2023国赛数学建模思路 - 复盘:校园消费行为分析
文章目录
- 0 赛题思路
- 1 赛题背景
- 2 分析目标
- 3 数据说明
- 4 数据预处理
- 5 数据分析
- 5.1 食堂就餐行为分析
- 5.2 学生消费行为分析
- 建模资料
0 赛题思路
(赛题出来以后第一时间在CSDN分享)
https://blog.csdn.net/dc_sinor?type=blog
1 赛题背景
校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统。在为师生提供优质、高效信息化服务的同时,系统自身也积累了大量的历史记录,其中蕴含着学生的消费行为以及学校食堂等各部门的运行状况等信息。
很多高校基于校园一卡通系统进行“智慧校园”的相关建设,例如《扬子晚报》2016年 1月 27日的报道:《南理工给贫困生“暖心饭卡补助”》。
不用申请,不用审核,饭卡上竟然能悄悄多出几百元……记者昨天从南京理工大学独家了解到,南理工教育基金会正式启动了“暖心饭卡”
项目,针对特困生的温饱问题进行“精准援助”。
项目专门针对贫困本科生的“温饱问题”进行援助。在学校一卡通中心,教育基金会的工作人员找来了全校一万六千余名在校本科生 9 月中旬到 11月中旬的刷卡记录,对所有的记录进行了大数据分析。最终圈定了 500余名“准援助对象”。
南理工教育基金会将拿出“种子基金”100万元作为启动资金,根据每位贫困学生的不同情况确定具体的补助金额,然后将这些钱“悄无声息”的打入学生的饭卡中,保证困难学生能够吃饱饭。
——《扬子晚报》2016年 1月 27日:南理工给贫困生“暖心饭卡补助”本赛题提供国内某高校校园一卡通系统一个月的运行数据,希望参赛者使用
数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为,为改进学校服务并为相关部门的决策提供信息支持。
