使用 Apache Kafka 和 Go 将数据引入 OpenSearch
需要编写自定义集成层来满足数据管道中的特定要求?了解如何使用 Go 通过 Kafka 和 OpenSearch 实现此目的。
可扩展的数据摄取是OpenSearch等大规模分布式搜索和分析引擎的一个关键方面。构建实时数据摄取管道的方法之一是使用Apache Kafka。它是一个开源事件流平台,用于处理高数据量(和速度),并与包括关系数据库和 NoSQL 数据库在内的各种来源集成。例如,规范用例之一是异构系统(源组件)之间的数据实时同步,以确保 OpenSearch 索引是最新的,并且可以通过仪表板和可视化用于分析或使用下游应用程序。
这篇博文将介绍如何创建数据管道,其中写入 Apache Kafka 的数据被引入 OpenSearch。我们将使用Amazon OpenSearch Serverless和Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless。Kafka Connect非常适合此类需求。它为 OpenSearch 和 ElasticSearch 提供接收器连接器(如果您选择将 ElasticSearch OSS 引擎与 Amazon OpenSearch 结合使用,则可以使用该连接器)。但有时,有特定的要求或原因可能需要使用定制解决方案。
例如,您可能正在使用 Kafka Connect 不支持的数据源(很少见,但可能会发生),并且不想从头开始编写数据源。或者,这可能是一次性集成,您想知道是否值得花费精力来设置和配置 Kafka Connect。也许还有其他问题,例如许可等。
值得庆幸的是,Kafka 和 OpenSearch 提供了多种编程语言的客户端库,使您可以编写自己的集成层。这正是本博客所涵盖的内容!我们将利用自定义Go应用程序通过Kafka和OpenSearch的 Go 客户端来摄取数据。
你将学习:
- 概述如何设置所需的 AWS 服务:OpenSearch Serverless、MSK Serverless、AWS Cloud9 以及 IAM 策略和安全配置
- 应用程序的高级演练
- 启动并运行数据摄取管道
- 如何在 OpenSearch 中查询数据
在深入讨论之前,我们先简要概述一下 OpenSearch Serverless 和 Amazon MSK Serverless。
Amazon OpenSearch 无服务器和 Amazon MSK 无服务器简介
OpenSearch 是一个开源搜索和分析引擎,用于日志分析、实时监控和点击流分析。Amazon OpenSearch Service 是一项托管服务,可简化 AWS 中 OpenSearch 集群的部署和扩展。
Amazon OpenSearch Service 支持 OpenSearch 和旧版 Elasticsearch OSS(直至 7.10,该软件的最终开源版本)。创建集群时,您可以选择使用哪个搜索引擎。
您可以创建一个 OpenSearch Service 域(与 OpenSearch 集群同义)来表示一个集群,其中每个 Amazon EC2 实例充当一个节点。然而,OpenSearch Serverless 通过为 OpenSearch 服务提供按需无服务器配置来消除操作复杂性。它使用索引集合来支持特定的工作负载,与传统集群不同,它分离了索引和搜索组件,并使用Amazon S3作为索引的主存储。该架构支持独立扩展搜索和索引功能。
您可以参考比较 OpenSearch Service 和 OpenSearch Serverless中的详细信息。
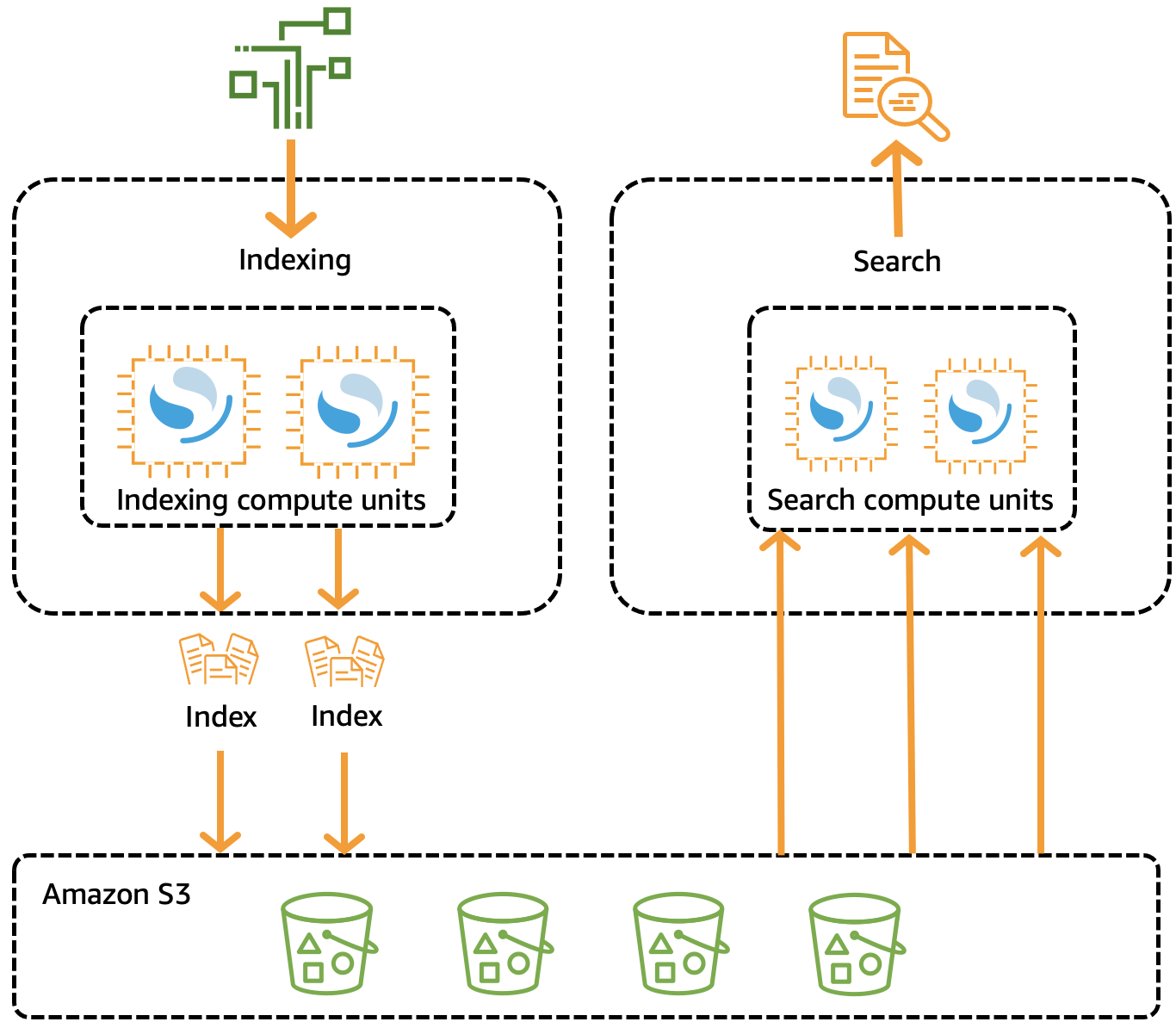
Amazon MSK(Apache Kafka 的托管流)是一项完全托管的服务,用于使用 Apache Kafka 处理流数据。它处理集群管理操作,例如创建、更新和删除。您可以使用标准 Apache Kafka 数据操作来生成和使用数据,而无需修改应用程序。它支持开源 Kafka 版本,确保与现有工具、插件和应用程序的兼容性。
MSK Serverless 是 Amazon MSK 中的一种集群类型,无需手动管理和扩展集群容量。它根据需求自动配置和扩展资源,并负责主题分区管理。采用即用即付定价模式,您只需为实际使用量付费。MSK Serverless 非常适合需要灵活、自动扩展流容量的应用程序。
让我们首先讨论高级应用程序架构,然后再讨论架构注意事项。
应用概述和关键架构注意事项
这是应用程序架构的简化版本,概述了组件以及它们如何相互交互。
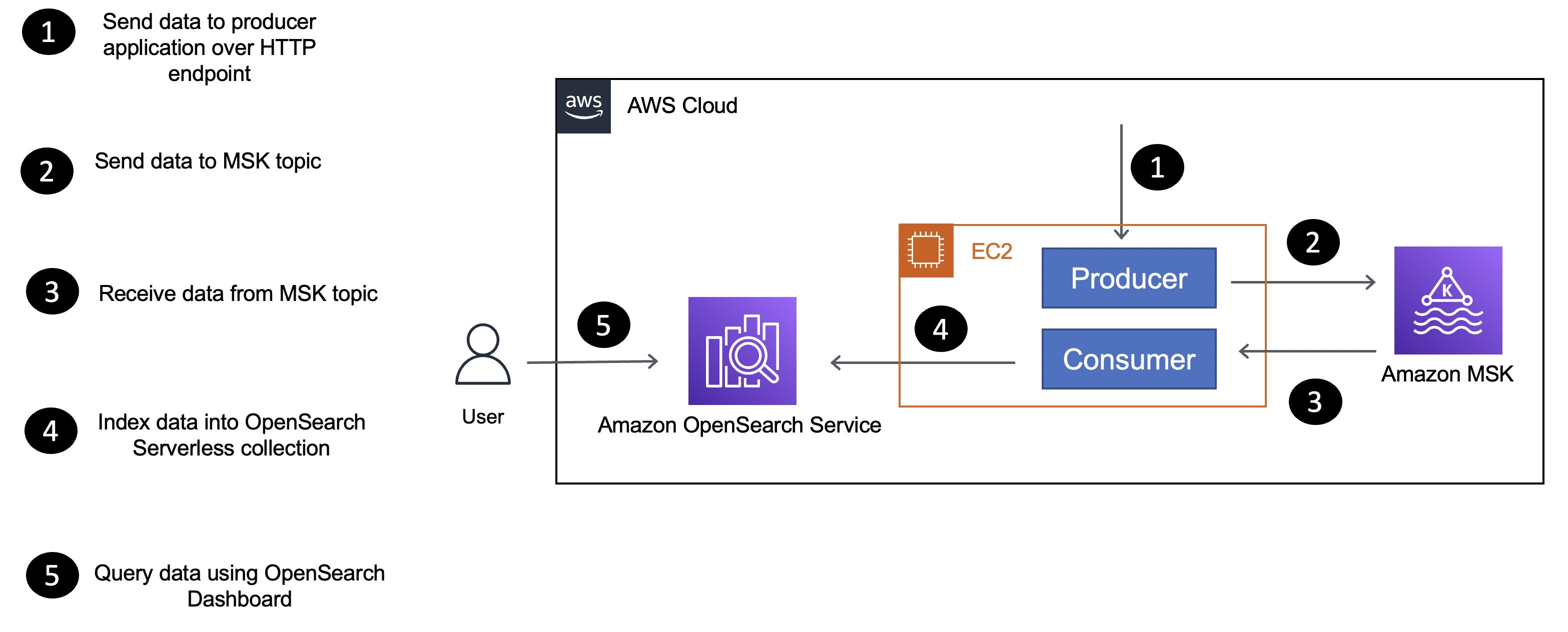
该应用程序由生产者和消费者组件组成,它们是部署到实例的 Go 应用程序EC2:
- 顾名思义,生产者将数据发送到 MSK Serverless 集群。
- 消费者应用程序
movie从 MSK Serverless 主题接收数据(信息),并使用 OpenSearch Go 客户端对movies集合中的数据进行索引。
注重简单性
值得注意的是,该博客文章已针对简单性和易于理解进行了优化,因此该解决方案并未针对运行生产工作负载进行调整。以下是一些已进行的简化:
- 生产者和消费者应用程序在同一计算平台(EC2 实例)上运行。
- 有一个消费者应用程序实例处理来自 MSK 主题的数据。但是,您可以尝试运行使用者应用程序的多个实例,并查看数据如何在实例之间分布。
- 不是使用 Kafka CLI 来生成数据,而是用 Go 编写自定义生成器应用程序以及 REST 端点来发送数据。这演示了如何用 Go 编写 Kafka 生产者应用程序并模仿 Kafka CLI。
