redis-如何保证数据库和缓存双写一致性?
前言
数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。
我很负责的告诉大家,该问题无论在面试,还是工作中遇到的概率非常大,所以非常有必要跟大家一起探讨一下。
今天这篇文章我会从浅入深,跟大家一起聊聊,数据库和缓存双写数据一致性问题常见的解决方案,这些方案中可能存在的坑,以及最优方案是什么。
1、 常见方案
通常情况下,我们使用缓存的主要目的是为了提升查询的性能。大多数情况下,我们是这样使用缓存的:
用户请求过来之后,先查缓存有没有数据,如果有则直接返回。
如果缓存没数据,再继续查数据库。
如果数据库有数据,则将查询出来的数据,放入缓存中,然后返回该数据。
如果数据库也没数据,则直接返回空。
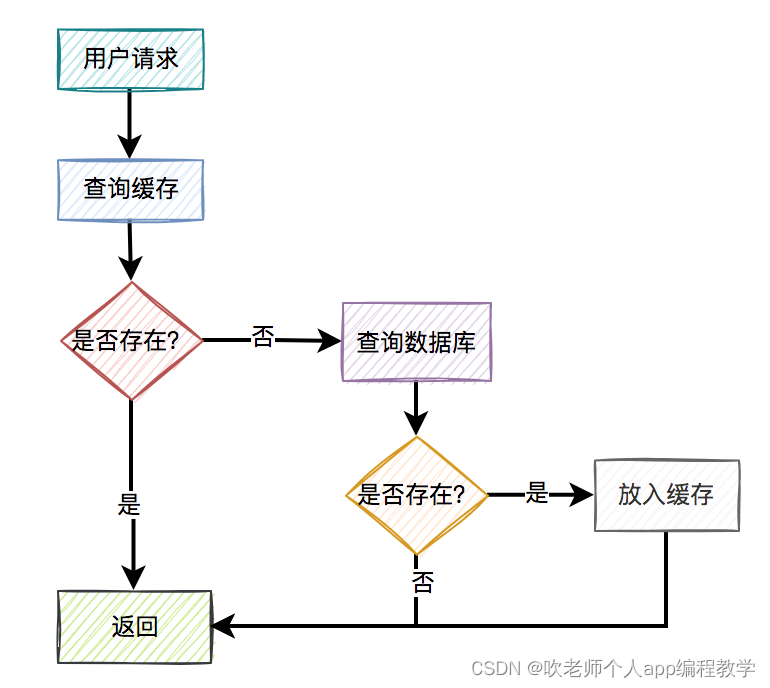
这是缓存非常常见的用法。一眼看上去,好像没有啥问题。
但你忽略了一个非常重要的细节:如果数据库中的某条数据,放入缓存之后,又立马被更新了,那么该如何更新缓存呢?
不更新缓存行不行?
答:当然不行,如果不更新缓存,在很长的一段时间内(决定于缓存的过期时间),用户请求从缓存中获取到的都可能是旧值,而非数据库的最新值。这不是有数据不一致的问题?
那么,我们该如何更新缓存呢?
目前有以下4种方案:
先写缓存,再写数据库
先写数据库,再写缓存
先删缓存,再写数据库
先写数据库,再删缓存
接下来,我们详细说说这4种方案。
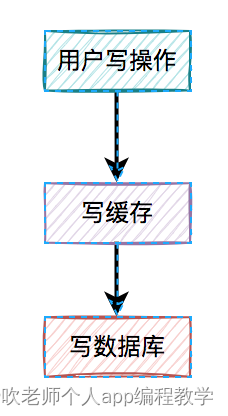
2、先写缓存,再写数据库
对于更新缓存的方案,很多人第一个想到的可能是在写操作中直接更新缓存(写缓存),更直接明了。
那么,问题来了:在写操作中,到底是先写缓存,还是先写数据库呢?
我们在这里先聊聊先写缓存,再写数据库的情况,因为它的问题最严重。
某一个用户的每一次写操作,如果刚写完缓存,突然网络出现了异常,导致写数据库失败了。其结果是缓存更新成了最新数据,但数据库没有,这样缓存中的数据不就变成脏数据了?如果此时该用户的查询请求,正好读取到该数据,就会出现问题,因为该数据在数据库中根本不存在,这个问题非常严重。
我们都知道,缓存的主要目的是把数据库的数据临时保存在内存,便于后续的查询,提升查询速度。
但如果某条数据,在数据库中都不存在,你缓存这种“假数据”又有啥意义呢?
因此,先写缓存,再写数据库的方案是不可取的,在实际工作中用得不多。
3、先写数据库,再写缓存
既然上面的方案行不通,接下来,聊聊先写数据库,再写缓存的方案,该方案在低并发编程中有人在用(我猜的)。
用户的写操作,先写数据库,再写缓存,可以避免之前“假数据”的问题。但它却带来了新的问题。
什么问题呢?
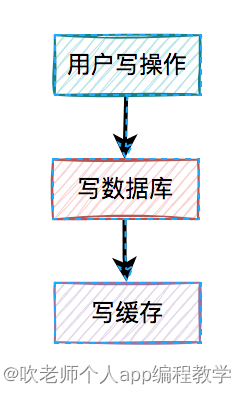
3.1 写缓存失败了
如果把写数据库和写缓存操作,放在同一个事务当中,当写缓存失败了,我们可以把写入数据库的数据进行回滚。
如果是并发量比较小,对接口性能要求不太高的系统,可以这么玩。
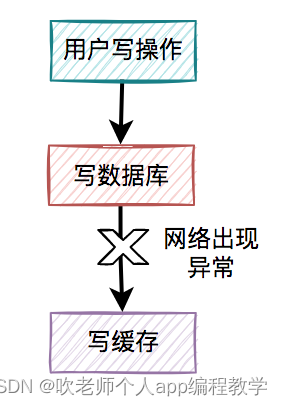
但如果在高并发的业务场景中,写数据库和写缓存,都属于远程操作。为了防止出现大事务,造成的死锁问题,通常建议写数据库和写缓存不要放在同一个事务中。
也就是说在该方案中,如果写数据库成功了,但写缓存失败了,数据库中已写入的数据不会回滚。
这就会出现:数据库是新数据,而缓存是旧数据,两边数据不一致的情况。
3.2 高并发下的问题
假设在高并发的场景中,针对同一个用户的同一条数据,有两个写数据请求:a和b,它们同时请求到业务系统。
其中请求a获取的是旧数据,而请求b获取的是新数据,如下图所示:
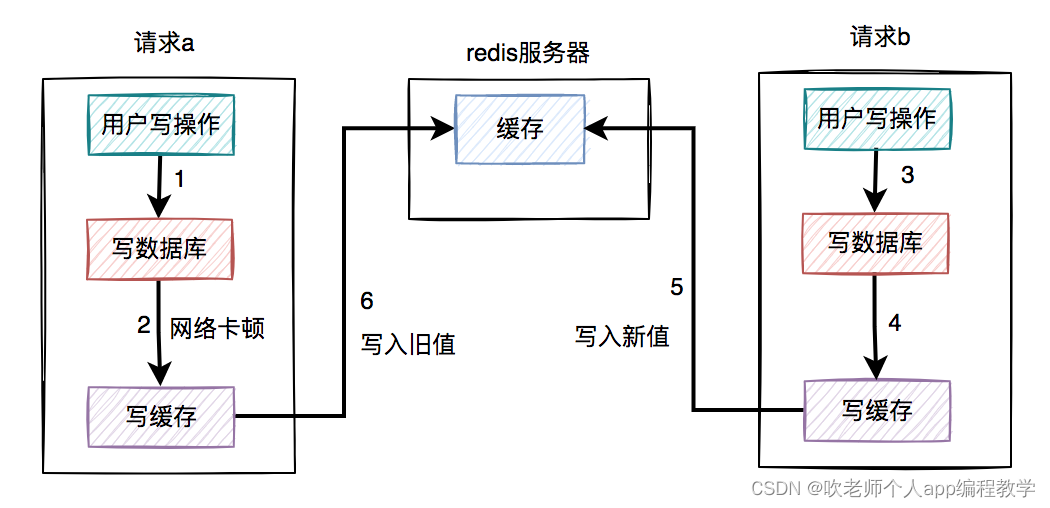
请求a先过来,刚写完了数据库。但由于网络原因,卡顿了一下,还没来得及写缓存。
这时候请求b过来了,先写了数据库。
接下来,请求b顺利写了缓存。
此时,请求a卡顿结束,也写了缓存。
很显然,在这个过程当中,请求b在缓存中的新数据,被请求a的旧数据覆盖了。
也就是说:在高并发场景中,如果多个线程同时执行先写数据库,再写缓存的操作,可能会出现数据库是新值,而缓存中是旧值,两边数据不一致的情况。
3.3、浪费系统资源
该方案还有一个比较大的问题就是:每个写操作,写完数据库,会马上写缓存,比较浪费系统资源。
为什么这么说呢?
你可以试想一下,如果写的缓存,并不是简单的数据内容,而是要经过非常复杂的计算得出的最终结果。这样每写一次缓存,都需要经过一次非常复杂的计算,不是非常浪费系统资源吗?
尤其是cpu和内存资源。
还有些业务场景比较特殊:写多读少。
如果在这类业务场景中,每个用的写操作,都需要写一次缓存,有点得不偿失。
由此可见,在高并发的场景中,先写数据库,再写缓存,这套方案问题挺多的,也不太建议使用。
