Spark repartition和coalesce的区别
- repartition只是coalesce接口中shuffle为true的实现。
- 不经过 shuffle,也就是coaleasce shuffle为false,是无法增加RDD的分区数的,比如你源RDD 100个分区,想要变成200个分区,只能使用repartition,也就是coaleasce shuffle为true。
- 如果上游为Partition个数为N,下游想要变成M个Partition。
- N > M , 比如N=100 M=60, 可以使用coaleasce shuffle为false。
- 但是如果N远大于M,比如N=100, M=1, 分区有一个激烈的变化时,此时如果用coalesce就只有一个task处理数据,资源利用不够,Executor空跑,这时repartition是一个比较好的选择,虽然有shuffle但是和只有1个Task处理任务比起来效率还是较高。
- N < M , coaleasce shuffle为false 不能增加分区,只能用repartition。
一、spark 分区 partition的理解
spark中是以vcore级别调度task
如果读取的是hdfs,那么有多少个block,就有多少个partition
举例来说:sparksql 要读表T, 如果表T有1w个小文件,那么就有1w个partition
这时候读取效率会较低。假设设置资源为 --executor-memory 2g --executor-cores 2 --num-executors 5。
步骤是:
- 拿出1-10号10个小文件(也就是10个partition) 分别给5个executor读取(spark调度会以vcore为单位,实际就是5个executor,10个task读10个partition)
- 如果5个executor执行速度相同,再拿11-20号文件 依次给这5个executor读取
- 而实际执行速度不会完全相同,那就是哪个task先执行完,哪个task领取下一个partition读取执行,以此类推。这样往往读取文件的调度时间大于读取文件本身,而且会频繁打开关闭文件句柄,浪费较为宝贵的io资源,执行效率也大大降低。
二、coalesce 与 repartition的区别(我们下面说的coalesce都默认shuffle参数为false的情况)
repartition(numPartitions:Int):RDD[T]和coalesce(numPartitions:Int,shuffle:Boolean=false):RDD[T]
repartition只是coalesce接口中shuffle为true的实现
我们还拿上面的例子说:
有1w的小文件,资源也为--executor-memory 2g --executor-cores 2 --num-executors 5。
- repartition(4):产生shuffle。这时会启动5个executor像之前介绍的那样依次读取1w个分区的文件,然后按照某个规则%4,写到4个文件中,这样分区的4个文件基本毫无规律,比较均匀。
- coalesce(4):这个coalesce不会产生shuffle。那启动5个executor在不发生shuffle的时候是如何生成4个文件呢,其实会有1个或2个或3个甚至更多的executor在空跑(具体几个executor空跑与spark调度有关,与数据本地性有关,与spark集群负载有关),他并没有读取任何数据!
PS:
- 如果结果产生的文件数要比源RDD partition少,用coalesce是实现不了的,例如有4个小文件(4个partition),你要生成5个文件用coalesce实现不了,也就是说不产生shuffle,无法实现文件数变多。
- 如果你只有1个executor(1个core),源RDD partition有5个,你要用coalesce产生2个文件。那么他是预分partition到executor上的,例如0-2号分区在先executor上执行完毕,3-4号分区再次在同一个executor执行。其实都是同一个executor但是前后要串行读不同数据。与用repartition(2)在读partition上有较大不同(串行依次读0-4号partition 做%2处理)。
三、实例
T表有10G数据 有100个partition 资源也为--executor-memory 2g --executor-cores 2 --num-executors 5。我们想要结果文件只有一个
- 如果用coalesce:sql(select * from T).coalesce(1)
5个executor 有4个在空跑,只有1个在真正读取数据执行,这时候效率是极低的。所以coalesce要慎用,而且它还用产出oom问题,这个我们以后再说。
- 如果用repartition:sql(select * from T).repartition(1)
这样效率就会高很多,并行5个executor在跑(10个task),然后shuffle到同一节点,最后写到一个文件中。
那么如果我不想产生一个文件了,我想产生10个文件会怎样,是不是coalesce 又变得比 repartition高效了呢。(因为coalesce无shuffle,相当于每个executor的 task认领 10个 partition)
那么如果我又不想产生10个文件呢?其实一旦要产生的文件数大于executor x vcore数,coalesce效率就更高(一般是这样,不绝对)。
四、总结
我们常认为coalesce不产生shuffle会比repartition 产生shuffle效率高,而实际情况往往要根据具体问题具体分析,coalesce效率不一定高,有时还有大坑,大家要慎用。
coalesce 与 repartition 他们两个都是RDD的分区进行重新划分,repartition只是coalesce接口中shuffle为true的实现(假设源RDD有N个分区,需要重新划分成M个分区)
1)如果N<M。一般情况下N个分区有数据分布不均匀的状况,利用HashPartitioner函数将数据重新分区为M个,这时需要将shuffle设置为true(repartition实现,coalesce也实现不了)。
2)如果N>M并且N和M相差不多,(假如N是1000,M是100)那么就可以将N个分区中的若干个分区合并成一个新的分区,最终合并为M个分区,这时可以将shuff设置为false(coalesce实现),如果M>N时,coalesce是无效的,不进行shuffle过程,父RDD和子RDD之间是窄依赖关系,无法使文件数(partiton)变多。
总之如果shuffle为false时,如果传入的参数大于现有的分区数目,RDD的分区数不变,也就是说不经过shuffle,是无法将RDD的分区数变多的
3)如果N>M并且两者相差悬殊,这时你要看executor数与要生成的partition关系,如果executor数 <= 要生成partition数,coalesce效率高,反之如果用coalesce会导致(executor数-要生成partiton数)个excutor空跑从而降低效率。如果在M为1的时候,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true。
参考:Spark repartition和coalesce的区别 - 简书
相关文章:

