OpenAI Function calling
开篇
原文出处
最近 OpenAI 在 6 月 13 号发布了新 feature,主要针对模型进行了优化,提供了 function calling 的功能,该 feature 对于很多集成 OpenAI 的应用来说绝对是一个“神器”。
Prompt 的演进
如果初看 OpenAI 官网对function calling的介绍,似乎不足以体现它的重要性。为了更进一步理解它的作用,我们先来简单回顾一下在使用 OPenAI 时 Prompt 是如何演进的。
Prompt 1.0

还记得 chatGPT 在最一开始大火时,除了 AI 强大的能力作为一个吸引点之外,“低门槛的要求使得所有人都可以使用”也扮演着至关重要的角色。也正是如此,大家不再对 AI 感到陌生,借助和 AI 对话,随便一个 Prompt 就可以让使用者直接或间接的获得帮助。
但是随着使用深度的增加,大家慢慢发现chatGPT有时会思维发散,往往不能聚焦关键问题,甚至会“无言乱语”。
在此之上,1.0 版本的 Prompt 出现,它要求对话开始前需要设定上下文。在这样的提示下,AI 能够有较好的表现,并且不再发散,可以解决较为简单的问题。
Prompt 2.0

随着使用场景的复杂化,单纯的设置一个上下文给chatGPT已经远远不够。你必须给“足”上下文,最简单的方式就是提供exmaple,这种做法的背后逻辑和 COT(Chain of Thought)是一样的。
2.0 版本的 Prompt 是使用最广泛的也是最可靠的。
Prompt 3.0

