Python统计中文词频的四种方法
统计中文词频是Python考试中常见的操作,由于考察内容较多,因此比较麻烦,那么有没有好的方法来实现呢?今天,我们总结了四种常见的中文词频统计方法,并列出代码,供大家学习参考。
中文词频统计主要是通过open()打开文本,然后read()方法读取后,采用结巴分词(jieba)模块进行分词,接着用推表推导式、Counter或者是字典的方法来统计词频,也可以采用NLTK的方法,最后格式化打印出来。
题目:统计中文文本文件【词频统计文本.txt】中长度大于1的词的词频,然后打印出词频数最高的10个词。
默认系统里已经安装好了jieba这个模块。如果还没有安装,可以在cmd下通过pip install jieba来安装这个模块。
一、字典法——常用的方法
先读取文本,然后jieba分词,再对分词后的列表进行遍历,然后用字典统计词频。这里排除了单个词,代码如下:
import jieba
txt = open("词频统计文本.txt", "r").read()
words = jieba.lcut(txt)
counts = {}
for word in words:if len(word) == 1: #排除单个字符的分词结果continueelse:counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(10):word, count = items[i]print("{0:<10}{1:>5}".format(word,count))
print ('已统计数量排前10的词')二、Counter法——代码简单,速度快
先生成Counter对象,再排序,最后再打印出来。这里我们使用了most_common的方法,代码更为简洁,更好理解一点。代码如下:
import jieba
from collections import Counter
with open("词频统计文本.txt", "r",encoding="utf-8") as f:words = jieba.lcut(f.read())words = [item for item in words if len(item)>1]
counts = Counter(words)
for word,count in counts.most_common(10):print(word,count)
print ('已统计数量排前10的词')三、NLTK方法——有点儿小麻烦
利用列表推导式筛选列表,利用NLTK中的FreqDist来统计列表中的词步,代码如下。
import jieba,os
from nltk.probability import FreqDist
with open("词频统计文本.txt","r",encoding="utf-8") as f:text = f.read()
words = jieba.lcut(text)
lst = [i for i in words if len(i)>1]
freq = FreqDist(lst)
for item in freq.most_common(10):word,count=itemprint(f"{word:<10}\t{count:<5}")
print ('已统计数量排前10的词')使用这种方法,得安装nltk包,较为麻烦。
四、列表推导式法
如果不借助其它包,我们可以充分利用Python自带的count方法和列表推导式,实现词频的统计。这其中与前面排序的方法不同的是,我们采用了sorted的方法,完整代码如下:
import jieba,os
with open("词频统计文本.txt","r",encoding="utf-8") as f:text = f.read()
words = jieba.lcut(text)
lst = [(key,words.count(key)) for key in set(words) if len(key)>1]
items = sorted(lst,key=lambda x:x[1],reverse=True)
for i in range(10):word, count = items[i]if len(word) == 1: #排除单个字符的分词结果continueelse:print(f"{word:<10}\t{count:<5}")
print ('已统计数量排前10的词')五、学后反思
1. 中文词频统计主要考察文本的读取、列表的遍历、jieba分词、词频统计、排序、结果的格式化和打印输出等综合能力。因此,它是Python二级中常考的题目,认真学习,并找出多种词频统计的方法可以更好地理解Python中的相关概念和基础语法知识。
2. 四种方法中最麻烦的是NLTK法和列表推导式化,字典法和Counter方法最为常用,字典法常出现在考试中,而Counter的方法实用性更强,大家可以有选择地使用。
3. 有了词频表,后续可以进行可视化的图表生成,包括词云图和线形图等,以便更直观地观察语篇中词的特点。
相关文章:

Python统计中文词频的四种方法
统计中文词频是Python考试中常见的操作,由于考察内容较多,因此比较麻烦,那么有没有好的方法来实现呢?今天,我们总结了四种常见的中文词频统计方法,并列出代码,供大家学习参考。 中文词频统计主…...
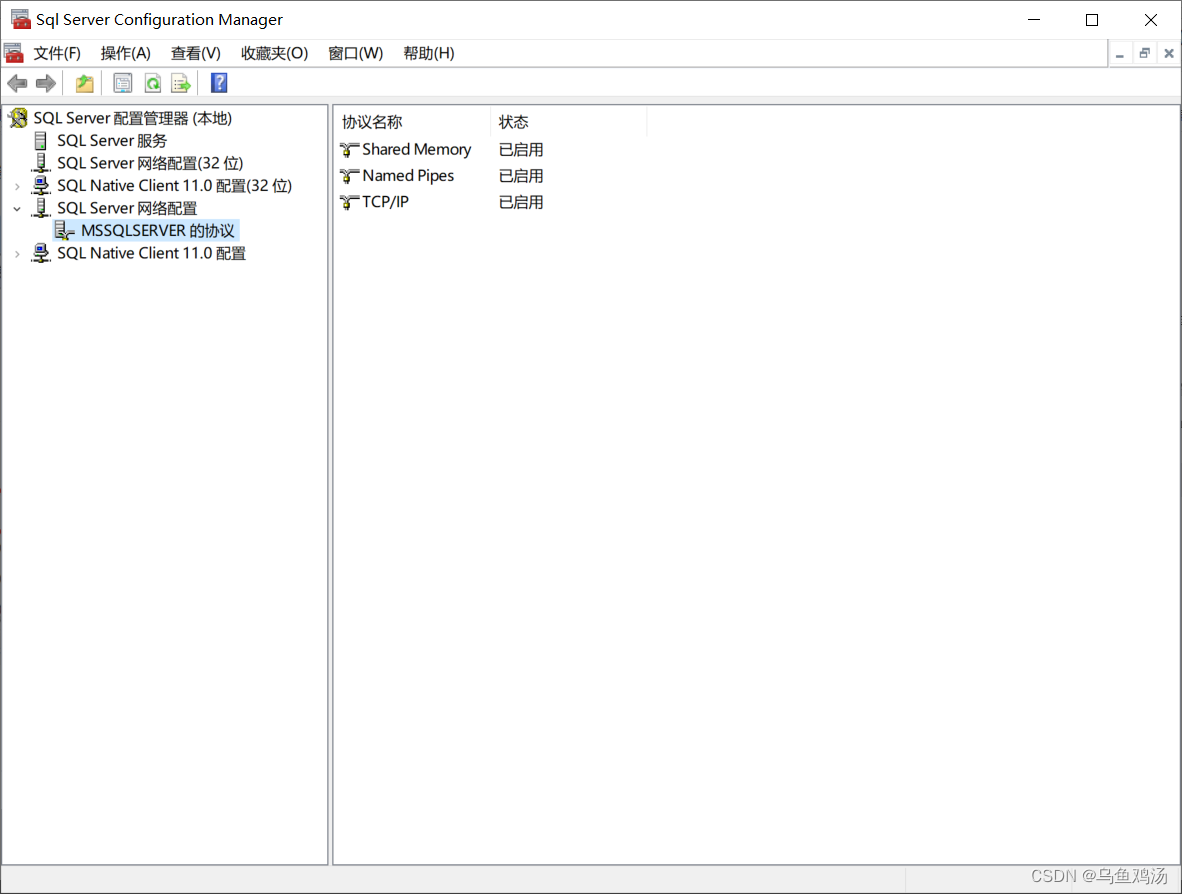
sql server 快速安装
目录标题 一、下载二、直接选择基本安装二、下载ssms(数据库图形化操作页面)三、开启sa账号认证(一)第一步:更改身份验证模式(二)第二步:启用 sa 登录四、开启tcp/ip 一、下载 下载…...

