小样本UIE 信息抽取微调快速上手(不含doccona标注)
文章目录
- 1.安装环境(可略过)
- 2.模型简介(略读)
- 抽取任务输入输出示例:
- 1.实体识别
- 2.关系抽取
- 3.快速上手(主菜)
- (1)转换数据
- ==标注数据样例==
- (2)生成训练数据
- ==训练数据样例==
- (3)微调训练
1.安装环境(可略过)
模型快速复现的基本思路,只要两步,一是安装环境,二是跑模型。
安装GPU版本的paddlepaddle看参照此博客,如果不幸地,你报错缺少libcudart动态库文件,请参照此博客解决环境安装问题,毕竟安装环境是AIer不可逾越的鸿沟。
2.模型简介(略读)
知其然也知其所以然,能到快速上手阶段,肯定已经了解了UIE的一些相关介绍,这里仅从偏实践角度,简短剖析一下任务细节,具体介绍可参照官方github。
UIE(Universal Information Extraction) 针对少样本、低资源、不同领域等场景,实现从非结构化文本中抽取结构化信息,包含了实体识别、关系抽取、事件抽取、情感分析、评论抽取等任务。
该任务的亮点在于:
(1)将多任务的信息抽取统一为一个抽取模板
(2)基于结构化生成的预训练模型,可以实现少样本、跨领域的模型微调,且能够达到工业级可应用的SOTA效果。
统一模板可结合UIE整体框架来理解,如下图所示。

