简述7个流行的强化学习算法及代码实现!
目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。这些算法已被用于在游戏、机器人和决策制定等各种应用中,并且这些流行的算法还在不断发展和改进,本文我们将对其做一个简单的介绍。
1、Q-learning
Q-learning:Q-learning 是一种无模型、非策略的强化学习算法。它使用 Bellman 方程估计最佳动作值函数,该方程迭代地更新给定状态动作对的估计值。Q-learning 以其简单性和处理大型连续状态空间的能力而闻名。
下面是一个使用 Python 实现 Q-learning 的简单示例:
import numpy as np# Define the Q-table and the learning rate
Q = np.zeros((state_space_size, action_space_size))
alpha = 0.1# Define the exploration rate and discount factor
epsilon = 0.1
gamma = 0.99for episode in range(num_episodes):current_state = initial_statewhile not done:# Choose an action using an epsilon-greedy policyif np.random.uniform(0, 1) < epsilon:action = np.random.randint(0, action_space_size)else:action = np.argmax(Q[current_state])# Take the action and observe the next state and rewardnext_state, reward, done = take_action(current_state, action)# Update the Q-table using the Bellman equationQ[current_state, action] = Q[current_state, action] + alpha * (reward + gamma * np.max(Q[next_state]) - Q[current_state, action])current_state = next_state上面的示例中,state_space_size 和 action_space_size 分别是环境中的状态数和动作数。num_episodes 是要为运行算法的轮次数。initial_state 是环境的起始状态。take_action(current_state, action) 是一个函数,它将当前状态和一个动作作为输入,并返回下一个状态、奖励和一个指示轮次是否完成的布尔值。
在 while 循环中,使用 epsilon-greedy 策略根据当前状态选择一个动作。使用概率 epsilon选择一个随机动作,使用概率 1-epsilon选择对当前状态具有最高 Q 值的动作。
采取行动后,观察下一个状态和奖励,使用Bellman方程更新q。并将当前状态更新为下一个状态。这只是 Q-learning 的一个简单示例,并未考虑 Q-table 的初始化和要解决的问题的具体细节。
2、SARSA
SARSA:SARSA 是一种无模型、基于策略的强化学习算法。它也使用Bellman方程来估计动作价值函数,但它是基于下一个动作的期望值,而不是像 Q-learning 中的最优动作。SARSA 以其处理随机动力学问题的能力而闻名。
import numpy as np# Define the Q-table and the learning rate
Q = np.zeros((state_space_size, action_space_size))
alpha = 0.1# Define the exploration rate and discount factor
epsilon = 0.1
gamma = 0.99for episode in range(num_episodes):current_state = initial_stateaction = epsilon_greedy_policy(epsilon, Q, current_state)while not done:# Take the action and observe the next state and rewardnext_state, reward, done = take_action(current_state, action)# Choose next action using epsilon-greedy policynext_action = epsilon_greedy_policy(epsilon, Q, next_state)# Update the Q-table using the Bellman equationQ[current_state, action] = Q[current_state, action] + alpha * (reward + gamma * Q[next_state, next_action] - Q[current_state, action])current_state = next_stateaction = next_actionstate_space_size和action_space_size分别是环境中的状态和操作的数量。num_episodes是您想要运行SARSA算法的轮次数。Initial_state是环境的初始状态。take_action(current_state, action)是一个将当前状态和作为操作输入的函数,并返回下一个状态、奖励和一个指示情节是否完成的布尔值。
在while循环中,使用在单独的函数epsilon_greedy_policy(epsilon, Q, current_state)中定义的epsilon-greedy策略来根据当前状态选择操作。使用概率 epsilon选择一个随机动作,使用概率 1-epsilon对当前状态具有最高 Q 值的动作。
上面与Q-learning相同,但是采取了一个行动后,在观察下一个状态和奖励时它然后使用贪心策略选择下一个行动。并使用Bellman方程更新q表。
3、DDPG
DDPG 是一种用于连续动作空间的无模型、非策略算法。它是一种actor-critic算法,其中actor网络用于选择动作,而critic网络用于评估动作。DDPG 对于机器人控制和其他连续控制任务特别有用。
import numpy as np
from keras.models import Model, Sequential
from keras.layers import Dense, Input
from keras.optimizers import Adam# Define the actor and critic models
actor = Sequential()
actor.add(Dense(32, input_dim=state_space_size, activation='relu'))
actor.add(Dense(32, activation='relu'))
actor.add(Dense(action_space_size, activation='tanh'))