如果你已经用了,赶紧看看踩坑了没?
4. 先删缓存,再写数据库
通过上面的内容我们得知,如果直接更新缓存的问题很多。
那么,为何我们不能换一种思路:不去直接更新缓存,而改为删除缓存呢?
删除缓存方案,同样有两种:
先删缓存,再写数据库
先写数据库,再删缓存
我们一起先看看:先删缓存,再写数据库的情况。
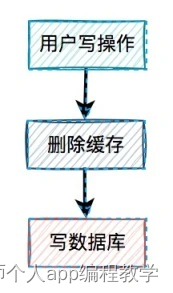
说白了,在用户的写操作中,先执行删除缓存操作,再去写数据库。这套方案,可以是可以,但也会有一样问题。
4.1 高并发下的问题
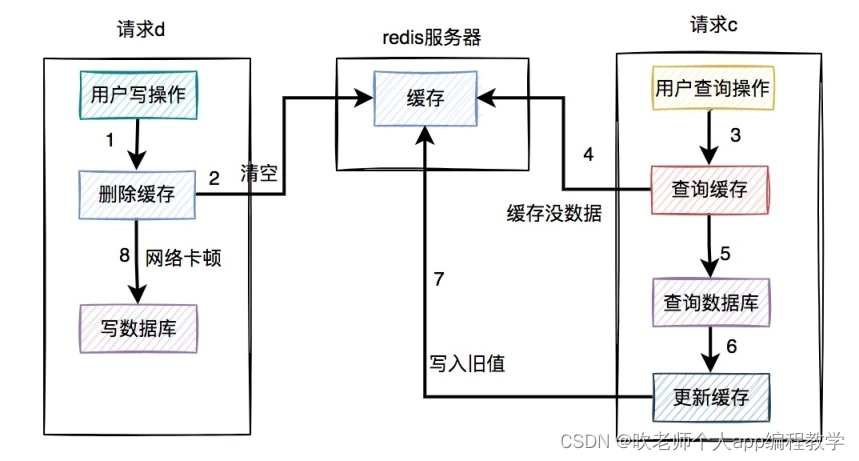
假设在高并发的场景中,同一个用户的同一条数据,有一个读数据请求 c,还有另一个写数据请求 d(一个更新操作),同时请求到业务系统。如下图所示:
请求 d 先过来,把缓存删除了。但由于网络原因,卡顿了一下,还没来得及写数据库。
这时请求 c 过来了,先查缓存发现没数据,再查数据库,有数据,但是旧值。
请求 c 将数据库中的旧值,更新到缓存中。
此时,请求 d 卡顿结束,把新值写入数据库。
在这个过程当中,请求 d 的新值并没有被请求 c 写入缓存,同样会导致缓存和数据库的数据不一致的情况。
那么,这种场景的数据不一致问题,能否解决呢?
4.2 缓存双删
在上面的业务场景中,一个读数据请求,一个写数据请求。当写数据请求把缓存删了之后,读数据请求,可能把当时从数据库查询出来的旧值,写入缓存当中。
有人说还不好办,请求 d 在写完数据库之后,把缓存重新删一次不就行了?
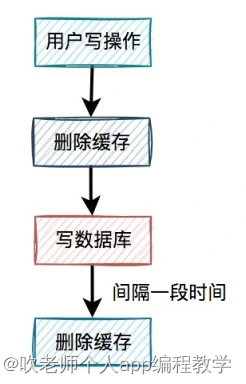
这就是我们所说的缓存双删,即在写数据库之前删除一次,写完数据库后,再删除一次。
该方案有个非常关键的地方是:第二次删除缓存,并非立马就删,而是要在一定的时间间隔之后。
我们再重新回顾一下,高并发下一个读数据请求,一个写数据请求导致数据不一致的产生过程:
请求 d 先过来,把缓存删除了。但由于网络原因,卡顿了一下,还没来得及写数据库。
这时请求 c 过来了,先查缓存发现没数据,再查数据库,有数据,但是旧值。
请求 c 将数据库中的旧值,更新到缓存中。
此时,请求 d 卡顿结束,把新值写入数据库。
一段时间之后,比如:500ms,请求 d 将缓存删除。
这样来看确实可以解决缓存不一致问题。
那么,为什么一定要间隔一段时间之后,才能删除缓存呢?
请求 d 卡顿结束,把新值写入数据库后,请求 c 将数据库中的旧值,更新到缓存中。
此时,如果请求 d 删除太快,在请求 c 将数据库中的旧值更新到缓存之前,就已经把缓存删除了,这次删除就没任何意义。必须要在请求 c 更新缓存之后,再删除缓存,才能把旧值及时删除了。
所以需要在请求 d 中加一个时间间隔,确保请求 c,或者类似于请求 c 的其他请求,如果在缓存中设置了旧值,最终都能够被请求 d 删除掉。
接下来,还有一个问题:如果第二次删除缓存时,删除失败了该怎么办?
这里先留点悬念,后面会详细说。
5. 先写数据库,再删缓存
从前面得知,先删缓存,再写数据库,在并发的情况下,也可能会出现缓存和数据库的数据不一致的情况。
那么,我们只能寄希望于最后的方案了。
接下来,我们重点看看先写数据库,再删缓存的方案。
在高并发的场景中,有一个读数据请求,有一个写数据请求,更新过程如下:
请求 e 先写数据库,由于网络原因卡顿了一下,没有来得及删除缓存。
请求 f 查询缓存,发现缓存中有数据,直接返回该数据。
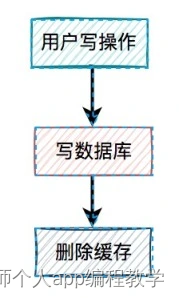
请求 e 删除缓存。
在这个过程中,只有请求 f 读了一次旧数据,后来旧数据被请求 e 及时删除了,看起来问题不大。
但如果是读数据请求先过来呢?
请求 f 查询缓存,发现缓存中有数据,直接返回该数据。
请求 e 先写数据库。
请求 e 删除缓存。
这种情况看起来也没问题呀?
答:对的。
但就怕出现下面这种情况,即缓存自己失效了。如下图所示:
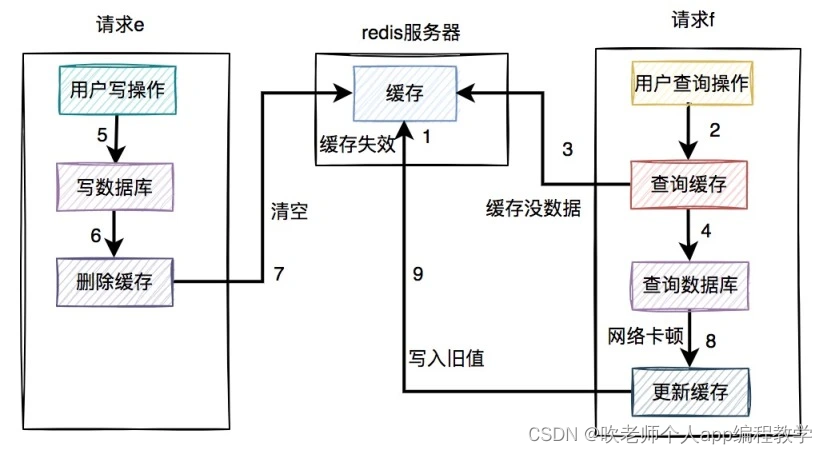
缓存过期时间到了,自动失效。
请求 f 查询缓存,发缓存中没有数据,查询数据库的旧值,但由于网络原因卡顿了,没有来得及更新缓存。
请求 e 先写数据库,接着删除了缓存。
请求 f 更新旧值到缓存中。
这时,缓存和数据库的数据同样出现不一致的情况了。
但这种情况还是比较少的,需要同时满足以下条件才可以:
缓存刚好自动失效。
请求 f 从数据库查出旧值,更新缓存的耗时,比请求 e 写数据库,并且删除缓存的还长。
我们都知道查询数据库的速度,一般比写数据库要快,更何况写完数据库,还要删除缓存。所以绝大多数情况下,写数据请求比读数据情况耗时更长。
由此可见,系统同时满足上述两个条件的概率非常小。
推荐大家使用先写数据库,再删缓存的方案,虽说不能 100%避免数据不一致问题,但出现该问题的概率,相对于其他方案来说是最小的。