其底座是基于T5模型预训练的,多任务模型那就少不了prompt,这个prompt设计也非常巧妙,把prompt提示抽象成两种类别,Spotting进行实体识别,Associating进行关系类别识别,那么格式化就是:[spot] 实体类别 [asso] 关系类别 [text]。与实体识别、关系抽取、事件抽取任务联系起来,实体识别、事件触发词识别以及事件论元识别就是在做Spotting操作,找取目标信息片段,关系抽取、事件论元与事件触发词之间的关系是做Associating操作,寻找目标信息片段之间的关系。
对于不同的抽取任务只要给出统一的schema,那么模型就会自动将其组装为prompt喂给模型,进行Spotting、Associating操作。
抽取任务输入输出示例:
1.实体识别
from pprint import pprint>>> from paddlenlp import Taskflow
schema = [‘时间’, ‘选手’, ‘赛事名称’] # Define the schema for entity extraction
ie = Taskflow(‘information_extraction’, schema=schema)
pprint(ie(“2月8日上午北京冬奥会自由式滑雪女子大跳台决赛中中国选手谷爱凌以188.25分获得金牌!”)) # Better print results using pprint
[{‘时间’: [{‘end’: 6,
‘probability’: 0.9857378532924486,
‘start’: 0,
‘text’: ‘2月8日上午’}],
‘赛事名称’: [{‘end’: 23,
‘probability’: 0.8503089953268272,
‘start’: 6,
‘text’: ‘北京冬奥会自由式滑雪女子大跳台决赛’}],
‘选手’: [{‘end’: 31,
‘probability’: 0.8981548639781138,
‘start’: 28,
‘text’: ‘谷爱凌’}]}]
2.关系抽取
schema = {‘竞赛名称’: [‘主办方’, ‘承办方’, ‘已举办次数’]} # Define the schema for relation extraction>>> ie.set_schema(schema) # Reset schema>>> pprint(ie(‘2022语言与智能技术竞赛由中国中文信息学会和中国计算机学会联合主办,百度公司、中国中文信息学会评测工作委员会和中国计算机学会自然语言处理专委会承办,已连续举办4届,成为全球最热门的中文NLP赛事之一。’))
[{‘竞赛名称’: [{‘end’: 13,
‘probability’: 0.7825402622754041,
‘relations’: {‘主办方’: [{‘end’: 22,
‘probability’: 0.8421710521379353,
‘start’: 14,
‘text’: ‘中国中文信息学会’},
{‘end’: 30,
‘probability’: 0.7580801847701935,
‘start’: 23,
‘text’: ‘中国计算机学会’}],
‘已举办次数’: [{‘end’: 82,
‘probability’: 0.4671295049136148,
‘start’: 80,
‘text’: ‘4届’}],
‘承办方’: [{‘end’: 39,
‘probability’: 0.8292706618236352,
‘start’: 35,
‘text’: ‘百度公司’},
{‘end’: 72,
‘probability’: 0.6193477885474685,
‘start’: 56,
‘text’: ‘中国计算机学会自然语言处理专委会’},
{‘end’: 55,
‘probability’: 0.7000497331473241,
‘start’: 40,
‘text’: ‘中国中文信息学会评测工作委员会’}]},
‘start’: 0,
‘text’: ‘2022语言与智能技术竞赛’}]}]
以上的两个任务可以直接利用paddlenlp的Taskflow直接输出结果,这是预训练模型通用的抽取任务,输出效果也不错。Taskflow可理解为paddle为是产业实践研发的任务框架,包含数据的预处理、模型推理、后处理等任务执行所遵循的框架。细分场景中一般需要一定的标注数据进行微调。
3.快速上手(主菜)
项目中代码结构,如果不修改模型,不部署,仅微调的话,仅用到doccano.py、finetune.py、evaluate.py就足够了。
├── utils.py # 数据处理工具
├── model.py # 模型组网脚本
├── doccano.py # 数据标注脚本
├── doccano.md # 数据标注文档
├── finetune.py # 模型微调、压缩脚本
├── evaluate.py # 模型评估脚本
└── README.md
(1)转换数据
将自己的数据直接转化为doccona标注后的数据示例,为什么不直接转换为喂给模型的训练、验证数据,因为官方提供了转换脚本,里面包含正负样例构造、shuffle以及划分训练、验证、测试集,非常方便。
标注数据样例