机器学习之损失函数
深度学习中常用的损失函数多种多样,具体选择取决于任务类型和问题的性质。以下是一些常见的深度学习任务和相应的常用损失函数: 分类任务: 交叉熵损失函数(Cross-Entropy Loss):用于二分类和多类别分类任务…...

nacos适配SqlServer、Oracle
继上文《nacos适配达梦、瀚高、人大金仓数据库及部分源码探究 》后补充nacos适配SqlServer、Oracle的贴码,主要区别是SqlServer、Oracle的分页SQL有点不一样,做个记录; SqlServer的分页有三种实现方式:offset /fetch next、利用ma…...
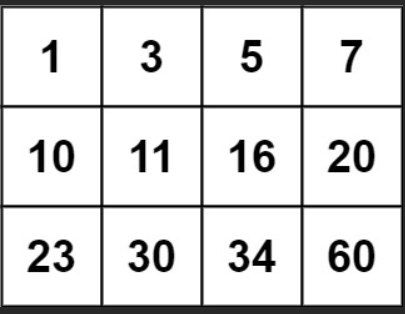
力扣:74. 搜索二维矩阵(Python3)
题目: 给你一个满足下述两条属性的 m x n 整数矩阵: 每行中的整数从左到右按非递减顺序排列。每行的第一个整数大于前一行的最后一个整数。 给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返…...

CPU、MCU、MPU、SOC、SOCPC、概念解释之在嵌入式领域常听到的名词含义
CPU、MCU、MPU、SOC等几个在嵌入式领域学习过程中会涉及到的几个名词。我们来学习一下,资料从网上搜集的,有错的地方可以指出。。。 CPU、MCU、MPU、SOC、SOCPC、 1. CPU2. MPU3.MCUMPU和MCU的区别:4.SOC5. SoPC 1. CPU CPU,即中…...
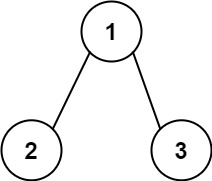
每日两题 111二叉树的最小深度 112路径总和(递归)
111 题目 给定一个二叉树,找出其最小深度。 最小深度是从根节点到最近叶子节点的最短路径上的节点数量。 说明:叶子节点是指没有子节点的节点。 示例 1: 输入:root [3,9,20,null,null,15,7] 输出:2示例 2&#x…...
实训笔记8.24
实训笔记8.24 8.24笔记一、Sqoop数据迁移工具1.1 Sqoop的基本概念1.2 Sqoop的基本操作1.2.1 命令语法1.2.2 list-databases1.2.3 list-tables1.2.3 eval1.2.4 import1.2.5 export1.2.6 导入 二、Flume日志采集工具2.1 数据采集的问题2.2 数据采集一般使用的技术2.3 扩展&#x…...
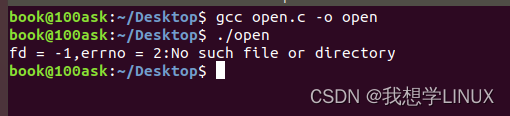
Linux下的系统编程——系统调用(五)
前言: 由操作系统实现并提供给外部应用程序的编程接口。(Application Programming Interface,API)。系统调用就是应用程序同系统之间数据交互的桥梁。 open/close函数 1.open函数: (1)int open(char *pathname, int flags) …...

动物体外受精手术VR模拟仿真培训系统保证学生及标本的安全
奶牛是养殖业主要的资源,因此保证奶牛的健康对养殖业的成功和可持续发展具有重要已用,奶牛有一些常见易发病,一旦处理不当,对奶牛业都会造成较大的经济损失,传统的奶牛手术培训实操难度大、风险高且花费大,…...
微信小程序|步骤条
步骤条是现代用户界面设计中常见的元素之一,它能够引导用户按照预定顺序完成一系列任务或步骤。在小程序中,实现步骤条可以为用户提供更好的导航和引导,使用户体验更加流畅和直观。本文将介绍如何在小程序中实现步骤条,并逐步展示实现的过程和关键技巧 目录 步骤条的作用及…...