2 分析目标
-
1. 分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
-
2. 构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
3 数据说明
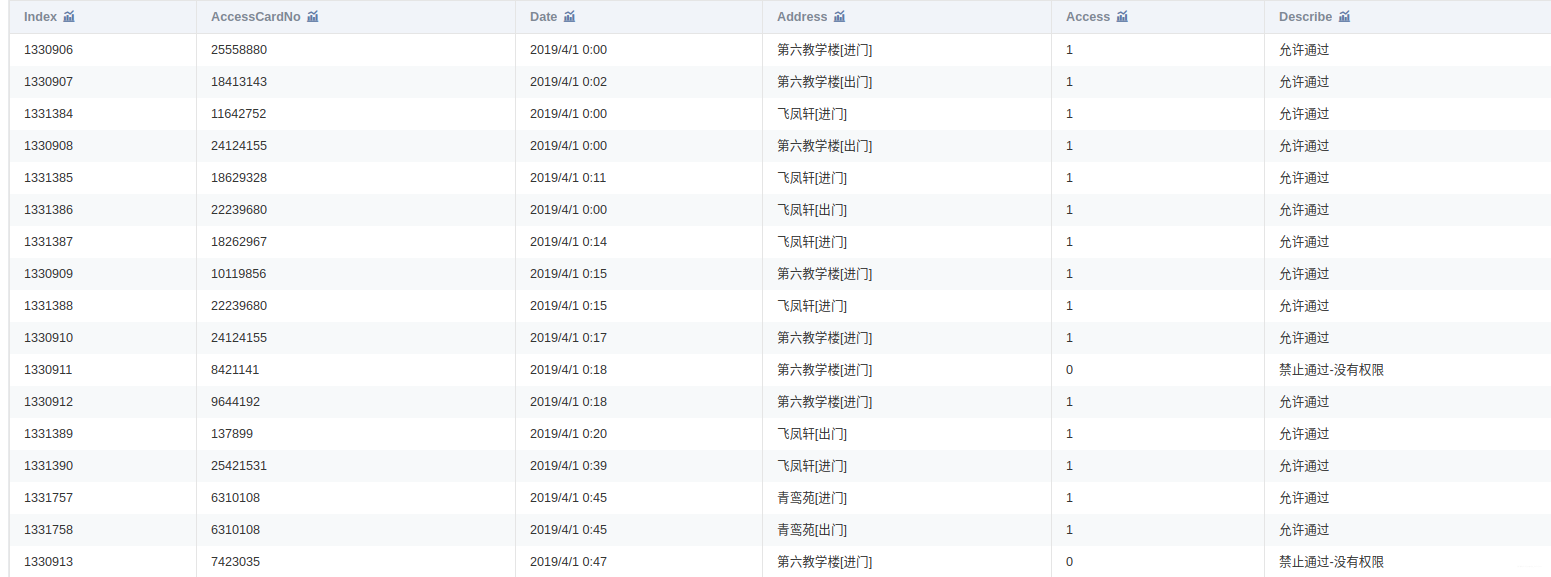
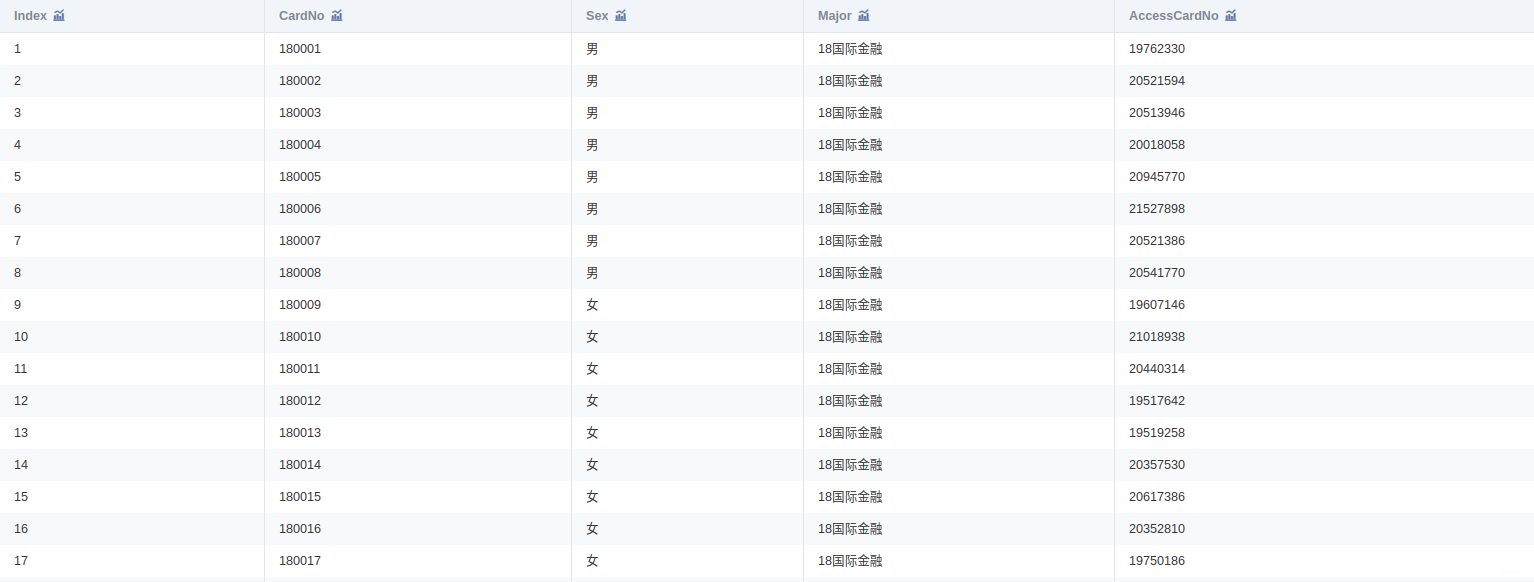
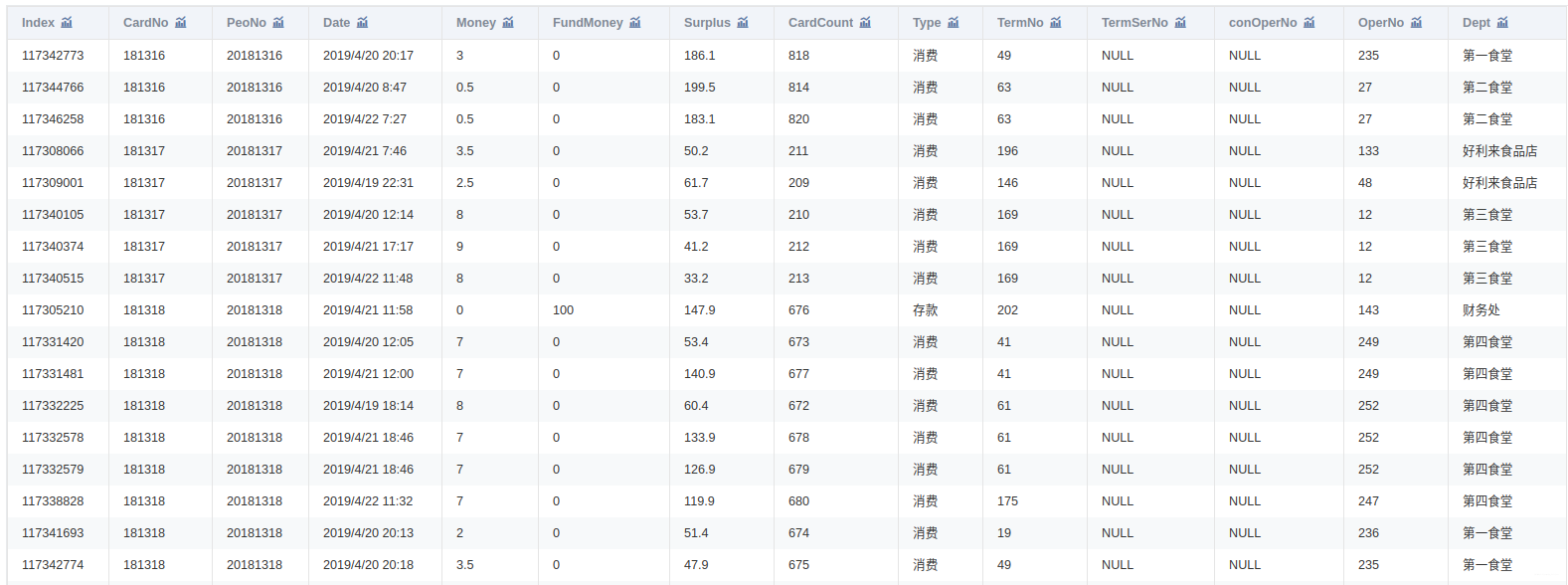
附件是某学校 2019年 4月 1 日至 4月 30日的一卡通数据
一共3个文件:data1.csv、data2.csv、data3.csv
4 数据预处理
将附件中的 data1.csv、data2.csv、data3.csv三份文件加载到分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X可从 1 开始往后编号),并在报告中描述处理过程。
import numpy as np
import pandas as pd
import os
os.chdir('/home/kesci/input/2019B1631')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
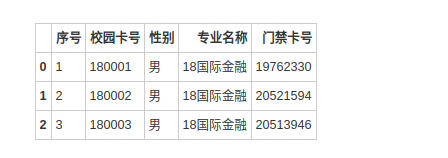
data1.head(3)
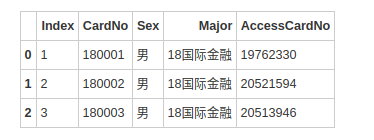
data1.columns = ['序号', '校园卡号', '性别', '专业名称', '门禁卡号']
data1.dtypes