- 使用的数据量很小。
- OpenSearch Serverless 集合具有公共访问类型。
对于生产工作负载,您应该考虑以下一些事项:
根据数据量和可扩展性要求为您的消费者应用程序选择合适的计算平台 - 下文将详细介绍。
为您的 OpenSearch Serverless 集合选择 VPC访问类型。
考虑使用Amazon OpenSearch Ingestion创建数据管道。
如果您仍然需要部署自定义应用程序来构建从 MSK 到 OpenSearch 的数据管道,以下是您可以选择的计算选项范围:
容器:您可以将消费者应用程序打包为 Docker 容器(Dockerfile可在 GitHub 存储库中获取)并将其部署到Amazon EKS或Amazon ECS。
如果您将应用程序部署到 Amazon EKS,您还可以考虑使用KEDA根据 MSK 主题中的消息数量自动扩展您的消费者应用程序。
无服务器:还可以使用MSK 作为 AWS Lambda 函数的事件源。您可以将消费者应用程序编写为 Lambda 函数,并将其配置为由 MSK 事件触发,或者在AWS Fargate上运行。
由于生产者应用程序是 REST API,因此您可以将其部署到 AWS App Runner。
最后,您可以利用Amazon EC2 Auto Scaling 组为您的消费者应用程序自动扩展 EC2 队列。
有足够的材料讨论如何使用基于 Java 的 Kafka 应用程序通过IAM 与 MSK Serverless连接。
让我们绕道了解一下 Go 的工作原理。
Go 客户端应用程序如何使用 IAM 通过 MSK Serverless 进行身份验证?
MSK Serverless 需要 IAM 访问控制来处理 MSK 集群的身份验证和授权。这意味着您的 MSK 客户端应用程序(在本例中为生产者和消费者)必须使用 IAM 向 MSK 进行身份验证,基于此它们将被允许或拒绝特定的 Apache Kafka 操作。
好处是franz-goKafka 客户端库支持 IAM 身份验证。以下是消费者应用程序的片段,展示了它在实践中的工作原理:
func init() {
//......cfg, err = config.LoadDefaultConfig(context.Background(), config.WithRegion("us-east-1"), config.WithCredentialsProvider(ec2rolecreds.New()))creds, err = cfg.Credentials.Retrieve(context.Background())
//....func initializeKafkaClient() {opts := []kgo.Opt{kgo.SeedBrokers(strings.Split(mskBroker, ",")...),kgo.SASL(sasl_aws.ManagedStreamingIAM(func(ctx context.Context) (sasl_aws.Auth, error) {return sasl_aws.Auth{AccessKey: creds.AccessKeyID,SecretKey: creds.SecretAccessKey,SessionToken: creds.SessionToken,UserAgent: "msk-ec2-consumer-app",}, nil})),
//.....
基础设施设置
本节将帮助您设置以下组件:
- 所需的 IAM 角色
- MSK 无服务器集群
- OpenSearch 无服务器集合
- 用于运行应用程序的 AWS Cloud9 EC2 环境
MSK 无服务器集群
您可以按照本文档使用 AWS 控制台设置 MSK 无服务器集群。执行此操作后,记下以下集群信息:VPC、子网、安全组(“属性”选项卡)和集群端点(单击“查看客户端信息”)。
应用程序 IAM 角色
本教程需要不同的 IAM 角色。
首先创建 IAM 角色来执行后续步骤,并按照步骤 1:配置权限(在 Amazon OpenSearch 文档中)的权限使用 OpenSearch Serverless。
为客户端应用程序创建另一个 IAM 角色,该角色将与 MSK Serverless 集群交互,并使用 OpenSearch Go 客户端对 OpenSearch Serverless 集合中的数据建立索引。创建如下内联 IAM 策略 - 确保替换所需的值。
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Action": ["kafka-cluster:*"],"Resource": ["<ARN of the MSK Serverless cluster>","arn:aws:kafka:us-east-1:<AWS_ACCOUNT_ID>:topic/<MSK_CLUSTER_NAME>/*","arn:aws:kafka:us-east-1:AWS_ACCOUNT_ID:group/<MSK_CLUSTER_NAME>/*"]},{"Effect": "Allow","Action": ["aoss:APIAccessAll"],"Resource": "*"}]
}使用以下信任策略:
{"Version": "2012-10-17","Statement": [{"Effect": "Allow","Principal": {"Service": "ec2.amazonaws.com"},"Action": "sts:AssumeRole"}]
}最后,您将向其附加 OpenSearch Serverless数据访问策略的另一个 IAM 角色- 下一步将详细介绍这一点。
OpenSearch 无服务器集合
使用文档创建 OpenSearch Serverless 集合。在遵循步骤 2:创建集合中的第 8 点时,请确保配置两个数据策略;即,在上一节的步骤 2 和 3 中创建的每个 IAM 角色。
注意:出于本教程的目的,我们选择公共访问类型。建议为生产工作负载选择VPC。
AWS Cloud9 EC2 环境
使用此文档创建 AWS Cloud9 EC2 开发环境。确保使用与 MSK Serverless 集群相同的VPC。
完成后,您需要执行以下操作: 打开 Cloud9 环境。在EC2 实例下,单击管理 EC2 实例。在 EC2 实例中,导航到安全性并记下附加的安全组。
打开与 MSK Serverless 集群关联的安全组并添加入站规则以允许 Cloud9 EC2 实例连接到它。选择Cloud9 EC2实例的安全组作为源,9098作为端口,选择TCP协议。
您现在已准备好运行该应用程序!
选择 Cloud9 环境并选择Open in Cloud9以启动 IDE。打开终端窗口,克隆 GitHub 存储库,然后将目录更改为该文件夹。
git clone https://github.com/build-on-aws/opensearch-using-kafka-golangcd opensearch-using-kafka-golang启动生产者应用程序:
cd msk-producerexport MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=moviesgo run main.go您应该在终端中看到以下日志:
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
starting producer app
http server ready要将数据发送到 MSK 无服务器集群,请使用 bash 脚本,该脚本将调用HTTP您刚刚启动的应用程序公开的端点,并使用movies.txt以下格式提交电影数据(来自文件):JSONcurl
./send-data.sh在生产者应用程序终端日志中,您应该看到类似于以下内容的输出:
producing data to topic
payload {"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
record produced successfully to offset 2 in partition 0 of topic moviesproducing data to topic
payload {"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
record produced successfully to offset 4 in partition 1 of topic movies.....出于本教程的目的并使其简单易懂,数据量已特意限制为 1500 条记录,并且脚本在将每条记录发送到生产者后有意休眠 1 秒。您应该能够轻松地跟随。
当生产者应用程序忙于向movies主题发送数据时,您可以启动消费者应用程序,开始处理来自 MSK Serverless 集群的数据,并将其在 OpenSearch Serverless 集合中建立索引。
cd msk-consumerexport MSK_BROKER=<enter MSK Serverless cluster endpoint>
export MSK_TOPIC=movies
export OPENSEARCH_INDEX_NAME=movies-index
export OPENSEARCH_ENDPOINT_URL=<enter OpenSearch Serverless endpoint>go run main.go您应该在终端中看到以下输出,这表明它确实已开始从 MSK Serverless 集群接收数据并在 OpenSearch Serverless 集合中对其建立索引。
using default value for AWS_REGION - us-east-1
MSK_BROKER <MSK Serverless cluster endpoint>
MSK_TOPIC movies
OPENSEARCH_INDEX_NAME movies-index
OPENSEARCH_ENDPOINT_URL <OpenSearch Serverless endpoint>
using credentials from: EC2RoleProvider
kafka consumer goroutine started. waiting for records