3.0 版本的 Prompt 并非比 2.0 要高级,只是在需求上不一样。因为随着大量 AI 工具和 OpenAI 集成,想要充分利用 AI 的能力,让更多的系统和模块和你结合,就必须得提取参数或者返回特定的输出。
因此,3.0 聚焦更多的是集成。
Function calling
Prompt 在迭代到 3.0 版本后,AI 的缺点已经一览无遗。虽然chatGPT有大量的知识储备,但它的数据都是预训练的,由于不能联网,所以它并不是“无所不知”的。
因此,集成第三方系统对模型的赋能就成为了当下众多 AI 应用的首要方案。可赋能就代表得知道用户到底要知道什么,这就是 3.0 版本的努力方向。但是 3.0 的版本其实并不能非常稳定的输出特定格式,或者即便格式可以固定,json 数据的类型也不能很好的控制。比如上面的 3.0 例子里,不是所有的 AI 模型都能稳定输出price: 1500,也有可能是$1500(Bard)。
也许你会觉得1500和$1500的差异并不大,大不了可以处理一下前缀之类的问题,那就大错特错了。因为这是作为 不同模块(或系统)链接的桥梁,就如同 API 之间集成的契约一般,必须有严格的定义。
一个典型的例子就是前段时间大火的Auto-GPT, 在 3.5 turbo 的模型下,它很难完成一个任务,往往会陷入无限的循环,主要的原因就是它需要非常严格的上下文衔接来集成各种 command,但凡有一丁儿点的差异都会导致“连接”失败。
在此背景下,function calling出现了。
它允许用户定义一个或多个 function 描述,该描述满足 API doc 的规范,定义了参数的类型和含义。AI 在经过 function calling 的调教后,可以准确的理解这种规范并按照上下文去决定是否可以“命中”该方法,如果“命中”,则会返回该方法的参数。
到此它已经解决了参数提取的问题,但并没有结束。此时开发者可以利用这个参数去集成第三方系统,获取特定的信息然后把结果反馈给模型,这样模型就有了这个方法的输入和输出,看起来像是模型“执行”了该方法,而实际是模型被动的获取了它没有的知识。
最后,AI 根据新获得的知识和信息,给用户输出最后的结果。
Example: DB 搜索
假设我们想利用 AI 在 DB 层建立搜索接口,我们可以按照以下步骤:
-
- 将 DB 的 meta 数据作为上下文,定义 ask_database 的方法规范
{"functions": [{"name": "ask_database","description": "Use this function to answer user questions about music. Output should be a fully formed SQL query.","parameters": {"type": "object","properties": {"query": {"type": "string","description": "SQL query extracting info to answer the user\\'s question.SQL should be written using this database schema:\"Table name: album_tb; Columns: album(string), published_at(string), likes(string)\".The query should be returned in plain text, not in JSON."}},"required": ["query"]}}]
}
-
- 设定 system 上下文,提示模型如果 user 的 prompt 无法命中 function 的话就不要强行“脑补”
这很有用,说明不是所有的 Prompt 都需要被 function 来解析,有点类似 if else,这样可以回归到正常的对话中。
{"role": "system","content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."
}
-
- 提问
{"role": "user","content": "What are the top 2 the albums"
}
-
- 模型命中 function 并且返回解析的参数
{"role": "assistant","content": null,"function_call": {"name": "ask_database","arguments": "{\n \"query\": \"SELECT * FROM album_tb ORDER BY likes DESC LIMIT 5\"\n}"}
}
-
- 查询 DB,将数据返回给我模型(赋能)
{"role": "function","name": "ask_database","content": "[{\"album\":\"Tanya\",\"published_at\":\"2000-01-01\",\"likes\":\"10000\"},{\"artist\":\"Im OK\",\"published_at\":\"1999-01-01\",\"likes\":\"20000\"}]"
}
-
- 模型根据新的知识储备响应用户的 Prompt
{"role": "assistant","content": "The top 2 albums are \"Im OK\" with 20,000 likes and \"Tanya\" with 10,000 likes."
}
-
- 再次提问,测试新的知识储备是否被模型深刻理解
{"role": "user","content": "What are the most popular one"
}
-
- 模型可以准确的在新的知识储备进行搜索
{"role": "assistant","content": "The most popular album is \"Im OK\" with 20000 likes."
}
完整的 API 请求如下:
{"model": "gpt-3.5-turbo-0613","messages": [{"role": "system","content": "Don't make assumptions about what values to plug into functions. Ask for clarification if a user request is ambiguous."},{"role": "user","content": "What are the top 2 the albums"},{"role": "assistant","content": null,"function_call": {"name": "ask_database","arguments": "{\n \"query\": \"SELECT * FROM album_tb ORDER BY likes DESC LIMIT 5\"\n}"}},{"role": "function","name": "ask_database","content": "[{\"album\":\"Tanya\",\"published_at\":\"2000-01-01\",\"likes\":\"10000\"},{\"artist\":\"Im OK\",\"published_at\":\"19999-01-01\",\"likes\":\"20000\"}]"},{"role": "user","content": "What are the most popular one"}],"functions": [{"name": "ask_database","description": "Use this function to answer user questions about music. Output should be a fully formed SQL query.","parameters": {"type": "object","properties": {"query": {"type": "string","description": "SQL query extracting info to answer the user\\'s question.SQL should be written using this database schema:\"Table name: album_tb; Columns: album(string), published_at(string), likes(string)\".The query should be returned in plain text, not in JSON."}},"required": ["query"]}}]
}
模型
OpenAI 在 6 月 13 号的 release 中,专门针对 function calling 发布了新的模型,无论是价格还是上下文的长度都有比较大的变化,以下为 3.5(免费)的模型列表:

最后
function calling 对与模型精准的理解 Prompt 和集成外部知识储备系统绝对是一个强大的工具,未来 Prompt 的趋势肯定也会朝着个方向去设计,拭目以待吧。
相关文章:
OpenAI Function calling
开篇 原文出处 最近 OpenAI 在 6 月 13 号发布了新 feature,主要针对模型进行了优化,提供了 function calling 的功能,该 feature 对于很多集成 OpenAI 的应用来说绝对是一个“神器”。 Prompt 的演进 如果初看 OpenAI 官网对function ca…...

【C语言】字符分类函数、字符转换函数、内存函数
前言 之前我们用两篇文章介绍了strlen、strcpy、stract、strcmp、strncpy、strncat、strncmp、strstr、strtok、streeror这些函数 第一篇文章strlen、strcpy、stract 第二篇文章strcmp、strncpy、strncat、strncmp 第三篇文章strstr、strtok、streeror 今天我们就来学习字…...
Deep Learning With Pytorch - 最基本的感知机、贯序模型/分类、拟合
文章目录 如何利用pytorch创建一个简单的网络模型?Step1. 感知机,多层感知机(MLP)的基本结构Step2. 超平面 ω T ⋅ x b 0 \omega^{T}xb0 ωT⋅xb0 or ω T ⋅ x b \omega^{T}xb ωT⋅xb感知机函数 Step3. 利用感知机进行决策…...
测试工具coverage的高阶使用
在文章Python之单元测试使用的一点心得中,笔者介绍了自己在使用Python测试工具coverge的一点心得,包括: 使用coverage模块计算代码测试覆盖率使用coverage api计算代码测试覆盖率coverage配置文件的使用coverage badge的生成 本文在此基础上…...