如何才能设计出“好的”测试用例?
软件测试用例的设计质量直接影响到测试的完整性、有效性以及自动化测试的实施效果,是软件测试成功的重要保证,良好的软件测试用例对于提高测试的有效性和效率至关重要。那大家知道好的测试用例该怎么写吗?应该从哪几个方面来撰写呢࿱…...
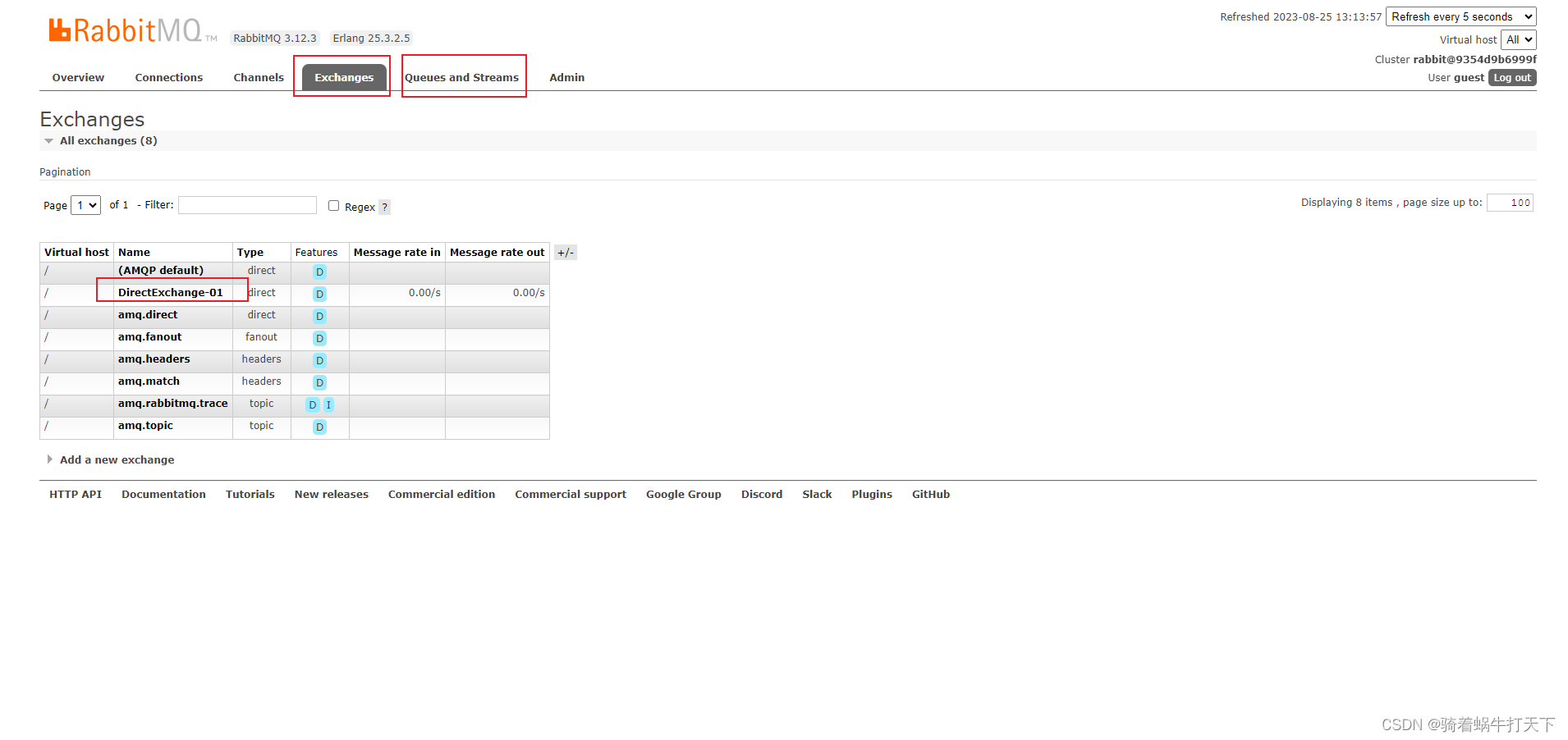
DirectExchange直连交换机
目录 一、简介 二、使用步骤 三、demo 父pom文件 pom文件 配置文件 config 消费者 生产者 测试 一、简介 直连型交换机,根据消息携带的路由键将消息投递给对应队列。 大致流程,有一个队列绑定到一个直连交换机上,同时赋予一个路由…...