paritions ASSIGNED for topic movies [0 1 2]got record from partition 1 key= val={"directors": ["Joseph Gordon-Levitt"], "release_date": "2013-01-18T00:00:00Z", "rating": 7.4, "genres": ["Comedy", "Drama"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQxNTc3NDM2MF5BMl5BanBnXkFtZTcwNzQ5NTQ3OQ@@._V1_SX400_.jpg", "plot": "A New Jersey guy dedicated to his family, friends, and church, develops unrealistic expectations from watching porn and works to find happiness and intimacy with his potential true love.", "title": "Don Jon", "rank": 1, "running_time_secs": 5400, "actors": ["Joseph Gordon-Levitt", "Scarlett Johansson", "Julianne Moore"], "year": 2013}
movie data indexed
committing offsets
got record from partition 2 key= val={"directors": ["Ron Howard"], "release_date": "2013-09-02T00:00:00Z", "rating": 8.3, "genres": ["Action", "Biography", "Drama", "Sport"], "image_url": "http://ia.media-imdb.com/images/M/MV5BMTQyMDE0MTY0OV5BMl5BanBnXkFtZTcwMjI2OTI0OQ@@._V1_SX400_.jpg", "plot": "A re-creation of the merciless 1970s rivalry between Formula One rivals James Hunt and Niki Lauda.", "title": "Rush", "rank": 2, "running_time_secs": 7380, "actors": ["Daniel Br\u00c3\u00bchl", "Chris Hemsworth", "Olivia Wilde"], "year": 2013}
movie data indexed
committing offsets.....该过程完成后,您应该1500在 OpenSearch Serverless 集合中为电影建立索引。不过,您不必等待它完成。一旦有了数百条记录,您就可以继续导航到OpenSearch 仪表板中的开发工具来执行以下查询。
在 OpenSearch 中查询电影数据
运行简单查询
让我们从一个简单的查询开始,列出索引中的所有文档(不带任何参数或过滤器)。
GET movies-index/_search仅获取特定字段的数据
默认情况下,搜索请求会检索对文档建立索引时提供的整个 JSON 对象。使用该_source选项从选定字段检索源。例如,要仅检索title、plot和genres字段,请运行以下查询:
GET movies-index/_search
{"_source": {"includes": ["title","plot","genres"]}
}获取数据以与术语查询的精确搜索术语匹配
您可以使用术语查询来实现此目的。例如,要搜索字段christmas中包含该术语的电影title,请运行以下查询:
GET movies-index/_search
{"query": {"term": { "title": {"value": "christmas"}}}
}**将选择性字段选择与术语查询相结合。
您可以使用此查询仅检索某些字段,但对特定术语感兴趣:
GET movies-index/_search
{"_source": {"includes": ["title","actors"]},"query": {"query_string": {"default_field": "title","query": "harry"}}
}聚合
使用聚合根据特定字段中的值分组来计算汇总值。例如,您可以汇总ratings、 、genre和 等字段year,以根据这些字段的值搜索结果。通过聚合,我们可以回答这样的问题:“每种类型有多少部电影?”
GET movies-index/_search
{"size":0,"aggs": {"genres": {"terms":{"field": "genres.keyword"}}}
}结论
回顾一下,您部署了一个管道,使用 Kafka 将数据提取到 OpenSearch Serverless 中,然后以不同的方式对其进行查询。在此过程中,您还了解了生产工作负载需要记住的架构注意事项和计算选项,以及使用基于 Go 的 Kafka 应用程序和 MSK IAM 身份验证。我还建议阅读文章在 Go 中为 Amazon OpenSearch 构建 CRUD 应用程序,特别是如果您正在寻找以通过 Go SDK 执行 OpenSearch 操作为中心的教程。
相关文章:
使用 Apache Kafka 和 Go 将数据引入 OpenSearch
需要编写自定义集成层来满足数据管道中的特定要求?了解如何使用 Go 通过 Kafka 和 OpenSearch 实现此目的。 可扩展的数据摄取是OpenSearch等大规模分布式搜索和分析引擎的一个关键方面。构建实时数据摄取管道的方法之一是使用Apache Kafka。它是一个开源事件流平台…...