安卓监听端口接收消息
文章目录 其他文章监听端口接收消息 建立新线程完整代码 其他文章 下面是我的另一篇文章,是在电脑上发送数据,配合本篇文章,可以实现电脑与手机的局域网通讯。直接复制粘贴就能行,非常滴好用。 点击连接 另外,如果你不…...

「Node」下载安装配置node.js
以下是Node.js的下载、安装和配置的全面教程: 下载 Node.js 打开 Node.js 官方网站:Previous Releases在主页上,您会看到两个版本可供选择:LTS(长期支持版本)和最新版(Current)。如…...
NOIP2014普及组,提高组 比例简化 飞扬的小鸟 答案
比例简化 说明 在社交媒体上,经常会看到针对某一个观点同意与否的民意调查以及结果。例如,对某一观点表示支持的有1498 人,反对的有 902人,那么赞同与反对的比例可以简单的记为1498:902。 不过,如果把调查结果就以这种…...

【Java】使用Apache POI识别PPT中的图片和文字,以及对应的大小、坐标、颜色、字体等
本文介绍如何使用Apache POI识别PPT中的图片和文字,获取图片的数据、大小、尺寸、坐标,以及获取文字的字体、大小、颜色、坐标。 官方文档:https://poi.apache.org/components/slideshow/xslf-cookbook.html 官方文档和网上的资料介绍的很少…...

根据源码,模拟实现 RabbitMQ - 实现消息持久化,统一硬盘操作(3)
目录 一、实现消息持久化 1.1、消息的存储设定 1.1.1、存储方式 1.1.2、存储格式约定 1.1.3、queue_data.txt 文件内容 1.1.4、queue_stat.txt 文件内容 1.2、实现 MessageFileManager 类 1.2.1、设计目录结构和文件格式 1.2.2、实现消息的写入 1.2.3、实现消息的删除…...
)
找到所有数组中消失的数(C语言详解)
题目:找到所有数组中消失的数 题目详情: 给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1,n] 内。请你找出所以在 [1,n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。 示例1: 输入…...
计算机毕设项目之基于django+mysql的疫情实时监控大屏系统(前后全分离)
系统阐述的是一款新冠肺炎疫情实时监控系统的设计与实现,对于Python、B/S结构、MySql进行了较为深入的学习与应用。主要针对系统的设计,描述,实现和分析与测试方面来表明开发的过程。开发中使用了 django框架和MySql数据库技术搭建系统的整体…...

Unity UI内存泄漏优化
项目一运行,占用的内存越来越多,不会释放,导致GC越来越频繁,越来越慢,这些都是为什么呢,今天从UI方面谈起。 首先让我们来聊聊什么是内存泄漏呢? 一般来讲内存泄漏就是指我们的应用向内存申请…...

学习笔记:Opencv实现图像特征提取算法SIFT
2023.8.19 为了在暑假内实现深度学习的进阶学习,特意学习一下传统算法,分享学习心得,记录学习日常 SIFT的百科: SIFT Scale Invariant Feature Transform, 尺度不变特征转换 全网最详细SIFT算法原理实现_ssift算法_Tc.小浩的博客…...
使用和原理)
【golang】接口类型(interface)使用和原理
接口类型的类型字面量与结构体类型的看起来有些相似,它们都用花括号包裹一些核心信息。只不过,结构体类型包裹的是它的字段声明,而接口类型包裹的是它的方法定义。 接口类型声明中的这些方法所代表的就是该接口的方法集合。一个接口的方法集…...