{"id": 1, "text": "昨天晚上十点加班打车回家58元", "relations": [], "entities": [{"id": 0, "start_offset": 0, "end_offset": 6, "label": "时间"}, {"id": 1, "start_offset": 11, "end_offset": 12, "label": "目的地"}, {"id": 2, "start_offset": 12, "end_offset": 14, "label": "费用"}]}
{"id": 2, "text": "三月三号早上12点46加班,到公司54", "relations": [], "entities": [{"id": 3, "start_offset": 0, "end_offset": 11, "label": "时间"}, {"id": 4, "start_offset": 15, "end_offset": 17, "label": "目的地"}, {"id": 5, "start_offset": 17, "end_offset": 19, "label": "费用"}]}
注:我刚开始纠结该示例任务的schema = [‘出发地’, ‘目的地’, ‘费用’, ‘时间’],有的示例数据没有“目的地”无法定位offset怎么办?
准备标注数据的时候,没有的实体类别项,忽略不记录就行。
因为转换为训练数据集的时候,每个示例是根据类别分别转换的,如第一条数据,会转化为抽取"时间"类别数据,抽取"目的地"类别数据,抽取"费用"类别数据的3条数据,"出发地"类别就不用管。
(2)生成训练数据
经过doccona标注后的数据样例,通过doccona.py进行转换,生成训练集、验证集、测试集,命令如下所示。
python doccano.py \--doccano_file ./data/doccano_ext.json \--save_dir ./data \--splits 0.8 0.1 0.1
训练数据样例
{"content": "出租车从酒店到公司一共34元时间是10月21日", "result_list": [{"text": "10月21日", "start": 17, "end": 23}], "prompt": "时间"}
{"content": "二零一九年十一月十三日晚上十点三十四分加班打车回家,四十三元", "result_list": [{"text": "家", "start": 24, "end": 25}], "prompt": "目的地"}
{"content": "月五号凌晨0点08分打车回家三十点五元", "result_list": [{"text": "家", "start": 13, "end": 14}], "prompt": "目的地"}
(3)微调训练
因为我有多张显卡,一开始想用多卡并行微调训练,没想到还需要安装一个ncll2,果断放弃,选择单卡也能微调,且速度挺快。总共100多条标注数据,生成训练集600多条数据,10多分钟就训练完了。
注意,我修改的参数,–device gpu:8 指定了特定的gpu,batch_size改为了8,因为显卡内存被别程序占用,8才能跑起来。
微调命令如下所示:
python finetune.py \--device gpu:8 \--logging_steps 10 \--save_steps 100 \--eval_steps 100 \--seed 42 \--model_name_or_path uie-base \--output_dir $finetuned_model \--train_path data/train.txt \--dev_path data/dev.txt \--max_seq_length 512 \--per_device_eval_batch_size 8 \--per_device_train_batch_size 8 \--num_train_epochs 20 \--learning_rate 1e-5 \--label_names "start_positions" "end_positions" \--do_train \--do_eval \--do_export \--export_model_dir $finetuned_model \--overwrite_output_dir \--disable_tqdm True \--metric_for_best_model eval_f1 \--load_best_model_at_end True \--save_total_limit 1
参考:
[1].https://mp.weixin.qq.com/s/lL950H9T7UFsJRopuWQ59w
[2].https://github.com/PaddlePaddle/PaddleNLP/blob/develop/model_zoo/uie/README.md#%E6%A8%A1%E5%9E%8B%E5%BE%AE%E8%B0%83
相关文章:
小样本UIE 信息抽取微调快速上手(不含doccona标注)
文章目录 1.安装环境(可略过)2.模型简介(略读)抽取任务输入输出示例:1.实体识别2.关系抽取 3.快速上手(主菜)(1)转换数据标注数据样例 (2)生成训练数据训练数据样例 &…...
)
Vue项目(购物车)
目录 购物车效果展示: 购物车代码: 购物车效果展示: 此项目添加、修改、删除数据的地方都写了浏览器都会把它存储起来 下次运行项目时会把浏览器数据拿出来并在页面展示 Video_20230816145047 购物车代码: 复制完代码࿰…...