data1.to_csv('/home/kesci/work/output/2019B/task1_1_1.csv', index=False, encoding='gbk')
data2.head(3)

将 data1.csv中的学生个人信息与 data2.csv中的消费记录建立关联,处理结果保存为“task1_2_1.csv”;将 data1.csv 中的学生个人信息与data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5 数据分析
5.1 食堂就餐行为分析
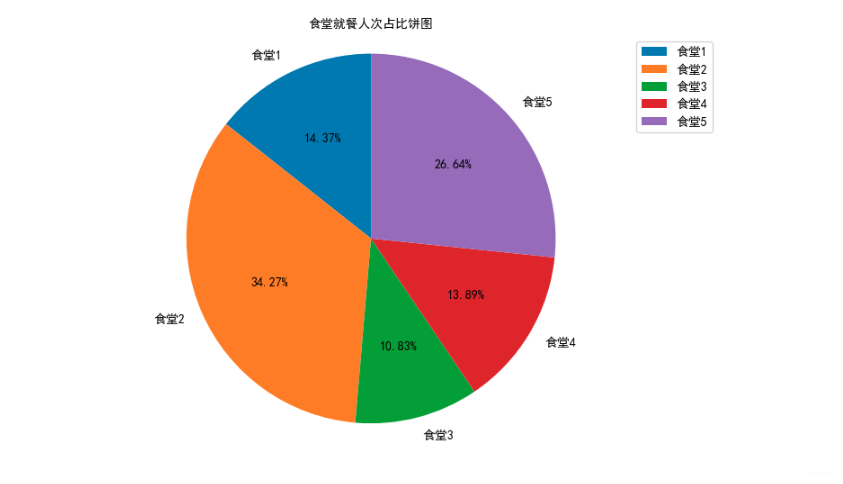
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡记录可能为一次就餐行为)
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format='retina'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings('ignore')
canteen1 = data['消费地点'].apply(str).str.contains('第一食堂').sum()
canteen2 = data['消费地点'].apply(str).str.contains('第二食堂').sum()
canteen3 = data['消费地点'].apply(str).str.contains('第三食堂').sum()
canteen4 = data['消费地点'].apply(str).str.contains('第四食堂').sum()
canteen5 = data['消费地点'].apply(str).str.contains('第五食堂').sum()
# 绘制饼图
canteen_name = ['食堂1', '食堂2', '食堂3', '食堂4', '食堂5']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("食堂就餐人次占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
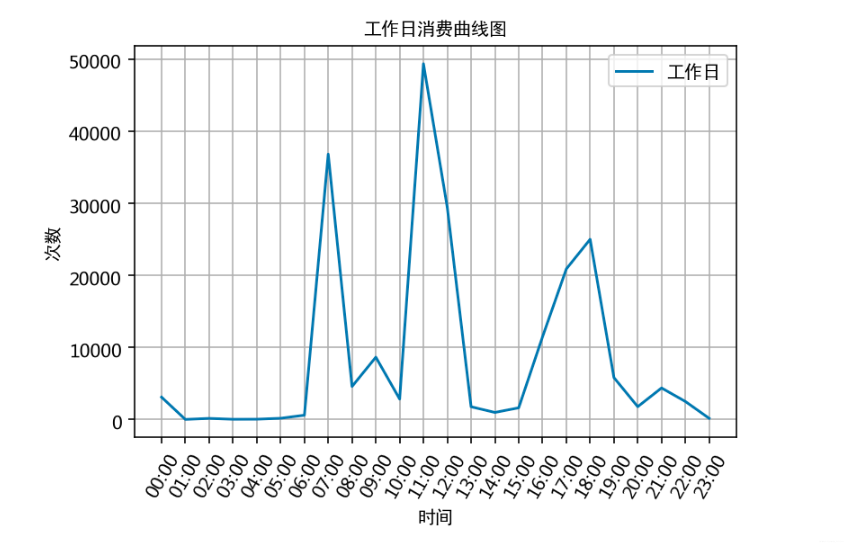
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。