actor.compile(loss='mse', optimizer=Adam(lr=0.001))critic = Sequential()
critic.add(Dense(32, input_dim=state_space_size, activation='relu'))
critic.add(Dense(32, activation='relu'))
critic.add(Dense(1, activation='linear'))
critic.compile(loss='mse', optimizer=Adam(lr=0.001))# Define the replay buffer
replay_buffer = []# Define the exploration noise
exploration_noise = OrnsteinUhlenbeckProcess(size=action_space_size, theta=0.15, mu=0, sigma=0.2)for episode in range(num_episodes):current_state = initial_statewhile not done:# Select an action using the actor model and add exploration noiseaction = actor.predict(current_state)[0] + exploration_noise.sample()action = np.clip(action, -1, 1)# Take the action and observe the next state and rewardnext_state, reward, done = take_action(current_state, action)# Add the experience to the replay bufferreplay_buffer.append((current_state, action, reward, next_state, done))# Sample a batch of experiences from the replay bufferbatch = sample(replay_buffer, batch_size)# Update the critic modelstates = np.array([x[0] for x in batch])actions = np.array([x[1] for x in batch])rewards = np.array([x[2] for x in batch])next_states = np.array([x[3] for x in batch])target_q_values = rewards + gamma * critic.predict(next_states)critic.train_on_batch(states, target_q_values)# Update the actor modelaction_gradients = np.array(critic.get_gradients(states, actions))actor.train_on_batch(states, action_gradients)current_state = next_state在本例中,state_space_size和action_space_size分别是环境中的状态和操作的数量。num_episodes是轮次数。Initial_state是环境的初始状态。Take_action (current_state, action)是一个函数,它接受当前状态和操作作为输入,并返回下一个操作。
4、A2C
A2C(Advantage Actor-Critic)是一种有策略的actor-critic算法,它使用Advantage函数来更新策略。该算法实现简单,可以处理离散和连续的动作空间。
import numpy as np
from keras.models import Model, Sequential
from keras.layers import Dense, Input
from keras.optimizers import Adam
from keras.utils import to_categorical# Define the actor and critic models
state_input = Input(shape=(state_space_size,))
actor = Dense(32, activation='relu')(state_input)
actor = Dense(32, activation='relu')(actor)
actor = Dense(action_space_size, activation='softmax')(actor)
actor_model = Model(inputs=state_input, outputs=actor)
actor_model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001))state_input = Input(shape=(state_space_size,))
critic = Dense(32, activation='relu')(state_input)
critic = Dense(32, activation='relu')(critic)
critic = Dense(1, activation='linear')(critic)
critic_model = Model(inputs=state_input, outputs=critic)
critic_model.compile(loss='mse', optimizer=Adam(lr=0.001))for episode in range(num_episodes):current_state = initial_statedone = Falsewhile not done:# Select an action using the actor model and add exploration noiseaction_probs = actor_model.predict(np.array([current_state]))[0]action = np.random.choice(range(action_space_size), p=action_probs)# Take the action and observe the next state and rewardnext_state, reward, done = take_action(current_state, action)# Calculate the advantagetarget_value = critic_model.predict(np.array([next_state]))[0][0]advantage = reward + gamma * target_value - critic_model.predict(np.array([current_state]))[0][0]# Update the actor modelaction_one_hot = to_categorical(action, action_space_size)actor_model.train_on_batch(np.array([current_state]), advantage * action_one_hot)# Update the critic modelcritic_model.train_on_batch(np.array([current_state]), reward + gamma * target_value)current_state = next_state在这个例子中,actor模型是一个神经网络,它有2个隐藏层,每个隐藏层有32个神经元,具有relu激活函数,输出层具有softmax激活函数。critic模型也是一个神经网络,它有2个隐含层,每层32个神经元,具有relu激活函数,输出层具有线性激活函数。