23.08.16驱动点灯
#include <linux/init.h> #include <linux/module.h> #include <linux/fs.h> #include <linux/uaccess.h> #include <linux/io.h> #include <linux/device.h> #include "head.h"int major; char kbuf[128] {0};//定义指针接收映…...
数据结构——堆
数据结构——堆 堆堆简介堆的分类 二叉堆过程插入操作 删除操作向下调整: 增加某个点的权值实现参考代码:建堆方法一:使用 decreasekey(即,向上调整)方法二:使用向下调整 应用对顶堆 其他&#…...

重复学习1:NLP
目录 1. 自然语言处理与知识图谱1.1 RNN 循环神经网络初探 2. 吴恩达深度学习 1. 自然语言处理与知识图谱 1.1 RNN 循环神经网络初探 1.1.2 回顾数据维度与神经网络(1) 2. 吴恩达深度学习 P151 1.1 为什么选择序列模型(1,2) P152 1.2 数学符号(1,)...
做海外游戏推广有哪些条件?
做海外游戏推广需要充分准备和一系列条件的支持。以下是一些关键条件: 市场调研和策略制定:了解目标市场的文化、玩家偏好、竞争格局等是必要的。根据调研结果制定适合的推广策略。 本地化:将游戏内容、界面、语言、货币等进行本地化&#…...
JavaFx基础学习【五】:FXML布局文件使用
目录 前言 一、介绍 二、简单体验 三、FXML标签元素 四、fx属性介绍 五、重写initialize(名字需要保持一致)方法 六、Scene Builder快速布局 前言 如果你还没有看过前面的文章,可以通过以下链接快速前往学习: JavaFx基础学…...

通过Python爬虫提升网站搜索排名
目录 怎么使用Python爬虫提升排名 1. 抓取竞争对手数据: 2. 关键词研究: 3. 网页内容优化: 4. 内部链接建设: 5. 外部链接建设: 6. 监测和调整: 需要注意哪些方面 1. 合法性和道德性: …...