# 对data中消费时间数据进行时间格式转换,转换后可作运算,coerce将无效解析设置为NaT
data.loc[:,'消费时间'] = pd.to_datetime(data.loc[:,'消费时间'],format='%Y-%m-%d %H:%M',errors='coerce')
data.dtypes
# 创建一个消费星期列,根据消费时间计算出消费时间是星期几,Monday=1, Sunday=7
data['消费星期'] = data['消费时间'].dt.dayofweek + 1
data.head(3)
# 以周一至周五作为工作日,周六日作为非工作日,拆分为两组数据
work_day_query = data.loc[:,'消费星期'] <= 5
unwork_day_query = data.loc[:,'消费星期'] > 5work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 计算工作日消费时间对应的各时间的消费次数
work_day_times = []
for i in range(24):work_day_times.append(work_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):x.append('{:02d}:00'.format(i))
# 绘图
plt.plot(x, work_day_times, label='工作日')
# x,y轴标签
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
# 标题
plt.title('工作日消费曲线图', fontproperties=font)
# x轴倾斜60度
plt.xticks(rotation=60)
# 显示label
plt.legend(prop=font)
# 加网格
plt.grid()
# 计算飞工作日消费时间对应的各时间的消费次数
unwork_day_times = []
for i in range(24):unwork_day_times.append(unwork_day_data['消费时间'].apply(str).str.contains(' {:02d}:'.format(i)).sum())# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24): x.append('{:02d}:00'.format(i))
plt.plot(x, unwork_day_times, label='非工作日')
plt.xlabel('时间', fontproperties=font);
plt.ylabel('次数', fontproperties=font)
plt.title('非工作日消费曲线图', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
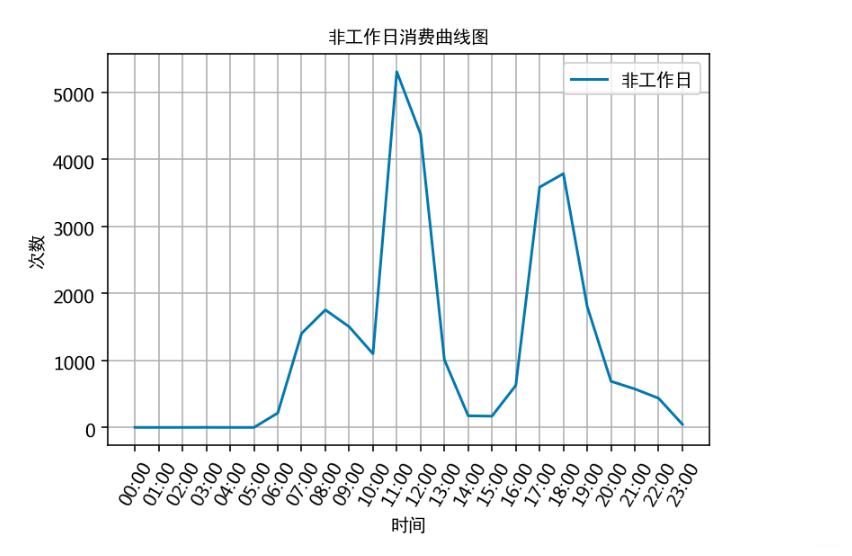
根据上述分析的结果,很容易为食堂的运营提供建议,比如错开高峰等等。
5.2 学生消费行为分析
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消费额,并选择 3个专业,分析不同专业间不同性别学生群体的消费特点。
data = pd.read_csv('/home/kesci/work/output/2019B/task1_2_1.csv', encoding='gbk')
data.head()

# 计算人均刷卡频次(总刷卡次数/学生总人数)
cost_count = data['消费时间'].count()
student_count = data['校园卡号'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count# 计算人均消费额(总消费金额/学生总人数)
cost_sum = data['消费金额'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money# 选择消费次数最多的3个专业进行分析
data['专业名称'].value_counts(dropna=False)
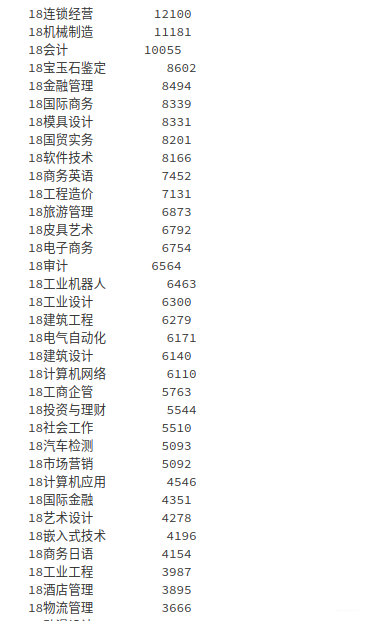
# 消费次数最多的3个专业为 连锁经营、机械制造、会计
major1 = data['专业名称'].apply(str).str.contains('18连锁经营')
major2 = data['专业名称'].apply(str).str.contains('18机械制造')
major3 = data['专业名称'].apply(str).str.contains('18会计')
major4 = data['专业名称'].apply(str).str.contains('18机械制造(学徒)')data_new = data[(major1 | major2 | major3) ^ major4]
data_new['专业名称'].value_counts(dropna=False)分析 每个专业,不同性别 的学生消费特点
data_male = data_new[data_new['性别'] == '男']
data_female = data_new[data_new['性别'] == '女']
data_female.head()
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,分析每一类学生群体的消费特点。
data['专业名称'].value_counts(dropna=False).count()
# 选择特征:性别、总消费金额、总消费次数
data_1 = data[['校园卡号','性别']].drop_duplicates().reset_index(drop=True)
data_1['性别'] = data_1['性别'].astype(str).replace(({'男': 1, '女': 0}))
data_1.set_index(['校园卡号'], inplace=True)
data_2 = data.groupby('校园卡号').sum()[['消费金额']]
data_2.columns = ['总消费金额']
data_3 = data.groupby('校园卡号').count()[['消费时间']]
data_3.columns = ['总消费次数']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()# 构建聚类模型
from sklearn.cluster import KMeans
# k为聚类类别,iteration为聚类最大循环次数,data_zs为标准化后的数据
k = 3 # 分成几类可以在此处调整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs为并发数
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1统计各个类别的数目,r2找出聚类中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
r.columns = list(data_123.columns) + ['类别数目']# 选出消费总额最低的500名学生的消费信息
data_500 = data.groupby('校园卡号').sum()[['消费金额']]
data_500.sort_values(by=['消费金额'],ascending=True,inplace=True,na_position='first')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data['校园卡号'].isin(data_500_index)]
data_500.head(10)
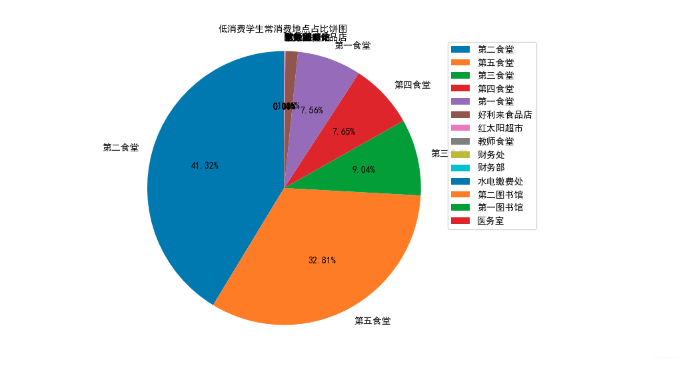
# 绘制饼图
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct='%1.2f%%', shadow=False, startangle=90, textprops={'fontproperties':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("低消费学生常消费地点占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis('equal')
# 显示图像
plt.show()
建模资料
资料分享: 最强建模资料