2.SpringMvc中Model、ModelMap和ModelAndView使用详解
1.前言 最近SSM框架开发web项目,用得比较火热。spring-MVC肯定用过,在请求处理方法可出现和返回的参数类型中,最重要就是Model和ModelAndView了,对于MVC框架,控制器Controller执行业务逻辑,用于产生模型数据…...

Spark repartition和coalesce的区别
repartition只是coalesce接口中shuffle为true的实现。不经过 shuffle,也就是coaleasce shuffle为false,是无法增加RDD的分区数的,比如你源RDD 100个分区,想要变成200个分区,只能使用repartition,也就是coal…...
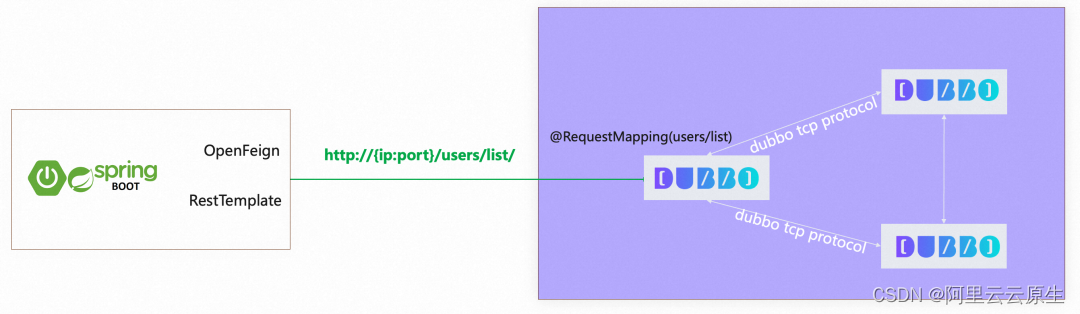
微服务最佳实践,零改造实现 Spring Cloud Apache Dubbo 互通
作者:孙彩荣 很遗憾,这不是一篇关于中间件理论或原理讲解的文章,没有高深晦涩的工作原理分析,文后也没有令人惊叹的工程数字统计。本文以实际项目和代码为示例,一步一步演示如何以最低成本实现 Apache Dubbo 体系与 S…...