但在该方案中,如果删除缓存失败了该怎么办呢?
6. 删缓存失败怎么办?
其实先写数据库,再删缓存的方案,跟缓存双删的方案一样,有一个共同的风险点,即:如果缓存删除失败了,也会导致缓存和数据库的数据不一致。
那么,删除缓存失败怎么办呢?
答:需要加重试机制。
在接口中如果更新了数据库成功了,但更新缓存失败了,可以立刻重试 3 次。如果其中有任何一次成功,则直接返回成功。如果 3 次都失败了,则写入数据库,准备后续再处理。
当然,如果你在接口中直接同步重试,该接口并发量比较高的时候,可能有点影响接口性能。
这时,就需要改成异步重试了。
异步重试方式有很多种,比如:
每次都单独起一个线程,该线程专门做重试的工作。但如果在高并发的场景下,可能会创建太多的线程,导致系统 OOM 问题,不太建议使用。
将重试的任务交给线程池处理,但如果服务器重启,部分数据可能会丢失。
将重试数据写表,然后使用 elastic-job 等定时任务进行重试。
将重试的请求写入 mq 等消息中间件中,在 mq 的 consumer 中处理。
订阅 mysql 的 binlog,在订阅者中,如果发现了更新数据请求,则删除相应的缓存。
7. 定时任务
使用定时任务重试的具体方案如下:
当用户操作写完数据库,但删除缓存失败了,需要将用户数据写入重试表中。如下图所示:
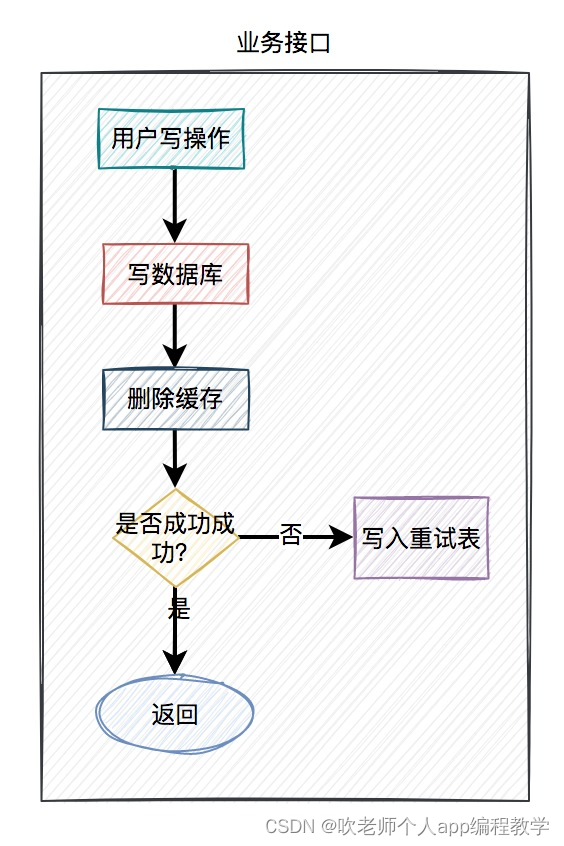
在定时任务中,异步读取重试表中的用户数据。重试表需要记录一个重试次数字段,初始值为 0。然后重试 5 次,不断删除缓存,每重试一次该字段值+1。如果其中有任意一次成功了,则返回成功。如果重试了 5 次,还是失败,则我们需要在重试表中记录一个失败的状态,等待后续进一步处理。
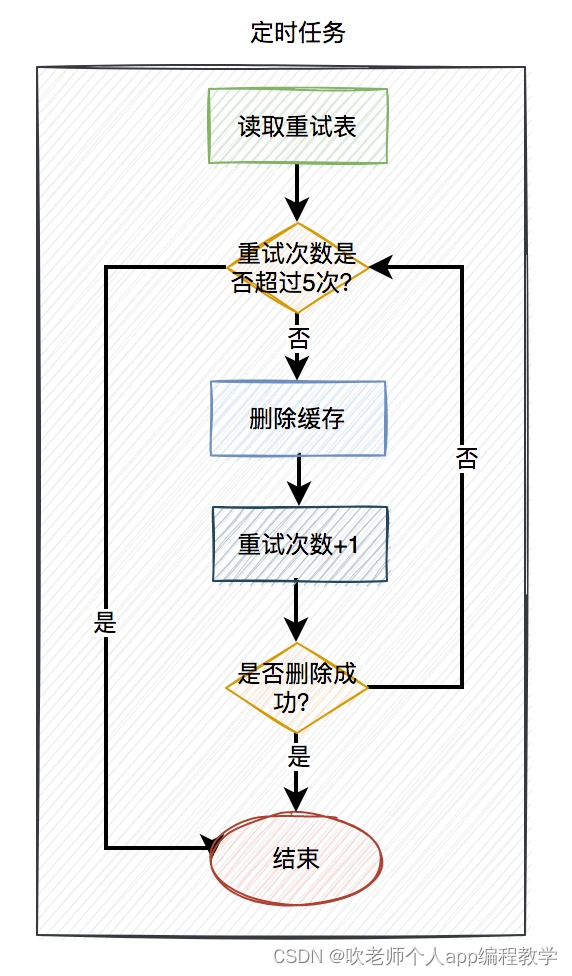
在高并发场景中,定时任务推荐使用elastic-job。相对于 xxl-job 等定时任务,它可以分片处理,提升处理速度。同时每片的间隔可以设置成:1,2,3,5,7 秒等。
如果大家对定时任务比较感兴趣的话,可以看看我的另一篇文章《学会这10种定时任务,我有点飘了》,里面列出了目前最主流的定时任务。
使用定时任务重试的话,有个缺点就是实时性没那么高,对于实时性要求特别高的业务场景,该方案不太适用。但是对于一般场景,还是可以用一用的。
但它有一个很大的优点,即数据是落库的,不会丢数据。
8. mq
在高并发的业务场景中,mq(消息队列)是必不可少的技术之一。它不仅可以异步解耦,还能削峰填谷。对保证系统的稳定性是非常有意义的。
对 mq 有兴趣的朋友可以看看我的另一篇文章《mq的那些破事儿》。
mq 的生产者,生产了消息之后,通过指定的 topic 发送到 mq 服务器。然后 mq 的消费者,订阅该 topic 的消息,读取消息数据之后,做业务逻辑处理。
使用mq重试的具体方案如下:
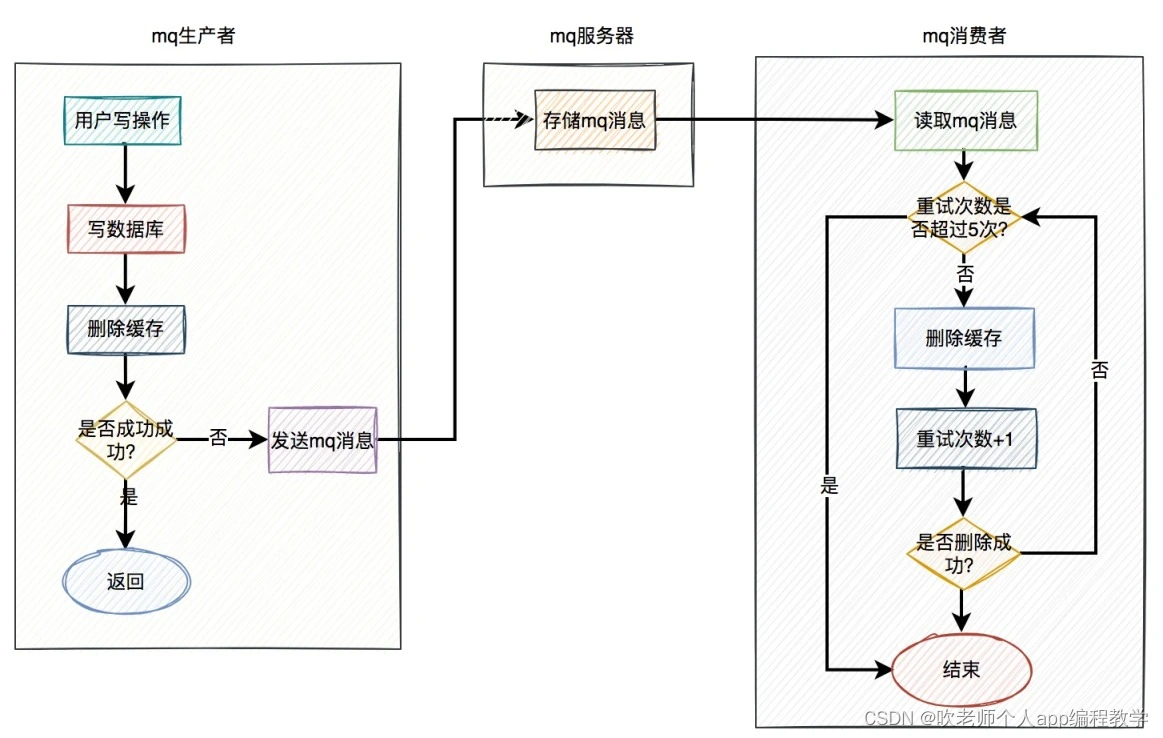
当用户操作写完数据库,但删除缓存失败了,产生一条 mq 消息,发送给 mq 服务器。
mq 消费者读取 mq 消息,重试 5 次删除缓存。如果其中有任意一次成功了,则返回成功。如果重试了 5 次,还是失败,则写入死信队列中。
推荐 mq 使用rocketmq,重试机制和死信队列默认是支持的。使用起来非常方便,而且还支持顺序消息,延迟消息和事务消息等多种业务场景。
当然在该方案中,删除缓存可以完全走异步。即用户的写操作,在写完数据库之后,不用立刻删除一次缓存。而直接发送 mq 消息,到 mq 服务器,然后有 mq 消费者全权负责删除缓存的任务。
因为 mq 的实时性还是比较高的,因此改良后的方案也是一种不错的选择
9. binlog
前面我们聊过的,无论是定时任务,还是 mq(消息队列),做重试机制,对业务都有一定的侵入性。
在使用定时任务的方案中,需要在业务代码中增加额外逻辑,如果删除缓存失败,需要将数据写入重试表。
而使用 mq 的方案中,如果删除缓存失败了,需要在业务代码中发送 mq 消息到 mq 服务器。
其实,还有一种更优雅的实现,即监听binlog,比如使用:canal等中间件。
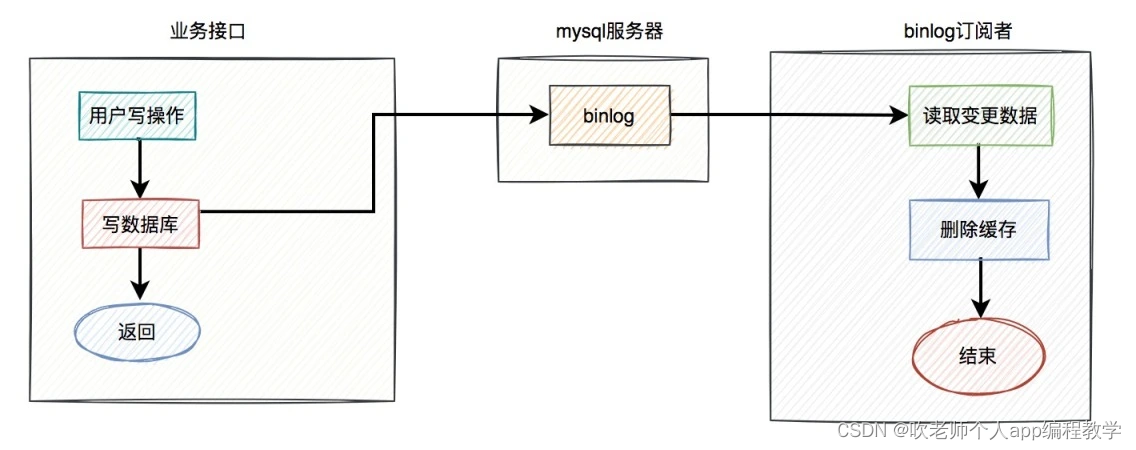
具体方案如下:
在业务接口中写数据库之后,就不管了,直接返回成功。
mysql 服务器会自动把变更的数据写入 binlog 中。
binlog 订阅者获取变更的数据,然后删除缓存。
这套方案中业务接口确实简化了一些流程,只用关心数据库操作即可,而在 binlog 订阅者中做缓存删除工作。
但如果只是按照图中的方案进行删除缓存,只删除了一次,也可能会失败。
如何解决这个问题呢?
答:这就需要加上前面聊过的重试机制了。如果删除缓存失败,写入重试表,使用定时任务重试。或者写入 mq,让 mq 自动重试。
在这里推荐使用mq自动重试机制。