相关文章:
2023国赛数学建模思路 - 复盘:校园消费行为分析
文章目录 0 赛题思路1 赛题背景2 分析目标3 数据说明4 数据预处理5 数据分析5.1 食堂就餐行为分析5.2 学生消费行为分析 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 1 赛题背景 校园一卡通是集…...

第7章:贝叶斯分类器
贝叶斯决策论 贝叶斯分类器:使用贝叶斯公式 贝叶斯学习:使用分布估计(不同于频率主义的点估计) 极大似然估计 朴素贝叶斯分类 半朴素贝叶斯 条件独立性假设,在现实生活中往往很难成立。 半朴素贝叶 斯的一个常用策略…...

【LeetCode】88.合并两个有序数组
题目 给你两个按 非递减顺序 排列的整数数组 nums1 和 nums2,另有两个整数 m 和 n ,分别表示 nums1 和 nums2 中的元素数目。 请你 合并 nums2 到 nums1 中,使合并后的数组同样按 非递减顺序 排列。 注意:最终,合并…...

05 - 研究 .git 目录
查看所有文章链接:(更新中)GIT常用场景- 目录 文章目录 1. HEAD2. config3. refs4. objects 1. HEAD 2. config 3. refs 4. objects Git对象一共有三种:数据对象 blob、树对象 tree以及提交对象 commit,这些对象都被保…...

MySQL之索引和事务
索引什么是索引索引怎么用索引的原理 事务使用事务事务特性MySQL隔离级别 索引 什么是索引 索引包含数据表所有记录的引用指针;你可以对某一列或者多列创建索引和指定不同的类型(唯一索引、主键索引、普通索引等不同类型;他们底层实现也是不…...