leetcode 力扣刷题 两数/三数/四数之和 哈希表和双指针解题
两数/三数/四数之和 题目合集 哈希表求解1. 两数之和454. 四数相加Ⅱ 双指针求解15.三数之和18. 四数之和 这个博客是关于:找出数组中几个元素,使其之和等于题意给出的target 这一类题目的,但是各个题之间又有些差异,使得需要用不…...
(搜索) 剑指 Offer 12. 矩阵中的路径 ——【Leetcode每日一题】
❓剑指 Offer 12. 矩阵中的路径 难度:中等 给定一个 m * n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。 单词必须按照字母顺序,通过相邻的单元格内的字母构…...
构建高可用的去中心化微服务集群架构指南
随着云计算、大数据和物联网的快速发展,企业对于可扩展的、高性能的微服务架构的需求也日益增长。传统的集中式架构已经不能满足这些需求,因此出现了去中心化的微服务集群架构。本文将介绍如何构建高可用的去中心化微服务集群架构,以满足企业…...

Sui主网升级至V1.7.1版本
Sui主网现已升级至V1.7.1版本,此升级包含了多项修复和优化。升级要点如下所示: #12915 协议版本提升至20版本。 在Sui框架中新增Kiosk Extensions API和一个新的sui::kiosk_extension模块。 您可以使用该API构建自定义的Kiosk应用程序,以…...
-[基础知识])
自然语言处理从入门到应用——LangChain:索引(Indexes)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录 索引(Indexes)是指为了使LLM与文档更好地进行交互而对其进行结构化的方式。在链中,索引最常用于“检索”步骤中,该步骤指的是根据用户的查询返回最相关的文档:…...
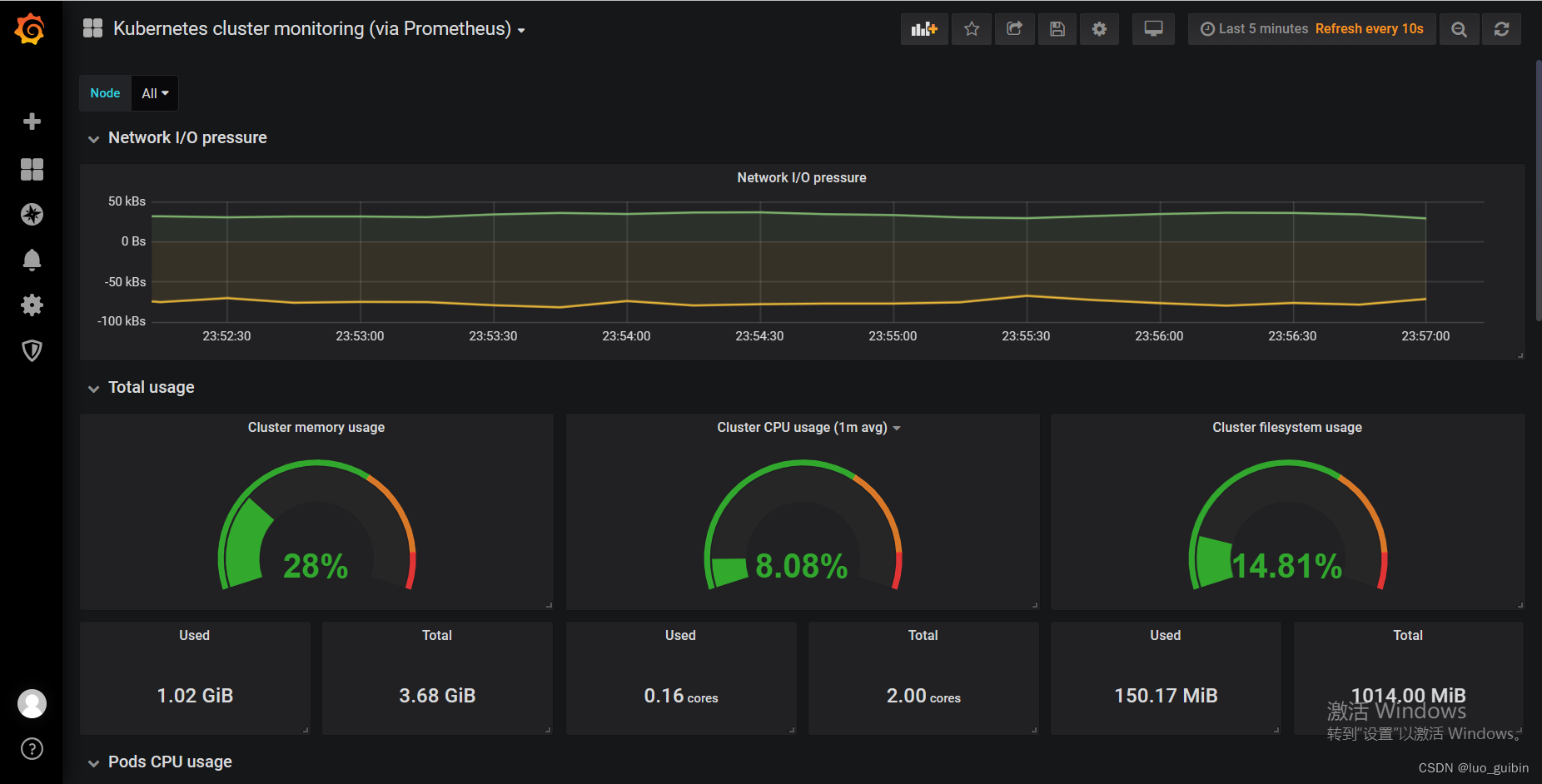
k8s集群监控方案--node-exporter+prometheus+grafana
目录 前置条件 一、下载yaml文件 二、部署yaml各个组件 2.1 node-exporter.yaml 2.2 Prometheus 2.3 grafana 2.4访问测试 三、grafana初始化 3.1加载数据源 3.2导入模板 四、helm方式部署 前置条件 安装好k8s集群(几个节点都可以,本人为了方便实验k8s集…...
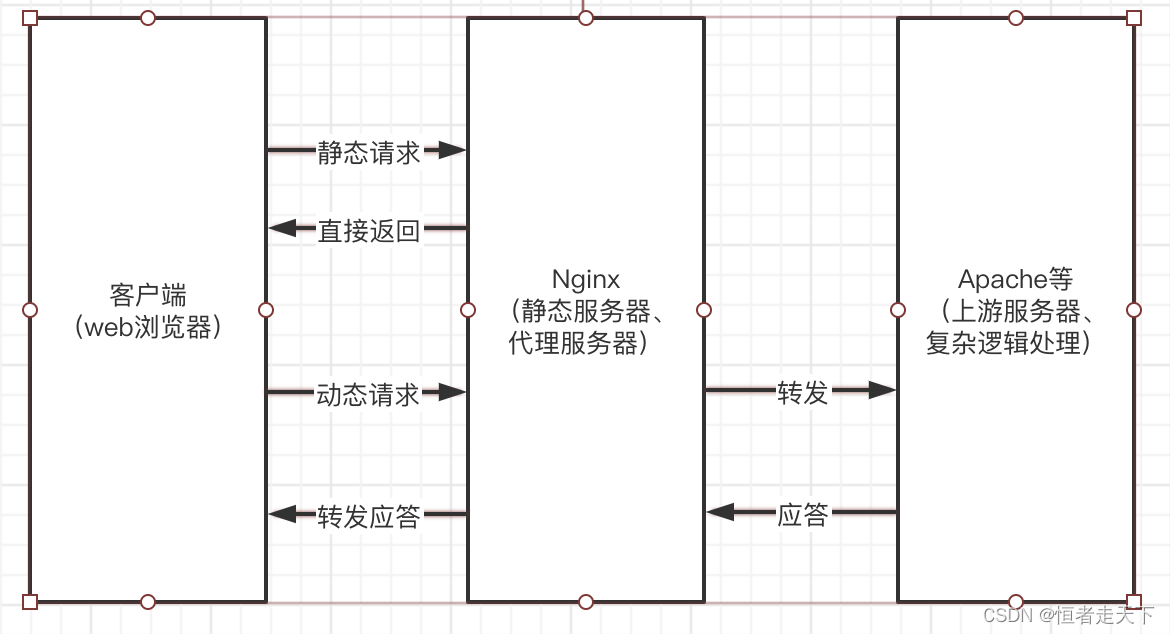
nginx反向代理流程
一、nginx反向代理流程 反向代理:使用代理服务器来接受internet上的连接请求,然后将请求转发给内部网络中的上游服务器,并将上游服务器得到的结果返回给请求连接的客户端,代理服务器对外表现就是一个web服务器。Nginx就经常拿来做…...