【博客698】为什么当linux作为router使用时,安装docker后流量转发失败
为什么当linux作为router使用时,安装docker后流量转发失败 场景 当一台linux机器作为其它服务器的router,负责转发流量的时候,让你在linux上安装docker之后,就会出现流量都被drop掉了 原因 没装docker之前: [root~]…...
el-dialog嵌套,修改内层el-dialog样式(自定义样式)
el-dialog嵌套使用时,内层的el-dialog要添加append-to-body属性 给内层的el-dialog添加custom-class属性,添加自定义类名 <el-dialog:visible.sync"dialogVisible"append-to-bodycustom-class"tree-cesium-container"><span>这是一段信息<…...
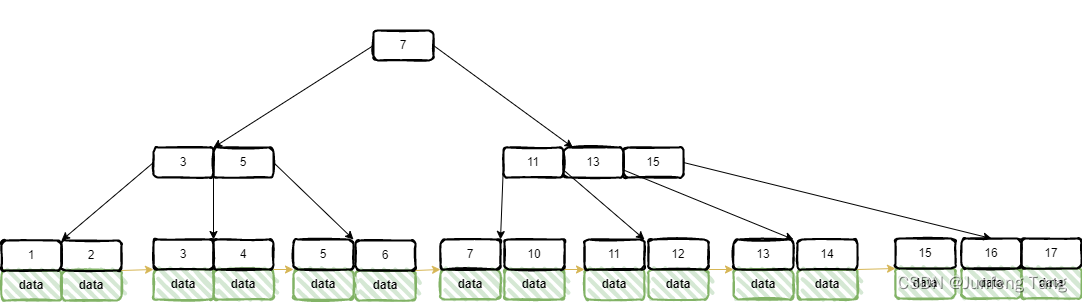
B树和B+树区别
B树和B树的区别 B树 B树被称为平衡树,在B树中,一个节点可以有两个以上的子节点。B树的高度为log M N。在B树中,数据按照特定的顺序排序,最小值在左侧,最大值在右侧。 B树是一种平衡的多分树,通常我们说m阶…...
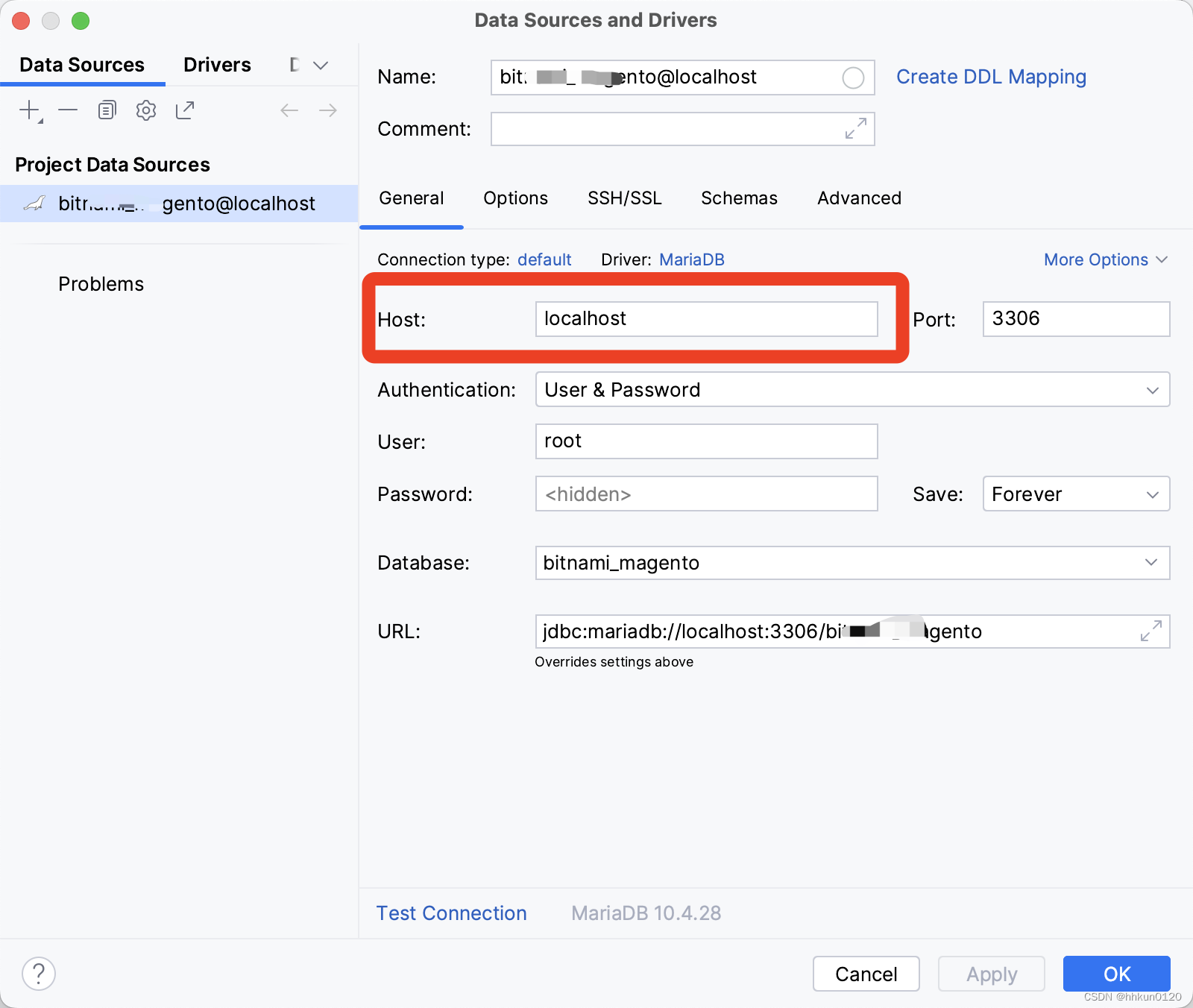
intelJ IDEA\PHPStorm \WebStorm\PyCharm 通过ssh连接远程Mysql\Postgresql等数据库
最容易出错的地方是在general面板下的host,不应该填真实的host地址,而应该填localhost或者127.0.0.1 具体操作步骤见下图...