⛳ 将本地已有的项目上传到 git 仓库
目录 ⛳ 将本地已有的项目上传到 git 仓库🏭 一、克隆 拷贝🎨 二、强行合并两个仓库 ⛳ 将本地已有的项目上传到 git 仓库 有两种方法: 一、克隆 拷贝 二、强行合并两个仓库 🏭 一、克隆 拷贝 直接用把远程仓库拉到本…...
)
ADB常用命令整理(全网最全)
调试Android程序时,我们经常需要使用adb shell命令。adb是Android Debug Bridge的缩写,它充当调试桥梁的作用,就像一条连接开发机和设备之间的桥梁。 通过adb,我们可以在Eclipse中使用DDMS来调试Android程序,简单来说…...
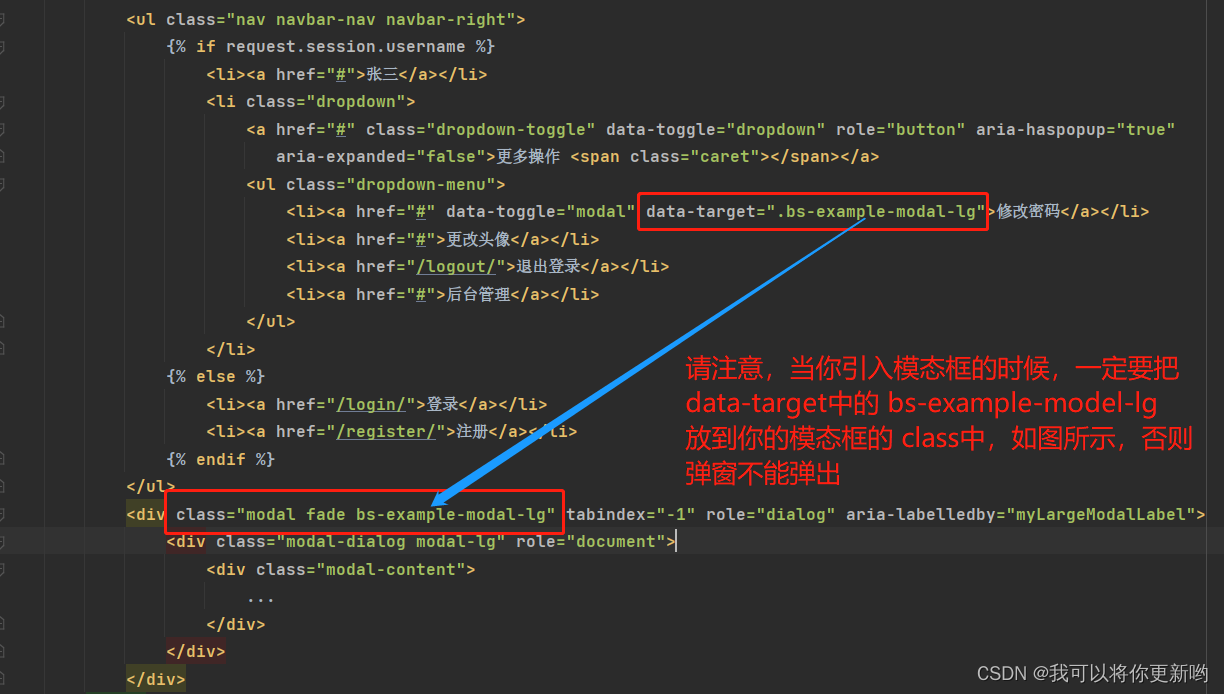
BBS项目day02、注册、登录(登录之随机验证码)、退出登录、密码加密加盐、首页(导航条、模态框,修改密码)
一、注册 1.注册之前端页面 <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>注册页面</title><!--动态引入文件-->{% load static %}<script src"{% static js/jquery.min.js %…...
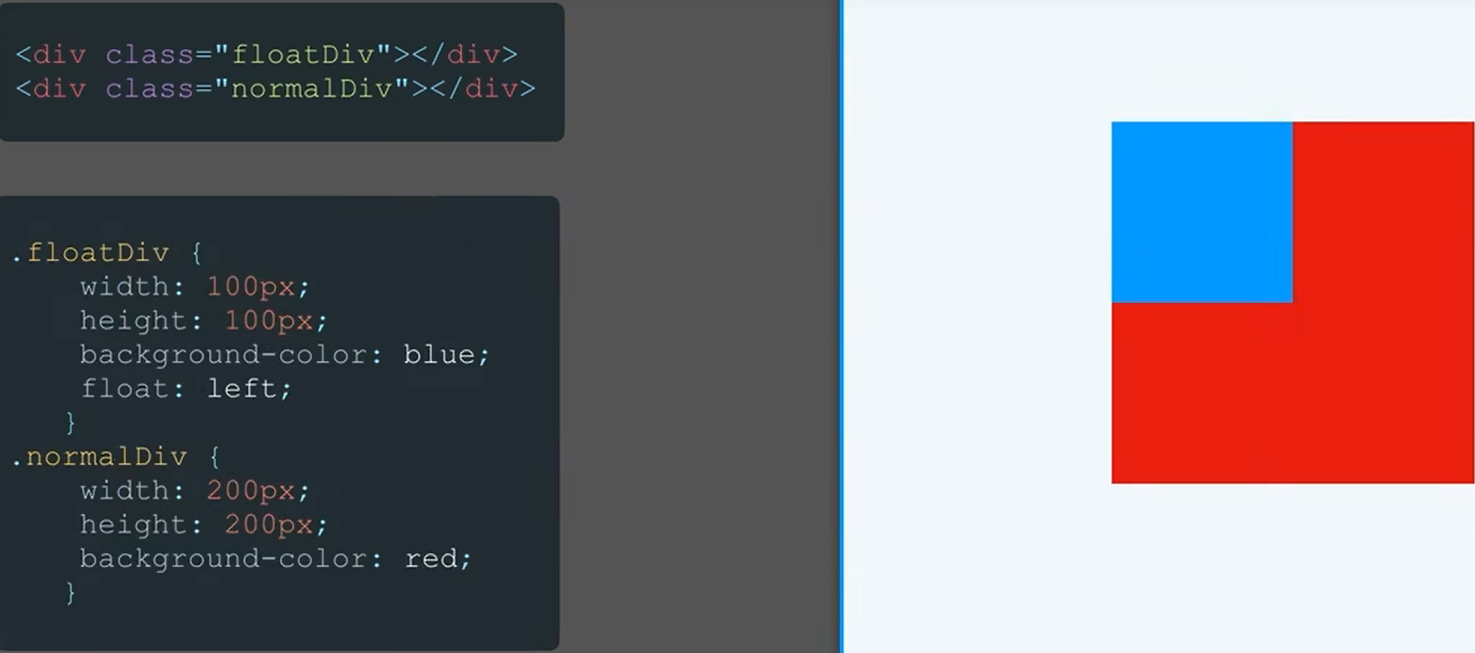
HTML5+CSS3自用笔记
助解:解析编译,加载运行 浏览器的渲染过程 JS加载执行 普通js/sync:阻塞 DOM加载解析 async:下载完就执行,无依赖 <script type"text/javascript" src"x.min.js" async"async"&g…...
)
无则插入有则更新(PostgreSQL,MySQL,Oracle、SqlServer)
无则插入有则更新 PostgreSQL 无则插入有则更新 conflict(带有唯一性约束的字段),根据此字段判断是更新还是插入 INSERT INTO student(id,name,sex) VALUES(1, 小明, 男) ON conflict (id) DO UPDATE SET id 1,name 小明,sex 男;无则插入有则不做操作 INSERT I…...