Java“牵手”根据店铺ID获取淘宝店铺所有商品数据方法,淘宝API实现批量店铺商品数据抓取示例
淘宝天猫商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取淘宝整店所有商品详情页面评价内容数据,您可以通过开放平台的接口或者直接访问淘宝商城的网页来获取店铺所有商品详情信息内的评论数据…...

从0开始yolov8模型目标检测训练
从0开始yolov8模型目标检测训练 1 大环境 首先有大环境,即已经准备好了python、nvidia驱动、cuda、cudnn等。 2 yolov8的虚拟环境 2.1 创建虚拟环境 conda create -n yolov8 python3.102.2 激活虚拟环境 注意:激活虚拟环境的时候,需要清…...

设计模式-抽象工厂模式
抽象工厂模式:该模式是对工厂模式的拓展,因为工厂模式中创建的产品都需要继承自同一个父类或接口,创建的产品类型相同,无法创建其他类型产品,所以抽象工厂模式对其进行拓展,使其可以创建其他类型的产品。 …...
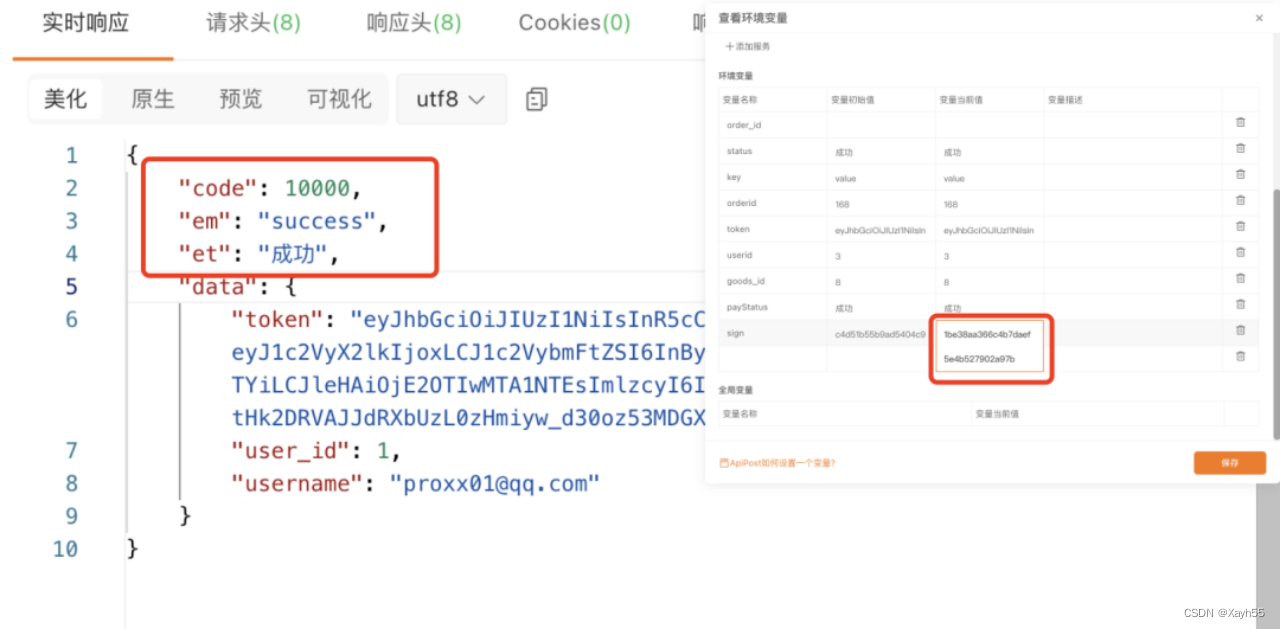
如何用Apipost实现sign签名?
我们平常对外的接口都会用到sign签名,对不同的用户提供不同的apikey ,这样可以提高接口请求的安全性,避免被人抓包后乱请求。 如何用Apipost实现sign签名? 可以在Apipost中通过预执行脚本调用内置的JS库去实现预执行脚本是在发送请求之前自…...
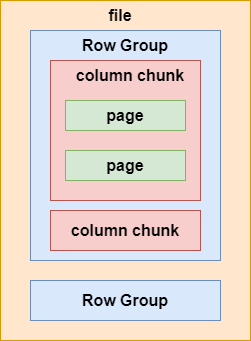
Hive底层数据存储格式
前言 在大数据领域,Hive是一种常用的数据仓库工具,用于管理和处理大规模数据集。Hive底层支持多种数据存储格式,这些格式对于数据存储、查询性能和压缩效率等方面有不同的优缺点。本文将介绍Hive底层的三种主要数据存储格式:文本文件格式、Parquet格式和ORC格式。 一、三…...
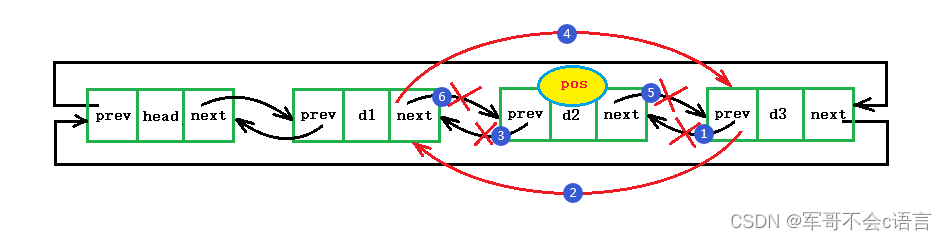
双向-->带头-->循环链表
目录 一、双向带头循环链表概述 1.什么是双向带头循环链表 2.双向带头循环链表的优势 3.双向带头循环链表简图 二、双向带头循环链表的增删查改图解及代码实现 1.双向带头循环链表的头插 2.双向带头循环链表的尾插 3.双向带头循环链表的头删 4.双向带头循环链表的尾删…...