在 binlog 订阅者中如果删除缓存失败,则发送一条 mq 消息到 mq 服务器,在 mq 消费者中自动重试 5 次。如果有任意一次成功,则直接返回成功。如果重试 5 次后还是失败,则该消息自动被放入死信队列,后面可能需要人工介入。
相关文章:
redis-如何保证数据库和缓存双写一致性?
前言 数据库和缓存(比如:redis)双写数据一致性问题,是一个跟开发语言无关的公共问题。尤其在高并发的场景下,这个问题变得更加严重。 我很负责的告诉大家,该问题无论在面试,还是工作中遇到的概率…...
系列二、核心概念运行流程
一、镜像&容器&仓库 1.1、镜像 定义:一个镜像代表着一个软件,例如:mysql镜像、redis镜像、nginx镜像。 特点:只读 1.2、容器 定义:基于某个镜像运行一次就会生成一个程序实例,一个程序实例称之为一…...
恢复 iPhone 和 iPad 数据的 10 种简单工具
它发生了.. 有时您需要从您的手机或平板设备恢复重要数据。 许多人已经开始将重要文件存储在手机上,因为他们几乎可以在任何情况下随时随地轻松访问数据。 从技术上讲,您会在几分之一秒内丢失所有存储的信息、照片、视频、音乐、文档等。因此ÿ…...
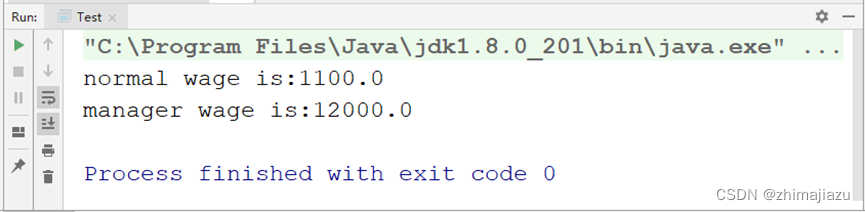
经理与员工工资关系-课后程序(JAVA基础案例教程-黑马程序员编著-第四章-课后作业)
【案例4-6】经理与员工工资案例(利用多态实现) 欢迎点赞关注收藏 【案例介绍】 案例描述 某公司的人员分为员工和经理两种,但经理也属于员工中的一种,公司的人员都有自己的姓名和地址,员工和经理都有自己的工号、工…...
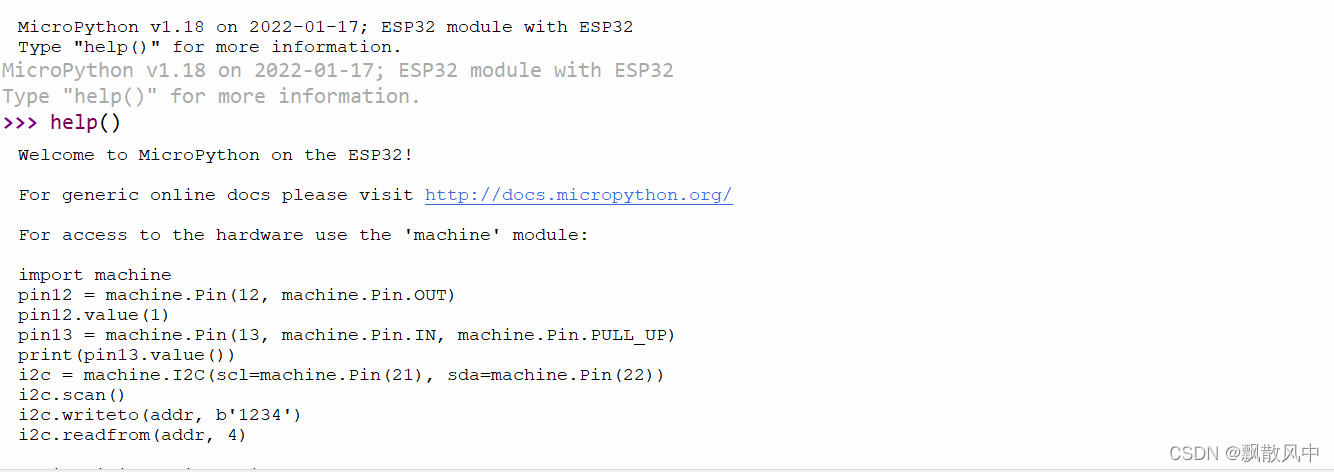
Micropython ESP32配置与烧录版本
下载ESP32的Micropython固件 官方连接https://www.micropython.org/download/esp32/ 看了下描述,上面的是IDF4.x系列编译,下面是IDF3.x系列编译,我们默认选新的 下载安装CP2102驱动 CP210x USB to UART Bridge VCP Drivers - Silicon Labs…...
)
java面试题-并发关键字(Synchronized,volatile,final)
Synchronized1.Synchronized可以作用在哪里?Synchronized可以作用在方法、代码块、静态方法和类上。方法public synchronized void method(){//同步代码块 }代码块Object lock new Object(); synchronized(lock){//同步代码块 }静态方法public static synchronized void stat…...
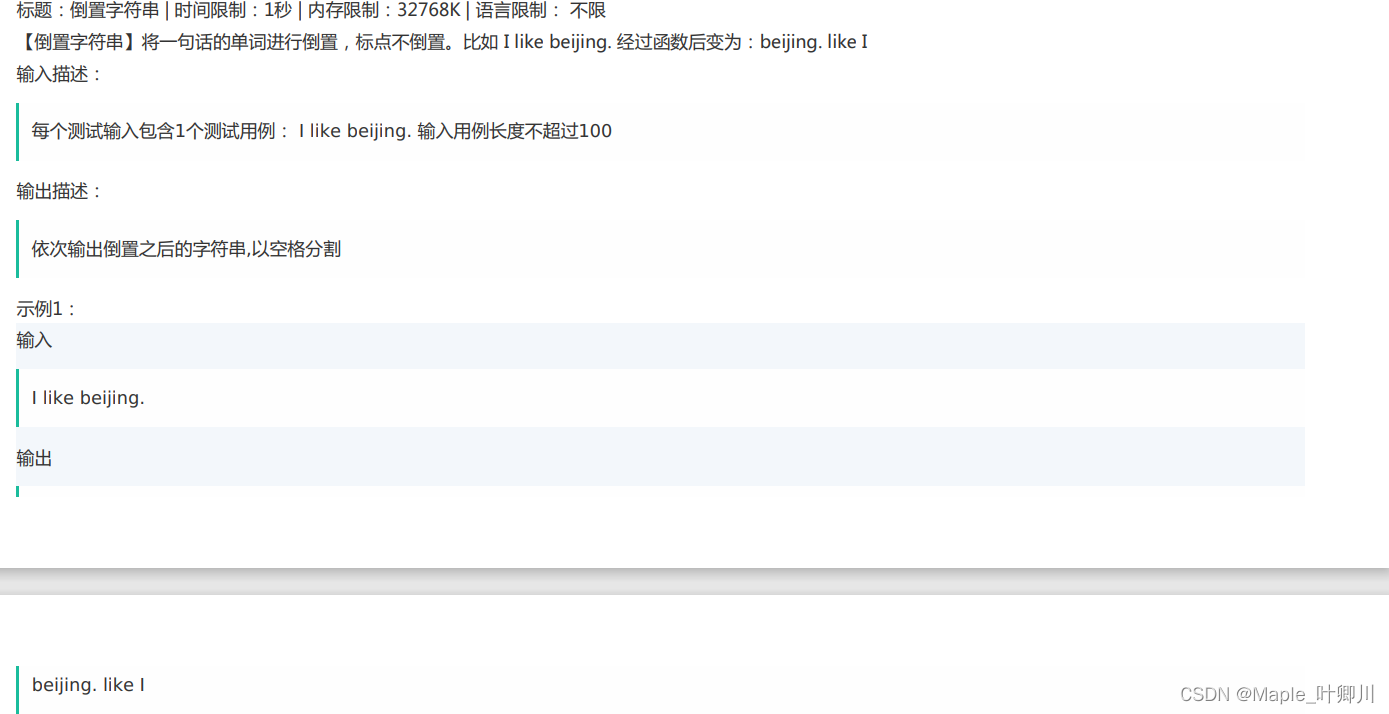
【笔试强训】Day_02
目录 一、选择题 1、 2、 3、 4、 5、 6、 7、 8、 9、 10、 二、编程题 1、排序子序列 2、倒置字符串 一、选择题 1、 使用printf函数打印一个double类型的数据,要求:输出为10进制,输出左对齐30个字符,4位精度。…...