使用分类交叉熵损失函数训练actor模型,使用均方误差损失函数训练critic模型。动作是根据actor模型预测选择的,并添加了用于探索的噪声。
5、PPO
PPO(Proximal Policy Optimization)是一种策略算法,它使用信任域优化的方法来更新策略。它在具有高维观察和连续动作空间的环境中特别有用。PPO 以其稳定性和高样品效率而著称。
import numpy as np
from keras.models import Model, Sequential
from keras.layers import Dense, Input
from keras.optimizers import Adam# Define the policy model
state_input = Input(shape=(state_space_size,))
policy = Dense(32, activation='relu')(state_input)
policy = Dense(32, activation='relu')(policy)
policy = Dense(action_space_size, activation='softmax')(policy)
policy_model = Model(inputs=state_input, outputs=policy)# Define the value model
value_model = Model(inputs=state_input, outputs=Dense(1, activation='linear')(policy))# Define the optimizer
optimizer = Adam(lr=0.001)for episode in range(num_episodes):current_state = initial_statewhile not done:# Select an action using the policy modelaction_probs = policy_model.predict(np.array([current_state]))[0]action = np.random.choice(range(action_space_size), p=action_probs)# Take the action and observe the next state and rewardnext_state, reward, done = take_action(current_state, action)# Calculate the advantagetarget_value = value_model.predict(np.array([next_state]))[0][0]advantage = reward + gamma * target_value - value_model.predict(np.array([current_state]))[0][0]# Calculate the old and new policy probabilitiesold_policy_prob = action_probs[action]new_policy_prob = policy_model.predict(np.array([next_state]))[0][action]# Calculate the ratio and the surrogate lossratio = new_policy_prob / old_policy_probsurrogate_loss = np.minimum(ratio * advantage, np.clip(ratio, 1 - epsilon, 1 + epsilon) * advantage)# Update the policy and value modelspolicy_model.trainable_weights = value_model.trainable_weightspolicy_model.compile(optimizer=optimizer, loss=-surrogate_loss)policy_model.train_on_batch(np.array([current_state]), np.array([action_one_hot]))value_model.train_on_batch(np.array([current_state]), reward + gamma * target_value)current_state = next_state6、DQN
DQN(深度 Q 网络)是一种无模型、非策略算法,它使用神经网络来逼近 Q 函数。DQN 特别适用于 Atari 游戏和其他类似问题,其中状态空间是高维的,并使用神经网络近似 Q 函数。
import numpy as np
from keras.models import Sequential
from keras.layers import Dense, Input
from keras.optimizers import Adam
from collections import deque# Define the Q-network model
model = Sequential()
model.add(Dense(32, input_dim=state_space_size, activation='relu'))
model.add(Dense(32, activation='relu'))
model.add(Dense(action_space_size, activation='linear'))
model.compile(loss='mse', optimizer=Adam(lr=0.001))# Define the replay buffer