Opencv4基于C++基础入门笔记:OpenCV环境配置搭建
文章目录: 一:软件安装 二:配置环境(配置完之后重启一下软件) 1.配置电脑系统环境变量 vs2012及其以下 vs2014及其以上 2.配置VS软件环境变量 vs2012及其以下 vs2014及其以上 三:测试 vs2012及其…...

JS基础之实现map方法
提示:内容虽少,但是里面也有好几个知识点。 step 1:实现函数 function mapTmp (fn){if(!Array.isArray(this) || !this?.length) return [];const arr [];this.forEach((item, index) > {const newItem fn(item, index, this);arr.pu…...
FPGA应用学习笔记-----复位电路(二)和小结
不可复位触发器若和可复位触发器混合写的话,不可复位触发器是由可复位触发器馈电的。 不应该出现的复位,因为延时导致了冒险,异步复位存在静态冒险 附加素隐含项,利用数电方法,消除静态冒险 这样多时钟区域还是算异步的…...
 —— STM32的SPI外设)
STM32单片机学习(28) —— STM32的SPI外设
文章目录概述SPI通信的移位机制(以bit为单位)SPI外设框图第一部分:数据通路SPI通信的数据帧格式SPI外设移位机制(以字节为单位)第二部分:主机时钟生成器SPI通信时钟频率与传输速率第三部分:主从…...

AMLP框架实战:基于MACE构建高精度机器学习势函数
1. 项目概述:当机器学习势函数遇上自动化管道在计算化学和材料科学领域,我们长久以来面临着一个核心矛盾:精度与效率的权衡。密度泛函理论(DFT)能提供接近实验的精度,但计算成本高昂,通常只能处…...

如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优
如何用SMUDebugTool彻底掌控你的AMD Ryzen处理器性能调优 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://gitcode.co…...

户外实用|艾迪欧 R6000 测评 —— 户外 / 自驾 / 露营的通讯好搭档
户外出行,通讯工具的核心是稳定、清晰、耐用、续航久、功能全。艾迪欧 R6000 作为一款兼顾专业与户外的 DMR 对讲机,全频段覆盖、双模通讯、自定义功能、长续航,完美适配自驾、露营、登山、越野等户外场景,是户外爱好者的靠谱通讯…...

如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南
如何扩展GASShooter:添加新武器、新能力与新游戏机制的终极指南 【免费下载链接】GASShooter Advanced FPS/TPS Sample Project for Unreal Engine 4s GameplayAbilitySystem plugin 项目地址: https://gitcode.com/gh_mirrors/ga/GASShooter GASShooter是Un…...

LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析
LeagueAkari:基于LCU接口的英雄联盟客户端自动化工具深度解析 【免费下载链接】League-Toolkit An all-in-one toolkit for LeagueClient. Gathering power 🚀. 项目地址: https://gitcode.com/gh_mirrors/le/League-Toolkit 功能模块架构与核心技…...

概率论:常见分布的期望与方差、中心极限定理、切比雪夫不等式
目录 一、0、1分布 二、二项分布 三、泊松分布 四、均匀分布 五、指数分布 六、正态分布 七、中心极限定理及其应用 (1)中心极限定理的定义 (2)使用示例 八、切比雪夫不等式 (1)切比雪夫不…...

关于内卷,几个值得深想的洞察
首先声明:这篇不劝躺平,也不教内卷——只是想说清楚,你到底在一个什么样的游戏里。 你以为内卷是“资源不足”,其实是“分配方式” 很多人对内卷有个本质上的认知错误:以为内卷是因为资源不够,大家为了抢资…...

OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS
OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重获新…...

OpenTK 3.3.3实现3D旋转立方体:C# OpenGL入门实战
1. 为什么一个旋转立方体是3D图形编程真正的“Hello World” 很多人第一次接触OpenGL或现代图形API时,总想直接上手做粒子系统、PBR渲染或者实时阴影——结果卡在顶点缓冲对象(VBO)绑定失败、着色器编译报错、甚至窗口根本没显示出来。我带过…...