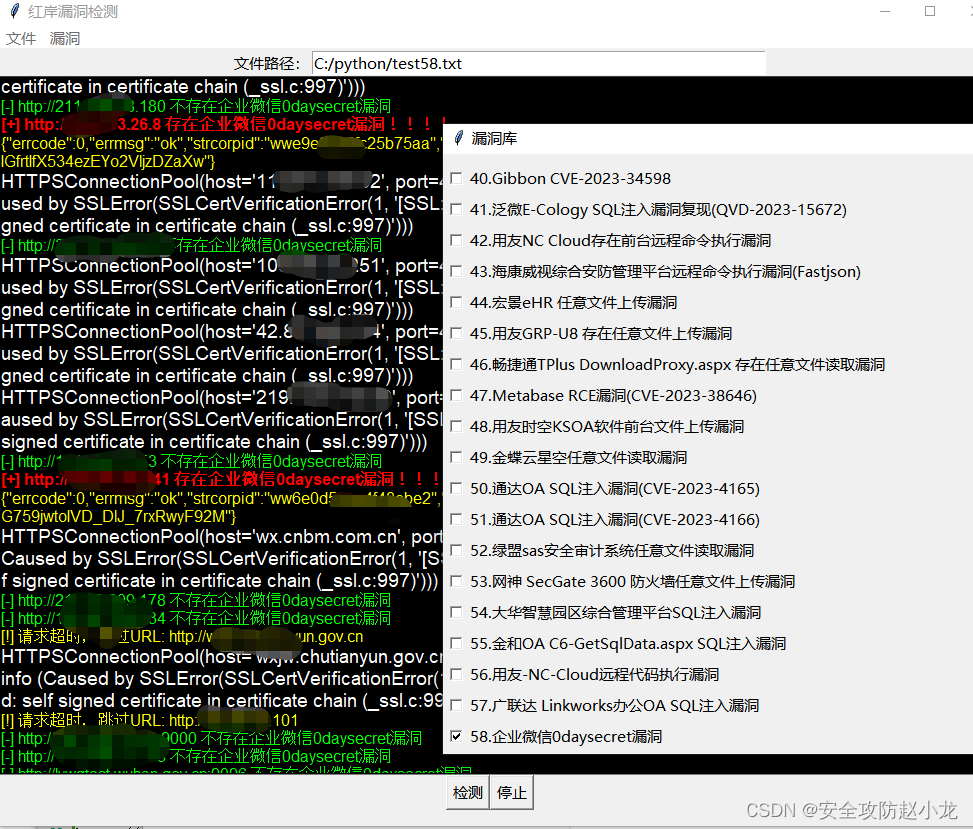
2023企业微信0day漏洞复现以及处理意见
2023企业微信0day漏洞复现以及处理意见 一、 漏洞概述二、 影响版本三、 漏洞复现小龙POC检测脚本: 四、 整改意见 免责声明:请勿利用文章内的相关技术从事非法测试,由于传播、利用此文所提供的信息或者工具而造成的任何直接或者间接的后果及损失&#x…...

【IMX6ULL驱动开发学习】04.应用程序和驱动程序数据传输和交互的4种方式:非阻塞、阻塞、POLL、异步通知
一、数据传输 1.1 APP和驱动 APP和驱动之间的数据访问是不能通过直接访问对方的内存地址来操作的,这里涉及Linux系统中的MMU(内存管理单元)。在驱动程序中通过这两个函数来获得APP和传给APP数据: copy_to_usercopy_from_user …...
二叉树part07)
day-21 代码随想录算法训练营(19)二叉树part07
530.二叉搜索树的最小绝对差 思路一:二叉搜索树的中序遍历必为升序数组,加入数组后计算相邻两个数差值,即可求出最小绝对差 思路二:同样的思路,中序遍历,直接使用指针记录上一个节点,同时更新…...

【Vue3】依赖注入
provide 和 inject 是 Vue.js 中用于实现依赖注入的两个关联功能。它们允许你在祖先组件中提供数据,然后在子孙组件中注入这些数据,实现组件之间的数据共享和传递。 provide:provide 是一个选项,你可以在父组件中通过它来提供数据…...
Vue 引入 Element-UI 组件库
Element-UI 官网地址:https://element.eleme.cn/#/zh-CN 完整引入:会将全部组件打包到项目中,导致项目过大,首次加载时间过长。 下载 Element-UI 一、打开项目,安装 Element-UI 组件库。 使用命令: npm …...

照耀国产的星火,再度上新!
国产之光,星火闪耀 ⭐ 新时代的星火⭐ 多模态能力⭐ 图像生成与虚拟人视频生成⭐ 音频生成与OCR笔记收藏⭐ 助手模式更新⭐ 插件能力⭐ 代码能力⭐ 写在最后 ⭐ 新时代的星火 在这个快速变革的时代,人工智能正迅猛地催生着前所未有的革命。从医疗到金融…...

大语言模型LLM的一些点
LLM发展史 GPT模型是一种自然语言处理模型,使用Transformer来预测下一个单词的概率分布,通过训练在大型文本语料库上学习到的语言模式来生成自然语言文本。 GPT-1(117亿参数),GPT-1有一定的泛化能力。能够用于和监督任务无关的任务中。GPT-2(…...

leetcode810. 黑板异或游戏(博弈论 - java)
黑板异或游戏 lc 810 - 黑板异或游戏题目描述博弈论 动态规划 lc 810 - 黑板异或游戏 难度 - 困难 原题链接 - 黑板异或游戏 题目描述 黑板上写着一个非负整数数组 nums[i] 。 Alice 和 Bob 轮流从黑板上擦掉一个数字,Alice 先手。如果擦除一个数字后,剩…...