Shell 编程:探索 Shell 的基本概念与用法
目录 Shell 简介 Shell 脚本 Shell 脚本运行 Shell 变量 1、创建变量和赋值 2、引用变量 3、修改变量的值 4、只读变量 5、删除变量 6、环境变量 Shell 字符串操作 1、拼接字符串 2、字符串长度 3、字符串截取 Shell 数组 1、创建数组 2、访问数组元素 shell …...
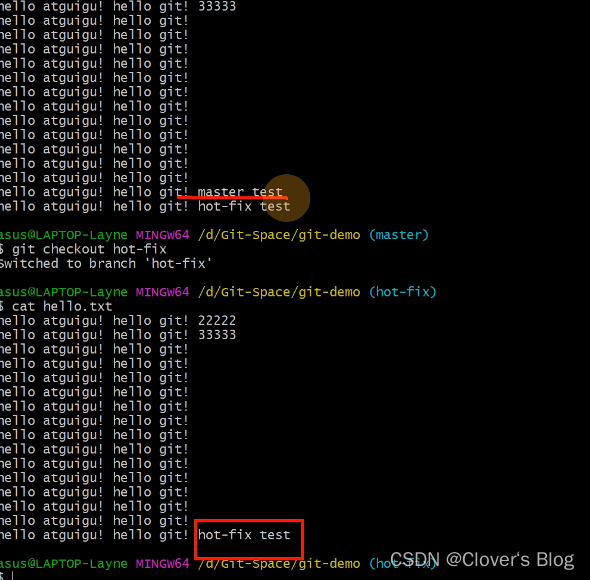
【Git分支操作---讲解二】
Git分支操作---讲解二 查看分支创建分支切换分支修改分支切换分支合并分支合并分支【冲突】(只会修改主分支不会修改其他分支)什么时候会有冲突? 查看分支 创建分支 切换分支 修改分支 切换分支 合并分支 合并分支【冲突】(只会修改主分支不会修改其他分支) 什么时…...

vue2+qrcodejs2+clipboard——实现二维码展示+下载+复制到剪切板——基础积累
最近在写后台管理系统时,遇到一个需求就是要实现二维码的展示下载复制到剪切板。 效果图如下: 1.二维码展示下载功能——qrcodejs20.0.2 我是安装的qrcodejs20.0.2,指定了具体的版本号,也可以安装默认的当前稳定版本࿰…...

【PHP】echo 输出数组报Array to string conversion解决办法
代码: <?PHP echo "Hello World!";$demoName array("kexuexiong","xiong");echo "<pre>";var_dump($demoName);echo $demoName; print_r($demoName);echo "</pre>"; ?>输出结果࿱…...
)
Arduino驱动MiCS-4514气体传感器(气体传感器篇)
目录 1、传感器特性 2、控制器和传感器连线图 3、驱动程序...

marked在vue项目中改变超链接跳转方式和图片放大预览
marked在vue项目中改变超链接跳转方式和图片放大预览 这里我是另起一个js文件对marked的配置做了修改,参考如下 import marked from marked let renderer new marked.Renderer() const linkRenderer renderer.link const imgRenderer renderer.image // 超链接…...
leetcode485. 最大连续 1 的个数
思路:【双指针】 left左边界,right往右跑遇到0,则计算该长度。并更新cnt(最大连续1个数)。 class Solution { public:int findMaxConsecutiveOnes(vector<int>& nums) {int left 0, right 0;int cnt 0;…...