Spark repartition和coalesce的区别
repartition只是coalesce接口中shuffle为true的实现。不经过 shuffle,也就是coaleasce shuffle为false,是无法增加RDD的分区数的,比如你源RDD 100个分区,想要变成200个分区,只能使用repartition,也就是coal…...
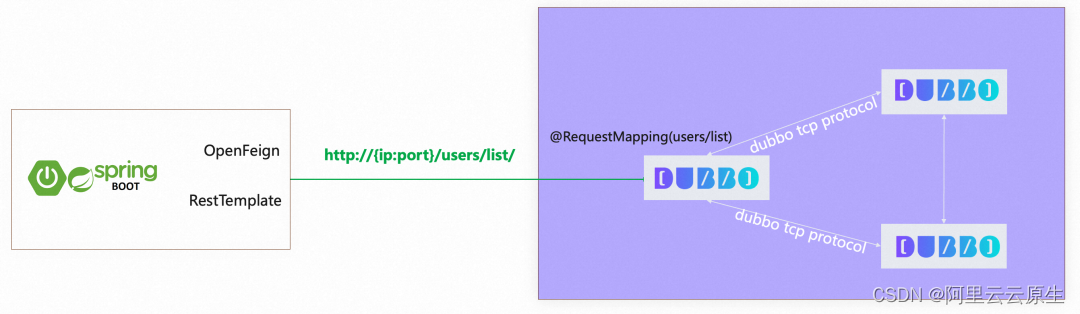
微服务最佳实践,零改造实现 Spring Cloud Apache Dubbo 互通
作者:孙彩荣 很遗憾,这不是一篇关于中间件理论或原理讲解的文章,没有高深晦涩的工作原理分析,文后也没有令人惊叹的工程数字统计。本文以实际项目和代码为示例,一步一步演示如何以最低成本实现 Apache Dubbo 体系与 S…...

leetcode 力扣刷题 两数/三数/四数之和 哈希表和双指针解题
两数/三数/四数之和 题目合集 哈希表求解1. 两数之和454. 四数相加Ⅱ 双指针求解15.三数之和18. 四数之和 这个博客是关于:找出数组中几个元素,使其之和等于题意给出的target 这一类题目的,但是各个题之间又有些差异,使得需要用不…...
(搜索) 剑指 Offer 12. 矩阵中的路径 ——【Leetcode每日一题】
❓剑指 Offer 12. 矩阵中的路径 难度:中等 给定一个 m * n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。 单词必须按照字母顺序,通过相邻的单元格内的字母构…...
构建高可用的去中心化微服务集群架构指南
随着云计算、大数据和物联网的快速发展,企业对于可扩展的、高性能的微服务架构的需求也日益增长。传统的集中式架构已经不能满足这些需求,因此出现了去中心化的微服务集群架构。本文将介绍如何构建高可用的去中心化微服务集群架构,以满足企业…...