replay_buffer = deque(maxlen=replay_buffer_size)for episode in range(num_episodes):current_state = initial_statewhile not done:# Select an action using an epsilon-greedy policyif np.random.rand() < epsilon:action = np.random.randint(0, action_space_size)else:action = np.argmax(model.predict(np.array([current_state]))[0])# Take the action and observe the next state and rewardnext_state, reward, done = take_action(current_state, action)# Add the experience to the replay bufferreplay_buffer.append((current_state, action, reward, next_state, done))# Sample a batch of experiences from the replay bufferbatch = random.sample(replay_buffer, batch_size)# Prepare the inputs and targets for the Q-networkinputs = np.array([x[0] for x in batch])targets = model.predict(inputs)for i, (state, action, reward, next_state, done) in enumerate(batch):if done:targets[i, action] = rewardelse:targets[i, action] = reward + gamma * np.max(model.predict(np.array([next_state]))[0])# Update the Q-networkmodel.train_on_batch(inputs, targets)current_state = next_state上面的代码,Q-network有2个隐藏层,每个隐藏层有32个神经元,使用relu激活函数。该网络使用均方误差损失函数和Adam优化器进行训练。
7、TRPO
TRPO (Trust Region Policy Optimization)是一种无模型的策略算法,它使用信任域优化方法来更新策略。它在具有高维观察和连续动作空间的环境中特别有用。
TRPO 是一个复杂的算法,需要多个步骤和组件来实现。TRPO不是用几行代码就能实现的简单算法。
所以我们这里使用实现了TRPO的现有库,例如OpenAI Baselines,它提供了包括TRPO在内的各种预先实现的强化学习算法,。
要在OpenAI Baselines中使用TRPO,我们需要安装:
pip install baselines然后可以使用baselines库中的trpo_mpi模块在你的环境中训练TRPO代理,这里有一个简单的例子:
import gym
from baselines.common.vec_env.dummy_vec_env import DummyVecEnv
from baselines.trpo_mpi import trpo_mpi# Initialize the environment
env = gym.make("CartPole-v1")
env = DummyVecEnv([lambda: env])# Define the policy network
policy_fn = mlp_policy# Train the TRPO model
model = trpo_mpi.learn(env, policy_fn, max_iters=1000)我们使用Gym库初始化环境。然后定义策略网络,并调用TRPO模块中的learn()函数来训练模型。
还有许多其他库也提供了TRPO的实现,例如TensorFlow、PyTorch和RLLib。下面时一个使用TF 2.0实现的样例
import tensorflow as tf
import gym# Define the policy network
class PolicyNetwork(tf.keras.Model):def __init__(self):super(PolicyNetwork, self).__init__()self.dense1 = tf.keras.layers.Dense(16, activation='relu')self.dense2 = tf.keras.layers.Dense(16, activation='relu')self.dense3 = tf.keras.layers.Dense(1, activation='sigmoid')def call(self, inputs):x = self.dense1(inputs)x = self.dense2(x)x = self.dense3(x)return x# Initialize the environment
env = gym.make("CartPole-v1")# Initialize the policy network
policy_network = PolicyNetwork()# Define the optimizer
optimizer = tf.optimizers.Adam()# Define the loss function
loss_fn = tf.losses.BinaryCrossentropy()# Set the maximum number of iterations
max_iters = 1000# Start the training loop
for i in range(max_iters):# Sample an action from the policy networkaction = tf.squeeze(tf.random.categorical(policy_network(observation), 1))# Take a step in the environmentobservation, reward, done, _ = env.step(action)with tf.GradientTape() as tape:# Compute the lossloss = loss_fn(reward, policy_network(observation))# Compute the gradientsgrads = tape.gradient(loss, policy_network.trainable_variables)# Perform the update stepoptimizer.apply_gradients(zip(grads, policy_network.trainable_variables))if done:# Reset the environmentobservation = env.reset()在这个例子中,我们首先使用TensorFlow的Keras API定义一个策略网络。然后使用Gym库和策略网络初始化环境。然后定义用于训练策略网络的优化器和损失函数。
在训练循环中,从策略网络中采样一个动作,在环境中前进一步,然后使用TensorFlow的GradientTape计算损失和梯度。然后我们使用优化器执行更新步骤。
这是一个简单的例子,只展示了如何在TensorFlow 2.0中实现TRPO。TRPO是一个非常复杂的算法,这个例子没有涵盖所有的细节,但它是试验TRPO的一个很好的起点。
总结
以上就是我们总结的7个常用的强化学习算法,这些算法并不相互排斥,通常与其他技术(如值函数逼近、基于模型的方法和集成方法)结合使用,可以获得更好的结果。
相关文章:

简述7个流行的强化学习算法及代码实现!
目前流行的强化学习算法包括 Q-learning、SARSA、DDPG、A2C、PPO、DQN 和 TRPO。这些算法已被用于在游戏、机器人和决策制定等各种应用中,并且这些流行的算法还在不断发展和改进,本文我们将对其做一个简单的介绍。1、Q-learningQ-learning:Q-…...

朗润国际期货招商:地方政府工作报告中对于促进消费
地方政府工作报告中对于促进消费 北京:把恢复和扩大消费摆在优先位置。加紧推进国际消费中心城市建设、深化商圈改造提升行动、统筹推进物流基地规划建设,强化新消费地标载体建设、试点建设80个“一刻钟便民生活圈”,提高生活性服务重品质。…...

前端性能优化的一些技巧(90% chatGpt生成)
终于弄好了chatGpt的账号,赶紧来体验一波。先来一波结论,这篇文章的主要内容来源,90%是用chatGpt生成的。先上chatGpt的生成的结果:作为一名懒惰的程序员,chatGpt会帮助我变得更懒...,好了下面开始文章的正…...
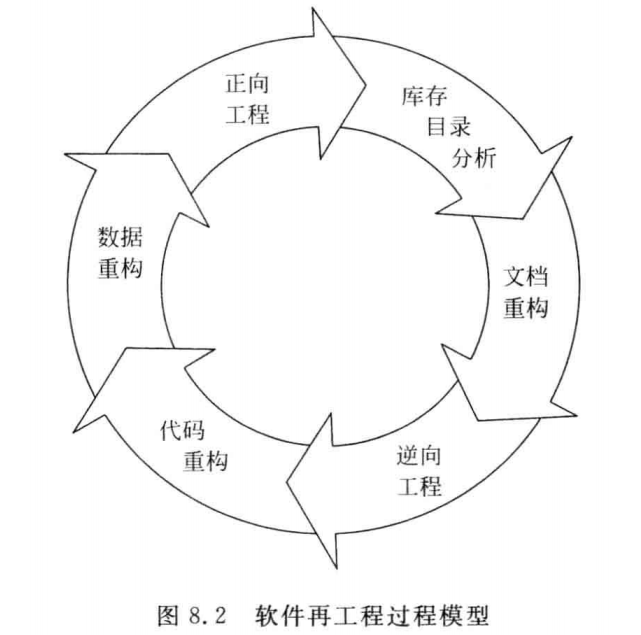
[软件工程导论(第六版)]第8章 维护(复习笔记)
文章目录8.1 软件维护的定义8.2 软件维护的特点8.3 软件维护过程8.4 软件的可维护性8.5 预防性维护8.6 软件再工程过程维护的基本任务:保证软件在一个相当长的时期能够正常运行软件工程的主要目的就是要提高软件的可维护性,减少软件维护所需要的工作量&a…...
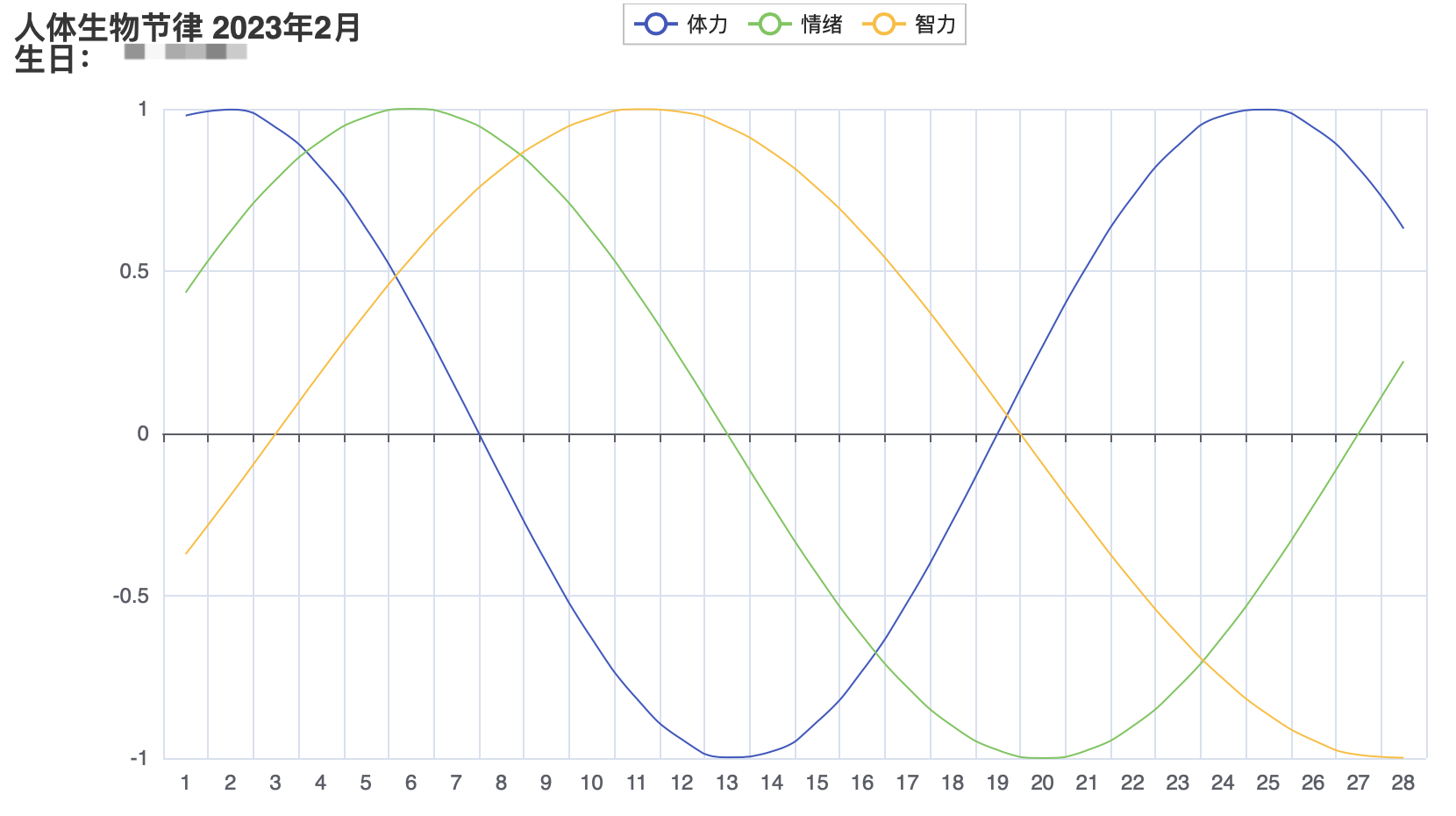
Python - 绘制人体生物节律
文章目录项目说明关于人体生物节律用到的技术代码实现获取每月有多少天计算每天到生日过了多少天计算节律绘图结果项目说明 这里仿照 http://www.4qx.net/The_Human_Body_Clock.php 做一个人体生物节律的计算和展示 关于人体生物节律 百度/维基百科 解释 https://zh.wikiped…...