vfuhyuuy
Sublime Text is an awesome text editor. If you’ve never heard of it, you shouldcheck it out right now. I’ve made this tutorial because there’s no installer for the Linux versions of Sublime Text. While that’s not a real problem, I feel there is a clean…...

CSS自学框架之表单
首先我们看一下表单样式,下面共有5张截图 一、CSS代码 /*表单*/fieldset{border: none;margin-bottom: 2em;}fieldset > *{ margin-bottom: 1em }fieldset:last-child{ margin-bottom: 0 }fieldset legend{ margin: 0 0 1em }/* legend标签是CSS中用于定义…...

使用Spring Boot和Redis实现用户IP接口限流的详细指南
系列文章目录 文章目录 系列文章目录前言一、准备工作二、编写限流过滤器三、配置Redis四、测试接口限流总结 前言 在高并发场景下,为了保护系统免受恶意请求的影响,接口限流是一项重要的安全措施。本文将介绍如何使用Spring Boot和Redis来实现用户IP的…...
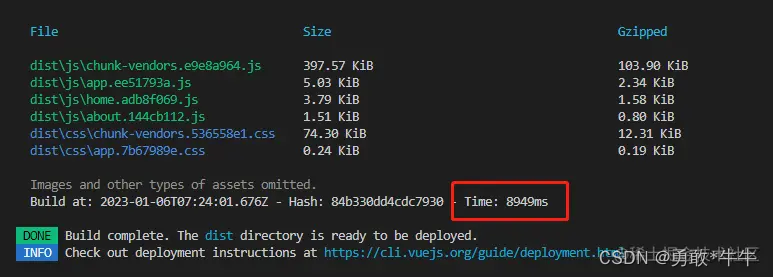
前端性能优化——包体积压缩插件,打包速度提升插件,提升浏览器响应的速率模式
前端代码优化 –其他的优化可以具体在网上搜索 压缩项目打包后的体积大小、提升打包速度,是前端性能优化中非常重要的环节,结合工作中的实践总结,梳理出一些 常规且有效 的性能优化建议 ue 项目可以通过添加–report命令: "…...
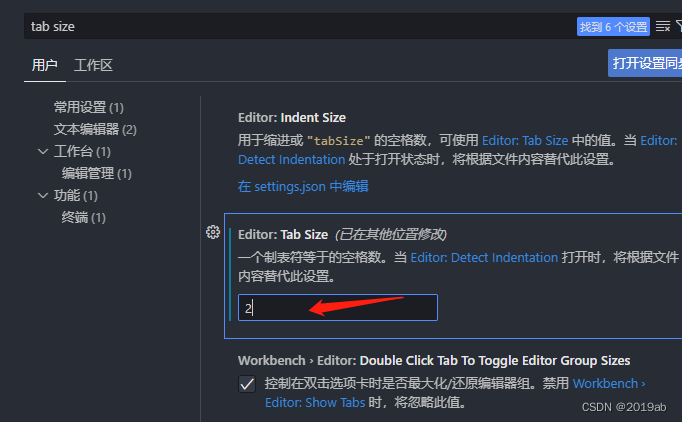
配置vscode
配置vscode 设置相关 网址:https://code.visualstudio.com/ 搜索不要用百度用这个:cn.bing.com 1.安装中文包 Chinese (Simplified) (简体中文) 2.安装 open in browser 3.安装主题 Atom One Dark Theme 4. 安装图标样式 VSCode Great Icons 5.安装 L…...
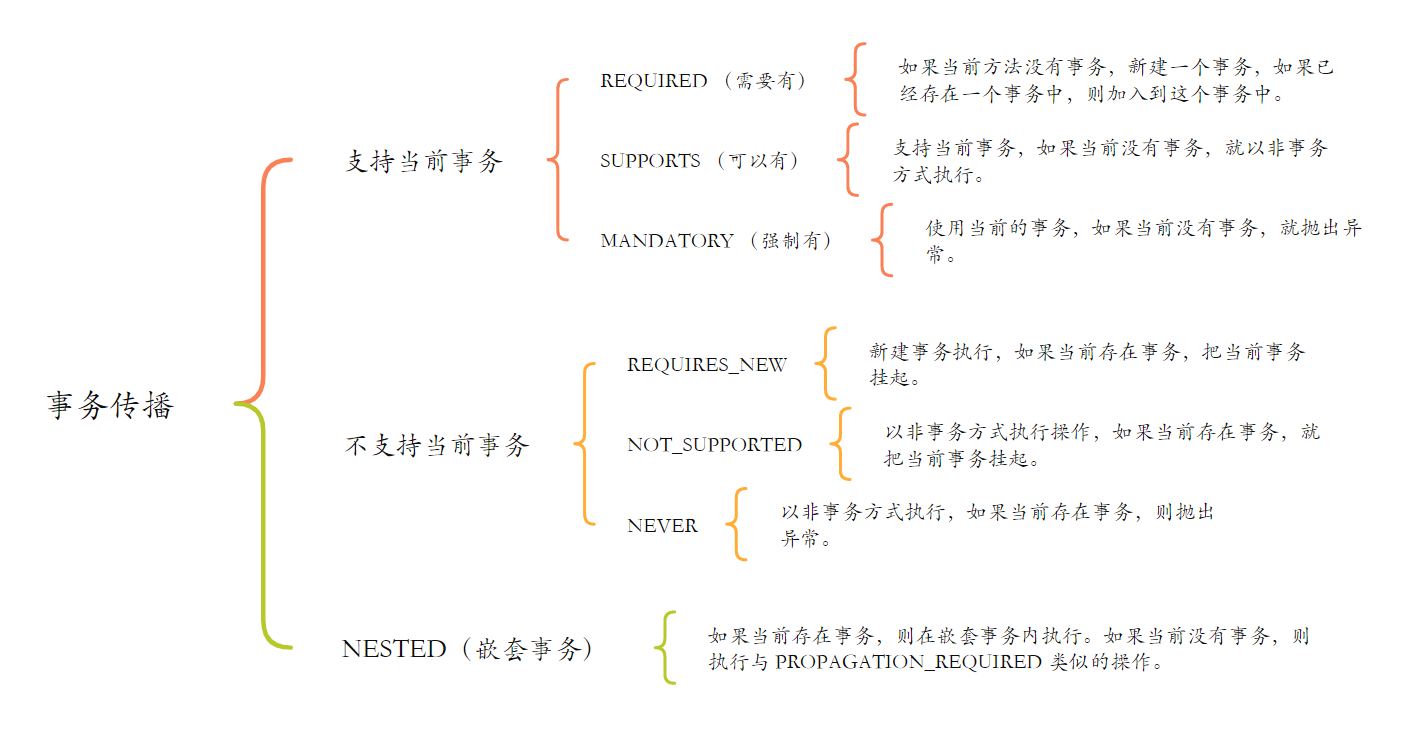
【Spring】深入理解 Spring 事务及其传播机制
文章目录 一、Spring 事务是什么二、Spring 中事务的实现方法2.1 Spring 编程式事务(手动)2.1.1 编程式事务的使用演示2.1.2 编程式事务存在的问题 2.2 Spring 声明式事务(自动)2.2.1 Transactional 作用范围2.2.2 Transactional …...

eclipse常用设置
1、调整编辑页面字体大小 窗口 (Window)- 首选项(Preferences)- 常规(General)- 外观 (Appearence)- 颜色与字体 (Colors And Fonts),在右边的对话框里选择 Java - Java Editor Text Font,点击出现的修改&…...

ajax解析
Ajax(Asynchronous JavaScript and XML)是一种用于在不重新加载整个页面的情况下与服务器交换数据的技术。它通过异步的方式发送请求和接收响应,能够实现在后台与服务器进行数据交互,然后更新页面的部分内容,从而提升用…...
)
别再搜组策略了!Windows 11家庭版设置密码永不过期的3个命令行方法(实测有效)
Windows 11家庭版密码永不过期终极指南:抛弃组策略的3种命令行方案 每次开机都要重新设置密码?Windows 11家庭版用户常常陷入这种困扰。与专业版不同,家庭版系统阉割了组策略编辑器这个关键工具,让普通用户面对密码过期问题时束手…...