【Linux操作系统】Linux系统编程中的共享存储映射(mmap)
在Linux系统编程中,进程之间的通信是一项重要的任务。共享存储映射(mmap)是一种高效的进程通信方式,它允许多个进程共享同一个内存区域,从而实现数据的共享和通信。本文将介绍共享存储映射的概念、原理、使用方法和注意…...
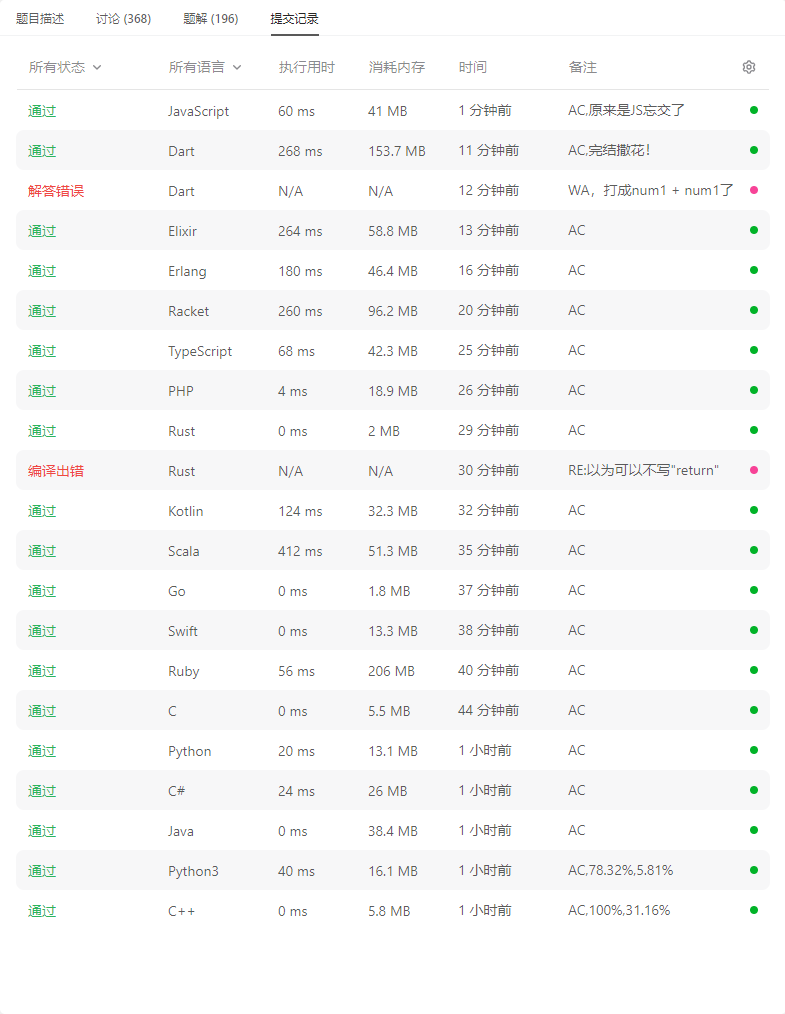
2235.两整数相加:19种语言解法(力扣全解法)
【LetMeFly】2235.两整数相加:19种语言解法(力扣全解法) 力扣题目链接:https://leetcode.cn/problems/add-two-integers/ 给你两个整数 num1 和 num2,返回这两个整数的和。 示例 1: 输入:num…...
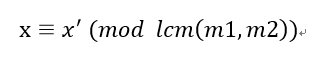
中国剩余定理及扩展
目录 中国剩余定理解释 中国剩余定理扩展——求解模数不互质情况下的线性方程组: 代码实现: 互质: 非互质: 中国剩余定理解释 在《孙子算经》中有这样一个问题:“今有物不知其数,三三数之剩二&#x…...

数据在内存中的存储(deeper)
数据在内存中的存储(deeper) 一.数据类型的详细介绍二.整形在内存中的存储三.浮点型在内存中的存储 一.数据类型的详细介绍 类型的意义: 使用这个类型开辟内存空间的大小(大小决定了使用范围)如何看待内存空间的视角…...

算法修炼Day52|● 300.最长递增子序列 ● 674. 最长连续递增序列 ● 718. 最长重复子数组
LeetCode:300.最长递增子序列 300. 最长递增子序列 - 力扣(LeetCode) 1.思路 dp[i]的状态表示以nums[i]为结尾的最长递增子序列的个数。 dp[i]有很多个,选择其中最大的dp[i]Math.max(dp[j]1,dp[i]) 2.代码实现 1class Solution {2 pub…...