Sui主网升级至V1.7.1版本
Sui主网现已升级至V1.7.1版本,此升级包含了多项修复和优化。升级要点如下所示: #12915 协议版本提升至20版本。 在Sui框架中新增Kiosk Extensions API和一个新的sui::kiosk_extension模块。 您可以使用该API构建自定义的Kiosk应用程序,以…...
-[基础知识])
自然语言处理从入门到应用——LangChain:索引(Indexes)-[基础知识]
分类目录:《自然语言处理从入门到应用》总目录 索引(Indexes)是指为了使LLM与文档更好地进行交互而对其进行结构化的方式。在链中,索引最常用于“检索”步骤中,该步骤指的是根据用户的查询返回最相关的文档:…...
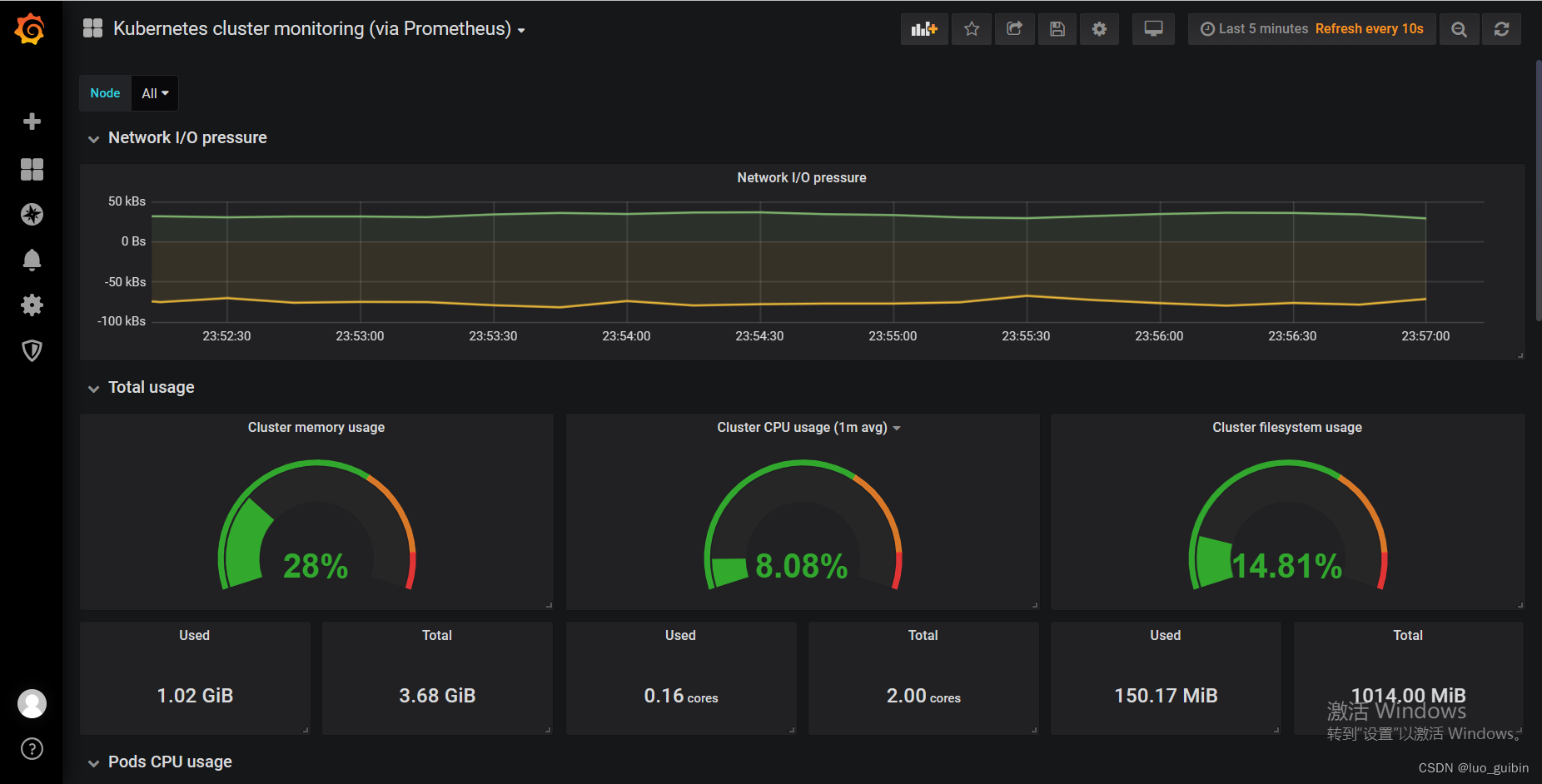