DepGraph:适用任何结构的剪枝
文章目录摘要1、简介2、相关工作3、方法3.1、神经网络中的依赖关系3.2、依赖关系图3.3、使用依赖图剪枝4、实验4.1、设置。4.2、CIFAR的结果4.3、消融实验4.4、适用任何结构剪枝5、结论摘要 论文链接:https://arxiv.org/abs/2301.12900 源码:https://gi…...
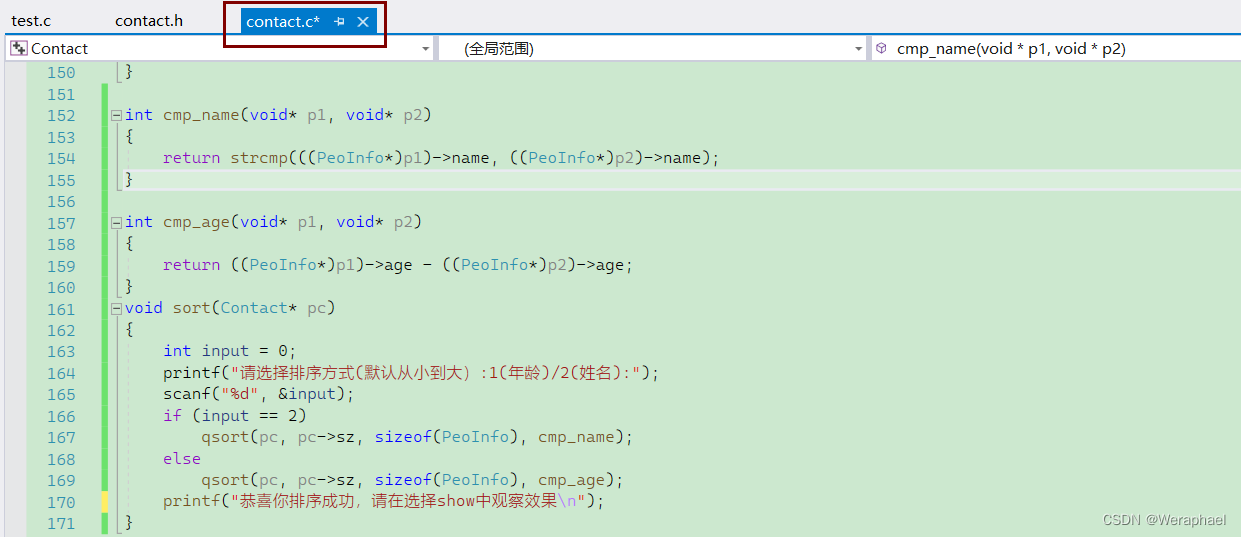
【结构体版】通讯录
👦个人主页:Weraphael ✍🏻作者简介:目前是C语言学习者 ✈️专栏:项目 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞&#x…...