GEO优化实战指南:中小企业如何精准提升本地服务获客效率?
随着线上营销的重要性日益凸显,中小企业面临着前所未有的机遇与挑战。GEO(生成式引擎优化)作为近年来兴起的一种技术手段,旨在帮助企业更高效地利用AI平台进行品牌推广与客户获取。本文将探讨中小企业如何通过GEO优化策略…...

LabVIEW多语言界面开发:基于JKI Simple Localization的控件本地化实战
1. 项目概述与核心思路 在开发面向全球用户的LabVIEW应用程序时,多语言界面支持是一个绕不开的刚需。想象一下,你的测控软件或工业自动化系统需要部署到不同国家,如果每次都要为不同语言单独开发一套界面,那工作量无疑是巨大的&am…...

3步高效解决Krita AI Diffusion插件IP-Adapter缺失问题
3步高效解决Krita AI Diffusion插件IP-Adapter缺失问题 【免费下载链接】krita-ai-diffusion Streamlined interface for generating images with AI in Krita. Inpaint and outpaint with optional text prompt, no tweaking required. 项目地址: https://gitcode.com/gh_mi…...

猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载
猫抓浏览器扩展完全指南:5步掌握网页视频资源嗅探与下载 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否曾经遇到过想保存网页上…...

安装离线版mysql,全网最详细
CentOS7 离线安装 MySQL 5.7 完整版(一次装好、配置齐全、开机自启、远程访问、字符集、防火墙、环境变量、日志、权限全部搞定,零返工)适配你的服务器:CentOS Linux release 7.6.1810 x86_64,Java1.8 已就绪ÿ…...
)
从零开始:手把手教你用Python解析MMD的PMX模型文件(附完整代码)
从零开始:手把手教你用Python解析MMD的PMX模型文件(附完整代码) 在3D图形与游戏开发领域,MMD(MikuMikuDance)的PMX模型文件因其丰富的表情骨骼系统和精致的二次元风格而广受欢迎。本文将带领你从二进制层面…...

前后端分离项目避坑指南:为什么你的网关CORS配置了还是报跨域错误?
前后端分离项目避坑指南:为什么你的网关CORS配置了还是报跨域错误? 在前后端分离架构中,跨域资源共享(CORS)问题一直是开发者绕不开的"拦路虎"。即便在网关层正确配置了CORS规则,开发者仍可能遇到…...

别再乱画了!GD32/STM32复位与唤醒按键电路设计,90%新手会踩的坑
GD32/STM32复位与唤醒按键电路设计避坑指南 1. 复位电路设计的核心误区与解决方案 许多工程师在设计GD32/STM32复位电路时,往往低估了RC时间常数的重要性。我曾亲眼见过一个团队花费两周时间排查系统随机重启问题,最终发现竟是复位电路中一个10kΩ电阻被…...
:谷歌AI团队内部培训手册泄露版)
NotebookLM具身智能落地实战(从零部署到ROS2集成):谷歌AI团队内部培训手册泄露版
更多请点击: https://intelliparadigm.com 第一章:NotebookLM具身智能研究 NotebookLM 是 Google 推出的基于用户自有文档进行语义理解与推理的 AI 助手,其核心能力在于“文档感知”(document-grounded reasoning)。当…...

Ti AWR2243实测:毫米波雷达通道积累,选相干还是非相干?一个实验讲清楚
Ti AWR2243毫米波雷达通道积累策略:工程实践中的深度抉择 毫米波雷达在现代自动驾驶系统中扮演着关键角色,而通道积累策略的选择直接影响着目标检测的精度与系统实时性。面对192个虚拟通道的海量数据,工程师们常常陷入两难:是追求…...