k8s集群监控方案--node-exporter+prometheus+grafana
目录 前置条件 一、下载yaml文件 二、部署yaml各个组件 2.1 node-exporter.yaml 2.2 Prometheus 2.3 grafana 2.4访问测试 三、grafana初始化 3.1加载数据源 3.2导入模板 四、helm方式部署 前置条件 安装好k8s集群(几个节点都可以,本人为了方便实验k8s集…...
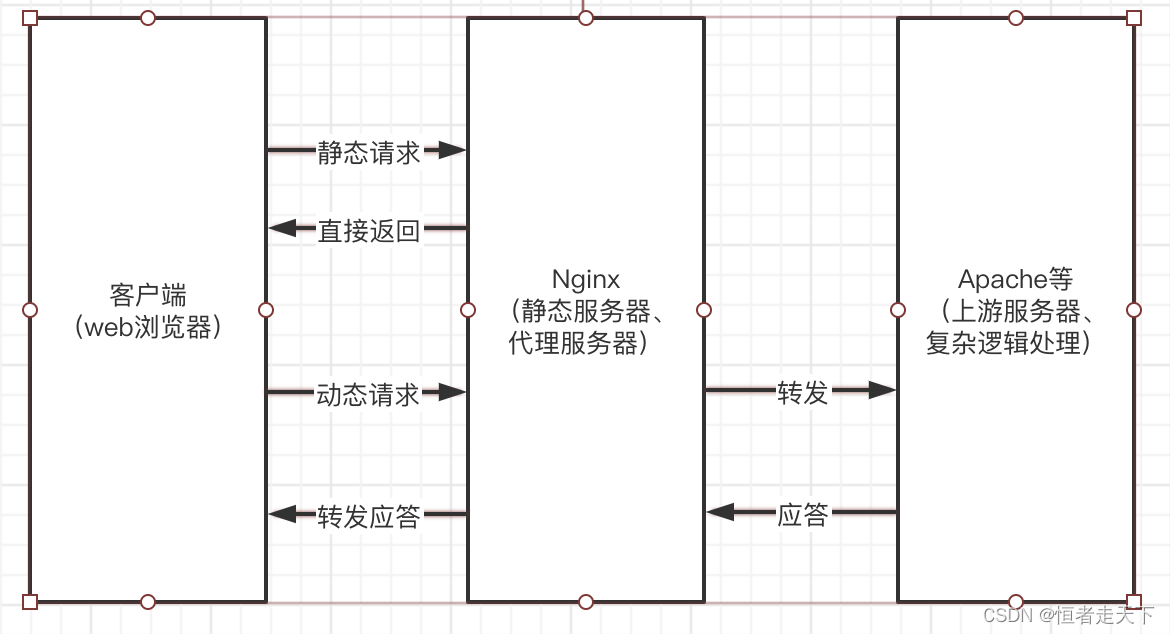
nginx反向代理流程
一、nginx反向代理流程 反向代理:使用代理服务器来接受internet上的连接请求,然后将请求转发给内部网络中的上游服务器,并将上游服务器得到的结果返回给请求连接的客户端,代理服务器对外表现就是一个web服务器。Nginx就经常拿来做…...