Debezium系列之:基于debezium采集数据到kafka,再从kafka将数据流式传输到下游数据库
Debezium系列之:基于debezium采集数据到kafka,再从kafka将数据流式传输到下游数据库 一、需求背景二、准备Debezium集群和相关jar包的详细步骤三、查看插件是否加载成功四、源数据库表结构五、根据源数据库表结构准备目标数据库的表六、基于debezium采集数据到kafka七、查看c…...

【2023】华为OD机试真题Java-题目0217-上班之路
上班之路 题目描述 Jungle生活在美丽的蓝鲸城,大马路都是方方正正,但是每天马路的封闭情况都不一样。 地图由以下元素组成: . — 空地,可以达到;* — 路障,不可达到;S — Jungle的家;T — 公司. 其中我们会限制Jungle拐弯的次数,同时Jungle可以清除给定个数的路障,现在…...
)
基于spring生态的基础后端开发及渗透测试流程(二)
基于spring生态的基础后端开发及渗透测试流程(二)安全设备IDS蜜罐安全加固渗透测试信息收集子域名域名注册信息企业信息端口扫描源码泄露路径扫描真实ip探测js扫描设备检测蜜罐识别waf识别社工爆破漏洞扫描系统扫描web扫描应急响应继上次写了一份基于spr…...
)
Python语言零基础入门教程(二十六)
Python OS 文件/目录方法 Python语言零基础入门教程(二十五) 51、Python os.stat_float_times() 方法 概述 os.stat_float_times() 方法用于决定stat_result是否以float对象显示时间戳。 语法 stat_float_times()方法语法格式如下: os.s…...