【NVMEM子系统】二、NVMEM驱动框架
个人主页:董哥聊技术我是董哥,嵌入式领域新星创作者创作理念:专注分享高质量嵌入式文章,让大家读有所得!文章目录1、前言2、驱动框架3、源码目录结构4、用户空间下的目录结构1、前言 NVMEM SUBSYSTEM,该子系…...
小波神经网络(WNN)的实现(Python,附源码及数据集)
文章目录一、理论基础1、小波神经网络结构2、前向传播过程3、反向传播过程4、建模步骤二、小波神经网络的实现1、训练过程(WNN.py)2、测试过程(test.py)3、测试结果4、参考源码及实验数据集一、理论基础 小波神经网络(…...

商标干货!所有企业都值得收藏!
商标,是用于识别和区分不同商品或服务来源的标志,代表了企业的产品质量和服务保证,可以说,商标承载了一个企业的信誉,是企业参与市场竞争的重要工具,对于企业及其产品的重要性不言而喻。 根据《商标法》四十…...

4次迭代,让我的 Client 优化 100倍!泄漏一个 人人可用的极品方案!
4次迭代,让我的HttpClient提速100倍 在大家的生产项目中,经常需要通过Client组件(HttpClient/OkHttp/JDK Connection)调用第三方接口。 尼恩的一个生产项目也不例外。 在一个高并发的中台生产项目中。有一个比较特殊的请求,一次…...

并查集(高级数据结构)-蓝桥杯
一、并查集并查集(Disioint Set):一种非常精巧而实用的数据结构用于处理不相交集合的合并问题。用于处理不相交集合的合并问题。经典应用:连通子图。最小生成树Kruskal算法。最近公共祖先。二、应用场景有n个人,他们属于不同的帮派。 已知这些…...
你是真的“C”——C语言详解求两个正数最小公倍数的3种境界
C语言详解求两个正数最小公倍数的3种境界~😎前言🙌必备小知识~😘求最小公倍数境界1~ 😊求最小公倍数境界2~ 😊求最小公倍数境界3~ 😊总结撒花💞博客昵称:博客小梦😊 最喜…...

【java】Spring Cloud --Feign Client超时时间配置以及单独给某接口设置超时时间方法
文章目录feign配置(最常用)ribbon配置hystrix配置单独给某接口设置超时时间FeignClient面对服务级有三种超时时间配置feign配置(最常用) feign:sentinel:enabled: trueclient:config:default://全部服务配置connectTimeout: 5000…...