常见的 JavaScript 框架比较
以下是10种常见的JavaScript框架的比较: React:是由Facebook开发和维护的开源JavaScript库,用于构建用户界面。它允许你使用组件来构建复杂的UI,并专注于每个组件的内部逻辑,而不必担心管理整个应用程序的状态。WebBu…...

基于R语言APSIM模型进阶应用与参数优化、批量模拟
随着数字农业和智慧农业的发展,基于过程的农业生产系统模型在模拟作物对气候变化的响应与适应、农田管理优化、作物品种和株型筛选、农田固碳和温室气体排放等领域扮演着越来越重要的作用。APSIM (Agricultural Production Systems sIMulator)模型是世界知名的作物生…...

AMD卡启动Stable Diffusion AI绘画的方法
WindowsAMD安装法 1.安装python 3.10.6,在python官网上下载安装程序,***重要*** 在安装的第一个窗口下方勾选“将python添加到path”。 2.安装git 3.WindowsAMD使用AUTOMATIC1111的directml这一个fork,在这个页面的第一段:https:/…...
)
Ubuntu系统kubeadm安装K8S_v1.25.x容器使用docker(K8S_v1.24版本以后依然使用docker容器管理)
安装所需要的全部文档请点击这里下载 系统是: root@k8s-master:~# cat /etc/lsb-release DISTRIB_ID=Ubuntu DISTRIB_RELEASE=22.04 DISTRIB_CODENAME=jammy DISTRIB_DESCRIPTION=“Ubuntu 22.04.3 LTS” root@k8s-master:~# uname -a Linux k8s-master 5.15.0-76-generic #8…...
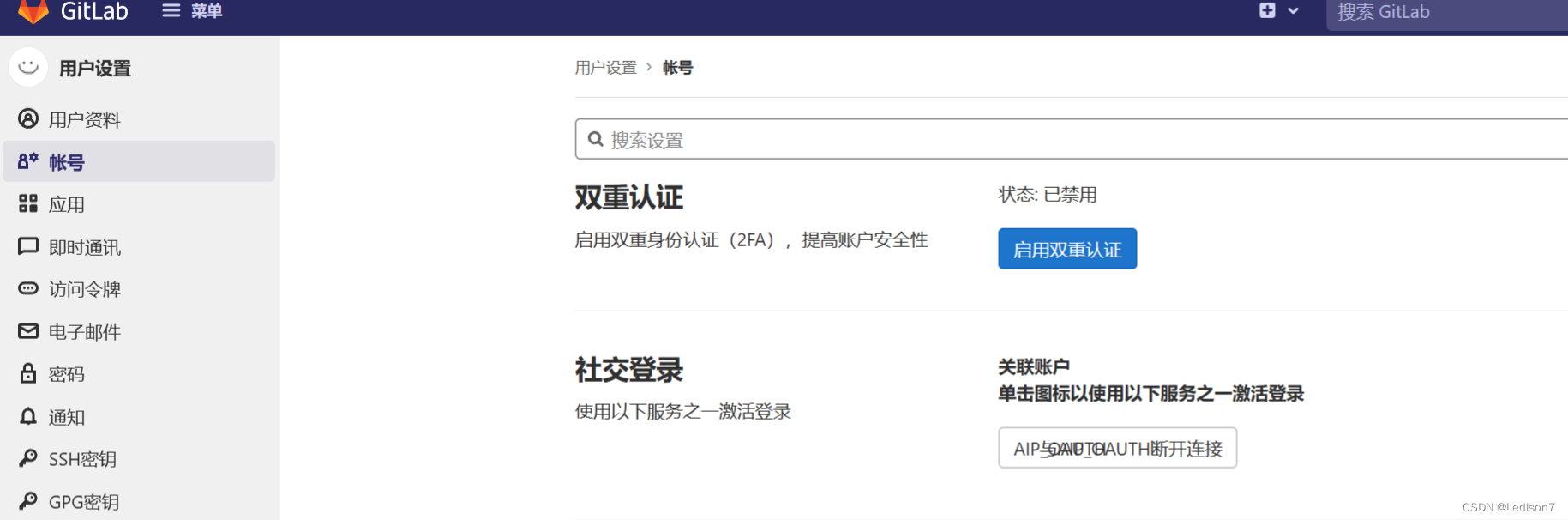
【MaxKey对接一】对接gitlab的oauth登录
MaxKey的Oauth过程 引导进入 GET http://{{maxKey_host}}/sign/authz/oauth/v20/authorize?client_idYOUR_CLIENT_ID&response_typecode&redirect_uriYOUR_REGISTERED_REDIRECT_URI 登录后回调地址 YOUR_REGISTERED_REDIRECT_URI/?code{{code}} 换取Access Token GET…...