Java“牵手”根据店铺ID获取淘宝店铺所有商品数据方法,淘宝API实现批量店铺商品数据抓取示例
淘宝天猫商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取淘宝整店所有商品详情页面评价内容数据,您可以通过开放平台的接口或者直接访问淘宝商城的网页来获取店铺所有商品详情信息内的评论数据…...

从0开始yolov8模型目标检测训练
从0开始yolov8模型目标检测训练 1 大环境 首先有大环境,即已经准备好了python、nvidia驱动、cuda、cudnn等。 2 yolov8的虚拟环境 2.1 创建虚拟环境 conda create -n yolov8 python3.102.2 激活虚拟环境 注意:激活虚拟环境的时候,需要清…...

设计模式-抽象工厂模式
抽象工厂模式:该模式是对工厂模式的拓展,因为工厂模式中创建的产品都需要继承自同一个父类或接口,创建的产品类型相同,无法创建其他类型产品,所以抽象工厂模式对其进行拓展,使其可以创建其他类型的产品。 …...
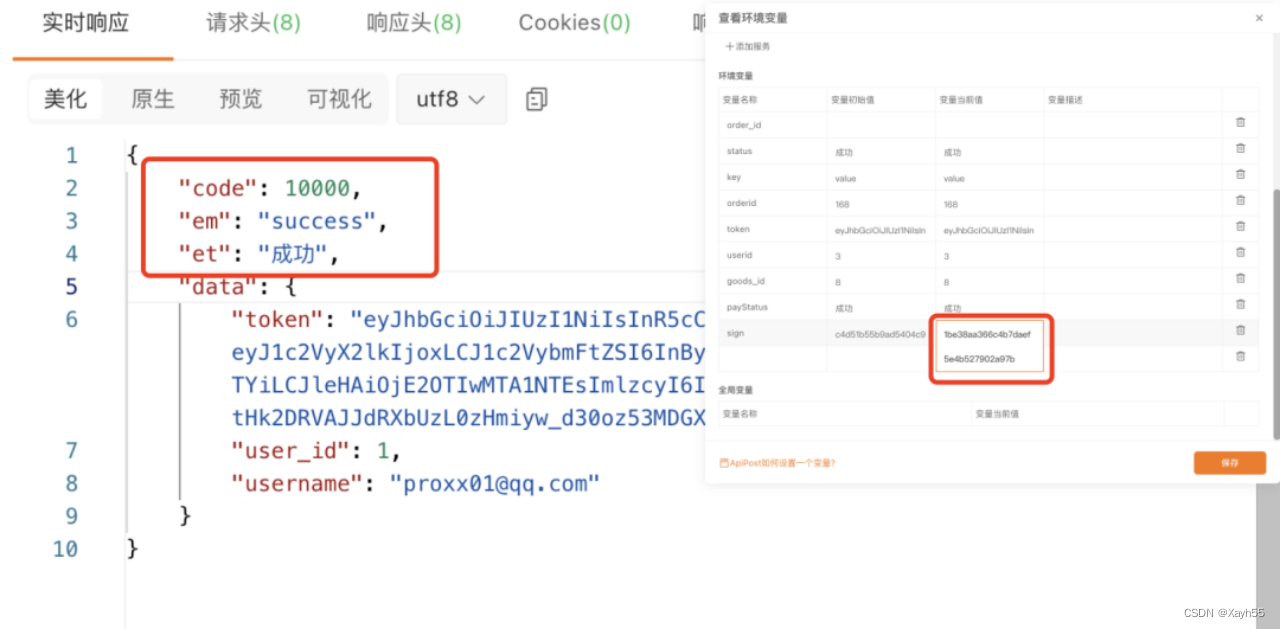
如何用Apipost实现sign签名?
我们平常对外的接口都会用到sign签名,对不同的用户提供不同的apikey ,这样可以提高接口请求的安全性,避免被人抓包后乱请求。 如何用Apipost实现sign签名? 可以在Apipost中通过预执行脚本调用内置的JS库去实现预执行脚本是在发送请求之前自…...
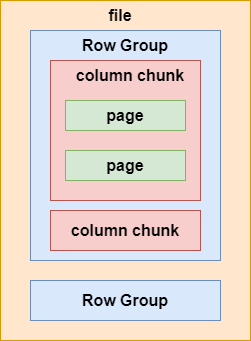
Hive底层数据存储格式
前言 在大数据领域,Hive是一种常用的数据仓库工具,用于管理和处理大规模数据集。Hive底层支持多种数据存储格式,这些格式对于数据存储、查询性能和压缩效率等方面有不同的优缺点。本文将介绍Hive底层的三种主要数据存储格式:文本文件格式、Parquet格式和ORC格式。 一、三…...
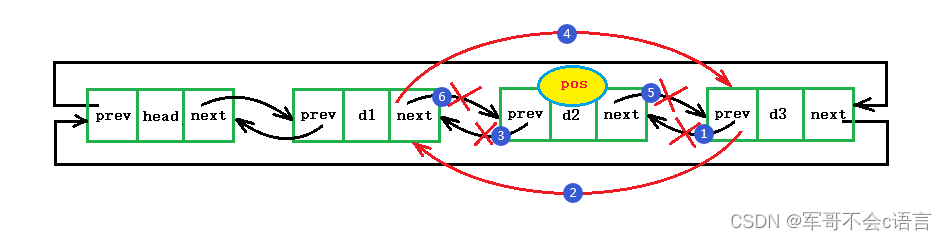
双向-->带头-->循环链表
目录 一、双向带头循环链表概述 1.什么是双向带头循环链表 2.双向带头循环链表的优势 3.双向带头循环链表简图 二、双向带头循环链表的增删查改图解及代码实现 1.双向带头循环链表的头插 2.双向带头循环链表的尾插 3.双向带头循环链表的头删 4.双向带头循环链表的尾删…...