spark代码
RDD Tom,DataBase,80 Tom,Algorithm,50 Tom,DataStructure,60 Jim,DataBase,90 Jim,Algorithm,60 Jim,DataStructure,80 该系总共有多少学生; val lines sc.textFile("file:///usr/local/spark/sparksqldata/Data01.txt") val par lines.map(ro…...
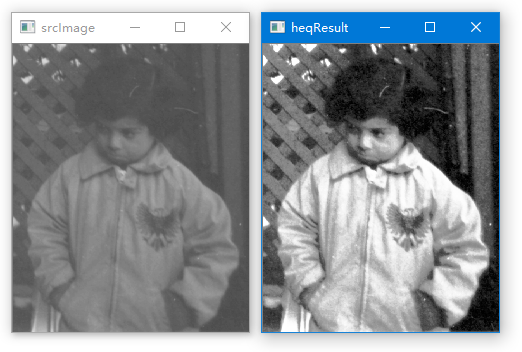
利用OpenCV的函数equalizeHist()对图像作直方图均衡化处理
如果一幅图像的灰度值集中在某个比较窄的区域,则图像的对比度会显得比较小,不便于对图像的分析和处理。 图像的直方图均衡化可以实现将原图像的灰度值范围扩大,这样图像的对比度就得到了提高,从而方便对图像进行后续的分析和处理…...

星河智联Android开发
背景:朋友内推,过了一周约面。本人 2019年毕业 20230208一面 1.自我介绍 2.为啥换工作 3.项目经历(中控面板、智能音箱、语音问的比较细) 4.问题 Handler机制原理?了解同步和异步消息吗?View事件分发…...

【C++】关联式容器——map和set的使用
文章目录一、关联式容器二、键值对三、树形结构的关联式容器1.set2.multiset3.map4.multimap四、题目练习一、关联式容器 序列式容器📕:已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C11)等,这些容器统称为…...

Promise的实现原理
作用:异步问题同步化解决方案,解决回调地狱、链式操作原理: 状态:pending、fufilled reject构造函数传入一个函数,resolve进入then,reject进入catch静态方法:resolve reject all any react ne…...
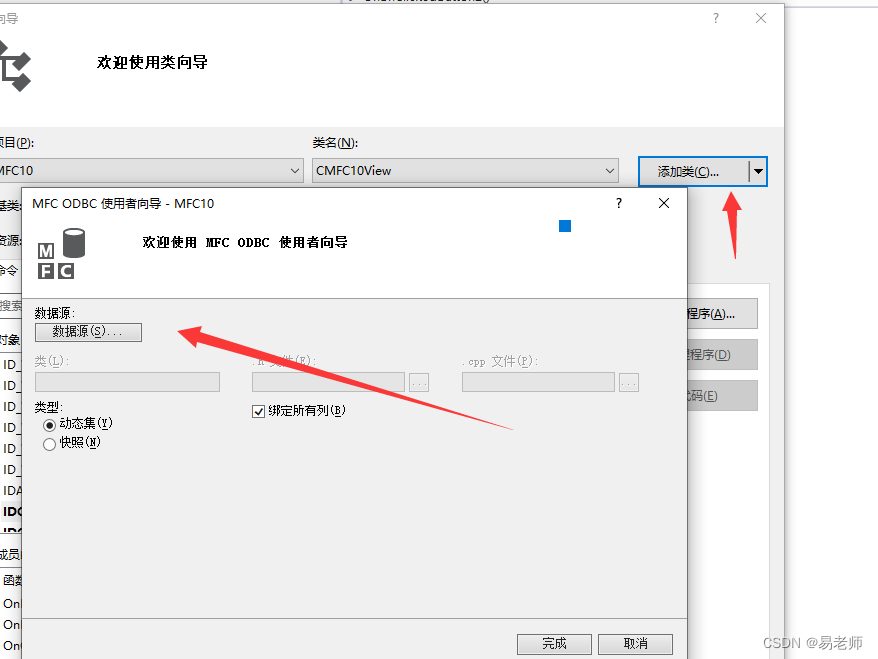
【MFC】数据库操作——ODBC(20)
ODBC:开放式数据库连接,是为解决异构数据库(不同数据库采用的数据存储方法不同)共享而产生的。ODBC API相对来说非常复杂,这里介绍MFC的ODBC类。 添加ODBC用户DSN 首先,在计算机中添加用户DSN:(WIN10下&a…...
旺店通与金蝶云星空对接集成采购入库单接口
旺店通旗舰奇门与金蝶云星空对接集成采购入库单查询连通销售退货新增V1(12-采购入库单集成方案-P)数据源系统:旺店通旗舰奇门旺店通是北京掌上先机网络科技有限公司旗下品牌,国内的零售云服务提供商,基于云计算SaaS服务模式,以体系化解决方案…...
Linux基础-学会使用命令帮助
概述使用 whatis使用 man查看命令程序路径 which总结参考资料概述Linux 命令及其参数繁多,大多数人都是无法记住全部功能和具体参数意思的。在 linux 终端,面对命令不知道怎么用,或不记得命令的拼写及参数时,我们需要求助于系统的…...