算法练习Day48|198.打家劫舍 ● 213.打家劫舍II ● 337.打家劫舍III
LeetCode: 198. 打家劫舍 - 力扣(LeetCode) 1.思路 边界思维,只有一个元素和两个元素的初始化考虑 当元素数大于3个时, 逆向思维,是否偷最后一个元素,倒序得出递推公式dp[i] Math.max(dp[i - 1], dp[i …...

什么是设计模式?常用的设计有哪些?
单例模式工厂模式代理模式(proxy) 一、设计模式 设计模式是前辈们经过无数次实践所总结的一些方法(针对特定问题的特定方法) 这些设计模式中的方法都是经过反复使用过的。 二、常用的设计模式有哪些? 1、单例模式&…...
clickHouse部署
docker仓库地址 https://hub.docker.com/ 1、docker环境搭建 # 1.先安装yml yum install -y yum-utils device-mapper-persistent-data lvm2 # 2.设置阿里云镜像 sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 3.查…...

Flutter实现倒计时功能,秒数转时分秒,然后倒计时
Flutter实现倒计时功能 发布时间:2023/05/12 本文实例为大家分享了Flutter实现倒计时功能的具体代码,供大家参考,具体内容如下 有一个需求,需要在页面进行显示倒计时,倒计时结束后,做相应的逻辑处理。 实…...

如何永久激活IDM?2024终极免费激活与试用重置完全指南
如何永久激活IDM?2024终极免费激活与试用重置完全指南 【免费下载链接】IDM-Activation-Script IDM Activation & Trail Reset Script 项目地址: https://gitcode.com/gh_mirrors/id/IDM-Activation-Script IDM Activation Script是一款专为Internet Dow…...
)
【仅剩最后47份】盐印相风格训练数据集泄露报告(含原始Agfa APX 400扫描底片参数+Midjourney反向蒸馏权重)
更多请点击: https://codechina.net 第一章:盐印相风格的视觉基因与数字重生 盐印相(Salted Paper Print)作为19世纪早期摄影术的奠基性工艺,其独特颗粒质感、柔和影调过渡与温润泛黄基底,构成了不可复制的…...

宝丽来胶片模拟不等于加噪点!深度拆解Polaroid SX-70光学特性与MJ v6渲染引擎的4层映射偏差,附12组可直接复用的--sref哈希值
更多请点击: https://intelliparadigm.com 第一章:宝丽来SX-70胶片的光学本质与历史语境 宝丽来SX-70胶片并非传统意义上的“静态感光材料”,而是一套高度集成的自显影光学化学系统。其核心在于多层涂布结构中嵌入的镜面反射层、碱性催化剂囊…...

硬件选型干货|钡特电源DQ1-15D1709S与金升阳QA01-17属工业标准模块电源,避坑指南
在工业电子硬件研发中,工业DC-DC模块是板级隔离供电的核心器件,其标准化封装、性能稳定性及国产化水平,直接影响研发效率、系统可靠性与供应链安全。钡特电源DQ1-15D1709S与金升阳QA01-17作为国产直流电源模块领域的代表性型号,均…...

cmder设置默认打开路径
从你发的截图来看,目前没有任何一项被选中(右侧的代码框是空的,而且右下角的 Startup dir... 按钮也是灰色不可点击的状态),并且确实没有带 * 号的项。没关系,如果没有带 * 号,按照下面的步骤操…...

明日方舟基建管理神器:Arknights-Mower 智能助手完整指南
明日方舟基建管理神器:Arknights-Mower 智能助手完整指南 【免费下载链接】arknights-mower 《明日方舟》长草助手 项目地址: https://gitcode.com/gh_mirrors/ar/arknights-mower 每天花半小时手动调整干员排班,计算心情值,安排宿舍休…...

从欧氏距离到余弦相似度:5种距离度量如何影响你的KNN模型?用Scikit-learn实战对比
从欧氏距离到余弦相似度:5种距离度量如何影响你的KNN模型?用Scikit-learn实战对比 在机器学习的世界里,K近邻算法(KNN)因其简单直观而广受欢迎。但很多实践者往往只关注k值的选择,却忽略了另一个同等重要的超参数——距离度量。就…...

OpenShift高可用集群搭建后,这10个运维“救命”命令和5个常见故障排查场景你必须知道
OpenShift高可用集群运维实战:10个关键命令与5大故障场景深度解析 当你的OpenShift集群从测试环境迈向生产环境时,那些在搭建阶段被忽略的运维细节往往会突然成为拦路虎。不同于标准Kubernetes,OpenShift在提供企业级功能的同时也带来了更复杂…...

Unity 2019格斗游戏开发:帧同步、输入缓冲与Hitbox/Hurtbox实现
1. 为什么2019版Unity仍是横板格斗开发的“黄金锚点”我带过三届游戏开发训练营,每次开课前都会问学员:“你最想用哪个版本做格斗游戏?”——超过七成的人脱口而出“最新版”。但当我把他们拉进一个用Unity 2019.4.40f1跑通的《街霸》风格连招…...

Suno.cn从工具到生态,AI音乐平台的崛起、挑战与本土化之路
2026年,Suno已从一款“文字生成音乐”的玩具,成长为估值25亿美元、年营收超3亿美元的全球AI音乐巨头。然而,在版权风暴与本土化浪潮中,它的故事远未结束。 🚀 一、市场地位与商业成功:Suno的狂飙突进 Suno在2026年的增长堪称现象级。其首席执行官Mikey Shulman宣布,平…...