【Buildroot】构建根文件系统等
文章目录 0. 前言10. 环境软件硬件 20. Buildroot 环境搭建简述下载环境搭建toolchain下载、安装构建镜像(仅供参考) 80. 问题点1. 编译、清除时提示权限不足 0. 前言 对嵌入式linux开发和linux开发环境不熟悉的同志们就不要往下看了 对嵌入式linux开发和…...
利用css动画和定时器setTimeout,实现上传图片进度条
思路 利用css动画和js定时器(setTimeout),实现简单的进度条。 优势 不使用 setInterval,减少js代码量,业务代码更加简洁。 示意图 上传中上传成功上传失败 代码 html <!-- img-wrap有两种状态:u…...
关于VScode插件,你不得不知道的几件事
一、前言 VSCode是微软家一个非常轻量化的编辑器,体量虽轻,但是却有异常强大的功能。原因在于VSCode许多强大功能都是基于插件实现的,IDE只提供一个最基本的框架和基本功能,我们需要使用插件来丰富和扩展它的功能。 由于插件的重…...

MySQL 奇遇记三则
公司新项目,要使用 MySQL 数据库。 第一次使用 MySQL,有点小激动。听说过 N 多次,这一次终于用上了。 为什么是奇遇记? 因为在网上几乎搜索不到别人遇到和我一样的问题。 系统 :WINDOWS10X64 中文版 数据库…...

UI设计师的主要职责说明(合集)
UI设计师的主要职责说明1 职责: 1、负责公司移动端、PC端产品相关的交互、UI等设计 2、负责公司宣传册、海报、运营物料、banner等设计 3、负责公司品牌相关的视觉设计 3、制定相关设计规范,提高产品的可用性、不断优化产品体验; 4、与PM、运营紧密…...

离散化离散化差分
数组开不了1e9,但是好在坐标点会很分散,那么相当于将点“挤到”1-n的位置,一个位置映射了一个坐标点,排序后,坐标的相对位置并不发生改变,离散化由此得来。#include<bits/stdc.h> #define int long l…...

Python 爬虫进阶技巧:JSON 数据多层嵌套解析取值技巧
前言 在现代网络数据采集场景中,JSON(JavaScript Object Notation)已成为前后端数据交互的核心格式,绝大多数动态网页、API 接口均采用多层嵌套 JSON 结构传输数据。对于爬虫开发者而言,基础的 JSON 取值仅能应对简单数据结构,而面对深度嵌套、数组嵌套、混合嵌套等复杂…...

终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具
终极解决方案:3分钟搞定百度网盘提取码的免费自动化工具 【免费下载链接】baidupankey 项目地址: https://gitcode.com/gh_mirrors/ba/baidupankey 还在为百度网盘资源下载卡在提取码这一步而烦恼吗?每次遇到需要密码的分享链接,都要…...

在线图片处理工具源码, 多功能编辑格式转换HTML单文件版
概述 在数字化内容创作与网站运营的日常中,高效、便捷的图片处理能力是提升工作效率的关键。无论是为了优化网页加载速度而进行的图片压缩,还是为了满足特定设计需求的格式转换与尺寸调整,都离不开得力的工具支持。为此,幽络源源…...

国际B2B企业平台表达框架:IBM式重构与ServiceNow式统一执行
如果把国际B2B品牌表达看成一个系统问题,IBM / ServiceNow这组样本可以拆成一套判断框架。它不是讨论文案怎么写,而是讨论输入什么业务条件,输出什么品牌角色、结构和证据链。框架结论:IBM与ServiceNow都服务企业转型,…...

发音人「像真人」之外还要看什么:稳定性与一致性
🎯 发音人「像真人」之外还要看什么:稳定性与一致性在文字转语音领域,「像真人」往往是第一印象。然而,当您需要批量生成有声内容、长期使用同一音色时,真正决定体验的是稳定性与一致性。 顶伯文字转语音工具正是围绕这…...

如何用MIKE IO快速上手水文数据分析:Python数据处理终极指南
如何用MIKE IO快速上手水文数据分析:Python数据处理终极指南 【免费下载链接】mikeio Read, write and manipulate dfs0, dfs1, dfs2, dfs3, dfsu and mesh files. 项目地址: https://gitcode.com/gh_mirrors/mi/mikeio MIKE IO是一个功能强大的Python开源库…...

AI短视频生成引擎:从文章到视频的自动化流水线实战
1. 项目概述:一个能“读懂”文章的AI视频工厂最近在折腾短视频内容创作的朋友,估计都经历过一个共同的痛点:找选题、写脚本、找素材、配音、剪辑……一套流程下来,几个小时就没了,效率低得让人抓狂。尤其是想把一篇深度…...

【Prometheus】如何分析和解读 Prometheus 的日志信息以定位问题?
Prometheus 日志深度解读指南:从启动异常到 TSDB 损坏的全链路故障定位 用户问题原文:“如何分析和解读 Prometheus 的日志信息以定位问题?” 在支撑单集群500万+时间序列的生产环境中,Prometheus 的日志是 SRE 团队洞察系统内部状态的“黑匣子”。一次未被正确解读的日志警…...

Windows 平台 OpenClaw 2.7.1 可视化安装避坑技巧与高效配置方法
OpenClaw 2.7.1 Windows 一键部署教程|3 分钟快速搭建本地 AI 智能助手OpenClaw(小龙虾)是一款实用性极强的本地 AI 智能体工具,适配全系 Windows 系统。软件依托自然语言交互逻辑,可智能完成电脑操控、文件分类管理、…...