使用 HTML、CSS 和 JavaScript 创建实时 Web 编辑器
使用 HTML、CSS 和 JavaScript 创建实时 Web 编辑器 在本文中,我们将创建一个实时网页编辑器。这是一个 Web 应用程序,允许我们在网页上编写 HTML、CSS 和 JavaScript 代码并实时查看结果。这是学习 Web 开发和测试代码片段的绝佳工具。我们将使用ifram…...

赣州 GEO 科普|AI 时代品牌信息基建,七文 GEO 助力品牌长效可见
赣州GEO科普|AI时代品牌信息基建,读懂生成式引擎优化逻辑人工智能全面普及的当下,生成式AI正在重塑大众的信息获取方式。如今多数用户习惯借助文心一言等AI工具检索品牌、查询行业服务,人工智能会整合全网信息进行智能作答。在此行…...

在ARM架构Windows上,用Hyper-V快速部署Ubuntu Server 22.04 LTS
1. 为什么选择ARM架构WindowsHyper-V跑Ubuntu? 最近两年ARM架构的Windows设备越来越多了,像Surface Pro X这样的设备用起来确实轻便省电。但很多开发者发现,想在ARM电脑上跑个Linux环境测试代码,总会遇到各种兼容性问题。我自己用…...
)
RK3588 Android12在线视频播放拷机重启?手把手教你定位DMABUF内存泄漏(附/proc节点排查法)
RK3588 Android12视频播放内存泄漏实战:从崩溃日志到精准定位DMABUF泄漏进程 当RK3588平台在Android12系统上长时间播放在线视频时突然重启,这种看似随机的系统崩溃往往让开发者头疼不已。本文将带您深入内核层,通过一套可复用的方法论&#…...
)
ESP32-C3驱动2寸ST7789屏幕?手把手教你搞定LVGL移植(附避坑代码)
ESP32-C3与ST7789屏幕的LVGL移植实战指南 在物联网设备开发中,显示交互界面往往是提升用户体验的关键一环。ESP32-C3作为乐鑫推出的高性价比RISC-V芯片,搭配ST7789驱动的2寸LCD屏幕,能够构建出性能稳定、成本可控的嵌入式显示方案。本文将带你…...

终极指南:Diablo Edit2暗黑破坏神2存档修改器完整使用教程
终极指南:Diablo Edit2暗黑破坏神2存档修改器完整使用教程 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 你是否曾为暗黑破坏神2中重复刷装备而烦恼?是否因为技能点分配失…...

暗黑破坏神2角色编辑器终极指南:如何轻松打造完美角色
暗黑破坏神2角色编辑器终极指南:如何轻松打造完美角色 【免费下载链接】diablo_edit Diablo II Character editor. 项目地址: https://gitcode.com/gh_mirrors/di/diablo_edit 还在为暗黑破坏神2中无尽的刷装备、练级而烦恼吗?Diablo Edit2是一款…...

Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度
Glass Browser:透明悬浮浏览器,解锁Windows多任务处理新维度 【免费下载链接】glass-browser A floating, always-on-top, transparent browser for Windows. 项目地址: https://gitcode.com/gh_mirrors/gl/glass-browser 当你在编写代码时需要查…...

基于TypeScript的MCP服务器开发指南:为AI助手构建安全工具调用能力
1. 项目概述:一个为TypeScript开发者打造的MCP服务器最近在折腾AI应用开发,特别是想给Claude、Cursor这类智能助手扩展更强大的工具调用能力时,不可避免地接触到了Model Context Protocol。如果你也在研究如何让AI助手安全、可控地访问文件系…...

RePKG终极指南:如何深度解析Wallpaper Engine资源包与TEX纹理转换
RePKG终极指南:如何深度解析Wallpaper Engine资源包与TEX纹理转换 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg RePKG是一款专为Wallpaper Engine设计的专业级资源包解…...

基于OpenTelemetry构建企业级可观测性:从设计到生产实践
1. 项目概述:从“黑盒”到“白盒”的工程实践在分布式系统、微服务架构乃至复杂的单体应用开发中,我们常常面临一个共同的困境:系统内部的状态如同一个“黑盒”。当线上服务出现响应缓慢、内存泄漏或偶发性错误时,传统的日志&…...