Opencv4基于C++基础入门笔记:OpenCV环境配置搭建
文章目录: 一:软件安装 二:配置环境(配置完之后重启一下软件) 1.配置电脑系统环境变量 vs2012及其以下 vs2014及其以上 2.配置VS软件环境变量 vs2012及其以下 vs2014及其以上 三:测试 vs2012及其…...

JS基础之实现map方法
提示:内容虽少,但是里面也有好几个知识点。 step 1:实现函数 function mapTmp (fn){if(!Array.isArray(this) || !this?.length) return [];const arr [];this.forEach((item, index) > {const newItem fn(item, index, this);arr.pu…...
FPGA应用学习笔记-----复位电路(二)和小结
不可复位触发器若和可复位触发器混合写的话,不可复位触发器是由可复位触发器馈电的。 不应该出现的复位,因为延时导致了冒险,异步复位存在静态冒险 附加素隐含项,利用数电方法,消除静态冒险 这样多时钟区域还是算异步的…...
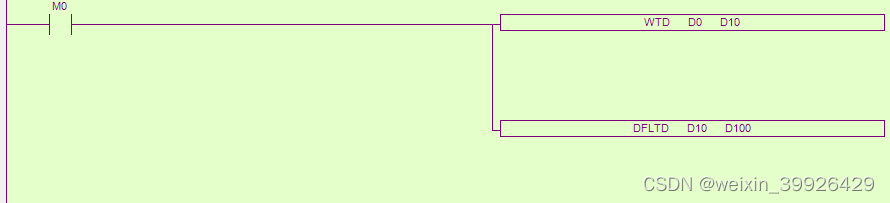
信捷 XD PLC 16位整数转换为双精度浮点数
完成16位整数转换为双精度浮点数,信捷XD PLC需要两个指令,逐步转换,一个指令搞不定。 具体的: 第1步:int16->int32 第2步:int32->Double 例子,比如说将D0转换成浮点数放到D100~D103...
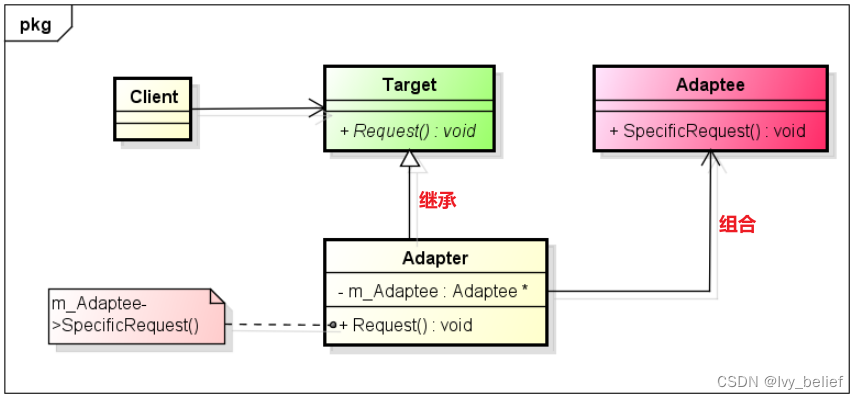
(二)结构型模式:1、适配器模式(Adapter Pattern)(C++实现示例)
目录 1、适配器模式(Adapter Pattern)含义 2、适配器模式应用场景 3、适配器模式的UML图学习 4、C实现适配器模式的示例 1、适配器模式(Adapter Pattern)含义 将一个接口转换为客户端所期待的接口,从而使两个接口…...