人们最想看到的是:你在坚持什么?
【人们最想看到的是:你在坚持什么】 长远规划才能对抗不确定性 品牌也能够对抗不确定性 想想这么多年东搞搞,西搞搞 最后缺乏正向积累的【厚度】 趣讲大白话:把每滴水尽量接到碗里 人吃的是饭,拉出来的是信息 *********** 人们在频…...

300行代码手写spring初体验v1.0版本
70%猜想30%验证 spring:IOC 、DI、AOP、MVC MVC作为入口 web.xml 内部依赖一个DispathcheServlet这样一个接口 先来说一下springMVC的一些基础知识 整体的一个思路: 在web.xml里面进行了一个核心servlet的一个配置 核心就是这个DispatcherServlet …...
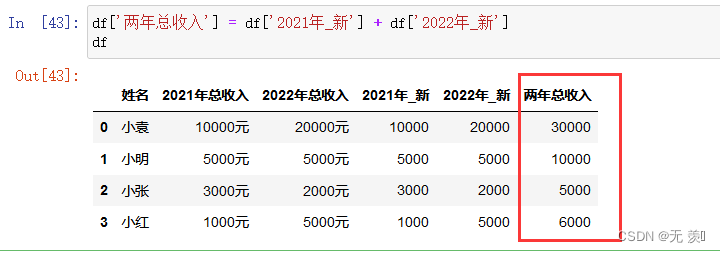
100天精通Python(数据分析篇)——第76天:Pandas数据类型转换函数pd.to_numeric(参数说明+实战案例)
文章目录专栏导读一、to_numeric参数说明0. 介绍1. arg1)接收列表2)接收一维数组3)接收Series对象2. errors1)errorscoerce2)errors ignore3. downcast1)downcastinteger2)downcastsigned3&…...
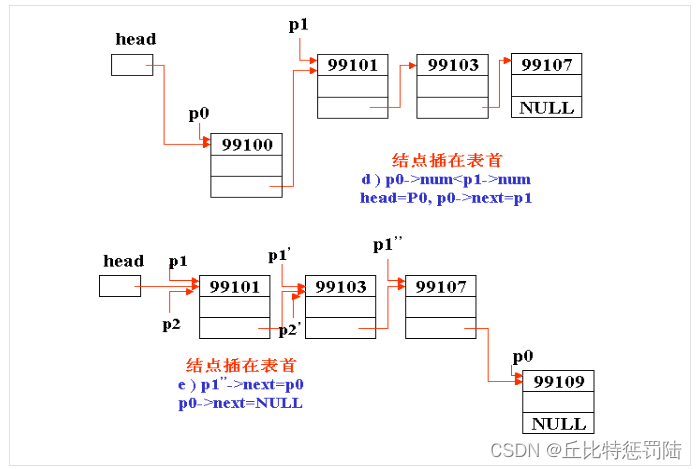
链表(超详细--包教包会)
目录 一、概述 二、对链表的基本操作 三、链表的分类 四、静态链表 五、动态链表 1、malloc函数 2、calloc函数 3、free函数 六、动态链表的建立 七、输出链表中的数据 八、查找节点 九、删除节点 十、插入节点 十一、整体代码 一、概述 链表存储结构是一种动态数据…...