产品经理开需求会必看!2026年5款会议纪要自动生成软件,真香体验散会就出完整纪要
做产品的天天泡需求会,做销售的天天跑客户要整理录音,做学生的天天要整理访谈,不同人对转写工具的需求天差地别——有人要准确率不能漏需求,有人要便宜不能月月大出血,有人要能识别方言听不懂客户说啥也不怕。我测了市…...

Gerrit与GitLab单向同步实战:配置详解与常见问题排查
1. 为什么需要Gerrit与GitLab单向同步? 在代码管理的工作流中,Gerrit和GitLab各自扮演着不同角色。Gerrit以强大的代码审核机制著称,而GitLab则更擅长作为Git仓库托管平台。很多团队既想保留GitLab现有的CI/CD流程,又希望引入Gerr…...

Bedrock Launcher:一键畅玩Minecraft基岩版全版本的终极解决方案
Bedrock Launcher:一键畅玩Minecraft基岩版全版本的终极解决方案 【免费下载链接】BedrockLauncher 项目地址: https://gitcode.com/gh_mirrors/be/BedrockLauncher 还在为Minecraft基岩版版本切换而烦恼吗?每次想体验不同版本都要卸载重装&…...

GLM-OCR模型处理SolidWorks工程图中的技术说明
GLM-OCR模型处理SolidWorks工程图中的技术说明 在制造业和工程设计领域,SolidWorks输出的二维工程图是产品信息的核心载体。一张图纸里,除了几何图形,还包含了大量的文本信息:技术要求、标题栏里的零件名称与材料、明细表中的零件…...

ai结对编程:在快马平台借助kimi进行代码审查与智能重构
今天想和大家分享一个特别实用的开发技巧——如何利用AI辅助工具来提升代码质量。最近我在InsCode(快马)平台上尝试了Kimi模型的代码审查功能,发现它不仅能找出代码中的潜在问题,还能给出具体的优化方案,整个过程就像有个经验丰富的开发者在旁…...

【实战 01】任务定义:从经营维度构建 Text2SQL Agent 评测基准
0. 引言:数据分析的“最后一公里”在大型集团的数字化实践中,BI 看板解决了“看数”的问题,但无法解决“问数”的即时性。业务人员(如置业顾问、项目总、财务经理)往往有大量碎片的、非标的数据需求。Text2SQL Agent 的…...

Python自动化:调用企业微信API高效推送邮件通知
1. 为什么需要企业微信邮件自动化 每天手动发送运营报告的日子我受够了。作为团队的技术负责人,曾经每周都要花2小时整理数据、写邮件、检查收件人列表。直到发现企业微信API能实现全自动化,现在整个过程只需30秒,准确率还更高。 企业微信的邮…...

GHelper:重新定义华硕设备的硬件控制体验
GHelper:重新定义华硕设备的硬件控制体验 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus, Flow, TUF, Strix, Scar, and othe…...
)
边走边聊 Python 3.8:Chapter 1 Win7 上手 Python 3.8(环境篇)
Chapter 1:Win7 上手 Python 3.8(环境篇) 在 Win7 上学习 Python,从来不是一件轻松的事:版本兼容、环境变量、注册表、库安装……每一步都可能踩坑。但正因为如此,当你真正把 Python 跑起来,你会比任何人都更懂系统、懂环境、懂底层。本章将带你从零开始,搭建一个稳定…...
)
智慧算力枢纽中心建设方案:从“烟囱林立”到“云网融合”的数字化重构(PPT)
摘要:本文基于《智慧算力枢纽中心建设方案》,深度剖析了在数字经济爆发式增长背景下,如何通过“云-网-端”一体化架构解决传统IT基础设施“资源孤岛、运维割裂、安全脆弱”的行业痛点。文章详细阐述了从传统服务器向全栈资源池化演进的技术路…...