强化学习在并行机构人形机器人控制中的应用
1. 项目概述在机器人控制领域,强化学习(RL)正逐渐成为解决复杂动力学系统问题的有力工具。然而,当面对具有并行驱动机构的人形机器人时,传统RL训练方法往往面临一个关键挑战:大多数仿真环境无法准确模拟闭环运动链(Closed Kinemat…...

别再死记硬背SMO公式了!用Python手写一个SVM分类器,带你一步步拆解SMO核心逻辑
用Python手写SVM分类器:代码驱动理解SMO算法核心在机器学习领域,支持向量机(SVM)以其优秀的分类性能和坚实的数学基础著称。然而,许多学习者在理解其核心算法——序列最小优化(SMO)时,往往被复杂的数学推导所困扰。本文将采用一种…...

Python基础语法:常用内置函数
round():四舍五入 # 省略 ndigits print(round(3.14)) # 输出 3(int) print(round(3.66)) # 输出 4# 指定 ndigits print(round(3.14159, 2)) # 输出 3.14(float) print(round(3.666, 2)) # 输出 3.67# …...

Unity Visual Scripting不是拖拽玩具:中阶开发者的编程范式重构指南
1. 为什么Unity官方Visual Scripting不是“拖拽完就能跑”的玩具,而是一套需要重新理解的编程范式很多人第一次点开Unity的Visual Scripting(VS)面板时,看到那些五颜六色的节点和丝滑的连线,下意识觉得:“这…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...

Ubuntu经常安装软件
1、垃圾清理工具stacer sudo apt updatesudo apt install stacer apt cleanapt autocleanapt autoremove 2、类似与everything的工具Fsearcch 1sudo add-apt-repository ppa:christian-boxdoerfer/fsearch-stable 2sudo apt update 3sudo apt install fsearch (注…...
)
告别杂乱!用FileMenu Tools 8.4.2一键清理Windows 11右键菜单(附隐藏技巧)
Windows 11右键菜单精简指南:用FileMenu Tools打造高效工作流每次在文件上点击右键时,那个缓慢弹出的冗长菜单是否让你感到烦躁?随着安装的软件越来越多,Windows的右键菜单往往会变得臃肿不堪,严重影响工作效率。今天&…...
,锁定雾浓度≤0.38的7个关键阈值参数)
【云雾效果商业级交付标准】:基于Adobe Sensei图像雾度分析报告(N=1,247张MJ生成图),锁定雾浓度≤0.38的7个关键阈值参数
更多请点击: https://intelliparadigm.com 第一章:云雾效果商业级交付标准的定义与行业意义 云雾效果在现代数字体验中已超越视觉装饰范畴,成为空间感知建模、沉浸式交互与品牌情绪传达的核心媒介。商业级交付标准并非仅关注“是否可见雾气”…...

别再手动维护接口文档了!用Spring Boot 3和Swagger 3实现代码与文档的自动同步
Spring Boot 3与Swagger 3:构建零维护成本的API文档工作流 每次接口变更都要手动更新文档?团队成员总是抱怨文档与实际接口不一致?在敏捷开发时代,传统文档维护方式已成为拖累工程效率的典型痛点。本文将揭示如何通过Spring Boot …...

零基础怎么学Agent?这个工程师考试内容拆给你看
站在 AI Agent(智能体)爆发的十字路口,很多既没有深厚算法背景、也没有丰富写代码经验的“小白”常常感到迷茫:动辄谈及的大模型交互、复杂的业务编排,零基础真的能学会吗? 事实上,智能体开发早…...