爬虫基本知识的认知(爬虫流程 HTTP构建)| 爬虫理论课,附赠三体案例
爬虫是指通过程序自动化地从互联网上获取数据的过程。 基本的爬虫流程可以概括为以下几个步骤: 发送 HTTP 请求:通过 HTTP 协议向指定的 URL 发送请求,获取对应的 HTML 页面。解析 HTML 页面:使用 HTML 解析器对获取的 HTML 页面…...
Ubuntu20.04如何安装虚拟机(并安装Android)
安装虚拟机(KVM)这种KVM只能安装windows无法安装安卓(From https://phoenixnap.com/kb/ubuntu-install-kvm)A type 2 hypervisor enables users to run isolated instances of other operating systems inside a host system. As a Linux based OS, Ubun…...

【腾讯一面】我对我的Java基础不自信了
我对我的Java基础不自信了1、List和set的区别?2、HashSet 是如何保证不重复的3、HashMap是线程安全的吗,为什么不是线程安全的?4、HashMap的扩容过程5、Java获取反射的三种方法6、Redis持久化机制原理7、redis持久化的方式各有哪些优缺点1、L…...

ESP32+PHP+MySQL:构建云端物联网数据可视化看板
1. 从零搭建ESP32物联网数据采集系统 第一次接触ESP32时,我被它强大的WiFi和蓝牙功能惊艳到了。这块售价仅几十元的小开发板,居然能轻松实现传感器数据采集和无线传输。今天我要分享的,就是如何用ESP32构建一个完整的物联网数据可视化系统。 …...

MiniCPM-V-2_6数据结构设计:高效管理海量图片识别结果的内存与存储方案
MiniCPM-V-2_6数据结构设计:高效管理海量图片识别结果的内存与存储方案 你是不是也遇到过这样的场景?用MiniCPM-V-2_6处理了几百张、甚至上千张图片,生成的描述文本堆在内存里,程序越跑越慢,想找之前某张图的识别结果…...
)
constexpr + consteval + constinit 三重锁性能模型(工业级嵌入式系统内存占用压缩41%,启动时间缩短至23ms)
第一章:constexpr consteval constinit 三重锁性能模型概览C20 引入的 constexpr、consteval 和 constinit 构成了一套分层编译期约束体系,共同构成现代 C 静态性能保障的“三重锁”模型。它们并非替代关系,而是按语义强度递进:…...

大模型应用开发零基础教程:30分钟上手
大模型应用开发零基础教程:30分钟上手 标签:#人工智能、#大模型、#自然语言处理、#大模型开发、#智能体开发、#agent开发、#AI 系统封装学习规划(从玩具到产品) 用streamlit run xxx.py --server.port 8501本地测试免费部署&#…...

SEO_为什么你的SEO没效果?关键原因分析
SEO为什么你的SEO没效果?关键原因分析 在互联网时代,SEO(搜索引擎优化)是提升网站在搜索引擎排名的关键手段。不少网站在付出大量努力后,却发现SEO效果不佳,这是一个令人困扰的问题。为什么你的SEO没有效果…...

PHP Tokenizer终极指南:5个企业级代码分析实战案例
PHP Tokenizer终极指南:5个企业级代码分析实战案例 【免费下载链接】tokenizer A small library for converting tokenized PHP source code into XML (and potentially other formats) 项目地址: https://gitcode.com/gh_mirrors/to/tokenizer PHP Tokenize…...

刷题不再难:用代码随想录和Hot100打造你的算法思维
算法思维跃迁:从代码随想录到Hot100的实战精进指南 1. 算法能力提升的黄金路径 在技术面试中,算法能力往往是区分候选人的关键指标。但许多开发者在刷题过程中常陷入"刷了就忘"的困境,缺乏系统性训练方法。本文将揭示如何通过代码随…...

易语言手游中控框架源码|逍遥模拟器专用模板
温馨提示:文末有联系方式【核心亮点:即买即用的成熟中控框架】 本套源码为完整可编译、可调试的易语言手游中控模板框架,已通过逍遥模拟器实机验证,安装后无需复杂配置即可稳定运行,大幅缩短项目启动周期。【适用场景&…...
)
numpy+pandas核心操作全总结:详细代码注释(数组/Series/DataFrame完整指南)
📢 更多数据分析干货,关注公众号:船长Talk,每天分享 Python/SQL 实战技巧!两个重要的包:numpy、pandas,是数据分析师的必备基础。本文做全面总结,每段代码都有详细注释,建…...

【互联网大厂Java面试】核心技术栈面试问答实战解析
互联网大厂Java求职面试实战问答 本文以互联网大厂Java求职者面试为场景,围绕核心技术栈,采用故事化形式,严肃的面试官与搞笑的水货程序员谢飞机进行问答。文章分3轮,每轮包含3-5个问题,问题循序渐进,旨在…...