PPTXjs终极指南:3分钟学会在浏览器中完美预览PPTX文件
PPTXjs终极指南:3分钟学会在浏览器中完美预览PPTX文件 【免费下载链接】PPTXjs jquery plugin for convertation pptx to html 项目地址: https://gitcode.com/gh_mirrors/pp/PPTXjs 还在为PPT文件兼容性问题烦恼吗?当精心制作的演示文稿在不同设…...

3分钟掌握Shutter Encoder:免费开源的终极视频转换工具解决方案
3分钟掌握Shutter Encoder:免费开源的终极视频转换工具解决方案 【免费下载链接】shutter-encoder A professional video compression tool accessible to all, mostly based on FFmpeg. 项目地址: https://gitcode.com/gh_mirrors/sh/shutter-encoder 还在为…...
零基础入门全攻略:原理、架构、手搓代码与实战落地)
Python+AI智能体(Agent)零基础入门全攻略:原理、架构、手搓代码与实战落地
PythonAI智能体(Agent)零基础入门全攻略:原理、架构、手搓代码与实战落地 文章目录: 【前言】 一、前言:为什么现在必须学PythonAI Agent智能体二、核心概念:彻底搞懂什么是AI Agent智能体 2.1 官方工程定义2.2 普通大模型LLM V…...

告别Chrome依赖:在Edge上完美复刻XPath Helper,打造你的爬虫元素定位工作流
告别Chrome依赖:在Edge上完美复刻XPath Helper,打造你的爬虫元素定位工作流 浏览器工具链的迁移从来不是简单的插件替换,而是一场关于开发习惯与效率的深度重构。当微软Edge凭借Chromium内核的稳定性和内存优化逐渐成为技术工作者的新宠&…...

代码随想录算法训练营第六十天|Bellman_ford 队列优化算法、Bellman_ford之判断负权回路、bellman_ford之单源有限最短路
参考文章均来自代码随想录 Bellman_ford 队列优化算法 参考文章链接 对第 59天中的题目进行优化 详细见参考文章推理步骤 还是用邻接表 #include <iostream> #include <vector> #include <queue> #include <list> #include <climits> using …...

Vivado用户必看:中文用户名导致Vscode关联失效?手把手教你修改vivado.xml文件
Vivado与Vscode联动的终极解决方案:彻底攻克中文路径兼容性问题 在FPGA开发领域,Vivado作为Xilinx推出的旗舰级开发工具,与轻量级代码编辑器Vscode的联动已经成为提升开发效率的标准配置。然而,许多中文用户在实际操作中常常遇到…...

别只会用!cat了:在Kaggle Notebook里动态编辑YOLOv5配置文件的完整攻略
突破Kaggle只读限制:YOLOv5配置文件动态编辑全指南 在Kaggle Notebook中进行计算机视觉项目开发时,许多开发者都遇到过这样的困境:当需要修改YOLOv5模型配置文件时,发现Kaggle的/kaggle/input目录是只读的。本文将介绍三种专业级解…...
)
Unity交通仿真入门:从零到一搭建十字路口红绿灯与车辆AI(附完整C#源码)
Unity交通仿真实战:十字路口红绿灯与车辆AI开发指南 在游戏开发和城市模拟领域,交通仿真一直是个充满挑战又极具实用价值的课题。想象一下,你正站在一个繁忙的十字路口,观察着红绿灯有节奏地变换,车辆井然有序地通过—…...

别再死磕开发了!网络安全职业前景全面解析:薪资水平、就业方向与学习路线图
别,你可千万别后悔!!! 首先,你学网安这个选择没有一点毛病,作为一个前辈,我可以明明白白的告诉你,近年程序员就业情况当中,网安是最舒服的一批,所以我看到你说…...